
谢喵;
专业书阅读的特点是,中文和英文读得一样慢
另外四级真的要背单词么?我考四级时也就100/150左右的英语水平,裸过没什么压力。
看下豆瓣上的评论吧:原版还是译本? (评论: 现代操作系统)
如果你时间精力允许,建议慢慢啃原版;如果实在没那么多精力,翻译版也还凑合。翻译不是很好,个别地方可能会影响理解,但基本意思是不会有明显出入的。
谢邀。既然有那么多条件限制,建议你还是读中文版,个别实在影响理解的地方再对照英文版看一下。
就是用图像来解释一些计算机领域的概念啊
这个是必须的。操作系统的理解,需要以计算机体系结构为基础。而如果不理解操作系统,对体系结构的深入理解也说不上。
比较2本书的目录看看吧,主题都类似的话,择其一学习就是了。
打基础的书,应该是多遍学习的。第一次学习,建立知识框架、使用代价。后面实际用到那部分了知道到哪里翻具体知识点。
不要第一遍细细读那样。很枯燥、对于难度高的知识你很容易被打击信心。
两本英文版都很好,中翻译版的现代操作系统太差,应该是让学生翻译的,有一种“有道”的感觉
首先你要知道, 用户程序和内核模式的权限是分开且隔离的。 所以用户程序是无法通过指令来执行内核模式下的指令的。如果用户程序直接拥有了内核权限。。。那就很危险了。。。他可以指挥你的电脑的任何组建执行任何指令。 那么怎么办呢? 巧妙利用同步性中断。陷阱指令在这里就是同步性中断的一个具体体现。你可以把陷阱指令想象成一个exception。 一旦同步性中断被触发,那么调度会通知内核处理错误。 这里,我们就可以以参数及内存位置的形式告诉内核,哦我不是fault,我只是叫你来帮我执行几个指令。 这时内核在验证完用户程序拥有执行对应指令的权利后就可以以内核权限执行完那些本无法执行的指令,再通知调度继续执行用户程序。这样就实现了一次完整的内核态的进入(又称为提权)与退出(降权)。
因为『陷阱』并不是指某一种特殊的『陷阱指令』。
比如你可以写一条『除』指令,并把除数设置为零。运行这条指令就可能会触发CPU的除法异常。如果你的操作系统对这个行为感兴趣,那么它可以通过对CPU进行一系列的设置,让一个内核模式的程序来处理这个异常。
上面那个例子相对来说比较少见,更常见的是读取或者写入了一段没有被MMU映射的内存。这个行为会触发一个内存访问错误异常。在某些系统下这个异常会导致系统进入内核态,开始走一个缺页中断流程,把磁盘上保存的页面数据重新复制到内存中。
上面两个例子都是一条普通的指令在某些情况下变成了一个『陷阱』,虽然个人不记得有什么操作系统是这样实现的,但是这些陷阱确实可以用来进入内核态,被用以实现系统调用。所以某种意义上来说,你的教科书很严谨。
不要被“陷阱”一词坑了。
先上汇编代码,用实际代码体验一下啥是“系统调用”:
; Hello World程序 - by xknowledge ; 编译:nasm -f elf64 HelloWorld.asm ; 连接:ld -m elf_x86_64 HelloWorld.o -o HelloWorld ; 运行:https://www.zhihu.com/topic//HelloWorld;echo $? ; *描述:第一个Hello World汇编程序* SECTION .data msg db 'Hello World!', 0AH ; 将要写入的内容(字符串)赋值给msg变量。 ; 0AH是换行符LF(Line Feed,换行)对应的十六进制ASCII码。 SECTION .text global _start _start: ;glibc封装的WRITE:ssize_t write(int fd, const void *buf, size_t count); mov rax, 1 ; 请求内核调用特定的系统调用:WRITE (对应的系统调用号是1) mov rdi, 1 ; 参数1:写入哪个文件。STDOUT即标准输出对应的文件描述符是1 mov rsi, msg ; 参数2:写入内容。字符串缓冲的起始地址 mov rdx, 13 ; 参数3:写入内容长度。要输出的字节数 - 每个字符占1个字节,外加上 0AH (换行符),一共13字节 syscall ; 从用户模式进入内核模式,自动执行系统调用(此时要进行的系统调用是WRITE) push rax ; 将SYS_WRITE返回给rax的值(实际输出字符串的长度)压入栈(内存)中。 mov rax, SYS_EXIT ; 请求内核调用特定的系统调用: EXIT (对应的系统调用号是60)。 pop rdi ; 将栈中的数据(实际输出字符串的长度)写入rdi。 sub rdi, 13 ; 用rdi中的长度减去字符串本该有的长度,这时的rdi作为EXIT的返回值,为0表示输出了完整的字符串 syscall ; 从用户模式进入内核模式,自动执行系统调用(此时要进行的系统调用是EXIT)上述代码是intel 64位机器上gnu/linux 20的一个汇编应用程序,它执行了2次系统调用,也就是每次执行到syscall时,就会发生所谓的“系统调用”。
第一次,调用WRITE。这个系统调用的名字怎么来的?在我本机x86_64 gnu/linux 20上,它位于/usr/include/x86_64-linux-gnu/asm/unistd_64.h这个文件中:
#ifndef _ASM_X86_UNISTD_64_H #define _ASM_X86_UNISTD_64_H 1 #define __NR_read 0 #define __NR_write 1 #define __NR_open 2 #define __NR_close 3 #define __NR_stat 4 #define __NR_fstat 5 #define __NR_lstat 6这个文件显示,linux内核一共有300多个系统调用,上面可以看到写文件write这个系统调用的代号是1,move rax,1就是在指定系统调用号。
为什么是rax这个寄存器中放系统调用号呢?那就得看intel调用习惯,或者内核源代码怎么写的。
查不到调用习惯,也懒得看内核源代码?没关系,这些系统调用在操作系统上一般都有封装,gnu/linux上就是用glibc封装了绝大多数系统调用,我们可以用man 2来查看:
man 2 write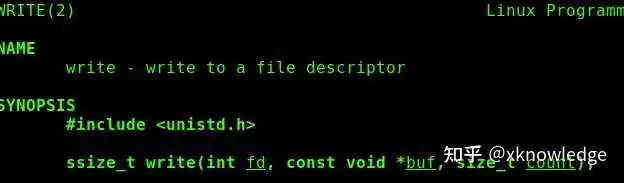
我们知道了这个系统调用需要3个参数:
第一个参数是fd(file descriptor),也就是文件描述符,在上述汇编代码中,我们传入的是1这个文件描述符,它在我本机上代表STDOUT(系统标准输出,也就是输出到控制台)。
其余2个参数看上述汇编代码注解吧。
现在如果你运行过上述代码,你就知道“系统调用”是个啥玩意了,它就是内核暴露给应用层的接口,就跟你调用API很类似。
300多个系统调用,涉及到进程、内存、文件、信号、网络等等。
需要特别注意的是,在intel 64位机器上,我们进行系统调用用的是syscall指令(64位特有,速度更快),而在intel 32位机器上(或者32位汇编代码),如果要进行系统调用就必须使用int 80h,也就是实现一个软中断——中断当前汇编代码的运行,转向执行内核“函数”,内核完成了应用汇编程序的请求后将控制返回给应用,应用继续执行。再遇到下一个系统调用时,又“陷进”内核中,这一下下的,就像应用掉进了“陷阱”一样。
在标志寄存器中(EFLGAS),有一个TP标志,也就是陷阱标志。这个标志在debug代码中会用到,在debug模式中,代码执行变得很慢,就好像代码运行的过程中一步踩一个“坑”(我们前面的汇编程序踩了两个“坑”)。
所以,这里说的“陷阱”,是一种形象化的说法,可以理解成“一种陷阱机制”。而从汇编代码来看,我们看到的似乎使用一条指令来执行系统调用的,但其实际含义是该指令syscall(或int 80h)使系统从用户模式进入内核模式——它仅仅是陷阱机制中的一个步骤,后面内核还要自动根据rax寄存器中的值,来判断应用程序请求执行的是哪个系统调用,确定了系统调用和参数后,才能进行系统调用。
本文介绍处理机调度相关的内容,主要涉及三级调度与调度算法等知识。
作业从提交到完成一般需要经历三级调度:作业调度(高级调度)、内存调度(中级调度)和进程调度(低级调度),调度的频率依次递增。
- 作业调度:作业调度一般是将一个作业从外存调入内存,为其分配内存、外设等资源,使其能够竞争处理机资源。对每个作业来说,每个作业一般只调入一次、调出一次。
- 内存调度:内存调度是为了提高内存利用率和系统吞吐量,一般会将暂时无法运行的进程挂起,当具备运行条件且内存有空闲时,会将这些进程调回,挂在就绪队列上等待调度。
- 进程调度:最频繁的调度方式,一般从就绪队列中调出一个进程,为它分配处理机资源。
- 非剥夺调度方式:当一个进程处于运行状态时,即使有更紧急或优先级更高的进程进入就绪队列,也不会抢占正在运行进程的处理机资源,只有当前运行进程结束运行或进入阻塞状态时才会从就绪队列将更紧迫的进程调出并分配处理机资源。
- 剥夺调度方式:当有一个更紧急或优先级更高的进程需要使用处理机,当前进程会被暂停,执行更紧迫进程的调度方式。
- CPU利用率:当CPU一直处于忙碌状态时,CPU利用率最高。
- 系统吞吐量:表示单位时间内完成的作业数量,当作业都是短作业时,系统吞吐量会比较大。
- 周转时间:是作业从提交到完成的时间,包括作业等待、在就绪队列排队、运行、IO操作的时间总和。
- 平均周转时间:是多个作业的周转时间的平均值。
- 带权周转时间:
- 平均带权周转时间:是多个带权周转时间的平均值。
- 等待时间:进程等待处理机的时间之和。
- 响应时间:从用户提交到首次响应所花费的时间。
调度算法是本文的重点,也是很常见的考点,以下介绍常见的调度算法。
从名字就可以知道这是一种“先来后到”的调度算法,这种调度算法支持作业调度和进程调度。FCFS调度算法每次挑选队列中最先到达的进程或作业,依次进行调度。 这是一种非剥夺调度算法,直观来看,非常公平,但是还是有缺点的。
特点:算法简单,但效率低,对长作业有利,短作业可能要等待很长时间。有利于CPU密集型作业,不利于IO密集型作业。
短作业/进程优先算法是一种优先调度短作业(进程)的调度算法,同样也是一种非剥夺调度算法。
特点:对短作业有利,对长作业不利,如果一直有短作业进来,可能长作业会一直得不到执行。不考虑作业紧迫程度,有些紧迫的作业可能不能及时处理。有利于IO密集型作业,不利于CPU密集型作业。
优先级调度算法既可以用于作业调度也可以用于进程调度。当用于作业调度时,会从后备作业队列中选出一个或多个优先级最高的作业,将它们调入内存中,并分配相应资源;当用于进程调度时,会从就绪队列中选出优先级最高的进程,将处理机分配给这个进程,使它能够运行。
根据高优先级进程能否抢占处理机还可以将这种算法分为非剥夺式优先级调度算法和剥夺式优先级调度算法。
在进程创建后进程优先级能否改变又可以将进程优先级分为静态优先级和动态优先级。
- 静态优先级。静态优先级是进程在创建时就已经确定好的,在进程运行期间不能改变。
- 动态优先级。动态优先级是指进程运行期间优先级根据进程实际运行情况动态变化的。
高响应比优先调度算法适用于作业调度,是短作业优先调度算法和先来先服务算法的折中。我们先来看一下什么是响应比吧。
高响应比优先调度算法具有以下特点:
- 短作业的要求服务时间很短,因此在相同等待时间的情况下,短作业的响应比也更高,会被优先执行。
- 当要求服务时间相同时,等待时间长的作业会被优先服务。
- 长作业的要求服务时间比较长,但是随着等待时间的增加,长作业的响应比也会增加,然后可以分配处理机。
时间片轮转调度算法一般在分时系统上使用,每个进程被分配固定大小的时间片,当时间片用完以后,无论进程是否执行结束,处理机都将被剥夺给下一个进程。
特点:时间片轮转调度算法的时间片大小选择很讲究,如果时间片过大,该调度算法会退化成为先来先服务调度算法,而时间片设置过小,处理机会频繁切换,进程真正使用处理机的时间减少,系统吞吐量下降。
多级反馈队列调度算法是这些调度算法中最复杂的,也是整合了前面一些调度算法而形成的算法,我们来看一下它的工作过程。
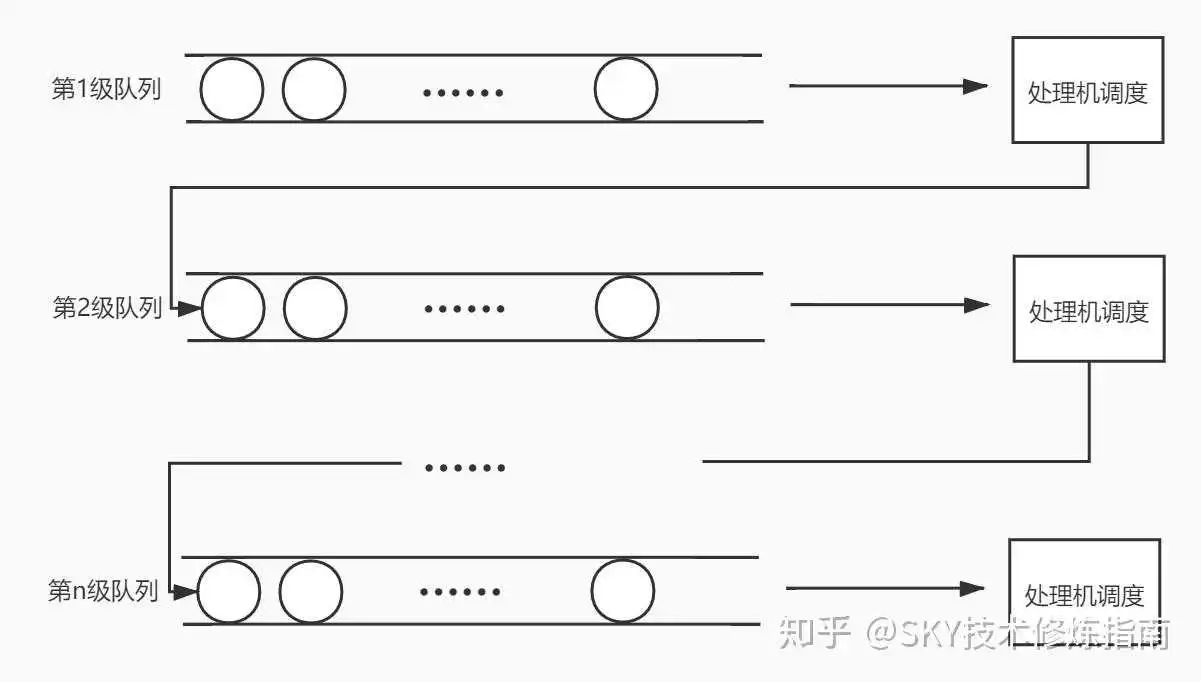
多级反馈队列调度算法工作过程有以下这些特点:
- 每一级队列从上至下的优先级逐渐递减,优先级越高的队列时间片越小。也就是说,最顶层的队列的时间片最小。
- 最新的进程进入内存会被放入最上层的队列末尾,当执行到这个进程时,如果能在分配的时间片内完成则会出队列,如果不能在时间片内完成就进入下一级队列末尾,等待处理机资源。
- 如果高优先级队列有进程存在,则处理机会优先处理上级队列中的进程。如果处理机正在执行某一队列中的进程,此时更高优先级队列中有进程进入,那么当前正在执行的进程会回到当前队列的队尾,处理机执行新进入队列的进程。
最后要提一点,多级反馈队列调度算法兼顾短作业优先的同时,不会让长作业长期处于等待状态最终出现饥饿。
喜欢的欢迎点赞并关注我的公众号:SKY技术修炼指南
阅读笔记不说无用的
- 操作系统中最核心的概念是进程.
- 严格地说,CPU在某一瞬间只能运行一个进程.
- 在当代计算机中,所有进程均被组成若干顺序进程,包括操作系统自己的进程服务.
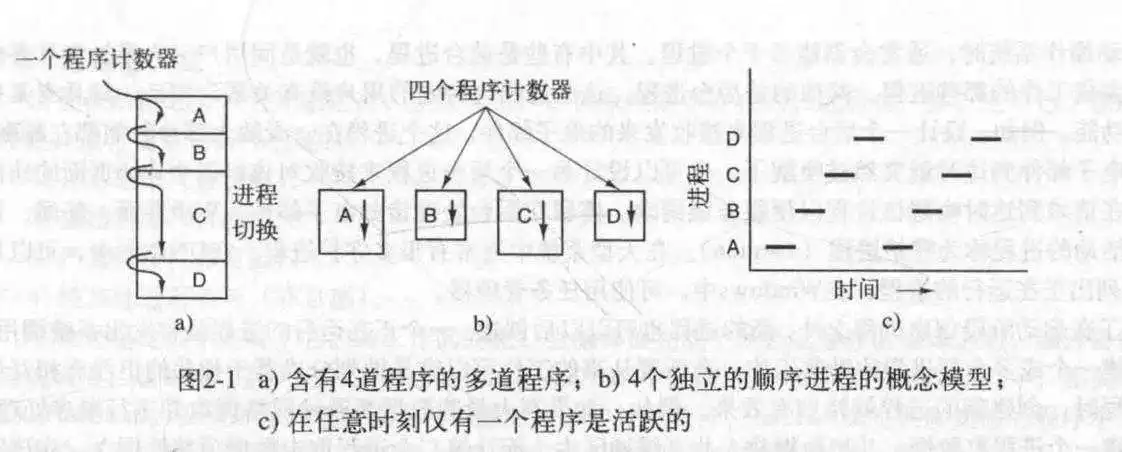
- 如果一个程序执行了两遍,那么算两个进程.
- 进程创建有以下4中情形:
1.系统初始化 2.正在运行的程序执行创建进程的系统调用 3.用户请求创建一个进程(如双击运行一个程序) 4.一个批处理作业的初始化- 停留在后台的进程称为"守护进程".
- 在Unix和Win系统中,父进程和子进程有不同的地址空间(也就是内存空间);且进程之间的地址空间不可见,为进程私有.
- 注意,在Unix系统中,子进程和父进程共享不可写内存块;如果父进程或子进程想要对这样的共享区域写入,应先复制出自己的内存块,再写入.
- 在Win中,父子进程内存空间在一开始就完全不同,故没法共享.
- 进程终止有以下4种原因:
1.正常退出(自愿) 2.出错退出(自愿) 3.严重错误(非自愿) 4.被其他进程杀死(非自愿)- 在进程组里,每个进程都可以捕获新的信号
- 在Unix系统里,所有进程组成一个以init进程为根的一棵进程树.
- 在Win里,没有进程层次概念,父进程拥有一个称为"句柄"的令牌控制子进程.
- 进程的3种状态及其相互关系:
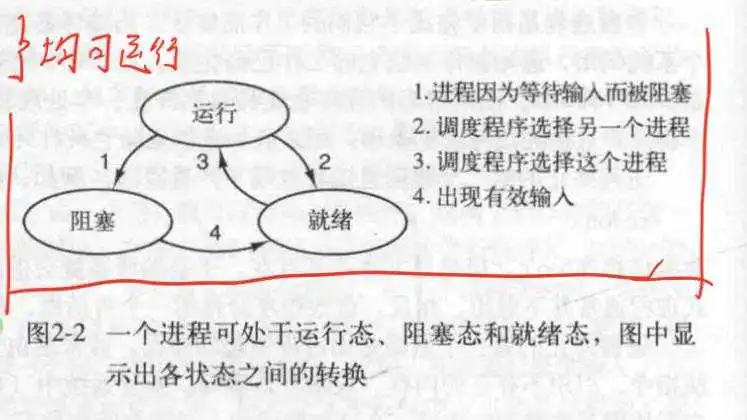
1.运行态(此时程序正在使用CPU) 2.就绪态(可运行,但是没有CPU使用权) 3.阻塞态(除非某种外部事件发生(比如输入流到达),否则进程不能运行)- 调度程序的主要工作就是决定应当运行哪个进程,何时运行,运行多久.
- 进程在操作系统中以进程表的形式存在.
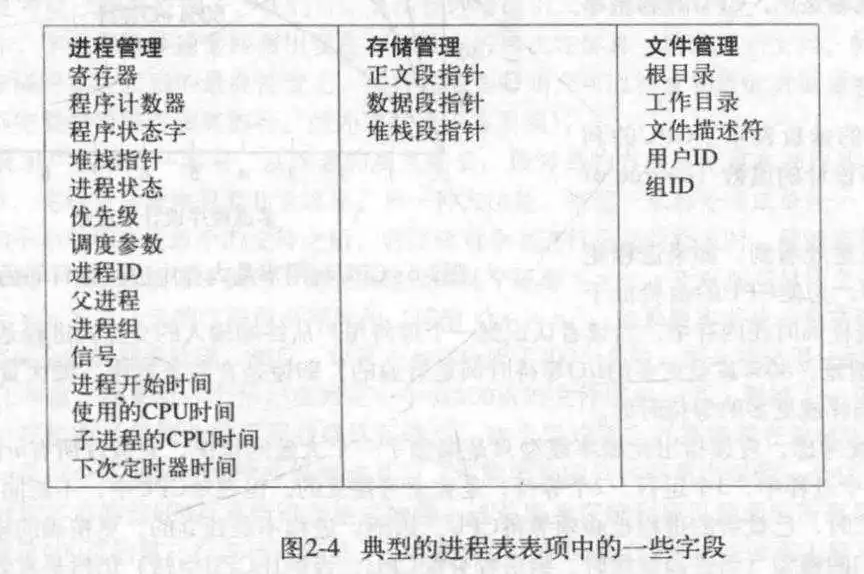
- 在操作系统里,有一个称为"中断向量"的东西,它包含中断服务例程的相关信息.中断服务例程用于处理被中断程序的收尾工作;所有的中断都是从保存寄存器开始的.
- 假设某个进程等待IO操作的时间/其停留在内存中的时间=P(P<1),若此时内存中有n个进程,那么CPU利用率=1-P^n.
- 每个进程有一个地址空间和一个控制线程.
- 使用线程的原因:
1.多线程拥有共享同一个地址空间和所有可用数据的能力,此能力在文件交互上很有用,因为不用频繁地打开关闭文件. 2.创建和销毁的代价相比较于进程低很多. 3.在存在大量的计算和I/O处理时,多线程更加得心应手. 4.在多CPU系统里,使真正的并行计算成为了可能- 进程模型基于两种独立的概念:资源分组处理与执行(就是每个进程独立运行且共享CPU)
- 线程与进程的区别:进程用于把资源集中到一起,而线程则是在CPU上被调度执行的实体.
- 线程之间天生无保护,需要程序员手动添加
- 所有线程共享同一个打开文件集,子进程,定时器以及相关信号等.

- 线程有四种状态:
1.运行 2.阻塞 3.就绪 4.终止- 每个线程都有自己的堆栈,用来保存它所运行的,过程调用,的结果(函数返回值);可以理解为为某一过程调用预留了返回值的位置;这是一个很重要的特性
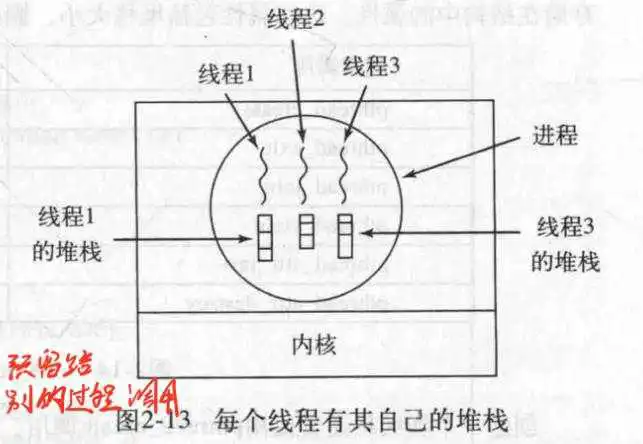
- 一个进程执行的典型线程运行情况:
1.主线程(进程的第一个线程)调用create创建新的线程; 2.若某个线程完成了工作,调用exit退出,此线程不再可用; 3.若A线程需要B线程的执行结果,则调用join进入阻塞状态,直到B退出; 4.线程可调用yield来让出CPU使用权,让其他线程可以运行,这是很重要的,因为线程之间不存在时钟中断来轮换使用CPU.(时钟中断仅限于进程)- POSIX是一个典型的可移植线程程序.
- 有两种方法实现线程包:一是用户态,一是内核态
1.用户态 优点: 线程切换快; 每个线程可以有自己的调度算法; 缺点: 某个线程的阻塞(被动的)会导致整个进程阻塞,也就是阻塞当前进程的所有线程; 页面故障会导致全部阻塞; 同一进程中的线程之间的调度问题; 2.内核态 优点: 不会因为某个线程阻塞而停下所有线程(此时线程由内核托管); 不会出现某个线程吃死CPU的情况; 缺点: 线程的创建,销毁,切换代价高昂; 线程在父子进程中的继承问题; 多个线程对同一信号处理问题;- 某些机制使用了混合实现.
- 调度程序激活机制:其工作目标是模拟内核线程的功能,避免了在内核态和用户态之间的切换.其工作原理简述如下:
1.若发生阻塞,内核通知运行时系统,让它标记此线程为阻塞并启动另一就绪线程; 2.若刚刚阻塞的线程获得了可用事件(比如数据到达),则内核通知运行时系统,把刚刚那个线程设置成可运行的. 3.若发生中断,若被中断的进程对引起中断的原因不感兴趣,那么在中断处理程序处理完中断后,把被中断的线程恢复到中断前的状态; 4.若对此感兴趣,则被中断的线程不再启动,被挂起. 5.再之后,运行时系统开始新的调度(可能包括刚刚被中断的线程).- 弹出式线程,这种线程相当新,没有必须存储的寄存器,堆栈等诸如此类的内容.每个线程从全新开始,每一个线程彼此之间都完全一样,所以,可以快速地创建这类线程.
- 进程间通信主要存在3个问题:
1.一个进程如何把信息传递给另一个 2.两个或更多进程在关键活动中不会出现交叉 3.进程之间通信的正确顺序后两个更像是同步问题;以上问题及其解决方案同样适用于线程. 2. 竞争条件是指两个或多个进程对同一共享数据进行读写,而实际解决取决于精确时序的情况. 3. 互斥是指通过某种手段确保同一时刻只有一个进程对共享数据进行操作. 4. 临界区域或临界区指的是对共享内存进行访问的程序片段. 5. 一个好的解决竞争条件的解决方案应满足以下4点:
1.任何两个进程不能同时处于其临界区. 2.不应对CPU的速度和数量作任何假设 3.临界区外运行的进程不得阻塞其他进程进入临界区 4.不得使进程无限期等待进入临界区- 来看几种解决方案:
1.屏蔽中断法:在某个进程进入临界区后,屏蔽一切中断. 中断是指:某种硬件/软件信号,使CPU停止运行当前程序转去运行另一程序 不足:无法用于多核心或多CPU系统 2.锁变量 不足:本身也需要同步,没有太大意义 3.严格轮换法:会导致程序忙等待 用于忙等待的锁称为自旋锁 4.Peterson解法:优化版的严格轮换法 5.TSL/XCHG指令:给内存总线加锁,确保此指令执行结束之前,其他CPU不得访问内存Peterson解法和TSL/XCHG指令均会造成忙等待(空占CPU而不干活),且TSL和XCHG还可能造成优先级反转问题
严格轮换法

Peterson解法

TSL指令法

XCHG指令法:

- 以生产者-消费者模型为例.对于睡眠/唤醒(sleep/wakeup)机制,可能会发生wakeup信号丢失的可能,比如说,调度程序尝试唤醒消费者,但此时消费者是醒着的,于是此唤醒信号就丢失了,进而导致读写不一致,于是引入一个唤醒等待位,用来tashiyige记录唤醒了几次;还是上面的情况,在下次消费者打算睡眠时,因为唤醒等待位的存在,强迫它此次不睡眠,这样就可以做到信号不丢失
- 不可以无限地添加唤醒等待位,于是引入了信号量这个概念.他是一个整型,只有0和正值;实际上对他的操作,是使用up()和down()来进行地.
- 对信号量的操作:
操作系统在进行测试信号量,更新信号量,以及在需要时使某个进程休眠时采取屏蔽全部中断;或使用TSL/XCHG来进行原子性的信号量操作. up()对信号量增加1;加之前看看信号量是不是为<=0;如果不是就+1;如果是,就说明此时有进程在这个信号量上睡眠(言外之意就是这个信号量为0了),就随机唤醒一个进程,但继续保持0(废话不然不守恒) down()操作,如果信号量>0,则-1;否则休眠此进程,但是此时进程并没终止,在它下次被唤醒时继续进行down()之后的操作 注意,检查信号量的值,修改其值或休眠进程,这个操作必须是原子性的,所以up()和down()由操作系统提供
- 信号量还能用于实现同步,安排程序的执行顺序.
- 如果仅仅需要实现互斥,而不需要统计次数,那么可以使用互斥量,互斥量在实现用户空间线程包时很有用.
- 互斥量仅有两个操作,加锁和释放锁,直接使用TSL和XCHG就可以实现相应的操作

有一点需要注意,和直接使用TSL不同的是,由于时钟超时的存在,所以即使当前线程拿不到锁,也会在后面一会儿后让另一个线程尝试进入临界区;而在互斥量这里,因为是用户线程,所以不存在时钟,所以只能在尝试失败后,手动转移让其他线程来尝试进入临界区.
当然,还有try_lock()这样的方法,用于设定拿不到锁后该干嘛.
- 对于各种解决方法对于共享内存的访问问题,即-怎么在进程之间访问共享区域呢?有两种方法:一是把某些共享数据放在内核里,通过系统调用来访问,另一种是,也是Unix和Win使用的,是让进程之间共享部分地址空间,比如内存,甚至文件.
- 快速用户区互斥量futex.这是Linux的一个特性,它包含两个核心组件:内核服务和用户库.内核中维护着一个阻塞队列,实际线程操作尽可能在用户空间操作,当某个线程试图获取锁,如果它没拿到,这个线程不会自旋,而是使用一个系统调用把这个线程放到内核的阻塞队列上(既然跑不了,那相比于忙等待,转移到内核态似乎也没花很多代价);如果拿到了锁,那就运行,并在运行结束通知内核对阻塞队列里的一个或多个线程解除阻塞.
- pthread的使用请看下图,在这里提一下条件变量,啥意思呢?它允许线程在未满足某些条件时阻塞(wait),直到条件满足被唤醒(signal).当条件变量激活时,记得释放互斥量的锁,不然其他的线程还是没法运行去给当前线程创造条件.

条件变量与互斥量经常一起使用,这种模式用于让一个线程锁住互斥量,然后当它不能获得它所期待的结果时,它会等待条件变量,直到另一个线程向它发送信号,告诉它条件已具备,可以继续执行.pthread_cond_wait原子性地调用并释放它所持有的锁,由于这个原因,互斥量也是参数之一.

