
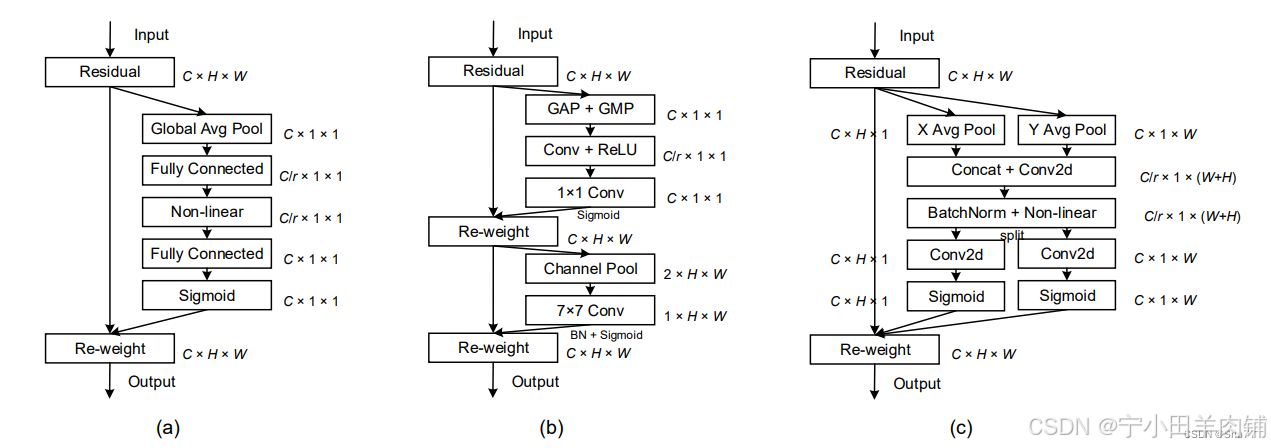
U-Net网络模型(注意力改进版本)
这一段时间做项目用到了U-Net网络模型,但是原始的U-Net网络还有很大的改良空间,在卷积下采样的过程中加入了通道注意力和空间注意力
常规的U-net模型如下图:
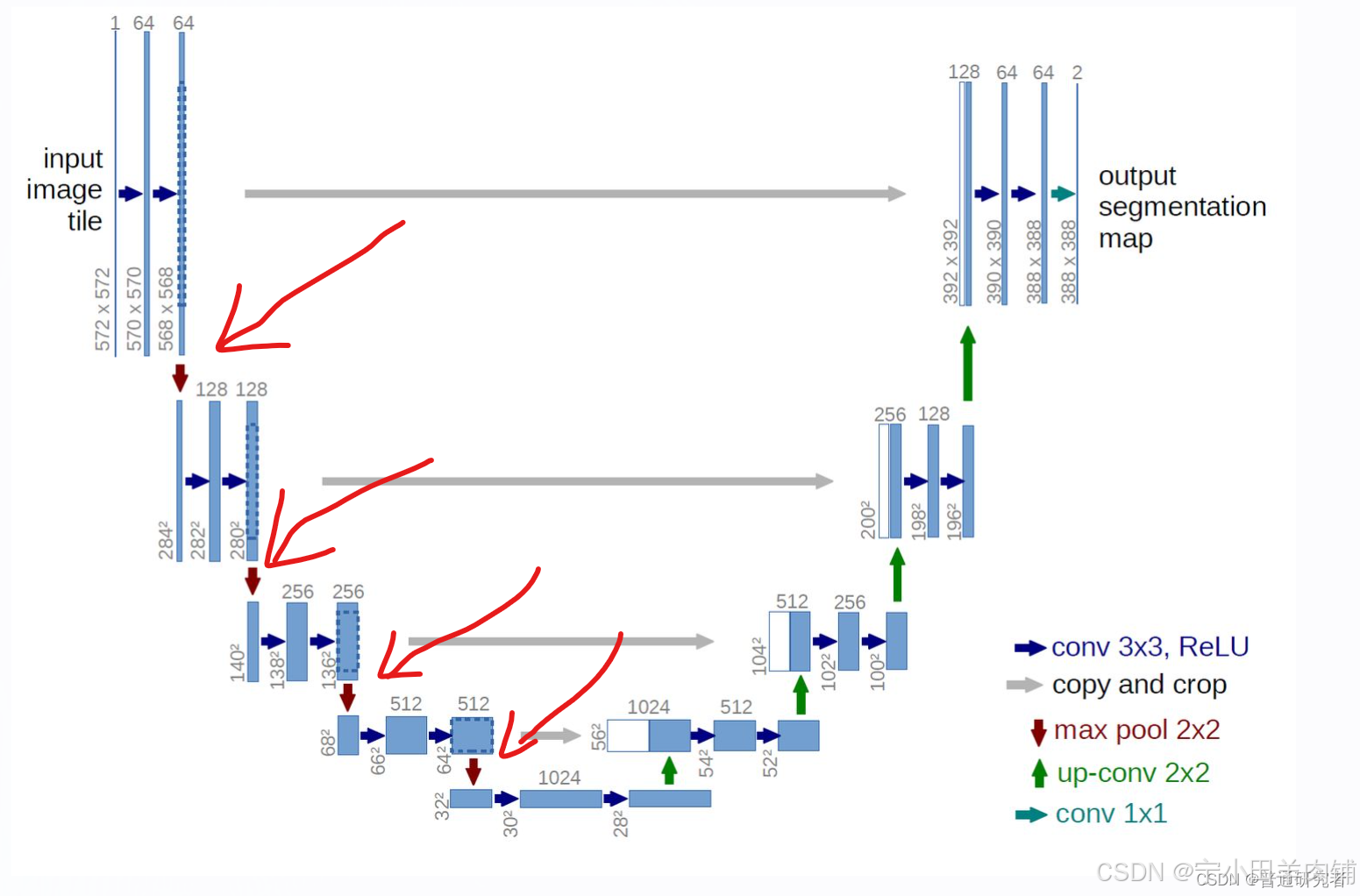
红色箭头为可以添加的地方:即下采样之间。
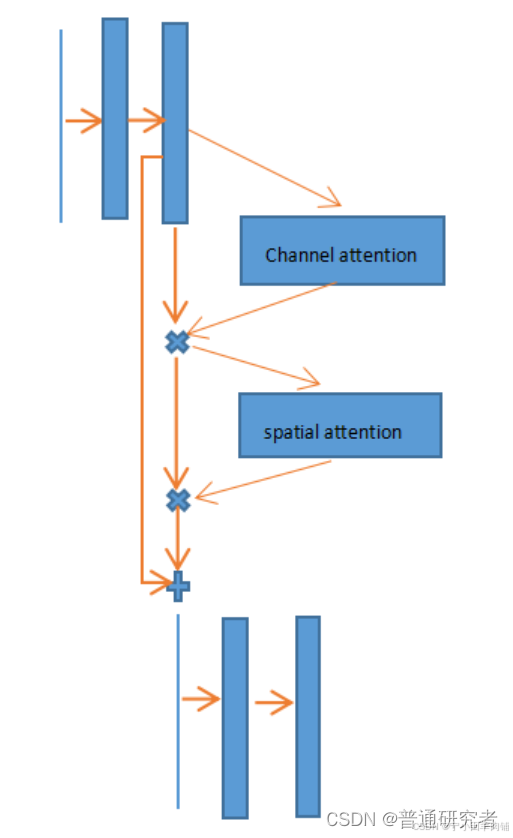
