
Java并发编程系列开坑了,Java并发编程可以说是中高级研发工程师的必备素养,也是中高级岗位面试必问的问题,本系列就是为了带读者们系统的一步一步击破Java并发编程各个难点,打破屏障,在面试中所向披靡,拿到心仪的offer,Java并发编程系列文章依然采用图文并茂的风格,让小白也能秒懂。
Java内存模型()简称,作为Java并发编程系列的开篇,它是Java并发编程的基础知识,理解它能让你更好的明白线程安全到底是怎么一回事。
程序是指令与数据的集合,计算机执行程序时,是在执行每条指令,因为要从内存读指令,又要根据指令指示去内存读写数据做运算,所以执行指令就免不了与内存打交道,早期内存读写速度与处理速度差距不大,倒没什么问题。
随着技术快速发展,的速度越来越快,内存却没有太大的变化,导致内存的读写()速度与的处理速度差距越来越大,为了解决这个问题,引入了缓存()的设计,在与内存之间加上缓存层,这里的缓存层就是指内的寄存器与高速缓存()
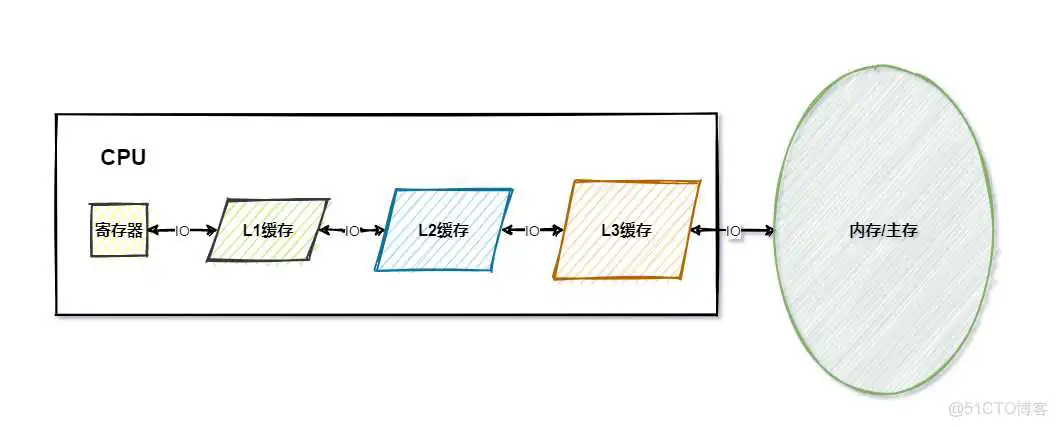
从上图中可以看出,寄存器最快,主内最慢,越快的存储空间越小,离越近,相反存储空间越大速度越慢,离越远。
运行时,会将指令与数据从主存复制到缓存层,后续的读写与运算都是基于缓存层的指令与数据,运算结束后,再将结果从缓存层写回主存。
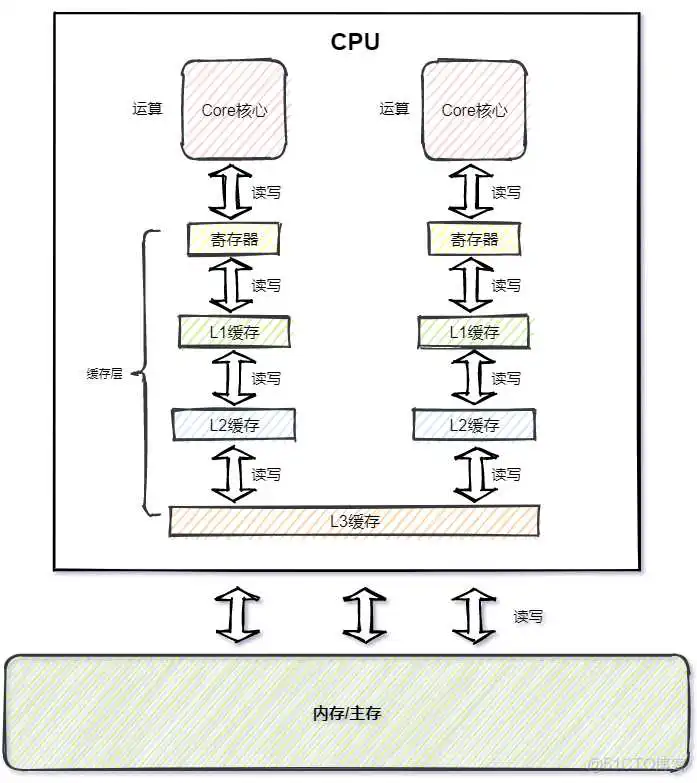
上图可以看出,基本都是在和缓存层打交道,采用缓存设计弥补主存与处理速度的差距,这种设计不仅仅体现在硬件层面,在日常开发中,那些并发量高的业务场景都能看到,但是凡事都有利弊,缓存虽然加快了速度,同样也带来了在多线程场景存在的缓存一致性问题,关于缓存一致性问题后面会说,这里大家留个印象。
