
文章目录
- ResNet主体
- BasicBlock
- ResNet18
- ResNet34
- ResNet20
- Bottleneck Block
- ResNet50
- ResNet到底解决了什么问题
https://github.com/pytorch/vision/blob/9a481d0beca799ff148fe2e083b/torchvision/models/resnet.py 各种ResNet网络是由BasicBlock或者bottleneck构成的,它们是构成深度残差网络的基本模块

需要注意的是最后的avgpool是全局的平均池化

图1. BasicBlock结构图1

这个需要强调一下,正常的ResNet20应该是文章中提出,针对cifar数据集设计的n=3时候, 1+6*3+1=20


图2 ResNet20参数量计算

图2. Bottleneck 结构图1
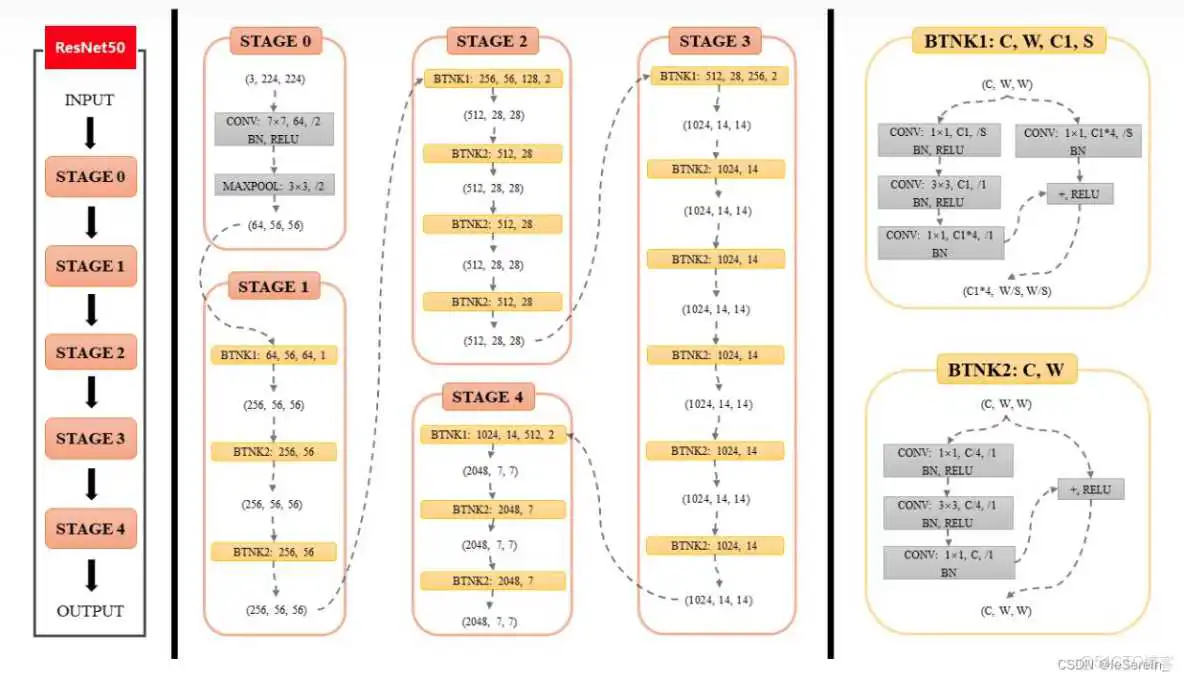
图3. ResNet50结构图2
和以上的网络结构一样,把Bottleneck按层数堆起来就可以了
推荐看知乎问题Resnet到底在解决一个什么问题呢? 贴一些我比较喜欢的回答:
A. 对于层的网络来说,没有残差表示的Plain Net梯度相关性的衰减在
,而ResNet的衰减却只有
B. 对于“梯度弥散”观点来说,在输出引入一个输入x的恒等映射,则梯度也会对应地引入一个常数1,这样的网络的确不容易出现梯度值异常,在某种意义上,起到了稳定梯度的作用。
C. 跳连接相加可以实现不同分辨率特征的组合,因为浅层容易有高分辨率但是低级语义的特征,而深层的特征有高级语义,但分辨率就很低了。引入跳接实际上让模型自身有了更加“灵活”的结构,即在训练过程本身,模型可以选择在每一个部分是“更多进行卷积与非线性变换”还是“更多倾向于什么都不做”,抑或是将两者结合。模型在训练便可以自适应本身的结构。3
D. 当使用了残差网络时,就是加入了skip connection 结构,这时候由一个building block 的任务由: F(x) := H(x),变成了F(x) := H(x)-x对比这两个待拟合的函数, 拟合残差图更容易优化,也就是说:F(x) := H(x)-x比F(x) := H(x)更容易优化4. 举了一个差分放大器的例子:F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化。
说法众多,好用就完事儿了嗷~
- 【pytorch系列】ResNet中的BasicBlock与bottleneck ↩︎ ↩︎
- ResNet50网络结构图及结构详解 ↩︎
- https://www.zhihu.com/question//answer/ ↩︎
- https://www.zhihu.com/question//answer/ ↩︎
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/53776.html