
窗口函数是 MySQL 8.0 版本引入的强大功能,它允许在与一组相关行(称为窗口)相关的上下文中执行计算,而无需使用传统的 GROUP BY 子句对结果进行分组。窗口函数可以在查询结果集的每一行上执行特定的计算,同时能够访问该行所在窗口内的其他行数据,从而实现诸如排名、累计计算、移动平均等复杂的分析操作。
- function_name:这是具体的窗口函数名称,常见的有聚合类窗口函数(如 SUM、AVG、MAX、MIN 等)、排序类窗口函数(如 RANK、DENSE_RANK、ROW_NUMBER 等)、分析类窗口函数(如 LAG、LEAD、FIRST_VALUE、LAST_VALUE 等)。
- expression:根据不同的窗口函数和任务需求,选择输入相应的参数。
- OVER:是窗口函数语法中的关键字部分,它用于指定窗口的定义方式。
- PARTITION BY:用于对结果集进行分区操作,,窗口函数会在每个分区内独立进行计算。在一个数据表中也可以指定多个分区表达式,用逗号分隔。例如:PARTITION BY region, department,表示先按照地区分区,在每个地区内再按照部门进一步分区。
- ORDER BY:指定在每个分区内数据的排序方式,可以指定多个排序表达式,并用逗号分隔,同时可以选择升序(ASC)或降序(DESC)排列。例如:ORDER BY sales_amount DESC 表示按照销售金额降序排列。
- window_frame_clause:这是一个可选部分,用于进一步精确指定窗口的范围。常见的定义方式有:
(1)ROWS BETWEEN:通过指定相对于当前行的行数范围来定义窗口。
(2)RANGE BETWEEN:通过指定相对于当前行的值的范围来定义窗口。
以下是一些常见窗口函数的具体语法示例,主要包括聚合类窗口函数、排序类窗口函数、以及取值类窗口函数等:
- AVG(): 计算窗口范围内指定列数据的平均值。
- MAX(): 返回窗口范围内指定列数据的最大值。