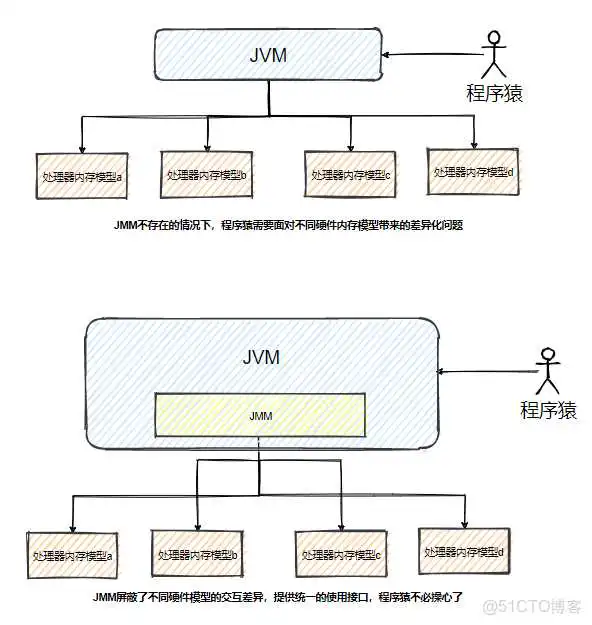
Java内存模型(),后续都以简称, 是建立在硬件内存模型基础上的抽象模型,并不是物理上的内存划分,简单说,为了使虚拟机()在各平台下达到一致的内存交互效果,需要屏蔽下游不同硬件模型的交互差异,统一规范,为上游提供统一的使用接口。
是保证在各平台下对计算机内存的交互都能保证效果一致的机制及规范。
抽象结构划分为线程本地缓存与主存,每个线程均有自己的本地缓存,本地缓存是线程私有的,主存则是计算机内存,它是共享的。
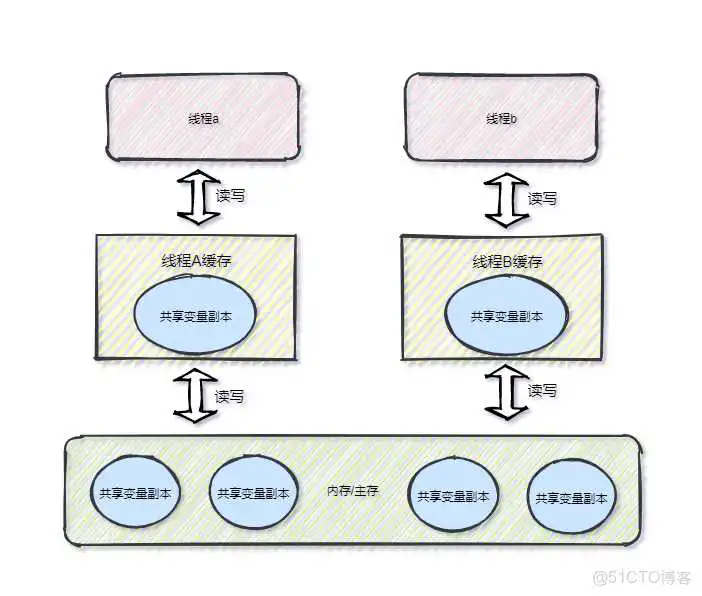
不难发现与硬件内存模型差别不大,可以简单的把线程类比成Core核心,线程本地缓存类比成缓存层,如下图所示

虽然内存交互规范好了,但是多线程场景必然存在线程安全问题(竞争共享资源),为了使多线程能正确的同步执行,就需要保证并发的三大特性可见性、原子性、有序性。
当一个线程修改了共享变量的值,其他线程能够立即得知这个修改,这就是可见性,如果无法保证,就会出现缓存一致性的问题,规定,所有的变量都放在主存中,当线程使用变量时,先从缓存中获取,缓存未命中,再从主存复制到缓存,最终导致线程操作的都是自己缓存中的变量。
线程A执行流程
- 线程从缓存获取变量
- 缓存未命中,从主存复制到缓存,此时是
- 线程获取变量,执行计算
- 计算结果,写入缓存
- 计算结果,写入主存
线程B执行流程
- 线程从缓存获取变量
- 缓存未命中,从主存复制到缓存,此时是
- 线程获取变量a,执行计算
- 计算结果,写入缓存
- 计算结果,写入主存
