
- Spark面试题(一)
- Spark面试题(二)
- Spark面试题(三)
- Spark面试题(四)
- Spark面试题(五)——数据倾斜调优
- Spark面试题(六)——Spark资源调优
- Spark面试题(七)——Spark程序开发调优
- Spark面试题(八)——Spark的Shuffle配置调优

① 构建Application的运行环境,Driver创建一个SparkContext

具体的task运行在那他机器上,dag划分stage的时候确定的
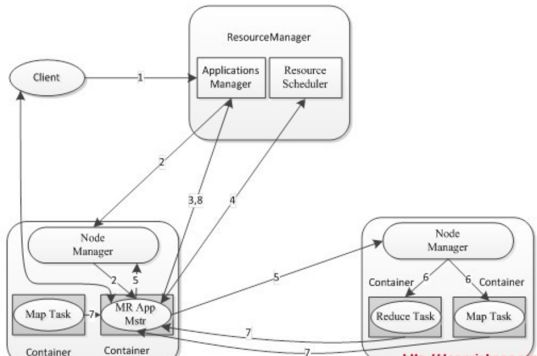
不一定,当数据规模小,Hash shuffle快于Sorted Shuffle数据规模大的时候;当数据量大,sorted Shuffle会比Hash shuffle快很多,因为数量大的有很多小文件,不均匀,甚至出现数据倾斜,消耗内存大,1.x之前spark使用hash,适合处理中小规模,1.x之后,增加了Sorted shuffle,Spark更能胜任大规模处理了。
到此这篇spark面试题(Spark面试题)的文章就介绍到这了,更多相关内容请继续浏览下面的相关 推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/56215.html