
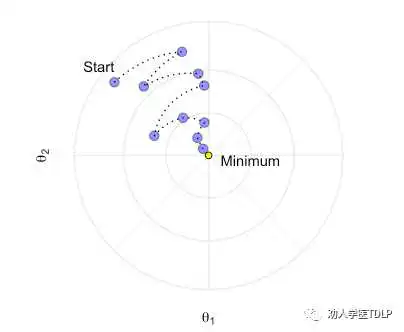
随机梯度下降通常会通过跳出局部最小值来找到接近最优的解决方案
-
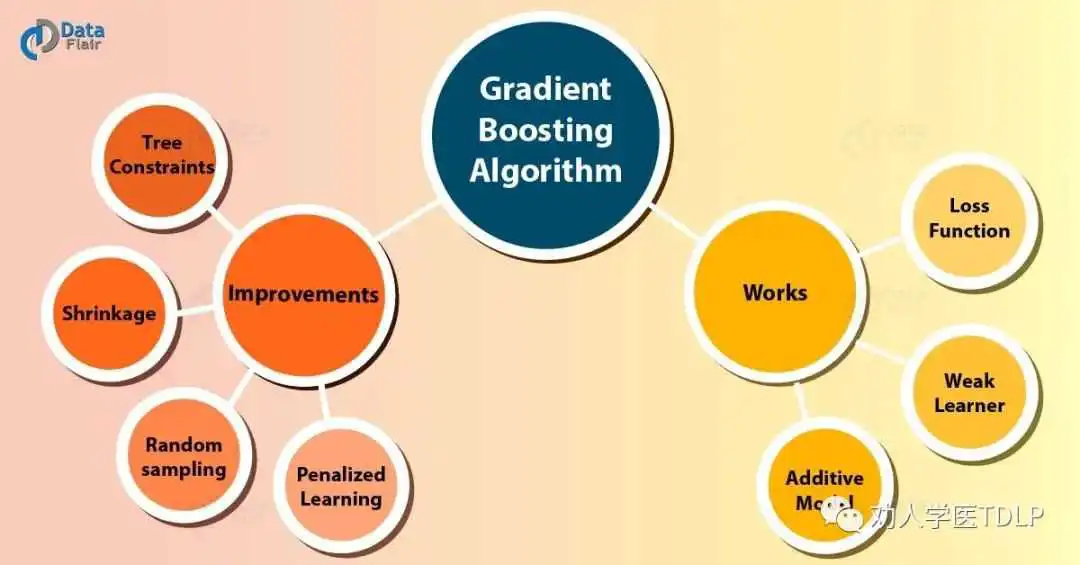
在创建每棵树之前对行进行二次抽样(在 gbm、h2o 和 xgboost 中可用) -
在创建每棵树之前对列进行二次抽样(h2o 和 xgboost) -
在考虑每棵树中的每个拆分之前对列进行二次抽样(h2o 和 xgboost)
-
择相对较高的学习率。通常默认值 0.1 有效,但 0.05-0.2 之间的某个值应该适用于大多数问题。 -
确定此学习率的最佳树数目。 -
修复树超参数并调整学习率并评估速度与性能。 -
调优树特异参数以决定学习率。 -
找到树特异参数后,降低学习率以评估准确性是否有所提高。 -
使用最终的超参数设置并增加 CV 程序以获得更稳健的估计。通常,由于计算上限,上述步骤使用简单的验证程序或 5 折 CV 。如果在整个步骤 1-5 中使用了 k 折 CV,则不需要此步骤。
# Helper packageslibrary(tidyverse) # for general data wrangling needs# Modeling packageslibrary(gbm) # for original implementation of regular and stochastic GBMslibrary(h2o) # for a java-based implementation of GBM variantslibrary(xgboost) # for fitting extreme gradient boostinglibrary(AmesHousing) #for loading ames datalibrary(rsample)# for data splitames<-make_ames() #loading ames data# Stratified sampling with the rsample packageset.seed(123)split <- initial_split(ames, prop = 0.7,strata = "Sale_Price")ames_train <- training(split)ames_test <- testing(split)h2o.init(max_mem_size = "10g")train_h2o <- as.h2o(ames_train)response <- "Sale_Price"predictors <- setdiff(colnames(ames_train), response)
# refined hyperparameter gridhyper_grid <- list(sample_rate = c(0.5, 0.75, 1), # row subsamplingcol_sample_rate = c(0.5, 0.75, 1), # col subsampling for each splitcol_sample_rate_per_tree = c(0.5, 0.75, 1) # col subsampling for each tree)# random grid search strategysearch_criteria <- list(strategy = "RandomDiscrete",stopping_metric = "mse",stopping_tolerance = 0.001,stopping_rounds = 10,max_runtime_secs = 60*60)# perform grid searchgrid <- h2o.grid(algorithm = "gbm",grid_id = "gbm_grid",x = predictors,y = response,training_frame = train_h2o,hyper_params = hyper_grid,ntrees = 6000,learn_rate = 0.01,max_depth = 7,min_rows = 5,nfolds = 10,stopping_rounds = 10,stopping_tolerance = 0,search_criteria = search_criteria,seed = 123)# collect the results and sort by our model performance metric of choicegrid_perf <- h2o.getGrid(grid_id = "gbm_grid",sort_by = "mse",decreasing = FALSE)grid_perfH2O Grid Details================Grid ID: gbm_gridUsed hyper parameters:- col_sample_rate- col_sample_rate_per_tree- sample_rateNumber of models: 18Number of failed models: 0Hyper-Parameter Search Summary: ordered by increasing msecol_sample_rate col_sample_rate_per_tree sample_rate model_ids mse1 0.5 0.5 0.5 gbm_grid_model_8 4.5138E82 0.5 1.0 0.5 gbm_grid_model_3 4.6835E83 0.5 0.75 0.75 gbm_grid_model_12 4.85947E84 0.75 0.5 0.75 gbm_grid_model_5 4.1389E85 1.0 0.75 0.5 gbm_grid_model_14 4.37276E86 0.5 0.5 0.75 gbm_grid_model_10 4.9245E87 0.75 1.0 0.5 gbm_grid_model_4 4.0368E88 1.0 1.0 0.5 gbm_grid_model_1 4.8762E89 1.0 0.75 0.75 gbm_grid_model_6 4.47874E810 0.75 1.0 0.75 