、两个线程执行完后,线程与线程缓存数据不一致,这就是缓存一致性问题,一个是,另一个是,如果线程再进行一次操作,写入主存的还是,也就是说两个线程对共进行了次,期望的结果是,最终得到的结果却是。
解决缓存一致性问题,就要保证可见性,思路也很简单,变量写入主存后,把其他线程缓存的该变量清空,这样其他线程缓存未命中,就会去主存加载。
线程A执行流程
- 线程从缓存获取变量
- 缓存未命中,从主存复制到缓存,此时是
- 线程获取变量,执行计算
- 计算结果,写入缓存
- 计算结果,写入主存,并清空线程缓存变量
线程B执行流程
- 线程从缓存获取变量
- 缓存未命中,从主存复制到缓存,此时是
- 线程获取变量a,执行计算
- 计算结果,写入缓存
- 计算结果,写入主存,并清空线程缓存变量
、两个线程执行完后,线程缓存是空的,此时线程A再进行一次操作,会从主存加载(先从缓存中获取,缓存未命中,再从主存复制到缓存)得到,最后写入主存的是,中提供了修饰变量保证可见性(本文重点是,所以不会对做过多的解读)。
看似问题都解决了,然而上面描述的场景是建立在理想情况(线程有序的执行),实际中线程可能是并发(交替执行),也可能是并行,只保证可见性仍然会有问题,所以还需要保证原子性。
原子性是指一个或者多个操作在执行的过程中不被中断的特性,要么执行,要不执行,不能执行到一半,为了直观的了解什么是原子性,看看下面这段代码
- 原子性操作:只有一步操作,就是赋值
- 非原子操作:有三步操作,读取值、计算、赋值
如果多线程场景进行操作,仅保证可见性,没有保证原子性,同样会出现问题。
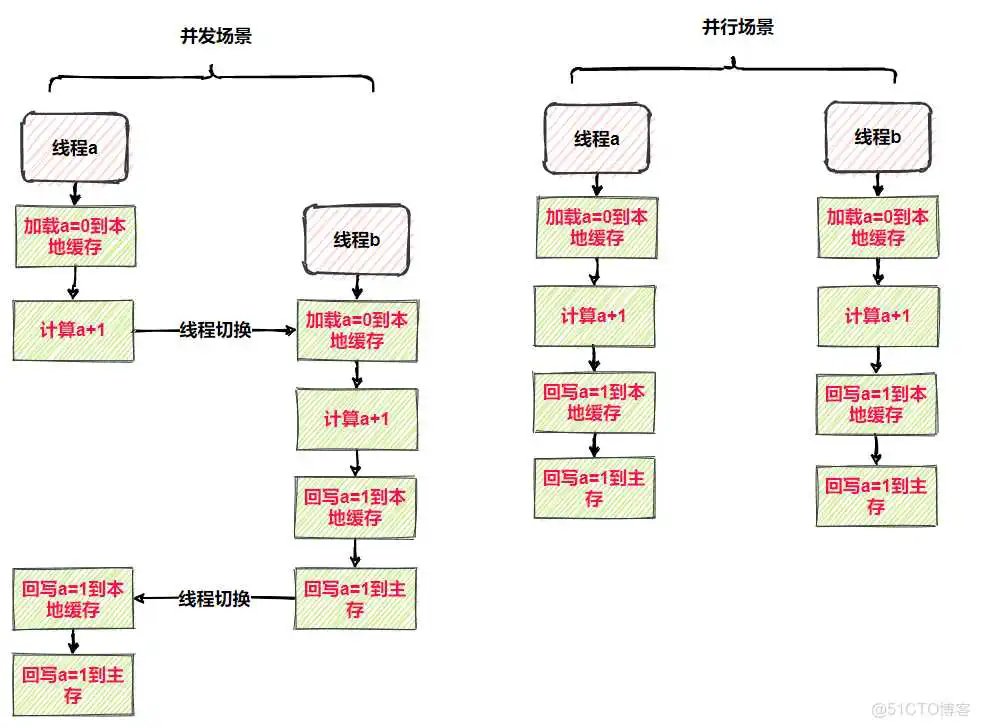
并发场景(线程交替执行)
