
梯度提升回归树是区别于随机森林的另一种集成方法,它的特点在于纠正与加强,通过合并多个决策树来构建一个更为强大的模型。
该模型即可以用于分类问题,也可以用于回归问题中。
梯度提升回归树与随机森林的方法不同,梯度提升采用连续的方式构造树,每颗树都试图纠正前一颗树的错误,也可称为弱学习器。
三个重要参数
在该模型中,有三个重要参数分别为 n_estimators(子树数量)、learning_rate(学习率)、max_depth(最大深度)。
子树数量 n_estimators
通常用来设置纠正错误的子树数量,梯度提升树通常使用深度很小(1到 5之间)的子树,即强预剪枝,来进行构造强化树。
并且这样占用的内存也更少,预测速度也更快。
学习率 learning_rate
通常用来控制每颗树纠正前一棵树的强度。
较高的学习率意味着每颗树都可以做出较强的修正,这样的模型普遍更复杂。
最大深度 max_depth
通常用于降低每颗树的复杂度,从而避免深度过大造成过拟合的现象。
梯度提升模型的 max_depth 通常都设置得很小,一般来讲不超过5。
GradientBoostingClassifier类的应用
下面是在乳腺癌数据集上应用sklearn.ensemble包GradientBoostingClassifier类的示例。
默认参数
默认使用100颗树,最大深度为3,学习率为0.1。
可见训练集的预测准确度为 100%, 测试集的准确度为 96.5%, 存在过拟合现象,接下来微调参数。
降低最大深度 max_depth
可见,测试集性能有所提升,训练集性能有所降低,泛化能力加强。
降低学习率 learning_rate
可见,训练集与测试集预测准确度都有所下降,且泛化能力无明显加强,故学习率取默认值较好。
特征重要性分析
我们可以将梯度提升回归树的特征重要性可视化,便于更好地理解模型。
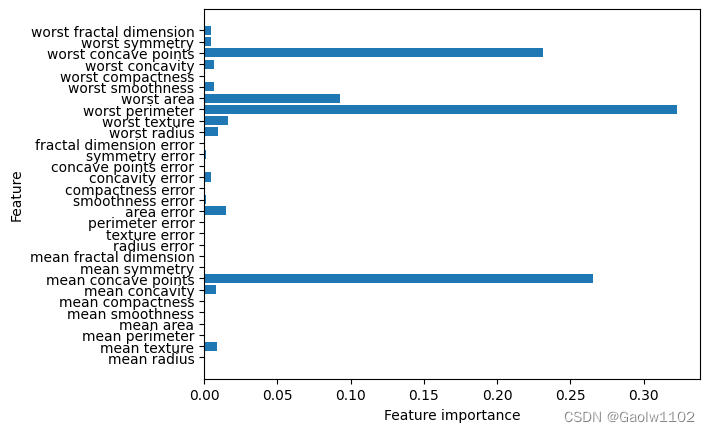
可以看到,梯度提升树的特征重要性与随机森林的特征重要性有些类似,不过梯度提升树完全忽略了某些特征。
优、缺点
梯度提升决策树是监督学习中最强大也是最常用的模型之一。
该算法无需对数据进行缩放就可以表现得很好,而且也适用于二元特征与连续特征同时存在的数据集。
缺点是需要进行仔细调参,且训练时间可能较长,通常不适用于高维稀疏数据。
到此这篇梯度提升树回归模型(梯度提升树原理)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/jszy-jnts/50202.html