
目录
1专用窗口函数
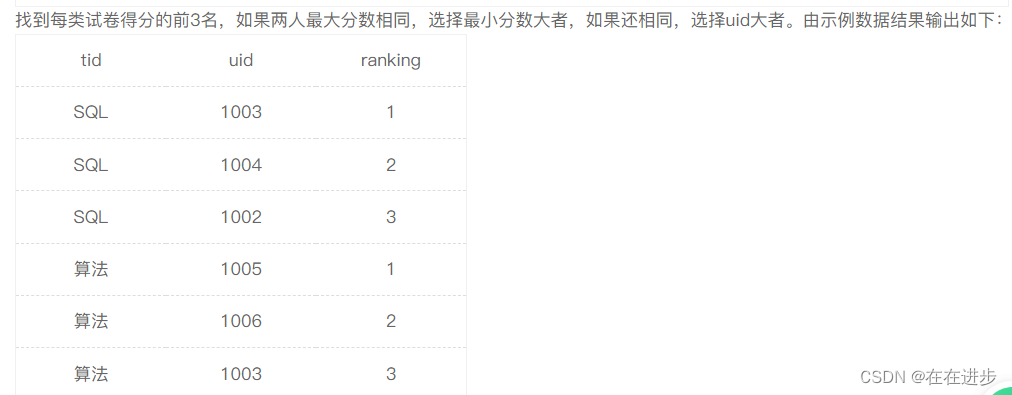
1.1 每类试卷得分前3名
1.2第二快/慢用时之差大于试卷时长一半的试卷
1.3连续两次作答试卷的最大时间窗
1.4近三个月未完成试卷数为0的用户完成情况
1.5未完成率较高的50%用户近三个月答卷情况
2聚合窗口函数
2.1 对试卷得分做min-max归一化
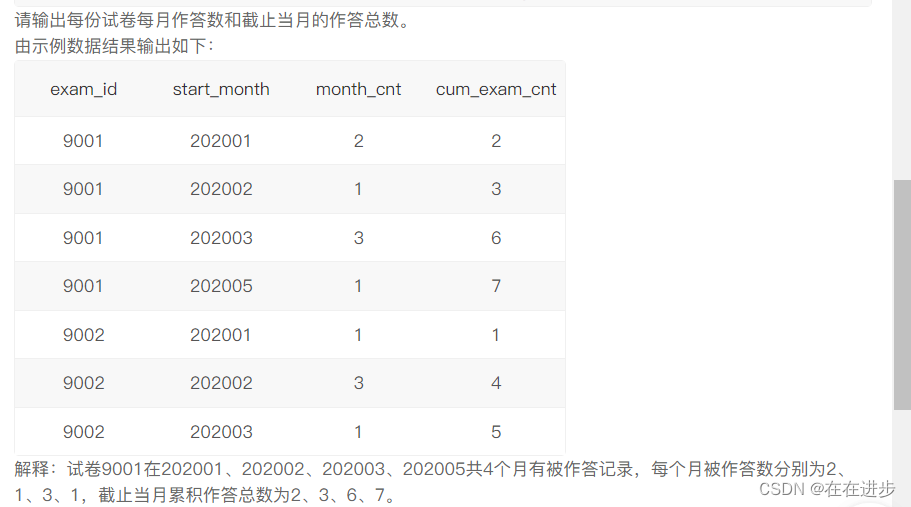
2.2每份试卷每月作答数和截止当月的作答总数。
2.3 每月及截止当月的答题情况
我的代码:筛选好难,不懂啥意思
正确代码:
复盘:
(1)排序:如果两人最大分数相同,选择最小分数大者,如果还相同,选择uid大者
ORDER BY MAX(score) desc ,MIN(score) desc,uid desc
(2)窗口函数
【排序窗口函数】
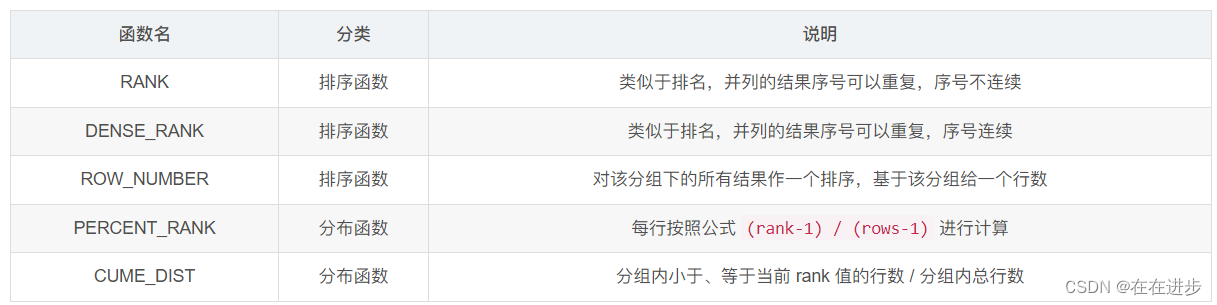
● rank()over()——1,1,3,4
