
create database database_name
use database_name
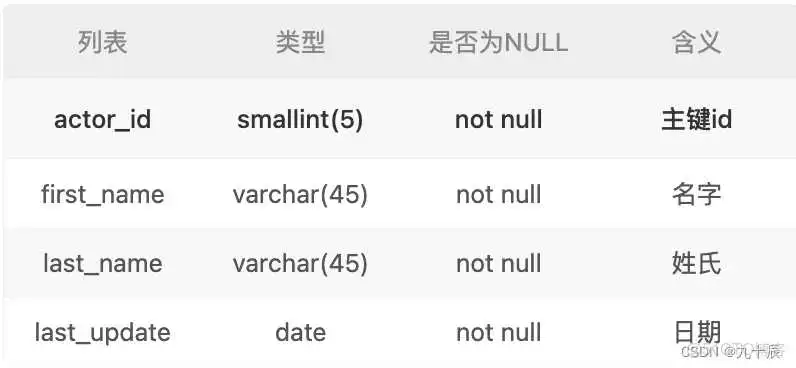
3.1普通建表
该建表命令创建的表结构如图所示:
3.2 复制建表
3.2.1复制表结构+数据
3.2.2复制表结构
插入数据:
删除数据:
删除特定行
删除所有行
tips:在mysql中不允许在子查询的同时删除原表数据,但是sqllite可以这样做
更新数据:
假设有一个名为 的表,该表有 , , 和 三个列。
更新特定行
更新多个列/字段
更新多行
tips:在不带 子句的情况下使用 会更新表中的所有行。
事务
定义:将一系列操作作为一个单一的、不可分割的工作单元来处理。
在事务中,要么所有的操作都成功执行,要么所有的操作都不执行。事务的这种特性确保了数据库的完整性和一致性
四个基本特性(acid):
- 原子性(Atomicity):事务是数据库操作的最小单位,它们要么全部完成,要么全部不执行。如果事务的一部分操作失败,整个事务将回滚到开始状态。
- 一致性(Consistency):事务必须使数据库从一个一致的状态转换到另一个一致的状态。这意味着事务执行的结果必须满足所有的数据库约束。
- 隔离性(Isolation):数据库系统提供了一定级别的隔离,以防止多个事务并发执行时相互干扰。这意味着一个事务的操作和中间状态对其他事务是不可见的。
- 持久性(Durability):一旦事务提交,其对数据库所做的更改就是永久性的,即使系统发生故障也不会丢失。
是
语句标志着一个新事务的开始。在执行这个语句后,你可以执行一个或多个数据库操作(如 、、 等),这些操作作为事务的一部分。在 之后执行的操作不会立即反映在数据库中。这些变更暂时保持在事务的上下文中,直到事务被提交或回滚。这种机制允许你在事务中执行多步操作,同时保持数据的一致性和完整性。
语句用于提交事务。这意味着自从上一个 以来所有的数据库更改都将被永久保存到数据库中。只有在执行 之后,这些更改才对其他用户可见。
现代DBMS中的事务应用
事务的管理通常由数据库管理系统(DBMS)提供支持,它保证了这些操作在执行时符合事务的ACID属性。在大多数现代数据库系统中,即使是单一的SQL操作也被视为一个事务。数据库操作可以分为隐式事务和显式事务:
隐式事务:在没有明确指定事务边界的情况下,每个单独的SQL语句都会自动成为一个事务。这种情况下,DBMS会自动为每个语句启动事务,并在语句执行成功后自动提交事务,或在执行失败时自动回滚事务。这是最基本的事务处理形式,适用于简单的单一语句操作。
显式事务:当需要对多个操作进行分组以确保它们作为一个单元一起成功或失败时,你需要使用显式事务。在这种情况下,你会明确地指定事务的开始和结束。这通常涉及到使用如BEGIN TRANSACTION、COMMIT和ROLLBACK等SQL命令来控制事务的边界:
• BEGIN TRANSACTION启动一个新事务。
• COMMIT提交当前事务,使自事务开始以来进行的所有修改成为数据库的永久部分。
• ROLLBACK回滚当前事务,取消自事务开始以来进行的所有未提交的修改。
5.1 insert into
5.2 replace into
5.4 从其他表导入数据
SELECT 本身是一个查询语句,用于从数据库中检索数据。但是,当 SELECT 语句与 INSERT INTO 语句结合使用时,它的功能就扩展了,不仅仅是检索数据,还包括将检索到的数据插入到另一个表中。——在 SQL 中,INSERT INTO ... SELECT ... 语句允许你将一个查询的结果直接插入到一个表中。
标准操作:
MySQL中的索引是数据库表中一种特殊的数据结构,它可以加快数据检索速度。索引存储在磁盘上,它们包含指向表中数据行的指针。
索引一共有五种:主键索引(primary key)、唯一索引(unique)、普通索引、全文索引、组合索引。
主键(PRIMARY KEY)索引
- 每个表只能有一个主键。
