
我们在分析mybatis执行sql的时候,最终定位到数据库连接池上。当时分析到mybatis通过数据库连接池获取到链接,然后通过连接执行sql。
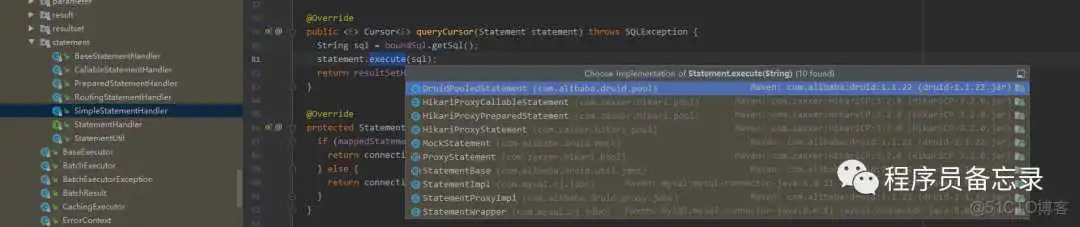
所以这块作者的想法还是和以前一样,先投入进去不管整体,先搞清楚基础逻辑,然后进行细节思考。最后在考虑springBoot的配置bean。基于此,我们首先看一下获取数据库连接的问题。在之前的学习中,我们知道juc中有线程池,那么druid的数据库连接池和线程池有什么区别?怀着问题,我们开始吧!
我们先学习一下DruidDateSource
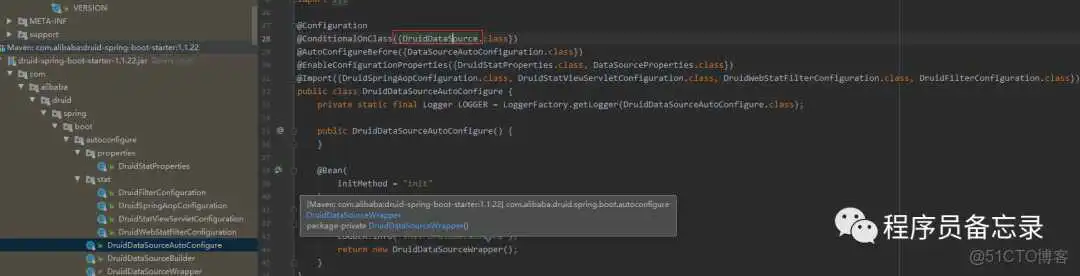
我们看到该类下有很多参数,而这些参数基本都是我们配置的druid参数
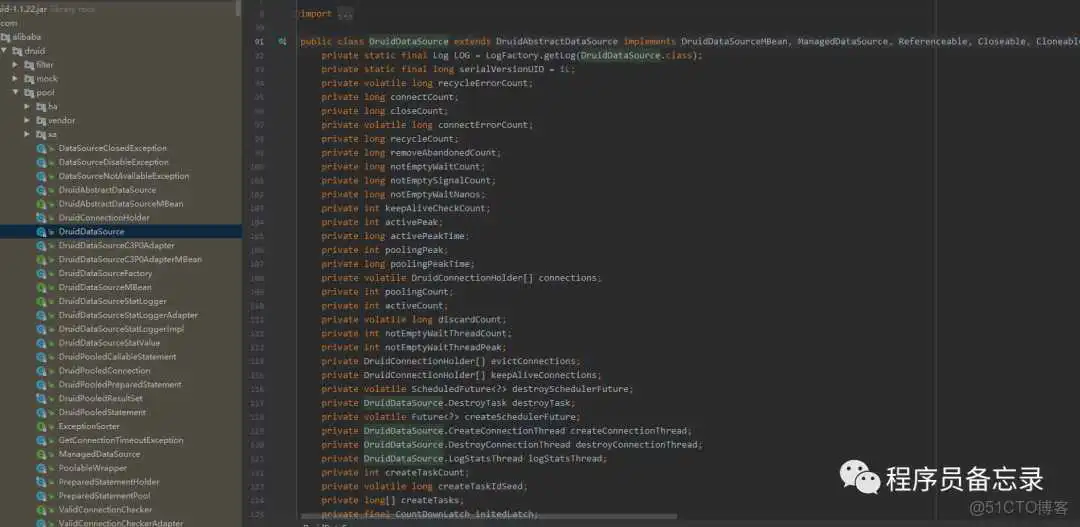
作者通过debug调试,发现这些配置的读取却是从环境变量中读取的。同时我们也注意到其中的connections是volatile修饰的,说明对线程可见。
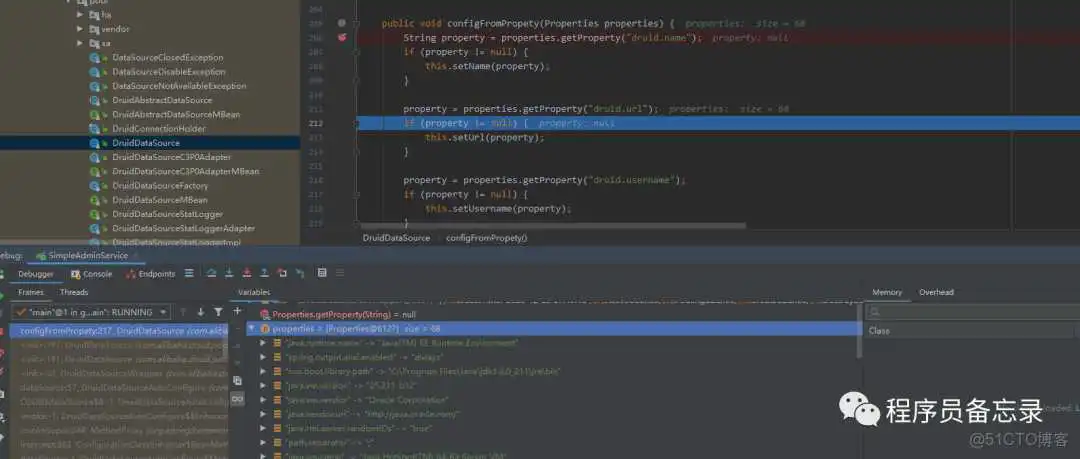
再进一步,我们看一下getConnection的实现逻辑
通过上述代码,我们了解到druid其实也是基于数组实现,先创建最大容量的数组,然后初始化核心连接数。其中采用了重入锁ReentrantLock保证代码只执行一次。这里的poolingCount从0开始累计,表征数据库连接的个数。而方法