- 许多适用于进程的调度算法也可以适用于线程,当内核管理线程时,调度经常是按线程级别的,与线程所属的进程无关.
- 进程有两个主要的行为:计算密集型/IO密集型,在一个进程里,计算占大多是计算密集型操作,而IO密集型则是IO操作之间较少进行计算而不是IO操作时间很长.如果是IO密集型,记得多运行这种类型的进程.
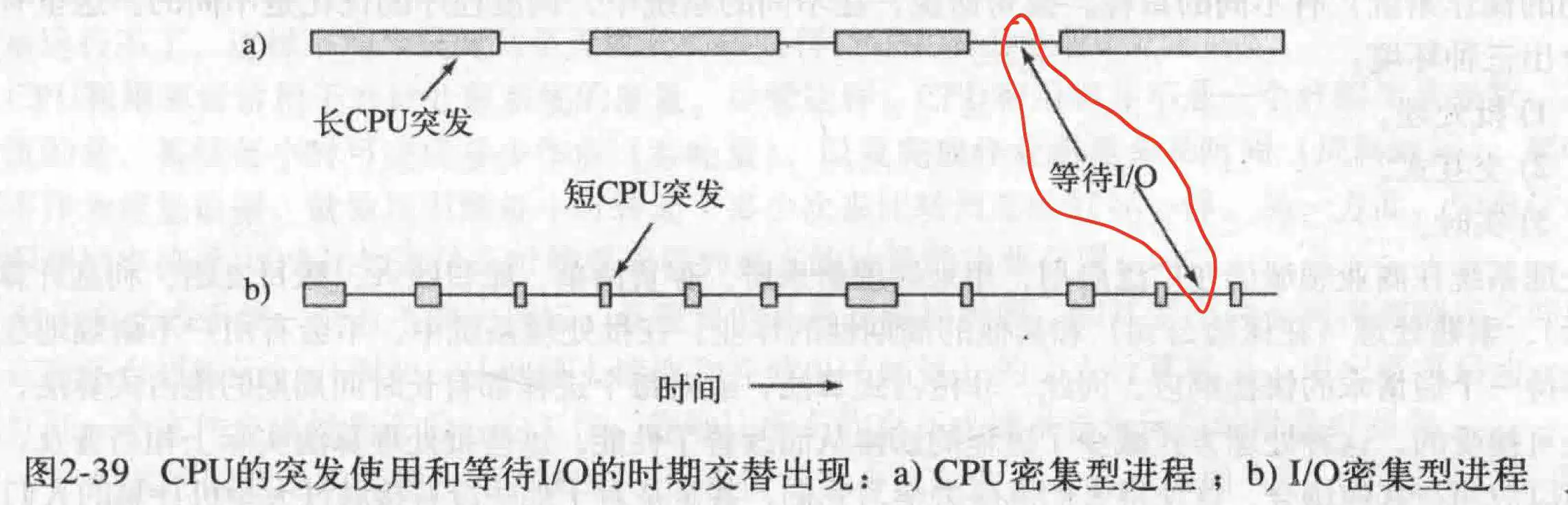
这张图看得出来,CPU挺闲的
- 根据如何处理时钟中断,可以把调度算法分为两类:非抢占式调度和抢占式调度.后者需要时钟中断来把CPU交给调度程序,前者希望程序主动让出CPU.
- 调度算法主要用于3种环境:
1.批处理 主要用于商业领域 2.交互式 常见于PC,移动终端,服务器 3.实时 在多媒体播放设备比较常见- 一个优秀的调度算法需要考虑很多问题

对于交互式系统,最小响应时间是一个很重要的指标.实时系统最主要的要求是满足几乎所有的截止时间要求.
- 批处理系统中的调度
1.先来先服务 2.最短作业优先(前提是均可运行,处于就绪状态) 3.最短剩余时间优先7.交互式系统中的调度
1.轮转调度(最古老,最简单,最公平,使用最广的算法) 使用时间片制度,某个进程时间片用完会强制剥夺CPU使用权并移到等待队列尾 良好的设计可以在保证公平的前提下减少上下文切换(代价很高),所以认为时间片设置为20-50ms通常是一个不错的选择 2.优先级调度(每个进程被赋予了优先级,高优先级的先运行) 为了防止高优先级的进程无休止的运行,调度程序可能在每个时钟中断时降低当前进程的优先级,或者给当前进程一个时间片,用完了后次优先级进程便获得了机会. 对于IO密集型,可以考虑使用某个进程上次的时间片总长/结束时已使用时长=f来获得它的优先级 当然,也可以通过分级制度,在各个不同优先级的进程组之间使用优先级调度,组内使用轮转调度. 3.多级队列 属于最高优先级类的进程获得一个时间片,次级类的进程获得两个时间片.当某个进程使用完了他的时间片,便被切换到下一级中.这种做法的好处是,减少了上下文切换. 4.最短进程优先 通过老化策略得到当前进程的估计执行时间,进行作业时间最短排序 5.保证调度 尽可能使各个进程公平 6.彩票调度 在保证公平的基础上,略微可以偏袒于优先级高的进程 7.公平分享调度 保证用户公平,而不是进程公平,因为每个用户持有的进程数量不一定相同.- 实时系统中的调度,实时系统是一种时间起主导作用的系统.实时系统通常可以分为硬实时和软实时,前者要求进程必须满足绝对的截止时间,后者可以稍微有点误差.在这里,调度程序的就是调度那些满足所有截止时间的进程.实时系统的调度算法可以是静态的或动态的.
- 实时系统中的事件按照响应方式可以分为周期性和非周期性事件,对于一个系统,可调度的条件是:每个周期事件需要使用的CPU时间/周期,之和<=1,如果大于1就说明无法保证在每个事件都执行一遍的情况下把它们都执行一遍.
- 对于如何更好地实现调度,这里把调度机制和调度策略分开来.用户可以提供自己的调度策略供操作系统使用,完成特定的调度方法.
- 关于线程调度,要求区分用户级和内核级,因为在用户级时,内核不知道线程的存在,所以分配的CPU是分给进程的,而进程又分给线程,假设进程为A,那么可能出现A1, A2, A3, B1, B2...的情况.对于内核级,因为是内核直接管理线程,所以可能会出现这样的执行顺序:A1, B1, A2, B2, A3...
- 内核知道上下文切换代价很高,所以在内核级时,内核在同样的线程选择上,会优先选择同一进程的.还有,用户级的线程阻塞会造成进程阻塞.
- 地址空间是,一个进程可用于寻址内存的,一套地址,的集合.每个进程都有自己的地址空间,并且这个地址空间独立于其他进程的地址空间(除非有共享).
- 在这里介绍一下基址寄存器和界限寄存器.他们的主要作用是给出实际地址的地址偏移量和地址范围.程序的起始物理地址装载进基址寄存器中,程序的长度放在界限寄存器里.缺点在于,每次访问内存都需要进行加法和比较运算.
主要原理就是:把一个进程完整的调入内存,运行一段时间,再存回磁盘,空闲进程主要在磁盘上.
但是交换空间可能出现多个小内存空闲区的情况,这时可以使用内存压缩技术,这个技术比较吃CPU.
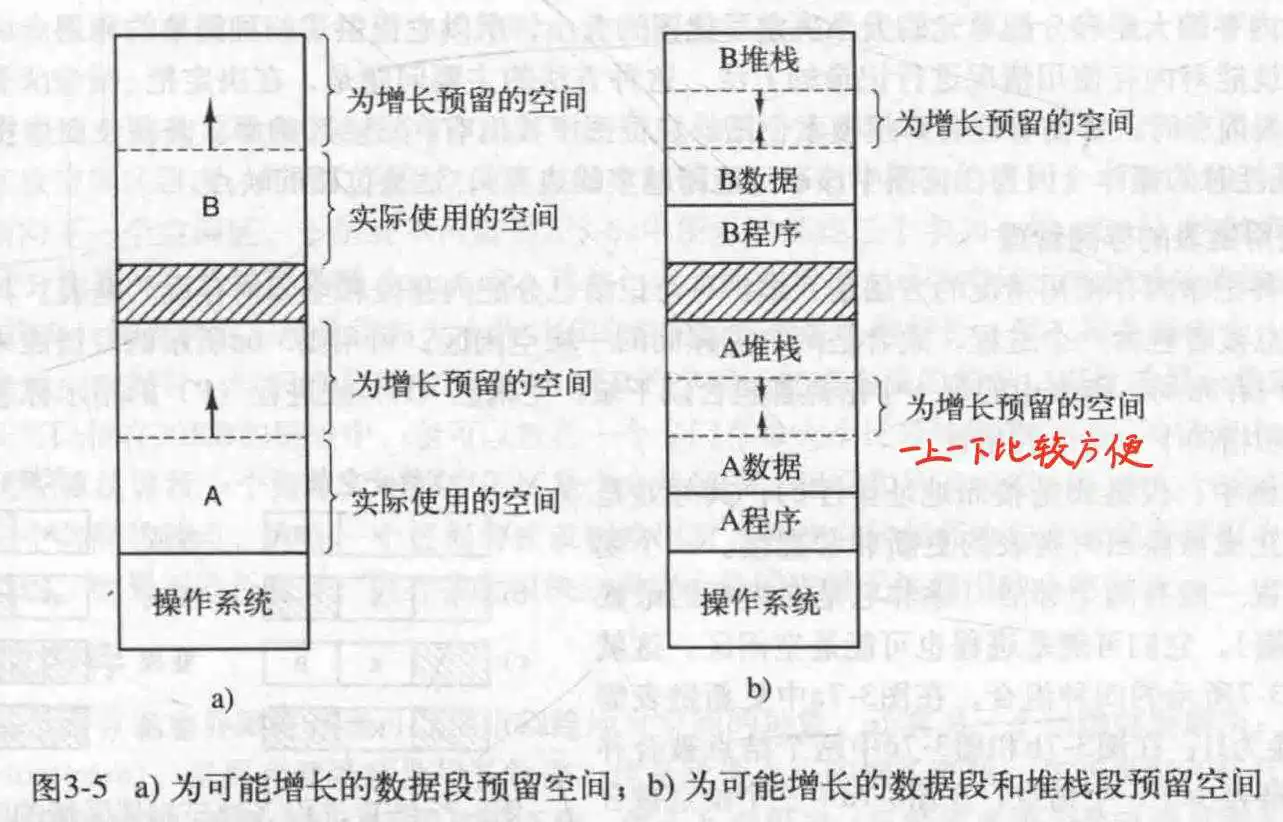
进程需要增长,所以可以通过把它移动到更大的空间来实现,或者移除它相邻的进程.如果一个进程在内存中不能增长,并且磁盘空间也满了,那么只能把它挂起直到有可用空间.
不过,可以预先分配足够大的内存,供后期增长;在移出时,仅仅移除已使用的内存.
在一个进程中,具体来说一般都是堆栈和数据会增长,正文一般不会动,那么可以把堆栈放程序空间的上面,数据放下面,中间是可以供增长使用的空闲空间.
- 使用位图的存储管理.这种方式类似邻接矩阵,用0和1记录某个内存块是否被占用.分割的内存块的大小决定了位图的大小.缺点很明显,在内存很大时,需要很大的位图来保存,这本身就很占用内存;而且在查询可用的位置时,需要遍历整个图,这是一个耗时的操作.
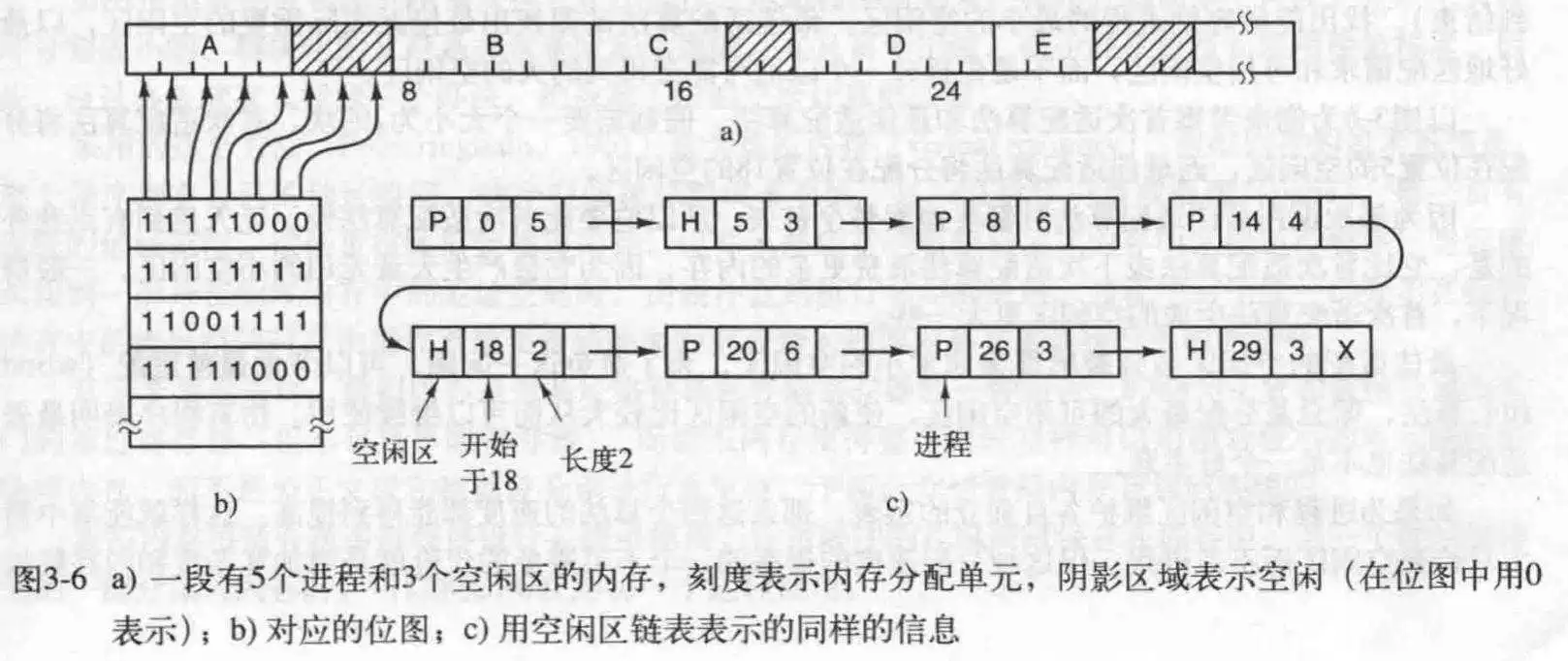
- 使用链表的存储管理.简单来说就是,每个节点包含一个指向前面节点的指针和指向后面节点的指针,一个记录当前位置是空闲还是使用的标志,起始地址(内存块的地址,但内存块是好几个字节组成的,这个起始地址就是这个内存块最左边的地址),长度(此内存块多大).
对于改变某个节点状态,会产生四种结果,如果当前节点被置为空闲且相邻节点也是空闲的,可以把他们合并,所以四种操作如下所示:

那么如何找到需要大小的内存呢?来看几个算法:
首次适配算法,会沿着链表一直找,直到找到足够的空闲区.
下次适配算法,在首次适配的基础上记录一下位置,方便下次使用,看起来很好,可是实际性能还不如首次适配.
最佳适配算法,遍历整个链表,找到最小可用空闲区,虽然其本意在于减小内存使用,但实际上,它会产生大量小的空闲区,反而浪费了内存.
最差适配算法,每次找最大可用的空闲区,但实际使用也不咋地.
如果分离进程和空闲区,分出两个链表,各自维护,可能会高效,但是代价是增加了复杂度和内存释放(两个链表均实行了操作).
还可以对链表排序;或者,打表,就是为那些常用大小的空闲区维护一个链表,每次需要直接获取.这个叫快速适配算法
这些算法都有一个缺点,就是在进程换出或终止时,需要进程合并操作,这是一件耗时的事.
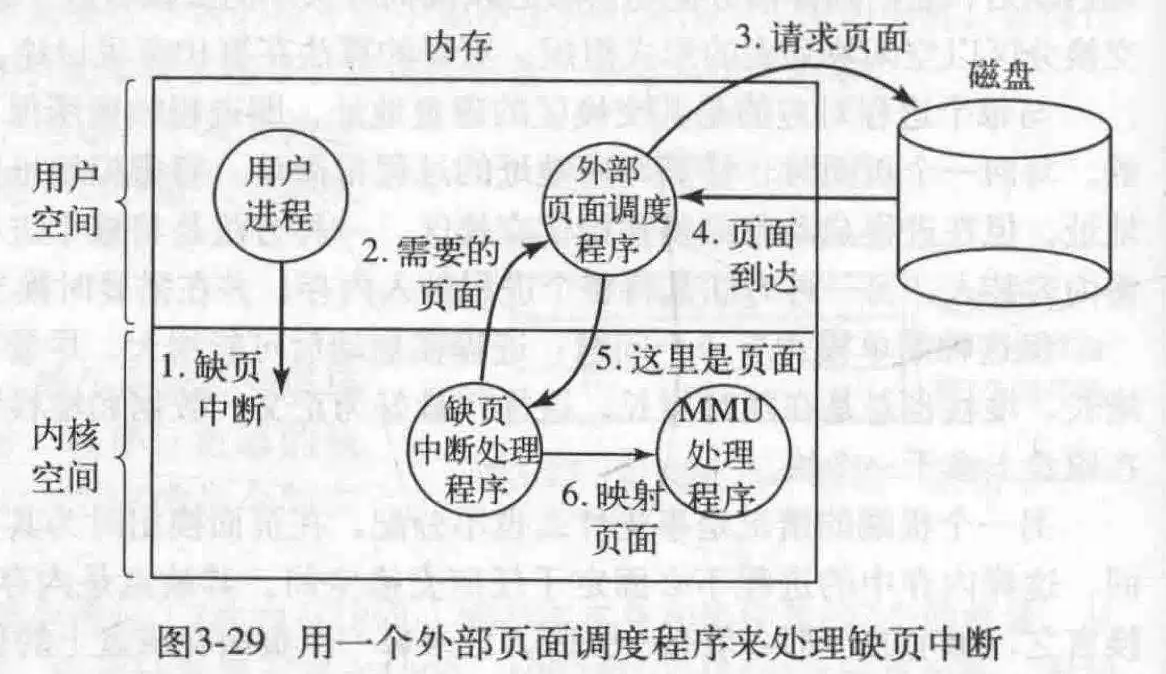
虚拟内存的基本思想是,每个程序都有自己的地址空间,这些地址空间被分割成许多块,每一块被称为页面(页),每一页有连续的地址范围,但是页与页之间不一定;这些页被映射到物理内存中,但是不是全部页都被映射到了.当程序访问未映射的页时,会触发缺页中断,此时有系统进行创建映射(包括找到另一个页框,备份,写入新数据,创建映射关系),然后重新执行刚刚被中断的指令.
当一个进程等待它的一部分读入内存中时,可以把CPU交给别的进程使用.
注意,程序向操作系统申请内存,操作系统派给内存(虚拟内存),一般情况下都是操作系统为当前进程选定一大块区域给它用,进程不知道这个事情,他只管要,系统封装了细节.一般来说,申请来的内存都是那一大块内存里的(虽然这一大块也是虚拟的,不过通过映射,对程序来说那就是真实的内存)
由程序产生的这些地址称为虚拟地址,他们构成了一个虚拟地址空间,在使用虚拟内存的计算机上,虚拟地址被送到内存管理单元(MMU)中,进行解析得到物理地址或进行重新映射.虚拟地址空间按照固定大小划分成一个个的页面,而在物理内存中,与页面大小一致且与页面对应的,是叫页框的东西.那便是页面映射的目标了.
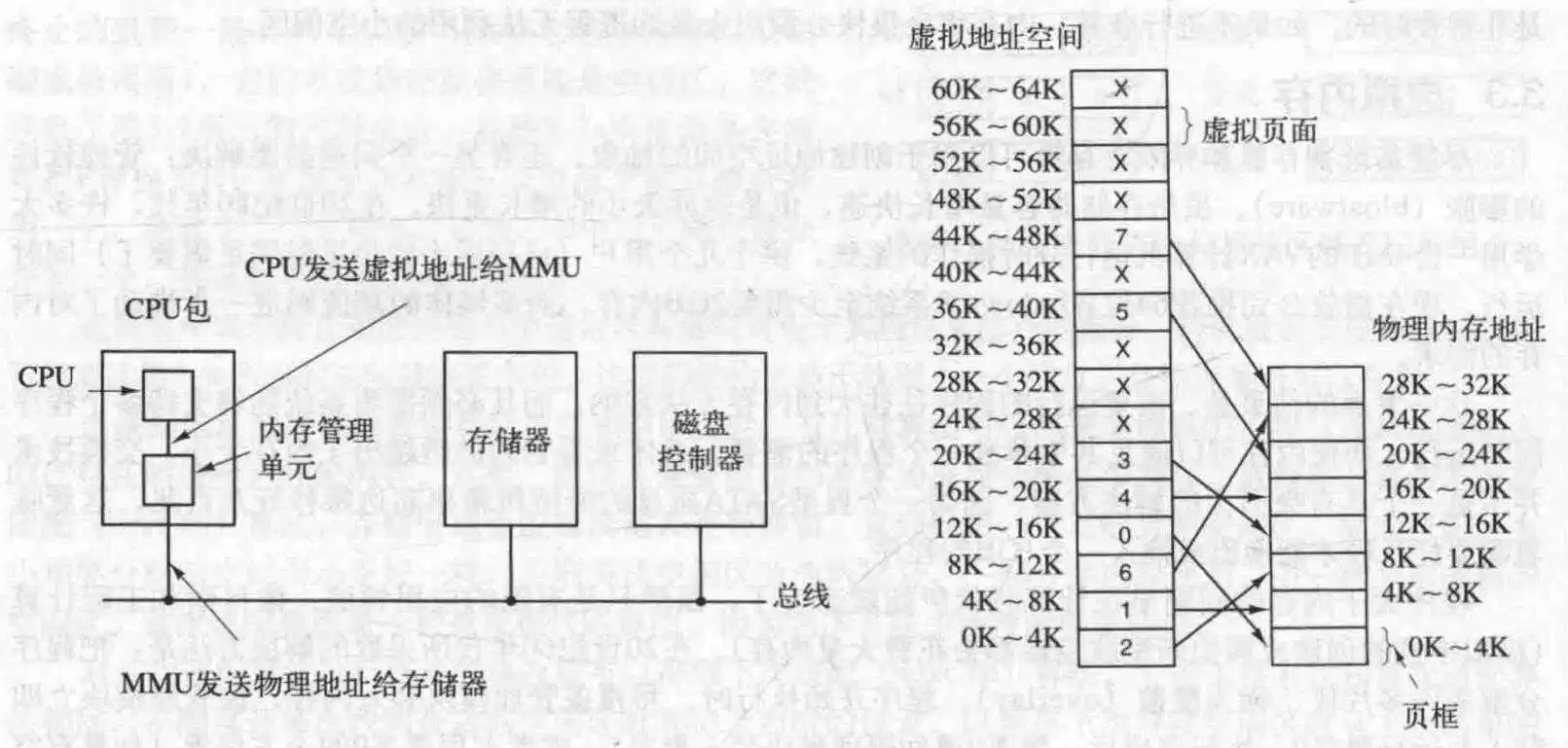
页表就像一个函数一样,可以把虚拟地址映射到具体的(精确到字节的)物理内存地址.它定义了页面与页框的一一对应的映射关系.
MMU内部大概如下所示,里面有一个页表,指出了页面如何映射到页框:
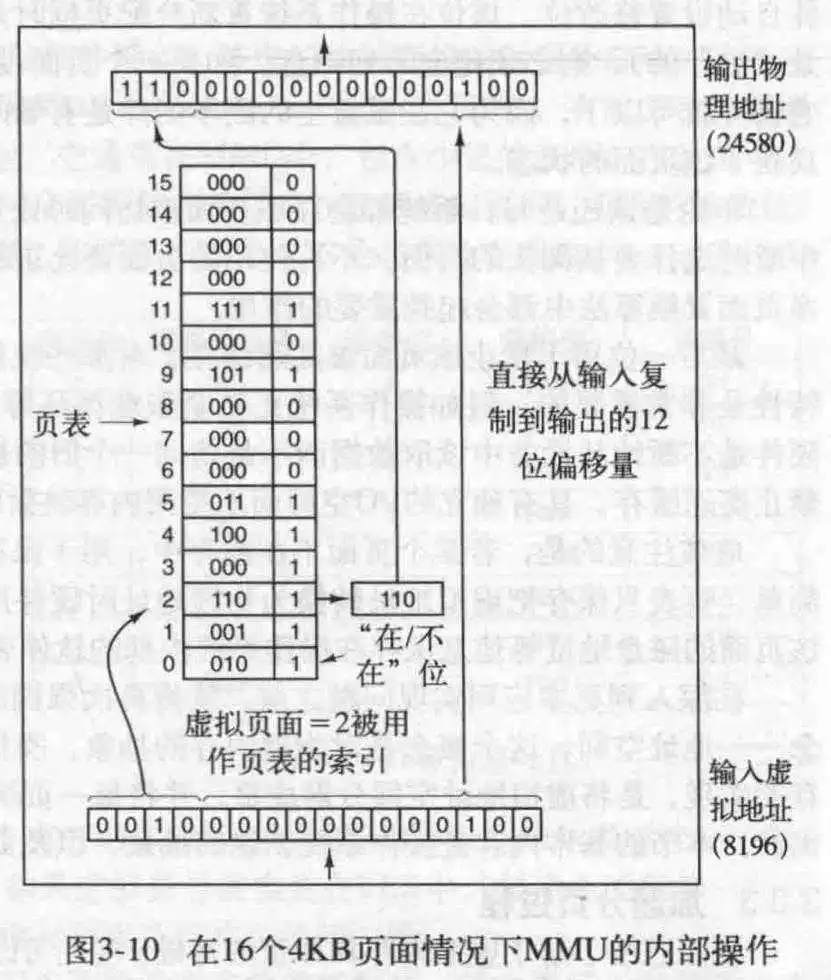
对于输入,假设是一个16位数,那么前4位作为页号(页表的下标),后12位作为偏移量,得出的地址为定位到的页表项的值(新的4位)+偏移量.
一个页表包含很多项,每项的大概结构如下所示:
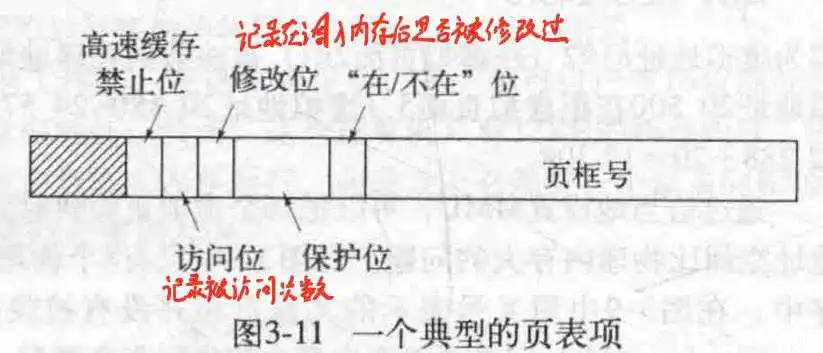
来看一下具体各项参数的意义:
页框号用来定位实际的地址. 在/不在位用来标识此项是否可用. 保护位用来指出可进行的操作,是读还是写还是执行. 修改位记录调入内存后页面是否被修改过. 访问位记录被访问的次数. 高速缓存禁止位指出是否开启高速缓存.
关于高速缓存位,如果是即时IO操作,最好关掉,不然可能会造成读取失败.关于访问位,那是给操作系统看的,用来决定置换哪个页面.
- 转换检测缓冲区 TLB,又称快表,用来记录常使用的映射关系,这样在需要的时候直接查表就可以了,而不需要通过MMU进行转换.TLB中含有页表项的大多数,除了虚拟页号外(它在页表中起到索引的作用,而在TLB中,整个虚拟地址就是索引(数组下标),故不再需要虚拟页号的存在),几乎都有.
如果某次执行匹配,发现TLB没有此项,会在MMU查询之后从TLB中淘汰一个,并进行替换.
- 软件TLB管理 在内存中申请一块地址,保存TLB表,刚刚的那种方式是通过硬件实现的;这种软件的方式是交付给OS来实现.此时的OS不仅进行TLB维护,还进行TLB更新,页面替换,缺页中断处理等.不过要记得在TLB中固定这个软件TLB的地址,防止被替换,那就是"我杀我自己"了,就很尴尬.
来看看软失效和硬失效. 软失效查询的页面不在TLB但在内存中,这种不需要磁盘IO操作. 硬失效需要硬盘IO操作,并置换页面,更新映射关系,进行页表遍历(在页表结构中查找相应的映射)这个操作是软失效的百万倍耗时.
次要缺页错误指的是需要的数据已经被其他某个进程调入内存,此时重新整理映射关系就好. 严重缺页错误指的是需要从磁盘调入某个数据到内存中并建立映射关系.
把整个页表保存在内存里不一定可以,尤其是在内存很大的情况下,那就一点都不现实了.来看两个解决方法.
- 多级页表
使用两个或多个页表进行映射,为什么这么设计呢?因为对一个程序来说,给它分配的内存,尤其是中间的空闲区(用来增长的)根本没必要加进去,而这些空闲区往往还占了很大的空间,所以采用分级的方法,就能减少表的大小.
比方说在顶级页表的第0级,保存程序正文,倒数第一级,保存堆栈,倒数第二级保存数据,中间都是不用的.然后刚刚的三级分别指向三个二级页表,每个二级页表再映射到页框上,这样,只需要四个页表就能保存了.
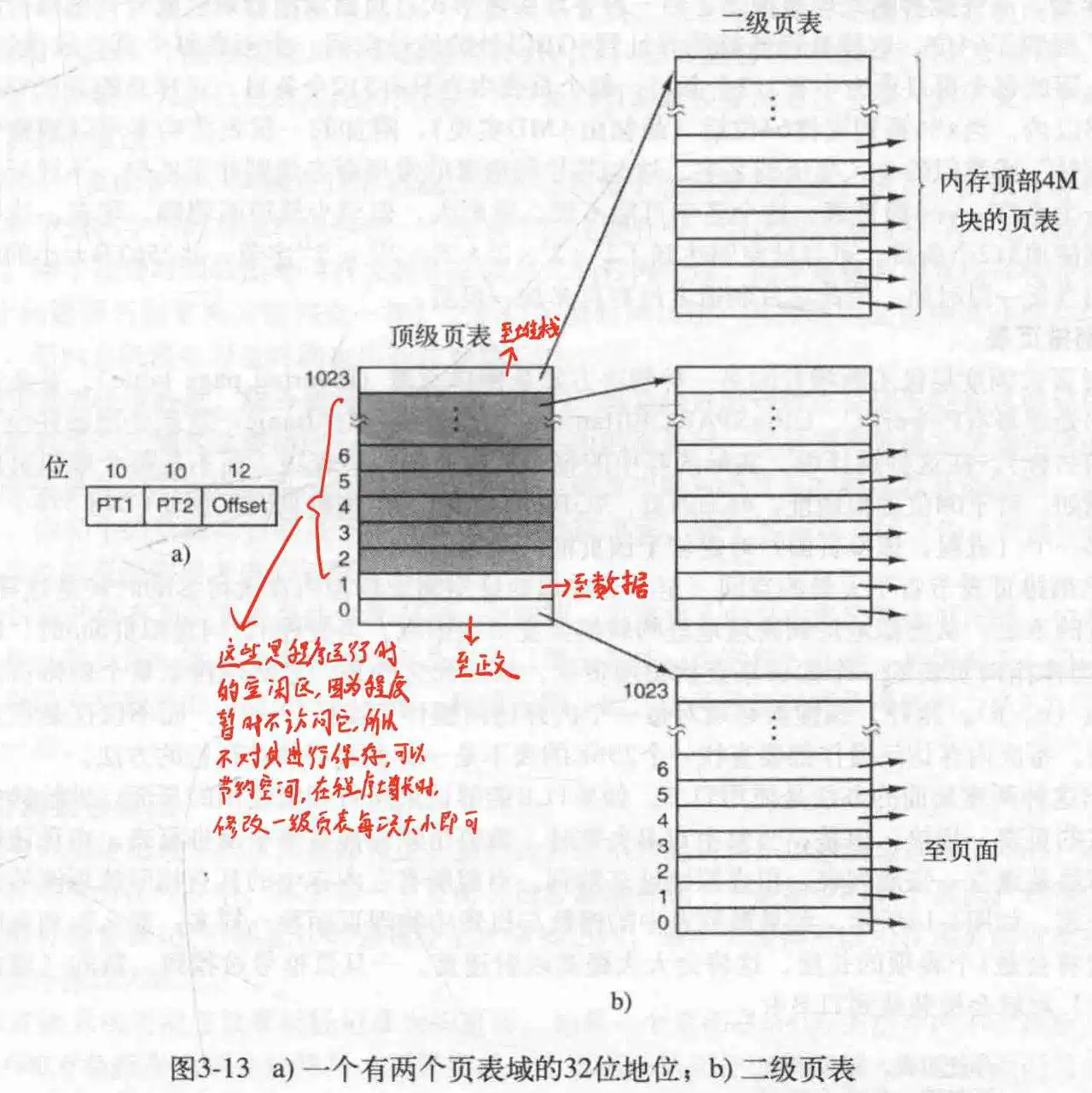
对于顶级页表中间的,把他们的在/不在位设为0,禁止程序访问,这样可以监控程序的行为.
- 倒排页表 刚刚那种都是页面映射页框,注意,在实际上可能是多个页面映射一个页框(当前是A进程映射页框A,过会可能是B进程映射页框A,但是页表都记下来了),但是实际运行只有一个页面和一个页框在映射.所以可以设计某种方式,让一个页框对应多个页面,这样就节省很多空间了.
但是这种方式有一个弊端,就是想找到页面对应的页框时,得全部遍历,即使有TLB,这也不是个好办法,于是乎,可以使用哈希表,获取虚拟地址的哈希值,再使用链接法,把他们链接起来,注意,此时链接的是一个个的小结构体,它们由页面和页框组成,所以还是可以找到页面对应的页框的.
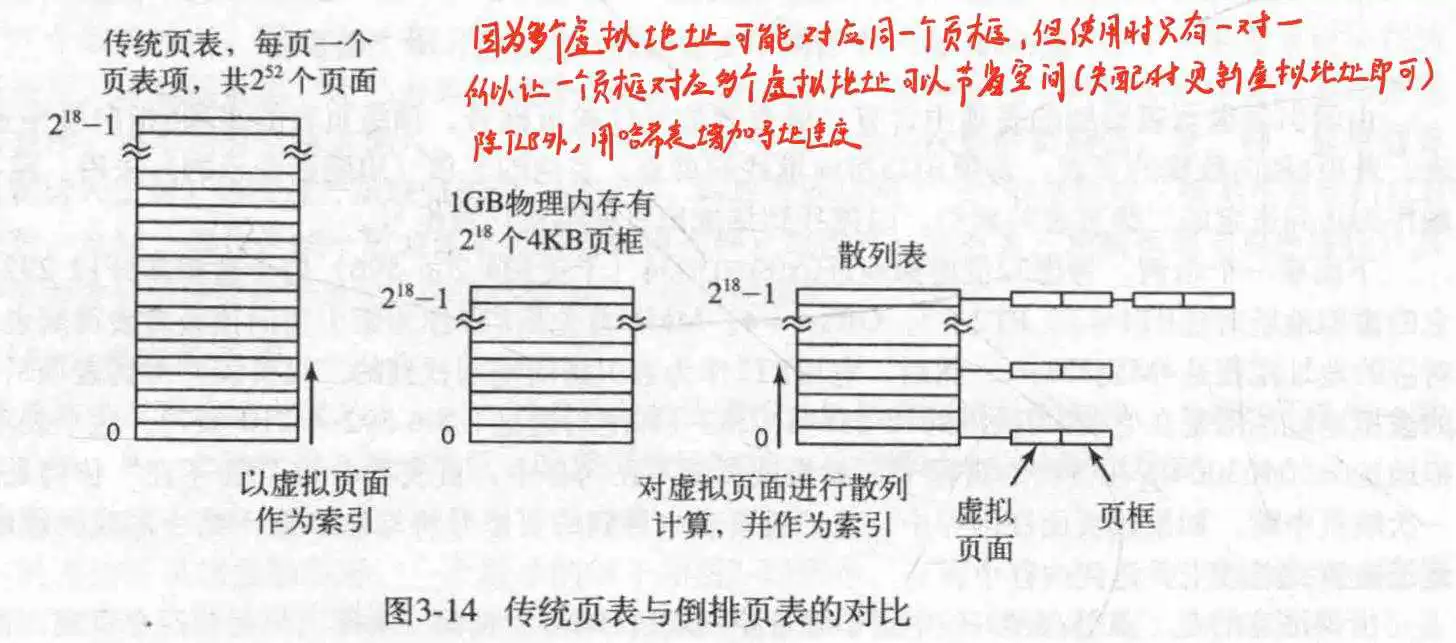
此方法在64位机里很常见.
在执行页面置换之前,记得进行备份页框的数据.如果准备换出的页面在内存上被修改过,记得备份到硬盘,否则直接覆盖.
通过某种神奇的方式获取最不常用的页面并置换,可是不可能实现.
对于页面,定期的把它的R位(访问位)清零,以区别最近没有被访问的页面和被访问的页面.
当发生缺页中断时,操作系统检查R位和M位(修改位)的值,并把页面分为四类:
第0类:没有被访问,没有被修改; 第1类:没有被访问,已被修改; 第2类:已被访问,没有被修改; 第3类:已被访问,已被修改;
当准备置换时,从编号最小且非空类里选一个页面出来.
排个队,每次把新加入的页面排到队尾,替换时优先选择队首的.
在先进先出算法的基础上,检查R位,如果是0,就置换,否则置0并加到队尾.
类似第二次机会算法,但是是环形链表形式的.
当发生缺页中断时,首先检查当前指针指向的页面R位,是0就替换,并前移指针,否则置0前移指针.
此方法要求有一个硬件计数器,在每条指令执行完后自增,然后访问页面时自动加到页面上去,这个值代表页面的上次使用时间,越小说明页面越旧,最后替换就行,可是难点在于,不好实现.
在这里,为每个页面添加程序计数器,然后使用一种老化算法,首先,在R位被加到计数器之前,右移一位计数器,再把R加到左边,这样就完成了更新.这样就能保证计数器越大,页面被访问越频繁.
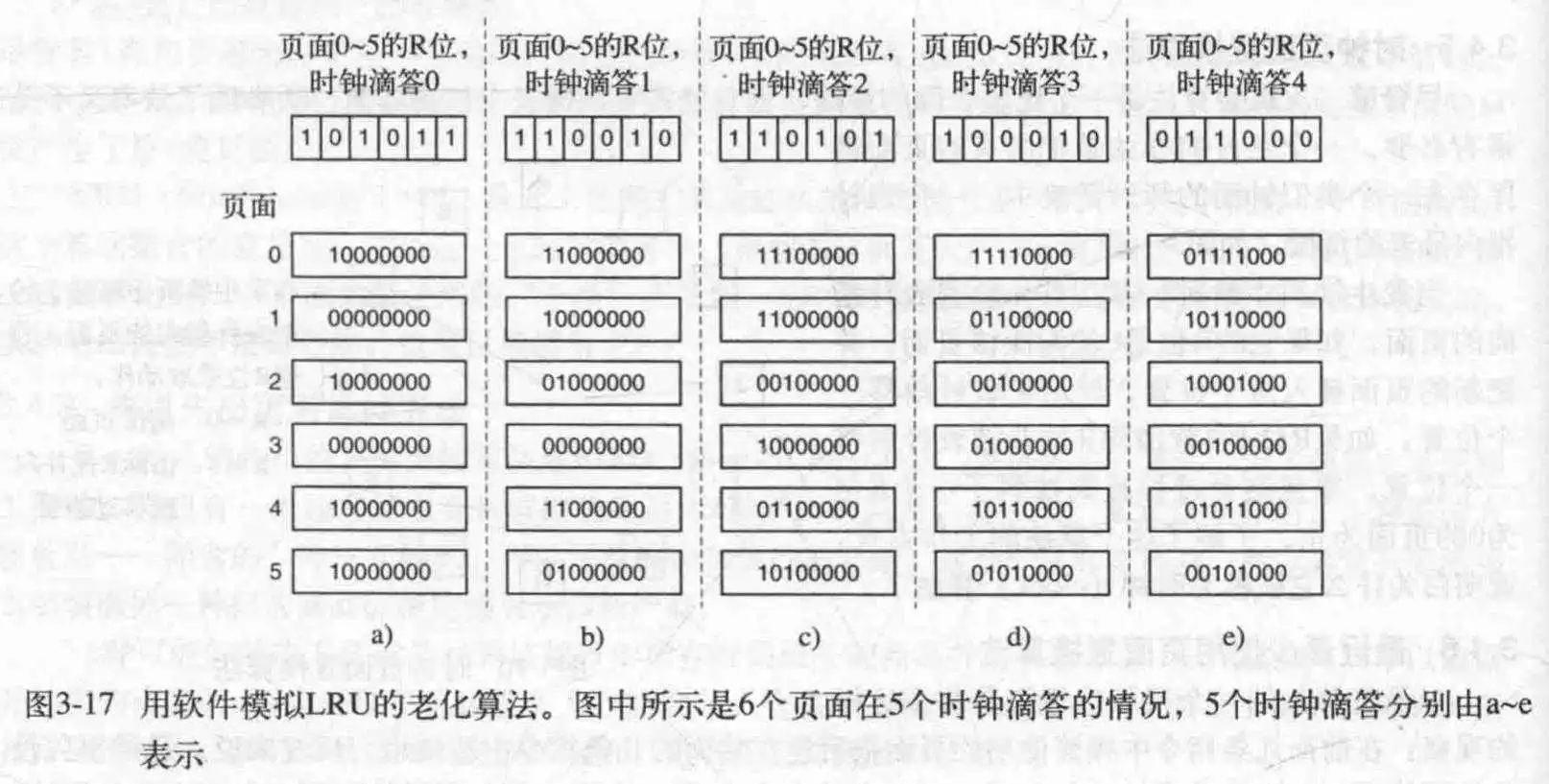
该算法和LRU的区别是老化计数器只有有限位数,所以没法更细致的区分页面.
首先明确几个概念.一个线程当前正在使用的页面的集合被称为工作集.若每执行几条指令就发生一次缺页中断,那么成这个程序发生了颠簸.
在多道程序设计系统中,经常把进程转移到磁盘上(移走全部页面),但是再转换回来就很容易发生缺页中断,遂引入工作集模型,确保进程在运行前,它的工作集就已经在内存中了.在程序运行前预先装入其工作集页面也称为预先调页.
工作集是随时间变化的,设在任意时刻t都存在一个集合,它包含最近k次内存访问所访问过的全部页面,这个集合w(k, t)就是工作集,因为最近k=1次访问的页面必定属于k>1次所访问的页面.所以w(k, t)是k的单调非递减函数.当然,w(k, t)并不能无限增大,所以得到这样的图像:

k的值有一个很大的范围,它处在这个范围中时,工作集不会变,因为工作集随时间变化很慢.预先调页就是在程序运行之前预先推测出工作集(根据上次运行结果推测)并装入内存.OS还可以根据推断出的工作集,决定淘汰哪些个页面.
实际实现比较困难,于是选用近似方法,考虑执行时间,什么意思呢?进程的工作集可以定义为在过去的t秒的实际运行时间所访问过的页面的集合.然后在页表上添加一个时间属性.
工作过程:在时钟中断时,会清空R位.每次发生缺页中断时,就扫描页表来找寻合适的页面,此时检查每个页表的R位;
如果是1,就把当前时间写入到页表项的"上次使用时间"域,说明这个页面在当前时钟滴答(上一次时钟中断到现在时钟中断这个时间内)中已经被访问过;
如果R是0,则可以作为候选者,然后计算它的生存时间,与t比较,如果大于t就替换它,然后继续扫描以更新剩余的项.
如果R=0同时生存时间小于等于t,那么临时留下来,但是要记录生存时间最长的页面,然后继续,最后如果找到了多个R=0的页面,那么淘汰生存时间最长的页面.
最最最后,如果R都为1,那随机淘汰一个,最好淘汰一个干净的页面.
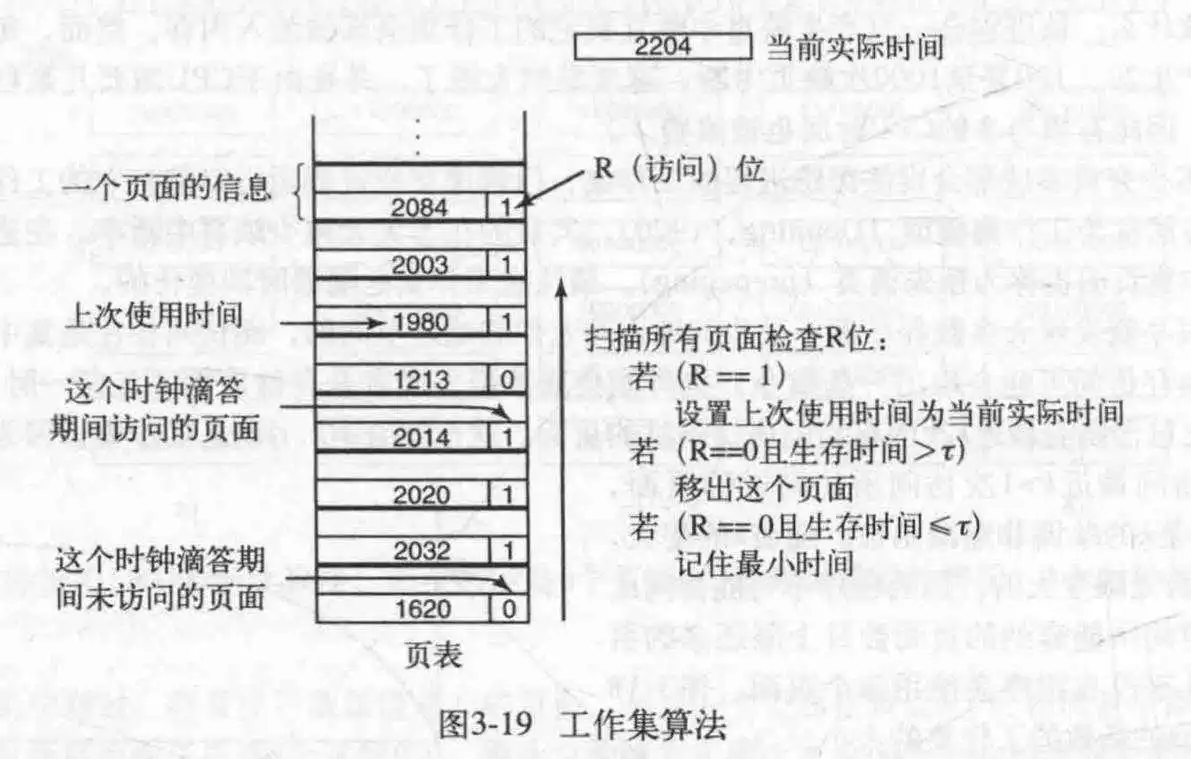
此算法类似时钟算法,简述其工作流程:
首先检查指向的页面,如果R=1,置0移动到下一个页面;
如果R=0且生存时间大于t且页面干净,申请此页框;如果被修改过,为了避免提前的IO操作,指针继续向前走;
如果回到起点,那么肯定发生二者之一的情况:至少调度了一次写操作;没有调度过写操作.
第一种情况,是我们需要的,没话说,置换遇到的第一个干净的页面;第二种,随便选一个干净的页面,所以需要遍历途中记录干净的页面,如果这也满足不了,那就替换当前页面
实际使用中,软件模拟LRU页面置换算法和工作集时钟页面置换算法比较可行.
来看一个实际的问题,如果进程进行新的映射,那么问题来了,是替换整个虚拟空间的最合适的页面呢?还是仅仅替换当前进程的虚拟空间的合适的页面呢?前者叫全局策略,后者叫局部策略.全局策略动态的分配进程的空间,局部策略则是固定了进程的内存空间大小.
使用局部策略需要在一开始指定合适的大小.如果使用全局策略,那就需要PFF(缺页中断率)算法来动态的更改分配给某个进程的页面数.此算法会计算每秒的缺页中断数,或者使用过去某些秒内的数据为参考,然后得出一个结果,如果缺页中断率过低,甚至可能剥夺某些进程的页面(进程口吐芬芳).如下图所示:中断率应保持在A和B之间.横坐标是时间.
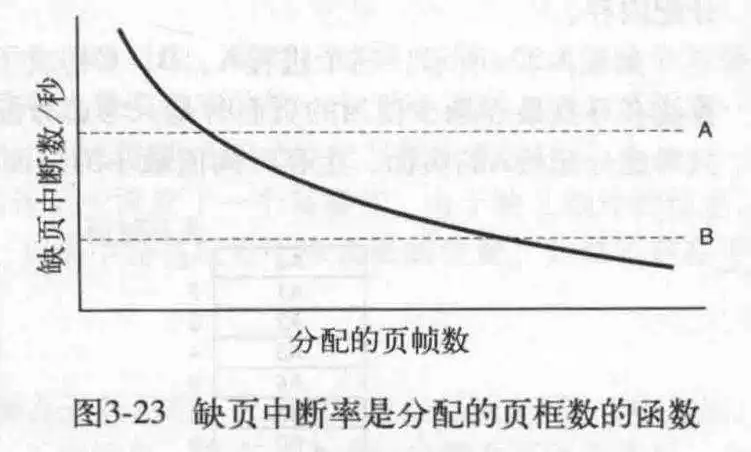
对于某些算法,只有局部策略才有意义,比如两个工作集算法.
如果某个进程发生了颠簸,且一直不好解决,那么可以尝试把一些进程移除内存,交换到硬盘,完全让出空间.如果还是不行,继续交换进程.但是并不收回他们的页面,不过在换出时,要记得考虑进程类型(IO密集型还是计算密集型),以及进程的特性.
页面大小的选择也很重要,选择大了,会造成浪费,选择小了,会增加页表大小,以及管理的复杂度.小的页面还会占用更多的TLB,要知道,TLB对性能而言,异常重要.传输一个大的页面到硬盘和传输一个小的页面差不多.最后,设进程平均大小是s字节,页面大小是p字节,每个页表项需要p字节,我们来看看内存开销:
开销=se/p+p/2
求导得当p=(2se)^(1/2)时,开销最小.
现在常见的页面大小是4KB或8KB.
在这种模式下,两个空间分别有自己的页表,自己的映射,自己的物理空间,分离的意义是为了更好地利用空间.程序放程序空间,数据放数据空间.
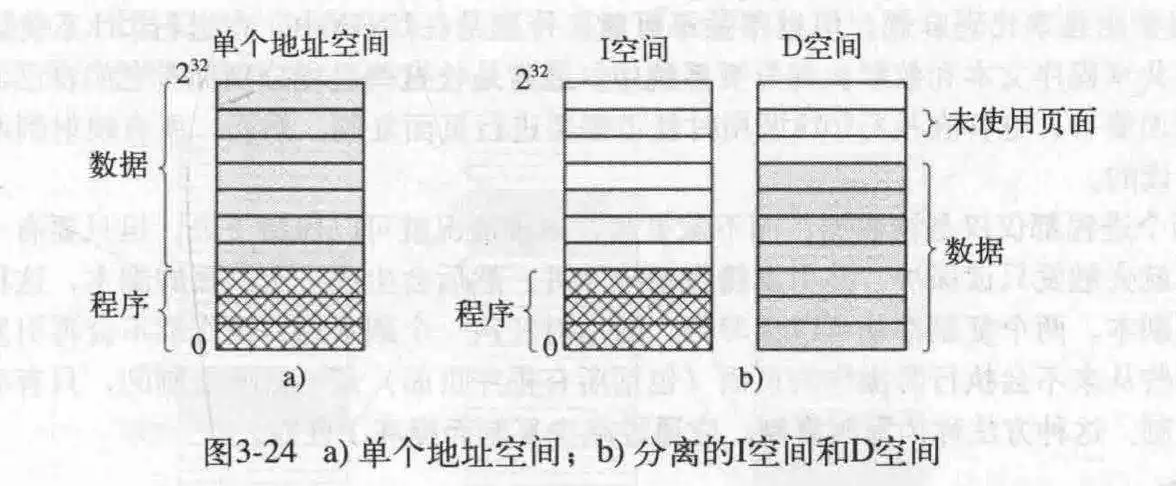
为了减少内存空间地重复,更好地增加进程间传输能力.
有一点,当A进程结束时,应该可以注意到A进程的某些页面是否被共享了,是否被B进程所使用.所以需要一个专门的数据结构记录共享界面.
当然,还要记得加上写时复制,如果某个进程试图更新共享页面,则立马生成此页面地副本,这样每个进程都有自己的副本了,记得,只有实际修改的数据页面需要复制,这样就能保证每个进程的独立性了.
如果某个程序已经装载了某个库在内存中的话,新的进程就不需要再次导入;共享库是以页面为单位装载的,需要多少便加载多少.除了实现了更好地节约内存,更快的性能,另一点就是更新方便,不会牵一发而动全身,仅仅更新部分的库就可以,而不需要整个重加载.
为了解决共享库的地址重定位问题,在代码中使用相对指令的地址,这样就可以做到与具体的位置无关了.
通过把文件当成内存的形式映射到页面,实现进程间的文件共享,是文件操作向内存操作一样简单易用.
为了保证有足够的页框可用,分页守护线程会定期运行,使用页面置换算法获取更多的页框,并进行把原页框的数据写会到磁盘(如果有必要的话).
分页守护线程还可以确保页框都是"干净"的,这样可以在下次直接写入.
实现进程间的内存共享.
与分页有关的工作,共有四个时期:进程创建时,进程执行时,缺页中断时,进程终止时.
进程创建: OS确定进程需要的空间大小,然后为它们创建一个页表并初始化并固定到内存中.若进程被换出,页表就可以清除了.还有,OS还要在硬盘中分配出交换空间,用来放置换出的程序.OS还要使用程序正文和数据对交换空间进程初始化,以便进行置换页面时方便使用.最后,OS把页表和交换空间的信息存储在进程表里.
进程执行: 当一个进程执行时,必须重置MMU,刷新TLB(所以看得出MMU TLB仅为当前进程服务,不会记录前一个进程的信息).新进程的页表必须称为当前页表.
缺页中断: OS读取硬件寄存器,找到是哪个虚拟地址导致了缺页中断,并计算出需要的页面,然后进行页面置换,把磁盘的数据复制到相应的页框中;最后,回退程序计数器,重新执行导致中断的指令.
进程退出: 当一个进程退出时,OS释放与它有关的页表,页面,和页面所占用的磁盘空间;当然,如果他们中的某些被共享了,就得等最后一个使用它们的进程退出才能释放.
一个具体的缺页中断处理过程如下:
- 硬件陷入内核,保存程序计数器.大多数机器将当前指令的各种信息保存在特殊的CPU寄存器中.
- 启动一个汇编程序,保存通用寄存器和 其他易失信息.此程序将OS作为一个函数来调用.
- OS被启动,读取某个硬件寄存器,获得导致失败的虚拟地址,如果没有的话,检索程序计数器,分析计算出需要的地址.
- 此时OS获得了虚拟地址,会检查地址是否有效,存取与保护是否一致,如不一致则发出一个信号或杀死进程.然后检查是否有页框可用,如果没有就置换;
- 如果需要置换,那就看是否需要写回磁盘,如果需要就挂起此进程(因为进行IO操作比较耗时)运行另一个进程,同时把此页框标记为忙碌,禁止其他进程使用.
- 当从磁盘写入页框时,还要把这个进程挂起,运行其他进程(还是因为磁盘IO操作比较耗时).
- 更新页表,更新页框状态为正常
- 恢复到发生缺页中断指令以前的状态,程序计数器重新指向这条指令.
- 调度引发缺页中断的进程,OS返回汇编程序的调用.
- 汇编指令恢复寄存器等状态信息,返回到用户空间继续执行,仿佛什么都没发生过.
用来处理虚拟地址计算问题,有些CPU不好推算出虚拟地址,于是使用第二个隐藏的寄存器保存指令.
确保正在进行IO操作的进程不会被移出内存.
Unix系统从文件系统上划分出一块分区用于做交换分区,当系统启动时,该交换分区为空,并在内存中单独的记录着它的大小.与每个进程对应的是交换分区的磁盘地址,保存在进程表里.计算页面在磁盘中的地址很简单,虚拟地址的偏移量加上交换空间的起始地址.
对于进程的增长,可以采用正文与数据分离的形式,分别建立交换区.
对于分配方法,有两种,一种预先分配好,一种用时再分配.前者页面对应的磁盘位置直接可以获得,后者需要新的表记录每个页面对应的磁盘位置.
旨在降低复杂度,让存储管理器作为用户及进程运行.
用于解决程序增长问题,把空间划分成一段一段的,用来实现更精细化的增长空间分配和控制
I/O设备主要分两种(算上时钟是三种):块设备和字符设备。
块设备每次把信息存储在固定大小的块里,然后传输;字符设备以字符为单位发送或接收一个字符流。
I/O设备一般由两个部分组成:电子部件和机器部件。电子部件又称为设备控制器,它们通常包含了一个小的芯片,内存,小的存储单元,因此每个设备控制器就像一个微型计算机一样。
设备控制器负责把串行地把比特(位)流转换成字节块(一个字节=8比特),并进行有必要的错误纠正工作。
刚刚说了,设备控制器(一下简称设控)一般都有几个寄存器用来和CPU通信,比方说CPU可以借此命令设控发送数据,接收数据等。当然一般的设控都有一个可被操作系统读写地缓冲区。
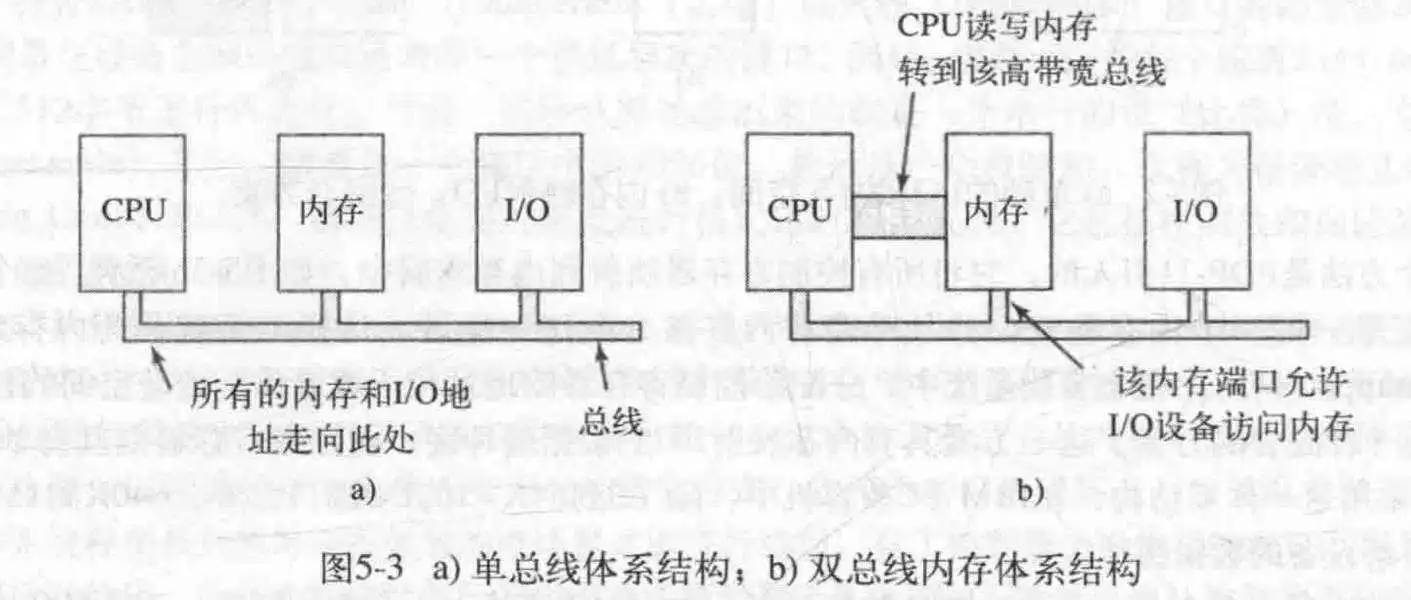
有一个问题,CPU如何和设控通信?有两个方法,一个是对于每个设控寄存器,分配一个I/O端口号;第二个方法是把所有设控寄存器映射到主存里面去。
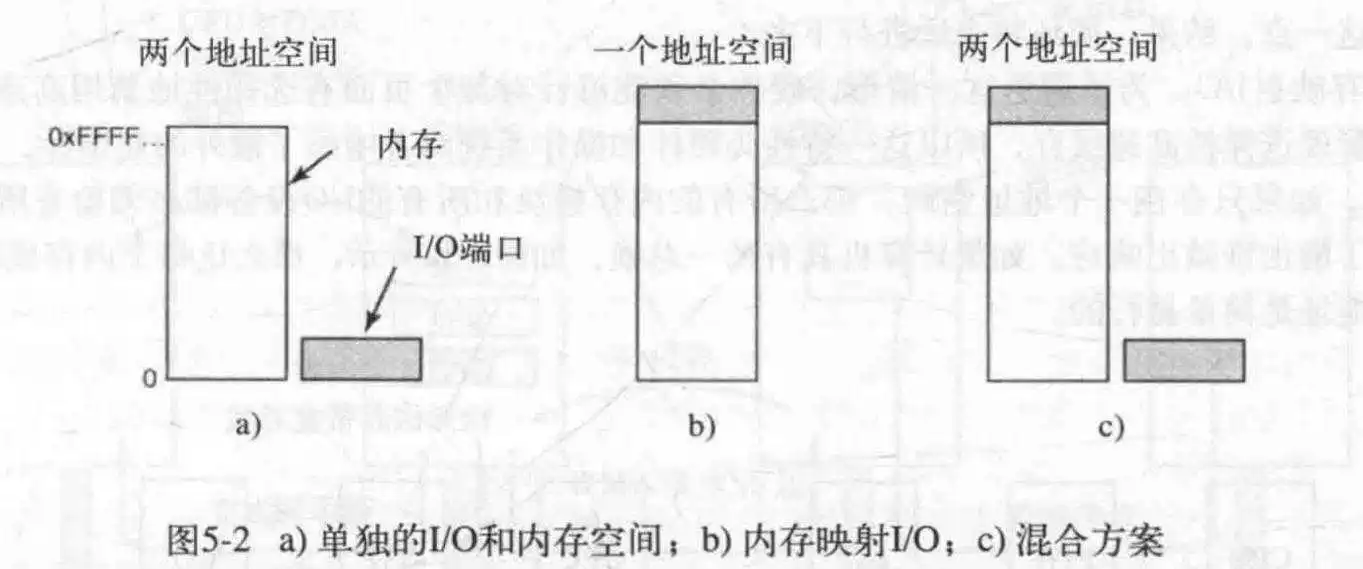
前者需要使用特殊的汇编命令才能访问,比方说:IN和OUT。
第二种方法又称为内存映射I/O。每个设控寄存器被分配一个唯一的,不会被再次分配地内存空间。第三种是混合实现,这种方案具有内存映射I/O地数据缓冲区,同时设控寄存器也拥有自己的I/O端口。这也是x86架构使用的方法。
来看看他们的优缺点:
对于内存映射I/O,不需要额外的汇编代码即可在C语言里访问设控寄存器地值(IN/OUT不属于C能嵌入的汇编);
而且不需要特殊的机制进行保护,这样就可以避免用户进程地读写。因为设控寄存器地值放在了内存里,只要不把这个页面分配到用户进程的地址空间就好了,而且正因如此,很容易做驱动程序唯一性定位,OS仅仅需要在驱动程序进程的页表包含相对应的设控寄存器页面就行了;
第三个好处就是,想要对数据操作,直接对内存进行操作就行,如果不是内存映射I/O,那还得读入到CPU,再进行操作,多了一步指令。
不过,万事皆有利有弊,内存映射I/O的缺点是,想要实现此操作,硬件和OS必须禁用相应页面的高速缓存,否则会造成I/O异常(比如重复读取,无限不可用等),这就需要复杂的硬件和OS操作;
另一点就是,当代OS大多拥有内存专线,所以I/O设备没法查看内存地址。此外,还必须采用特殊的机制使内存映射I/O工作在这样的模式下。一种方法是把全部引用发送给内存,若失败,转发至I/O;或者使用探查法,放过可能是I/O地址的引用;再或者,进行规定范围,范围之外发送到I/O。
CPU直接存取I/O设备过于浪费时间,于是引入DMA方便处理,它就像CPU的小助手,独立于CPU,可以实现对几乎所有I/O设备的访问,读写。很多时候,都是主板自带一个DMA控制器,这样CPU直接访问它就可以了。
一个DMA包含多个可被CPU读取设置的寄存器,其中包含一个内存地址寄存器,字节计数器,一个或多个设控寄存器。设控寄存器指定要使用的I/O端口,传送方向(从哪个I/O设备读写到哪个I/O设备),传送单位,以及在一次突发传送中要传送的字节数。
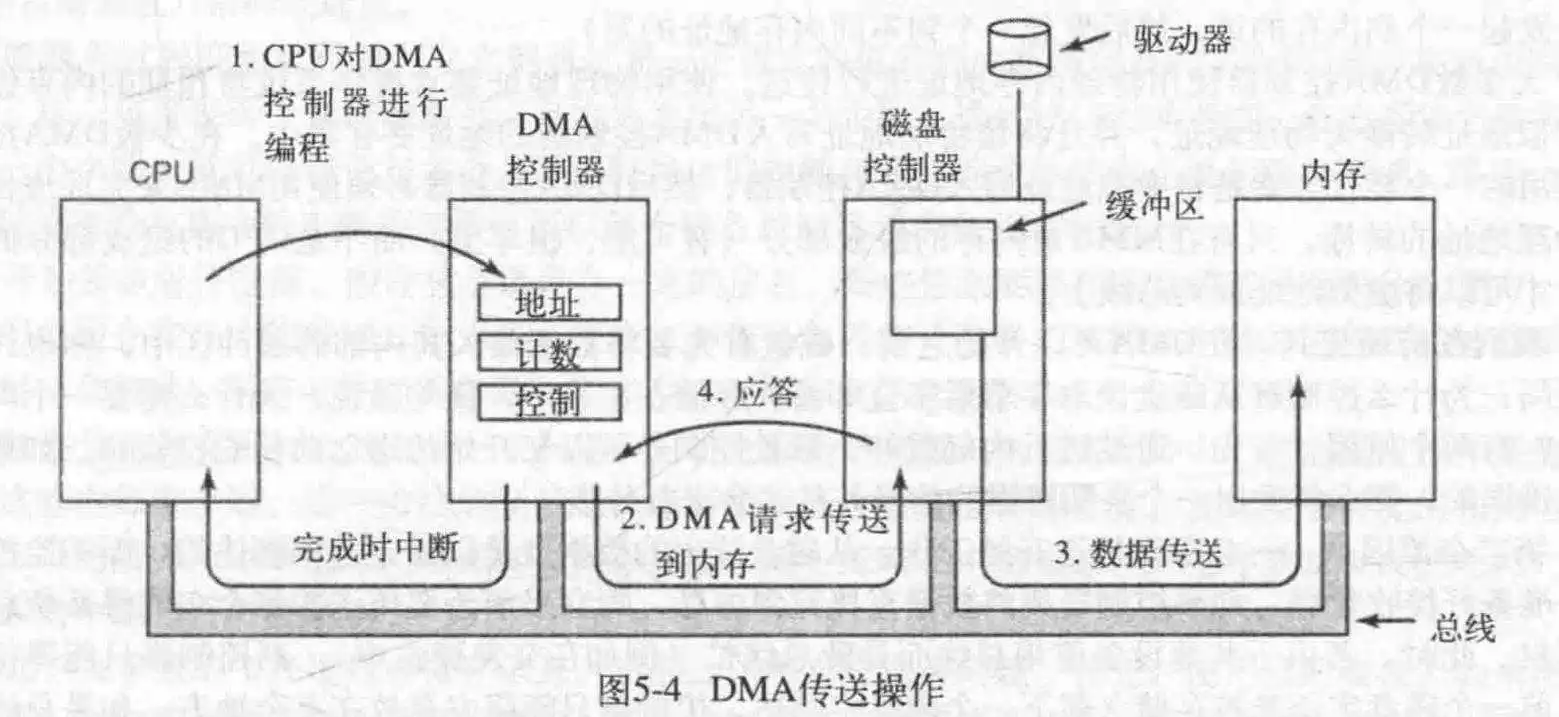
来看一个使用DMA读取硬盘的例子:
首先,CPU设置DMA的控制器的寄存器,告诉他数据放到哪里,一会我去拿;读多少个;一次读几个之类的信息。然后CPU干其他事去了。(第一步)
接着,DMA向磁盘发送读请求(第二步),磁盘读取,把数据写入到内存(要写的位置,即内存地址在总线的地址线上),这是一个标准的总线周期(第三步)。
此时完成写入,磁盘发处应答信号(第四步),DMA收到,步增内存地址,步减字节计数器,若不为0,重复2-4步,当字节计数器为0时,DMA中断CPU,OS开始实际的工作。
DMA在不同的系统上差距颇大,有些DMA可以一次处理多个传输,这样的DMA控制器内部具有多组寄存器,每一通道一组,CPU在不同的通道上装载不同的寄存器值发出请求,每路传送对应一个不同的I/O设控,每传送一个字,DMA就会决定下一次为哪个设备提供服务,他可能使用轮转算法,也可能会考虑优先级,不过它也可以调用全部通道为同一个I/O设备服务,所以通常总线上的每个设控的应答线都与全部通道绑定。
DMA可以在两种模式下工作:每次一字模式和每次一块模式。在前一个模式中,DMA每次请求传输一个字并得到这个字,如果CPU也想用总线,它就得等待,这一机制称为周期窃取,因为设控偶尔偷偷地溜进并且偷走一个CPU地临时的总线周期,从而轻微地延迟CPU。
如果是在块模式下,则是突发模式,因为此时占用的时间更长,发送的数据更多;不过缺点就是,如果此次传输数据比较多,时间比较长,那就可能阻塞CPU和其他I/O设备。
不过还有一种,飞跃模式,在这种模式下,DMA同时设控直接把数据放到某处。但是还有的DMA是叫设控把数据给它,它来放,这样多了一个额外的总线周期,不过更加灵活。
大多数DMA使用物理地址传送,这就要求当OS给DMA的地址寄存器赋值时,记得把虚拟地址转换成物理地址;还有一些使用虚拟地址,这就要求内存自带MMU而不是CPU。
哦对,DMA处理磁盘时,磁盘要先把数据读到缓冲区,原因有二:一是进行数据校检,二是,一旦磁盘开始读,数据就是以固定速率读出,而不缓存的话,磁盘需要写道DMA或内存,万一没抢到总线使用权,就尴尬了,数据还得管理,无疑加大了设计难度。
说中断前先说说陷阱,此陷阱非那个捕猎的陷阱,这个陷阱指的是“陷入其中的”意思,用户程序需要内核级调用时(内核可以访问全部硬件),就会陷入内核运行(深入内核运行硬件级调用更合适),这就叫陷阱。
中断在于可以让CPU转去运行触发中断的进程(如果是时钟中断就随机运行一个进程),在于触发进程上下文切换,避免一个进程吃死CPU(这一点由时钟实现,后面讲)。
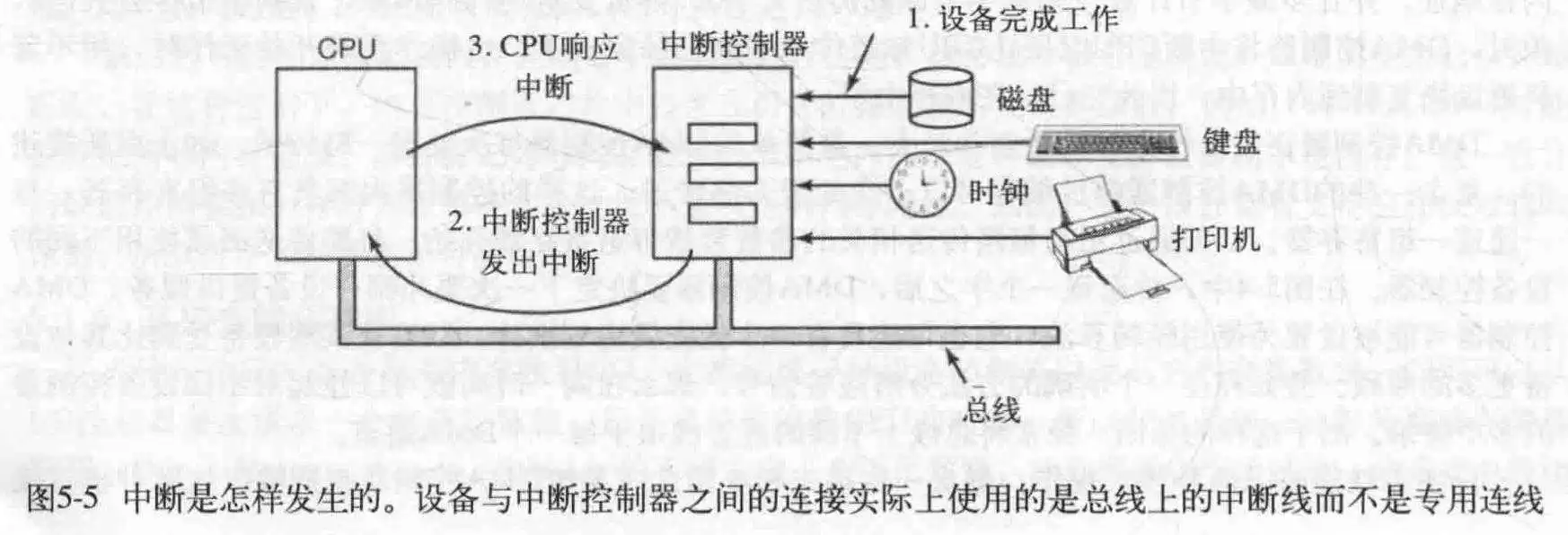
来看看在I/O里中断的事情趴!
首先,某个I/O完成,在分配给它的总线信号上置起一个信号,引发中断。中断控制器检测到,决定怎么处理。
如果没有其他的中断等待处理,就处理它的中断,如果正在处理某个中断,或更高优先级的中断同时发出,它就得等等了。然后这个I/O不停地置起信号,直到得到请求(你不给我我就闹~)。
为了处理中断,中断控制器在地址线上放一个数字,表明哪个设备需要处理,并对CPU置起中断信号。
CPU被中断,进行上下文切换,根据数字作为下标索引在中断容器这张表里寻找一个程序计数器,此PC指向一个中断服务程序,陷阱一般和中断共享同一个中断容器。
中断服务程序向中断控制器地某个I/O端口写入一个确定的值,告诉它CPU收到啦!可以再次发起中断了。不过,可以让CPU晚点再告诉中断控制器,这样CPU才能安静地处理当前中断。
接下来就是保存刚刚运行的那个进程的信息,比如PC等,或者也包含某些寄存器。
但是保存到哪?一种方法是内部寄存器。可是这样只有OS完全读取完毕后才能对中断处理器应答,不然可能造成新的中断程序抹掉刚刚保存的信息,但是如果此时中断被禁止,将会导致死机并丢失中断,丢失数据。
或者保存在堆栈中,谁的堆栈?当前程序的?那样可能会造成野指针,或者因为缺页中断进行中断进而导致更大的问题。内核堆栈?那样要进行MMU重置和TLB重置,开销相当大。
现代CPU常采用超线程技术和指令重排序技术,所以对于指令,并不是某条指令前的指令全部执行完毕,某条指令后的指令完全执行。所以借此可以划分精确中断和不精确中断。一般来说,精确中断具有以下四个特性:
1. PC(程序计数器)保存在一个已知的地方 2. PC所指向的指令之前的指令全部完成 3. PC所指向的指令之后的指令全部未执行 4. PC所指向的指令的执行状态已知
不满足这些要求的称为不精确中断。拥有不精确中断的计算机通常将大量的指令状态推到堆栈里,因为此时程序计数器没法精确的说明指令的执行情况了,所以只能靠OS利用堆栈中的信息进行推算,这就造成了重启机器极其复杂,致使中断响应缓慢,所以超标量的计算机反而不适合实时操作。
有些计算机是针对某些中断和陷阱是精确的,某些则是不精确中断,比方说,I/O处理时精确中断而除零异常则不是,因为重启进程没意义,除零本来就是错的;还有些计算机可以设置它的某个位,使它对于所有中断都是精确的,只不过对开销很大,因为需要实时记录指令日志并维护寄存器影子副本。
还有些计算机,如x86,具有精确中断以兼容老的软件,这就给芯片架构和工艺带来了复杂度。如果不使用精确中断,那么CPU处理速度会慢,如果用了,OS会慢,所以这是一个值得权衡的问题。
与I/O设计一个关键的概念是设备独立性,即无关于具体的设备,用户都可以通过同样的方式访问到。
与设备独立性密切相关的是统一命名。即一个文件或一个设备的名字应该是一个不依赖于设备的名称。做到所有的文件和设备都采用相同的方式寻址,也就是路径名寻址。
I/O软件的另一个重要问题是错误处理,对于错误的处理,应该尽可能地把错误在底层处理了,尽量不往上抛。
另一个关键问题是同步和异步传输。异步传输在CPU发出I/O请求后便忙于其他的事了,同步传输则会阻塞CPU直到数据可用。
I/O软件还有一个问题就是缓冲。缓冲涉及大量的复制工作,并且经常对I/O性能有重大影响。
最后还有一个概念是共享设备和独占设备的问题,有些设备,比如磁盘,可以被多个用户使用,多个用户同时读取一个文件是没什么问题的,但是对于类似打印机的设备,则只能在同一时刻允许一个用户独占,独占设备引入了各种各样的问题,比方说,死锁。
I/O可以采用根本上不同的三种方式实现:程序控制I/O,中断驱动I/O,使用DMA的I/O。
I/O最简单的形式,是让CPU做全部的工作,CPU负责I/O设备数据写入,调度先后顺序,等待操作完成,读取响应,再写入下一个数据。这一方法称为程序控制I/O。程序控制I/O简单易实现,但是缺点也很明显,就是直到全部I/O完成之前,要占用全部的CPU时间(因为可能发生轮询或忙等待来进行I/O调度操作),这在任务复杂的系统里是不可接受的。
对于某些服务,比方说打印机,一个字符一个字符的打印,那么需要CPU一个字符一个字符的复制到打印机寄存器里面去,而每次等待打印机完成打印并复制下一个字符的过程对CPU来说是很漫长的,所以可以使用中断驱动I/O。
CPU复制第一个字符,然后启用调度程序,运行另一个进程。
每次打印机完成打印,产生一个中断,CPU运行中断处理程序,保存当前进程状态,处理引起中断的程序,对中断控制器应答,调用调度算法,运行新的进程(可能是刚刚那个也可能不是)。
介于每次处理中断,保存进程状态,进行上下文切换的开销比较大,那么可以考虑使用DMA控制的I/O。在这里,DMA作为CPU小助手存在,帮它完成I/O期间的工作,CPU对它进行编程,然后去忙其他的事,DMA负责整个I/O周期并在完成后通知CPU,这就是DMA的I/O。
不过,如果DMA比较慢的话(通常比CPU慢),那么可以考虑使用软件控制I/O或中断驱动I/O。

