


论文导读
2022年论文导读第十六期(总第五十六期)
目 录
|
1 |
3DJCG: A Unified Framework for Joint Dense Captioning and Visual Grounding on 3D Point Clouds |
|
2 |
ATPFL: Automatic Trajectory Prediction Model Design under Federated Learning Framework |
|
3 |
Multi-instance Point Cloud Registration by Efficient Correspondence Clustering |
|
4 |
Neural Compression-Based Feature Learning for Video Restoration |
|
5 |
Infrared Invisible Clothing: Hiding from Infrared Detectors at Multiple Angles in Real World |
|
6 |
Classification-Then-Grounding: Reformulating Video Scene Graphs as Temporal Bipartite Graphs |
01
3DJCG: A Unified Framework for Joint Dense Captioning and Visual Grounding on 3D Point Clouds
作者:蔡代钢1,赵立晨1,张晶1,*,盛律1,徐东2
单位:1北京航空航天大学,2悉尼大学
邮箱:
,
,
,
,
论文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Cai_3DJCG_A_Unified_Framework_for_Joint_Dense_Captioning_and_Visual_CVPR_2022_paper.pdf
*通讯作者
通过观察到3D密集描述生成(Dense Captioning)和3D视觉定位(Visual Grounding)任务本质上包含共享和互补信息,本文提出了一个统一的框架来共同解决这两个不同但密切相关的任务,(1)本文使用一个和任务无关的三维对象检测器,属性和关系特征增强模块,和两个轻量级任务特定头(即描述生成头和视觉定位头)模块来实现两个任务的联合训练。(2)本文的模型在3D数据密集描述生成和视觉定位任务上的性能取得了SOTA:ScanRefer数据集[1]--视觉定位任务,Scan2Cap数据集[2]--密集描述生成任务。
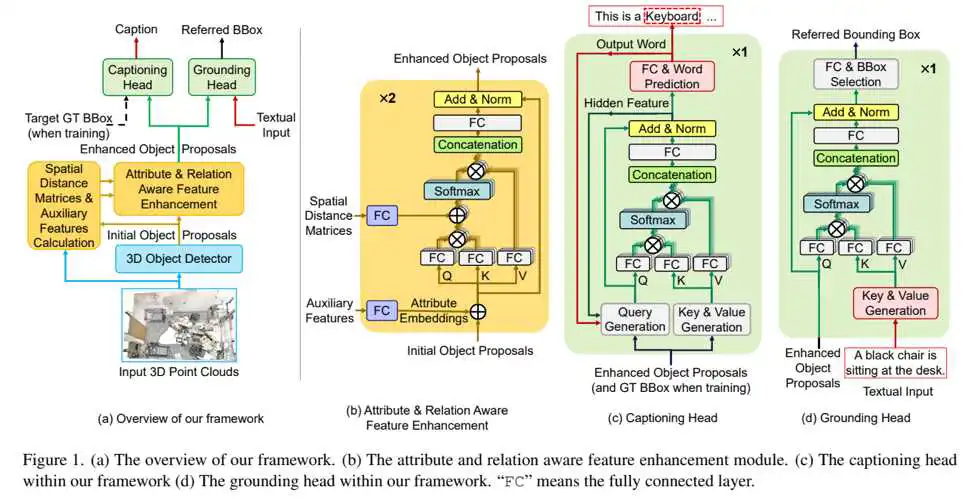
图1 3DJCG总体网络架构
如图1 (a)所示,本文所提出的网络框架由三个模块组成:1)目标检测模块,2)属性和关系感知特征增强模块,以及3)任务特定的描述生成头和视觉定位头。目标检测模块和特征增强模块是任务无关的,由两个任务共享,描述生成头和视觉定位头分别用于密集描述生成和视觉定位任务。具体而言,本文使用VoteNet[3]对点云进行聚类,然后借鉴FCOS[4]的思想,通过预测中心点和目标对象每一侧之间的距离来生成初始proposal。接着通过任务无关的属性和关系感知特征增强模块来增强proposal的特征,生成增强的proposal。最后将增强的proposal分别输入到描述生成头和视觉定位头中,并为每个任务生成最终结果。