● dense_rank()over()——1,1,2,3
● row_number()over()——1,2,3,4

我的代码:没搞出来,好久没有弄窗口了,这个题好难
方法1:max(if)
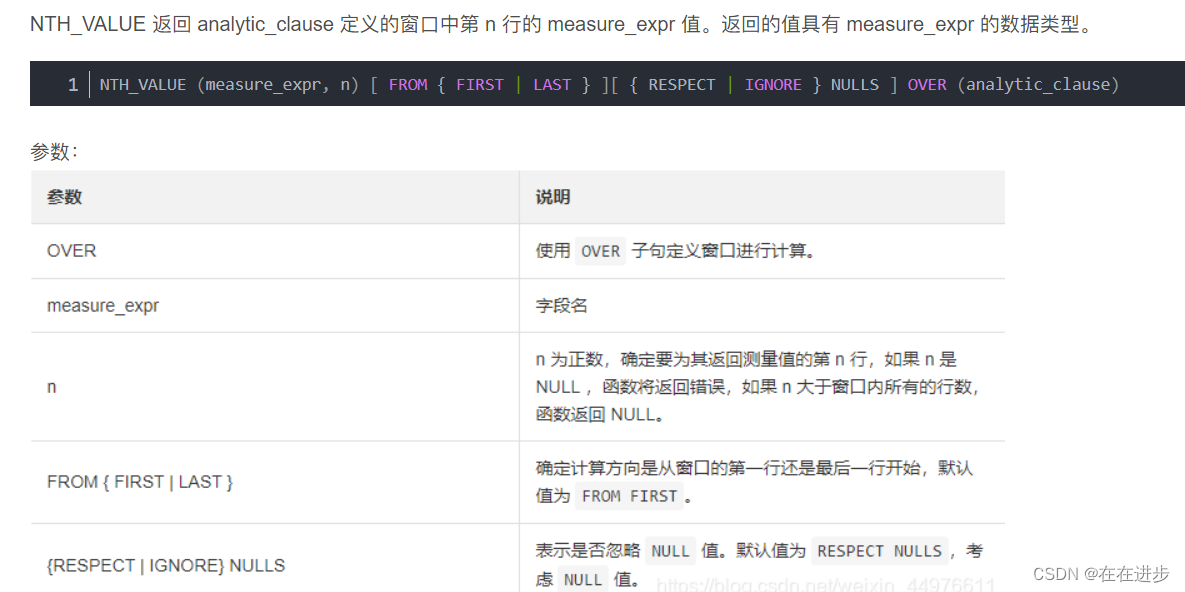
方法2:分析(窗口)函数:NTH_VALUE
复盘:
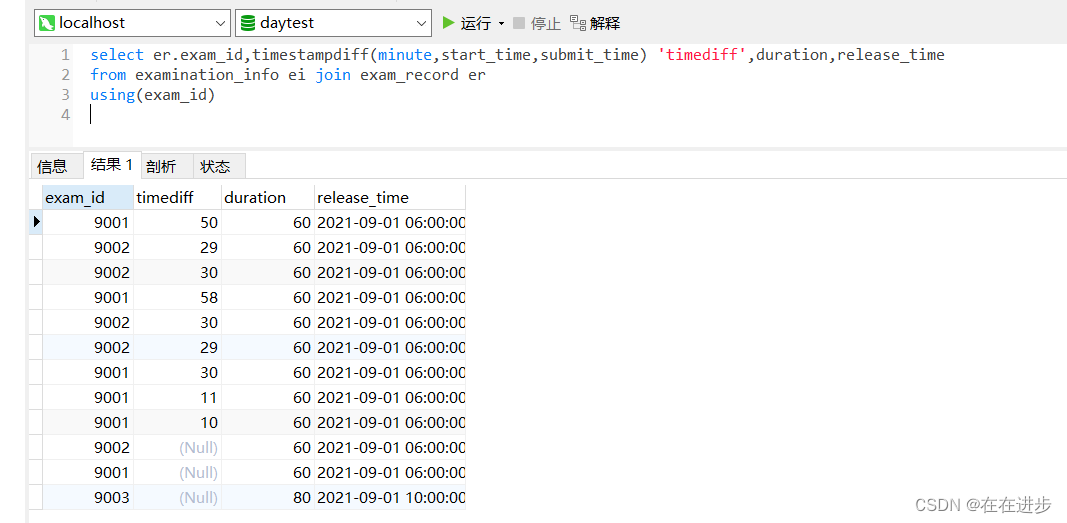
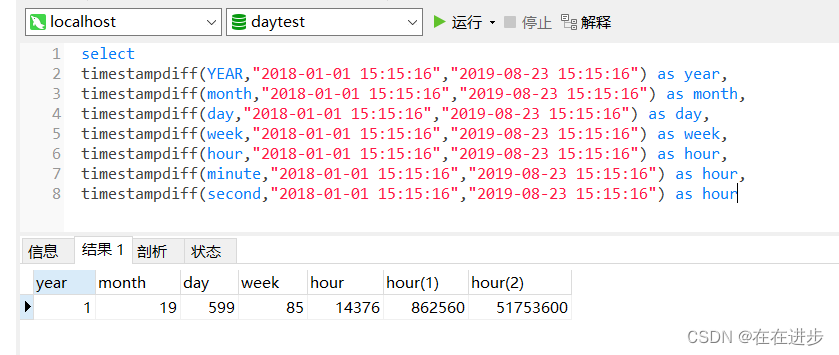
(1)时间差函数:timestampdiff,如计算差多少分钟,timestampdiff(minute,时间1,时间2),是时间2-时间1,单位是minute
(2)如何取次最大和次最小呢:分析(窗口)函数:NTH_VALUE
(3)关于窗口函数,才发现我本地的数据库连接版本是5,只有MySQL8以上才能用窗口函数好像,所以不能在本地演练推导了。(我一点也不想升级,安装都很麻烦,升级的话肯定各种报错)