对于中断,应该尽可能把它隐藏起来,其中最好的方法就是,把启动I/O操作的驱动程序阻塞起来,直到I/O完成产生一个中断。驱动程序可以通过多种方法阻塞自己,比方说对信号量执行down操作。对一个条件变量执行wait操作或在一个消息上执行receive操作。
当中断发生,中断处理程序进行工作以处理中断,然后,把触发中断且被阻塞的驱动程序解除阻塞。
不过实际的处理可能要复杂一些,对OS而言,在中断处理程序结束后,还有更多的工作去完成。这些工作是在硬件中断完成之后必须在软件层面完成的。
1. 保存左右没有被中断硬件保存的寄存器(包括PSW) 2. 为中断服务程序设置上下文,包括TLB,MMU和页表 3. 为中断服务程序设置堆栈 4. 应答中断控制器(表明可以再次接收中断),如果不存在集中的中断控制器,则再次开放中断 5. 将寄存器从他们被保存的地方复制到进程表里 6. 运行中断服务程序,从发出中断的设控的寄存器里提取信息 7. 根据调度程序选择接下来要运行的进程 8. 为下一次要运行的进程设置MMU,TLB等 9. 装入新进程的寄存器,包括PSW 10. 新进程开始运行借此可见,中断处理还是蛮耗费CPU的。
设备驱动程序,用来联系实际的硬件控制器,作为CPU和设控之间的桥梁存在。驱动程序一般作为OS的一部分而被安装在OS内,所以OS开发者一般也会为它们保留接口。
一般操作系统会把驱动程序分为块驱动程序和字符驱动程序,OS会为他们分别预留一些接口供它们实现。对于驱动程序而言,它们必须是可重入的,这代表对于一个驱动程序而言,在第一次调用完成之前第二次被调用。
驱动程序一般不允许系统调用,但它们常常需要与内核的其余部分进行交互。
与设备无关的I/O软件的基本功能是执行那些所有I/O设备都有的功能,并向上暴露给用户层软件一个统一的接口。

驱动程序统一接口的主要目的是简化OS接口的设计,尽量让不同驱动程序可以更简单地装载进OS中。通过对不同的I/O设备驱动程序提供一致的,公共的接口实现。
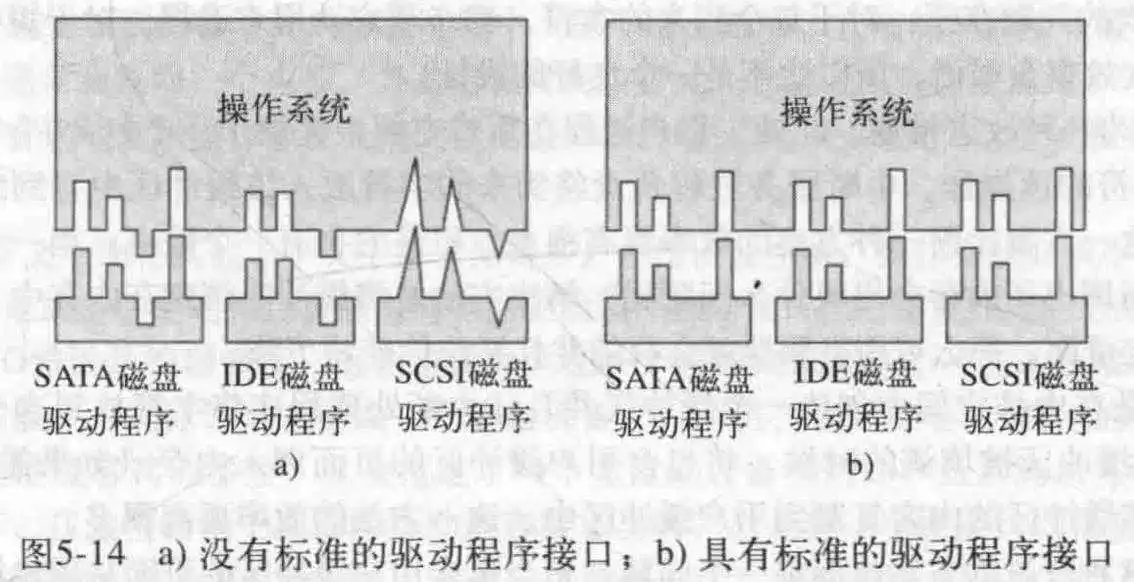
驱动程序一般向OS提供一个函数表指针,表里面包含了此驱动支持的调用。OS可以通过这个指针来实现对某一驱动的某一方法的精确调用。
所有设备都具有主设备号和次设备号,并且所有的驱动程序都是通过使用主设备号来选择驱动程序而得到访问。
缓冲在数据处理上显得格外重要,无论是块设备还是字符设备。如果不使用缓冲,每次数据到来都会调用程序,这无疑是低效的。所以引入缓冲区这个概念,啥意思呢?就是每次把到来的数据提前的缓冲器起来。待到需要的时候再给用户,但是这就引发了几个问题。
如果把缓冲区放在用户进程,那么在处理时缓冲区被分页而调出了内存怎么办?锁定或许可以,但是进程多了之后就会导致内存池减少,系统性能降低。
再在内核建立一个缓冲区,每次满了后复制到用户?如果正在调入的过程,新的数据到达,怎么保存呢?那就再建立一个缓冲区,此时新的缓冲区接收,旧的复制到用户,而这,就是双缓冲。更进一步,可以做一个循环缓冲,让两个缓冲区交替接收,送回数据。
缓冲在输出上也很有用,对于输出,可以把要输出的内容复制到内核,交由内核处理,用户进程转而去忙其他的事。
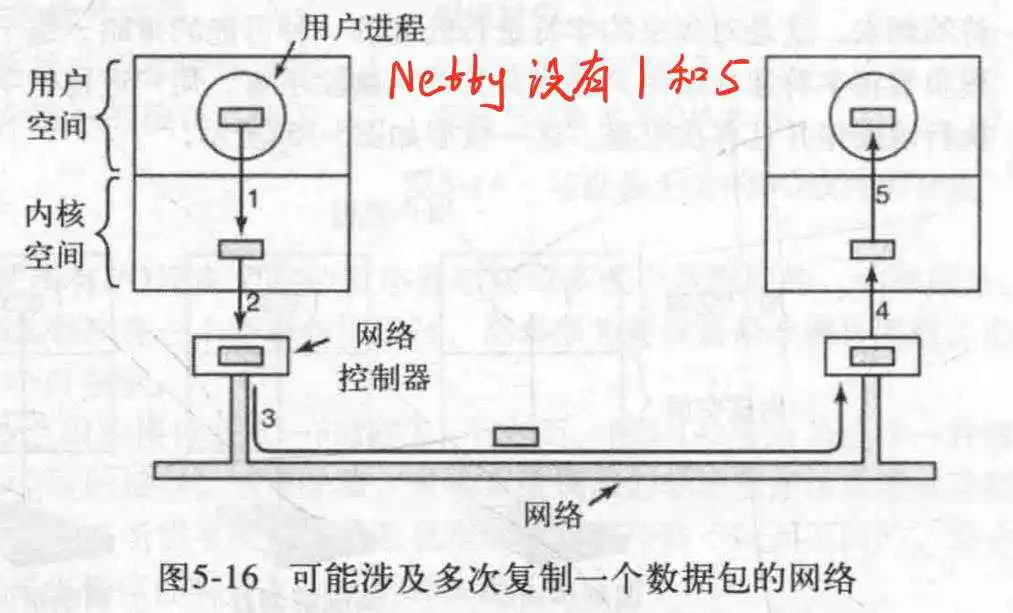
但是过多的缓冲不一定是有益的,比方说一个典型的网络I/O:
对于错误报告,一般有两种,编程错误和实际的I/O错误。前者比如读打印机,写键盘等不可能的操作,仅需向调用者返回错误代码即可,后者可能需要驱动程序来决定应该做什么。
对于设备来说,还可以为他们设计一个专用的分配与释放程序用来管理I/O设备资源。
对于磁盘来说,不同的磁盘可能有不同的扇区大小,这一点应该由与设备无关的软件完成对OS的隐藏,以此来提供一个大小固定的块。
对于I/O软件,有一些是存在于用户空间供用户调用的,比方说C语言的printf和scanf函数,就是典型的例子。当然,这属于用户层面的库过程的调用,并不是所有的都是这么实现的,可以假脱机机制。比方说打印机。但是这时就诞生了一个问题,那就是可能会发生某个进程长时间占用假脱机的情况。所以可以为它设立一个守护线程和假脱机目录,每次需要打印的文件放到假脱机目录就好,然后由守护进程负责处理,这里,守护进程是唯一可以访问假脱机的进程,这样就避免了刚刚的问题。
来看一个总结吧!

磁盘是最常用的存储介质,即使是在SSD大行其道的今天依旧如此,机械硬盘有着不可替代的地位。
来看一下磁盘结构:
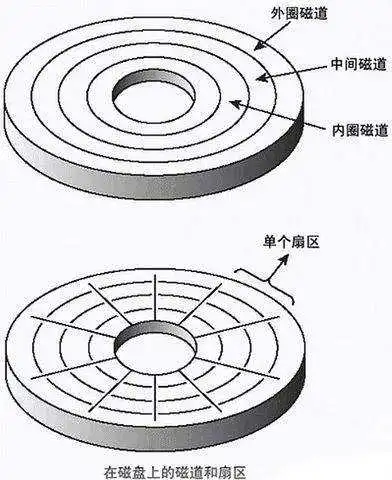
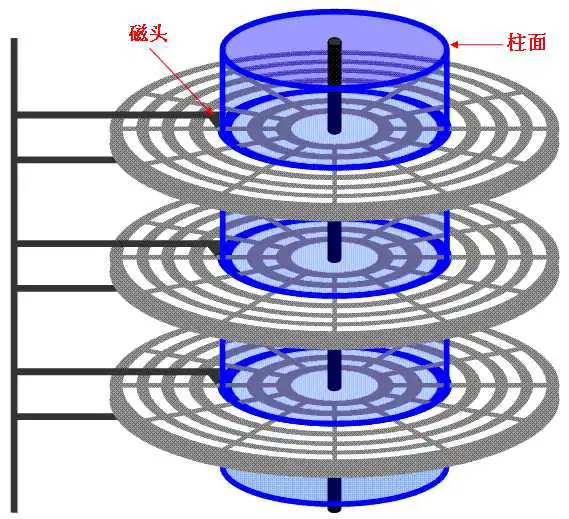
柱面是抽象出来的概念,是一个个同心同半径的磁道组成的。每个磁盘有上下两个面,从上向下依次为0号-n号磁盘面。
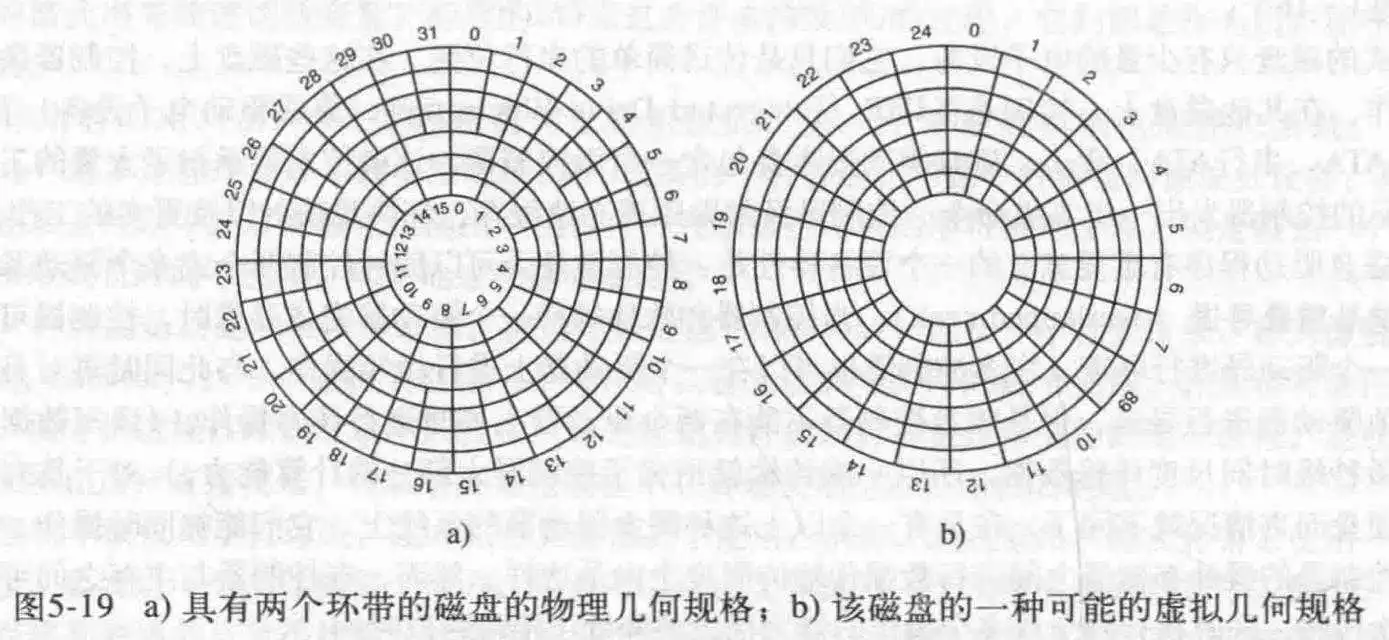
当代磁盘扇区并不同半径的,而是没向外一个磁道,大概增加4%的扇区,这是为了充分利用空间。比如下图的第一个。
磁盘控制器在今天来看,更像是一个微处理器,它可以接受一组高级指令,可以对数据缓存,坏块重映射等工作。对于磁盘驱动程序有一个很有意义的指标就是,磁盘控制器能否一次控制两个或多个驱动器(马达)进行寻道。这被称为重叠寻道。一个控制器可以在让某个驱动器读取数据的时候,命令另一个驱动器去寻道。不过,一般而言一个控制器只会和主存有一次传输,因为多次传输会降低平均速率。
RAID
在磁盘能使用前,必须经过由软件完成的低级格式化。
每一个扇区的组成如下所示。
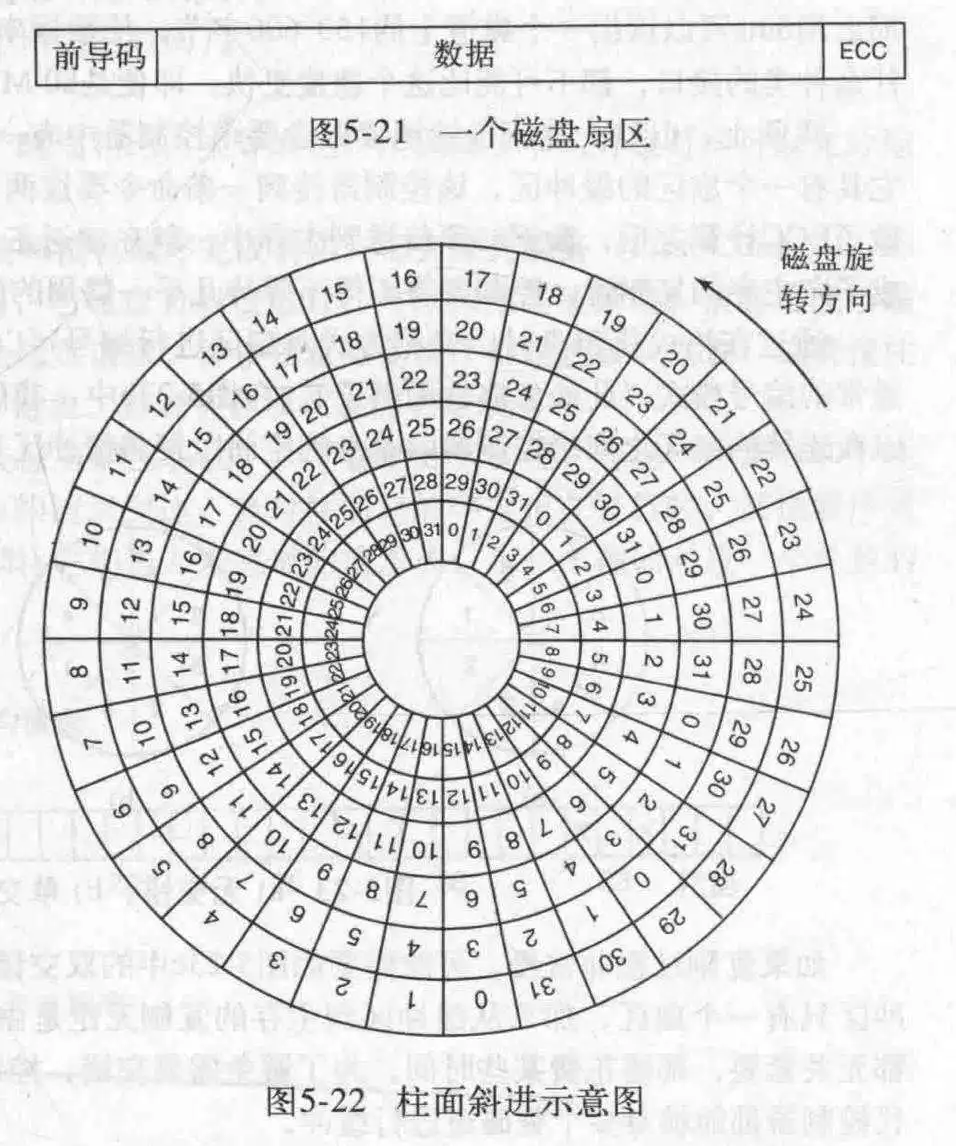
其中,前导码以一定的位模式开始,位模式使硬件得以识别扇区的开始,前导码还包含柱面与扇区号,以及某些其他信息。数据部分的大小由格式化程序决定,一般为512字节。ECC(错误校正码)域包含冗余信息,用来恢复读错误,一般的硬盘都有备用扇区,用来重映射坏扇区。
当然,在低级初始化时,可能会进行柱面斜进,因为每次进行连续读取时,当前磁道读完了,可能需要读取下一个磁道,如果磁道起始终止位置一样的话,那么大概率在把磁头移过去时,第0号扇区已经过去了,因为移动磁头需要时间。所以可以把下一个磁道的0号扇区后移几个,这就叫做柱面斜进。
当然了,也存在磁头斜进,不过他的时间远小于一个柱面斜进的时间。
当控制器读取到扇区上的数据时,进行ECC校检之后,会把数据写回到主存,这个过程需要时间,所以可能下一个扇区就在磁头下溜走了,所以可以错开一个存放,给控制器一点时间,或者错开两个,前者是单交错,后者是双交错。
低级格式完成后,要对磁盘进行分区,逻辑上,每个分区就是一个独立的磁盘。一般来说,0号分区是主引导记录,现代操作系统也支持GPT,即GUID分区表,以实现更大的分区。
分区完毕后,对每个分区进行高级格式化。这一操作会设置引导块,空闲分区管理(空闲列表或位图),根目录,和一个空的文件系统。还要把一个代码设置在分区表的对应项里,用以表明在此分区中使用的是哪个文件系统。
当电源打开,BIOS运行,读入主引导记录,并进行跳转,然后这一引导程序试图找到活动的分区,接着找到存放操作系统内核的文件系统,载入OS。
对于一个磁盘,读写一个块需要的时间主要由以下因素决定:
1. 寻道时间(将磁盘臂移动到适当的柱面上所需要的时间) 2. 旋转延迟(等到适当的扇区旋转到磁头下所需的时间) 3. 实际数据传输时间前两个是影响时间的主要因素。
来看几个磁盘臂调度算法是怎么完成减少时间这一目标的。
先来先服务算法(FCFS),组织一个链表,把所有请求按照到达顺序组织起来,依次处理,但是时间消耗比较严重。
最短寻道优先算法(SSF),每次处理与当前磁头最近的请求,这一算法会导致请求分配不公平,边缘的请求被执行的机会会少很多。
电梯算法,此算法维护一个方向位,每次处理完一个请求,检查方向位是UP还是DOWN,如果是UP,则上移处理更高位置的请求,如果没有更高位置的请求,则方向位取反,然后重复刚刚的操作。如果没有请求,就停在此处。
略微改进的算法,即方向总是按照相同的方向进行扫描。当处理完最高编号柱面上的未完成的请求后,磁盘臂移动到具有未完成的请求的最低编号的柱面,然后继续沿向上的方向移动。这样就好像最低编号是最高编号的临近位一样。把整个编号看成了环状的。
当然,实际使用上,如果当前柱面还有其他的请求,就直接处理了,因为它们仅仅是磁道不同而已,此时不需要寻道时间也不需要旋转延迟(因为不是当前磁头,是同一柱面的另一个磁道上的磁头)。
不过了,某些磁盘旋转延迟更大的话,那就要重新设计算法了,比方说未完成的请求按照扇区号排序(因为寻道很快,所以可以很快切换到下一个磁道,那么这时按顺序组织扇区就显得尤为重要)。
对于磁盘来说,一般都有一个高速缓冲区,对于读,除了读取需要的内容,还会把当前磁道剩余的读出来以备使用;写入的话,把数据放在高速缓冲区,一次性写入更快一些。
当一个控制器上有多个驱动器时,操作系统会为每个驱动器维护一张表。一旦某个驱动器空闲了,就把它移动到准备请求的柱面下;当前传输结束时,会检查是否有驱动器位于正确的柱面下,如果有则开始下一次传输,如果没有,驱动程序则在刚刚完成传输的驱动器上发出一个新的寻道指令并等待,直到下一次中断,检查哪个磁臂先到了目标位置。
磁盘可能出现坏扇区的情况,那么需要进行ECC修复,这是在错误仅有几位的情况下,如果扇区无法通过校检修复,就只能使用备用扇区以及重映射了。
一般有两个方法处理坏块,在控制器中对他们进行处理或者在OS中对他们进行处理。前一个方法是使用备用扇区进行替代,这是在出厂前进行的处理,有两种方法实现这个:
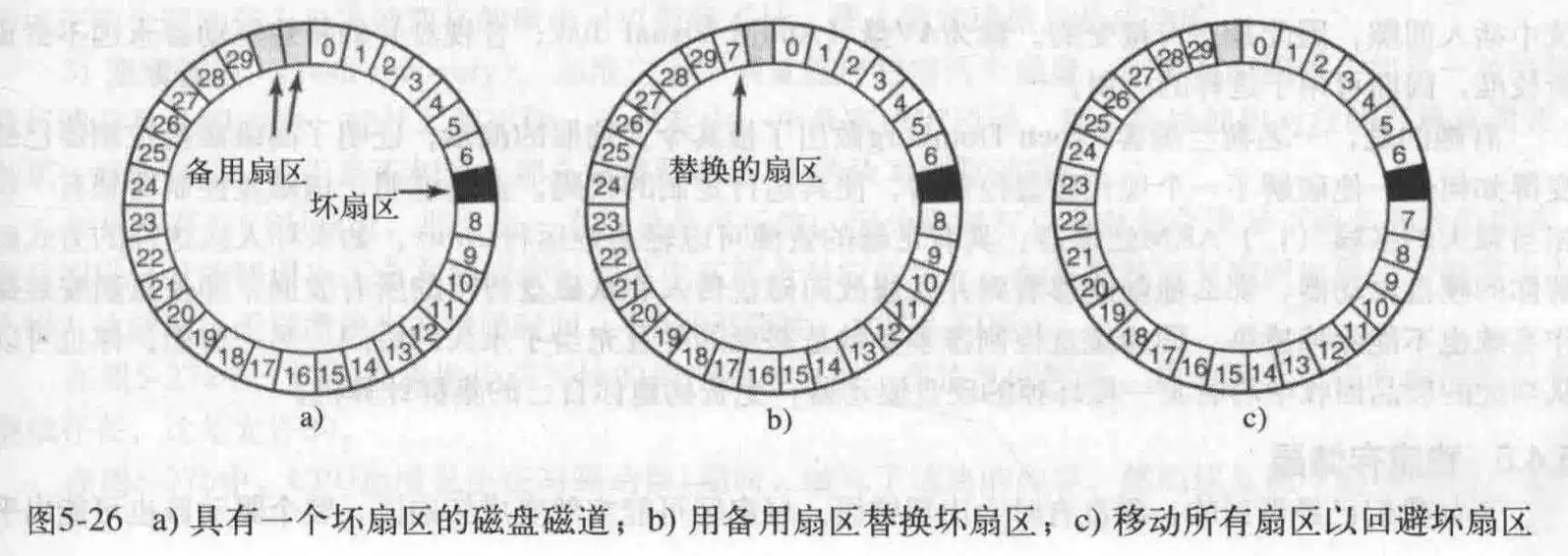
对于第一种修复方法,需要维护一张表格,记录坏块的替换块是谁,每个磁道一张表;对于第二种方法,则是通过设置前导码实现,不过这种方法需要坏块后面全部的前导码,好处就是性能好一些,不需要旋转一圈来找到坏块的备用块。
如果已经开始运行了,发生了坏块,那么使用第一种方法更好一些,因为第二种方法还要进行数据的复制,可能比较耗时,引起系统卡顿。
如果是操作系统做处理,就得获得一个坏扇区表,比方说通过读取磁道表,或者自己遍历获取全部块的状态,然后他们写到一个隐藏文件里去。并且保证坏块不能出现在任何文件,空闲表里。对于备份,实用软件如果是对文件备份,那么应该由OS隐藏坏块以避免被读到,如果是一个扇区一个扇区地备份,那只能期待写这个软件的程序员足够聪明了——在连续10次失败后放弃备份这个扇区。
时钟在一个计算机系统里很重要。
一般时钟使用晶体振荡器实现,加以一定的电压,石英晶体就能按一定的频率震动,产生周期性信号,把这个信号乘一个整数,就可以得到一个很大的频率。它给计算机的各个电路提供一个同步信号,这个信号被送到计数器,使其递减为0,引发一次时钟中断。
可编程时钟有几种编程模式。在一次完成模式下,当时钟启动时,他把存储在寄存器的值复制带计数器,每一次石英晶体信号都使计数器减1,当递减为零,产生一个中断,停止工作,直到软件显式地启动它。在方波模式下,当计数器变为0时,寄存器(所以这个寄存器可以用来设置中断周期)的值自动复制到计数器,整个过程无限期再次重复下去,这些周期性的中断称为时钟滴答。
可编程时钟的优点就是,中断频率可以由软件设置,一个可编程时钟芯片通常包含两个或三个独立的可编程时钟,并且还包含其他选项,比方说,屏蔽中断,用正计时代替倒计时。
为了防止电源关闭导致计算机丢失当前时间,主板上通常有一个低功耗时钟系统,每次系统启动时,会读取其时间,然后转换成自某个标准时间开始后的时钟滴答数。(Unix是1970/1/1/12:00 UTC时间,Win是1980/1/1)当然也可以联网获取,或者手动设置。
所以时钟啊,除了产生时钟中断,还用来计时。
时钟硬件所做的全部工作是根据已知的时间间隔产生中断。其他所有的全部工作都由软件——时钟驱动程序完成。一般而言,包含以下工作:
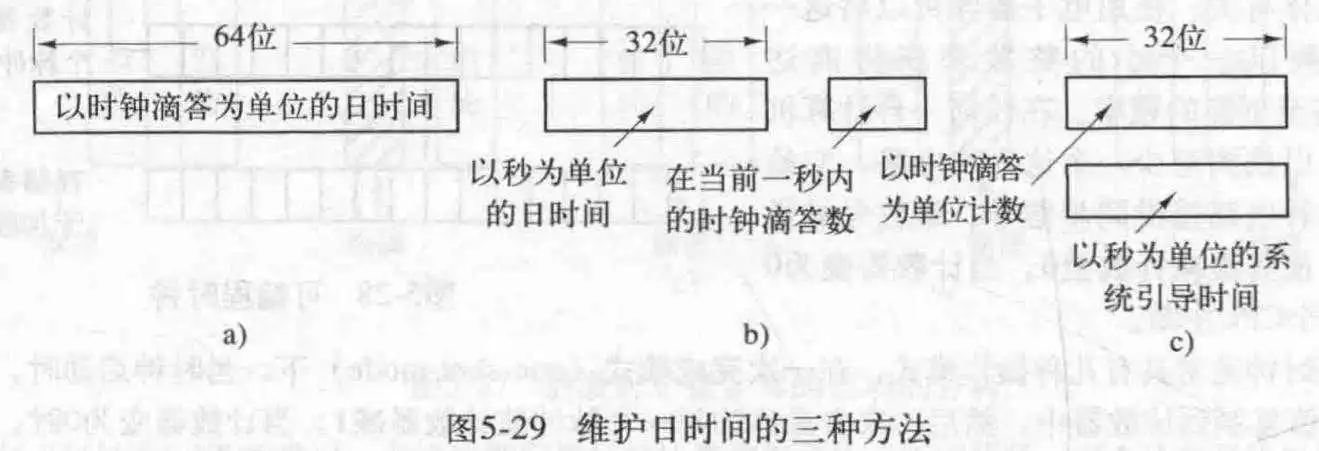
1. 维护实际时间(几点了几点了的意思) 2. 防止进程超时运行 3. 对CPU的使用情况记账 4. 处理用户进程提出的alarm系统调用 5. 为系统本身的各部分提供监视定时器 6. 完成概要剖析,监视和统计信息收集维护实际时间有三种方法,一种是用64为计数器累计时钟滴答数,第二种是以秒为单位,每次时钟滴答了一秒的长度就加1,最后一种记录开机时备份时钟的滴答数,并从此时开始累加,需要时间时,把备份时间加上累加时间就可以了。
时钟的第二个功能是防止进程超时运行,每次调度一个进程时,就把计数器的值初始化为以时钟滴答为单位的该进程的时间片的取值(CPU时间片(假设为ms)/时钟滴答间隔(单位也是ms)=此计数器的取值),每次滴答将此计数器减一,为0时执行调度程序。
对CPU有两种方式进行记账,精确的方法是,每次进程启动时,就启动一个辅助定时器,开始计时,每次中断保存此辅助计数器,然后中断结束继续;最后读出此辅助计数器的值即可。另一个方法可能没那么精确,全局变量保存一个指向进程表的指针,每次时钟滴答,通过指针把该进程的计数器加1,相当于此进程在为它的运行付费。但是这里有一个不精确的地方就是,如果发生中断,那么即使这个进程没用CPU,他还是缴费了?!但是吧,精确记账代价太高了,一般都是第二种方法。
时钟的另一个用法是,接收进程请求然后再一定时间间隔后向它报警,可能是信号,中断,消息或者类似的东西。
如果时钟驱动程序有足够多的时钟,他就可以为每个请求设置一个时钟,如果不是,就必须用物理时钟来模拟多个时钟。比方说,维护一张表,把所有定时器的信号时刻计入表中,每次日时间更新时,驱动程序进行检查以了解最近的信号是否已经发生。如果是的话,则在表中搜索下一个要发生的信号的时刻。如果有多个信号,那么用一个链表把他们按时间顺序链接起来,每一次滴答时,下一个信号减1,当他变为0时,就引发与链表中第一个表项相对应的信号,然后删除此表项。
监视定时器可以被用来对系统死机进行复位,系统运行时,它会定期的复位定时器,所以定时器不会过期。所以一旦定时器过期,则证明系统很久没有运行了,这是可以考虑进行全系统复位。
最后,时钟机制可以帮助统计某一进程的运行情况,通过把该进程囊括的程序计数器的区间加1(起始地址,终止地址+1)。然后呈现出来,这是对于程序的剖析。
一般而言,有两种方法管理I/O,一种是中断,一种是轮询,中断延迟低,响应及时(几乎是立即响应的),但是中断开销大;轮询需要忙等待,平均等待时间是轮询时间的一半,也不是很优秀。所以引入了软定时器这个概念。
软定时器避免了中断。当内核运行结束准备返回到用户态时,检查实时时钟,以了解软定时器是否到期,如果是,就执行被调度的事件。,这样就避免了内核态用户态切换。工作完成,复位软定时器,通过把当前时间加上时间间隔即可,以便再次闹响。
在这里,软定时器起到了实际时钟中断的作用——使CPU去执行其他进程,所以时间间隔的设置就显得很重要,因为软定时器随着其他进入内核的原因而改变频率,这些原因包括系统调用,TLB未命中,页面故障,I/O中断,CPU变成空闲等,所以一般设置2微秒(us)就可以。其实也可以这么理解,就是软定时器想运行,必须在它时间到了的时候(可超时),内核有程序在运行且已经运行完毕,此时才可以运行软定时器设置的进程,所以它会受进入内核的程序的影响。
多处理机系统的目的在于集中不同CPU,主机,甚至不同系统的个人PC来实现统一的工作。目前有三个可用的模型,用于实现协作式计算类型。分别是多处理机,多计算机和分布式系统。
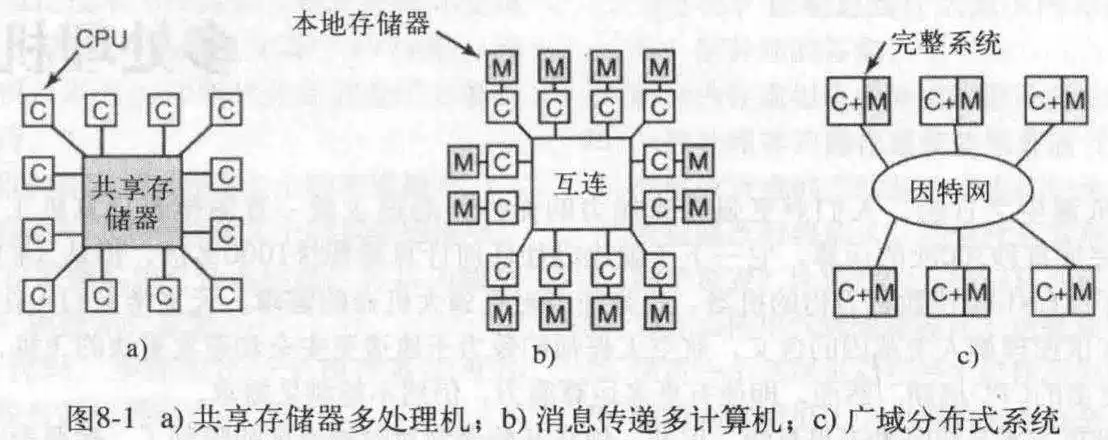
这一模型有一个很常见的使用场景,就是多核CPU,如果是这样的话那么这里的共享存储器就是L3缓存,这么说就清晰了,所以这里的处理机更像是一个CPU核心或一个CPU(单核的)。
这个更多是在一个房间里,用专用高速网络,连接多个独立的计算机,但是这些计算机没有键盘显示器显卡等,仅把它们串在一起做协作运算。
这个旨在通过普通网络连接全球的计算机,这些计算机可能完全不同,创建一个中间件统一它们做协作运算。
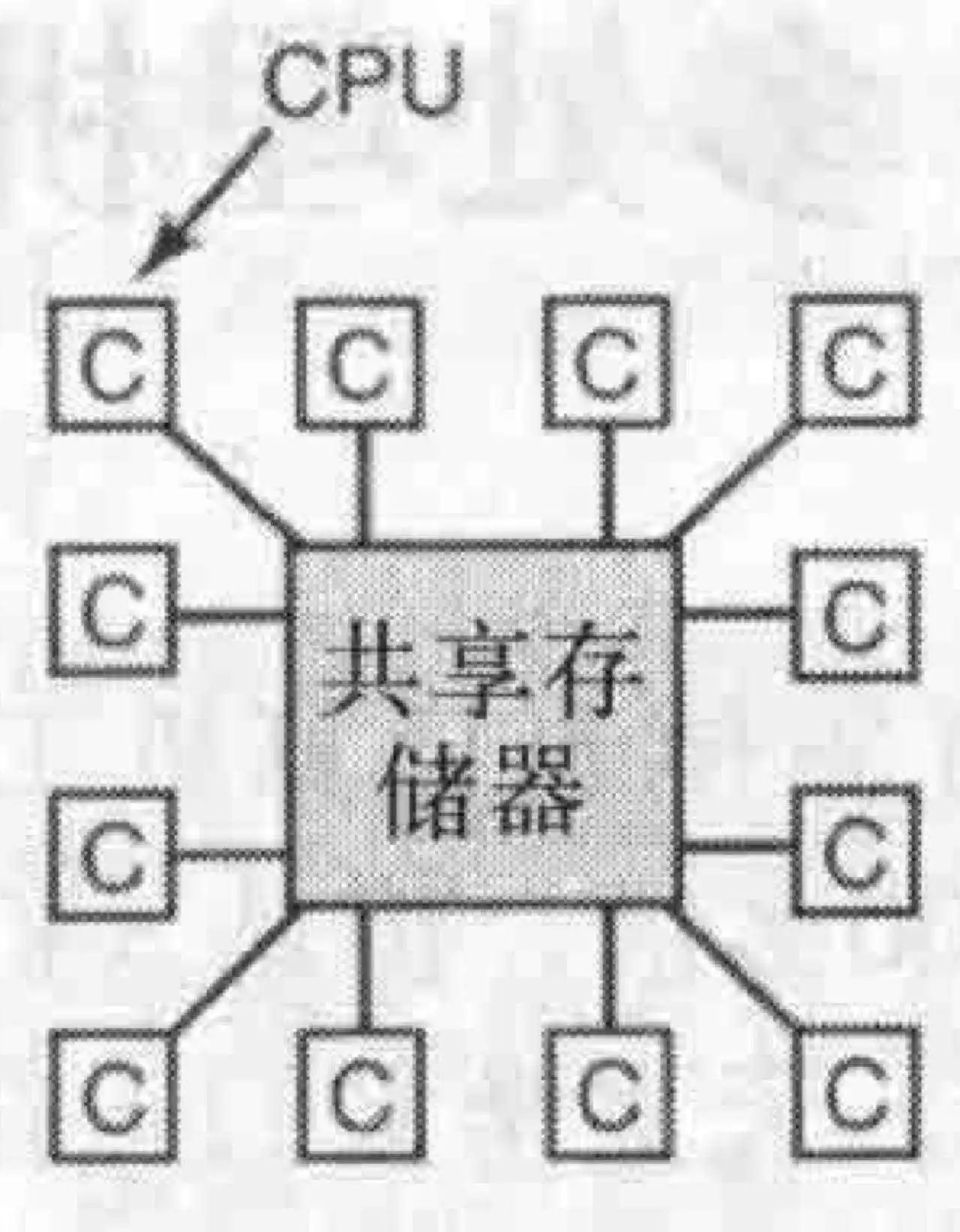
这个系统唯一特别的性质是,CPU对共享存储器写入某个值,然后读回来另一个值,因为可能另一个CPU修改了它。这种性质构成了处理器间通信的基础:一个CPU向存储器写数据而另一个从中读取。
访问存储器。如果对于CPU来说,读出每个存储器的速度一样快,那就是UMA(统一存储器访问)。否则就是NUMA(非一致存储器访问)。这些CPU共享同一个地址空间(仅对于公共部分),这和是UMA还是NUMA无关。
- 基于总线的UMA多处理机体系结构
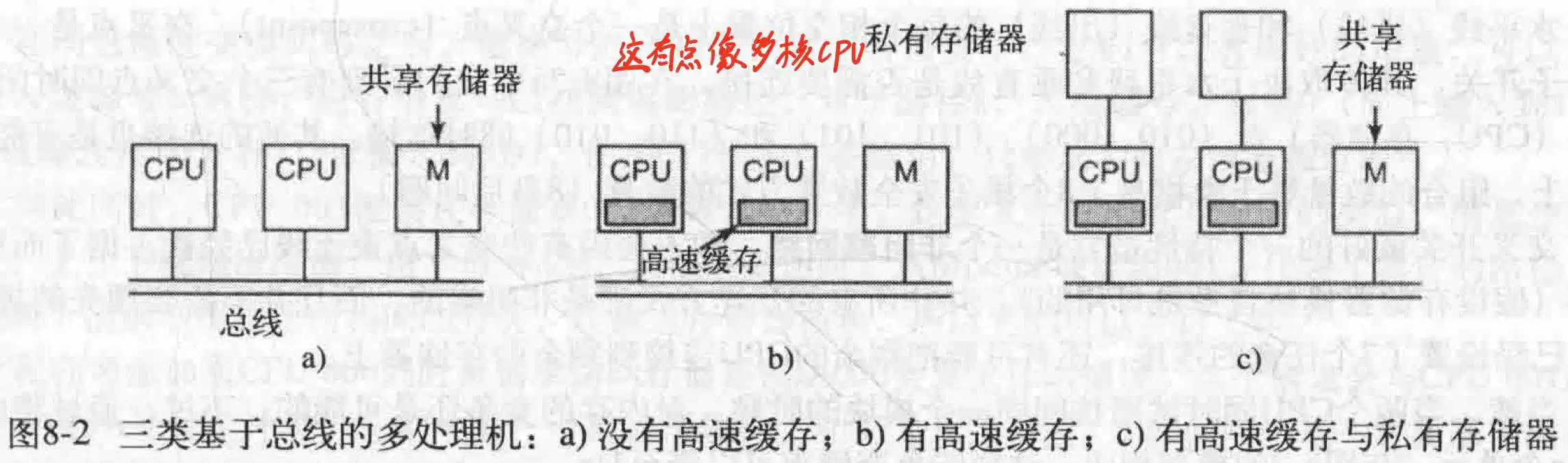
对于基于此模式的访问,CPU每次检查总线是否忙碌,如果不是,则把所需要的字的地址放在总线上,发出信号,等到总线给予回复;如果总现在忙,就等待。如图a所示,但是缺点是当CPU很多时(比如AMD 3990X)大多数的CPU就在空闲等待。
解决方案是为每个CPU添加一个高速缓存(L1),如图b,这样的话许多读操作就可以通过每个CPU的高速缓存来实现。为了更好的性能,每次读取总线的某个字时,它所在的整个块都被引入到高速缓存里。
每个高速缓存块都被标记为只读,或者读写(此时此高速缓存行仅为当前CPU独有)。那么怎么处理对于存在于多个CPU的高速缓存行呢?那就是高速缓存一致性协议,也是Intel在自家处理器使用的:每当一个CPU试图写一个同样存在于其他CPU高速缓存的某一块时,总线检测到写,通知其他CPU,让所有拥有此块但未修改的(也就是“干净”的)CPU丢弃它;让所有已修改的CPU把它写回到存储器(实现一致性),并让写者之后去存储器拿到这个块,那么此时写者拿到了最新的此块,而其他CPU也不会拿到过期的块。
当然了,还有一种优化方案,此时每个CPU除了高速缓存外,还有一个小的私有存储区,用专用高速总线连接,如图c,用来放非共享数据,比如程序代码,字符串,常量,其他只读数据,栈和局部变量,而共享存储器只用来放共享变量。
- 使用交叉开关的UMA多处理机
对于使用总线的方式,即使总线和高速缓冲区再优秀,还是把CPU的数量限制在16-32。所以我们需要一种新的方法,交叉开关很好地满足了这一需求。
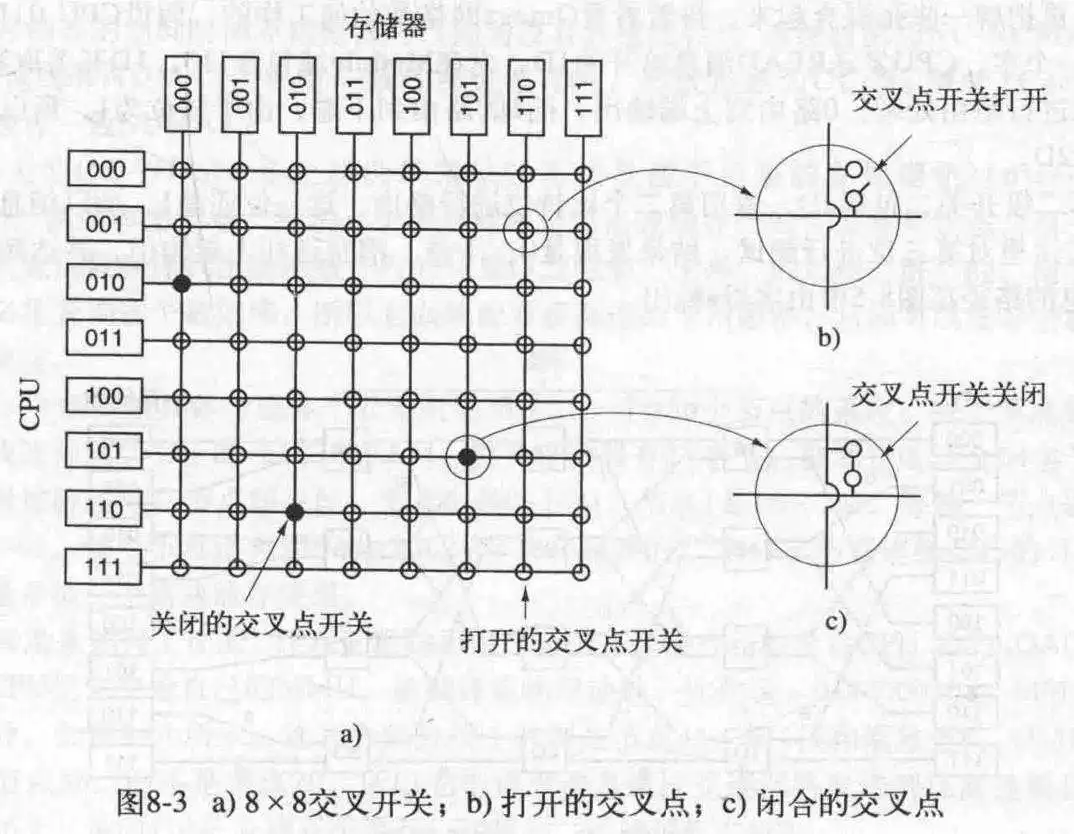
每一个CPU连接一个存储器,并且可以切换到另一个存储器,对于n*n的排列,仅需简单的设置某一横向开关和另一竖向开关的打开与关闭就能实现任意CPU与任意存储器连接,这就和8皇后问题一样。
交叉开关的优点是它是非阻塞的,可以不受某一已存在的连接的限制。而缺点是开关节点数随CPU数呈平方级增长。这对于中等级别是可以接受的,对于更大规模的系统来说是不可接受的。
- 使用多级交换网络的UMA多处理机

