
什么是dom4j?
简单来说,dom4j 就是用来读写 xml 的。相比 JDK 的 JAXP,dom4j 的 API 更容易使用,所以,目前 dom4j 在国内还是比较受欢迎。
本文主要讲的是如何使用 dom4j 以及分析 dom4j 的源码,除此之外,我希望回答更多的问题,例如,什么是 DOM?什么是 SAX?dom4j 真的有那么快吗?要不要使用 dom4j?
本文的结构大致如下:
- 先了解DOM和SAX?
- 如何使用 dom4j?
- 源码分析
- 要不要使用 dom4j?
为什么提到 DOM 和 SAX 呢?因为这是常识,提到 xml 解析,我们很难绕开它们。
DOM(Document Object Model) 和 SAX(Simple API for XML Parsing) 是读 xml 节点的两种方式,注意,它们只是方法论。
下面说说它们是如何读 xml 的。首先,从抽象层面,整个 xml 可以看成是一棵树,而具体的 xml 节点可以看成是树的根、枝、叶等。
DOM 是 一边读取 xml 文件,一边在内存中构建 xml 树,整棵树构建完了之后,我可以在树上面找我需要的节点。
SAX 是一边读取 xml 文件,一边处理节点,而不会在内存中构建树。
为了更好理解,我举个例子。
你要买橘子,DOM 是将所有橘子全部摆在你面前,你可以随便挑。而 SAX 则是一次只掏出一个橘子,然后问你要还是不要,如果你不要,那就把橘子丢掉,拿出下一个,如果你反悔了,想要上一个橘子,抱歉,那个已经不在了。
当然,这两种方式各有优缺点,没有绝对的好坏。DOM 支持随机访问节点,以及对节点进行增删改,但由于需要在内存中构建 xml 树,当树太大时容易出现内存溢出,而 SAX 不需要构建树,所以性能更高,但它不支持随机访问节点以及增删改。
通常情况下,我们更多的会使用 DOM,因为我们的 xml 并不大,而且经常需要随机访问节点,例如,读取配置文件一般就是用 DOM。在文件太大且不需要随机访问节点时,可以使用 SAX,例如,读取大型 xlsx 时就是用 SAX(没错,xlsx 本质也是 xml)。
本文说到的 dom4j 就属于 DOM。
JDK:1.8.0_231
maven:3.6.3
IDE:ideaIC-2021.1.win
dom4j:2.1.3
项目类型 Maven Project,打包方式 jar。
注意:如果要使用 XPath,必须引入 jaxen 的 jar 包。
已有一个学生对象的集合,使用 java 代码把学生对象转换为 xml 节点,做出这么一个 xml 文件。
dom4j 添加节点时支持链式编程(JAXP 就不支持),所以写起来比较简洁一些。
使用 java 代码读取上面生成的 xml 文件,将学生节点封装成学生对象。
dom4j 节点的遍历支持(JAXP 就不支持),所以可以更简单地遍历。
在读取 xml 时,我们很少通过遍历递归来获取我们所需的节点,更多的希望通过路径来直接找到节点,dom4j 通过 XPath 来提供支持(需要额外引入 jaxen 包)。
这里再补充下 XPath 的基本语法。
本文会先介绍将 xml 元素抽象成哪些具体的对象,再去分析读 xml 文件的源码(写的部分本文不扩展)。
注意,阅读以下内容最好先了解 JAXP SAX。
先来看下一个完整 xml 的节点组成。可以看出,一个 xml 文件包含了、、、、、等等。
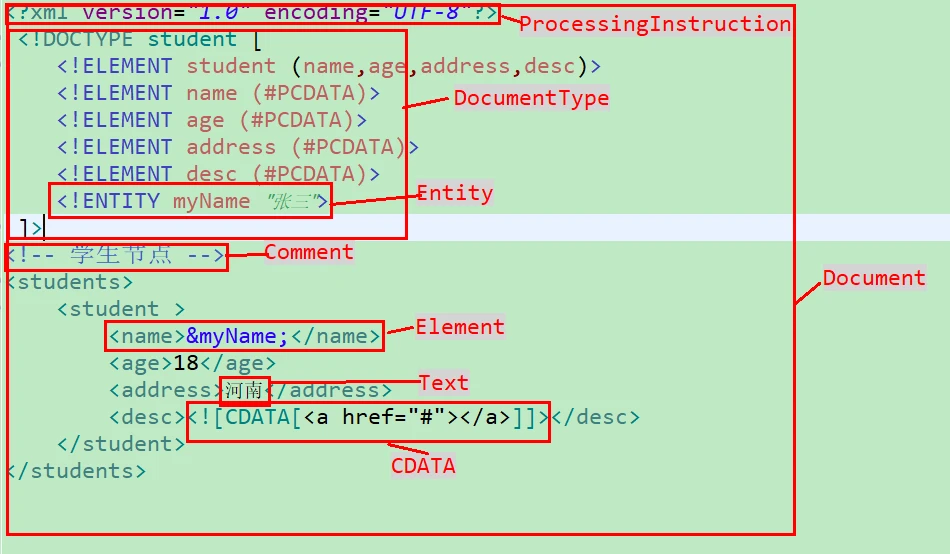