我的思路:(写不出来)
(1)先把每个用户作答时间用dateformat求出来
(2)在作差,应该可以用偏移分析函数:
【偏移分析函数】
● lag(字段名,偏移量[,默认值])over()——当前行向上取值“偏移量”行
● lead(字段名,偏移量[,默认值])over()——当前行向下取值“偏移量”行
例:
● ,confirmed 当天截至时间累计确诊人数
● ,lag(confirmed,1)over(partition by name order by whn) 昨天截至时间累计确诊人数
● ,(confirmed - lag(confirmed,1)over(partition by name order by whn)) 每天新增确诊人数
(3)然后选取最大的这个差值
正确代码:
复盘:
(1)先找出uid, 开始时间,下次开始时间。条件是2021创建子表
下次开始时间用偏移分析函数:
● lead(字段名,偏移量[,默认值])over()——当前行向下取值“偏移量”行
(2)最大时间窗口 = max(datediff(next_time,start_time))+1
(3)平均做答试卷套数=作答的试卷数 / 作答期间 *最大时间窗口
= 3/7*6
= count(start_time)/
(datediff(max(start_time),min(start_time))+1)
*(max(datediff(next_time,start_time))+1)
= round(count(start_time)/
(datediff(max(start_time),min(start_time))+1)
*(max(datediff(next_time,start_time))+1),2) #保留两位小数
(4)时间作差要用时间差函数datediff,不能直接相减:结果会是不一样的
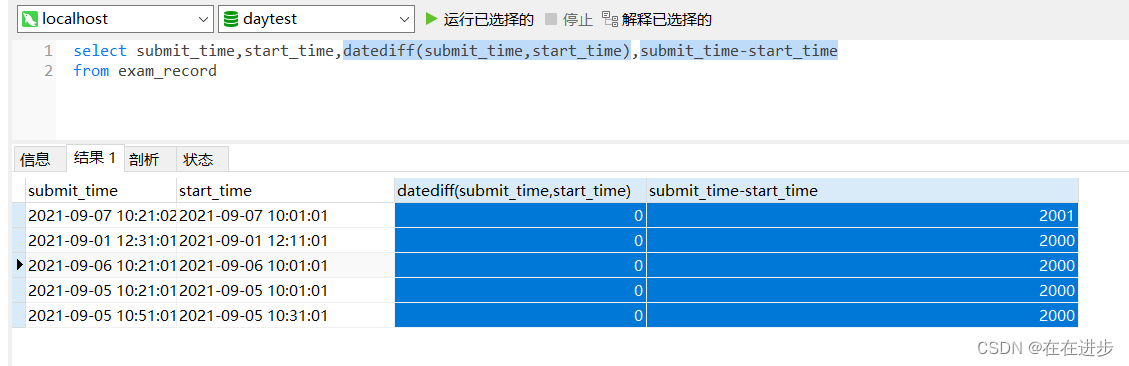
(5)datediff()函数 与 timestampdiff()函数的区别

我的代码:思路是这样,报错是必然的