具体而言,首先,如图1 (b)所示,属性和关系感知特征增强模块由堆叠的两层多头自注意力层(multi-head self-attention)组成,其中包含由几个全连接层组成的属性编码模块和关系编码模块,属性编码模块的作用是为了将物体自身的一些特性(比如颜色,大小等信息)进行编码,而关系特征编码模型,则是对每两个对象间的距离等信息进行编码。其次,如图1 (c)和图1 (d)所示,描述生成头模块和视觉定位头模块都是由一层多头交叉注意力模块(multi-head cross-attention)组成,用于融合视觉和文本特征。
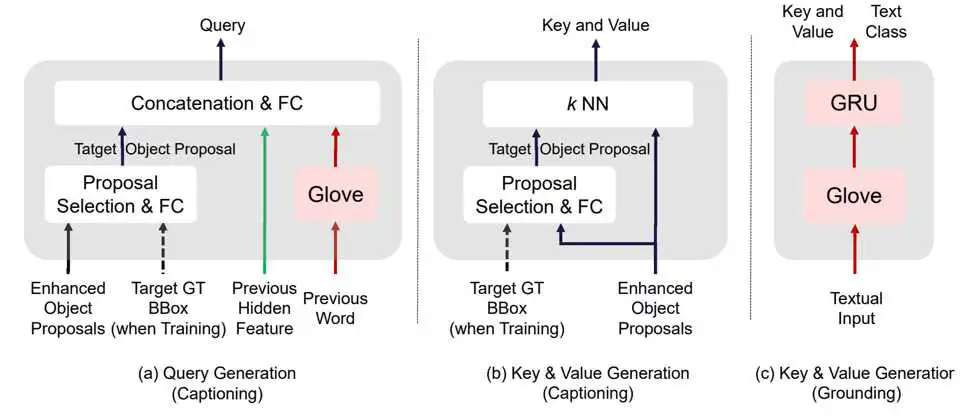
图2 Captioning head 和 Grounding head 中Query, Key & Value的获取
如图2所示,对于描述生成头(Captioning head),本文使用了K最近邻策略来选择距离target proposal最近的前K个proposal作为Cross-Attention的输入Key和Value,使用target proposal,前一个词语以及之前的hidden feature的融合特征作为Query;对于视觉定位头(Grounding head),本文使用预训练的GloVE模型以及GRU模型来提取出文本的特征作为Key和Value,使用proposal的特征作为Query。
表1 3DJCG与其他模型在Scan2Cap[2]数据集上密集描述生成(Dense Captioning)的结果

表2 3DJCG与其他模型在ScanRefer[1]数据集上视觉定位(Visual Grounding)的结果
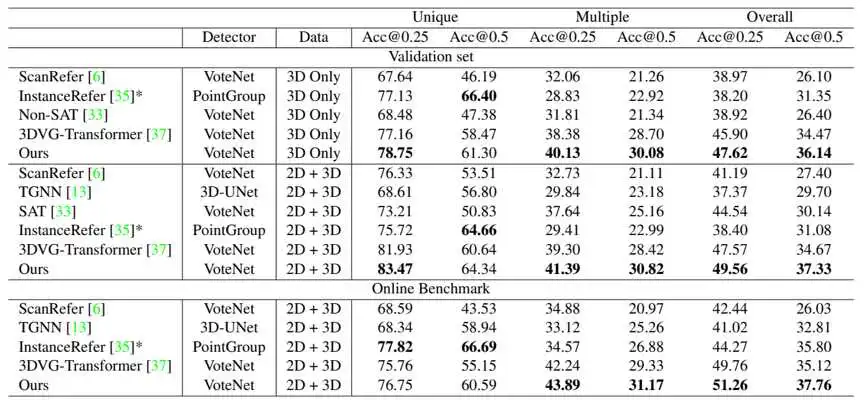
本文所提出的模型在3D数据集上的描述生成任务和视觉定位任务上的性能取得了SOTA。特别是在密集描述生成任务上,在“2D+3D”的设置下(输入数据为点云XYZ坐标+法线信息+multiviews多视图信息),本文的方法分别在C@0.5IoU,B-4@0.5IoU和R@0.5IoU三个指标上实现了10.4%、7.71%和6.32%的显著性能提升。
参考文献
[1]Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. ScanRefer: 3D object localization in RGB-D scans using natural language. In ECCV, 2020.
[2]Zhenyu Chen, Ali Gholami, Matthias Nießner, and Angel X Chang. Scan2Cap: Context-aware dense captioning in rgb-d scans. In CVPR, 2021.
[3]Charles R. Qi, Or Litany, Kaiming He, and Leonidas J. Guibas. Deep hough voting for 3D object detection in point clouds. In ICCV, 2019.
[4]Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In ICCV, pages 9627–9636, 2019. 3, 5
02
