
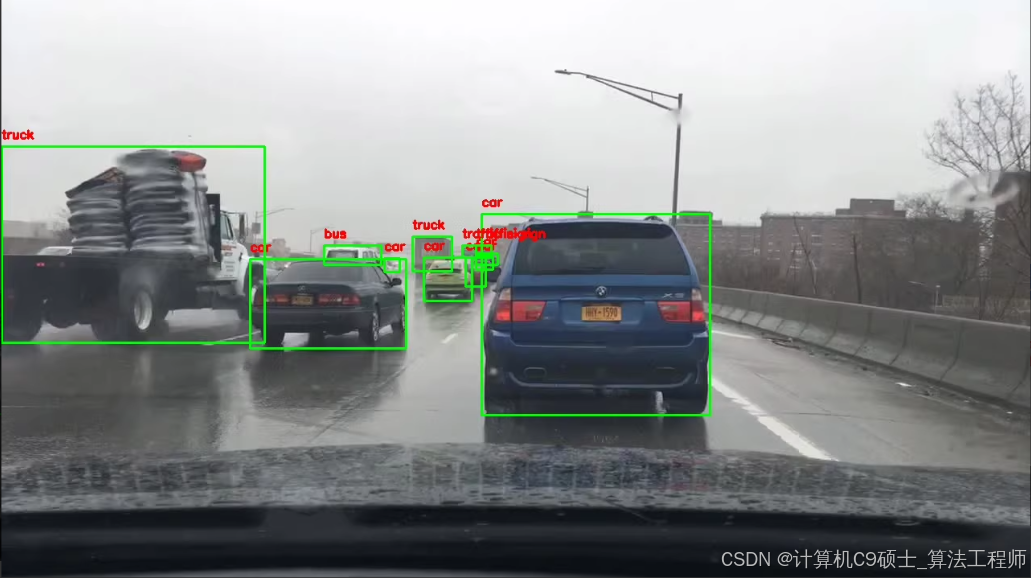
自动驾驶数据集,包含10万张图片
yolo可直接使用
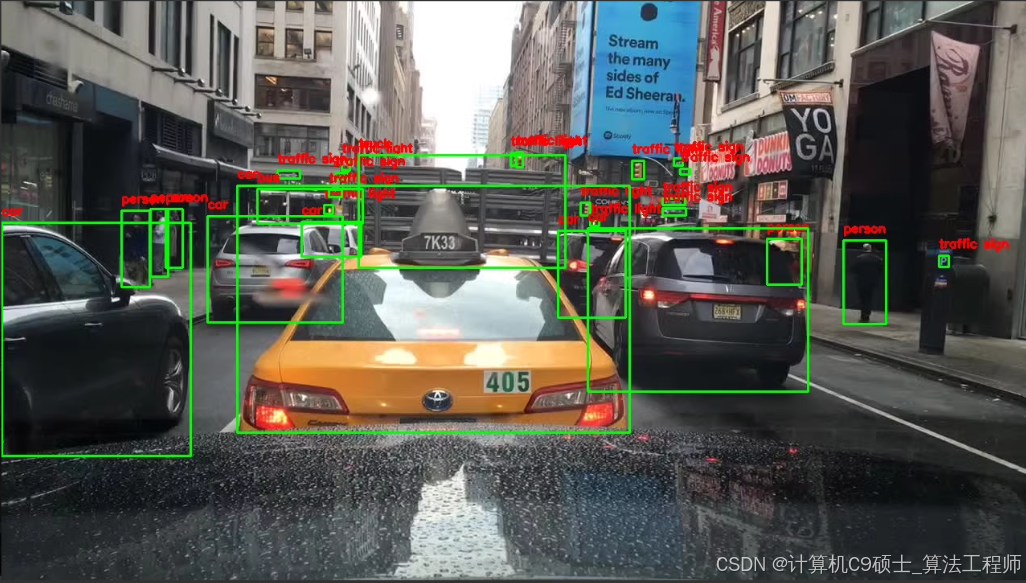
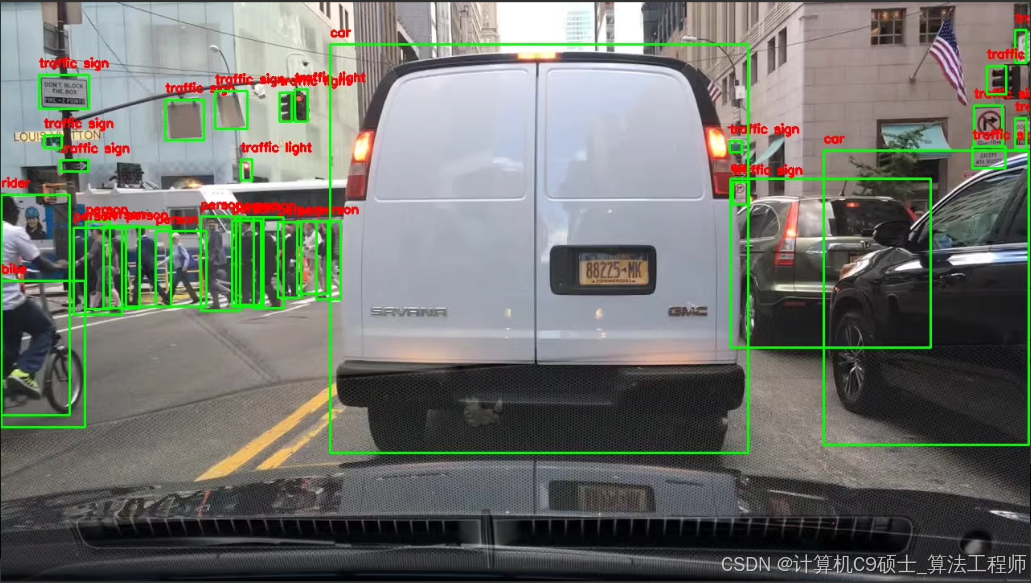
可用于自动驾驶目标识别研究
标注十个目标类别:
[“person”, “rider”, “car”, “bus”, “truck”, “bike”, “motor”, “traffic light”, “traffic sign”,“train”]
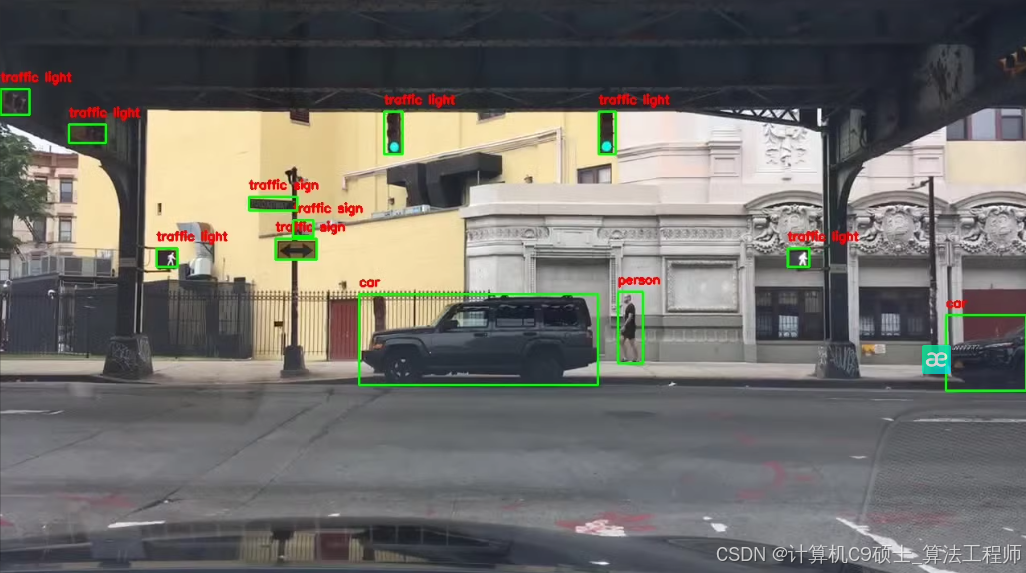
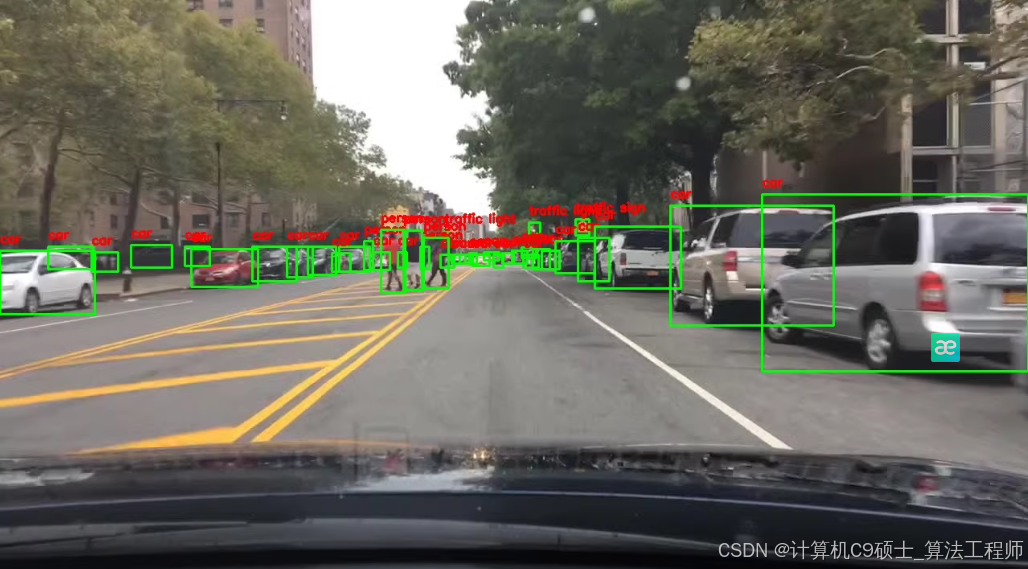
使用YOLOv8进行训练的详细步骤和代码。
数据集介绍
- 数据集概述
数据集名称:自动驾驶目标识别数据集
图像数量:10万张图片
标注目标类别:10个类别,包括[“person”, “rider”, “car”, “bus”, “truck”, “bike”, “motor”, “traffic light”, “traffic sign”, “train”]
数据集格式:YOLO格式
数据集划分:已划分好训练集、验证集和测试集 - 数据集结构
假设你的数据集已经按照以下结构组织:
深色版本
autonomous_driving_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
└── labels/
├── train/
├── val/
└── test/
每个文件夹中包含对应的图像文件和标签文件。确保所有图像文件都是.jpg或.png格式,而标签文件是.txt格式,并且它们的名字与对应的图像文件相同。
yaml
深色版本
train: autonomous_driving_dataset/images/train
val: autonomous_driving_dataset/images/val
test: autonomous_driving_dataset/images/test
labels_train: autonomous_driving_dataset/labels/train
labels_val: autonomous_driving_dataset/labels/val
labels_test: autonomous_driving_dataset/labels/test
names:
0: person
1: rider
2: car
3: bus
4: truck
5: bike
6: motor