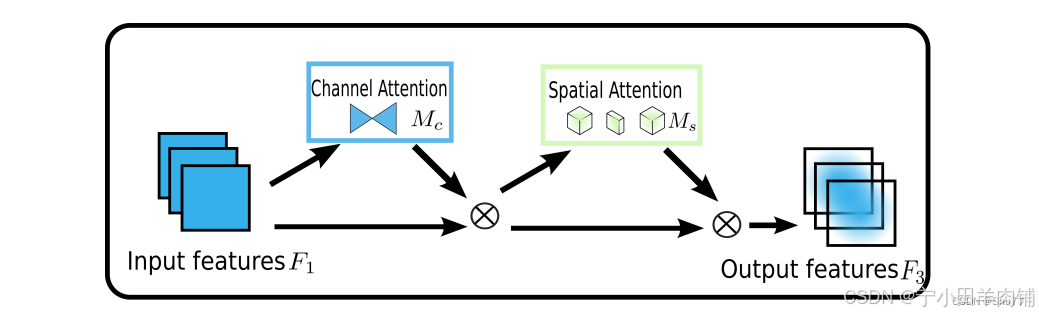
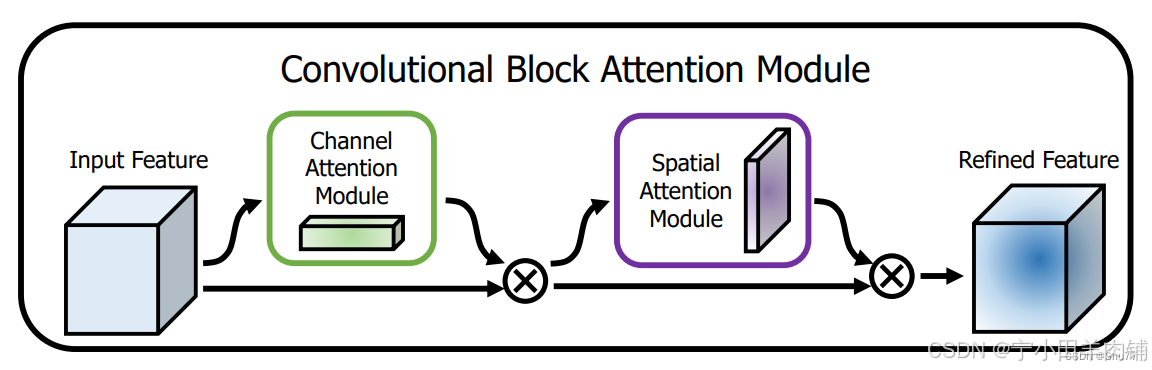
通道空间注意力是一个即插即用的注意力模块(如下图):
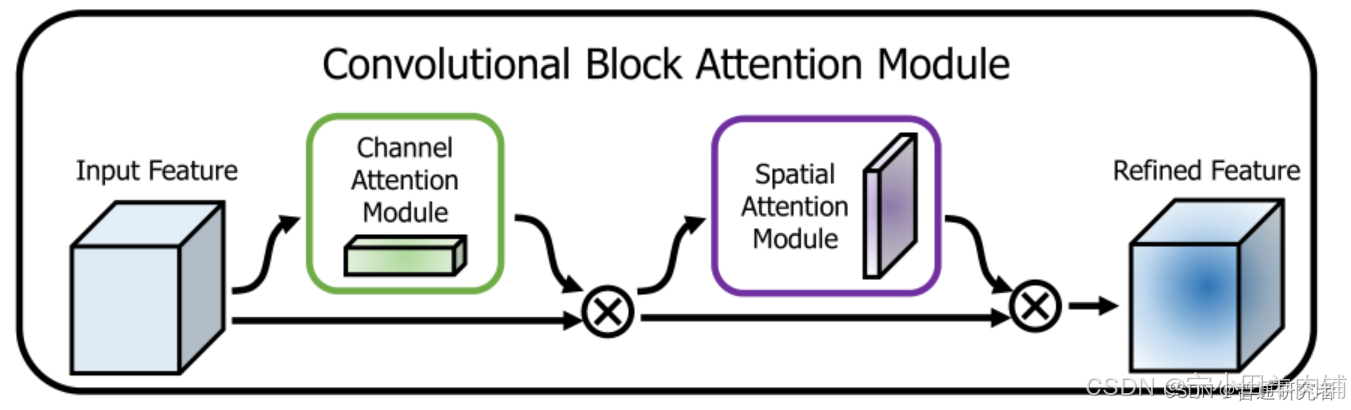
代码加入之后对于分割效果是有提升的:(代码如下)
CBAM代码:
网络模型结合之后代码
BiFPN 的主要思想:高效双向跨尺度连接和加权特征融合。
多尺度特征表示是目标检测的重点方向之一,作者认为其主要困难是如何有效地表示和处理多尺度特征。
早期的检测器通常直接根据从骨干网络中提取的金字塔特征层次结构进行预测 。
特征金字塔网络 (FPN)提出了一种自上而下的途径来组合多尺度特征。
基于FPN,PANet 在 FPN 之上添加了一个额外的自下而上的路径聚合网络;
NAS‑FPN [8]利用神经架构搜索来自动设计特征网络拓扑。虽然实现了更好的性能,但 NAS‑FPN 在搜索过程中需要数千 GPU 小时,并且生成的特征网络是不规则的,因此难以解释。
BiFPN:引入可学习的权重来学习不同输入特征的重要性,同时重复应用自上而下和自下而上的多尺度特征融合.