对于一个交换开关,它可以把输入重新从任意一个输出输出来。比如A->X或A->Y;B->X或B->Y。而每次CPU传输的是一个消息块,它包含四个属性,module指出了目标存储器,address指明在模块中的地址,opcode表明是读还是写,最后可选的value包含实际操作的值。交换开关检查model来确认是发送给X还是发送给Y。
这种2*2的交换开关可用于构建大型网络。其中一种就是简单经济的omega网络,如下所示,对于n个CPU和n个存储器,需要log2(n)级,每级n/2个开关,总数为(n/2)log2(n)个开关,当n很大时,这比交叉开关好一些。
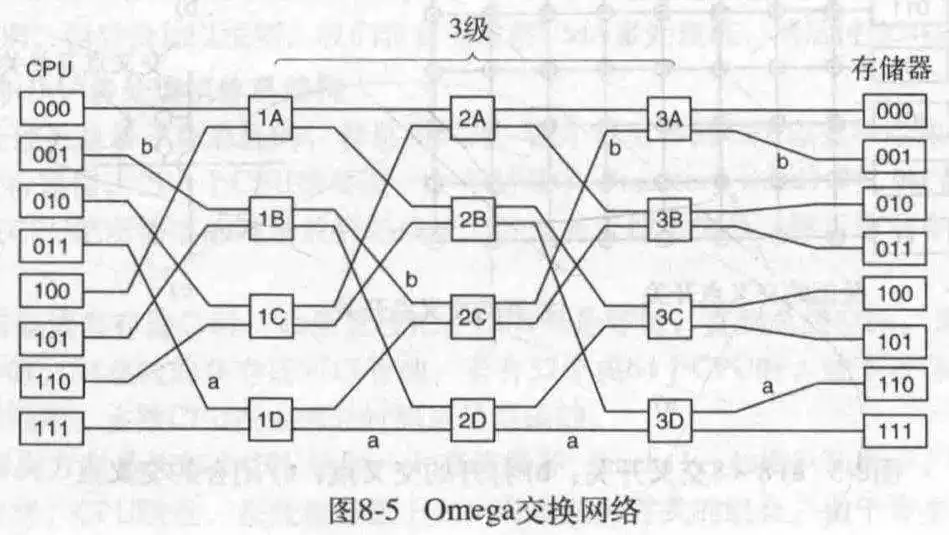
在消息经过交换网络后,模块号左边的位就不需要了,可以用来记录入线编号,这样应答消息可以找到回去的路。
omega网络是一种阻塞网络,所以对于同时访问同一个存储器的CPU而言,就会有一个需要等待,冲突可以发生在线上,也可以发生在存储器里,或者发生在开关中。
对于连续地字被放在不同的模块里称为交叉存储系统,这样可以把并行效率最大化,因为一般对于存储器的引用是连续编址的,或者设计多条从CPU到存储器的线路,使得非阻塞成为可能。
- NUMA多处理机
因为交叉开关和交换网络多处理机比较昂贵,所以规模还是不够大,在此,引入了NUMA这种机制。它有一个典型的特征就是,访问本地存储器会比访问远程存储器块(废话)。每个CPU都有自己的存储器,除了自己访问,也可供其他CPU访问。所有NUMA机器都具有以下关键特性:
1. 具有对所有CPU都可见的单个地址空间。 2. 通过LOAD和STORE指令访问远程存储器。 3. 访问远程存储器慢于访问本地存储器。对远程存储器的访问时间不被隐藏时(因为没有高速缓存),称为NC-NUMA;有一致性高速缓存时,系统成为CC-NUMA。
目前构造CC-NUMA最常见的方式是基于目录的多处理机,通过一个数据库来记录高速缓存行的位置及其状态。
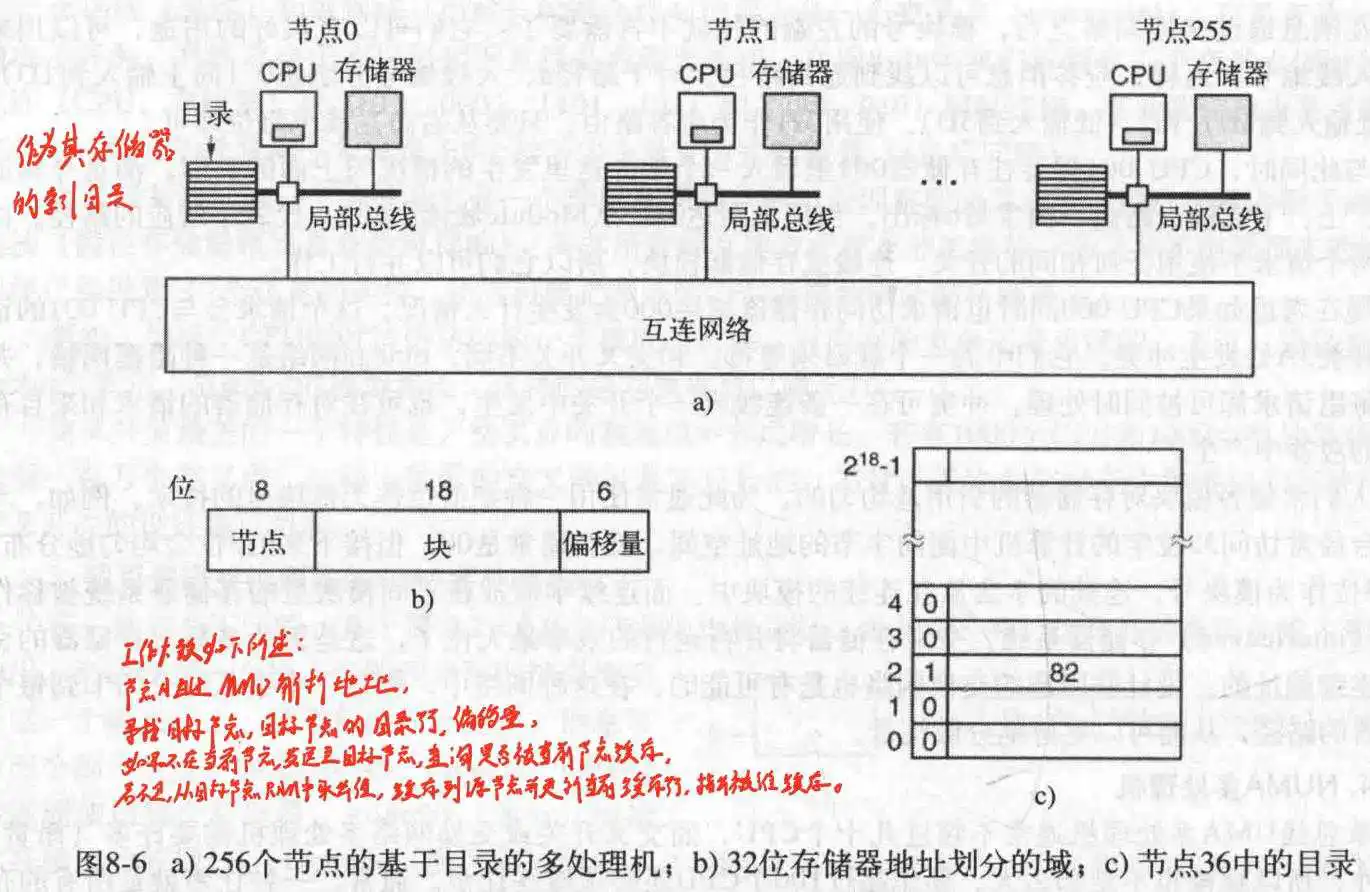
来看一个可能的例子,一个256节点的系统,每个节点包含一个CPU和RAM,每个RAM有16MB,整个系统存储器加一块有4GB(2^32),被划分成2^26个64字节大小的高速缓存行。全存储器被静态地在节点间分配,每个节点16MB,就是每个节点的RAM,节点0是0-16M,节点1是16M-32M,以此类推。节点通过互联网络彼此连接。每个节点还有记录16MB存储器的2^18个64字节的目录项。也就是每个节点都有一个目录,且目录项个数和高速缓存行个数一致,因为每行都要一个目录项来记录,在这里是2^18。
假设CPU20发处一条LOAD指令,然后CPU20把此指令交给自己的MMU,MMU翻译得到b形式的地址,假设它发现这个字在节点36,那么它就把请求消息通过互联网络发送到该高速缓存行的主节点36上,并询问数据库(目录)行4是否缓存,如果是,高速缓存在哪?假设此时是c所示的情况。请求到达36后,检索目录硬件,每一个目录项都是一个高速缓存行。此时看到行4未被缓存,于是从节点36的RAM中取出第4行,送回到节点20并更新目录项4,指出其目前被缓存在节点20。
假设此时CPU20又有一个请求访问节点36的第2行,得到其目前在82行,此时硬件更新目录项2为20,发送消息给82让它把该行发送给20并使自己的缓存无效。
这个形象化后就像每次引用后都会把引用节点的值带跑了,然后存在自己这里,下次再被其他节点引用然后转移到那里去,高速缓存行好像跑来跑去似的。
对于STORE的话,MMU解析正确的地址,把数据送到目标节点,目标节点在自己的RAM里存储,并更新对应的目录项为未缓存,这样可以保证再次引用得到的是新的值。
- 多和芯片
当某个CPU修改了内存中的某个字,特殊的硬件电路会使其他CPU的高速缓存中的该字原子性地删除来实现一致性,这个过程称为窥探。
- 众核芯片
就是CPU核心数很多,比如AMD 3990X 64核128线程。
- 异构多核
在一块芯片上封装了不同类型的处理器的系统称为异构多核处理器。
- 在多核上编程
这比较难...确实如此。
- 每个CPU都有自己的OS
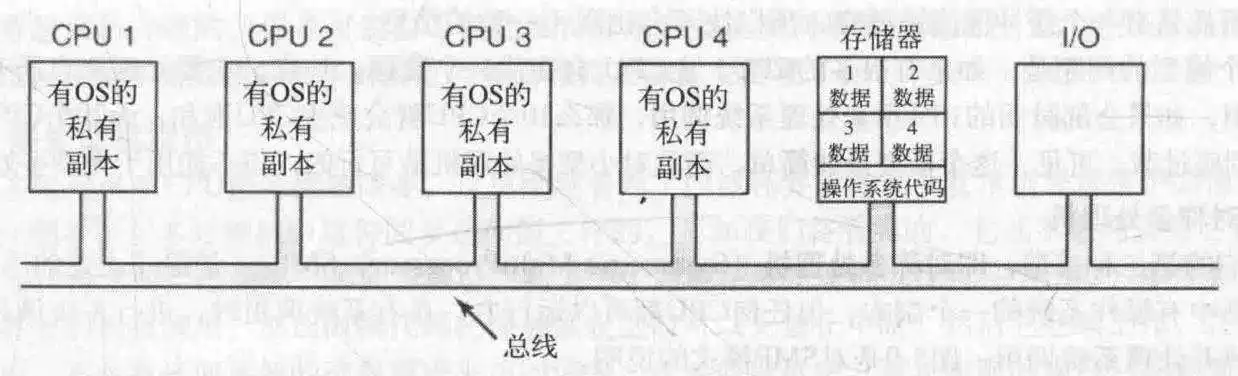
这么做允许多个CPU共享操作系统代码,而且只需要提供数据的私有副本,由于每个CPU共享的是OS的不可写部分,再加上每个CPU都有自己的OS数据副本,所以看起来就是每个CPU一个OS。
这一机制相比较于多计算机系统,它允许多个机器共享一套磁盘和其他I/O设备。
该设计固然不错,但是它存在四个潜在的问题:
第一是,在一个进程进行系统调用时,该系统调用是在本机的CPU上进行处理的。
二是,这里没有进程共享,每个进程都在自己的OS和CPU上,因此可能发生某一CPU吃满而另一空闲。
第三,无法共享内存页面,所以可能会出现某个CPU不停地调整页面而另一个在旁边守着空内存看戏地情况。
第四个,也是最坏的情况,每个系统进行自己的磁盘缓冲区维护工作,然后他们分别写入磁盘,嚯!不一致现象就这么出现了。
综上所述,这种模型实际上很少使用。
- 主从多处理机
在这里,有一个主CPU,所有的系统调用都定位到主CPU上,而且进程,OS数据表等由一个CPU控制,就不会出现不一致以及同步竞争问题,当某个CPU空闲,就向主CPU申请一个进程运行。但是,这种模型加剧了主CPU的负担。主CPU逐渐成为性能瓶颈。所以也不怎么用。
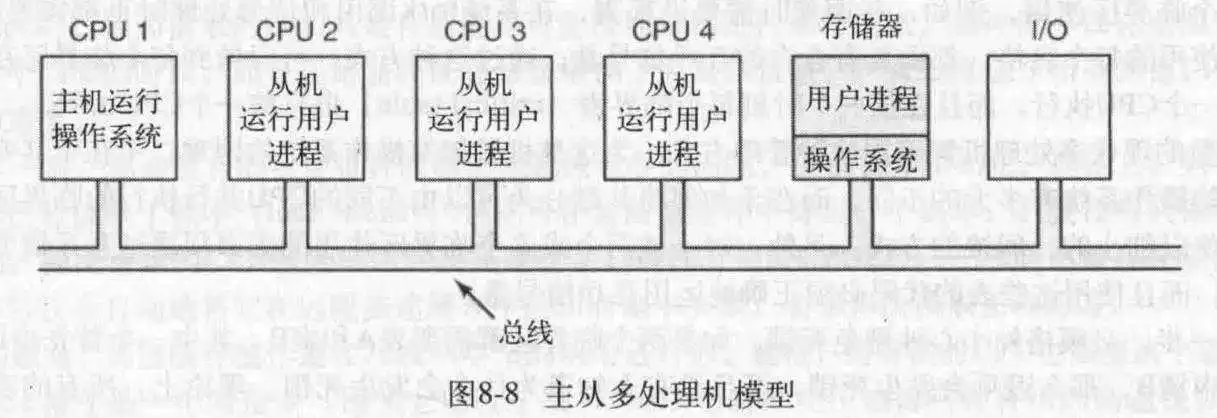
- 对称多处理机
对称多处理机消除了主从机的不对称性。
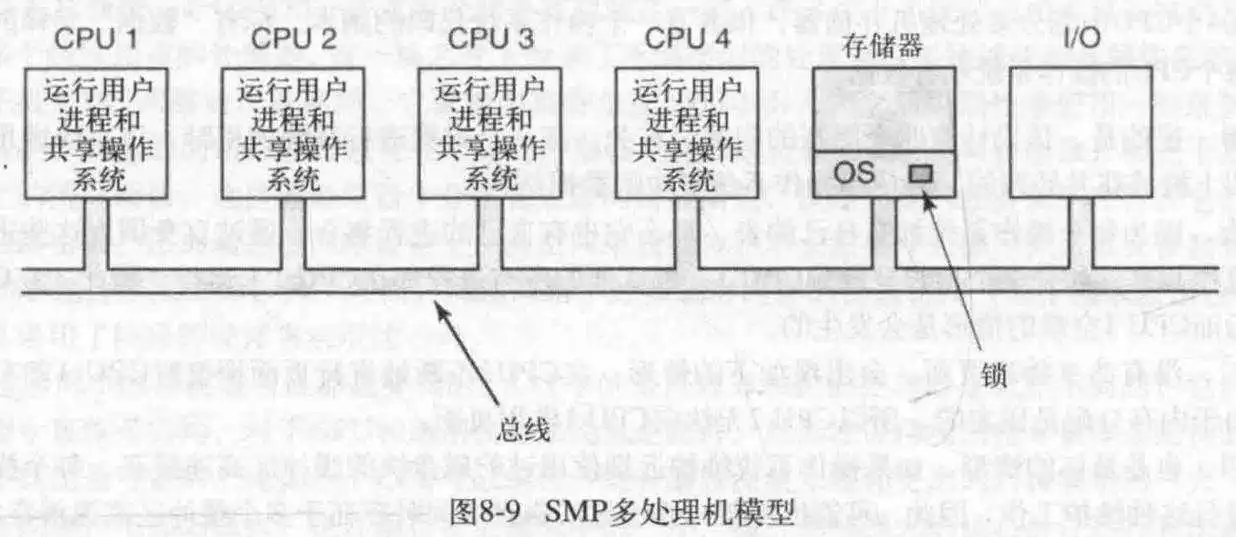
对于这种设计,所有CPU共享OS,以及OS里面的进程。然后把整个OS当成一个临界区,进行加锁,操作,释放锁。这叫大内核锁(BKL)。但是吧,如果每次在OS操作会花费很久的话,这可能造成后面CPU的长队列等待,所以也不是什么好想法,遂直接把OS切分成不同的临界区。这样的话就可以做到进行不同任务的CPU并行运行,当然也可以做到某些数据被多CPU共享(如果共享它们不会造成麻烦的话),不过记录临界区状态的临界表只能被一个CPU访问。
现在大多数多处理机都采用这种方式,这就使得OS编写更加困难,因为此时要仔细考量临界区分割问题,以及死锁等复杂问题。
在多处理机中,禁用中断仅仅作用于当前CPU,而不会影响其他CPU的行为。因此,必须采用一种合适的互斥信号量协议,使所有的CPU可以按照此协议互斥地工作。
所有互斥访问的核心都是一条特殊指令,该指令允许检测一个存储器字并以一种不可见的方式写入它。
为了实现互斥访问,可以使用TSL指令。TSL指令必须首先锁住总线,然后进行对存储器的读写,最后释放总线。对总线加锁的典型做法是,先使用通常的总线协议请求总线,并申明(assert)已拥有某些特定的总线线路,在这两个操作完成,只要保持这条总线的拥有权,其他CPU就没法访问,这样就完成了对总线加锁的过程。
不过,TSL是自旋锁(就是在得不到锁时会不停地循环获取锁),这就浪费了CPU以及加剧了总线的负担(因为它一直问总线:我能加锁了吗?能了吗?能吗?...),进而影响其他CPU地工作(因为总线带宽被拉低了)。
或许高速缓存可以解决这一问题,但事实并非如此。某个请求锁的CPU试图获取锁,读到了lock的值,如果此时锁在别的CPU手上,那么这个CPU把lock放入自己的高速缓存,然后不再请求,每次循环自己的高速缓存(或不循环)就可以了,直到那个有锁的CPU释放锁。怎么释放呢?它把lock对应的高速缓存设为0并释放锁,此时由于高速缓存一致性协议的存在,所有拥有lock高速缓存的CPU都丢掉自己的高速缓存,再次去读取lock的值,然后判断是否获得锁。如果获得了,就把内存里的lock字和自己的高速缓存设为1(因为一致性协议会从它这读值给其他请求锁的,所以设为1就告诉其他CPU锁不可用),就开始接下来的工作。
这看似没问题,可是由于缓存优化,每次都会读取lock字周围的块,所以最终读取的是64/32位的块。因为TSL是一个写指令,所以每次有CPU请求锁时,都会触发高速缓存一致性协议,使得锁拥有者的高速缓存块失效,然后从内存位请求者请求一个私有的,唯一的副本,如果锁拥有者触发了锁字的邻接字,就又会触发从内存取块到高速缓存里,这样包含锁的块就在锁的拥有者和请求者之间来回跑,这就造成了更大的总线流量。
解决方案是,先设置一个读请求,然后每次尝试读取,如果读取成功,再施加TSL指令,否则只是读指令,这让多CPU共享同一个高速缓存块成为了可能,这个优化减少了高速缓存块在CPU之间的移动复制。在持有锁的CPU释放了锁后,其他CPU发现锁可用,然后施加TSL指令,注意,此时即使有多个CPU发现了锁可用,最后也只会有一个CPU成功获得锁。
另一个很好的减少总线流量的方法是使用以太网的二进制指数回退算法。此时不是采用轮询方式,而是采用延时查询锁的方式,如果不成功,延时加倍,直至某个最大值。
一个更好的想法是,为每个请求锁的CPU一个私有锁,然后把它们附在等待链表的末尾,当某个持有实际锁的CPU完成时,释放该实际锁并释放链表首的CPU的私有锁,让首CPU进行操作,然后循环往复。
自旋与切换
对于CPU等待锁的时间,到底是进行不停地轮询呢?还是切换其他进程运行呢?这是一个值得考究的问题。
一般而言,这取决于获得锁地时间,如果切换进程地耗时远大于取得锁的时间的话,可以考虑使用自旋,如果进程切换更快的话,那么毫无疑问选择切换到另一个进程并运行。
在这里,有一种称为事后算法的方法,根据获得锁与进程切换的时间进行分析,得出具体哪种方法更好。
在这里有一个研究模型可供参考:一个未能获得互斥信号量的进程首先自旋一段时间,如果时间超过某个阀值,切换,该阀值是一个定值,也可以是一个动态改变的值,这取决于先前观察到的等待互斥信号量的历史信息。
线程分类
对于用户线程,内核眼中只有用户进程,所以是没法精确调度的;对于单线程进程和用户空间线程,调度单位都是进程;但是对于内核线程,内核忽略它是哪个进程的然后进行任意的调度。
有些线程是协作关系,有些线程是...没有关系。对于协作的线程,可以安排它们并行,并安排彼此间通信。
- 分时(time-sharing)
在这里的分时调度类似于普通的进程调度,包括使用时间片的轮转调度,带有优先级的优先级等级调度。所以可以很容易看到,这适用于线程无关的情况,如果是这样的话,以这种方式调度是明智的选择并且很容易高效的实现。
不过这存在两个缺点,一是随着CPU数量的增加所引起的对调度数据结构的潜在竞争;二是当线程由于I/O阻塞所引起的上下文切换的开销。
还有一种情况,假如某个持有互斥量的线程被挂起,那么另一个进程启动并试图获取此互斥量,它就会立马被阻塞。为了避免这样的情况,可以使用一种称为智能调度的方法,如果一个线程获取了信号量,它就会设置一个进程范围内的标志,表明它获得了信号量,智能调度会尽量不挂起它,甚至过多的延长它的时间片直到它完成临界区的工作并释放锁。
对于实际的调度,还有一种情况,某个线程在它上次运行过的CPU里运行效果会更好,因为可能还留有缓存等,所以对于这个线程的调度可以考虑这个问题。这是亲和调度,它尽量让某个线程运行在上次运行过的CPU上。创建这种亲和力的一种途径是两级调度算法。每次位线程分配CPU时,考察哪个CPU比较闲,这种把线程分给CPU的工作在算法的顶层运行,其结果是每个CPU获得了自己的线程集。线程的实际调度工作在算法的底层进行。如果某个CPU把自己的线程集跑完了,它会找另一个CPU要线程跑。两级调度还使得CPU对就绪线程数据结构的竞争减到了最小。
- 空间共享(space-sharing)
在多个CPU上同时运行多个线程称为空间共享。对于空间调度,每次检查是否有同线程数量一样多的CPU存在,如果存在,每个进程一个CPU,开始运行,否则等待,直到满足此条件。CPU们被划分成不同的分区,用来满足不同的进程。另一种方式是主动的管理线程的并行度,或者说,当可用CPU数不足时,主动削减需要运行的线程数。
- 群调度(gang-scheduling)
空间共享的缺点在于,如果有线程发生了阻塞,那么其所在的CPU就被白白的浪费了,而分时的缺点在于不好实现线程间通信(因为这需要同时运行线程)。如下所示:
所以提出了群调度,每次一起运行一批线程,它们的起始时间终止时间相同,且尽量让这些线程属于同一进程,然后在有空闲CPU时补上其他进程的线程。
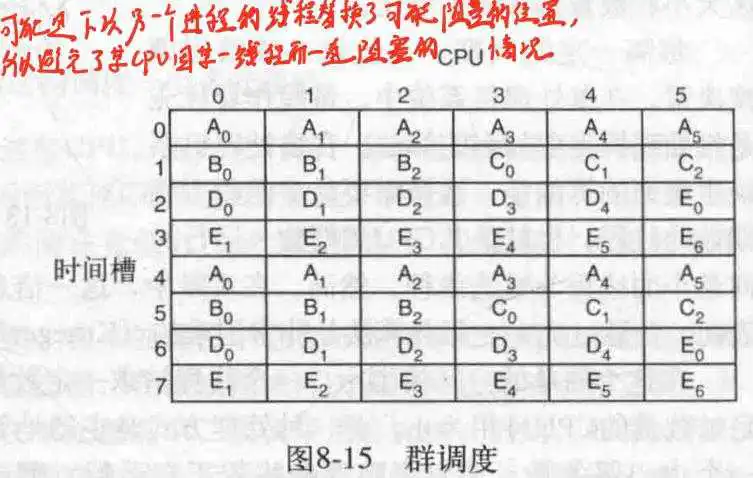
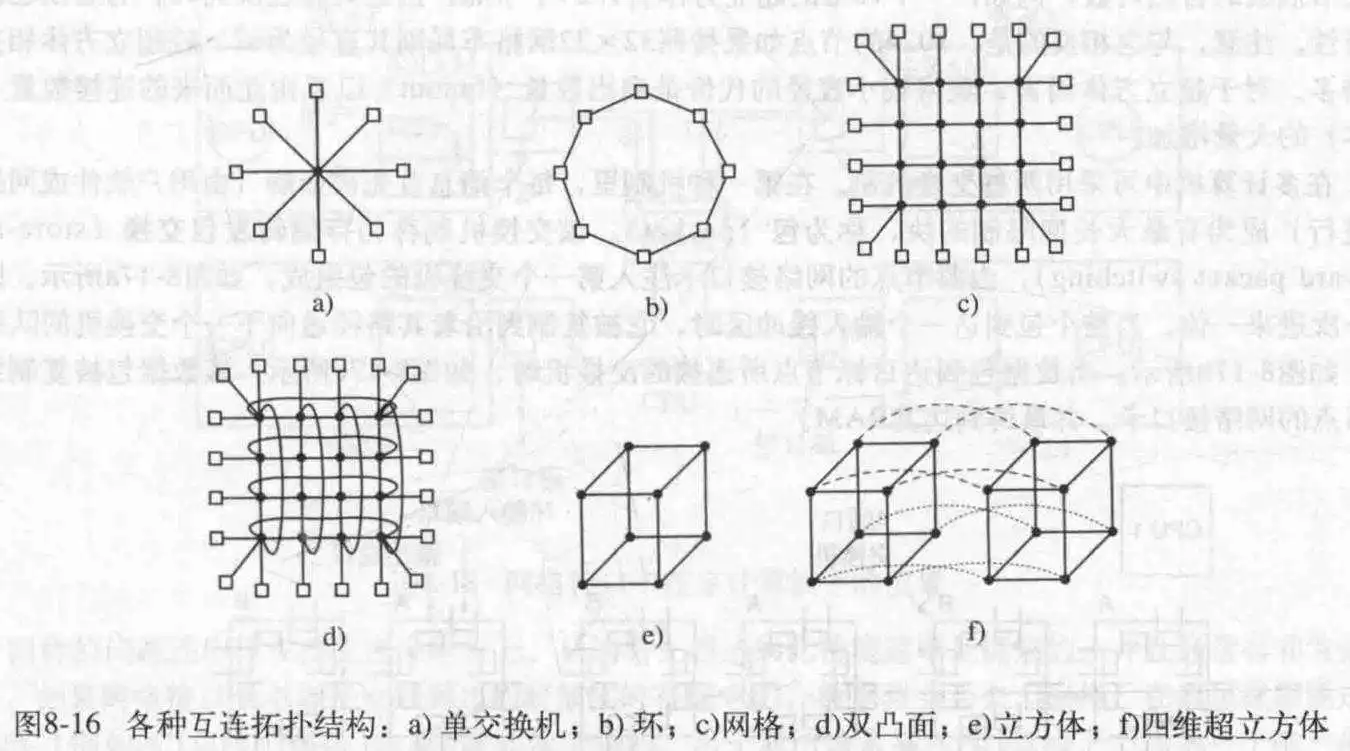
由于多处理机构造困难,造价高昂,所以为了进一步提升CPU数量,引入了多计算机。
多计算机容易构造,因为其基本部件只是一个配有高性能网络接口卡的PC裸机,没有键盘,鼠标,显示器。当然,获得高性能的关键是巧妙地设计互联网络以及网络接口卡。
来看几种网络连接方式:
一个多计算机系统的基本节点包含一个CPU,存储器,一个网络接口,有时还有一个硬盘。
- 互联技术
在每个节点,有一个网络接口用于把各个节点连接在一起,就上图的连接方式来进行分析。
a和b是简单常见的结构。c中的网格,是一种商业中常用的二维设计,这个系统比较简单易扩展,不过它有一个参数,称为直径,即任意两点间的最长路径。该值随节点数的平方根增加。d是其变种之一,双凸面,这种网络容错能力更强,直径也更小。e表示的立方体,f表示的超立方体。现代多计算机更多采用多立方体结构。
在多计算机中,可采用两种交换机制。在第一种机制里,每个消息被分解成有最大长度限制的块,成为包,该交换机制称为存储转发包交换。包从源节点出发,一步一步向前传递,缓冲,最后到达目的节点。包交换机制存在时延问题,解决措施之一是,把包切分成更小的包,然后只要包的第一个单元到达一个交换机,传输就开始而不必等下一个。
另一种交换方式是电路交换。它包括由第一个交换机建立的,通过所有交换机最终到达目的地的传输路径,此路径一旦建立就会一直保持,比特流会源源不断地,快速地通过路径到达目的地,中间的交换机没有缓冲。
电路交换的变种之一是虫孔路由。它把每个包拆分成子包,并允许第一个子包在整个路径还没有建立之前就开始流动。
- 网络接口
一般来说,网络接口板上都有一个存储进出包的RAM,因为许多互联网络是同步的,所以一旦一个包的传送开始,比特流必须以恒定的速率连续进行。而在主RAM中,可能还有其它的应用在使用RAM,这就可能导致速率不一致,而使用接口板专用的RAM就可以解决这个问题。同样的问题也发生在读取数据时,因为比特流一般是以很高的速率到达,所以在接口板缓冲一下是一个不错的选择。
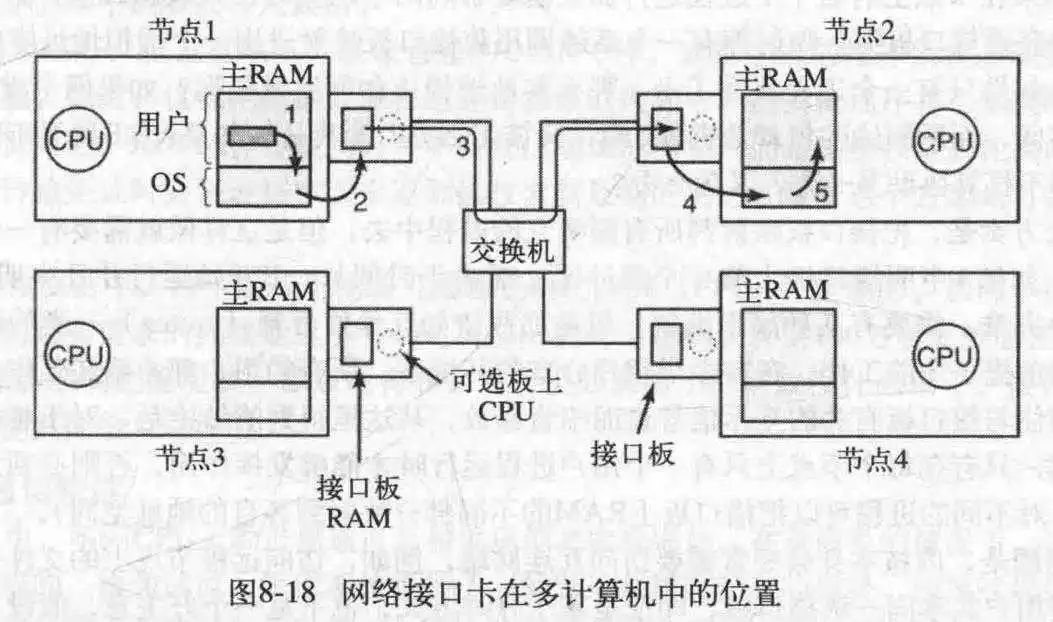
接口板上还可以有一个或多个DMA通道,甚至一个完整的CPU(也可能不止一个)。DMA通道可以在接口板和主RAM之间以非常快的速率复制包,因为可以一次性传输多个字。接口板上的CPU功能日益强大,可以进行加密/解密操作,压缩/解压缩等,如果是多CPU还要进行同步,避免竞争条件。
最后,这种一层一层复制数据的跨层复制是安全的,但是不一定高效。
对于网络通信来说,过多的复制操作是高性能的杀手,所以应尽可能减少复制的发生。有不少多计算机会把接口板映射到用户空间。这种情况不需要内核的参与,但是却引来了两个问题。第一个问题是,映射到虚拟空间的话,假设A进程使用,但是B的消息到达,C进程想发送消息,这应该怎么处理?二是内核有时也要访问网络。假设此时接口板在用户空间,内核消息到达,怎么处理?
对于第一个问题的解决方案,可以把接口板映射到某一个进程里,但是由于存在分时调度,某个刚刚获得接口板的进程被切换,另一需要接口板的进程上场,然后阻塞?所以对于这种方案,只有在每个节点只有一个用户进程时才能工作,否则需要专门的预防机制(比如把接口板上的RAM的不同部分映射到不同的进程)。
第二个问题的解决方案可以是,用两个接口板,一个给用户空间,一个给内核,简单粗暴。
不过,较新的网络接口板都有任务队列,而且有多个队列,可以虚拟化为多个虚拟端口,所以它们可以有效地支持多用户。这对虚拟机也很有用。
- 节点至网络接口通信
此时需要考虑下一个问题,就是怎么把包送到接口板上。最快的方法是直接使用板上的DMA芯片把消息从主RAM复制到板上。但是这存在一个问题,就是DMA一般使用物理地址,并且独立于CPU运行,除非存在I/O MMU,否则很难解决。对于这个问题,细分一下,还可以这么描述:用户进程不知道物理地址,只知道虚拟地址,通过系统调用来转换是不现实的,因为映射到用户空间的意图就是减少系统调用;另一个问题是DMA正在读取某个页面时,OS进行了页面置换?或者正在写入然后发生了页面置换??这更严重。
解决上述问题的方法,可以是采取一类钉住和释放的系统调用。不过,这也会加剧OS负担,尤其在包被分成很小的块时,同时这也会增加软件的复杂性。
- 远程直接内存访问
就是直接用某个机子访问另一个远程机器的内存,但是不是很现实。
操作系统提供了进程间发送和接收消息的系统调用,其实现过程对用户进程是隐藏的,库过程使得这些调用对用户进程可用。所以,对于计算机之间的远程通信,可以把它们封装的尽可能像过程调用那样。下面来讨论这两种方法。
- 发送和接收
在最简单的情形下,所提供的通信服务调用可以减少到只有两个库过程调用。一个用于发送消息,一个用于接收。
比方说,发送可以是:send(dest, &mptr);
而接收消息可能是:receive(addr, &mptr);
进程使用这两个方法进行远程通信,dest指出目标进程,addr指出了接收者监听的地址。
- 阻塞调用和非阻塞调用
上述的调用是阻塞调用,就是调用send时,必须等消息发送完成才能进行下一步,receive也是,必须等到接收完成才能继续。
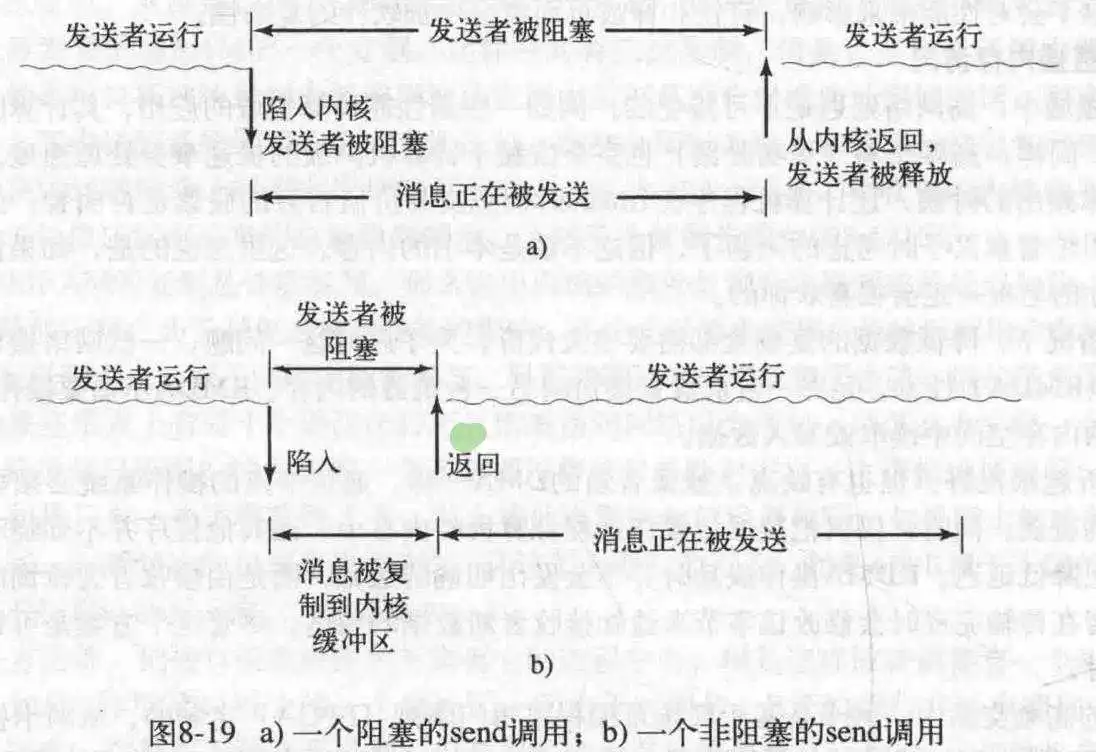
相对应的调用时非阻塞调用。在调用完send/receive后,控制权返回,进程继续自己的事,不过非阻塞调用的缺点往往很明显,发送进程由于不知道什么时候发送结束,所以并不知道什么时候才能重用缓冲区,而不再次使用缓冲区又是不可能的。在此有三种解决方案。
第一种是每次把数据复制进内核,然后让内核处理,此时调用的进程可以返回了,但是这就造成了额外的复制,降低了系统性能。
第二种是在消息发送完毕,中断进程,告诉它已发送。但是这会加剧编程负担,并且可能需要处理竞争条件,所以不是很现实的方法。
第三种是让缓冲区进行写时复制,在消息被发送之前,标记缓冲区为只读,然后每次进程想要再次写入缓冲区,就会触发复制(假如此时还没发送消息)。但是对临近的写操作也会触发复制,所以这可能需要把缓冲区孤立在自己的页面上。
自此我们看到,在发送端的选择是:
1. 阻塞发送(CPU在发送期间无事可做)。 2. 带有复制操作的非阻塞发送(复制本身是一种性能浪费)。 3. 带有中断操作的非阻塞发送(编程困难)。 4. 写时复制(最终可能也会需要额外的复制)。在正常条件下,第一种是最好的选择,尤其是在多线程协作时,因为其他线程依旧可以继续其他工作。
说完了发送,来看看接收,对于receive,阻塞调用也是一个不错的方法,而非阻塞只是通知内核缓冲区所在的位置,然后立刻返回。可以使用中断来通知进程消息到达,但是中断方式编程困难,速度很慢,于是可以采用一个方法poll来轮询进来的消息。该方法报告是否有消息正在等待,进程可以调用get_message()方法来获取第一个到达的消息。当然也可以把poll放在合适的代码里,不过,掌握以怎样的频度使用poll是有技巧的。
另一种选择就是弹出式线程,这个线程运行一个预定义的过程,其参数是一个指向进来消息的指针,在处理完这个消息后,该线程直接退出并被自动销毁。或者消息自身可以带有该处理程序的句柄,这样当消息到达时,就可以用很少的指令调用处理程序,因此避免了复制,处理程序从接口板取到消息然后即时处理。
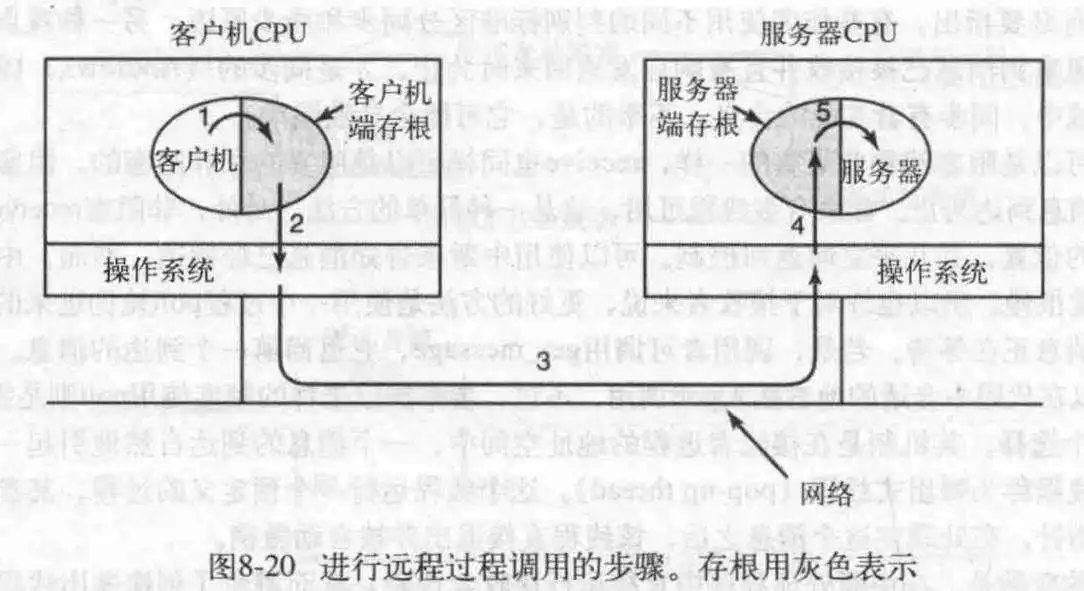
对于多计算机通信,send/receive本质上还是I/O调用,所以应该寻求一种其他的方式,于是引入了远程过程调用,它允许计算机A调用计算机B的程序,此时计算机B的程序被执行,计算机A的程序挂起,可以在过程调用的参数中传递信息,也可以在调用结果中返回信息。
远程调用背后的思想是尽可能使远程调用像本地调用。一般情况下,称调用者为客户机,被调用者为服务器要调用一个远程过程,客户程序必须必须绑定在客户端存根上,它是一个小型的库过程,它在客户机地址空间代表一个服务器过程。类似的,服务器程序也绑定在服务器存根上,这些过程隐藏了这样一个事实,就是客户机到服务器的过程调用并不是本地调用。
RPC调用过程简述如下:客户机调用客户端存根,这是一个本地调用,其参数以通常方式压入栈内;然后是客户端把参数打包成一条消息,进行系统调用来发出该消息,打包消息的过程称为编排;接下来是内核把该消息发送给服务器;再之是服务器内核把接收来的消息传送给服务器端存根;最后。服务器端存根调用服务器过程。应答则是反过来。
在这里,客户机程序只对客户端存根进行正常的本地调用,客户端存根与服务器过程同名。
通常,对本地过程调用传递指针没什么问题,但是对于RPC来说,这是不可能的,因为服务器客户机不在一个虚拟地址空间里。如果一定要用指针传参,那么对于基本类型以及确定类型是可以的,但是对于图像等复杂数据结构可能就不太行,所以需要对远程调用的参数作出限制。
第二个问题是,参数类型并不是总能推导出的。第三个问题是,对于一些弱类型语言,没法指出矢量类型大小,比如C语言的数组的大小就没法表示。第四个问题和全局变量有关,客户机程序和客户端存根可能使用全局变量来通信,但是在远程上,这是不可能的。
不同的CPU之间共享他们各自的RAM,对于某个地址的操作,如果不在自己的RAM里,会陷入OS,OS为CPU取回页面,建立映射关系,重新执行导致陷入的指令。
在这里需要先声明一个概念,那就是这些CPU共享的虚拟地址空间可能不如所有的RAM加起来大,也就是每个节点的RAM只有一部分被用作虚拟地址空间的物理映射地址。因为本意是共享而不是扩大空间。
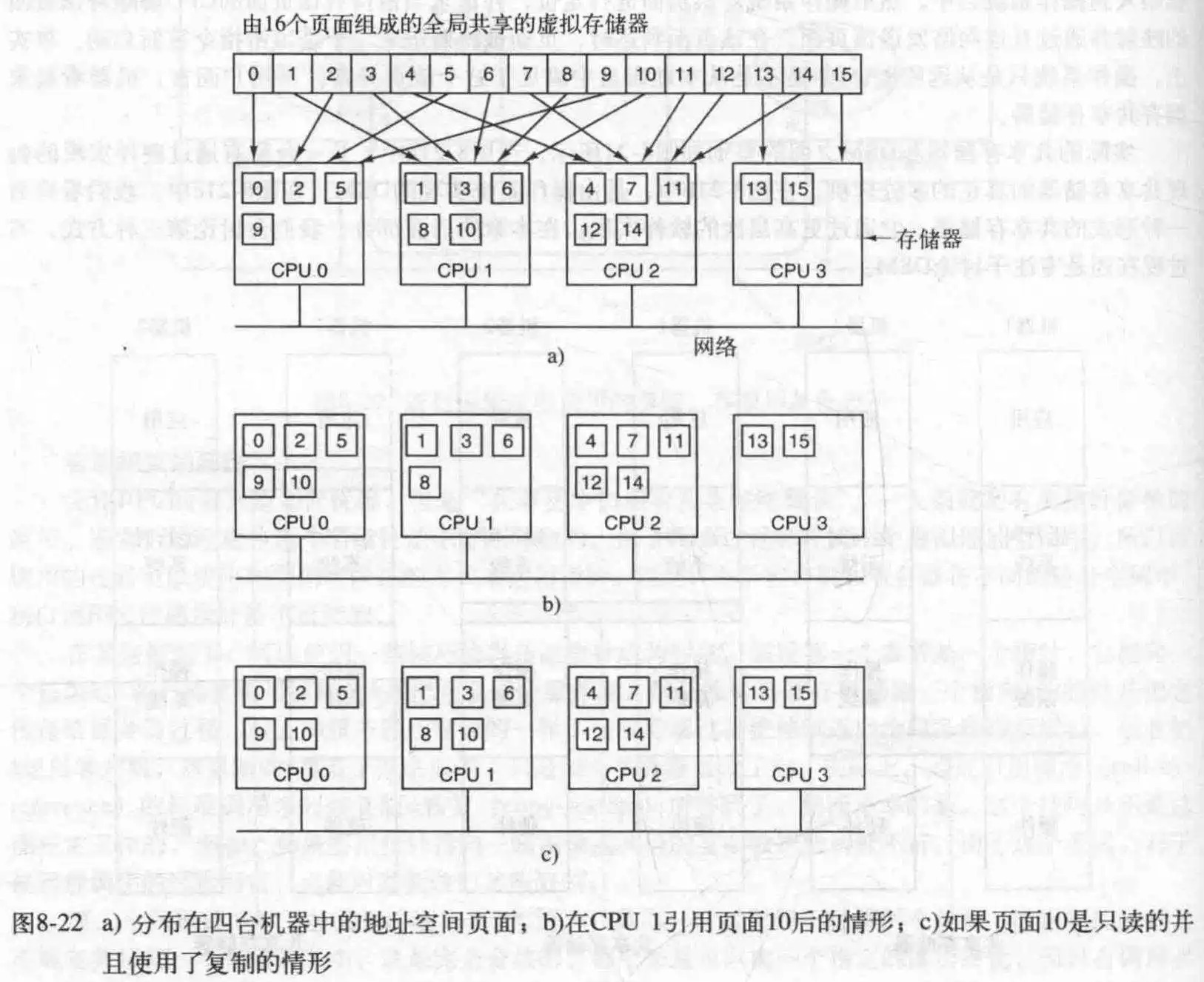
- 复制
对于系统的一个改进是复制那些只读页面,比方说程序代码,只读常量或其他只读数据结构。它可以明显的提升性能。
当然也可以复制读写页面,但是必须保证在某个页面在被修改后保持其副本的一致性。
- 伪共享
当决定复制页面时,问题出来了,因为每次都会复制一块内存,所以复制多大合适?因为网络传输时间最长的地方是一般是启动连接时,所以传输大块和小块差不多。选择大块时,会造成网络长期占用,阻塞其他进程引起的故障,同时CPU引用有一个局限性,就是它很可能会再次引用同一个内存块的字,所以大块内存优势也在此;小块内存可能就会增加传输次数。
过大的页面引发了另一个问题,伪共享。有两个变量A和B,进程1使用A,进行读写,进程2使用B,共享包含这两个变量的块后,如果两个进程频繁对各自的变量进行读写操作,那么会造成内存块在两个节点间来回移动(因为同步问题)。
- 实现顺序一致性
对于复制可写页面,然后某个CPU修改了页面内容,维护其他副本一致性的方法和高速缓存一致性协议差不多:在进行写之前,先向所有持有该页面副本的CPU发送一条消息,告诉它们解除映射并丢弃该页面,然后进行写。当然,也可进行在部分虚拟地址空间上加锁,然后在空间内进行写操作,在锁被释放时,产生的修改传播到其他副本上,只要某一时刻只有一个CPU锁住页面,就可以保持一致性。最后一种可能的方法是,写之前复制一下当前内容,写完了对比刚刚保存的原本内容,产生一个修改列表,然后送往获得锁的CPU更新它的对应的副本的值。
在这里,可以采用很多多处理机的调度策略,但是对于群调度,更重要的是有一个初始的协议决定哪个进程在那个时间槽中运行以及用于协调时间槽起点的某种方法。更多的策略见负载平衡。
在这里需要明确一件事情,一旦某个进程指定给了某个节点,就可以使用本地化调度算法,所以把进程指定给节点的算法就显得尤为重要。
- 图论确定算法
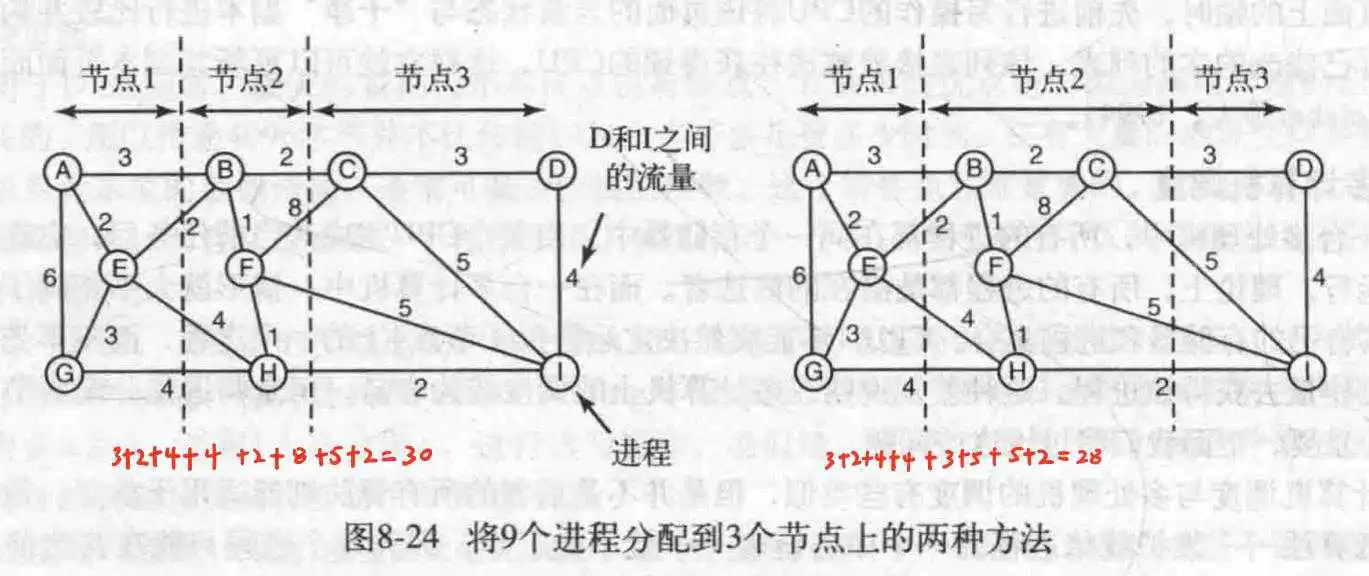
因为进程之间需要通信,所以可以以这个为出发点设计——减少节点之间的网络流量。
设计一个模型,圆代表进程,直线代表他们有通信,直线上的数字代表二者通信的平均负载。所以此算法的目的在于把整个图划分成n个独立的区域,使得区域与区域之间的流量和最小,如果是分割的话,就是分割线穿过的线的值加起来最小。这就是算法目标。
- 发布者发起的分布式启发算法
如果某个CPU负载很多,它会主动探查其他节点是否负载不重可以替它接几个进程,但是在整个系统负载都很重的情况下,在进行探查,无疑是雪上加霜,而且几乎没有哪个CPU的进程可以被卸载,所以这不是一个特别好的方法。
- 接收者发起的分布式启发算法
这次换成空闲的CPU主动找事干,它会探查其他CPU是否过载,然后要进程来运行,这种方法的优点是,不会在系统过载时再次增加系统负担。
当然,那这两种算法组合起来也是可能的。同时也可以设置一个历史记录,记录哪个CPU更可能过载,以更好地解决它的负担。
多处理机时在一个机箱里,多计算机在一个房间里,而分布式系统,那就厉害了,在全球。它的每个节点可能都不一样,每个结点的OS,CPU,内存,文件系统,会不一样,是否有硬盘,键盘鼠标都不好说。
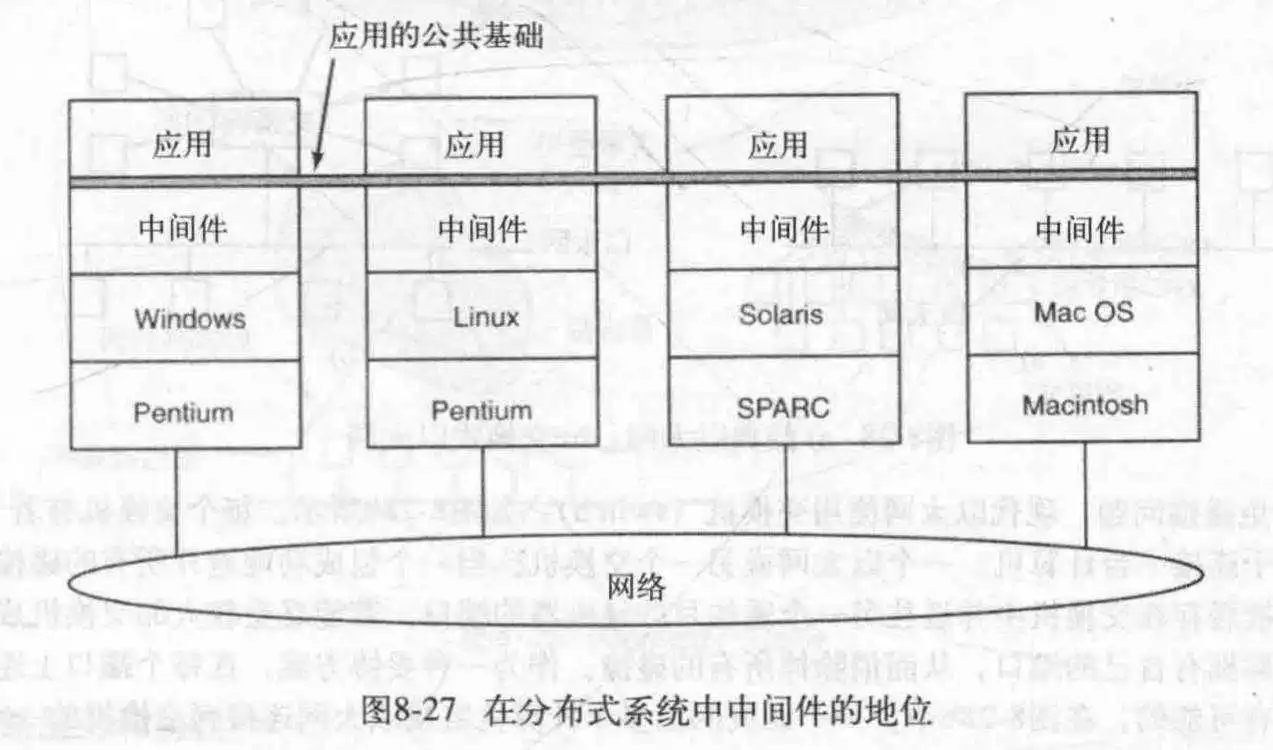
在操作系统顶层添加一层软件,用来统一分布式系统,这层软件就是中间件。从某种意义上来说,中间件就是分布式系统的操作系统。
- 以太网
作为连接多个计算的网络而存在,通过把网线插入计算机网络接口即可实现。
- 因特网
在更大范围内完成计算机之间的连接。在Internet上,所有的通信都是以包的形式传送的。
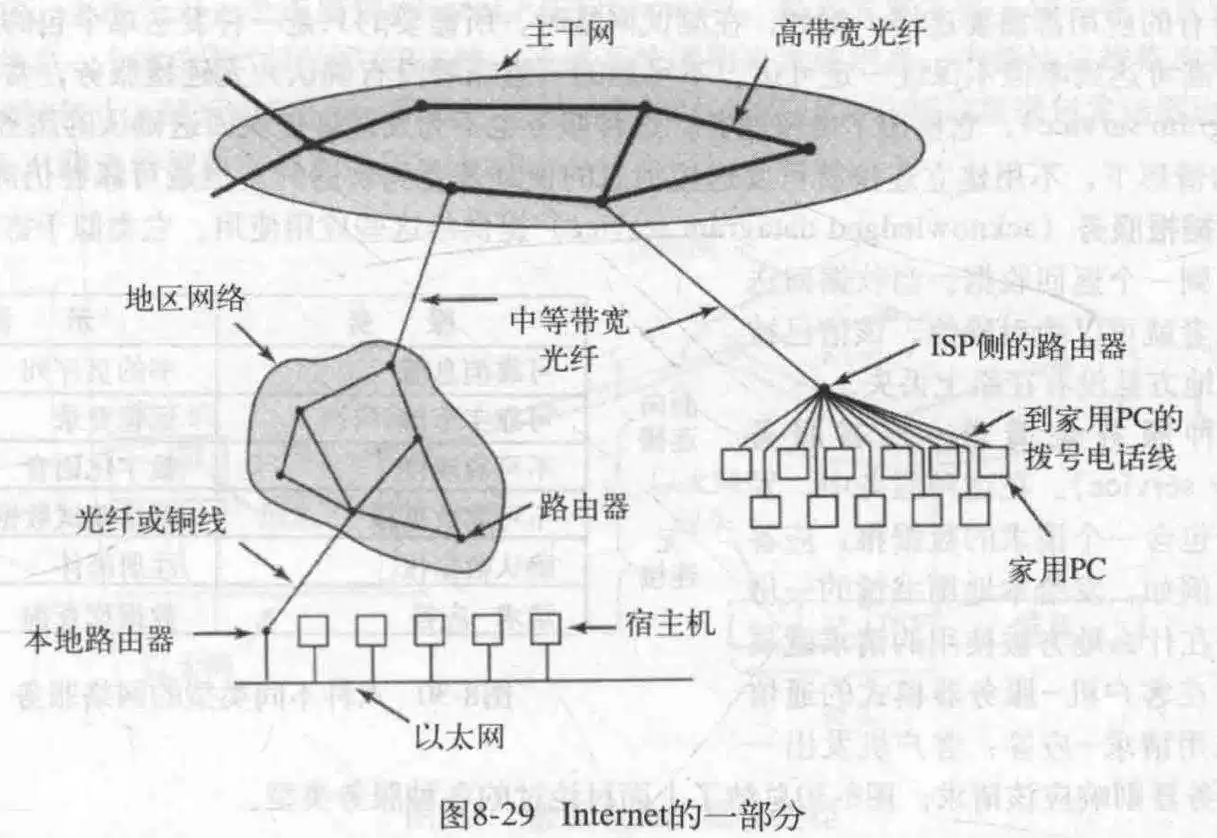
- 网络服务
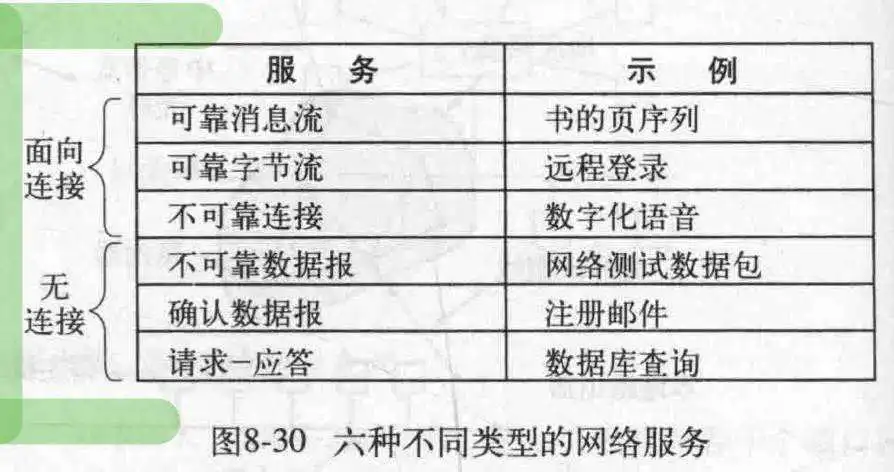
对于网络服务提供的方式,一般有两种:面向连接的服务和无连接服务。前者是对电话系统的模仿,后者是对邮政系统的模仿,不在乎应答,只管推送,每个包都有完整的目的地地址,独立于其他包而存在。
每种服务都可以用服务质量来描述,有些服务从来不丢数据,比方说通过接收者返回一个特别的确认包来实现。虽然这降低了传送的速度以及引入了过载和延迟的问题。
可靠的,面向连接的服务有两种很轻微的变种:消息序列和字节流。前者消息由边界,每次发送一个边界之内的消息,比如传送文件,短信等;后者的消息组成一个字节流,不存在边界问题,这可以用于ssh远程控制。
而对于某些应用而言,延迟是不可接受的,比方说语音频通话,毕竟,宁愿马赛克也不能音画不同步。
当然,并不是所有的应用都需要连接,如果只是测试网络,发送单个包(通常这个包具有高可达性)就好了,这是数据报服务。如果要求得到回复,那么可以使用确认数据报服务,它要求在发送一个数据包后得到一个回复。
最后还有一种,请求-应答服务,它在发送一个请求的数据报后,应答里包含着回复。
- 网络协议
网络协议,用于定义什么消息可以发送以及怎么响应这些消息。现代所有的网络都使用协议栈来把不同的协议一层层叠加起来使用。
大部分分布式系统都是用Internet作为基础,因此这些系统使用的关键协议是两种主要的Internet协议:IP和TCP。
IP是一种数据报协议,发送者可以向网络上发出长达64KB的数据报,并期望它能到达。IP数据报是非应答的,所以为了可靠的通信,通常在IP层之上使用另一种协议:TCP。TCP协议使用IP来提供面向连接的数据流。远程通信技术对于用户进程是隐藏的,它们看到的只是可靠的进程间通信,就像UNIX管道一样。
对于基于文档的中间件,用一个著名的例子阐述:Web。
Web背后的逻辑很简单,它指出每个计算机持有一个或多个文档,称为Web页面(现在来看应该是HTML页面)。每个页面可以包含文字,图像,声音,甚至指向别的页面的超链接。当用户使用Web浏览器访问远程计算机的某个页面时,Web浏览器发起请求,然后把请求返回的页面呈现给用户。
每个Web页面都有一个唯一的地址,称为URL(统一资源定位器),其形式为:protocol://ip:port/filename。
整个系统按照如下方式结合在一起:Web根本上是一个客户机-服务器系统,用户是客户端,而Web站点则是服务器。
阴藏在Web背后的思想是:使一个分布式系统看起来像一个巨大的,超链接的集合。另一种处理方式则是使一个分布式系统看起来像一个大型文件系统。
分布式系统采用一个文件系统意味着只存在一个全局文件系统,全世界的用户都能读写他们各自被授权的文件。通过一个进程把数据写入文件而另一个读出文件即可实现进程间通信。不过这引发了一些与分布性有关的新问题,如下所述:
- 传输模式
既然是文件系统,就必然涉及到文件的处理。对于文件的处理无非就是读和写,那么怎么读写整个系统里的文件呢?有两个可用方法,一个是上传/下载模式,一个是远程访问模式。前者每次客户机打算对服务器文件操作时,都会把文件复制到本地,然后操作,再把更新过的文件写回到服务器;而在后者,客户机远程操作服务器上的文件。
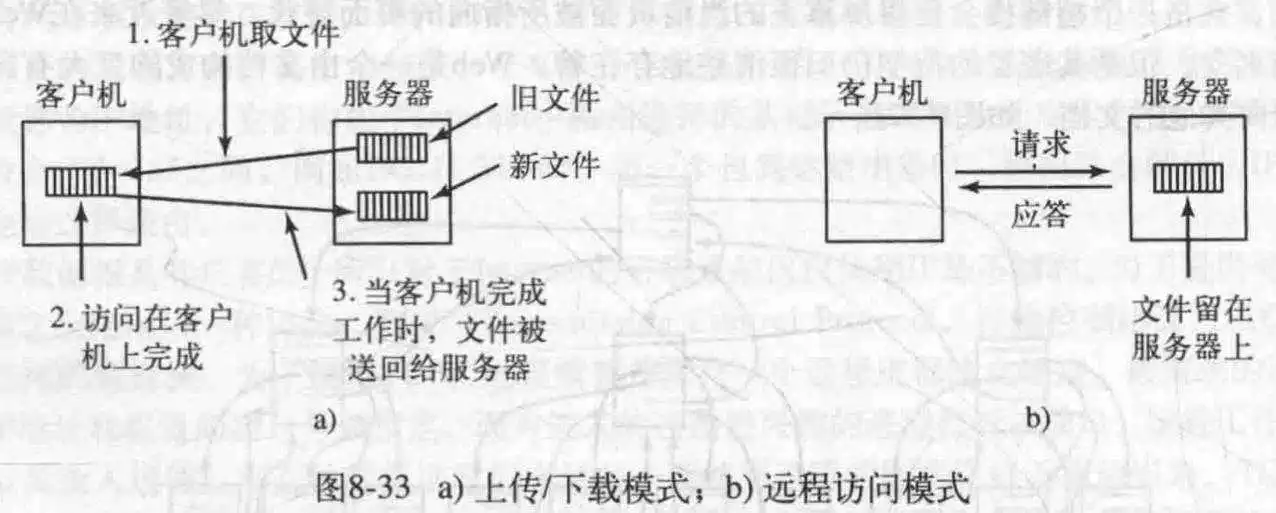
不过上传/下载模式要求客户机空间足够,当有多个用户时,还有考虑并发访问问题。
- 目录层次
如果采用文件系统,那么另一个需要考虑的方式是文件的组织形式,也就是文件目录。这就产生一个问题:是否所有的用户都拥有该目录层次的相同视图。
如果都一致,那么要求再客户机1的某个路径对于客户机2也必须可用;若采用不同的视图,则可能会发生同一路径下文件不存在的现象,不过这样的好处是灵活且可以直接实现。
- 命名透明性
对于基于文件系统的分布式系统,文件的命名也是一个值得考究的问题,在这里命名的主要问题是,它不是完全透明的。(在这里解释一下透明性,就是在PC里,每个文件都有路径名,此时它是透明的,因为知道它的绝对位置,以及它是在确定机器上的,也就是当前PC,但是在分布式系统不一定,因为不同的节点甚至系统都不一样,就很难做到刚刚的完全确定,这就是不透明的命名)
对于透明性,这里有两种类型,一种是位置透明性,其含义是路径名没有隐含文件所在的(物理)位置信息。所以该服务器可以随便跑,而不用在意它到底是在东京还是新泽西或者是成都。
如果在整个分布式系统中,随意在服务器之间移动某个文件但文件名称(包含路径的名称)不会改变,那么称该文件具有位置独立性。
最后来总结一下在分布式系统里处理文件和目录命名的方式通常有以下3种:
1. 机器+路径名,如/machine/path。 2. 将远程文件系统安装在本地文件层次中。 3. 在所有机器上看起来都相同的单一名字空间。- 文件共享的语义
既然是多用户,就不可避免地会发生多个用户对服务器上的同一个文件进行操作而引发的竞争问题。事实上,系统强制所有的系统调用有序,并且所有的处理器都能看到同样的顺序,我们将这种模型称为顺序一致性。
如果只有一个文件服务器且客户机不缓存,那么还是可以实现的,不过实际情况是客户机不缓存的话,所有请求打到服务器,会造成服务器性能堪忧,所以客户机必须缓存,但是这样就会造成客户机1对文件A的修改是本地化的,这样另一个请求文件A的客户机2拿到的就是过时的,进而造成不一致。解决措施可以是让每次修改立马同步到服务器,这样后面请求同一文件的客户机可以拿到最新的副本。不过这很低效。
另一个方法是只有在文件关闭时,才把更改同步到服务器上,这个就是上传/下载模式,这种同步语义得到了广泛地实现,即会话语义。
另一种可行的方法是,进行上传/下载模式时,对文件加锁,以避免不一致的文件。
此中间件使用一种称为ORB的对象实现,这种对象无关于语言,它含有域,以及访问域的方法。要调用一个对象中的方法,客户机需要先获得对该对象的引用。ORB被放置在客户机和服务器之间,客户机像客户端ORB传递参数,客户机的ORB与服务器的ORB取得联系,执行远程调用,整个过程类似RPC。
- Linda
对于Linda来说,整个系统共用一个元组空间,节点与节点之间通过元组空间通信,元组空间是一个元组的集合,元组是一系列数据的集合,有点像JSON字符串,里面用','分隔出一个一个的数据域。
每个节点都可以在元组空间里添加或者移除元组,out操作可以添加元组,in操作获取元组,匹配方式是内容匹配,只有元组内容一致才可以。元组元素支持表达式,变量和常量。in操作如果匹配到元组就把它移出元组空间并返回元组。当然了,还有read操作,它不会把元组移出,eval进行元组计算,并把计算结果放入元组空间。
- 发布/订阅
这种方式类似Linda的元组,生产者会产生一个新的消息并在网络上广播,这个过程称为发布,而消费者可以订阅特定的主题。系统会提供守护线程监听消息类型,如果是某个消费者感兴趣的就调用这个消费者进行处理。
为了实现更加稳定的系统,可以使用一个数据库来记录历史消息。
- 互斥:在任一时间只能有一个线程操作缓冲区
- 当缓冲区为空,消费者必须等待生产者(调度/同步约束)
- 当缓冲区为满,生产者必须等待消费者(调度/同步约束)
- 两个
wait()操作不能调换顺序,否则有可能会造成死锁。 - 当buffer已满时,若生产者首先执行
mutex->wait()进入临界区,当执行emptySem->wait()时,由于buffer已满,生产者会阻塞。 - 当消费者想进入临界区时,由于生产者在临界区中阻塞,而消费者又无法执行
emptySem->signal()唤醒生产者,造成死锁 - 两个
signal()可以调换顺序
#define N 100 //缓冲区大小 class semaphore; //信号量 class BoundedBuffer { private: semaphore* mutex = new semaphore(1); //控制对临界区的访问 semaphore* fullSem = new semaphore(0); //buffer的满槽数量(已被占用) semaphore* emptySem = new semaphore(N); //buffer的空槽数量(未被占用) public: void producer() { while(true) { emptySem->wait(); //将空槽数减1 mutex->wait(); // Add item to buffer mutex->signal(); fullSem->signal(); //将满槽数加1 } } void comsumer() { while(true) { fullSem->wait() //将满槽数减1 mutex->wait(); // Remove item from buffer mutex->signal(); emptySem->signal(); //将空槽数加1 } } }; - 生产者和消费者进入管程就要加锁,对应图中
Acquire()和Release() - 当生产者或者消费者需要等待在某个条件变量上时,需要调用
wait()操作,该操作中首先释放锁,因为要允许其他就绪进程进入管程,然后阻塞睡眠自身,当再次被唤醒时,进行获取锁操作,请求进入管程。
- 允许同一时间有多个读者,但在任何时候只有一个写者
- 当没有写者时读者才能访问数据
- 当没有读者和写者时写者才能访问数据
- 在任何时候只能有一个线程可以操作共享变量




