

作者|都一凡
机构|中国人民大学
研究方向|多模态大模型
-
Q1. 改变帧数对模型效果有什么影响? -
Q2. 改变视觉token的数量对模型效果有什么影响?
2.1.1 基于采样的方法
/section>
section style="letter-spacing: 0em;text-indent: 0em;padding-top: 8px;padding-bottom: 8px;margin: 8px;line-height: 1.75em;">
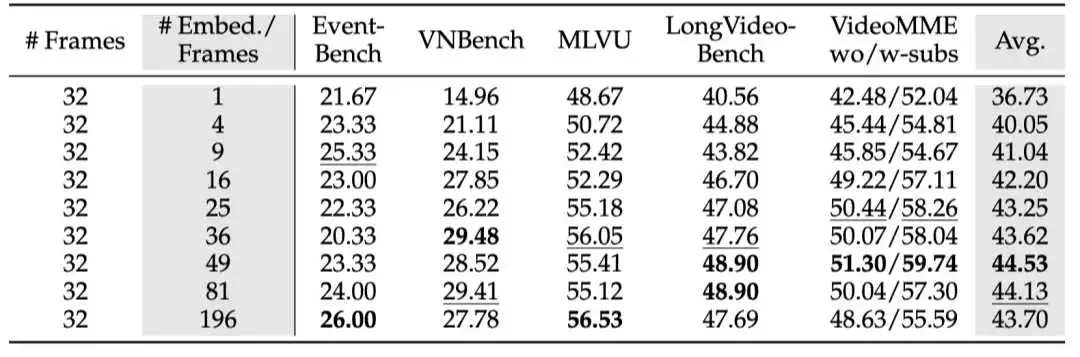
下表展示了在长视频理解的benchmark上改变视觉token数量的对模型效果的影响。总体来看,随着视觉token数量的增加,模型性能有所提升,特别是在token数量从 1 增加到 4 时提升最为明显。然而,有趣的是,当token数量超过某个阈值后,性能反而开始下降。例如,使用 196 个token的效果比使用 49 个token还要差,尽管使用 196 个token时的语言模型损失明显小于使用 49 个token时的损失,这表明模型loss并不总是能直接反映其在下游任务中的真实表现。/section>
section style="letter-spacing: 0em;text-indent: 0em;padding-top: 8px;padding-bottom: 8px;text-align: center;margin: 8px;line-height: 1.75em;">
表1. 采样视觉token对模型效果的影响/section>
section style="background-attachment: scroll;background-clip: border-box;background-image: none;background-origin: padding-box;background-position: 0% 0%;background-repeat: no-repeat;background-size: auto;width: auto;font-size: 16px;color: rgb(0, 0, 0);word-spacing: 0em;letter-spacing: 0em;word-break: break-word;margin: 8px;line-height: 1.75em;">
/section>
h4 data-tool="mdnice编辑器" style="margin: 8px;line-height: 1.75em;">
2.1.2 基于压缩的方法section style="letter-spacing: 0em;text-indent: 0em;padding-top: 8px;padding-bottom: 8px;margin: 8px;line-height: 1.75em;">
我们采用了 MeanPooling 策略来压缩视觉token,这种方法被目前的许多MLLM广泛采用,其优点是不引入额外的参数,避免了其他因素对实验结果的影响。我们在编码后的视觉token上使用不同的kernel size进行 MeanPooling,从而得到图像的压缩表示。具体来说,每张图像会被编码为 27×27 的视觉token矩阵,然后我们对其应用 的 MeanPooling,步长也为 ,其中 。这会将每张图像压缩成 1²、2²、3²、4²、5²、6²、7²、9² 和 14² 个token表示。为了保证能和基于采样的方法进行公平比较,其他实验条件保持不变。/section>
section style="letter-spacing: 0em;text-indent: 0em;padding-top: 8px;padding-bottom: 8px;margin: 8px;line-height: 1.75em;">
拟合得到的参数为:,
表明拟合结果较好。相比于上面提到的基于采样方法的参数
,压缩方法的
明显更大。这意味着使用压缩方法增加token数量时,损失会下降得更快,在上面的曲线图中也能明显的看出。此外,
压缩方法在相同的视觉token数量下,总是比采样方法得到的loss更低。这是因为压缩方法聚合了所有token中的信息,但是采样的方法直接丢弃部分视觉token,前者更有利于模型学习视觉特征,加速收敛速度。
随着视觉token数量的增加,模型能力持续提升
。这与基于采样的方法明显不同,进一步突出了压缩方法的优势。Benchmark上的结果和根据loss得到的结论一致,表明压缩方法在性能上具有更明显的优势。
figure data-tool="mdnice编辑器" style="margin-top: 10px;margin-bottom: 10px;display: flex;flex-direction: column;justify-content: center;align-items: center;">
Take-away Findings
section style="overflow-x: auto;padding: 16px;color: rgb(51, 51, 51);background: rgb(248, 248, 248);display: -webkit-box;font-family: Consolas, Monaco, Menlo, monospace;font-size: 12px;margin: 8px;line-height: 1.75em;">
- 增加视觉token的数量可以显著提升性能。基于采样的方法在 49 个token时达到峰值,而基于压缩的方法即使使用 196 个token也没有出现性能饱和。- 当视觉上下文窗口大小受限时,基于压缩方法能够用更少的token有效保留更多的视觉信息,得到更好的表现。
/section>
,改变
来探索帧数的scaling law。仍然是考虑基于采样和基于压缩的方法,如下图所示:
img src="https://mmbiz.qpic.cn/mmbiz_png/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKTZyViaohd2HxGOwxtfDibcTIzr3TkW0vnG2pFyjY0WJOxRp1r1tMay1ZA/640?wx_fmt=png&from=appmsg" class="rich_pages wxw-img" data-imgfileid="100107770" data-ratio="0.8366197183098592" data-src="https://mmbiz.qpic.cn/mmbiz_png/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKTZyViaohd2HxGOwxtfDibcTIzr3TkW0vnG2pFyjY0WJOxRp1r1tMay1ZA/640?wx_fmt=png&from=appmsg" data-type="png" data-w="710" style="display: block;margin-right: auto;margin-left: auto;height: auto !important;" width="380">
img src="https://mmbiz.qpic.cn/mmbiz_png/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKTmDWibvvvUvcZMb0CDVu6u8oAPfB3Whla3K5CYFzgfCQuJibickzDReDxw/640?wx_fmt=png&from=appmsg" class="rich_pages wxw-img" data-imgfileid="100107768" data-ratio="0.743073047858942" data-src="https://mmbiz.qpic.cn/mmbiz_png/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKTmDWibvvvUvcZMb0CDVu6u8oAPfB3Whla3K5CYFzgfCQuJibickzDReDxw/640?wx_fmt=png&from=appmsg" data-type="png" data-w="794" style="display: block;margin-right: auto;margin-left: auto;height: auto !important;" width="380">
设置为 {1, 8, 16, 32, 48, 64, 96, 128},来探索scaling效果。
与帧数
进行拟合,得到以下参数:
,表明拟合效果较好。如上图所示,拟合曲线显示
随着帧数
的增加而减少,并呈现出幂律趋势。
img src="https://mmbiz.qpic.cn/mmbiz_jpg/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKT7WGk5kRtSDIIoIq5jiahWl4QIYu79dNgyegc6Npeb2PuicpxnloMvUSg/640?wx_fmt=jpeg" class="rich_pages wxw-img" data-croporisrc="https://mmbiz.qpic.cn/mmbiz_png/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKT4KnadxOmyOR6RnwnSyQTVI8LNcLImw1aVPqF06EZ1V07o2DMKuXv3w/640?wx_fmt=png&from=appmsg" data-cropx1="0" data-cropx2="1080" data-cropy1="7.741935483870967" data-cropy2="313.54838709677415" data-imgfileid="100107771" data-ratio="0.28425925925925927" data-src="https://mmbiz.qpic.cn/mmbiz_jpg/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKT7WGk5kRtSDIIoIq5jiahWl4QIYu79dNgyegc6Npeb2PuicpxnloMvUSg/640?wx_fmt=jpeg" data-type="jpeg" data-w="1080" style="display: block;margin-right: auto;margin-left: auto;border-style: none;border-width: 3px;border-color: rgba(0, 0, 0, 0.4);border-radius: 0px;object-fit: fill;box-shadow: rgba(0, 0, 0, 0) 0px 0px 0px 0px;width: 558px;height: 158px;height: auto !important;">
,而这类任务无法仅通过增加帧数有效 解决。总体来看,与增加每帧的视觉token数相比,
对模型性能的提升更加显著。
来获得更好的性能。这个权衡将在下面得到进一步的验证。
帧,编码之后沿时间维度进行均值池化,将视频压缩为
帧。时间池化的核大小
取决于
和
的比例:
。
br />由于计算内存的限制,我们将
设为 128,并 选择
来探索帧数的扩展规律。为了与基于采样的方法进行公平比较,我们也将每帧的视觉token数量减少到 49。在实际操作中,我们使用
,而不是先进行空间均值池化后再进行时间池化,以避免feature map的过度平滑。
可以更好地描述其关系。我们根据帧数
拟合模型损失,得到
,
表明拟合较好。同时,对比
与
的方法曲线,压缩方法始终表现出更低的损失。这一现象揭示了视频数据中的
,即便将时间信息压缩到更少的帧中,仍能有效保留其关键内容。