- MIN(): 获取窗口范围内指定列数据的最小值。 排序类窗口函数 在窗口范围内明确每行数据的排名、序号等相关信息,依据不同的排名规则可获取到各异类型的排序结果。 - RANK(): 依照指定的排序条件对窗口内的数据行进行排名操作。 倘若存在两行或多行数据满足相同的排序条件(即数据值相等),那么这些行将共享同一排名,且下一行的排名会跳过相应的数量。
- DENSE_RANK():同样是用于排名的函数,当有两行或多行数据满足相同排序条件时,这些行将共享同一排名,不过下一行的排名不会跳过,而是呈现连续的状态。
- ROW_NUMBER():为窗口内的每行数据分配一个独一无二的序号,该序号依照指定的排序条件从1开始依次递增。无论数据值是否相等,每行都会被赋予不同的序号。 取值类窗口函数 主要用于获取与当前行相关的其他行的信息,比如获取前一行或后一行的值、计算行与行之间的差值等。 - LAG():用于获取当前行之前某一行的指定列的值。
- LEAD():与LAG()的功能相反,用于获取当前形之后某一行的指定列的值
- FIRST_VALUE():用于获取窗口范围内指定列的第一个值(通常是依照指定的排序条件来确定)。
- LAST_VALUE():用于获取窗口范围内指定列的最后一个值(通常是依照指定的排序条件来确定)。
本文创建一个名为 sales_data 的数据集,它记录了一家公司不同地区、不同销售人员在不同时间段的销售业绩相关信息,可以输入如下代码将数据写入数据表中:
- 聚合类窗口函数是窗口函数中的一种类型,它允许在与一组相关行(即窗口)相关的上下文中执行常见的聚合计算操作,如求和、求平均值、计数、求最大值、求最小值等。
- 与普通的聚合函数(使用 GROUP BY 子句进行分组聚合)不同的是,聚合类窗口函数会针对结果集的每一行,在该行所在的特定窗口范围内进行聚合计算,并返回基于该窗口聚合后的结果,而不是将整个数据集按照某些列进行分组汇总成少数几行结果。
- 下面依照本文使用的数据集,结合具体示例对四个函数用法进行介绍。
- 1.要求:计算每个地区内按销售日期排序后,截至每行记录的销售金额累计总和。
- 2.代码:
- 3.结果分析:
(1)不添加 ORDER BY 排序语句,直接对每个地区进行分区求和:

(2)使用ORDER BY 排序语句,计算每个地区内按销售日期排序后,截至每行记录的销售金额累计总和:

- 可以看到,相对于聚合函数GROUP BY 查询语句,使用窗口函数能够在不改变原始数据行结构的基础上,针对每一行数据计算出在其所在窗口(这里是按地区分区且按销售日期排序的窗口)内的累计销售金额;若使用 GROUP BY 子句要实现类似窗口函数那样针对每一行计算累计值的功能,需要使用子查询等相对复杂的方式来实现,代码的复杂度和可读性相对窗口函数会稍差一些。若对数据进行了分组聚合操作,则会丢失了原始数据中每个销售人员的单独记录信息。
- 在使用窗口函数(如 SUM 函数)并加入 ORDER BY 子句时,出现看起来像是逐行累加的情况,这其实是因为窗口函数在结合 ORDER BY 以及默认的帧范围设置下的计算逻辑导致的,如果需要直接显示总和,需要指定窗口范围。具体说明可以跳转本文第五部分:对窗口范围的解释说明。
- 1.要求:计算每个地区内按销售日期排序后,截至每行记录的销售金额平均值。
- 2.代码:
- 3.结果分析:
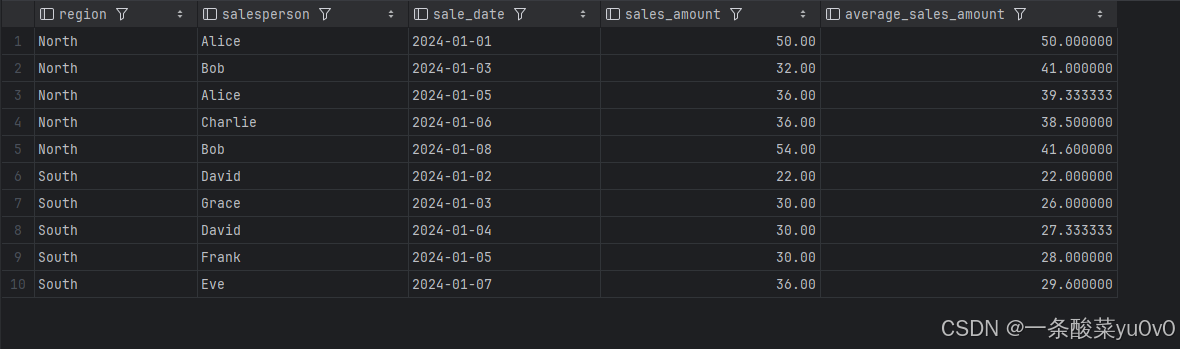
- AVG(sales_amount) 执行对 sales_amount 列求平均值的操作,接着利用窗口函数计算截至每行记录的销售金额平均值。
- PARTITION BY region 和 ORDER BY sale_date:结果集按地区分区,并在每个分区内按销售日期排序,以便在各地区内部独立计算销售金额的平均值。
- 1.要求:找出每个地区内按销售日期排序后,截至每行记录的销售金额最大(小)值。
- 2.代码:
- 3.结果分析:


MAX(sales_amount) OVER (PARTITION BY region ORDER BY sale_date) AS max_sales_amount 运用了窗口函数。MAX(sales_amount) 用于找出 sales_amount 列中的最大值,MIN(sales_amount) 同理。
- 排序类窗口函数主要用于在窗口范围内确定每行数据的排名、序号等相关信息,依据不同的排名规则可以得到不同类型的排序结果。主要包括RANK () 函数、DENSE_RANK () 函数以及ROW_NUMBER () 函数。