gbm_grid_model_13 4.9563E811 0.75 0.5 1.0 gbm_grid_model_2 5.02187E812 0.75 0.75 0.75 gbm_grid_model_15 5.03763E813 0.75 0.75 1.0 gbm_grid_model_9 5.80266E814 0.75 1.0 1.0 gbm_grid_model_11 5.319E815 1.0 1.0 1.0 gbm_grid_model_7 6.0542E816 1.0 0.75 1.0 gbm_grid_model_16 1.19803E917 0.5 1.0 0.75 gbm_grid_model_17 4.39005E918 1.0 0.5 1.0 gbm_grid_model_18 5.8916E9
Grab the model_id for the top model, chosen by cross validation errorbest_model_id <- grid_perf@model_ids[[1]]best_model <- h2o.getModel(best_model_id)# Now let’s get performance metrics on the best modelh2o.performance(model = best_model, xval = TRUE)# H2ORegressionMetrics: gbm# Reported on cross-validation data.# 10-fold cross-validation on training data (Metrics computed for combined holdout predictions)## MSE:# RMSE: 21125.73# MAE: 13045.95# RMSLE: 0.# Mean Residual Deviance :
R与机器学习系列|1.机器学习概论
R与机器学习系列|2.机器学习模型建立过程(上)
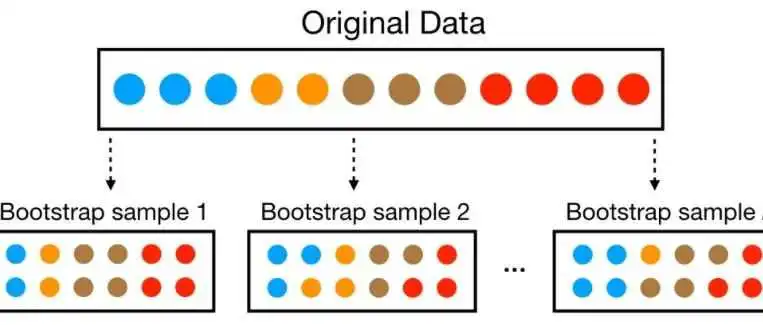
