
目前刚开始积累oracle函数,没有做分类,遇到一个加一个,后面融会贯通之后再做总结再做分类
Trunc(17.991,0)=Trunc(17.991)17,
Trunc(17.991,1)=17.9,
Trunc(sysdate,’Year’)=xxxx-1-1,
Trunc(sysdate,’MM’)=xxxx-xx-1,
Trunc(sysdate,’dd’)=Trunc(sysdate)=xxxx-xx-xx:0:00:00,
decode(字段或字段的运算,值1,值2,值3)
这个函数运行的结果是,当字段或字段的运算的值等于值1时,该函数返回值2,否则返回值3
当然值1,值2,值3也可以是表达式,这个函数使得某些sql语句简单了许多
sign(正数)=1,sign(负数)=-1,sign(0)=0,
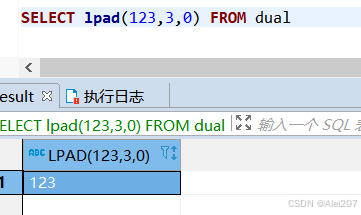
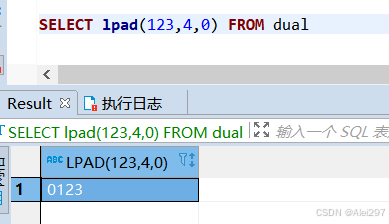
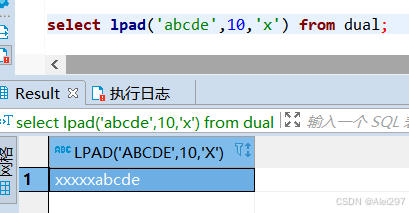

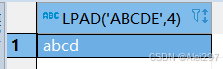
length此时等于4保留id的前四位
(1)将char或varchar2类型的string转换为一个number类型的数值,需要注意的是,被转换的字符串必须符合数值类型格式,如果被转换的字符串不符合数值型格式,Oracle将抛出错误提示;
(2)to_number和to_char恰好是两个相反的函数;
(3)如果数字在格式范围内的话,就是正确的,否则就是错误的;如:
(4)可以用来实现进制转换;16进制转换为10进制:
使用方法一:instr( string1, string2 ) >0 / instr(源字符串, 目标字符串)>0
使用方法二:instr( string1, string2 ) / instr(源字符串, 目标字符串)字符查找函数
在string1中查找string2返回string1中第一次出现string2的下标
例2.1

例2.2

使用方法三:instr( string1, string2 ,start_position,times) instr(源字符串, 目标字符串,开始位子,第几次出现)
例3.1
1.simple CASE(简单形式) 类似DECODE函数
simple case的表达式:
每个when单个值匹配, 当expr匹配到compare时返回then后面value,匹配不到值的时候就返回else中的defualtvalue,decode函数也是这个用法
也跟switch case类似语句
最多支持255个参数,其中每对When…Then算作2个参数
2.searched CASE(查询形式)
searched case的表达式:
转自https://blog.csdn.net/lanxingbudui/article/details/,
语句讲解
1、on后面的关联条件成立时,可以update、delete。
2、on后面的关联条件不成立时,可以insert。
3、当源表中不存在数据,而目标表中存在的数据可以删除。
注意事项:
1、只会操作“操作表”,源表不会有任何变化。
2、不一定要把update,delete,insert 操作都写全,可以根据实际情况。
3、merge into效率很高,强烈建议使用,尤其是在一次性提交事务中,可以先建一个临时表,更新完后,清空数据,这样update锁表的几率很小了。
4、Merge语句还有一个强大的功能是通过OUTPUT子句,可以将刚刚做过变动的数据进行输出。我们在上面的Merge语句后加入OUTPUT子句。
5、可以使用TOP关键字限制目标表被操作的行,如图8所示。在图2的语句基础上加上了TOP关键字,我们看到只有两行被更新
函数:replace()
含义:替换字符串
用法:replace(原字段,“原字段旧内容“,“原字段新内容“)
Oracle中的EXISTS和IN操作符都用于查询某个集合的值是否存在于另一个集合中,但它们在处理效率和用法上存在显著差异。
EXISTS通常用于子查询,它检查子查询是否至少返回一行数据。如果子查询返回至少一行数据,那么主查询将返回满足条件的记录。
EXISTS的查询效率较高,因为在执行子查询之前,系统会先将主查询挂起,待子查询执行完毕后,
存放在临时表中再执行主查询。例如,当外表(即主查询)的数据量非常大而内表(即子查询)的数据量较小时,使用EXISTS的效率更高。
IN操作符也用于子查询,但它是将子查询的结果与主查询进行比较,检查主查询中的字段是否在子查询的结果中。
当处理大表和复杂查询时,IN可能会导致性能下降。例如,当内表的数据量非常大而外表的数据量较小时,使用IN可能更有优势。
IN操作符用于匹配某个值是否在一个集合中,而EXISTS操作符用于判断子查询返回的结果集是否非空。
IN操作符会将集合中的值进行去重,而EXISTS操作符不会。
此外,IN操作符的执行效率相对较低,因为需要先计算出集合的所有值,而EXISTS操作符可以在子查询得到第一个匹配项时就停止查询,效率较高。
综上所述,选择使用EXISTS还是IN主要考虑查询效率问题。
如果外表的数据量非常大而内表的数据量较小时,通常使用EXISTS效率更高;
反之,如果内表的数据量非常大而外表的数据量较小时,使用IN可能更有优势
Oracle中的NOT EXISTS和NOT IN在处理查询时存在显著的区别,主要体现在查询效率和处理空值的方式上。
查询效率:NOT EXISTS通常比NOT IN效率更高。这是因为当使用NOT IN时,内外表都可能进行全表扫描,且无法使用索引,导致查询速度较慢。
相比之下,NOT EXISTS的子查询仍然能够使用表上的索引,从而提高了查询效率。
此外,如果查询语句使用了NOT IN,那么内外表都可能进行全表扫描,没有用到索引,而NOT EXISTS的子查询依然能用到表上的索引,因此无论哪个表更大,使用NOT EXISTS都比使用NOT IN要快。
处理空值的方式:对于NOT EXISTS查询,内表存在空值对查询结果没有影响,而外表存在空值的那条记录最终会输出。
而对于NOT IN查询,内表存在空值将导致最终的查询结果为空,且外表存在空值的那条记录最终将被过滤,其他数据不受影响。
综上所述,虽然NOT EXISTS和NOT IN在语法上可能看起来相似,但在实际应用中,选择使用哪一个取决于具体的查询需求和数据库结构。
在大多数情况下,为了提高查询效率,推荐使用NOT EXISTS而不是NOT IN,尤其是在处理包含大量数据的表时。
获取数字的绝对值
SELECT ABS(10) FROM DUAL; – 返回 10
SELECT ABS(-10) FROM DUAL; – 返回 10
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/haskellbc/65828.html