img src="https://mmbiz.qpic.cn/mmbiz_jpg/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKTq7Fsh0ic2BWkZyphiaCt9uAI3lXRprk2NdLMW7Zp2CocmpvIZMlY8tTg/640?wx_fmt=jpeg" class="rich_pages wxw-img" data-croporisrc="https://mmbiz.qpic.cn/mmbiz_png/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKTRIicgmcrDWQlHw1CoKI4jGWmhKREMgp6hIuiaTmCOAGOSjAnXwO2jfYw/640?wx_fmt=png&from=appmsg" data-cropx1="0" data-cropx2="1080" data-cropy1="5.806451612903225" data-cropy2="280.64516129032256" data-imgfileid="100107773" data-ratio="0.25462962962962965" data-src="https://mmbiz.qpic.cn/mmbiz_jpg/G7ia3FZ0o0ObRwGlflEdGkhcmSziaAKTq7Fsh0ic2BWkZyphiaCt9uAI3lXRprk2NdLMW7Zp2CocmpvIZMlY8tTg/640?wx_fmt=jpeg" data-type="jpeg" data-w="1080" style="display: block;margin-right: auto;margin-left: auto;border-style: none;border-width: 3px;border-color: rgba(0, 0, 0, 0.4);border-radius: 0px;object-fit: fill;box-shadow: rgba(0, 0, 0, 0) 0px 0px 0px 0px;width: 558px;height: 142px;height: auto !important;">
- 在有限的视觉上下文窗口中,基于压缩的方法比基于采样的方法在更少帧数的情况下保留更多时间信息。
建模为
和
的函数。在给定最大视觉上下文窗口大小
的情况下,
和
必须满足以下约束条件:
。由于我们希望在LLM的最大 输入长度或部署资源受限的情况下,同时确定视觉token数量和帧数的最佳组合,这等价于找到损失
的极小值点:
section data-formula="T_{\text{opt}}(L), M_{\text{opt}}(L) = \underset{T,M \text{ s.t. } T \times M < L}{\operatorname{arg min}} \mathcal{L}(T,M),
" style="text-align: center;overflow: auto;">
embed style="vertical-align: -2.473ex;width: 40.875ex;height: auto;max-width: 300% !important;" src="https://mmbiz.qpic.cn/mmbiz_svg/wJibWkqN1bUOUh2ph1dntLv6FgAxaibaicwxj7ASIxBxNKEwK06Yr4Zw1ShHdgxEcYolVR6Eia72ibjB18NQxNa36rcj5zfo12qSY/0?wx_fmt=svg&from=appmsg" data-type="svg+xml" data-imgfileid="100107525">
g stroke="currentColor" fill="currentColor" stroke-width="0" transform="matrix(1 0 0 -1 0 0)">
/g>
g>
/g>
g stroke="currentColor" fill="currentColor" stroke-width="0" transform="matrix(1 0 0 -1 0 0)">
/g>
g>
/g>
g stroke="currentColor" fill="currentColor" stroke-width="0" transform="matrix(1 0 0 -1 0 0)">
/g>
g>
/g>
g data-mml-node="msub">
/g>
g data-mml-node="mo" transform="translate(1785.9, 0)">
/g>
g data-mml-node="mn" transform="translate(2841.7, 0)">
/g>
g data-mml-node="mi">
/g>
g data-mml-node="mo" transform="translate(917.8, 0)">
/g>
g data-mml-node="mn" transform="translate(1973.6, 0)">
/g>
g data-mml-node="msub">
/g>
g data-mml-node="mo" transform="translate(1540.6, 0)">
/g>
g data-mml-node="mn" transform="translate(2596.4, 0)">
/g>
g data-mml-node="mi">
/g>
g data-mml-node="mo" transform="translate(843.8, 0)">
/g>
g data-mml-node="mn" transform="translate(1899.6, 0)">
/g>
g data-mml-node="msub">
/g>
g data-mml-node="mo" transform="translate(1362.3, 0)">
/g>
g data-mml-node="mn" transform="translate(2418.1, 0)">
/g>
g data-mml-node="msup">
/g>
g data-mml-node="mo" transform="translate(1440.3, 0)">
/g>
g data-mml-node="mn" transform="translate(2496.1, 0)">
/g>
g data-mml-node="mi">
/g>
g data-mml-node="mo" transform="translate(981.8, 0)">
/g>
g data-mml-node="mn" transform="translate(2037.6, 0)">
/g>
g data-mml-node="mo" transform="translate(3537.6, 0)">
/g>
g data-mml-node="mi" transform="translate(3982.2, 0)">
/g>
g data-mml-node="mo" transform="translate(5311, 0)">
/g>
g data-mml-node="mn" transform="translate(6366.8, 0)">
/g>