ATPFL: Automatic Trajectory Prediction Model Design under Federated Learning Framework
作者:王春楠1,陈翔1,王俊哲1,王宏志1,2†
单位:1哈尔滨工业大学计算学部,2鹏城实验室
邮箱:
,
,
@stu.hit.edu.cn,
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Wang_ATPFL_Automatic_Trajectory_Prediction_Model_Design_Under_Federated_Learning_Framework_CVPR_2022_paper.html
论文博客介绍:
https://mp.weixin..com/s/W2ZtqwLVEzINOtl-m2i2og
†通讯作者
研究动机:
虽然轨迹预测(Trajectory Prediction,简称TP)模型在计算机视觉和机器人领域取得了巨大的成功,但是,其模型结构和模型训练方案的设计极度依赖于繁重的人工工作和领域知识,这对普通用户并不是很友好。此外,现有研究忽略了联邦学习(Federated Learning,简称FL)场景,未能充分利用包含丰富轨迹场景的分布式多源轨迹数据集来学习更强大的TP模型。在本篇论文,我们弥补了上述缺陷,并提出了ATPFL框架,来帮助用户联合多源轨迹数据集来自动设计和训练出一个强大的TP模型。在ATPFL中,我们通过分析和总结现有的工作,构建了一个有效的TP搜索空间。然后,根据该搜索空间的特点,设计了一种关系-序列感知的搜索策略,以实现了TP模型的自动化设计。最后,我们找到合适的联邦训练方法,分别支持FL框架下的TP模型搜索和最终模型训练,确保搜索效率和最终模型性能。大量的实验结果表明,ATPFL可以帮助用户快速获取联邦性能良好的TP模型,比在单源数据集上训练的人造TP模型取得更好的实用结果。
图1 ATPFL的整体框
方案概述:
在ATPFL中,本研究设计了一个适合TP领域的AutoML算法,从而实现了TP模型的自动设计。我们总结了TP模型的设计过程,收集了每个步骤的可用操作,并通过分析现有的TP模型来确定每个操作的限制。然后将上述经验和知识整合在一个关系图中,从而构建了一个有效的TP领域的搜索空间。此外,考虑到搜索空间中操作之间复杂的约束关系以及不同步骤操作之间的时间关系,本研究还设计了一种关系-序列感知的搜索策略(relation-sequence-aware)来有效地探索TP搜索空间。与传统的AutoML 的传统搜索策略在模型设计过程中忽略操作之间的关系或忽略历史序列信息相比,本研究提出的策略将会更有效,更适合于TP 模型的搜索空间。
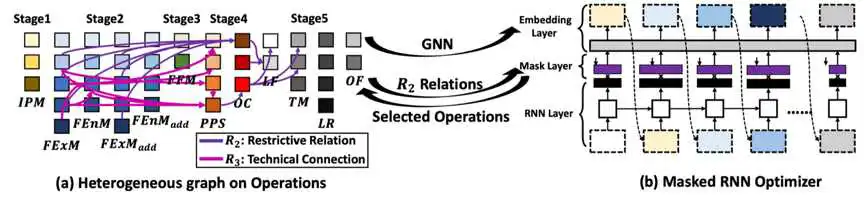
图2 关系-序列感知的搜索策略的整体框架
实验结果:
我们将ATPFL与两种常用的AutoML搜索策略进行了比较:一种是结合了递归神经网络控制器的RL(强化学习)搜索策略,另一种是基于EA(进化算法)的多目标优化搜索策略,以及AutoML中常用的基线随机搜索。我们将ATPFL中的关系-序列感知策略替换为这三种搜索策略,以检验它们在TP模型和FL框架下的性能。
除此之外,我们还以4种最先进TP模型:Social Ways、STGAT、 STGCNN 与 SGCN 为基线,来说明FL框架下自动TP模型设计的重要性。FL框架下4个AutoML算法和4个手动设计的TP模型的性能如表1和图3所示,图4给出了了ATPFL算法搜索出来最终的TP模型。