7: traffic_light
8: traffic_sign
9: train
- 安装依赖
确保你的开发环境中安装了必要的软件和库。YOLOv8是基于PyTorch框架的,因此你需要安装Python以及PyTorch。
安装Python(推荐3.7或更高版本)
安装PyTorch:你可以从PyTorch官方网站获取安装命令,根据你的系统配置选择合适的安装方式。
克隆YOLOv8的官方仓库到本地,并安装项目所需的其他依赖:
bash
深色版本
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
pip install -r requirements.txt
2. 训练模型
在完成上述准备工作后,你可以开始训练模型了。打开终端,进入YOLOv8项目的根目录,运行训练命令:
bash
深色版本
python ultralytics/yolo/v8/detect/train.py --data autonomous_driving_dataset.yaml --cfg yolov8.yaml --weights yolov8x.pt --batch-size 16 --epochs 100
这里:
–data 参数指定了数据集配置文件的路径。
–cfg 参数指定了模型配置文件。
–weights 参数用于指定预训练权重的路径,这有助于加速训练过程并提高最终模型的性能。
–batch-size 和 --epochs 分别设置了批量大小和训练轮数。
模型评估
训练完成后,可以通过验证集来评估模型的性能。YOLOv8提供了方便的命令来进行模型评估:
bash
深色版本
python ultralytics/yolo/v8/detect/val.py --data autonomous_driving_dataset.yaml --weights runs/train/exp/weights/best.pt
这里,best.pt 是训练过程中保存的最佳模型权重文件。
bash
深色版本
python ultralytics/yolo/v8/detect/predict.py --source path/to/your/image.jpg --weights runs/train/exp/weights/best.pt --conf 0.25
这里:
–source 参数指定了要检测的图像路径。
–conf 参数设置了置信度阈值,低于该阈值的检测结果将被忽略。
注意事项
数据增强:为了提高模型的泛化能力,可以考虑使用数据增强技术,如随机裁剪、翻转、颜色抖动等。
超参数调整:根据训练过程中观察到的损失值和验证集上的性能,适当调整学习率、批量大小等超参数。
