
分组聚合,先分组再进行排序(分组+排序)。
使用方法:row_number() over(partition by 列名1 order by 列名2 desc)的使用
表示根据 列名1 分组,然后在分组内部根据 列名2 排序,而此函数计算的值就表示每组内部排序后的顺序编号,可以用于去重复值。
举个栗子:
结果:
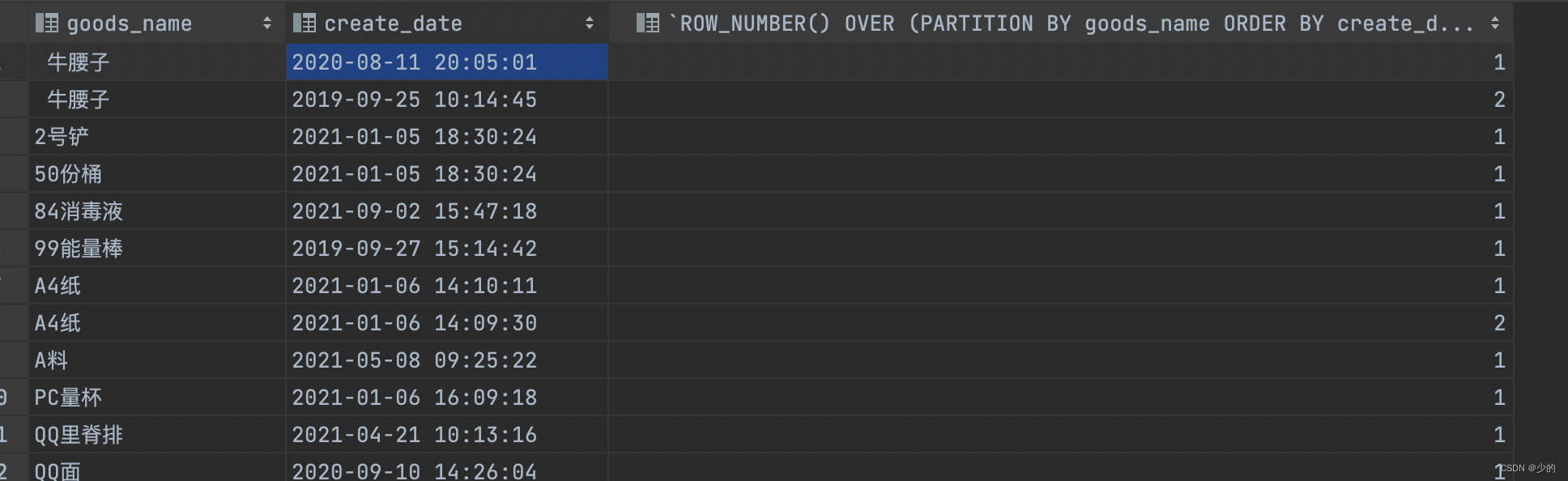
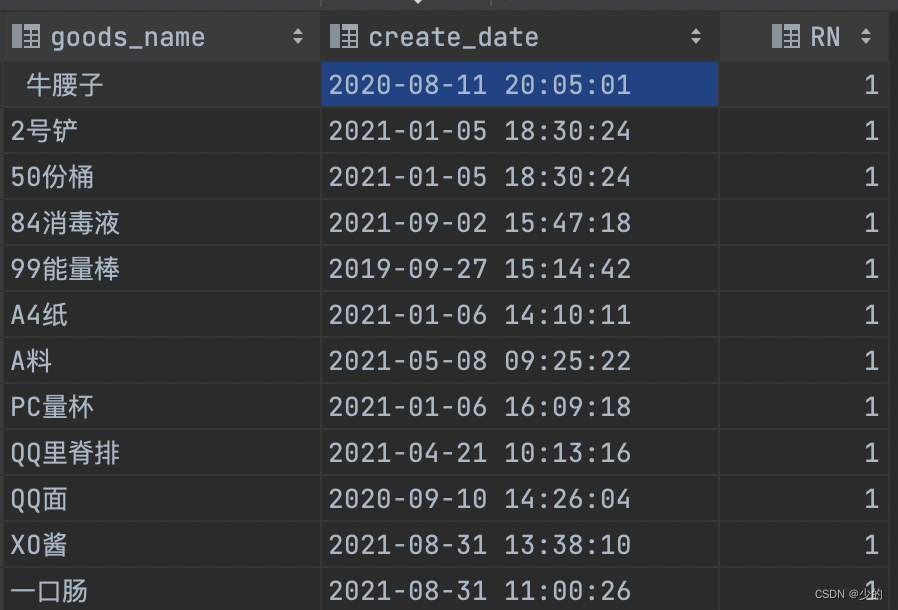
通过上面的语句可知,是按照goods_name字段分组,按create_date字段排序的。 如果需求就是只需查询出每个名字的最新创建时间记录,则可使用如下的语句, 由查询结果可知,名称相同但时间较早的数据被过滤掉了;
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/haskellbc/53554.html