
目录
一、概述
二、梯度下降法
2.1 梯度下降(GD)
2.2 随机梯度下降(SGD)
2.3 小批量梯度下降法(MBGD)
2.4 优缺点
三、动量优化法
3.1 SGD+Momentum
3.2 NAG
四、自适应学习率
4.1 AdaGrad
4.2 RMSProp
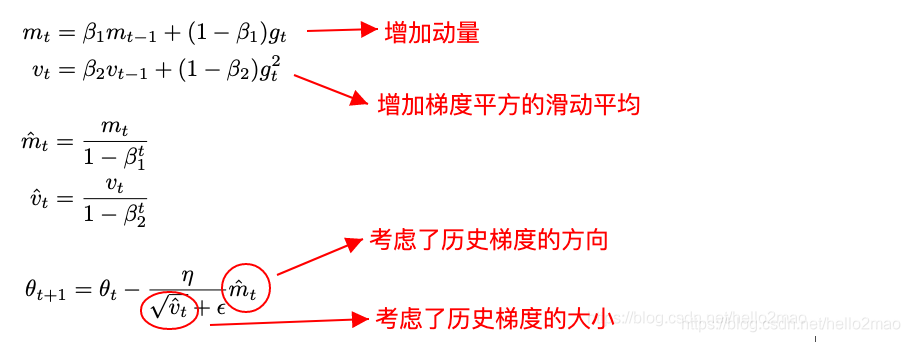
4.3 Adam
五、性能比较
六、Ref
记录下常见的优化算法。
重点是这篇paper:https://arxiv.org/pdf/1609.04747.pdf
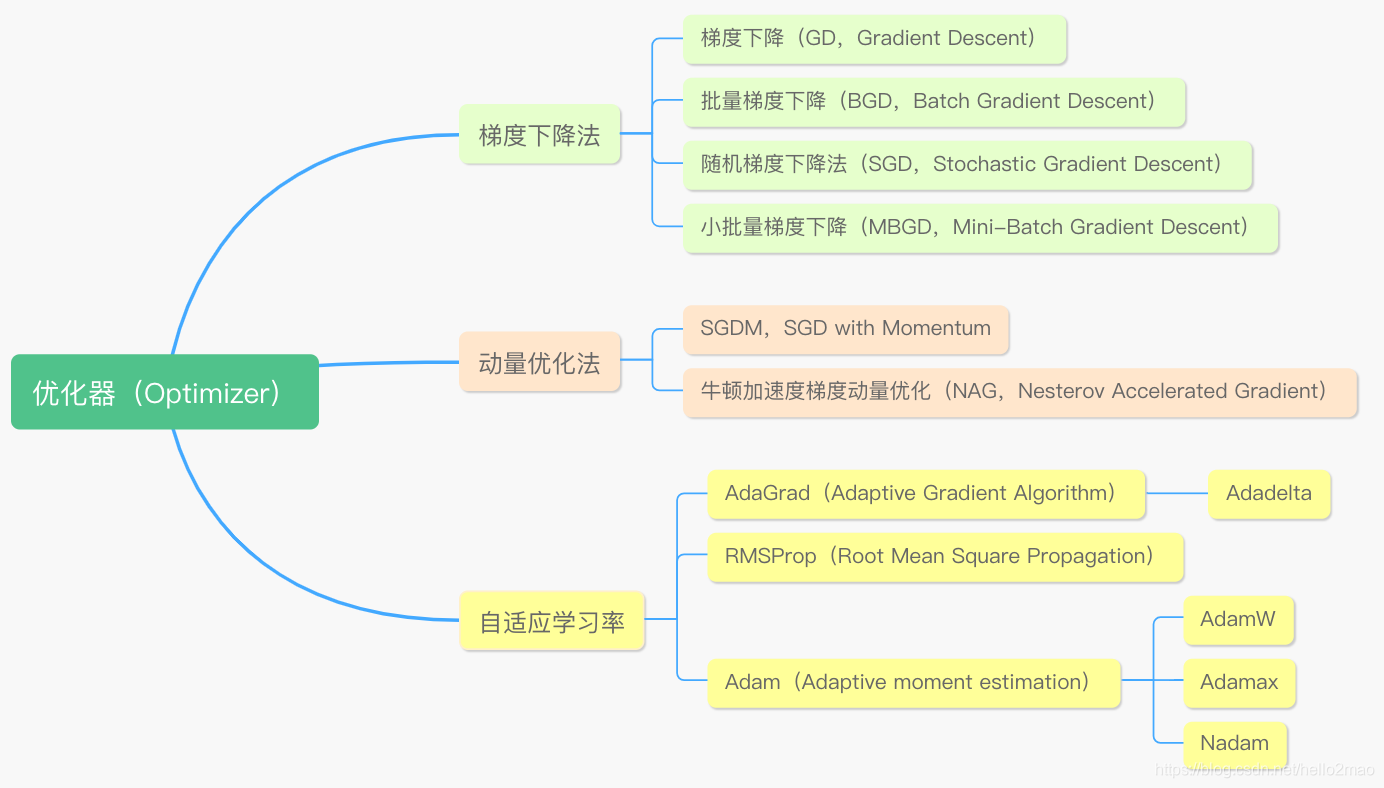
优化算法是训练过程中寻求最优解的方法,分类如下:
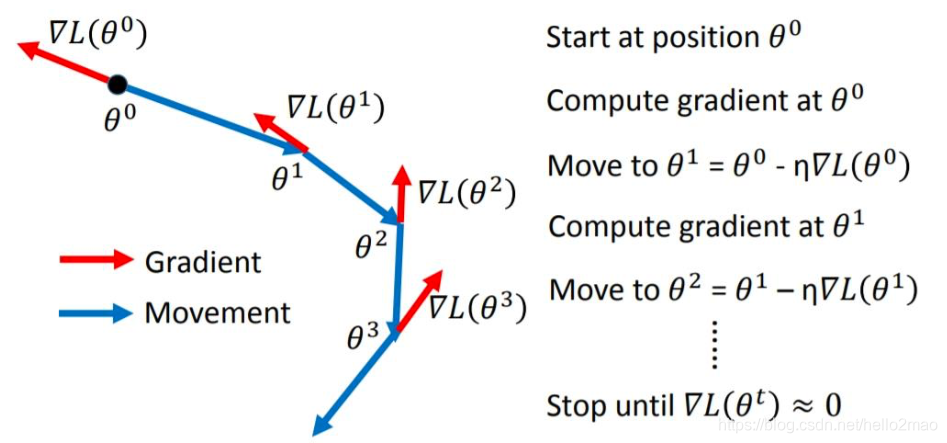
梯度下降是通过 Loss 对的一阶导数来找下降方向,并且以迭代的方式来更新参数,更新方式为 :