大佬代码:发现这个答案和我的好像,我再改改
我的代码改正:
复盘:
(1)这里不能用rank,加引号也不行,难道是和函数名重复了?改为ranking就好了
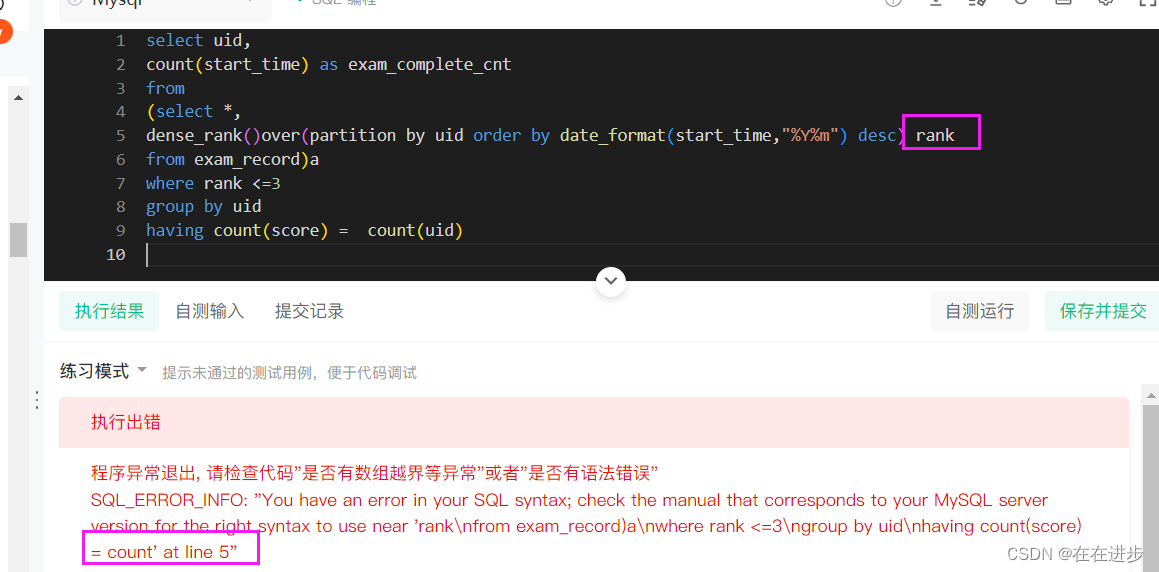
(2)窗口函数,等着二刷吧,有点小难
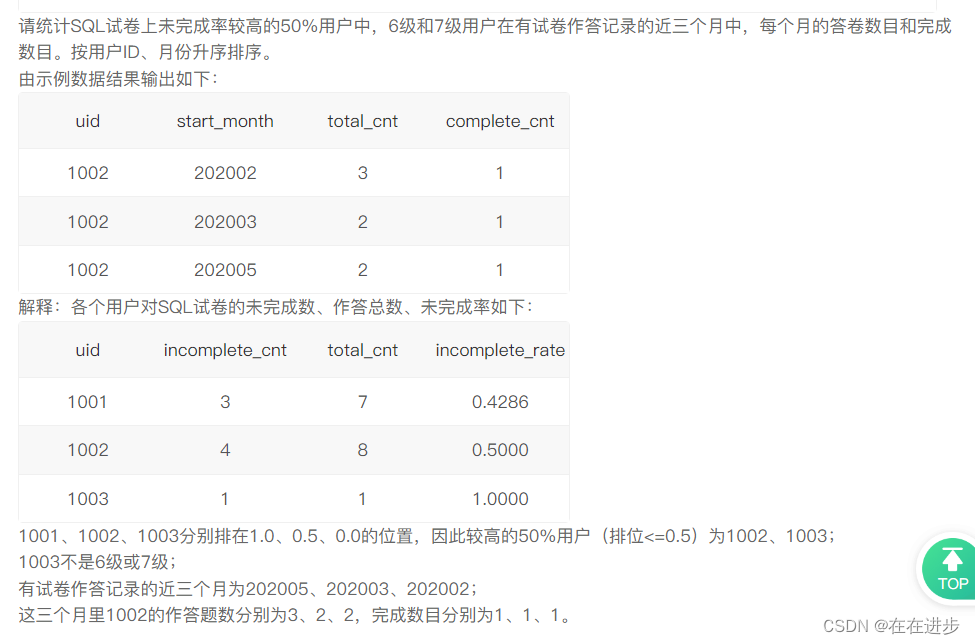
我的代码:思路是这样,报错是必然的
大佬代码:好牛,我啥时候能这个水平
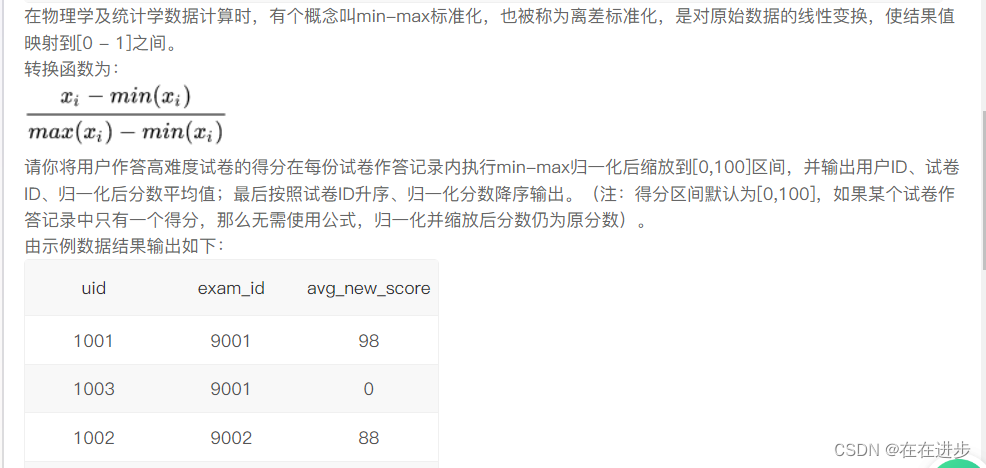
我的报错代码:(得分区间默认为[0,100],如果某个试卷作答记录中只有一个得分,那么无需使用公式,归一化并缩放后分数仍为原分数)这个怎么筛选出去呀
大佬代码:
复盘:
(1)最值窗口函数:不是直接max,min再后面分组
max(er.score)over(partition by er.exam_id) as max_score,