表1 ATPFL、AutoML算法和手动设计的TP模型的性能比较。第一部分考察了现有TP模型在单源TP数据集上的性能。第二部分在TP模型上比较了不同的联邦训练方法。第三部分比较了FL框架下不同的AutoML方法。
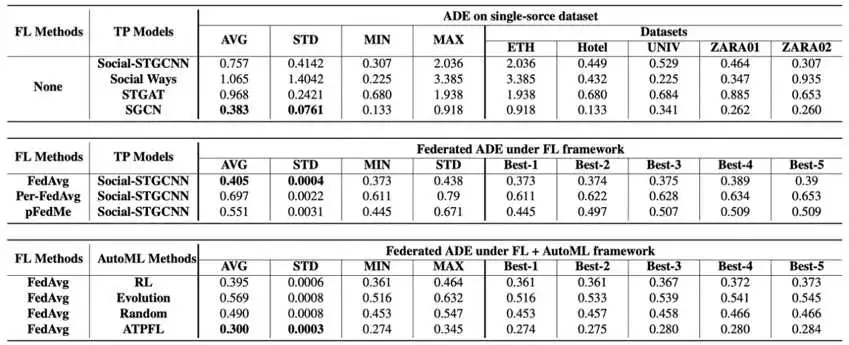
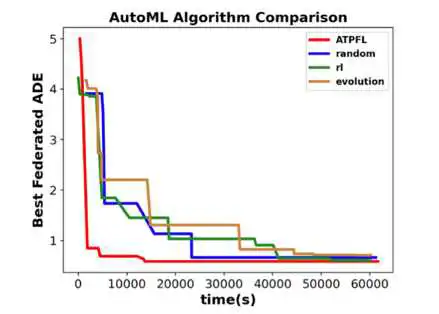
图3 不同AutoML算法搜索的最优TP模型的联邦性能
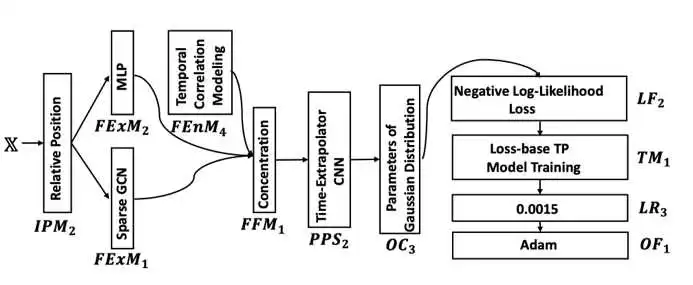
图4 ATPFL搜索出来的最佳TP模型设计方案
03
Multi-instance Point Cloud Registration by Efficient Correspondence Clustering
基于高效对应点对聚类的多物体点云配准算法
作者:唐玮璇,邹丹平*
单位:上海交通大学
邮箱:
,
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Tang_Multi-Instance_Point_Cloud_Registration_by_Efficient_Correspondence_Clustering_CVPR_2022_paper.html
*通讯作者
我们使用的流程还是遵照一对一点云配准的流程,我们使用state-of-art的点云特征提取器,比如PREDATOR或者D3Feat,提取点云特征并进行特征匹配,得到correspondence之后从中恢复出多个位姿,我们的contribution就是这个从correspondences中恢复位姿的算法,主要思想是刚体变换不改变线段长度,根据这个线索对correspondence进行聚类。
(a)
(b)

(c)
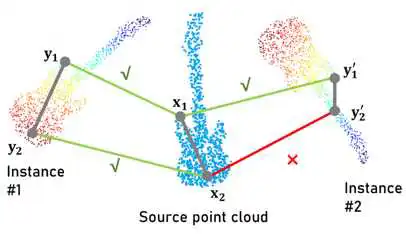
比如图(a)4个correspondences,就是这四条线,x1x2=y1y2不能保证x1y1和x2y2都是inlier,x1x2!=y1’y2’一定可以确定x1y1’和x2y2’中一定有至少一个outlier。
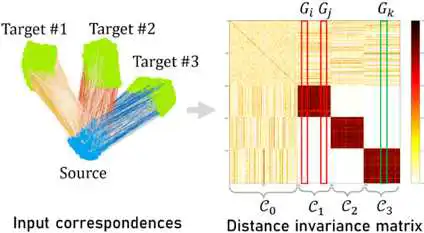
我们使用一个compatibility score来描述两对correspondence之间的长度一致性。比如,(b)图左边是输入的correspondences,右边是n*n的compatibility矩阵,每一个点代表一对correspondence的compatibility score,颜色越深代表越一致。可以看到,用这个一致性就可以区分出明显的3类correspondence,可以分出三个位姿。算法流程如图(c)所示,我们算法的两个主要模块就是clustering和refinement,然后因为输入的correspondence数量非常大,我们对它进行了降采样,降采样分类完了之后使用一个升采样模块得到所有correspondence的类别,然后分类计算位姿并refine结果。