下图表示各类网络模型的结构:
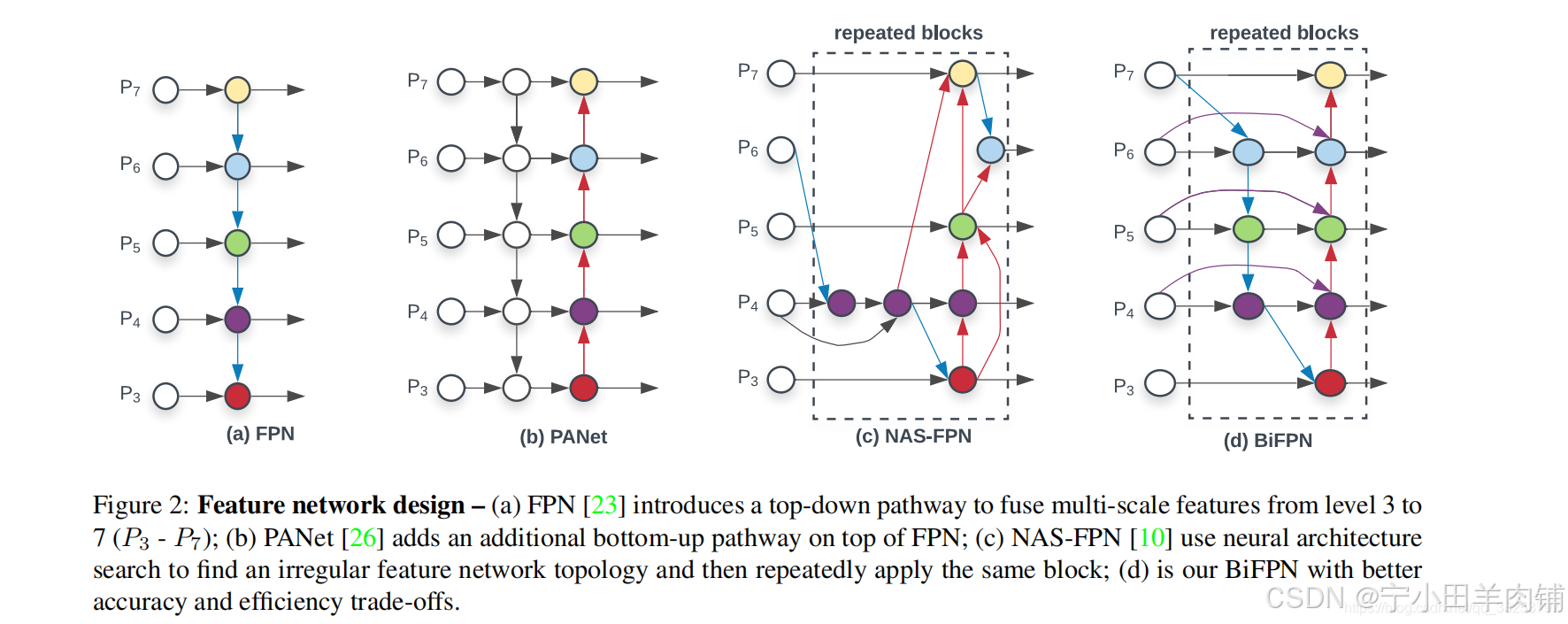
( a ) FPN 引入自上而下的路径来融合从 3 级到 7 级(P3 ‑ P7)的多尺度特征;
( b ) PANet 在 FPN 之上添加了一个额外的自下而上的路径;
( c ) NAS‑FPN 使用神经架构搜索找到不规则的特征网络拓扑,然后重复应用相同的块;
( d ) BiFPN 双向跨尺度连接和加权特征融合,具有更好的准确性和效率权衡。
简单了解过后,我们开始改进!
