
根据《统计学习方法》中所描述对于”强可学习“和”弱可学习“的概念:在PCA框架中,对于一个概念(一个类)来说,如果存在一个多项式的学习算法能够学习他,并且正确率很高,那么就称这个概念是 强可学习的;一个概念,如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。
所以对于更常见更容易发现的“弱学习算法”,如果可以通过一些手段和途径将它提升(Boost)为“强学习算法”,那么正确率就会大大提高。于是就产生了Boosting提升方法。最具代表性的是AdaBoost算法(AdaBoost algorithm)。
对于提升方法来说,两个问题最值得注意:(1)在每一轮如何改变训练数据的权值或概率分布?(2)如何将弱分类器组合成一个强分类器? 根据书上所说,对于第一个问题:AdaBoost的做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注。于是,分类问题被一系列的弱分类器“分而治之”。 至于第二个问题:弱分类器的组合,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
我们今天所说的提升树,就是以分类树和回归树作为基本分类器的提升方法,提升方法实际采用与前向分步算法。以决策树为基函数的提升方法称为提升树(Boosting Tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。
提升树是以分类树或回归树为基本分类器的提升方法。提升树被认为是统计学习中性能最好的方法之一。
3.1 提升树模型
提升方法实际采用加法模型(即基函数的线性组合)与前向分步算法。以决策树为基函数的提升方法称为提升树(Boosting Tree)。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。提升树模型可以表示为决策树的加法模型:
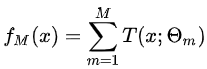

分为二叉分类提升树和二叉回归提升树,这里主要详述二叉回归提升树:
对回归问题的提升树算法来说,只需简单地拟合当前模型的残差。这样,算法是相当简单的。主要就是使用向前分布算法,在要做在前向分步算法的第m步,给定当前模型fm-1(x), 如,m=1,2,…,M,
, 需要我们去求解: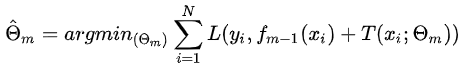
得到,即第m棵树的参数。
4. 回归提升树示例
例题来自统计学习方法中的例题,如下表的数据所示,x的取值范围为区间[0.5,10.5],y的取值范围为区间[5.0, 10.0],学习这个回归问题的提升树模型,考虑只用树桩作为基函数。
(1)首先求训练数据的切分点
假设我们的切分点为:
1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5,所以对于各个切分点,去求出相应的R1,R2,c1,c2和m(s),m(s)计算公式如下: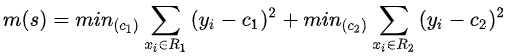 对于当切分点s=1.5时,此时 R1中有 1,R2中有2~10,所以
对于当切分点s=1.5时,此时 R1中有 1,R2中有2~10,所以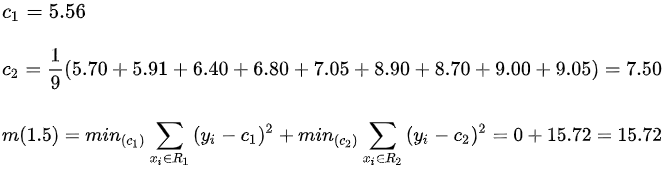
将所有m(s)计算结果如下图所示:
(2)求回归树
从上面的表我们可以看到,当s=6.5时,m(s)达到最小值,此时 R1中包含 1-6,R2中包含7-10,此时:
所以此时的回归树T1(x) 为
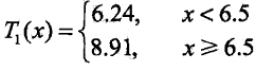
此时的假发模型为:f1(x) = T1(x),对于残差的计算方法是 r2i = yi-f1(xi) ,i=1,2,…10。那么对于f1(x)的残差如下表所示:
回归树T1(x) 我们已经构成,那么继续往下求回归树T2(x) ,方法与上面一致只是此时拟合的是上面的残差表的数据。
我们仍从s=1.5开始,此时还是R1中有 1,R2中有2~10,所以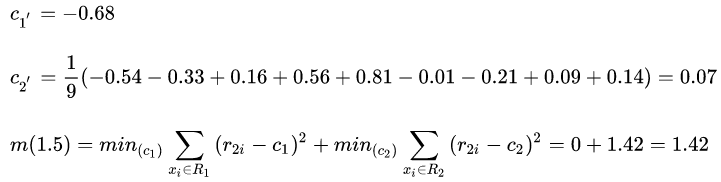
m(s)计算结果如下图所示:
根据上表所知s=3.5时m(s)达到最小值,此时回归树 T2(x) 为: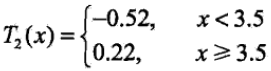
我们在利用加法模型得到现在的 f2(x) 为
此时的残差表就变为
之后的步骤就是一直不断的重复构建回归树,直到全部完成或者定义一个误差值,直到满足误差为止。剩下的回归树如下图所示
上述过程就是提升树利用加法模型与前向分歩算法实现学习的优化过程。但是这是对于损失函数是平方误差损失函数和指数损失函数来说,每一步的优化都较于简单,因为我们所要求的残差是由 ri = yi-f1(xi) 求得的,但是对于一般损失函数并没有这么容易就求得,所以为了满足一般损失函数而言,我们要用梯度提升算法(gradient boosting)它的思想借鉴于梯度下降法,其基本原理是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,然后将训练好的弱分类器以累加的形式结合到现有模型中。采用决策树作为弱分类器的Gradient Boosting算法被称为GBDT。
这里再描述一下梯度下降的基本步骤


我们在梯度下降算法是在多维参数空间中的负梯度方向,变量是参数。但是在梯度提升算法中,变量是函数,更新函数通过当前函数的负梯度方向来修正模型,使模型更优,最后累加的模型为近似最优函数。


所以我们观察到在提升树算法中,残差 y-Ft-1(x) 是损失函数 1/2(y-F(x))2 的负梯度方向,因此可以将其推广到其他不是平方误差(分类或是排序问题)的损失函数。也就是说,梯度提升算法是一种梯度下降算法,不同之处在于更改损失函数和求其负梯度就能将其推广。即,可以将结论推广为对于一般损失函数也可以利用损失函数的负梯度近似拟合残差。
因为在GBDT在模型训练时只使用了代价函数的一阶导数信息,XGBoost对代价函数进行二阶泰勒展开,可以同时使用一阶和二阶导数。所以在这里补充一下泰勒公式和用泰勒公式推导梯度下降法
用泰勒公式推导梯度下降法:

版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/jszy-jnts/41036.html