多物体点云配准目前没有合适的评价标准,我们参考一对一点云配准和retrieval任务提出了三个评价标准,就是Mean Hit Recall,Mean Hit Precision和Mean Hit F1。首先对于一对输入点云,我们会得到k个估计出来的位姿,同时我们还有一堆n个gt位姿,我们使用匈牙利算法找到位姿与gt位姿的匹配,然后对于每一个估计出来的位姿T,我们计算它与对应的G之间的rotation error和translation error,如果rotation error和translation error都在阈值范围内,就算这一个位姿T估计正确。统计这一对点云中,估计位姿的recall和precision还有f1,最后平均所有输入点云对的recall,precision还有f1得到这三个评估数据。
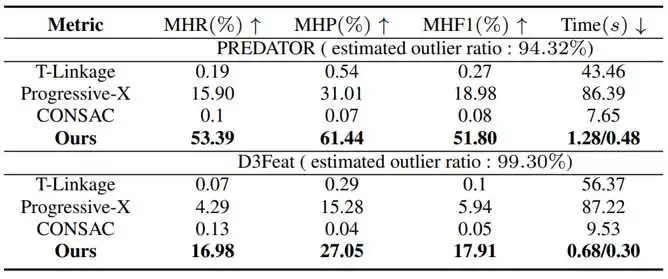
我们分别在仿真数据集和真实数据集上进行了实验验证,这是在仿真数据集的结果,这个仿真数据集中每一个sample都包含20个要估计位姿的instance,可以看到我们的效果远超现有SOTA算法,在outlier ratio为70%的correspondences集合中,我们的方法可以正确配准多达20个实例,而且速度比现有方法快至少10倍。
这是在Scan2CAD上的可视化结果。


这是我们用RGBD相机拍的一些数据,我们拍了一张物体的RGBD图,然后用SIFT做特征匹配得到correspondences配准它在场景中的所有位姿,可以看到我们的方法效果很好,而且运行速度是实时的。这里用的是SIFT做特征匹配,但是我们的算法对于用什么特征得到特征匹配没有要求的,用2D或者3D的特征都可以,之前的实验可以看出3D的特征,即使是现在的SOTA,比如PREDATOR,效果还是有待提升。这里RGB信息已知,所以我们这里用SIFT。
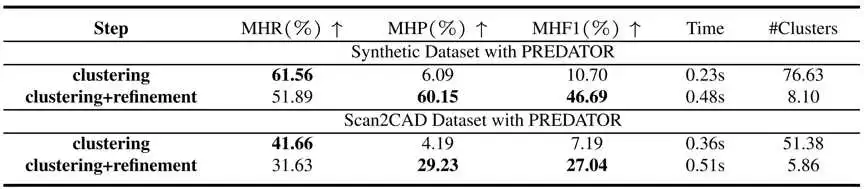
这是消融实验,可以看到,我们方法的两个重要模块,clustering和refinement都是有效的,没有refinement,recall很高但是precision很低,加上refinment可以在损失一部分recall的情况下大大提高precision。
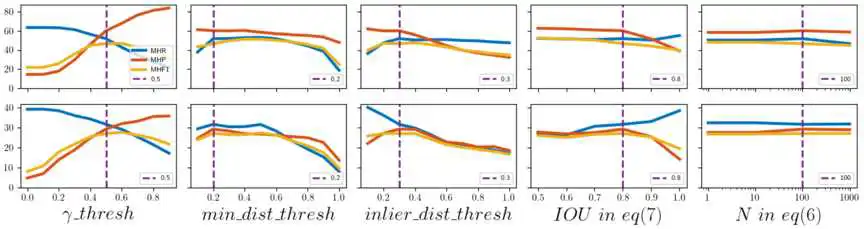
下面是我们方法F1 score随几个参数的变化曲线,上面一行是在synthetic数据集上调参数的结果,下面一行是在scan2CAD数据集上调参数的结果,可以看到我们的方法在synthetic和real两个数据集上走势非常相似,证明我们的方法对参数并不敏感。
04
Neural Compression-Based Feature Learning for Video Restoration
基于神经压缩的视频复原
作者:黄聪 李嘉豪 李斌 刘东 吕岩
单位:中国科学技术大学,微软亚洲研究院
邮箱:
;
;
;
;
论文:
https://arxiv.org/pdf/2203.09208.pdf
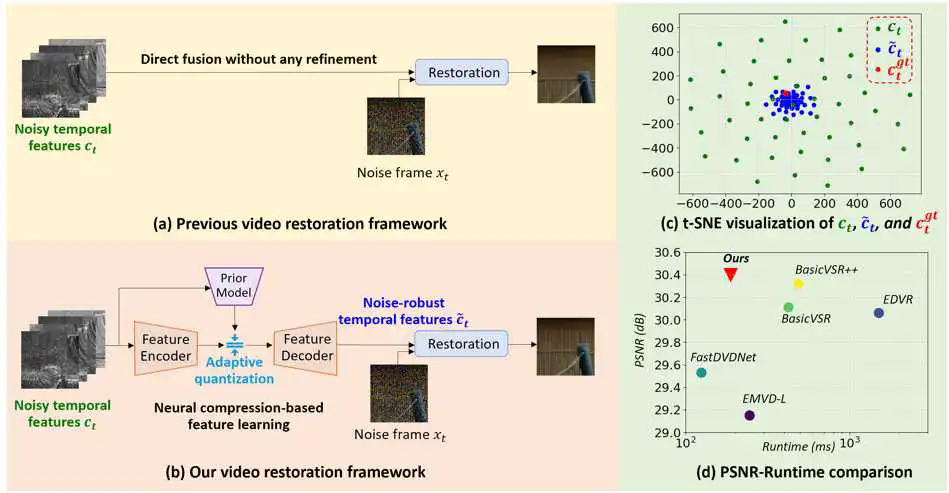
图 1 (a) 已有的视频复原框架 (b) 我们基于神经压缩的视频复原框架 (c) t-SNE 可视化对比 (d) 性能对比。
视频复原任务非常依赖时序特征来获得更好的重建质量。现有的视频复原方法主要关注如何设计更好的网络结构去提取时序特征,例如双向传播。至于如何有效使用时序特征并和当前帧融合,通常容易被忽视。实际上时序特征通常包含大量噪声和不相关的信息,直接使用而不经过任何特征提纯,反而会干扰当前帧的复原。