- 线程读取变量到缓存,是
- 进行运算得到结果
- 切换到线程
- 线程执行完整个流程,写入主存
- 线程恢复执行,把结果写入缓存与主存
- 最终结果错误
并行场(线程同时执行)
- 线程与线程同时执行,可能线程执行运算的时候,线程就已经全部执行完成,也可能两个线程同时计算完,同时写入,不管是那种,结果都是错误的。
为了解决此问题,只要把多个操作变成一步操作,即保证原子性。
中提供了(同时满足有序性、原子性、可见性)可以保证结果的原子性(注意这里的描述),保证原子性的原理很简单,因为可以对代码片段上锁,防止多个线程并发执行同一段代码(本文重点是,所以不会对做过多的解读)。
并发场景(线程与线程交替执行)
- 线程获取锁成功
- 线程读取变量到缓存,进行运算得到结果
- 此时切换到了线程
- 线程获取锁失败,阻塞等待
- 切换回线程
- 线程执行完所有流程,主存
- 线程A释放锁成功,通知线程获取锁
- 线程B获取锁成功,读取变量到缓存,此时
- 线程B执行完所有流程,主存
- 线程B释放锁成功
并行场景
- 线程获取锁成功
- 线程获取锁失败,阻塞等待
- 线程读取变量到缓存,进行运算得到结果
- 线程执行完所有流程,主存
- 线程释放锁成功,通知线程获取锁
- 线程获取锁成功,读取变量到缓存,此时
- 线程执行完所有流程,主存
- 线程释放锁成功
对共享资源代码段上锁,达到互斥效果,天然的解决了无法保证原子性、可见性、有序性带来的问题。
虽然在并行场线程还是被中断了,切换到了线程,但它依然需要等待线程执行完毕,才能继续,所以结果的原子性得到了保证。
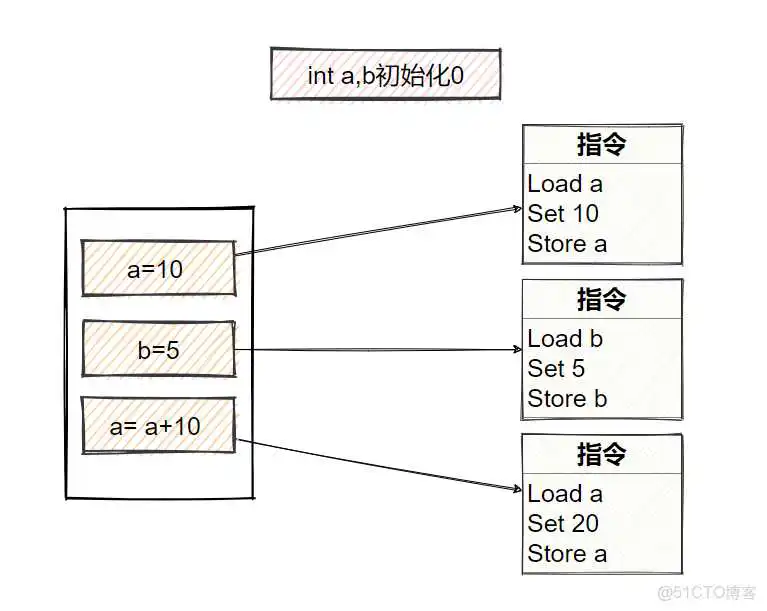
