
•所谓函数,就是把 具有独立功能的代码块 组织为一个小模块,在需要的时候调用;
•函数的使用包含两个步骤: 1.定义函数 —— 封装 独立的功能;2.调用函数 —— 享受 封装 的成果;
•函数的作用,在开发程序时,使用函数可以提高编写的效率以及代码的 重用
例如:sum_2_num(num1, num2)
参数带冒号:
在Python 中,函数参数可以带有冒号来指定参数的数据类型和默认值。带冒号的参数语法如下所示:
在上述语法中,function_name是函数的名称,para1、para2是函数的参数名称,type是参数的数据类型,default_value是参数的默认值。通过这种方式,我们可以在函数定义中明确参数的类型和默认值,以提高代码的可读性和可维护性。
在上述示例代码中,add是函数的名称,x和y是函数的参数名称,int是参数的数据类型,0是y参数的默认值。函数的返回类型被指定为int。
Python传参driver: WebDriver

def __init__(self, driver:WebDriver):
driver:WebDriver:指type() of driver是WebDriver。不影响运行。
_driver是driver:WebDriver的一个实例(instance)
函数的参数,增加函数的 通用性,针对 相同的数据处理逻辑,能够 适应更多的数据
形参(形式上的参数),定义 函数时,小括号中的参数,是用来接收参数用的,在函数内部 作为变量使用
实参(实际要用的参数),调用 函数时,小括号中的参数,是用来把数据传递到 函数内部 用的
可混合使用位置实参、关键字实参和默认值实参。
①位置实参(实参顺序很重要)
def pet(animal_type,pet_name):
snip
pet('dog','lucky')
②关键字实参
关键字实参是传递给函数的名称-值对,直接在实参中将名称和值关联起来了,因此向函数传递实参时不会混淆。不用考虑函数调用的实参顺序。
def pet(animal_type,pet_name):
snip
pet(animal_type='dog',pet_name='lucky')
③默认值实参
例如:
def pet(pet_name,animal_type='dog'):
snip
pet(pet_name='lucky')
注意事项:
问题 1:在函数内部,针对参数使用 赋值语句,会不会影响调用函数时传递的 实参变量?
—— 不会!无论传递的参数是 可变 还是 不可变 ,只要 针对参数 使用 赋值语句,会在 函数内部 修改 局部变量的引用,不会影响到 外部变量的引用。
问题 2:如果传递的参数是 可变类型,在函数内部,使用 方法 修改了数据的内容,同样会影响到外部的数据
参数为列表:
在函数中修改列表:
在函数中对这个列表所做的任何修改都是永久性的。
原函数:
改造成函数:
禁止函数修改列表:
有时候,需要禁止修改函数列表。你如上述例子,即便打印所有设计后,也要保留原来未打印的设计列表,以供备案。
解决方案:可向函数传递列表的副本而不是原件。function_name(list_name[:]),切片表示法[:]创建列表的副本。
定义 支持多值参数 的函数:
•有时可能需要一个函数能够处理的参数 个数 是不确定的,这个时候,就可以使用多值参数,Python允许函数从调用语句中收集任意数量的实参。
•python 中有 两种 多值参数: ◦参数名前增加 一个* 可以接收 元组
◦参数名前增加 两个* 可以接收 字典
•一般在给多值参数命名时,习惯使用以下两个名字
*args(args 是 arguments 的缩写,有变量的含义) —— 存放 元组 参数,前面有一个 *
kwargs(kw 是 keyword 的缩写,kwargs 可以记忆 键值对参数) —— 存放 字典 参数,前面有两个 *
案例:计算任意多个数字的和:
元组和字典的拆包:
•在调用带有多值参数的函数时,如果希望: ◦将一个 元组变量,直接传递给 args
◦将一个 字典变量,直接传递给 kwargs
如果调用函数变量前不使用星号:
注意:return 表示返回,后续的代码都不会被执行
举例:
有时候需要让实参变为可选的,这样调用函数时只需在必要时才提供额外的信息,可使用默认值来让实参变成可选的。
举例:get_formatted_name()
然而并非所有人都有中间名,如果只提供名和姓,该函数不能正常运行。改造:
函数可返回任何类型的值,包括列表和字典等复杂的数据结构。
函数参数和返回值的作用
一个函数里面又调用了另外一个函数,这就是 函数嵌套调用。
函数的递归:一个函数 内部 调用自己
◦函数内部可以调用其他函数,当然在函数内部也可以调用自己
模块可以让 曾经编写过的代码方便的被 复用!
