


三
剑
客
你好

如今AI绘画已经延伸出了诸多分支,光是模型就有成千上万种,那么我们又应当如何选取自己所需要的模型呢?

模型网站中各式各样的模型 今天,就让我们来认识一下基本的三种模型类型吧!

尽管Checkpoint这个单词看上去很陌生,但其实这是我们日常绘画中最常接触到的模型选手。
我们在WebUI和ComfyUI中的第一步,都是用于加载这个节点:

<<< 左右滑动见更多 >>>
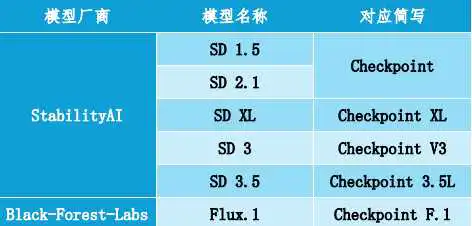
现在,最基础的Checkpoint是由Stability AI 和 Black Forest Labs开源提供的SD系列模型和Flux模型:
具体的对应关系,可以参考以下表格:
而目前我们所能看见的大量Checkpoint,都是基于这些基础模型进行的微调,从而实现对不同画风和技巧的偏重。




<<< 左右滑动见更多 >>>
Checkpoint的微调技术,又被称为Dreambooth,是指对不同的绘画风格和技巧有所侧重的训练,但没有对整个基础模型进行重新塑造。
当然,Checkpoint也有其局限的地方:
| 序号 | 局限 |
|---|---|
| 1 | 需要较大的数据集训练 |
| 2 | 训练需至少12GB显存支持 |
| 3 | 训练需要数个小时或者更多 |
| 4 | 模型大小普遍不小于2GB |
那么如何克服这些问题呢?
让我们先来梳理一下训练一个Checkpoint给我们带来的挑战,主要有以下两点:
作为一个基础节点,需要采集大量的画风一致的图片,为此所需要的 训练成本就相对较高; 作为吸取了大量数据的模型, 体量自然而言就会更大。
但有些时候,我们并不希望为每一种问题单独训练一个模型,比如:
画面的 手部细节问题; 一个 新火的二次元人物形象,比如黑神话悟空; 一些 复合概念,比如 哆啦A梦,山海经里的 异兽等。
当我们的需求从整体性的画风转变为细节控制时,训练一个Checkpoint来满足这个需求,就多少显得有些“杀鸡焉用牛刀”了。
这就是为什么出现了Embedding和LoRA技术。

熟悉大模型原理的观众可能对Embedding这个词语并不陌生,其本质即将文本转化为向量。
在绘画领域,我们通常借用这项技术,帮助绘画模型明确一些复合概念,比如玩具猫、狐妖等等:
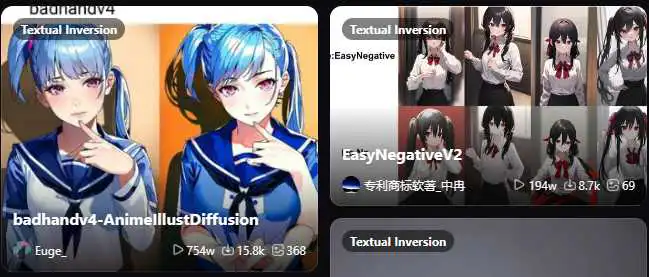
在上图中的两个Embedding模型,是最常使用以控制图片手部姿势等细节,相较于Checkpoint动辄2GB的体量,这些模型只需要数十个KB即可完成指定任务。
在训练成本上,Embedding几乎不需要训练时间,因为究其本质,它只是为绘画模型提供了参考书目的清单,帮助AI更好理解绘画任务。
小R提供的补充资料:https://stable-diffusion-art.com/embedding/
Embedding只是在文本阶段对模型进行了调整,但模型并不真的了解具体的细节:语言的描述也存在极限。
尤其是越新颖的概念,越会让模型无从下手。
但出于成本思维,我们只希望基于少量图片,对某一概念进行训练,以规避大量消耗,这就是LoRA技术。
通过学习少量图片,形成对某一概念的强化,实现了“小模型,少改动,大优化”的效果。
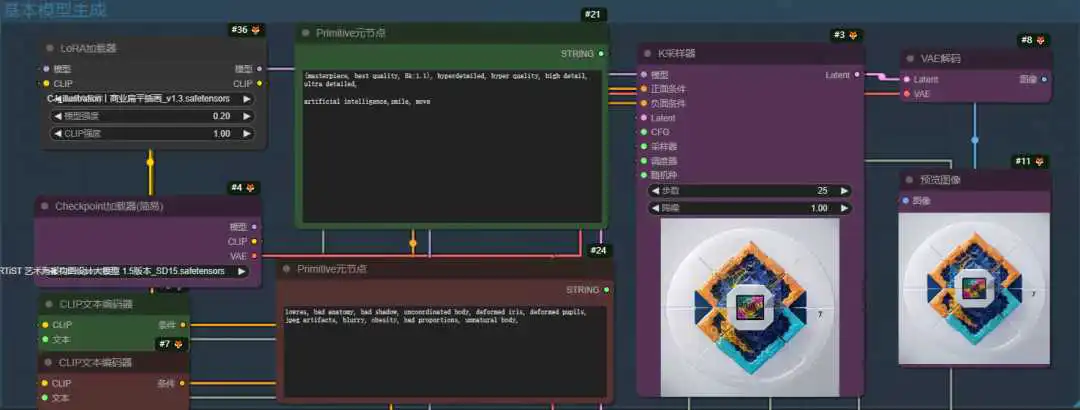
LoRA和Embedding,这两项技术都是建立在Checkpoint上的应用,这也是为什么他们能以极小的体量,对画面进行改动。
现在,我们可以这样理解这三类模型:
| 流程 | 应用 |
|---|---|
| 原先 | 文本 + Checkpoint |
| 现在 | 文本 + Embedding优化 + Checkpoint + LoRA优化 |
通过灵活应用Embedding和LoRA模型,我们便能起到“一个基础模型,多种风格”的效果,小R在这里也为大家准备了更深理解三者关系的资料,我们下次再见!
-
穿针引线,高效办公新境界:扣子工作流 -
精准调控AI绘画参数,掌握细节之美! -
自定义绘画不是梦:SD 框架下的“积木”与“电路” -
AI高清重塑细节之美,让图片素材焕发新生 -
AI画家请听令:从“低分辨率”到“杰作”的华丽转身!
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/57409.html