
然后是ResNeXt具体的网络结构。
类似ResNet,作者选择了很简单的基本结构,每一组C个不同的分支都进行相同的简单变换,下面是ResNeXt-50(32x4d)的配置清单,32指进入网络的第一个ResNeXt基本结构的分组数量C(即基数)为32,4d表示depth即每一个分组的通道数为4(所以第一个基本结构输入通道数为128):
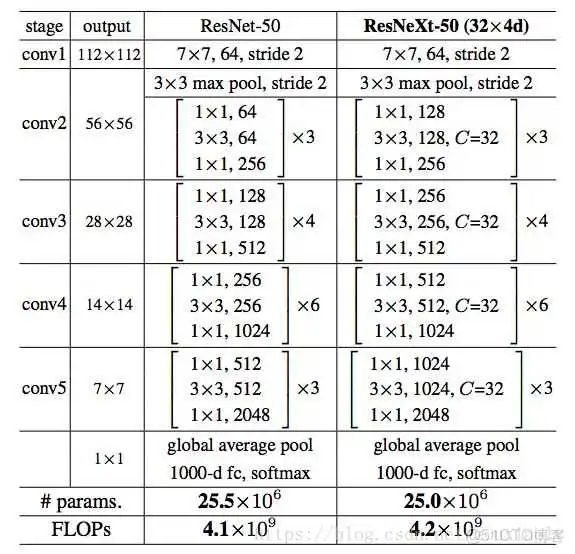
可以看到ResNet-50和ResNeXt-50(32x4d)拥有相同的参数,但是精度却更高。
具体实现上,因为1x1卷积可以合并,就合并了,代码更简单,并且效率更高。
参数量不变,但是效果太好,这个时候通常会有一个『但是』。。。但是,因为分组了,多个分支单独进行处理,所以相交于原来整个一起卷积,硬件执行效率上会低一点,训练ResNeXt-101(32x4d)每个mini-batch要0.95s,而ResNet-101只要0.70s,虽然本质上计算量是相同的,通过底层的优化因为能缩小这个差距。好消息是,看了下最近的cuDNN7的更新说明:
Grouped Convolutions for models such as ResNeXt and Xception and CTC (Connectionist Temporal Classification) loss layer for temporal classification
貌似已经针对分组卷积进行了优化,我还没进行过测试,不过我猜效率应该提升了不少。
至于具体的效果,ResNeXt-101(32x4d)大小和Inception v4相当,效果略差,但Inception-v4慢啊= =,ResNeXt-101(64x4d)比Inception-Resnet v2要大一点,精度相当或略低。
上面的比较并不算很严谨,和训练方式、实现方式等有很大的关系,实际使用中区别不大,还没有找到一个很全的benchmark可以准确比较。不过这里的结果可以作为一个参考。
得益于精心设计的复杂的网络结构,ResNet-Inception v2可能效果会更好一点,但是ResNeXt的网络结构更简单,可以防止对于特定数据集的过拟合。而且更简单的网络意味着在用于自己的任务的时候,自定义和修改起来更简单。
最后,提一个八卦,ResNet作者的论文被Inception v4那篇argue说residual connection可以提升训练收敛速度,但是对于精度没有太大帮助,然后这篇ResNeXt马上又怼回去了,说没有要降好几个点,对于网络的优化是有帮助的。。。
总结下:split-transform-merge模式是作者归纳的一个很通用的抽象程度很高的标准范式,然后ResNeXt就这这一范式的一个简单标准实现,简洁高效啊。
到此这篇resnet作者(resnet-d)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/20482.html