将函数存储在模块中
import 模块名字
import 模块名字 as 简略名字
#导入模块中的所有函数
from 模块名字 import *
#导入特定函数
from 模块名字 import 函数名字
input()
输入函数input(),函数等待用户在键盘上输入一些文本,并按下回车键,这个函数求值为一个字符串,即用户输入的文本。比如:myname = input(),你可以认为input()函数调用是一个表达式,它求值为用户输入的任何字符串。如果用户输入'Al',那么该表达式就求值为myName = 'Al'。
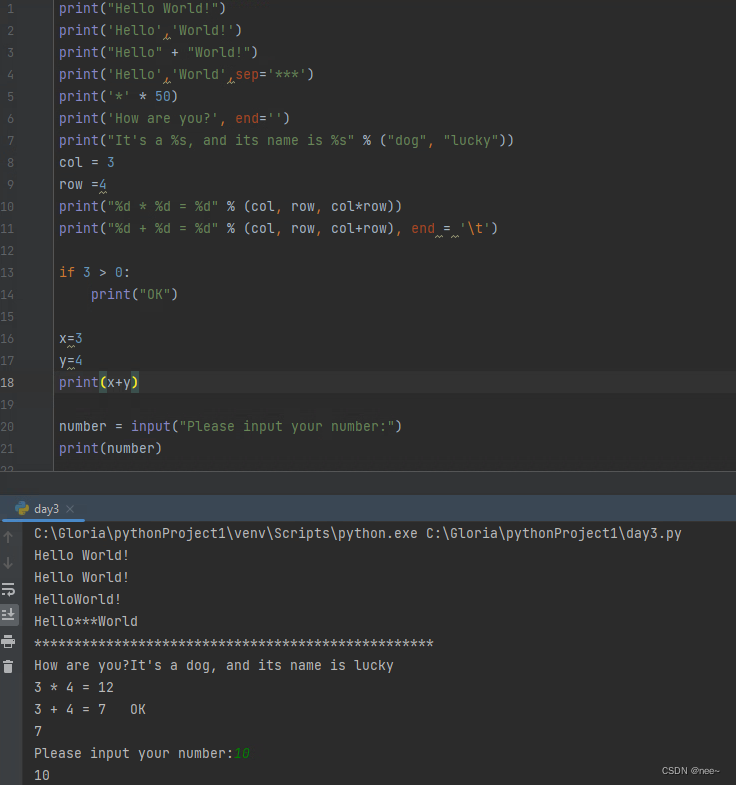
print()
print("%d * %d = %d" % (col, row, row * col), end=" ") # 用%表示前后对应
int()
- x -- 字符串或数字。
- base -- 进制数,默认十进制。

len()
len()函数,你可以向len()函数传递一个字符串(或包含字符串的变量),然后该函数求值为一个整型值,即字符串中字符的个数。
split()
string.split(str="", num) 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 ' ', ' ', ' ' 和空格。
num -- 分割次数。默认为 -1, 即分隔所有。
结果:
eval()
评估函数eval(),去掉参数最外侧引号并执行剩下的语句
format()
{ }.format( ),{ }表示槽,后续format里面的变量填充到槽里
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序 'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置 'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置 'world hello world'
round()
round(),通常让小数精确到小数点后多少位,其中小数位数是由第二个实参指定的。如果将第二个实参指定为负数,round()将圆整到最近的10,100,1000等整数倍。
round(number,digits)
- digits>0,四舍五入到指定的小数位
- digits=0, 四舍五入到最接近的整数
- digits<0 ,在小数点左侧进行四舍五入
- 如果round()函数只有number这个参数,等同于digits=0
四舍五入规则:
- 要求保留位数的后一位<=4,则舍去,如5.214保留小数点后两位,结果是5.21
- 要求保留位数的后一位“=5”,且该位数后面没有数字,则不进位,如5.215,结果为5.21
- 要求保留位数的最后一位“=5”,且该位数后面有数字,则进位,如5.2151,结果为5.22
- 要求保留位数的最后一位“>=6”,则进位。如5.216,结果为5.22
yield()
yield 的函数在 Python 中被称之为 generator(生成器),不像一般的函数会生成值后退出,生成器函数在生成值后会自动挂起并暂停他们的执行和状态,他的本地变量将保存状态信息,这些信息在函数恢复时将再度有效。
为什么叫生成器函数?因为他随着时间的推移生成了一个数值队列。一般的函数在执行完毕之后会返回一个值然后退出,但是生成器函数会自动挂起,然后重新拾起继续执行,他会利用yield关键字关起函数,给调用者返回一个值,同时保留了当前的足够多的状态,可以使函数继续执行。生成器和迭代协议是密切相关的,可迭代的对象都有一个__next()__成员方法,这个方法要么返回迭代的下一项,要么引起异常结束迭代。为了支持迭代协议,拥有yield语句的函数被编译为生成器,这类函数被调用时返回一个生成器对象,返回的对象支持迭代接口,即成员方法__next()__继续从中断处执行执行。
生成器有3种调用方式:
①用next调用
②循环调用
③循环中调用next
range()
函数原型:range(start, end, scan):
参数含义:
- start:计数从start开始。默认是从0开始。例如range(5)等价于range(0, 5);
- end:计数到end结束,但不包括end.例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- scan:每次跳跃的间距,默认为1,且step可正可负,但不能为0。例如:range(3,100,25),结果是3,28,53,78
range() 函数返回的结果是一个整数序列的对象。
另:
count()
count() 方法用于统计字符串里某个字符出现的次数
语法:str.count(sub, start=0,end=len(string))
- sub -- 搜索的子字符串
- start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
- end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
结果:str.count(sub, 4, 40) : 2
List count()
返回元素在列表中出现的次数。
结果:
max()
max() 方法返回给定参数的最大值,或者 iterable(可迭代对象,包含一个或多个供比较的项目) 中有最大值的项目。如果值是字符串,则按字母顺序进行比较
语法:
(iterable, *[, key, default])
(arg1, arg2, *args[, key]) #命名参数key,其为一个函数,用来指定取最大值的方法(key 实参指定排序函数用的参数)。default命名参数用来指定最大值不存在时返回的默认值。
和其他稳定排序工具如
- 默认数值型参数,取值大者;
- 当存在多个相同的最大值时,返回的是最先出现的那个最大值
- 字符型参数,取字母表排序靠后者;
- 序列型参数,则依次按索引位置的值进行比较取最大者。
- 还可以通过传入命名参数key,指定取最大值方法。
举例:
join()
结果:a-b-c
ctime()
Python time ctime() 函数把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。 如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于 asctime(localtime(secs))。
到此这篇pivot函数用法(pivot函数用法python)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/pythonbc/49136.html