- 下面依照本文使用的数据集,结合具体示例对三个函数用法进行介绍。
- 1.要求:对每个地区内销售人员按销售金额进行排名(销售金额从高到低),销售金额相同的人共享排名,之后的排名跳过相应数量。
- 2.代码:
- 3.结果分析:

RANK 函数按照指定的排序条件对窗口内的数据行进行排名。若有两行或多行数据满足相同的排序条件,这些行将共享同一排名,且下一行的排名会跳过相应的数量。如上图,Alice和Charlie两个销售人员的销售金额并列第 3 名,那么下一个销售人员Bob的排名就是第 5 名。
- 1.要求:对每个地区内销售人员按销售金额进行排名(销售金额从高到低),要求排名连续。
- 2.代码:
- 3.结果分析:
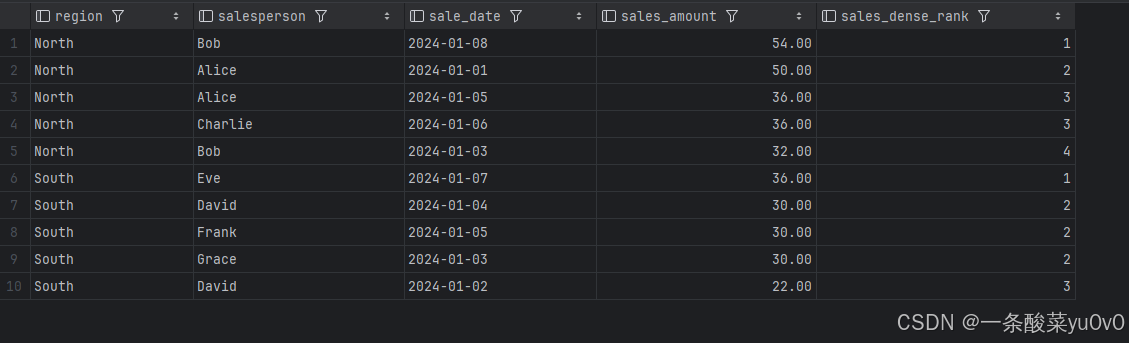
DENSE_RANK 函数同样用于对窗口内的数据行进行排名。当有两行或多行数据满足相同的排序条件时,这些行将共享同一排名,不过下一行的排名不会跳过,而是呈现连续的状态。
- 1.要求:为每个地区内销售人员按销售金额进行排名(销售金额从高到低),分配唯一序号。
- 2.代码:
- 3.结果分析:

ROW_NUMBER 函数为窗口内的每行数据分配一个独一无二的序号,该序号依照指定的排序条件从 1 开始依次递增。无论数据值是否相等,每行都会被赋予不同的序号。
- 取值类窗口函数主要用于获取与当前行相关的其他行的信息,通过在指定的窗口范围内进行操作,能够实现诸如获取前一行或后一行的值、计算行与行之间的差值等功能,以便进行更深入的数据分析。
- 下面依照本文使用的数据集,结合具体示例对四个函数用法进行介绍。
- 1.要求:获取每个地区内每个销售人员当前销售记录的前一次(后一次)销售金额。
- 2.代码:
- 3.结果分析:
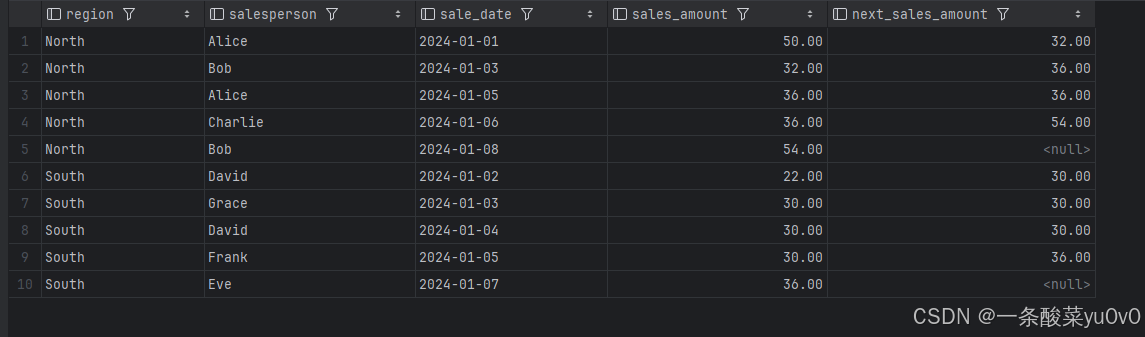
(1)获取每个地区内每个销售人员当前销售记录的前一次销售金额:

(2)获取每个地区内每个销售人员当前销售记录的后一次销售金额:
- 1.要求:获取每个地区内按销售日期排序后,每行销售记录的销售金额以及该地区销售日期最早(最晚)那笔销售记录的销售金额。