- 主键列不能包含NULL值。
- 主键保证了表中每行数据的唯一性。
1.创建新表时创建主键,略。
2.已有表时,想设置某个列为主键,可以使用alter table
唯一(UNIQUE)索引
- 保证列中每个值的唯一性。
- 与主键不同,唯一索引可以有多个,并且可以包含NULL值(但只能有一个NULL值)。
1.创建新表时,创建唯一索引
2.已有表时,想为某个列创建唯一索引
普通索引
- 最基本的索引,没有任何唯一性的限制。
- 可以帮助加快查询速度。
1.在建表时创建普通索引
2.已有表时,想为某个字段创建普通索引
3.举例说明,普通索引与唯一索引使用情况
首先是区别,就是某个字段的唯一索引是不允许重复的❎,也就是说该字段下每一行的index值都是唯一的;
但是某个字段的普通索引是允许重复的✅,也就是说该字段下每一行的index值是可以不唯一的;什么情况下需要不唯一的索引呢?
——比如,多个员工可能属于同一个部门,因此 department 列中会有重复的值。普通索引会索引这些值,使得我们可以快速根据部门检索员工,但它并不强制每个部门值都是唯一的;相比之下,如果是唯一的索引,那么两个员工是两行数据,同属一个部门,但是部门的索引由于唯一性的限制,却是不同的,那么数据库就没法根据这个索引来加快查找同一部门的员工了,就失去了意义。
全文(FULLTEXT)索引
- 专门用于全文搜索。
- 只有Char、VarChar和Text类型的列才能创建全文索引。
- 全文索引通过创建一个特殊的索引类型,其中包含文本数据的所有单词的列表,以及它们在文本数据中出现的位置。当执行全文搜索查询时,数据库可以快速查找包含特定单词或短语的行。
1.创建表时创建全文索引
2.已经有表时,创建全文索引
3.使用全文索引进行搜索
要利用全文索引进行搜索,可以使用 MATCH ... AGAINST 语法:这个查询会在 articles 表的 content 列中搜索包含 'some search term' 的记录。
组合索引
- 在表的多个列上建立的索引。
- 可以覆盖查询中涉及的多个列。
1.创建表时创建组合索引
2.已经有表时,创建组合索引
索引声明写法辨析
在创建表时,创建索引的写法并不局限于将索引定义放在表定义的最后。实际上,可以在定义每个列的同时直接指定某些类型的索引,尤其是主键(PRIMARY KEY)和唯一约束(UNIQUE)。这通常用于确保数据的完整性和唯一性。例如:
对于普通索引、全文索引、组合索引,则是一般要在最后声明
索引意义
仍然像之前一样编写 SELECT 语句。索引是在后台工作的,用户通常不会直接与其交互。数据库管理系统会自动决定是否使用索引来优化查询。
数据库优化器会根据查询条件、使用的索引类型、表中数据的统计信息以及可能还有其他因素,来决定是否使用索引以及如何使用索引。如果优化器认为使用索引可以提高查询效率,它会自动应用索引来检索数据。
索引原理
1.数据结构
数据库索引通常使用高效的数据结构,如 B-树(最常见)、B+树、哈希表等。这些数据结构优化了数据检索的速度。在B+树中,所有的数据都存储在叶子节点(通常包含指向实际数据的指针),而内部节点只存储键值,这使得B+树更适合用于数据库索引。
2.提高检索效率
索引大大减少了数据库必须检查的数据量。没有索引,DBMS 可能必须执行全表扫描,即逐行查看表中的每一行,直到找到所需的数据。索引使得DBMS可以快速定位到表的特定部分,从而只检查少量数据。
3.维护成本和插入、删除和更新成本变高
虽然索引可以显著提高查询效率,但它们也有维护成本。当表中的数据被添加、删除或修改时,索引也必须更新。这意味着写操作(INSERT、DELETE、UPDATE)可能会因为索引而变慢。
同时,索引还需要额外的存储空间。
强制索引*
在MySQL中,强制索引(Force Index)是一种优化技术,可以在查询时指示数据库使用特定的索引。这在数据库查询优化器未能选择最佳索引时非常有用。使用FORCE INDEX可以指导查询优化器使用特定索引,这可能会提高查询性能。(可能是因为mysql优化器可能在有多个索引时选择的索引不是最优的,是否最优需要通过在执行缓慢的sql前加上 关键字,查看执行计划)
