
树可以看成是一个连通且 无环 的 无向 图。
给定往一棵 n 个节点 (节点值 1~n) 的树中添加一条边后的图。添加的边的两个顶点包含在 1 到 n 中间,且这条附加的边不属于树中已存在的边。图的信息记录于长度为 n 的二维数组 edges ,edges[i] = [ai, bi] 表示图中在 ai 和 bi 之间存在一条边。
请找出一条可以删去的边,删除后可使得剩余部分是一个有着 n 个节点的树。如果有多个答案,则返回数组 edges 中最后出现的那个。
示例 1:
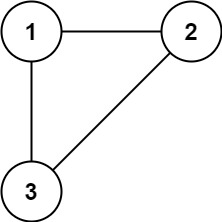
示例 2:
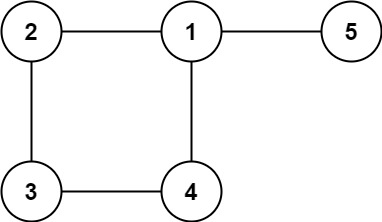
说明:
- n == edges.length
- 3 <= n <= 1000
- edges[i].length == 2
- 1 <= ai < bi <= edges.length
- ai != bi
- edges 中无重复元素
- 给定的图是连通的
有一颗 个节点的树,节点编号 。使用 表示向树中两个没有直接连接的节点之间加一条边之后的边的集合,找出一条可以删除的边使得 变为一颗有 个节点的树。如果有多种选择,返回 中最后出现的那个,即下标最大的边。
我们可以选择一个根节点,比如从节点 出发,使用回溯记录已经访问过的节点,如果发现回到已访问过的非父节点说明出现了环。如果只是寻找环的上的任一条边的话,直接返回即可。
麻烦点在于题目要求返回 中最后出现的边,因此我们需要记录访问的路径,从环开始的节点往后的节点都是在环上的。最后从后向前遍历 找到第一个两端点都在环上的边。
官网题解使用的是并查集。// todo
给你一个二维数组 edges 表示一个 n 个点的无向图,其中 edges[i] = [ui, vi, lengthi] 表示节点 ui 和节点 vi 之间有一条需要 lengthi 单位时间通过的无向边。
同时给你一个数组 disappear ,其中 disappear[i] 表示节点 i 从图中消失的时间点,在那一刻及以后,你无法再访问这个节点。
注意,图有可能一开始是不连通的,两个节点之间也可能有多条边。
请你返回数组 answer ,answer[i] 表示从节点 0 到节点 i 需要的 最少 单位时间。如果从节点 0 出发 无法 到达节点 i ,那么 answer[i] 为 -1 。
示例 1:
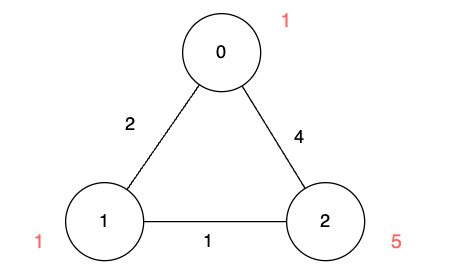
示例 2:
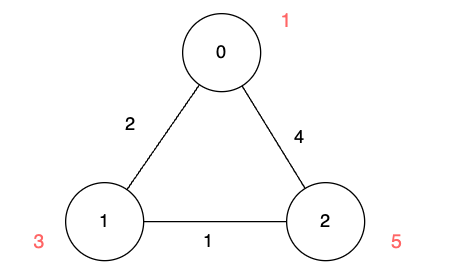
示例 3:
说明:
- 1 <= n <= 5 * 10^4
- 0 <= edges.length <= 10^5
- edges[i] == [ui, vi, lengthi]
- 0 <= ui, vi <= n - 1
- 1 <= lengthi <= 10^5
- disappear.length == n
- 1 <= disappear[i] <= 10^5
有一个n节点的带权无向图,权值表示经过该路径需要的时间。还有一个含有n个元素的数组,表示节点存在时间,即节点在该时间之后消失。让我们返回从0节点到达每个节点的最少时间,如到达时节点刚好消失则认为无法到达,返回-1。两节点之间可能有多条边,并且允许自己到自己的路径。
直接的想法是使用迪杰斯特拉算法求出到达各节点的最少时间,然后与节点消失时间比较。但是最短路径可能随着节点消失而变得不可达,因此需要在遍历的时候判断节点是否消失。
又重新手写了一遍,纠正了以前的误区:
- 对于距离dis初始化为INF的判断,认为INF+cost可能溢出。这是完全没有必要的,当前节点的dis一定已经更新过了。
- 容易写成dfs,每次都取当前节点邻居中最小的。但这样求得的可能不是最短路径。关于最短路径问题:
- 不带权,bfs
- 非负权,dijkstra
- 有负权,bellman-ford
- 多源(寻找图中所有顶点对之间最短路径)Floyd, 属于动态规划算法
- dijkstra 适用于DAG,对于无向图,需要避免环,或者向反方向查找。dijkstra类似于bfs,不过是取所有已访问节点的相邻节点中最小的,对于已处理的节点没有前往该节点更短的路径。
- dijkstra 算法的核心在于其选择下一个扩展顶点的策略和路径长度的累计方式,这与动态规划直接填充整个解决方案空间的策略有所不同。
- dijkstra 算法不依赖于特定的数据结构来选择最小节点,而是依赖算法本身的逻辑,不使用堆优化的实现依然可以得到正确的结果,只不过进行了不必要的计算。
将PriorityQueue改为LinkedList,不使用堆优化的反而更快,这就是测试用例的问题了。
给你一个二维数组 edges 表示一个 n 个点的无向图,其中 edges[i] = [ui, vi, lengthi] 表示节点 ui 和节点 vi 之间有一条需要 lengthi 单位时间通过的无向边。
同时给你一个数组 disappear ,其中 disappear[i] 表示节点 i 从图中消失的时间点,在那一刻及以后,你无法再访问这个节点。
注意,图有可能一开始是不连通的,两个节点之间也可能有多条边。