R与机器学习系列|2.机器学习模型建立过程(下)——重抽样方法

R与机器学习系列|2.机器学习模型建立过程(下)——偏差方差的权衡及超参数寻优

R与机器学习系列|2.机器学习模型建立过程(下)——模型评价指标及整体过程实现

R与机器学习系列|3.特征与目标工程(上)——目标工程及缺失值处理
R与机器学习系列|3.特征与目标工程(上)——缺失值处理及特征筛选
R与机器学习系列|3.特征与目标工程(下)——数值型数据特征工程
R与机器学习系列|3.特征与目标工程(下)——分类变量特征工程
R与机器学习系列|3.特征与目标工程(下)——降维及整体过程实现
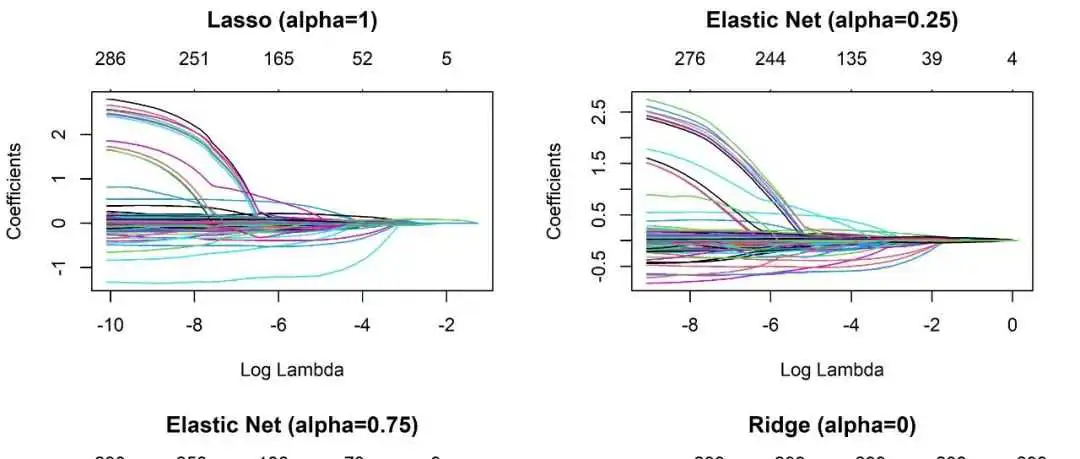
R与机器学习系列|4.正则化回归(Regularized Regression)
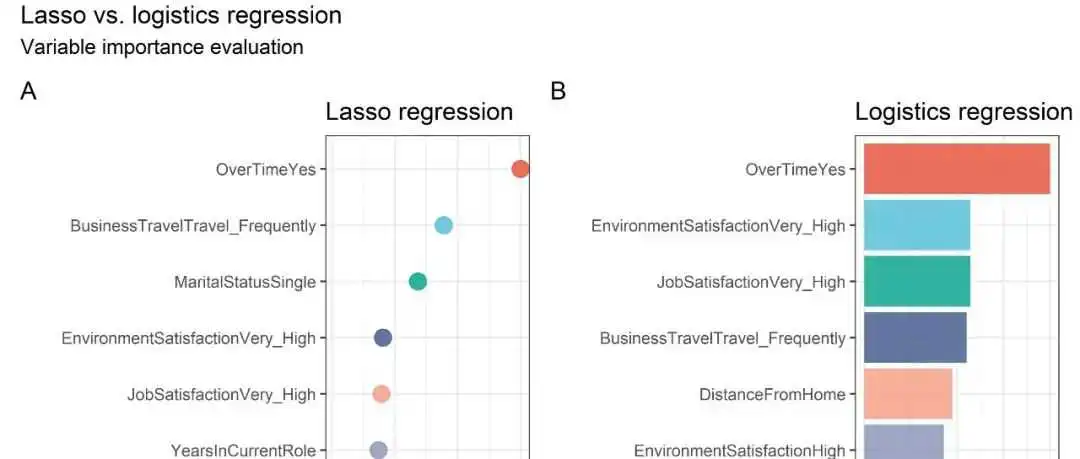
R与机器学习系列|4.正则化回归(Regularized Regression)(下)
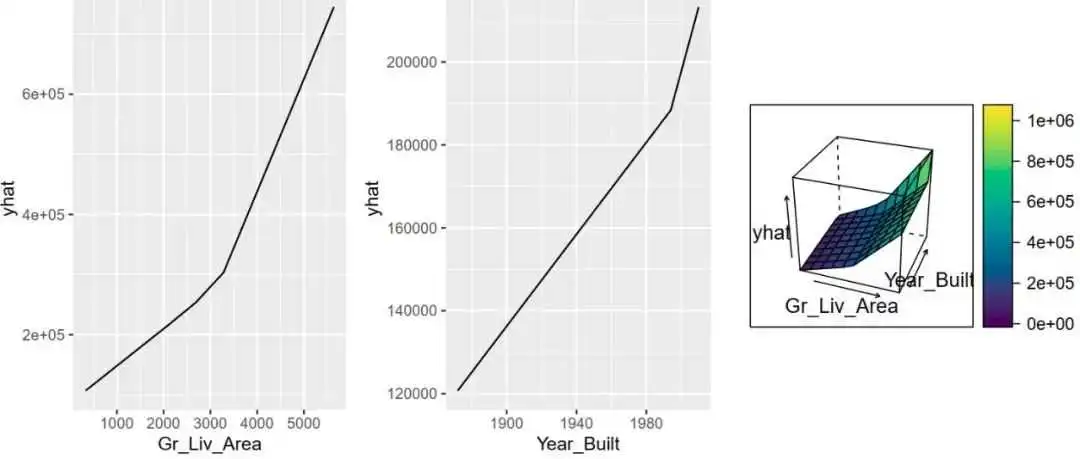
R与机器学习系列|5.多元自适应回归样条(Multivariate Adaptive Regression Splines)
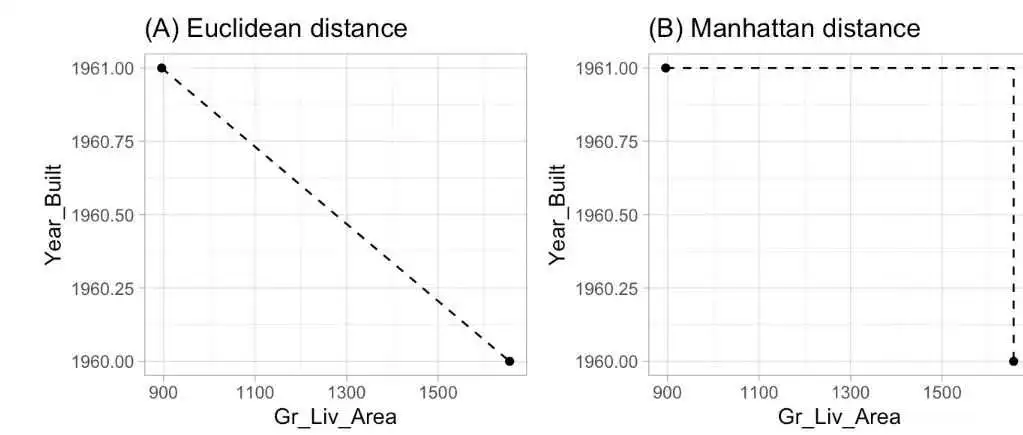
R与机器学习系列|6.k-近邻算法(k-NearestNeighbor,KNN)
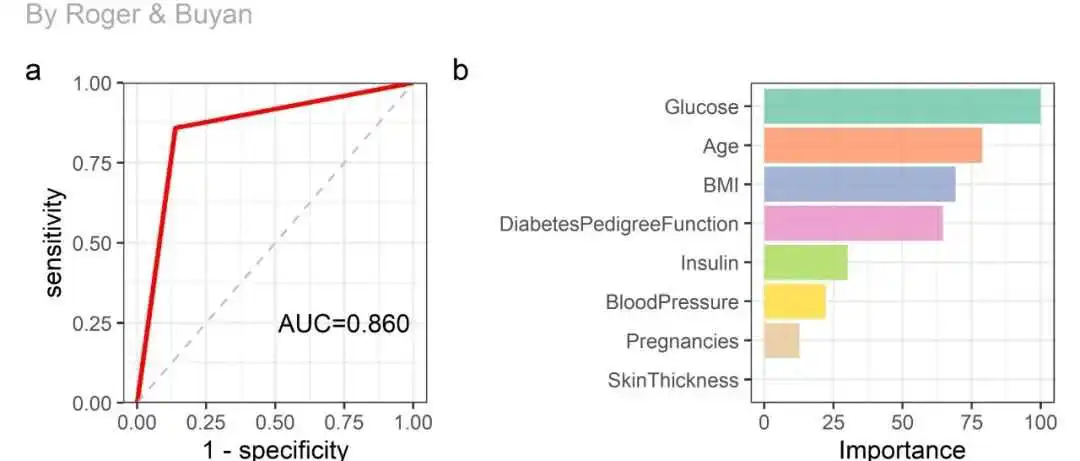
R与机器学习系列|7.决策树(Decision Trees)
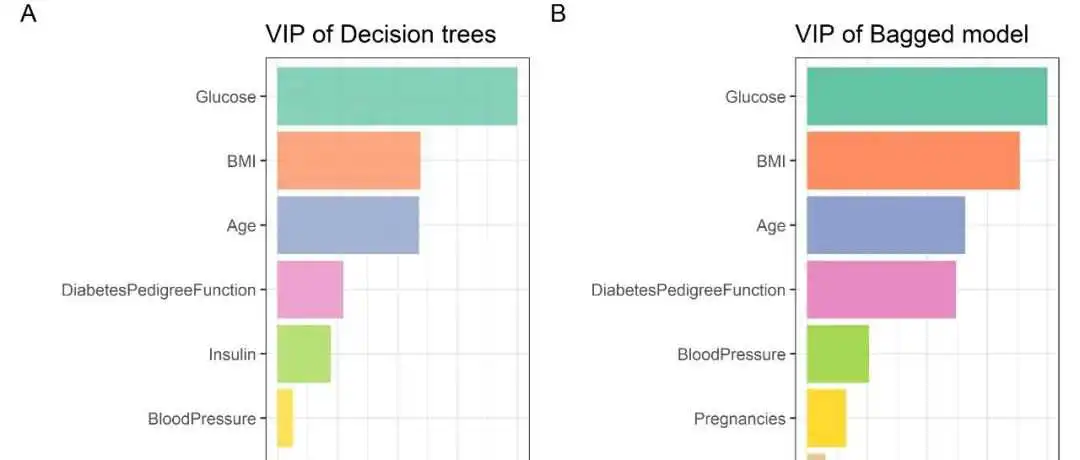
R与机器学习系列|8.Bagging
R与机器学习系列|9.随机森林(Random Forests)
R与机器学习系列|10.梯度提升算法(Gradient Boosting)(一)
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/jszy-jnts/83173.html