- 2.代码:
- 3.结果分析:
(1)获取该地区销售日期最早销售记录的销售金额:
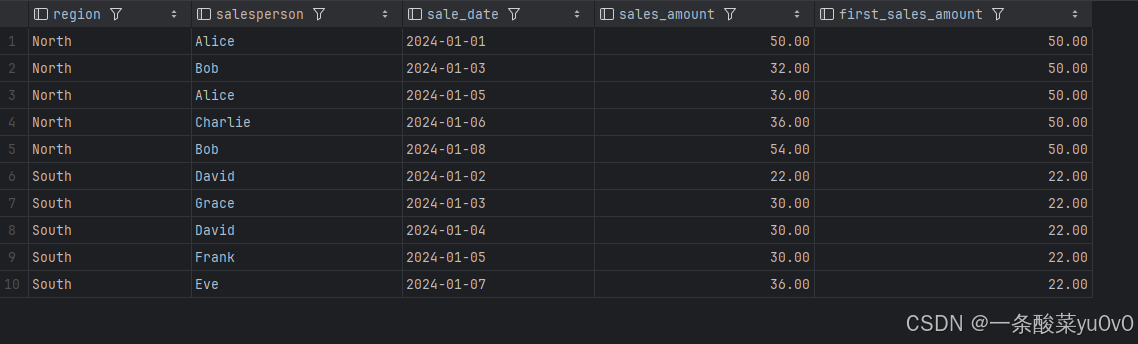
(2)获取该地区销售日期最晚销售记录的销售金额:
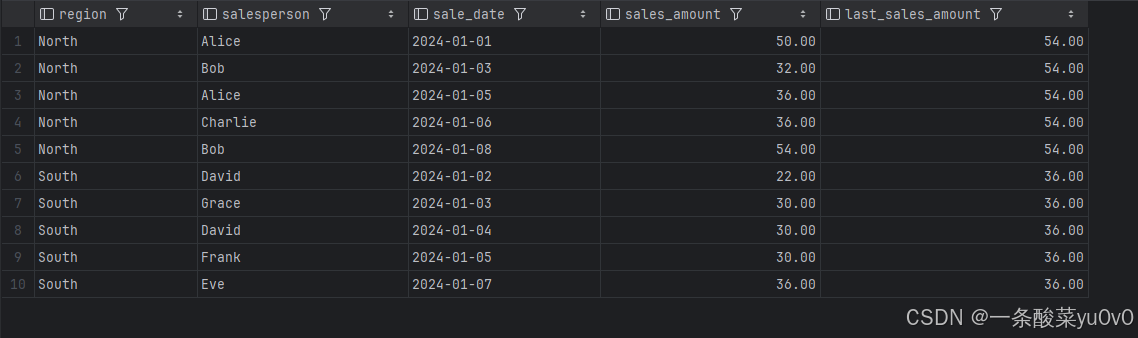
- 在使用FIRST_VALUE 与 LAST_VALUE函数时,在代码中加入 ROWS BETWEEN 来明确指定窗口范围,否则在MYSQL数据库中,按照默认的窗口范围是从分区内的第一行到当前行。具体说明可以跳转本文第五部分:对窗口范围的解释说明。
本文在介绍SUM函数和FIRST_VALUE 与 LAST_VALUE 函数时,发现如果不明确指定 ROWS BETWEEN 这样的窗口范围子句,可能会出现不同的查询结果,为可以更准确地控制窗口函数获取到我们想要的值,避免因数据库默认设置等因素导致的结果异常,需要根据任务需求对窗口函数的范围进行进一步限制,常见的关键词如下表所示:
假设我们有一个关于学生成绩的数据集,存储在名为 student_scores 的表中,包含以下列信息:
列名以及含义如下,下面我们将表格信息写入数据库中:
- student_id:学生编号
- class_name:班级名称
- subject:科目
- exam_date:考试日期
- score:成绩
- (1)计算每个班级每门科目每次考试的平均成绩;
- (2)获取每个班级每次考试成绩的排名;
- (3)获取每个班级每门科目每次考试成绩相对于前一次考试成绩的差值。
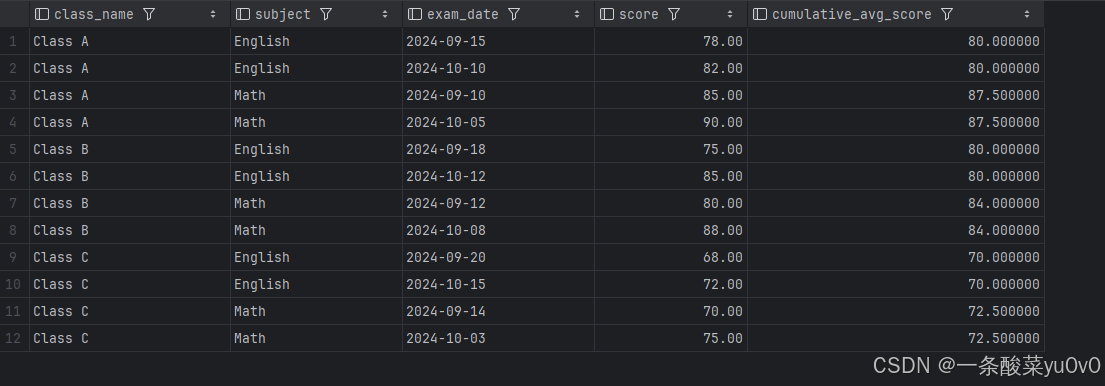
(1)计算每个班级每门科目每次考试的累计平均成绩;
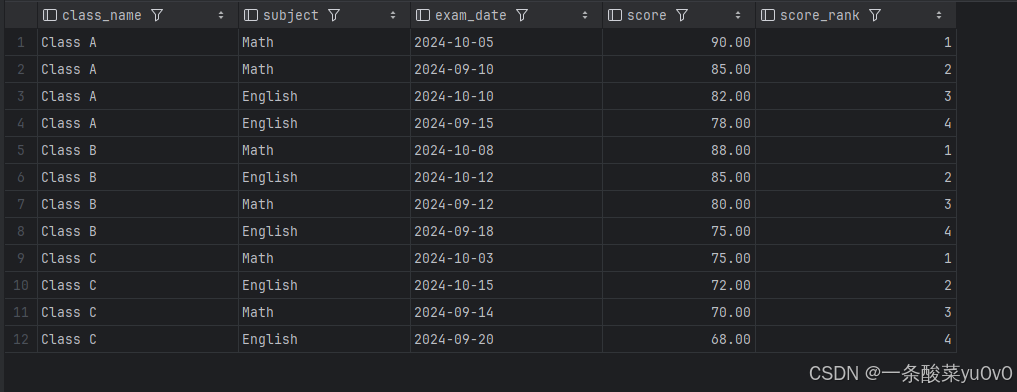
(2)获取每个班级每次考试成绩的排名:
(3)获取每个班级每门科目每次考试成绩相对于前一次考试成绩的差值:

版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sqlbc/17965.html