g data-mml-node="mi">
/g>
g data-mml-node="mo" transform="translate(981.8, 0)">
/g>
g data-mml-node="mn" transform="translate(2037.6, 0)">
/g>
g data-mml-node="mo" transform="translate(3037.6, 0)">
/g>
g data-mml-node="mi" transform="translate(3482.2, 0)">
/g>
g data-mml-node="mo" transform="translate(4811, 0)">
/g>
g data-mml-node="mn" transform="translate(5866.8, 0)">
/g>
g data-mml-node="mi">
/g>
g data-mml-node="mi">
/g>
g data-mml-node="mo" transform="translate(1273.2, 0)">
/g>
g data-mml-node="mi" transform="translate(2273.4, 0)">
/g>
g data-mml-node="mo" transform="translate(3255.2, 0)">
/g>
g data-mml-node="mi" transform="translate(4311, 0)">
/g>
g data-mml-node="TeXAtom" data-mjx-texclass="ORD">
/g>
g data-mml-node="mo" transform="translate(690, 0)">
/g>
g data-mml-node="mi" transform="translate(1079, 0)">
/g>
g data-mml-node="mo" transform="translate(2130, 0)">
/g>
g data-mml-node="mi" transform="translate(2574.7, 0)">
/g>
g data-mml-node="mo" transform="translate(3278.7, 0)">
/g>
path data-c="54" d="M40 437Q21 437 21 445Q21 450 37 501T71 602L88 651Q93 669 101 677H569H659Q691 677 697 676T704 667Q704 661 687 553T668 444Q668 437 649 437Q640 437 637 437T631 442L629 445Q629 451 635 490T641 551Q641 586 628 604T573 629Q568 630 515 631Q469 631 457 630T439 622Q438 621 368 343T298 60Q298 48 386 46Q418 46 427 45T436 36Q436 31 433 22Q429 4 424 1L422 0Q419 0 415 0Q410 0 363 1T228 2Q99 2 64 0H49Q43 6 43 9T45 27Q49 40 55 46H83H94Q174 46 189 55Q190 56 191 56Q196 59 201 76T241 233Q258 301 269 344Q339 619 339 625Q339 630 310 630H279Q212 630 191 624Q146 614 121 583T67 467Q60 445 57 441T43 437H40Z">
/path>
g data-mml-node="mtext">
/g>
path data-c="4D" d="M289 629Q289 635 232 637Q208 637 201 638T194 648Q194 649 196 659Q197 662 198 666T199 671T201 676T203 679T207 681T212 683T220 683T232 684Q238 684 262 684T307 683Q386 683 398 683T414 678Q415 674 451 396L487 117L510 154Q534 190 574 254T662 394Q837 673 839 675Q840 676 842 678T846 681L852 683H948Q965 683 988 683T1017 684Q1051 684 1051 673Q1051 668 1048 656T1045 643Q1041 637 1008 637Q968 636 957 634T939 623Q936 618 867 340T797 59Q797 55 798 54T805 50T822 48T855 46H886Q892 37 892 35Q892 19 885 5Q880 0 869 0Q864 0 828 1T736 2Q675 2 644 2T609 1Q592 1 592 11Q592 13 594 25Q598 41 602 43T625 46Q652 46 685 49Q699 52 704 61Q706 65 742 207T813 490T848 631L654 322Q458 10 453 5Q451 4 449 3Q444 0 433 0Q418 0 415 7Q413 11 374 317L335 624L267 354Q200 88 200 79Q206 46 272 46H282Q288 41 289 37T286 19Q282 3 278 1Q274 0 267 0Q265 0 255 0T221 1T157 2Q127 2 95 1T58 0Q43 0 39 2T35 11Q35 13 38 25T43 40Q45 46 65 46Q135 46 154 86Q158 92 223 354T289 629Z">
/path>
g data-mml-node="mtext">
/g>
MLNLP 社区
是由国内外机器学习与自然语言处理学者联合构建的民间学术社区,目前已经发展为国内外知名的机器学习与自然语言处理社区,旨在促进机器学习,自然语言处理学术界、产业界和广大爱好者之间的进步。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/57387.html