硬件资源:如果显存不足,可以减少批量大小或使用更小的模型变体。
多尺度训练:可以尝试多尺度训练,以提高模型对不同尺度目标的检测能力。
进一步优化
数据预处理:确保图像质量和尺寸一致,可以使用图像增强技术提高模型的鲁棒性。
模型选择:根据实际需求选择合适的YOLOv8模型变体,如yolov8s、yolov8m、yolov8l等。
多GPU训练:如果有多块GPU,可以使用多GPU训练来加速训练过程。
示例代码
- 数据集转换(如果需要)
假设你的标签文件已经是YOLO格式,可以直接跳过这一步。如果需要从其他格式(如COCO格式)转换,可以参考以下代码:
python
深色版本
import os
import json
import cv2
def convert_coco_to_yolo(coco_annotation_file, output_dir, image_dir):
with open(coco_annotation_file, ‘r’) as f:
coco_data = json.load(f)
convert_coco_to_yolo(‘path/to/coco/annotations.json’, ‘path/to/output/labels’, ‘path/to/images’)
2. 训练脚本
确保你已经将数据集和配置文件准备好,然后运行以下训练脚本:
cd ultralytics
python ultralytics/yolo/v8/detect/train.py --data autonomous_driving_dataset.yaml --cfg yolov8.yaml --weights yolov8x.pt --batch-size 16 --epochs 100
3. 评估脚本
训练完成后,评估模型性能:
bash
深色版本
python ultralytics/yolo/v8/detect/val.py --data autonomous_driving_dataset.yaml --weights runs/train/exp/weights/best.pt
4. 推理脚本
使用训练好的模型进行推理:
bash
深色版本
python ultralytics/yolo/v8/detect/predict.py --source path/to/your/image.jpg --weights runs/train/exp/weights/best.pt --conf 0.25
希望以上信息对你有所帮助!
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sjkxydsj/76142.html