其中,为学习率。
随机梯度下降法(Stochastic Gradient Descent,SGD):均匀地、随机选取其中一个样本,用它代表整体样本,即把它的值乘以N,就相当于获得了梯度的无偏估计值。
SGD的更新公式为:
每次迭代使用m个样本来对参数进行更新,MBGD的更新公式为:
优点:
- 简单;
缺点:
- 训练速度慢;
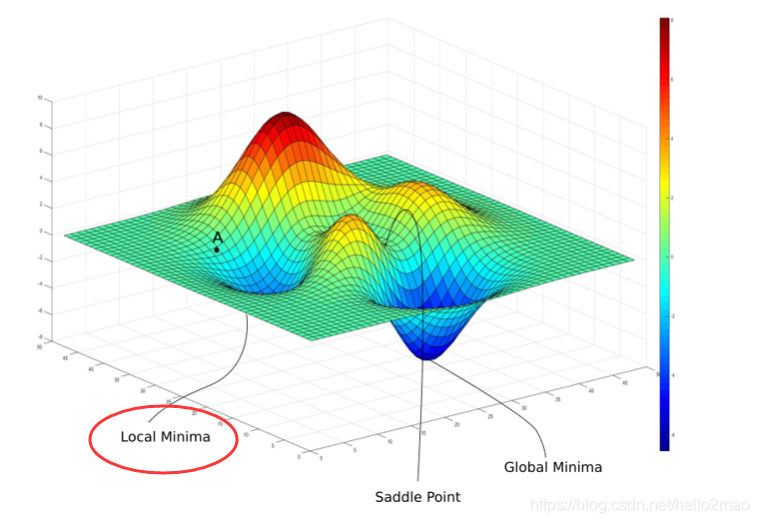
- 会进入Local Minima或者Saddle Point导致gradient为0;
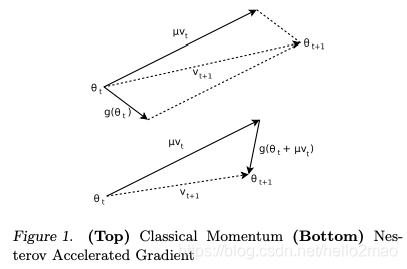
使当前训练数据的梯度受到之前训练数据的梯度的影响,即增加一个动量。
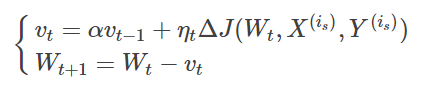