提示:以下是本篇文章改进内容,下面案例可供参考
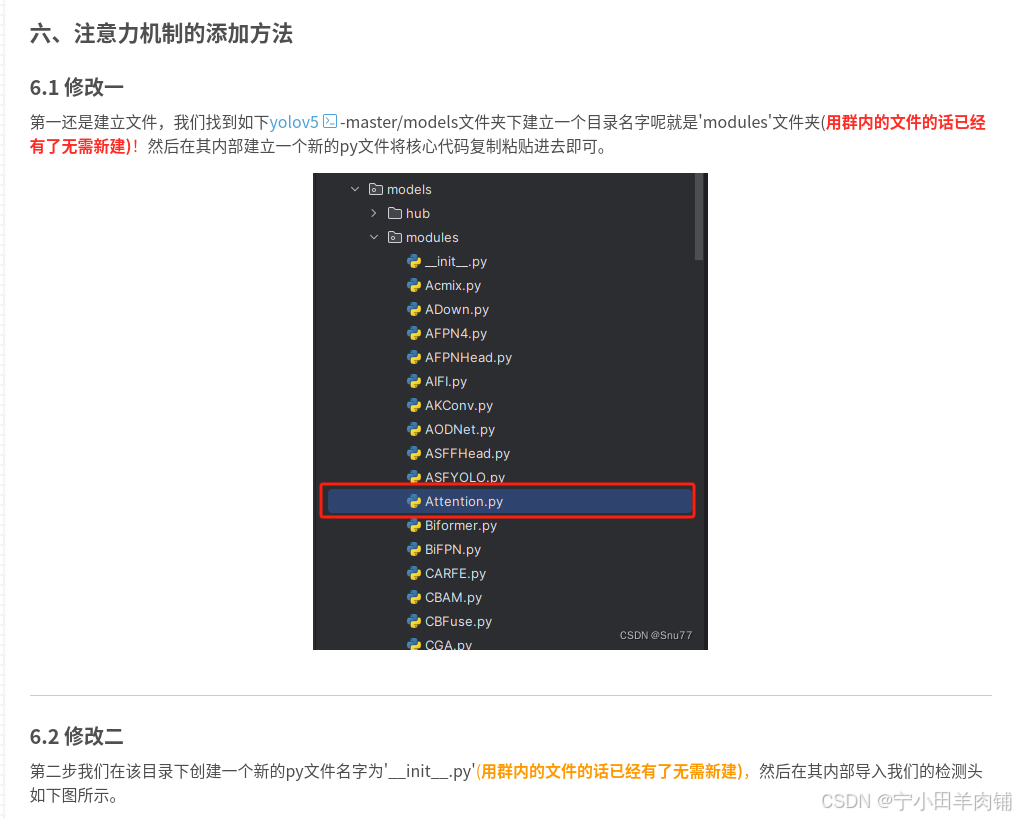
一、替换yaml文件
改进后的文件如下:
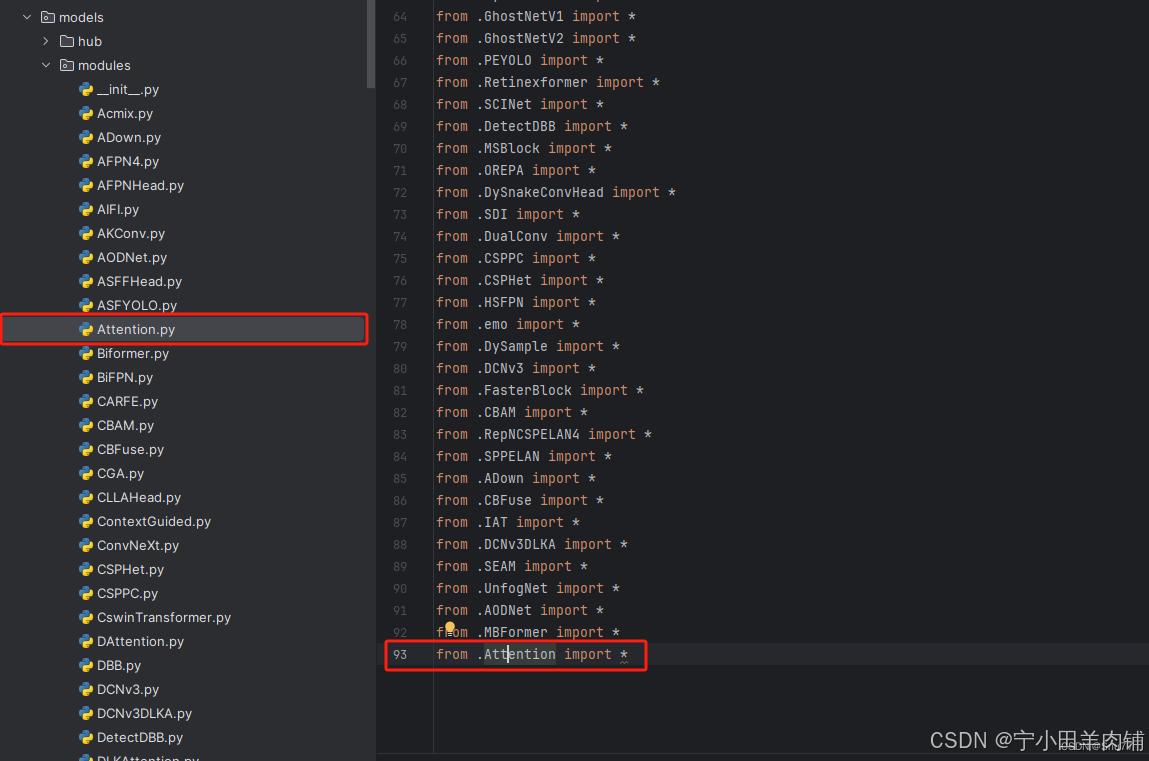
在nn文件夹中新建bifpn.py文件
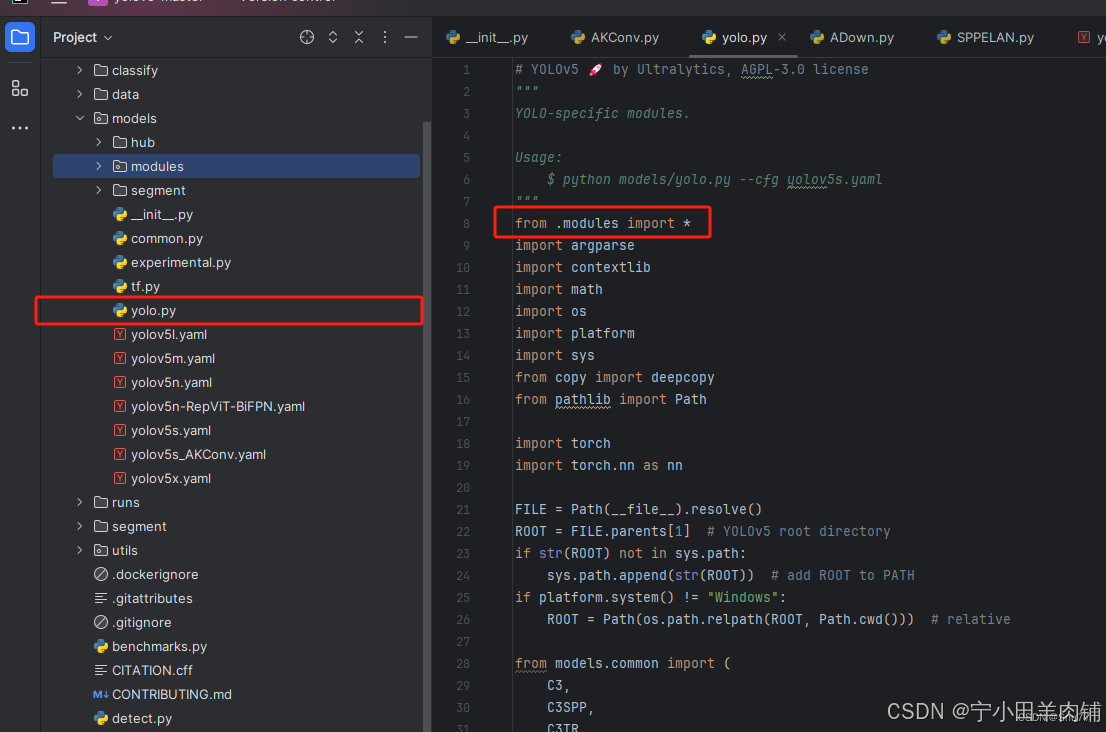
在nn文件夹中找到tasks.py文件,进行内容上的替换即可




![]()
![]()
![]()








![]()


![]()




![]()
这篇文章介绍了YOLOv5的重大改进,特别是在损失函数方面的创新。它不仅包括了多种IoU损失函数的改进和变体,如SIoU、WIoU、GIoU、DIoU、EIOU、CIoU,还融合了“Focus”思想,创造了一系列新的损失函数。这些组合形式的损失函数超过了二十余种,每种都针对特定的目标检测挑战进行优化。文章会详细探讨这些损失函数如何提高YOLOv5在各种检测任务中的性能,包括提升精度、加快收敛速度和增强模型对复杂场景的适应性。本文章主要是为了发最近新出的Inner思想改进的各种EIoU的文章服务,其中我经过实验在绝大多数下的效果都要比本文中提到的各种损失效果要好。

在理解各种损失函数之前我们需要先来理解一下交集面积和并集面积,在数学中我们都学习过集合的概念,这里的交集和并集的概念和数学集合中的含义是一样的。
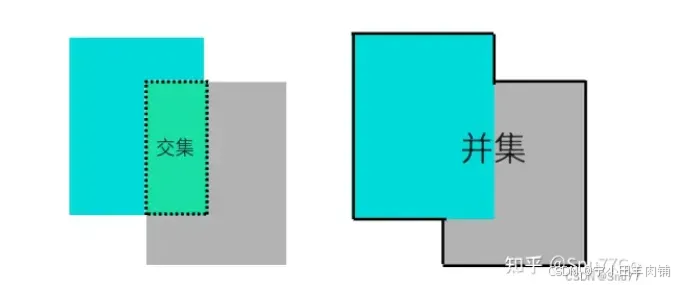
论文地址:IoU Loss for 2D/3D Object Detectio