PhysicalConnectionInfo pyConnectInfo = this.createPhysicalConnection();
才是创建数据库连接核心方法。
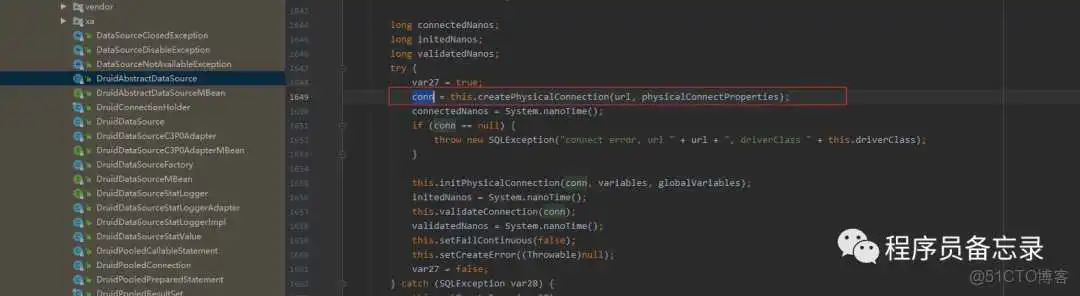

这里我们也看到了countdownlatch,我们知道其实计数用的,当其值为0表示线程要执行的任务全部执行了。

继续跟踪代码,我们发现在获取连接的方式是:
这块先判断是否有连接,有连接的话直接取,没有连接的时候就发送空信号进行创建,创建结束只之后进行获取连接并修改相关连接参数等。
至此我们大概得了解了druid获取链接的一些信息。首先从环境变量中获取配置参数,在获取连接的时候通过加锁的方式进行连接池的初始化,初始化的时候通过配置设置的连接容量进行实例化连接,在获取连接的时候,先判断是否有连接,没有连接的情况下会通过create线程去创建,在获取连接之后就会将连接数减一,并将连接所在的数据位置置为空。
到此这篇druid连接池配置参数(druid连接池连接失效)的文章就介绍到这了,更多相关内容请继续浏览下面的相关 推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rfx/11814.html