- 5个哲学家,5把叉子,只有哲学家拿到左右两把叉子时才能进食
- 哲学家可处于进食和思考两个状态
#define N 5 #define LEFT (i + N - 1)%N //左边哲学家 #define RIGHT (i + 1)%N //右边哲学家 #define THINKING 0 #define HUNGRAY 1 #define EATING 2 typedef int semaphore; int state[N]; // 跟踪哲学家的状态 semaphore mutex = 1; // 临界区互斥 semaphore s[N]; // 每个哲学家一个信号量 void think(); void eat(); void down(int* i); void up(int* i); void philosopher(int i) { // 哲学家行为抽象 while (1) { think(); take_forks(i); eat(); put_forks(i); } } void take_forks(int i) { down(&mutex); // 进入临界区 state[i] = HUNGRAY; test(i); up(&mutex); // 离开临界区 down(&s[i]); // 如果当前叉子已就位,继续执行;反之阻塞 } void put_forks(int i) { down(&mutex); // 进入临界区 state[i] = THINKING; test(LEFT); // 测试左边哲学家是否为HUNGRY test(RIGHT); // 测试右边哲学家是否为HUNGRY up(&mutex); // 离开临界区 } void test(i) { if(state[i] == HUNGRAY && state[LEFT] != EATING && state[RIGHT] != EATING) { state[i] = EATING; up(&s[i]); // 当前两边叉子已就位,s[i]置为1 } }此实验是来自《现代操作系统:原理与实现》
相比于6.828,此实验有虚拟实验平台,可以不用自己配环境。实验平台链接:实验 1:ChCore操作系统-机器启动
如果希望自己配环境做实验的话,移步官方实验配置:ChCore实验环境配置
我的代码仓库:chcore-lab: 银杏书实验chcore-lab (gitee.com)
声明:本人不能保证此答案的正确性,有部分原因是问题不清晰,另一部分原因是给的代码注释较少,有些代码由于个人能力无法读懂,所以推测部分我会标注清楚。希望大家能指正我的错误。
浏览《ARM 指令集参考指南》的 A1、A3 和 D 部分,以熟悉 ARM ISA。请做好阅读笔记,如果之前学习 x86-64 的汇编,请写下与 x86-64 相比的一些差异。
具体看专栏里的ARM汇编相关的文章(待出)
启动带调试的 QEMU,使用 GDB 的where命令来跟踪入口(第一个函数)及 bootloader 的地址。
0x0000000000080000 in ?? () (gdb) where #0 0x0000000000080000 in _start ()可以看到入口为0x0000000000080000 并且函数为_start。通过查找可知_start函数在boot/start.S文件中。
(吐槽一下平台判断正确的方式有点离谱,一直没过测试)
结合readelf -S build/kernel.img读取符号表与练习 2 中的GDB 调试信息,请找出请找出build/kernel.image入口定义在哪个文件中。
$ readelf -S build/kernel.img There are 9 section headers, starting at offset 0x20cd8: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] init PROGBITS 0000000000080000 00010000 000000000000b5b0 0000000000000008 WAX 0 0 4096 [ 2] .text PROGBITS ffffff000008c000 0001c000 00000000000011dc 0000000000000000 AX 0 0 8 [ 3] .rodata PROGBITS ffffff0000090000 00020000 00000000000000f8 0000000000000001 AMS 0 0 8 [ 4] .bss NOBITS ffffff0000090100 000200f8 0000000000008000 0000000000000000 WA 0 0 16 [ 5] .comment PROGBITS 0000000000000000 000200f8 0000000000000032 0000000000000001 MS 0 0 1 [ 6] .symtab SYMTAB 0000000000000000 00020130 0000000000000858 0000000000000018 7 46 8 [ 7] .strtab STRTAB 0000000000000000 00020988 000000000000030f 0000000000000000 0 0 1 [ 8] .shstrtab STRTAB 0000000000000000 00020c97 000000000000003c 0000000000000000 0 0 1 同时根据练习2获得的信息可以得出:程序入口在0x80000。在chcore-lab文件夹查找入口定义,可以看到在boot/image.h文件中有定义:#define TEXT_OFFSET 0x80000。
接着查找可以看到在scripts/linker-aarch64.lds.in文件中,TEXT_OFFSET被使用了。linker-aarch64.lds.in文件就是链接器脚本。链接器脚本是一个或多个输入文件合成一个输出文件。(链接器脚本规则参考[1])
#include "https://www.zhihu.com/topic/boot/image.h" SECTIONS { . = TEXT_OFFSET; // 把定位器符号置为0x80000 img_start = .; // 赋值语句 init : { ${init_object} // 将init_object中所有文件合并成一个init段 } ...... } 其中init_object在CMakeLists.txt文件定义:
set(init_object "${BINARY_KERNEL_IMG_PATH}/${BOOTLOADER_PATH}/start.S.o ${BINARY_KERNEL_IMG_PATH}/${BOOTLOADER_PATH}/mmu.c.o ${BINARY_KERNEL_IMG_PATH}/${BOOTLOADER_PATH}/tools.S.o ${BINARY_KERNEL_IMG_PATH}/${BOOTLOADER_PATH}/init_c.c.o ${BINARY_KERNEL_IMG_PATH}/${BOOTLOADER_PATH}/uart.c.o" ) 在文章[1]中,可知设置进程入口的方式有:
1. ld命令行的-e选项
2. 连接脚本的ENTRY(SYMBOL)命令
3. 如果定义了start 符号, 使用start符号值
4. 如果存在 .text section , 使用.text section的第一字节的位置值
5. 使用值0
通过搜索可以找到在CMakeLists.txt文件中有:
set_property( TARGET kernel.img APPEND_STRING PROPERTY LINK_FLAGS "-T ${CMAKE_CURRENT_BINARY_DIR}/${link_script} -e _start" ) 此条语句设置了编译时使用自定义链接器脚本并且设置程序入口为_start。
继续借助单步调试追踪程序的执行过程,思考一个问题:目前本实验中支持的内核是单核版本的内核,然而在 Raspi3 上电后,所有处理器会同时启动。结合boot/start.S中的启动代码,并说明挂起其他处理器的控制流。
使用GDB调试时,断点会不断在1.1-1.4线程中切换,只有1.1线程会往下走,由此可知只有1.1线程所在的处理器在运行,其他处理器都被挂起。从调试信息中可以看到挂起的线程都是在_start()函数中挂起。在boot/start.S文件中可以看到注释:
BEGIN_FUNC(_start) ...... cbz x8, primary /* hang all secondary processors before we intorduce multi-processors */ secondary_hang: bl secondary_hang primary: /* Turn to el1 from other exception levels. */ bl arm64_elX_to_el1 ...... END_FUNC(_start)根据注释可知:挂起操作就是让其他处理器一直死循环。
查看build/kernel.img的objdump信息。比较每一个段中的VMA和LMA是否相同?
$ objdump -h build/kernel.img build/kernel.img: file format elf64-little section: Idx Name Size VMA LMA File off Algn 0 init 0000b5b0 0000000000080000 0000000000080000 00010000 212 CONTENTS, ALLOC, LOAD, CODE 1 .text 000011dc ffffff000008c000 000000000008c000 0001c000 23 CONTENTS, ALLOC, LOAD, READONLY, CODE 2 .rodata 000000f8 ffffff0000090000 0000000000090000 00020000 23 CONTENTS, ALLOC, LOAD, READONLY, DATA 3 .bss 00008000 ffffff0000090100 0000000000090100 000200f8 24 ALLOC 4 .comment 00000032 0000000000000000 0000000000000000 000200f8 20 CONTENTS, READONLY可以从以上信息中得出:init段VMA和LMA相同。.text段、.bss段和.rodata段VMA和LMA不同。
VMA和LMA的设置主要在链接器脚本中:SECTIONS命令告诉ld如何把输入文件的sections映射到输出文件的各个section:如何将输入section合为输出section;如何把输出section放入程序地址空间(VMA)和进程地址空间(LMA)。
输出section描述具有如下格式:
SECTION [ADDRESS] [(TYPE)] : [AT(LMA)] { OUTPUT-SECTION-COMMAND OUTPUT-SECTION-COMMAND ... } [>REGION] [AT>LMA_REGION] [:PHDR :PHDR ...] [=FILLEXP][]内的内容为可选选项,SECTION 为section的名字。其中[ADDRESS]指定了VMA,[AT(LMA)]指定了LMA[2]。
现在来查看linker-aarch64.lds.in文件:
#include "https://www.zhihu.com/topic/boot/image.h" SECTIONS { . = TEXT_OFFSET; img_start = .; init : { ${init_object} } . = ALIGN(SZ_16K); init_end = ABSOLUTE(.); // KERNEL_VADDR在image.h定义为0xffffff0000000000 .text KERNEL_VADDR + init_end : AT(init_end) { *(.text*) } . = ALIGN(SZ_64K); .data : { *(.data*) } . = ALIGN(SZ_64K); .rodata : { *(.rodata*) } _edata = . - KERNEL_VADDR; _bss_start = . - KERNEL_VADDR; .bss : { *(.bss*) } _bss_end = . - KERNEL_VADDR; . = ALIGN(SZ_64K); img_end = . - KERNEL_VADDR; }可以很明显地看到init段没有设置VMA和LMA,所以链接器将VMA设为定位符号的值,并且默认VMA=LMA。而.text段设置了不同的VMA和LMA。而设置VMA会更改定位符号的值,使得后面的.bss段和.rodata段的VMA和LMA不同。
为什么VMA和LMA不同?
根据lab 1实验文档可以得知init段就是bootloader,主要的作用就是:
- 将处理器的异常级别从其他级别切换到EL1
- 初始化引导UART,页表和 MMU
- 最后跳转到实际的内核。
可以知道在init段运行时,MMU还未初始化,还处于实模式。所以不能使用虚拟地址,因为虚拟地址可能超出了物理地址的范围。而bootloader之后,内核就映射到虚拟地址,而内核段映射到高位应该是一种惯例。
在VMA和LMA不同的情况下,内核是如何将该段的地址从LMA变为VMA?提示:从每一个段的加载和运行情况进行分析
LMA变为VMA的方式就是虚拟地址映射到物理地址的过程。具体内容可以看银杏书第4章。
以不同的进制打印数字的功能(例如 8、10、16)尚未实现,请在kernel/common/printk.c中填充printk_write_num以完善printk的功能。
找到kernel/common/printk.c文件,分析一下代码:
static int printk_write_num(char out, long long i, int base, int sign, int width, int flags, int letbase) { char print_buf[PRINT_BUF_LEN]; char *s, c; int t, neg = 0, pc = 0; unsigned long long u = i, num; if (i == 0) { print_buf[0] = '0'; print_buf[1] = '\0'; return prints(out, print_buf, width, flags); // 将print_buf中的所有字符用simple_outputchar函数打印 } if (sign && base == 10 && i < 0) { neg = 1; u = -i; } // TODO: fill your code here // store the digitals in the buffer `print_buf`: // 1. the last postion of this buffer must be '\0' // 2. the format is only decided by `base` and `letbase` here if (neg) { // 如果数字是负数,那么需要添加‘-’ if (width && (flags & PAD_ZERO)) { // 如果要求打印的数字长度不为0或需要填充0去满足要求长度 simple_outputchar(out, '-'); // 用simple_outputchar函数打印打印字符‘-’ ++pc; --width; } else { *--s = '-'; // 因为不需要填充,所以字符‘-’直接放在数字前面 } } return pc + prints(out, s, width, flags); }simple_outputchar函数:
static void simple_outputchar(char str, char c) { if (str) { str = c; ++(*str); } else { uart_send(c); } }此函数的功能是通过串口发送字符到AUX_MU_IO_REG或将字符复制到str指定的位置。AUX_MU_IO_REG应该是树莓派和外设沟通的UART[4],但是现在不能确定,之后再看看。
内核栈初始化(即初始化SP和FP)的代码位于哪个函数?
全局搜索stack可以找到两个宏变量:kernel_stack和boot_cpu_stack。这两个都是栈,不同的是boot_cpu_stack栈是在bootloader中使用的栈,此栈是在start函数中被初始化。kernel_stack则是在内核启动(start_kernel函数中)时被初始化。所以内核栈初始化在start_kernel函数中:
BEGIN_FUNC(start_kernel) mov x3, #0 msr TPIDR_EL1, x3 ldr x2, =kernel_stack add x2, x2, KERNEL_STACK_SIZE mov sp, x2 bl main END_FUNC(start_kernel)ldr x2, =kernel_stack为ldr伪指令,功能是将kernel_stack的地址放入x2寄存器中。
内核栈在内存中位于哪里?内核如何为栈保留空间?
以下为猜测:kernel_stack定义在main.c文件中,是全局变量并且未初始化,所以按照编译规则应该放在.bss段。再回到之前的链接器脚本(linker-aarch64.lds.in)中,可以发现.bss段的地址是. - KERNEL_VADDR。
根据机器加载程序的方式,.bss段有全局变量的信息,在加载时就会开辟相应的空间给全局变量。
为了熟悉AArch64上的函数调用惯例,请在kernel/main.c中通过GDB找到stack_test函数的地址,在该处设置一个断点,并检查在内核启动后的每次调用情况。每个stack_test递归嵌套级别将多少个64位值压入堆栈,这些值是什么含义?
我将gdb输出导出到experiment7-gdb.txt文件中(这里说一下:实验文档中打印内存的方式和下面的输出结果不同,应该使用x /10xg $x29才是输出16进制的结果[5])。可以看到一共有6个输出结果,说明stack_test函数调用了6次。每次将4个64位值压入栈。
下面分析gdb到最后一个断点时的输出和stack_test函数:
0xffffff0000092050 <kernel_stack+8016>: 0xffffff0000092070 0xffffff000008c070 0xffffff0000092060 <kernel_stack+8032>: 0x0000000000000002 0x00000000ffffffc0 0xffffff0000092070 <kernel_stack+8048>: 0xffffff0000092090 0xffffff000008c070 0xffffff0000092080 <kernel_stack+8064>: 0x0000000000000003 0x00000000ffffffc0 0xffffff0000092090 <kernel_stack+8080>: 0xffffff00000920b0 0xffffff000008c070 0xffffff00000920a0 <kernel_stack+8096>: 0x0000000000000004 0x00000000ffffffc0 0xffffff00000920b0 <kernel_stack+8112>: 0xffffff00000920d0 0xffffff000008c070 0xffffff00000920c0 <kernel_stack+8128>: 0x0000000000000005 0x00000000ffffffc0 0xffffff00000920d0 <kernel_stack+8144>: 0xffffff00000920f0 0xffffff000008c0d4 0xffffff00000920e0 <kernel_stack+8160>: 0x0000000000000000 0x00000000ffffffc0 0xffffff00000920f0 <kernel_stack+8176>: 0x0000000000000000 0xffffff000008c018 0xffffff0000092100 <kernel_stack+8192>: 0x0000000000000000 0x0000000000000000 每两行一组,是一次函数调用的入栈结果。从结果看父函数的栈底地址和调用时的参数都被保存了。仅仅根据这些数据无法推断出来值的意思。
现在来查看一下stack_test函数:
void stack_test(long x) { kinfo("entering stack_test %d\n", x); if (x > 0) stack_test(x - 1); else stack_backtrace(); kinfo("leaving stack_test %d\n", x); }和其编译后的汇编语言:
0xffffff000008c020 <stack_test>: stp x29, x30, [sp,#-32]! /* FP、LR 入栈 */ 0xffffff000008c024 <stack_test+4>: mov x29, sp /* 更新FP */ 0xffffff000008c028 <stack_test+8>: str x19, [sp,#16] /* 在栈空间中保存x19寄存器 */ 0xffffff000008c02c <stack_test+12>: mov x19, x0 0xffffff000008c030 <stack_test+16>: mov x1, x0 0xffffff000008c034 <stack_test+20>: adrp x0, 0xffffff0000090000 0xffffff000008c038 <stack_test+24>: add x0, x0, #0x0 0xffffff000008c03c <stack_test+28>: bl 0xffffff000008c638 <printk> 0xffffff000008c040 <stack_test+32>: cmp x19, #0x0 0xffffff000008c044 <stack_test+36>: b.gt 0xffffff000008c068 <stack_test+72> 0xffffff000008c048 <stack_test+40>: bl 0xffffff000008c0dc <stack_backtrace> 0xffffff000008c04c <stack_test+44>: mov x1, x19 0xffffff000008c050 <stack_test+48>: adrp x0, 0xffffff0000090000 0xffffff000008c054 <stack_test+52>: add x0, x0, #0x20 0xffffff000008c058 <stack_test+56>: bl 0xffffff000008c638 <printk> 0xffffff000008c05c <stack_test+60>: ldr x19, [sp,#16] /* 恢复x19寄存器 */ 0xffffff000008c060 <stack_test+64>: ldp x29, x30, [sp],#32 /* FP、LR 出栈 */ 0xffffff000008c064 <stack_test+68>: ret 0xffffff000008c068 <stack_test+72>: sub x0, x19, #0x1 0xffffff000008c06c <stack_test+76>: bl 0xffffff000008c020 <stack_test> 0xffffff000008c070 <stack_test+80>: mov x1, x19 /* 递归调用时的返回地址 */ 0xffffff000008c074 <stack_test+84>: adrp x0, 0xffffff0000090000 0xffffff000008c078 <stack_test+88>: add x0, x0, #0x20 0xffffff000008c07c <stack_test+92>: bl 0xffffff000008c638 <printk> 0xffffff000008c080 <stack_test+96>: ldr x19, [sp,#16] /* 恢复x19寄存器 */ 0xffffff000008c084 <stack_test+100>: ldp x29, x30, [sp],#32 /* FP、LR 出栈 */ 0xffffff000008c088 <stack_test+104>: ret 从练习7介绍中可知x30为返回地址、x29为帧指针。那么现在就可以来分析了:
0xffffff0000092050 <kernel_stack+8016>: 0xffffff0000092070 0xffffff000008c070 0xffffff0000092060 <kernel_stack+8032>: 0x0000000000000002 0x00000000ffffffc0 0xffffff0000092070为帧指针(FP寄存器),0xffffff000008c070为返回地址(LR寄存器),返回到
<stack_test+80>,0x0000000000000002为保存的x19寄存器(由[6]可知,x19-x28是需要子寄存器保存以便返回的时候恢复现场),0x00000000ffffffc0为当前函数栈空间保存的数据(具体是什么暂时说不清楚)。
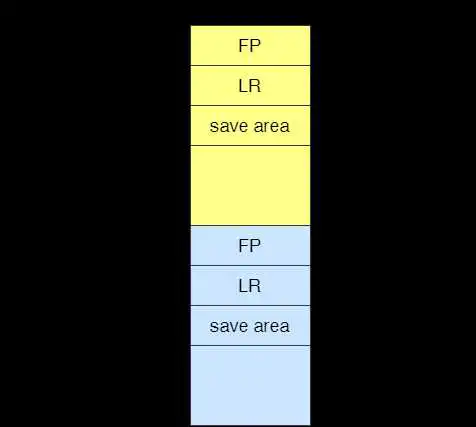
在AArch64中,返回地址(保存在x30寄存器),帧指针(保存在x29寄存器)和参数由寄存器传递。但是,当调用者函数(caller function)调用被调用者函数(callee fcuntion)时,为了复用这些寄存器,这些寄存器中原来的值是如何被存在栈中的?请使用示意图表示,回溯函数所需的信息(如SP、FP、LR、参数、部分寄存器值等)在栈中具体保存的位置在哪?
由练习7中的汇编代码和[6]可知,回溯函数所需的信息中只有FP、LR、部分寄存器保一定存在栈中,参数可能存在栈中(取决于参数的大小和多少)。保存方法:
- SP值:通过入栈和出栈FP和LR来更改和恢复值的
- 参数:参数总数不超过8个或所有参数大小不超过64字节,那么参数就保存在x0-x7寄存器中,多出来的参数放入栈中。
- FP、LR:下图所属栈顶 - 寄存器:下图所示save area
使用与示例相同的格式,在kernel/monitor.c中实现stack_backtrace。为了忽略编译器优化等级的影响,只需要考虑stack_test的情况,我们已经强制了这个函数编译优化等级。
由练习7可知,通过FP就能回溯到上一个函数的FP,直到回溯到FP为0时到头,然后根据练习8的图片可以知道LR和参数相对于FP的位置。
挑战:请思考,如果考虑更多情况(例如,多个参数)时,应当如何进行回溯操作
个人认为此题目有问题,ARM在调用函数时参数是放在x0-x7中的,所以不一定能被保存在栈中。stack_test能保存是因为在stack_test函数中使用了x19作为临时寄存器来计算被调用函数的参数x,并且x19是需要被调用函数来保存现场以便返回时恢复寄存器值[6],所以在栈中会保存参数x。
[1] LD 文件:规则详解_申小白的博客-CSDN博客_ld文件
[2] SECTIONS (biscuitos.github.io)
[3] linux内存管理1 基础知识_lgjjeff的博客-CSDN博客_ttbr0_el1
[4] raspberrypi/uart04.c at master · dwelch67/raspberrypi · GitHub
[5] gdb中x的用法_公众号:程序芯世界的博客-CSDN博客_gdb x
[6] Procedure Call Standard for the Arm® 64-bit Architecture (AArch64)
此实验是来自《现代操作系统:原理与实现》
相比于6.828,此实验有虚拟实验平台,可以不用自己配环境。实验平台链接:实验 2: ChCore操作系统-内存管理
如果希望自己配环境做实验的话,移步官方实验配置:ChCore实验环境配置
上交OS课程表和课程PPT:OS lectures
声明:本人不能保证此答案的正确性,有部分原因是问题不清晰,另一部分原因是给的代码注释较少,有些代码由于个人能力无法读懂,所以推测部分我会标注清楚。希望大家能指正我的错误。
请简单解释,在哪个文件或代码段中指定了ChCore物理内存布局。你可以从两个方面回答这个问题: 编译阶段和运行时阶段

