
- 什么是聚合函数
聚合函数作用于一组数据,并对一组数据返回一个值。
- 聚合函数类型
- AVG()
- SUM()
- MAX()
- MIN()
- COUNT()
- 聚合函数语法

- 聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
1.1 AVG和SUM函数
可以对数值型数据使用AVG 和 SUM 函数。
1.2 MIN和MAX函数
可以对任意数据类型的数据使用 MIN 和 MAX 函数。
1.3 COUNT函数
- COUNT(*)返回表中记录总数,适用于任意数据类型。
- COUNT(expr) 返回expr不为空的记录总数。
- 问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
- 问题:能不能使用count(列名)替换count(*)?
不要使用 count(列名)来替代 ,是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
2.1 基本使用
可以使用GROUP BY子句将表中的数据分成若干组
明确:WHERE一定放在FROM后面
在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中
2.2 使用多个列分组
2.3 GROUP BY中使用WITH ROLLUP
使用关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
注意:
当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
3.1 基本使用
过滤分组:HAVING子句
- 行已经被分组。
- 使用了聚合函数。
- 满足HAVING 子句中条件的分组将被显示。
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。

- 非法使用聚合函数 : 不能在 WHERE 子句中使用聚合函数。如下:

3.2 WHERE和HAVING的对比
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为,在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。 这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用的资源就比较多,执行效率也较低。
小结如下:
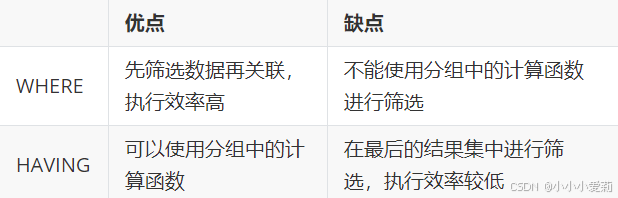
开发中的选择:
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别。
4.1 查询的结构
4.2 SELECT执行顺序
你需要记住 SELECT 查询时的两个顺序:
1. 关键字的顺序是不能颠倒的:
2.SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同):
比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
到此这篇聚合函数不能用在select(聚合函数不能用在什么语句中)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/haskellbc/53886.html