适用场景:普通的IoU并没有特定的适用场景
概念: 测量预测边界框和真实边界框之间的重叠度(最基本的边界框损失函数,后面的都是居于其进行计算)。

论文地址:SIoU: More Powerful Learning for Bounding Box Regression
适用场景:适用于需要高精度边界框对齐的场景,如精细的物体检测和小目标检测。
概念: SIoU损失通过融入角度考虑和规模敏感性,引入了一种更为复杂的边界框回归方法,解决了以往损失函数的局限性,SIoU损失函数包含四个组成部分:角度损失、距离损失、形状损失和第四个未指定的组成部分。通过整合这些方面,从而实现更好的训练速度和预测准确性。

论文地址:WIoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism
适用场景:适用于需要动态调整损失焦点的情况,如不均匀分布的目标或不同尺度的目标检测。
概念:引入动态聚焦机制的IoU变体,旨在改善边界框回归损失。

论文地址:GIoU: A Metric and A Loss for Bounding Box Regression
适用场景:适合处理有重叠和非重叠区域的复杂场景,如拥挤场景的目标检测。
概念: 在IoU的基础上考虑非重叠区域,以更全面评估边界框

论文地址:DIoU: Faster and Better Learning for Bounding Box Regression
适用场景:适用于需要快速收敛和精确定位的任务,特别是在边界框定位精度至关重要的场景。
概念:结合边界框中心点之间的距离和重叠区域。
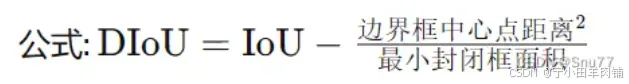