请你返回数组 answer ,answer[i] 表示从节点 0 到节点 i 需要的 最少 单位时间。如果从节点 0 出发 无法 到达节点 i ,那么 answer[i] 为 -1 。
示例 1:
示例 2:
示例 3:
说明:
- 1 <= n <= 5 * 10^4
- 0 <= edges.length <= 10^5
- edges[i] == [ui, vi, lengthi]
- 0 <= ui, vi <= n - 1
- 1 <= lengthi <= 10^5
- disappear.length == n
- 1 <= disappear[i] <= 10^5
有一个n节点的带权无向图,权值表示经过该路径需要的时间。还有一个含有n个元素的数组,表示节点存在时间,即节点在该时间之后消失。让我们返回从0节点到达每个节点的最少时间,如到达时节点刚好消失则认为无法到达,返回-1。两节点之间可能有多条边,并且允许自己到自己的路径。
直接的想法是使用迪杰斯特拉算法求出到达各节点的最少时间,然后与节点消失时间比较。但是最短路径可能随着节点消失而变得不可达,因此需要在遍历的时候判断节点是否消失。
又重新手写了一遍,纠正了以前的误区:
- 对于距离dis初始化为INF的判断,认为INF+cost可能溢出。这是完全没有必要的,当前节点的dis一定已经更新过了。
- 容易写成dfs,每次都取当前节点邻居中最小的。但这样求得的可能不是最短路径。关于最短路径问题:
- 不带权,bfs
- 非负权,dijkstra
- 有负权,bellman-ford
- 多源(寻找图中所有顶点对之间最短路径)Floyd, 属于动态规划算法
- dijkstra 适用于DAG,对于无向图,需要避免环,或者向反方向查找。dijkstra类似于bfs,不过是取所有已访问节点的相邻节点中最小的,对于已处理的节点没有前往该节点更短的路径。
- dijkstra 算法的核心在于其选择下一个扩展顶点的策略和路径长度的累计方式,这与动态规划直接填充整个解决方案空间的策略有所不同。
- dijkstra 算法不依赖于特定的数据结构来选择最小节点,而是依赖算法本身的逻辑,不使用堆优化的实现依然可以得到正确的结果,只不过进行了不必要的计算。
将PriorityQueue改为LinkedList,不使用堆优化的反而更快,这就是测试用例的问题了。
给你一个二维数组 edges 表示一个 n 个点的无向图,其中 edges[i] = [ui, vi, lengthi] 表示节点 ui 和节点 vi 之间有一条需要 lengthi 单位时间通过的无向边。
同时给你一个数组 disappear ,其中 disappear[i] 表示节点 i 从图中消失的时间点,在那一刻及以后,你无法再访问这个节点。
注意,图有可能一开始是不连通的,两个节点之间也可能有多条边。
请你返回数组 answer ,answer[i] 表示从节点 0 到节点 i 需要的 最少 单位时间。如果从节点 0 出发 无法 到达节点 i ,那么 answer[i] 为 -1 。
示例 1:
示例 2:
示例 3:
说明:
- 1 <= n <= 5 * 10^4
- 0 <= edges.length <= 10^5
- edges[i] == [ui, vi, lengthi]
- 0 <= ui, vi <= n - 1
- 1 <= lengthi <= 10^5
- disappear.length == n
- 1 <= disappear[i] <= 10^5
有一个n节点的带权无向图,权值表示经过该路径需要的时间。还有一个含有n个元素的数组,表示节点存在时间,即节点在该时间之后消失。让我们返回从0节点到达每个节点的最少时间,如到达时节点刚好消失则认为无法到达,返回-1。两节点之间可能有多条边,并且允许自己到自己的路径。
直接的想法是使用迪杰斯特拉算法求出到达各节点的最少时间,然后与节点消失时间比较。但是最短路径可能随着节点消失而变得不可达,因此需要在遍历的时候判断节点是否消失。
又重新手写了一遍,纠正了以前的误区:
- 对于距离dis初始化为INF的判断,认为INF+cost可能溢出。这是完全没有必要的,当前节点的dis一定已经更新过了。
- 容易写成dfs,每次都取当前节点邻居中最小的。但这样求得的可能不是最短路径。关于最短路径问题:
- 不带权,bfs
- 非负权,dijkstra
- 有负权,bellman-ford
- 多源(寻找图中所有顶点对之间最短路径)Floyd, 属于动态规划算法
- dijkstra 适用于DAG,对于无向图,需要避免环,或者向反方向查找。dijkstra类似于bfs,不过是取所有已访问节点的相邻节点中最小的,对于已处理的节点没有前往该节点更短的路径。
- dijkstra 算法的核心在于其选择下一个扩展顶点的策略和路径长度的累计方式,这与动态规划直接填充整个解决方案空间的策略有所不同。
- dijkstra 算法不依赖于特定的数据结构来选择最小节点,而是依赖算法本身的逻辑,不使用堆优化的实现依然可以得到正确的结果,只不过进行了不必要的计算。
将PriorityQueue改为LinkedList,不使用堆优化的反而更快,这就是测试用例的问题了。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/39809.html