为此我们提出了一种基于神经压缩的算法来学习高效的时序特征表达。因为神经压缩为了节省比特会把无关的信息或者噪声丢弃,是个天然的去噪者。因此我们利用神经压缩去有效地过滤噪声的干扰并保留时序上最重要的信息。如图1 (b) 所示, 我们会在特征融合之前,使用神经压缩去对时序特征提纯。为了实现对噪声的鲁棒性,我们为压缩模块设计了一种自适应并且可学习的量化机制,以便有效处理不同类别和不同程度的噪声干扰。在训练过程中,交叉熵损失函数和重建损失函数会引导先验模型去学习合适的量化步长。
图 1 (c) 展示了我们模型所学的特征有更强的噪声鲁棒性,并且更接近来自干净视频的特征。实验表明,这种特征学习方式能帮助我们的模型在多个视频恢复任务中取得了最好的性能,包括视频去噪,视频去雨和视频去雾。并且我们的方法在复杂度上也优于之前最好的方法。尤其是在视频去噪任务上,我们的方法比BasicVSR++提高了0.13 dB的PSNR并且只有它0.23倍的复杂度。
05
Infrared Invisible Clothing: Hiding from Infrared Detectors at Multiple Angles in Real World
作者:朱小佩,胡展豪,黄思源,李建民,胡晓林
单位:清华大学
邮箱:
;
;
;
;
论文:
https://openaccess.thecvf.com/content/CVPR2022/html/Zhu_Infrared_Invisible_Clothing_Hiding_From_Infrared_Detectors_at_Multiple_Angles_CVPR_2022_paper.html
1. 引言
热成像在人体测温,自动驾驶,安全监测当中有着广泛的应用。但是其安全性仅在近几年得到关注。我们提出了一种能够在多角度对红外目标检测器隐身的对抗服装。我们在数字世界中模拟了从布料到衣服的过程,并且设计了类似二维码的对抗图案。我们方法的核心是设计一个具有周期扩展性的图案,并且使得该图案在经过随机裁切和非刚性形变之后一滩具有对抗效果。数字仿真的结果表明确,对抗二维码图案能够使得YOLOv3的AP下降87.7%,而随机二维码和空白图案仅仅使得YOLOv3的AP下降57.9%和30.15%。我们在物理世界中用一种新型的气凝胶材料制作了对抗服装。结果表明,它可以成功在物理世界中对红外检测器隐身。对抗服装能够使得YOLOv3的AP下降64.6%,而随机图案服装和全隔热的服装仅仅使得AP下降28.3%和22.8%。我们使用模型集成技术来提升对黑盒模型的攻击效果。
2. 方法:
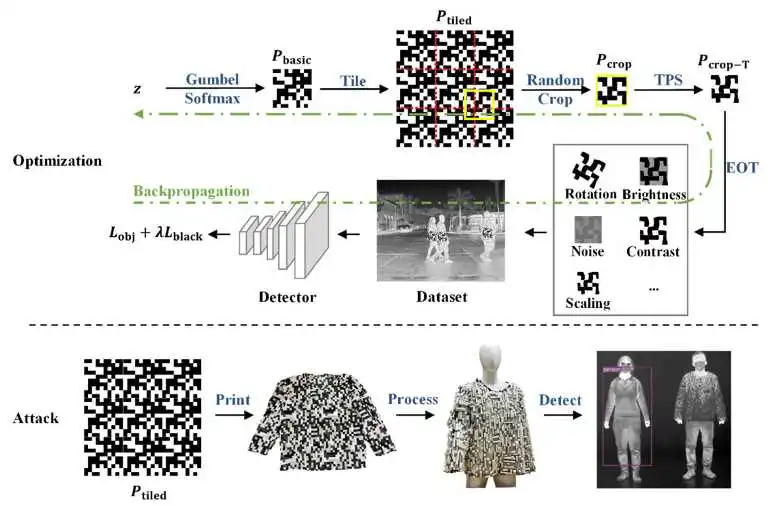
图1 主要流程图。上面是数字优化流程。下面是物理测试流程。
整体的方法可分为两大部分。数字优化和物理测试。在数字优化流程中,我们构建了基本的二维码图案,并用Gumbel-Softmax解决了离散不可导的问题。在对其进行周期扩展之后,我们又进行随机裁切处理,这是为了保证图案的各个部分都具有对抗效果。我们用薄板样条插值(TPS)来模拟现实世界的非刚性形变。并用EOT算法来模拟现实世界的多种噪声和扰动。将对抗图案添加到行人数据集当中并输入到检测器中,然后根绝检测器的Loss函数,反向传播来更新基本的二维码图案。由于该图案具有周期扩展性和抗形变特性,因此可以被加工成任意款式和大小的衣服。在物理测试当中,我们利用气凝胶来实现了对抗服装,它是一种优异的隔热材料,可以粘贴到二维码的黑色部分处,这样在红外成像下就可以显示出对应的图案。对于二维码的白色部分,可以仅仅利用人体本身的热量来显示图案,无需耗费其他能源。由此,便可以制造出一件红外“隐身衣”。
3. 结果
下图为数字仿真的测试结果和一组示例。

图 2 数字仿真结果