论文地址:EIoU:Loss for Accurate Bounding Box Regression
适用场景:可用于需要进一步优化边界框对齐和形状相似性的高级场景。
概念:EIoU损失函数的核心思想在于提高边界框回归的准确性和效率。它通过以下几个方面来优化目标检测:
1. 增加中心点距离损失:通过最小化预测框和真实框中心点之间的距离,提高边界框的定位准确性。
2. 考虑尺寸差异:通过惩罚宽度和高度的差异,EIoU确保预测框在形状上更接近真实框。
3. 结合最小封闭框尺寸:将损失函数与包含预测框和真实框的最小封闭框的尺寸相结合,从而使得损失更加敏感于对象的尺寸和位置。
EIoU损失函数在传统IoU基础上增加了这些考量,以期在各种尺度上都能获得更精确的目标定位,尤其是在物体大小和形状变化较大的场景中。
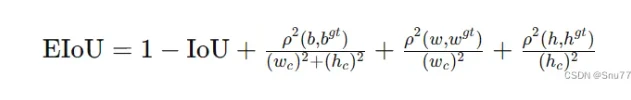
论文地址:CIoU:Enhancing Geometric Factors in Model Learning
适用场景:适合需要综合考虑重叠区域、形状和中心点位置的场景,如复杂背景或多目标跟踪。
概念:综合考虑重叠区域、中心点距离和长宽比。

论文地址:Focal Loss for Dense Object Detection
适用场景:适用于需要高精度边界框对齐的场景,如精细的物体检测和小目标检测。
Focal Loss由Kaiming He等人在论文《Focal Loss for Dense Object Detection》中提出,旨在解决在训练过程中正负样本数量极度不平衡的问题,尤其是在一些目标检测任务中,背景类别的样本可能远远多于前景类别的样本。