强制索引写法:
如果有一个名为table_a的表和一个索引名为my_index,这样使用FORCE INDEX:
这将强制MySQL使用my_index索引来执行查询。这种方法应谨慎使用,因为它会覆盖MySQL优化器的索引选择,只有在你确信某个索引比优化器自动选择的更有效时才推荐使用。
什么是视图
视图(View)是基于SQL查询的虚拟表,主要用于简化复杂的SQL查询和提高数据访问的安全性。视图不直接存储数据,而是存储SQL查询。它看起来和实际的表一样,可以包含特定的行和列,但这些数据来自于基础表。
视图的作用
视图的主要目的包括:
- 简化查询:对于复杂的SQL查询,可以创建一个视图,这样用户就可以通过简单查询视图来获取数据(像查询普通表一样查询视图),而不需要每次都执行复杂的查询。
- 安全性:视图可以用来限制对基础数据的访问,确保用户只能看到他们被授权访问的数据。
- 数据抽象:用户可以使用视图而不需要关心数据是如何存储和计算的。
查看方式
既然view是一种虚拟表,那么也就意味着,使用sql命令时,使用show tables的命令时,结果是基础表和视图的综合
如果要准确区分基础表和视图需要用如下命令:
SHOW FULL TABLES命令提供了更多的信息,包括每个表是视图还是真实的表。在结果中,它添加了一个TABLE_TYPE字段,这个字段的值可以是'BASE TABLE'(对于普通表)或者'VIEW'(对于视图)。这使得用户能够区分显示的列表中哪些是实际的表格,哪些是视图。如果只使用SHOW TABLES,这个区分是不可见的。
查询基础表:
创建视图
查询视图
修改或更新视图
删除视图
新增字段/列
在表最后一列后面增加
在指定位置增加列
在第一列增加
创建外键约束
外键类型说明:
现在的这个例子只是给table_a的一个字段加上了外键约束,并且引用了table_b的一个字段,
1.如果再给table_b的这个字段加上外键约束,并且引用table_a的那个字段且两字段都唯一,那么创建的这两个外键约束就会使得这个关系变成一对一关系
2.如果table_b中的这个字段是唯一的话,就已经创建了一对多的关系
3.实现多对多关系:假设有两个表 students 和 courses,表示学生和课程,一个学生可以注册多门课程,一门课程可以被多个学生注册。为了表示这种关系,可以创建一个名为 student_courses 的关联表。
第一步:创建原始表
第二步:创建关联表
说明:在 表中
- 和 是外键,分别指向 和 表。
- 对作为主键,确保每个学生和课程的组合是唯一的。
常见修改表结构语句
触发器的定义
触发器是一种特殊类型的存储过程,它不同于存储过程,它主要是通过事件触发而被执行的,即不是主动调用而执行的;它在满足某种条件下会自动执行。
触发器:trigger,是指事先为某张表绑定一段代码,当表中的某些内容发生改变的时候,系统会自动触发代码并执行;触发器可以在下列情况发生时被触发执行:
- INSERT:当数据被插入到表中时。
- UPDATE:当表中的数据被更新时。
- DELETE:当表中的数据被删除时。
创建触发器的基本语法:
示例:
假设有两个表:orders(订单表)和order_audit(订单审计表)。每当orders表中插入新的订单时,我们想在order_audit表中添加一条记录来记录这个事件。(如果触发器只包含一条语句,可以省略 BEGIN 和 END,但为了代码的清晰和一致性,即使只有一条语句,使用 BEGIN 和 END 也是一个好习惯。)
⚠️注意⚠️
- 在 触发器中, 用于访问新插入行的列。
- 在 触发器中, 用于访问更新后的行的列,而 用于访问更新前的行的列。
x
到此这篇sqlldr 命令(sqlldr命令不存在)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sqlbc/13802.html