下图为物理实验的测试结果。

图 3 物理测试实验结果
图中A为对抗二维码图案服装,O为普通服装,R为随机二维码图案服装,F为全隔热服装。与对照组相比,结果表明了对抗服装的隐身效果。
06
Classification-Then-Grounding: Reformulating Video Scene Graphs as Temporal Bipartite Graphs
作者:高凯锋,陈隆,牛玉磊,邵健,肖俊
单位:浙江大学,哥伦比亚大学
邮箱:
论文:
https://openaccess.thecvf.com/content/CVPR2022/papers/Gao_Classification-Then-Grounding_Reformulating_Video_Scene_Graphs_As_Temporal_Bipartite_Graphs_CVPR_2022_paper.pdf
1. 引言
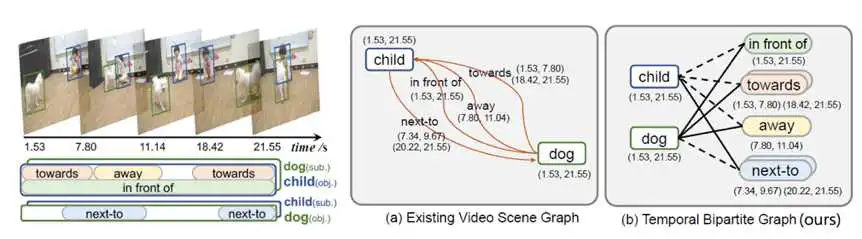
视频场景图生成(video scene graph generation) 旨在将视频中的复杂场景转化为结构化的实体关系图,其中的节点对应视频中的物体,边对应物体之间的视觉关系。相比于静态的图像场景图生成,视频场景图生成的主要挑战在于:(1)检测视频中的视觉关系需要考虑目标物之间的动态位置,以及时序上下文。(2)两个目标物之间可能存在多种视觉关系,并且这些视觉关系有时序依赖。(3)每个视觉关系的出现时间未必与目标物一致,需要定位不同关系的特定时间。
当前的视频场景图生成算法算法普遍基于轨迹片段检测关系。因此它们的关系定位粒度受限于轨迹片段划分质量,同时它们依赖关系合并算法,容易忽视长时间关系,以及容易忽视关系上下文信息。我们首次提出了先分类后定位的实体关系检测算法(BIG),提出了基于时序二分图的视频实体关系图。我们首先预测实体之间的多个关系,然后采用视频定位算法预测每个关系的时间位置。我们的方法可以实现更细粒度的关系定位,同时避免了由于实体切分片段造成的标签模糊问题,提升了模型训练的稳定性和算法的鲁棒性。在VidVRD数据集与VidOR数据集上均达到了state-of-the-art的性能。
2. 方法概述
我们提出了先分类后定位的实体关系检测算法,将实体关系图谱建模为时序二分图(temporal bipartite graph)。它包括实体节点、谓词节点,以及边。其中,每个实体节点对应视频中的一个物体边界框序列(轨迹),每个谓词节点对应一组具有特定起止时间的关系实例,每一条边连接一个实体节点和一个谓词节点,并指定该实体节点对于该谓词是作为主语或是宾语。
我们的整个关系检测框架分为分类阶段和定位阶段:
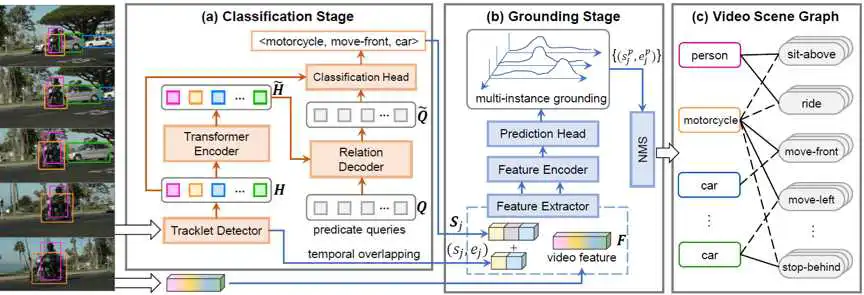
在分类阶段,我们需要预测谓词节点的类别,以及二分图的边(以邻接矩阵表征)。我们首先采用预训练的目标检测器检测出视频每一帧中的物体位置,然后采用目标跟踪算法得到物体轨迹。之后采用视觉Transformer对轨迹特征进行编码,融合轨迹之间的上下文特征,得到每个轨迹的增强特征\tilde{H}。我们设计了可学习的谓词查询向量(query embedding)Q,在视觉Transformer解码过程中,实体(轨迹)特征\tilde{H}与谓词特征Q进行交叉注意力操作,得到增强的谓词嵌入向量\tilde{Q}。我们设计了语义角色可知的交叉注意力模块(Role-aware Cross-Attention, RaCA):