在日常搬砖写代码时,可能大家都以为,程序运行时就是按照编写顺序执行的,但实际上不是这样,编译器和处理器为了优化性能,会对代码做重排,所以语句实际执行的先后顺序与输入的代码顺序可能一致,这就是指令重排序。
可能读者们会有疑问“指令重排为什么能优化性能?”,其实会对重排后的指令做并行执行,达到优化性能的效果。
重排序前的指令
重排序后的指令
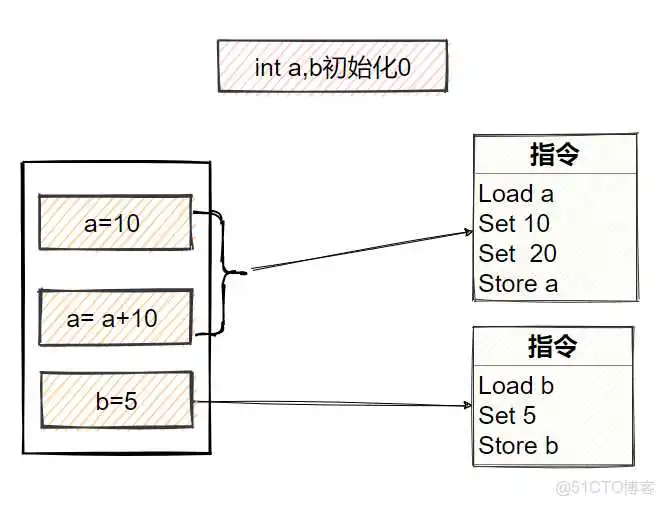
重排序后,对操作的指令发生了改变,节省了一次和,达到性能优化效果,这就是重排序带来的好处。
重排遵循原则,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果(即不管怎么重排序,单线程程序的执行结果不能被改变),下面这种情况,就属于数据依赖。
但也仅仅只是针对单线程,多线程场景可没这种保证,假设两个线程,线程代码段无数据依赖,线程依赖线程的结果,如下图(假设保证了可见性)
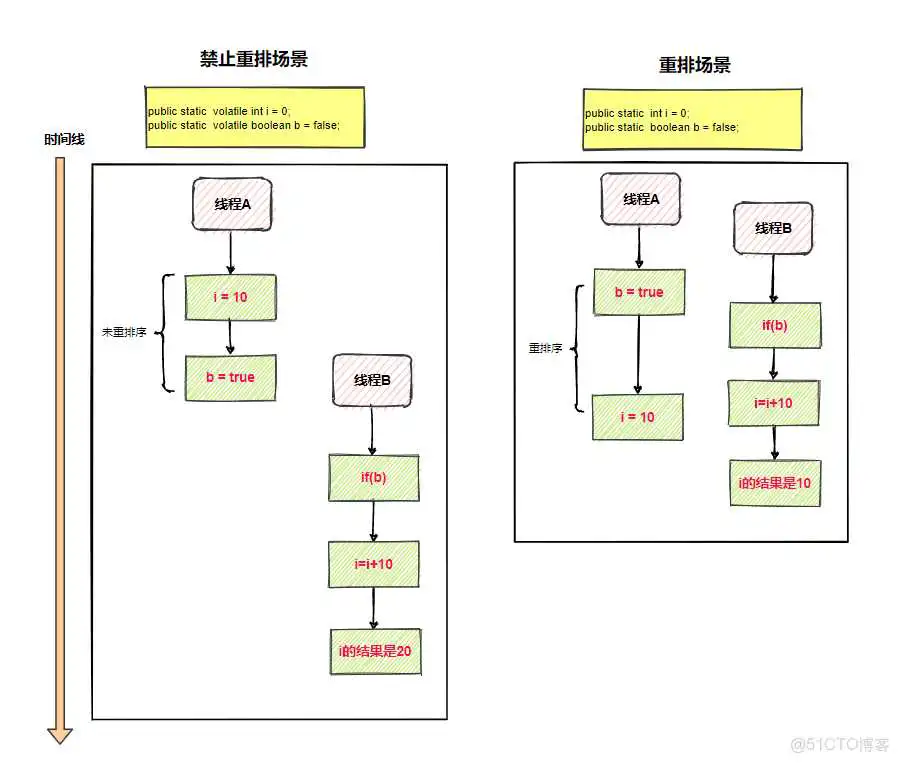
禁止重排场景(i默认0)
- 线程执行
- 线程执行
- 线程执行通过验证
- 线程执行
- 最终结果是
重排场景(i默认0)
- 线程执行
- 线程执行通过验证
- 线程执行
- 线程执行
- 最终结果是
为解决重排序,使用Java提供的修饰变量同时保证可见性、有序性,被修饰的变量会加上内存屏障禁止排序(本文重点是,所以不会对做过多的解读)。
到此这篇bytebufferwrap会复制数组吗(bytebuffer array)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/45563.html