Focal Loss通过修改交叉熵损失,增加一个调整因子,这个因子降低了那些已经被正确分类的样本的损失值,使得模型的训练焦点更多地放在难以分类的样本上。这种方式特别有利于提升小目标或者在复杂背景中容易被忽视的目标的检测性能。简而言之,Focal Loss让模型“关注”(或“专注”)于学习那些对提高整体性能更为关键的样本。
sECANet(Spatial-Channel-SENet)通道注意力机制是一种新型的注意力机制,结合了空间注意力和通道注意力,可以更好地捕捉物体在图像中的空间和通道信息。在Mask R-CNN中加入sECANet通道注意力机制,可以使模型更加精确地定位和分割物体,提高模型的准确率和鲁棒性。
具体来说,加入sECANet通道注意力机制的Mask R-CNN的优势有以下几点:
1.更好的特征表示:sECANet通道注意力机制可以提高特征的表达能力,使得模型可以更好地捕捉物体的空间和通道信息,从而提高特征表示的质量。
2.更精确的定位和分割:通过加入sECANet通道注意力机制,模型可以更加准确地定位和分割物体,从而提高模型的准确率和鲁棒性。
3.更高的效率:sECANet通道注意力机制可以帮助模型更快地收敛,从而提高模型的训练效率和推理速度。
综上所述,加入sECANet通道注意力机制的Mask R-CNN具有更好的特征表示、更精确的定位和分割以及更高的效率等优势。
到此这篇aodnet复现(centernet复现)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/83214.html