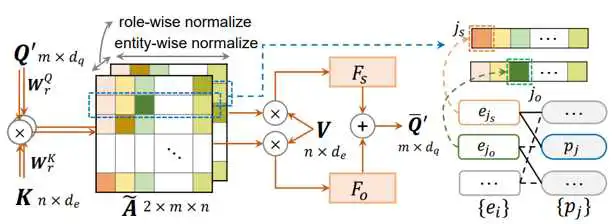
RaCA模块构建一个两通道的注意力矩阵A,每个通分别表征主语或宾语的实体节点相对于谓词节点的邻接矩阵。实体特征与谓词特征在每个通道上进行交叉注意力操作。然后,注意力矩阵A分别在实体方向和语义角色方向进行归一化:
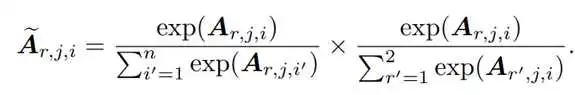
不同语义角色的实体特征基于A通过全连接神经网络融合,以增强谓词节点特征:
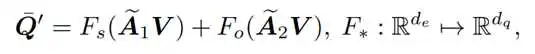
最后,我们基于增强后的谓词特征\tilde{Q}对谓词节点进行分类,同时将最终的交叉注意力矩阵A离散化,得到二分图的邻接矩阵。
在定位阶段,我们借鉴了视频定位算法的思路,将每一个关系三元组<主语,谓语,宾语>视为一个自然语言查询,定位每个关系发生的时间。考虑到视频场景的复杂性,同一个<主语,宾语>对之间的同一种关系可能间断发生多次,我们设计了多实例定位算法,为每个关系节点定位其发生的多个时间片段。多实例定位模块的输入是视频的I3D卷积特征与关系三元组类别的语义特征,输出是每个谓词节点的K个实例的时间位置。每个实例由置信度和中心度两个得分与边界距离表征,然后通过时间池化得到相应的时间位置。最终,K个实例通过非极大值抑制(NMS)减少假阳性样本,得到最终的每个谓词节点的多个时间片段。

3. 实验结果
表1 分类和定位阶段的有效性
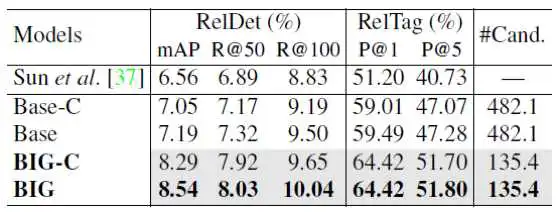
表1显示,本文的基线方法(Base-C)仍然能够超过当前基于实体片段(物体边界框序列)提名的方法[37](7.05% mAP vs 6.56% mAP),证明了先分类后定位这一关系检测框架的有效性。其次,本文的方法在分类阶段(BIG-C)的性能优于Base-C,证明了分类阶段的有效性。最后,本文的定位阶段方法应用于Base与BIG上时,都能够有相应的性能提升(例如mAP分别提升了0.14%与0.25%),证明了本文定位阶段的有效性。此外,我们还统计了本文方法和基线方法在分类阶段的平均候选关系数量(#Cand.),可以看到,本文的BIG产生更少候选关系(135.4 vs 482.1),即本文的方法能够以更低的计算复杂度达到更高的关系检测性能。
表2 多实例定位模块的有效性实验
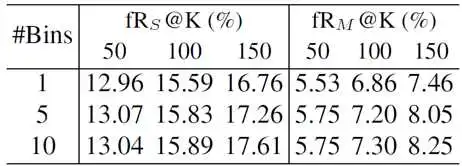
其次,我们对定位阶段中的多实例定位模块进行了消融实验,对比了不同预设实例数量(#Bins)情况下的检测召回率,结果如表2所示。一方面,采用多实例定位相比于单实例定位(#Bins=1)有显著的召回率提升;另一方面,增大定位算法中的预设实例数量能够有效地提升召回率,同时在多实例样本中的召回率提升更大。
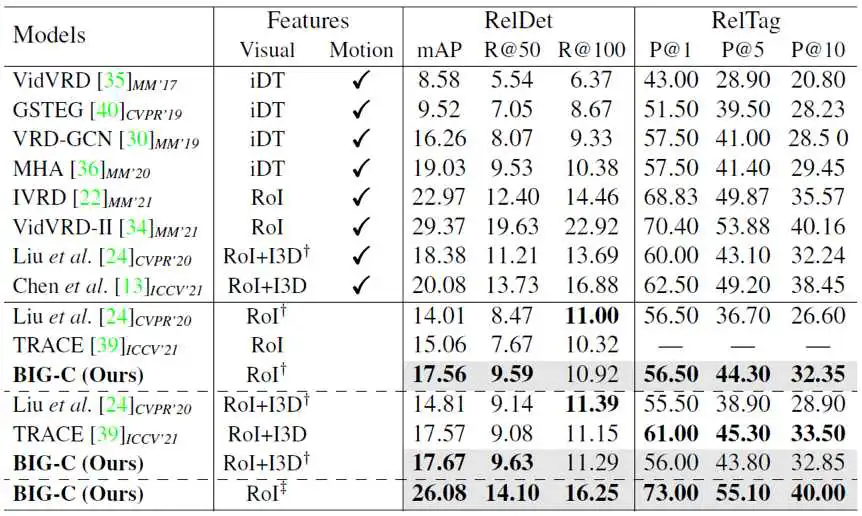
表3 本文的方法在VidVRD数据集上的性能
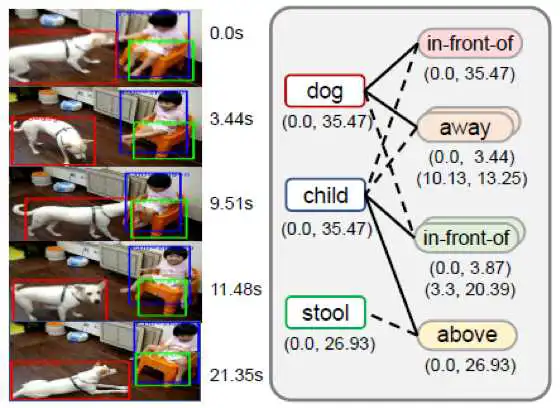
4. 可视化结果:
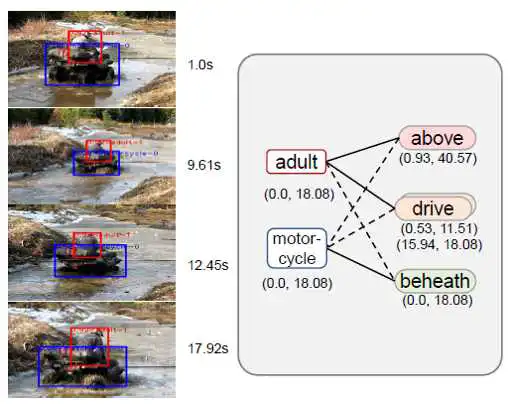
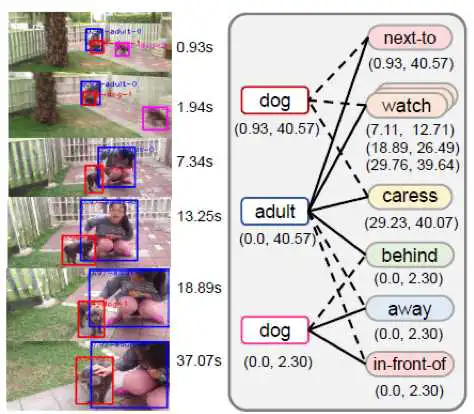

编辑人:桑基韬、聂礼强
专委会责任副主任:徐常胜
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/41147.html