编译阶段:回到lab1的练习3和练习4可以知道:在linker-aarch64.lds.in文件中指定了编译之后内核每段的VMA和LMA。编译阶段只确定了保留、bootloader和内核的物理内存布局。
运行阶段:当内核代码运行起来之后,buddy.c的init_buddy函数会被调用,用于初始化页面元数据和页面。一共有个4K大小页面和相应的元数据。
实现kernel/mm/buddy.c中的四个函数:buddy_get_pages(),split_page(),buddy_free_pages(),merge_page()。请参考伙伴块索引等功能的辅助函数:get_buddy_chunk()。
每个内存块都由 个物理页(4K)组成,n为内存块阶数,每个内存块的实际物理大小为
。
在init_buddy初始化时,生成个物理页(struct page)。
在代码注释中有:
struct page is the metadata of one physical 4k page
但实际上,在伙伴系统运行中,struct page其实也可以代表n阶的内存块。
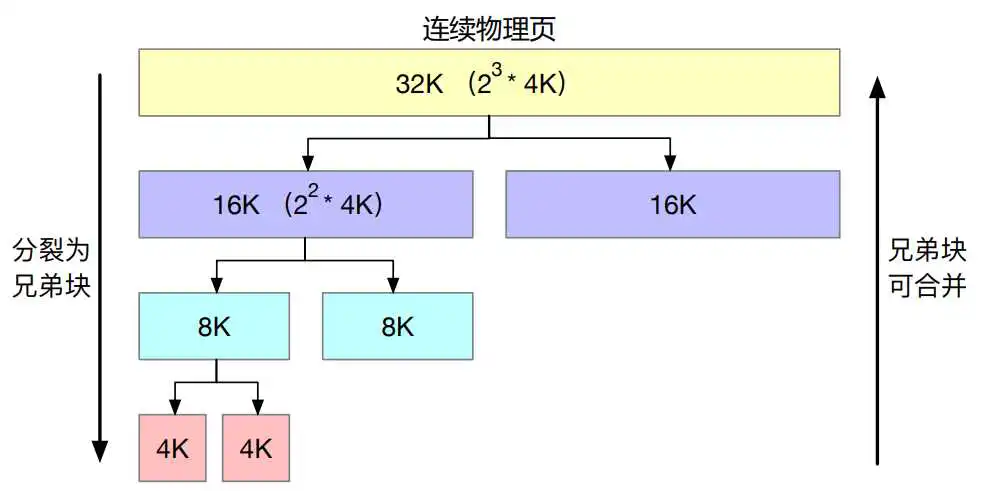
对于内存块的操作有: 1. 分割,只允许n阶内存块分割成两个n-1阶内存块,且分割后的两个内存块互为伙伴 2. 合并,只允许互为伙伴的两空闲内存块合并
伙伴系统是用于内核内存管理的,因此计算的地址时候都是用的内核虚拟地址。
内存页面池:
struct phys_mem_pool { u64 pool_start_addr; // 页面开始地址,即物理内存布局中的pages头部 u64 pool_mem_size; // 物理内存布局中的pages的物理大小 u64 pool_phys_page_num; // 物理页的数量 struct page *page_metadata; // 页面元数据的数组指针,即物理内存布局中的img_end struct free_list free_lists[BUDDY_MAX_ORDER]; // 不同阶数的空闲内存块链表 };空闲内存块链表(双向链表):
struct free_list { struct list_head free_list; // 空闲内存块链表头部 u64 nr_free; // 空闲内存块数量 }; struct list_head { struct list_head *prev; struct list_head *next; };空闲内存块链表链接的是在内存中的page metadata的node,下图为一个例子
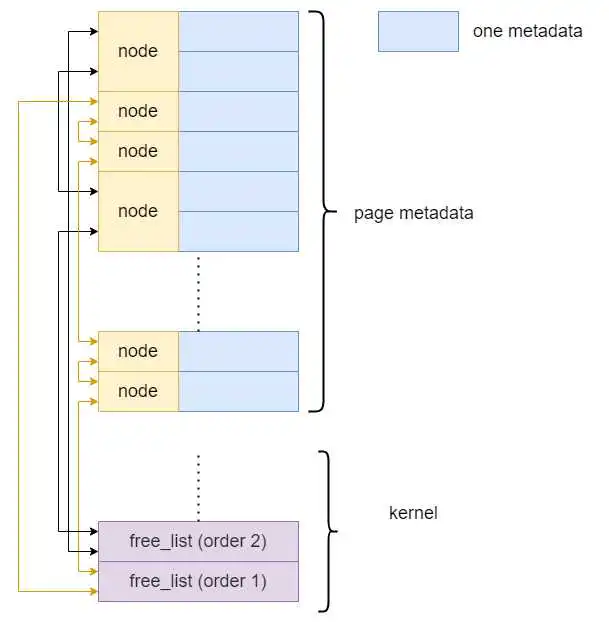
内存块(物理页)
struct page { struct list_head node; // 空闲内存块链表节点 int allocated; // 此内存块是否被分配 int order; // 此内存块的阶数 void *slab; // 暂时不用的变量 };内存块(struct page)被分配有两种可能性: 1. 程序占用了此内存块 2. 此内存块被合并进了更大的内存块,但是更大的内存块并不需要此struct page来表示
具体代码请移步gitee分支lab2
- 查找的空闲页如果阶数大于需要的阶数,需要用
split_page函数来获得适合的空闲页 - 需要将返回page设为非空闲页*
- 先将需要分割的page从free_list中取出
- 分割后的伙伴page设为空闲页*
- 将分割后的page加入相应的free_list
- 需要释放的page设为空闲页
- 调用
merge_page递归合并伙伴空闲page - 如果无法合并,则将需要释放的page加入free_list*
- page为非空闲页,则不能合并
- 查找到伙伴page,判断合并的条件
- 伙伴page为空闲页
- 伙伴page的阶数和page一样*
- 将最后合并完的page加入free_list*
- 代码编译需要先运行docker,因此需要给
chcore-lab/scripts文件夹的shell文件加执行权限。 - docker不自带gdb,需要下载。在下载之前需要先
apt-get update一下,更新一下镜像,不然找不到源。 - 实验平台只判断
/home/chcore-lab下的代码,并且是通过运行scripts文件夹下的grade-lab*程序来判断正误,所以需要给程序加执行权限。
AArch64采用了两个页表基地址寄存器,相较于x86-64架构中只有一个页表基地址寄存器,这样的好处是什么?请从性能与安全两个角度做简要的回答。
性能:AArch64架构上应用程序在使用系统调用时,无需切换页表和刷新TLB,避免了TLB刷新的开销。而x86-x64架构中,由于只有一个页表基地址寄存器,所以系统调用必须要切换页表和刷新TLB。
安全:在x86-x64架构中操作系统和应用程序是共用页表,AArch64架构则是分离,这样能保证操作系统和应用程序的空间隔离,提升安全性。
PS:此问题在银杏书第四章4.2.2中有关于性能答案
请问在页表条目中填写的下一级页表的地址是物理地址还是虚拟地址?
物理地址。从kernel/mm/page_table.h中的get_next_ptp函数可以看到,在创建了一个新的页表之后,将此页表的虚拟地址转换为了物理地址再存储到表条目里。
new_ptp_paddr = virt_to_phys((vaddr_t) new_ptp); new_pte_val.pte = 0; new_pte_val.table.is_valid = 1; new_pte_val.table.is_table = 1; new_pte_val.table.next_table_addr = new_ptp_paddr >> PAGE_SHIFT;在ChCore中检索当前页表条目的时候,使用的页表基地址是虚拟地址还是物理地址?
虚拟地址。同样是在kernel/mm/page_table.h的get_next_ptp函数中,使用宏GET_NEXT_PTP来获得下一页表地址
#define GET_PADDR_IN_PTE(entry) \ (((u64)entry->table.next_table_addr) << PAGE_SHIFT) #define GET_NEXT_PTP(entry) phys_to_virt(GET_PADDR_IN_PTE(entry))获得页表地址之后,通过计算出的index来获取当前需要的页表条目。通过以上代码和分析可知,查询页表条目时,物理地址已经转换为虚拟地址。
如果我们有4G物理内存,管理内存需要多少空间开销? 这个开销是如何降低的?
4G物理内存意味着在不允许大页并且所有内存都分配的情况下,系统一共有 个页和相应的页表条目。这些页表条目占
个字节。需要
个L2页表,
个L1页表,1个L0页表,页表占
个字节。一共需要个字节,占4G的0.09%。
开销的降低来自于
- 允许分配大页
- 出现内存被全部分配的情况几率较小
总结一下x86-64和AArch64地址翻译机制的区别,AArch64 MMU架构设计的优点是什么?
x86-x64的MMU有两种管理单元,一种是段式管理,另一种是页式管理。所以x86-x64需要先将逻辑地址翻译成线性地址再翻译成物理地址(Linux系统会设置所有段的起始地址都为0,使得逻辑地址和线性地址相同)[1]。
AArch64优点:只有虚拟地址到物理地址的映射,所以AArch64翻译次数更少,加上之前说的AArch64有两个页表基址寄存器,AArch64可以有效减少页表切换。
在文件kernel/mm/page_table中,实现map_range_in_pgtbl(),unmap_range_in_pgtbl()和query_in_pgtbl()。可以调用辅助函数:set_pte_flags(),get_next_ptp(),flush_tlb()。
这里需要注意的就是查找的递归范围和错误处理。具体代码请移步gitee分支lab2。
在AArch64 MMU架构中,使用了两个TTBR寄存器,ChCore使用一个TTBR寄存器映射内核地址空间,另一个寄存器映射用户态的地址空间,那么是否还需要通过设置页表位的属性来隔离内核态和用户态的地址空间?
需要,在AArch64 MMU架构有两个标志位来隔离内核态和用户态的地址空间(具体见[2]):
- PXN全称Privileged Execute-Never,表示只能在EL0级别(用户态)执行代码,用来阻止内核直接执行用户空间的代码。
- UXN全称Unprivileged Execute-Never,表示只能在EL0级别以上执行代码,用来阻止用户直接执行内核空间的代码。
这两个标志位能够极大地提升病毒利用漏洞的难度。
ChCore为什么要使用块条目组织内核内存?哪些虚拟地址空间在Boot阶段必须映射,哪些虚拟地址空间可以在内核启动后延迟?
因为内核内存访问的频率比较高,相比起页(4K)来说块(2M),能使TLB命中率更高,减少TLB刷新。
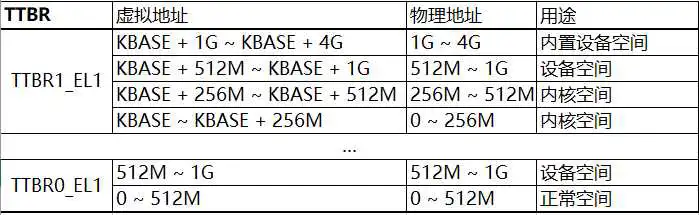
我不认同实验手册中的表20.4内存映射,我认为根据init_boot_pt函数和注释,我认为内存映射应该是这样的:
用户空间的内存映射是在boot阶段初始化(boot/mmu.c中的init_boot_pt函数)。
内核空间的内存映射一部分是在boot阶段初始化的:可用空间0xFFFF FF00 0000 0000 ~ 0xFFFF FF00 1000 0000和设备空间0xFFFF FF00 2000 0000 ~ 0xFFFF FF00 4000 0000。未初始化的部分放的是伙伴系统,而伙伴系统则是boot之后进入内核后初始化,通过map_kernel_space函数将0xFFFF FF00 1000 0000 ~ 0xFFFF FF00 2000 0000映射到物理空间。
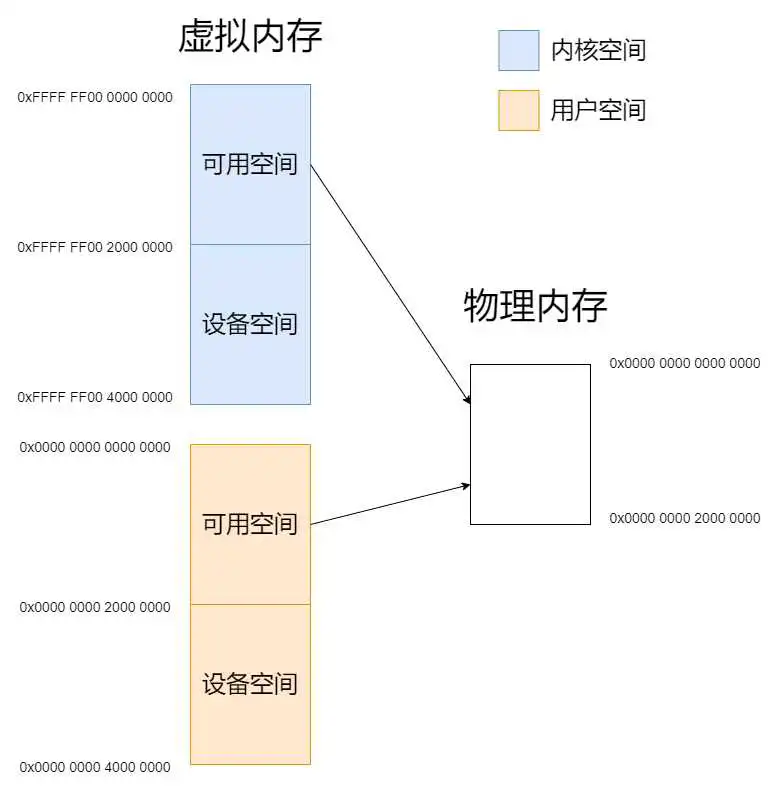
这里有一个问题就是伙伴系统的空间是否是0xFFFF FF00 1000 0000 ~ 0xFFFF FF00 2000 0000?
看init_buddy函数,伙伴系统的起始位置是img_end,物理页的起始位置(START_VADDR)计算出来是0xFFFF FF00 0180 0000,物理页结束位置(START_VADDR+npages*BUDDY_PAGE_SIZE)则为0xFFFF FF00 2043 0000。
感觉有点奇怪,暂时不知为什么伙伴系统的虚拟地址范围与map_kernel_space函数的映射范围有出入。
为什么用户程序不能读写内核内存?保护内核内存的具体机制是什么?
因为允许用户读写内核内存的话,系统容易被病毒攻击。具体机制就是通过内核态和用户态的翻译虚拟地址时用的是两个不同的页表基地址寄存器,加上标志位AP[3]来禁止用户读写内核内存。
完善map_kernel_space()函数,实现对内核空间的映射,并且可以通过kernel_space_check()的检查
先获得ttbr1寄存器地址,之后使用map_range_in_pgtbl函数映射一下就可以了,具体见lab2代码。
在运行代码的时候,映射虚拟地址时,会卡在get_next_ptp的memset函数,暂时不太清楚是为什么。一开始我以为是自己写的函数错误,导致运行的程序卡住了,没想到是memset函数卡住了。
以页粒度(4KB)映射内核空间。默认情况下(即实验2第二部分中),只有用户进程可以以页粒度中映射虚拟地址,因此需要修改函数
set_pte_flags(),来支持页粒度内核空间映射。
仔细看了页表项的union pte的设计,发现l2 block和l1 block的页表属性是一样的布局,但是l3 page在GP之后就和l2 block不同了。但是查看ARM手册之后,我发现无论是page还是block,它们的页表属性都应该是一样的布局[4]:
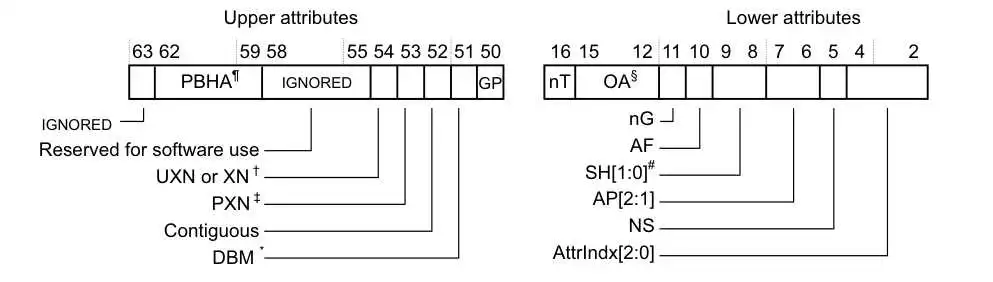
不太确定是否是ChCore使用ARMv8的区别,目前正在论坛询问。
如果块和页的页表属性都相同的话,在设置页表属性时,不需要纠结使用哪个变量。这样的话,支持页粒度内核空间映射和函数set_pte_flags没太大关系了,页表属性里面没有区分页粒度和块粒度的属性。(感觉这个题目奇奇怪怪的?
支持以块粒度(2MB)来管理用户态低空空间,修改page_table.c中的map_range_in_pgtbl()以区分需要映射的页的大小。
同样的,为了能支持块粒度和页粒度,需要在map_range_in_pgtbl中调用参数中增加一个变量:
enum psize { Block1GB = 1, Block2MB, Page4KB };根据此变量来设置页表条目:
switch (page_size) { case Page4KB: next_pte->l3_page.is_valid = true; next_pte->l3_page.is_page = true; next_pte->l3_page.pfn = pa >> L3_INDEX_SHIFT; break; case Block2MB: next_pte->l2_block.is_valid = true; next_pte->l2_block.is_table = false; next_pte->l2_block.pfn = pa >> L2_INDEX_SHIFT; break; case Block1GB: next_pte->l1_block.is_valid = true; next_pte->l1_block.is_table = false; next_pte->l1_block.pfn = pa >> L1_INDEX_SHIFT; break; default: BUG_ON(1); }[1] x86的分页机制和Linux实现
[2] Arm Architecture Reference Manual for A-profile architecture, D5.4.6
[3] Arm Architecture Reference Manual for A-profile architecture, D5.4.5
[4] Arm Architecture Reference Manual for A-profile architecture, D5.3.3 (Attribute fields in stage 1 VMSAv8-64 Block and Page descriptors)
最近在做银杏书的lab,需要通过分析ELF文件和其加载过程。
加载步骤[1]:
- 查ELF可执行文格式的有效性,比如数、序头表中(Sgment)的数量
- 寻找动态链接的“.intep”段,设置动态链接器路径
- 根据ELF可执行的序头表的述对ELF 文进行映射比如代码数据、只读数据。
- 初始化ELF 进程环境,比如进程启动时 EDX 寄存器的地址应该是DTFINI的地址。
- 将系统调用的返回地址修改成ELF可执行文件的入口点,这个入口点取决于程序的链接方式,对于静态链接的ELF可执行文件,这个程序入口就是ELF文件的文件头中e_entry所指的地址,对于动态链接的ELF可执行文件,程序入口点是动态链接器。
ELF文件由4部分组成: 1. ELF头(ELF header):用来标识文件为ELF文件并记录ELF信息(尤其是程序头表和节头表的大小和起始位置) 2. 程序头表(Program header) 3. 节(Section) 4. 节头表(Section header table)
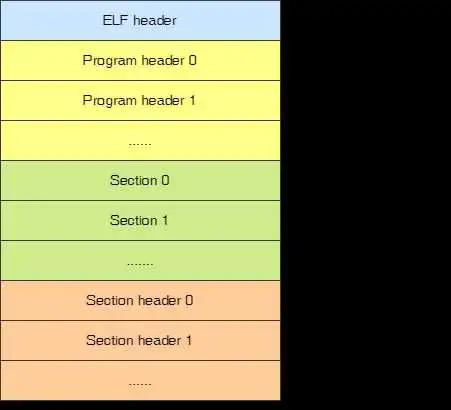
实际上,文件中不一定包含全部内容,也不一定是像以上所示来排布的,只有ELF头的位置是固定在文件开头,其余各部分是由ELF头中的值所确定的。
下面以银杏书实验中生成的内核镜像为例,分析一下ELF文件。
使用readelf -h来查看ELF头:
$ readelf -h kernel.img ELF Header: Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: AArch64 Version: 0x1 Entry point address: 0x80000 Start of program headers: 64 (bytes into file) Start of section headers: (bytes into file) Flags: 0x0 Size of this header: 64 (bytes) Size of program headers: 56 (bytes) Number of program headers: 3 Size of section headers: 64 (bytes) Number of section headers: 9 Section header string table index: 8表明此文件的字节序(Data Encoding),一般有两类:
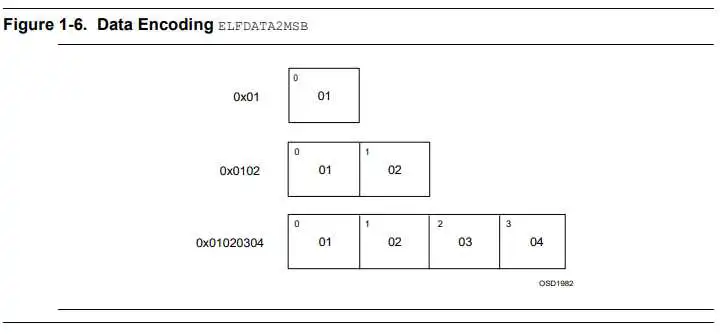
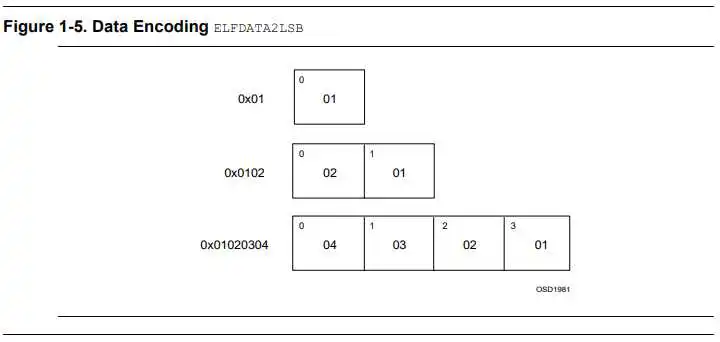
本实验为小端编码。
写明elf文件的类型,有以下几种:

在ELF文件中,字符串表是存储用来表示符号名和section name的[2]。
c语言中的字符串常量存储在.rodata中,并不存储在字符串表中
通常ELF中会有两个字符串表(一个字符串表是一个section): 1) .shstrtab存储section name 2) .strtab存储符号名
而Section header string table index就是指明.shstrtab是第几个section。
以此实验为例子,这就代表.shstrtab是第8个section。
通过readelf命令可以查看此ELF文件中所有的字符串表:
$ readelf -S build/kernel.img | grep STRTAB [ 7] .strtab STRTAB 0000000000000000 00020988 [ 8] .shstrtab STRTAB 0000000000000000 00020c97一个程序头表一个标识segment。以下图片展示了每个程序头在可执行文件中的分布[3]:
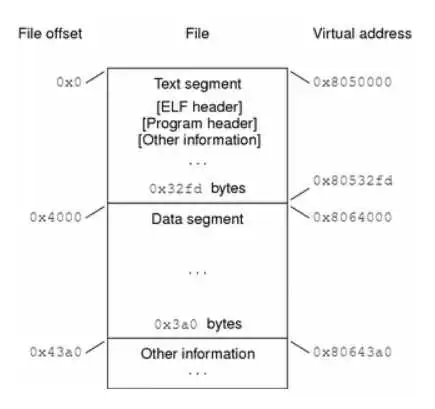
程序头表是告诉操作系统如何加载可执行文件到内存,一般是逻辑上将对应segment复制到虚拟内存,等真正执行的时候在通过缺页中断加载进物理内存。对于程序一般来说有两个segment,text segment(只读的指令和数据)和data segment(可读写的数据和指令)。以下图片展示了segment与虚拟内存的映射[3]:
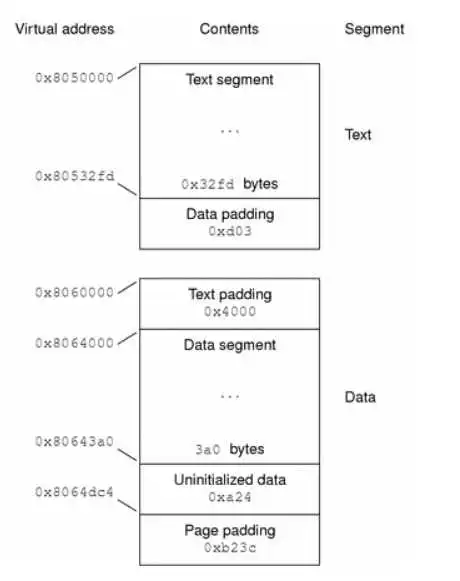
通过readelf命令可以查看ELF文件中程序头表:
$ readelf -l -w build/kernel.img Elf file type is EXEC (Executable file) Entry point 0x80000 There are 3 program headers, starting at offset 64 Program Headers: Type Offset VirtAddr PhysAddr FileSiz MemSiz Flags Align LOAD 0x0000000000010000 0x0000000000080000 0x0000000000080000 0x000000000000b5b0 0x000000000000b5b0 RWE 10000 LOAD 0x000000000001c000 0xffffff000008c000 0x000000000008c000 0x00000000000040f8 0x000000000000c100 RWE 10000 GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 0x0000000000000000 RW 10 Section to Segment mapping: Segment Sections... 00 init 01 .text .rodata .bss 02segment到section的映射:加载一个segment就是将相同类型的setion一起加载到内存中[4]。
因为存在动态链接,所以在加载完segment之后,需要将动态链接的指令、数据等进行重定位,这时就用到了section。section是重定位的最小单位,包含链接目标对象文件的所有信息(注意:链接的时候需要节,但运行时不需要[4])。
$ readelf -S build/kernel.img There are 9 section headers, starting at offset 0x20cd8: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] init PROGBITS 0000000000080000 00010000 000000000000b5b0 0000000000000008 WAX 0 0 4096 [ 2] .text PROGBITS ffffff000008c000 0001c000 00000000000011dc 0000000000000000 AX 0 0 8 [ 3] .rodata PROGBITS ffffff0000090000 00020000 00000000000000f8 0000000000000001 AMS 0 0 8 [ 4] .bss NOBITS ffffff0000090100 000200f8 0000000000008000 0000000000000000 WA 0 0 16 [ 5] .comment PROGBITS 0000000000000000 000200f8 0000000000000032 0000000000000001 MS 0 0 1 [ 6] .symtab SYMTAB 0000000000000000 00020130 0000000000000858 0000000000000018 7 46 8 [ 7] .strtab STRTAB 0000000000000000 00020988 000000000000030f 0000000000000000 0 0 1 [ 8] .shstrtab STRTAB 0000000000000000 00020c97 000000000000003c 0000000000000000 0 0 1[1]俞甲子, 石凡, 潘爱民. 程序员的自我修养:链接,装载与库[M]. 电子工业出版社, 2009.
[2] ELF:String table、Symbol table与Relocation - ILD (insidelinuxdev.net)
[3] Dynamic Linking (Linker and Libraries Guide) (oracle.com)
[4] Executable and Linkable Format 101 - Part 1 Sections and Segments
[5] What's the difference of section and segment inELFfile format
最近Deniffer在折腾什么呢? 答案是启航之旅V2!
启航之旅V2的详细介绍可以看
MIT6.S081启航之旅V2_哔哩哔哩_bilibili
- 每周1-2期视频讲解内容
- 每周定期和每个同学 one-one对齐进度 ()
- 当你
进行完各种尝试之后还是没有办法推进进度的时候,请立刻马上找Deniffer沟通 - ourdiz讨论网站
这是我花两个月打造的配套6.S081的课程,感兴趣的同学可以给我发邮件面试哈, 邮件地址: 报名还有一周就结束啦
到此这篇操作系统原理及应用(操作系统原理及应用电子书)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/kjbd-yiny/81284.html