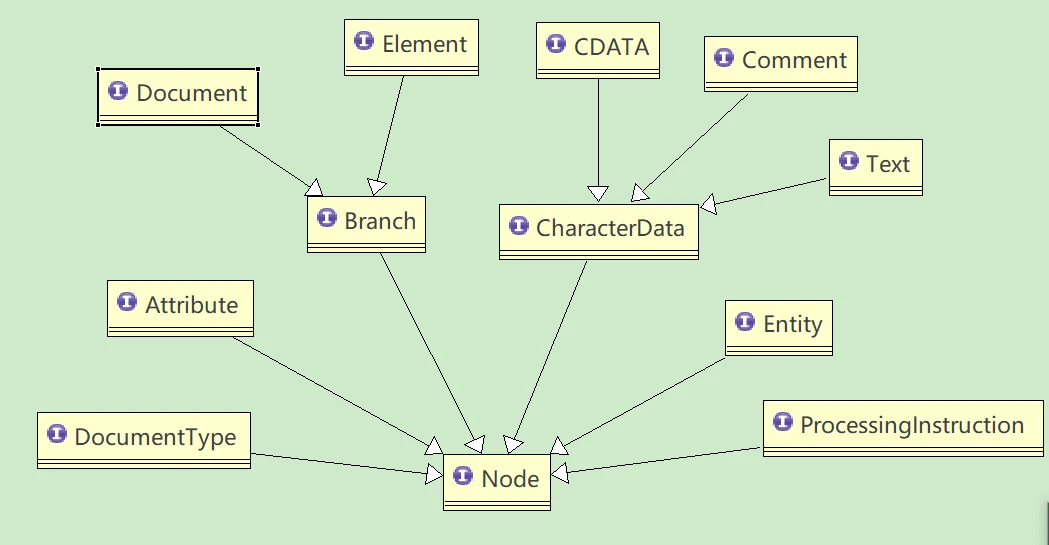
DOM 的思想就是将 xml 节点解析为具体的对象,并构建树形数据结构。基于此,提供了 xml 元素的接口规范,基本借用了这套规范(如下图),只是改造了接口的方法,使得我们操作时更加简便。
通过使用例子可知,我们解析xml文件的入口是对象的方法,入参可以是文件路径、url、字节流、字符流等,这些入参都会被包装成对象,最终调用方法。
看到这个方法的代码时,使用过 JAXP SAX 的朋友应该很熟悉。没错,dom4j 直接调用了 JAXP SAX 的 API 来读取节点,一边读节点,一边构建 xml 树。这么看来,dom4j 认同 JAXP SAX,但不认同 JAXP DOM。
注意:考虑篇幅和可读性,以下代码经过删减,仅保留所需部分。
通过上面的代码,可以知道,构建 xml 树的逻辑在里。这里看下它的几个重要方法和属性。
可以看出,这个 xml 树是一棵多叉树。
以上,dom4j 读部分的源码基本已经分析完,其他具体细节后续再做补充。
为什么要讨论这样的问题呢?首先,你的项目选择使用哪种技术,不是一拍脑袋就能决定的,需要谨慎评估,不能大家都说好,你就直接拿去用。其次,你觉得某个技术已经够好了,可能是因为你不知道还有更好的选择。
下面从易用性、性能、代码解耦等方面对比 dom4j 和 JAXP(实现用的是 JDK 默认的实现)。
在本项目的代码中,也有使用 JAXP 直接操作节点来实现上述读写例子的代码(文末有源码链接),通过对比可以发现,dom4j 的 API 确实更加简洁,这一点不得不承认。
注意,这里对比的是直接操作节点来实现读写,而不是使用 JAXB(JAXB 可以用注解来自动完成 xml 文件和 java 对象的映射),如果用 JAXB 来处理本文中的例子,会更简单一些(项目里同样给出了代码)。
再说说性能,我用 jmh 做了个测试(JDK 版本 1.8.0_231,dom4j 版本 2.1.3),在读方面,JAXP DOM 稍快于 dom4j,在写方面,dom4j 更快。
项目中我们经常遇到需要更换类库的问题,为了更少改动代码,我们的代码中往往只会使用到标准接口,而不会使用到具体实现,例如,使用 JDBC 来访问数据库。
JAXP 就属于标准接口,并且 JDK 自带了一套实现。在项目中使用 dom4j,就好比在项目中直接调用 mysql-connector 的 API,这样做可能会简单一些,但是,哪天我需要更换 xml 类库时,需要修改大量的代码。
经过以上对比,我的建议就是不要使用 dom4j,而是直接使用 JAXP。你会发现,更多的第三方类库使用的是 JAXP,例如,Spring、Mybatis、POI 等等。
当然,如果你觉得以后不会更改 xml 类库,可以考虑使用 dom4j。
以上,基本讲完 dom4j,不足的地方欢迎指正。
最后,感谢阅读。
dom4j官方文档
2021-09-26 更改
相关源码请移步:https://github.com/ZhangZiSheng001/dom4j-demo
到此这篇dom4j源码(dom4j outputformat详解)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/11917301.html
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/53153.html