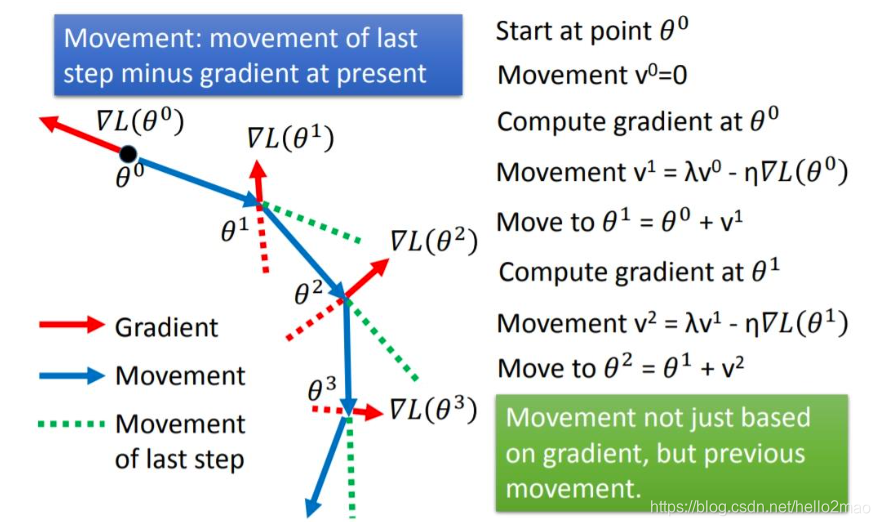
牛顿加速梯度动量优化方法(NAG, Nesterov accelerated gradient):拿着上一步的速度先走一小步,再看当前的梯度然后再走一步。
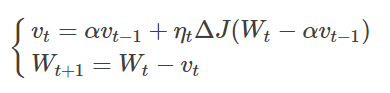
SGDM对比NAG如下:
AdaGrad算法通过记录历史梯度,能够随着训练过程自动减小学习率。
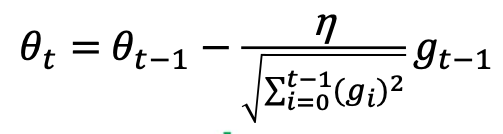
RMSProp简单修改了Adagrad方法,它做了一个梯度平方的滑动平均。
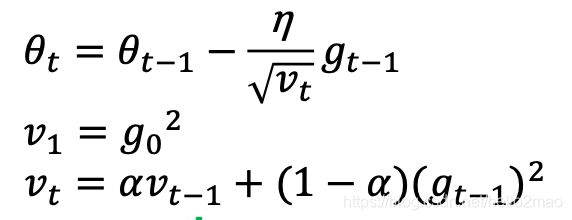
Adam看起来像是RMSProp的Momentum版。
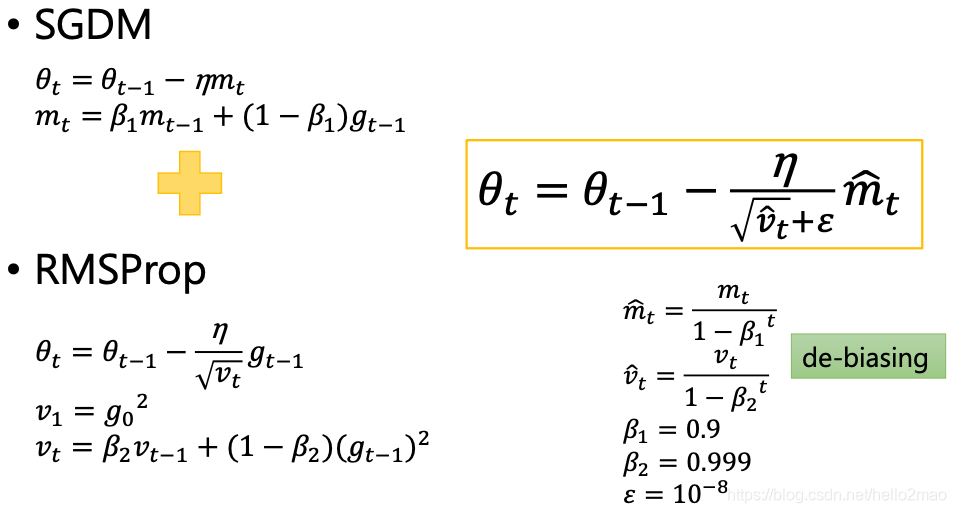
即:
用一份数据配合pytorch简单测试比较下几个优化器:
代码和数据见:https://github.com/hello2mao/Learn-MachineLearning/tree/master/DeepLearning/OptimizerTest
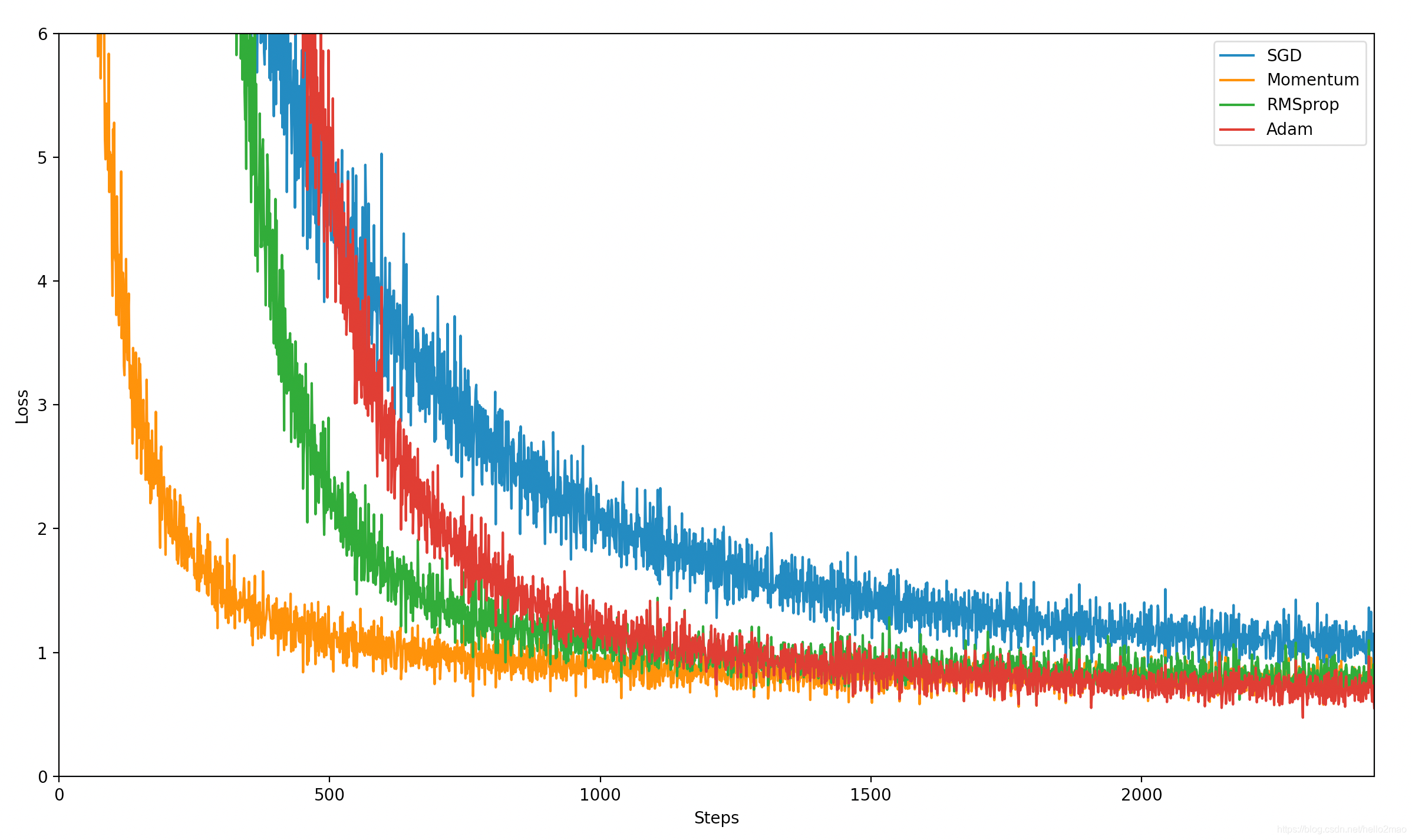
自己测试的数据果然看不出优劣,可以看下其他人的测试结果(详见:https://shaoanlu.wordpress.com/2017/05/29/sgd-all-which-one-is-the-best-optimizer-dogs-vs-cats-toy-experiment/):
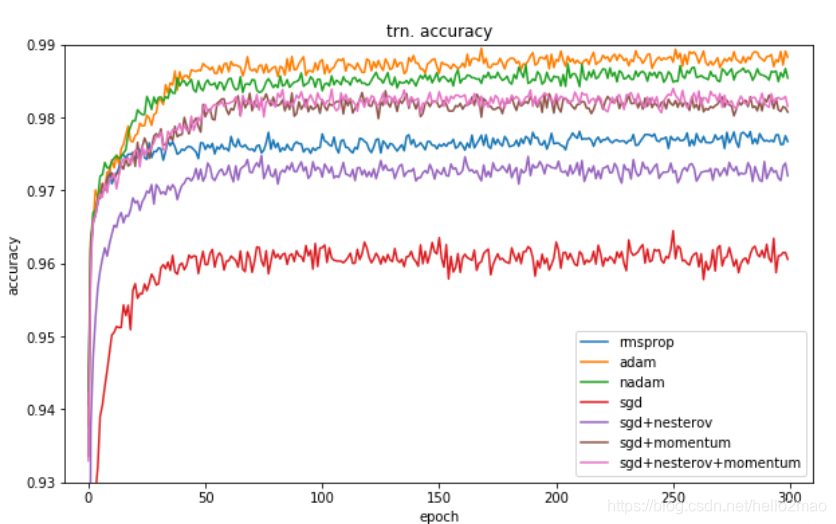
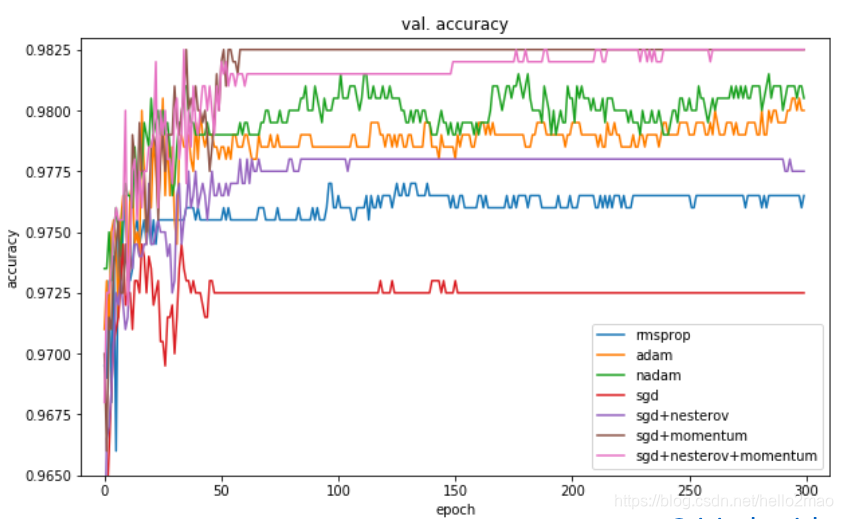
可以看到,在训练数据上,Adam表现比较好,在验证数据上,SGDM表现比较好,所以一般选择Adam或者SGDM ^_^.
- An overview of gradient descent optimization algorithms
- 比Momentum更快:揭开Nesterov Accelerated Gradient的真面目
- CS231n Convolutional Neural Networks for Visual Recognition
- https://www.bilibili.com/video/BV1Wv411h7kN?p=16
- https://www.bilibili.com/video/BV1Wv411h7kN?p=12
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/hd-xnyh/26828.html