min(er.score)over(partition by er.exam_id) as min_score
(2)用if来排除只有一个分数的情况
if(max_score!=min_score,(score-min_score)/(max_score-min_score)*100,score
我的代码:
大佬代码:
复盘:
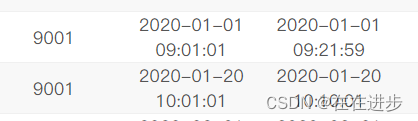
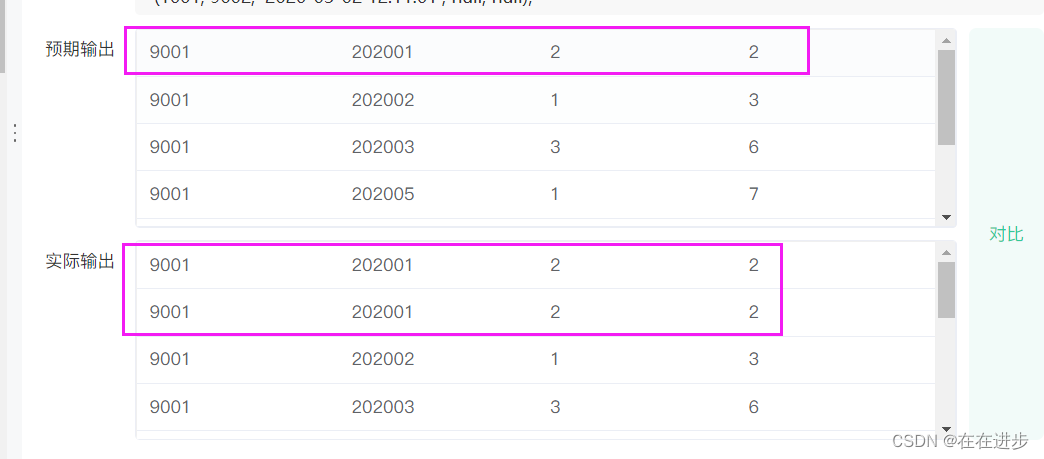
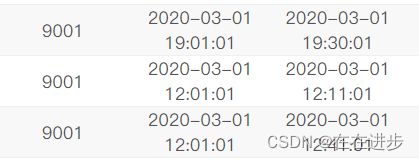
(1)要distinct exam_id,如果不去重 exam_id,那么同 exam_id和同月会被输出原文件中exam_id和同月配套出现那么多次。
如:
又如:
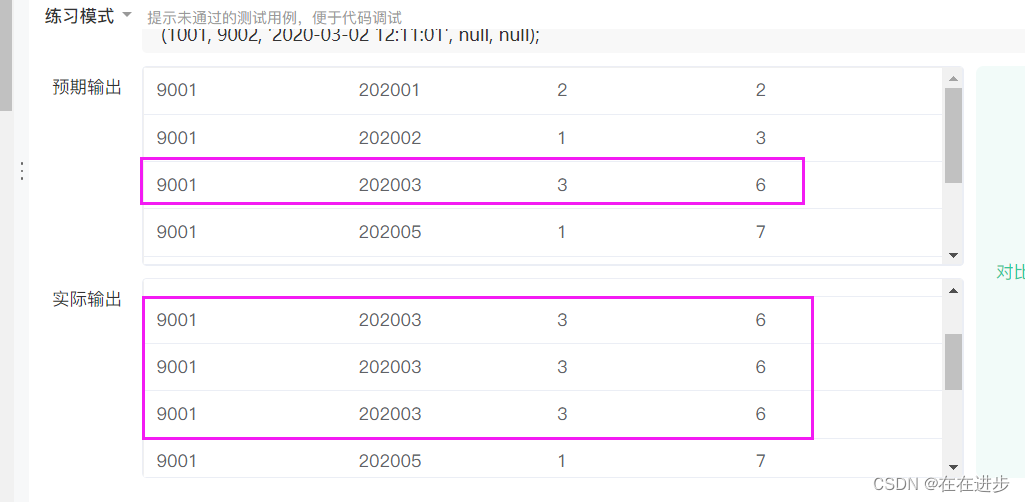
(2)是start_time而不是submit_time,start_time有记录才表明有作答
我的代码:后面三个没有整出来
大佬代码:
复盘:
(1)【排序窗口函数】
● rank()over()——1,1,3,4
● dense_rank()over()——1,1,2,3
● row_number()over()——1,2,3,4
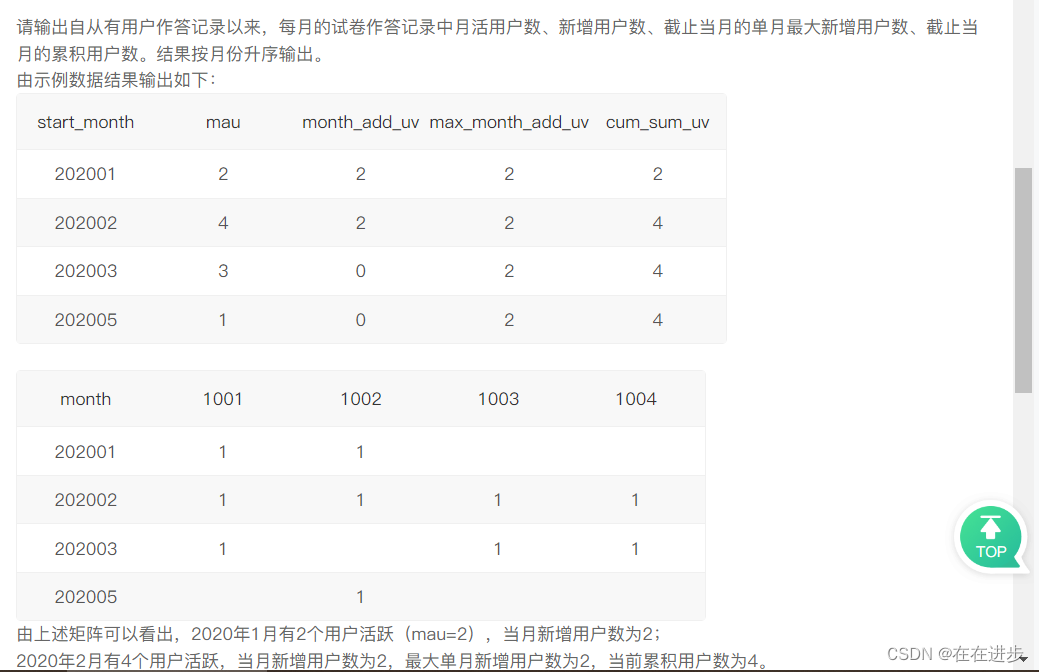
这里使用 row_number()over()就只有一个1,那么如果uid有排名为1的,就表示是这个月的新用户。
(2)
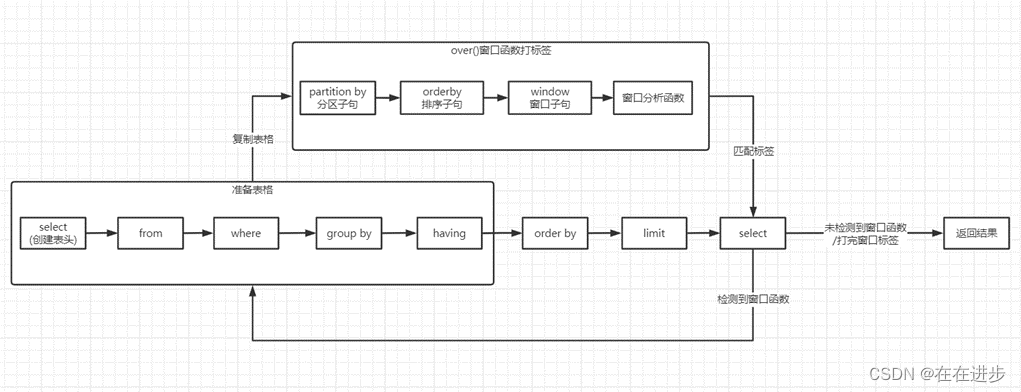
- SQL查询语句语法结构和运行顺序
- 运行顺序:from--where--group by--having--order by--limit--select
- 语法结构:select--from--where--group by--having--order by--limit
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sqlbc/75273.html