
第一章 基本知识
数据和信息
信息:关于现实世界事物存在方式和运动状态的反映。
数据:通常指用符号记录下来的、可以识别的信息。
数据处理和数据管理
数据处理是指从某些已知的数据出发,推导加工出一些新的信息。
数据管理是指数据的收集、整理、存储、维护、检索、传送等操作。这部分操作是数据处理业务的基本环节,而且是任何数据处理业务中必不可少的共有部分。
数据库基本术语
数据库(DB):长期存储在计算机内、有组织的、统一管理的相关数据的集合。
数据库管理系统(DBMS):位于用户和操作系统之间的一层数据管理软件。
数据库系统(DBS):实现有组织地、动态地存储大量关联数据、方便多用户访问的计算机硬件、软件和数据资源组成的系统。
数据库技术:与数据库的结构、存储、设计、管理和使用的相关技术。
数据存储方法的演化历史:磁盘、卡片和纸带发展到磁盘,同时磁盘容量出现飞速增长。
数据库技术的发展经历了三个阶段:手工管理阶段、文件系统阶段和数据库阶段。
手工管理阶段:在20世纪50年代以前,外存只有磁带、卡片和纸带,还没有直接存取设备,没有操作系统,没有管理数据的软件,也没有文件的概念。数据量少,由用户自己管理,且数据没有组织结构,是面向应用的,依赖于应用程序,不能独立存在。
文件系统阶段:50年代后期到60年代中期,出现了磁鼓、磁盘等存储设备,于是数据被组织成独立的数据文件,这样数据以“文件”形式长期保存在外部存储器的磁盘上,系统通过文件名访问,对文件里的记录进行存取,并可对文件中的记录进行增删改。文件系统实现了记录的结构化,即给出了记录间各种数据的关系,使得数据的逻辑结构与物理结构有了区别。文件组织也已经多样化。数据不再属于某个特定的程序,可以重复使用。
但文件从整体上看仍是无结构的,数据共享性、独立性差,数据之间联系弱,数据不一致,且有大量冗余,所以管理和维护的代价很大。
数据库阶段:60年代后期,出现了数据库这样的数据管理技术。1968年IBM推出层次模型的IMS系统。1969年CODASYL组织发布了DBTG报告,总结了当时各种数据库,提出网状模型。可以说,层次数据库是数据库系统的先驱,而网状数据库则是数据库概念、方法、技术的奠基者。1970年IBM的E.F.Codd连续发表论文,提出关系模型,奠定了关系数据库的理论基础。
数据库的特点有:采用数据模型表示复杂的数据结构;有较高的数据独立性;数据库系统为用户提供了方便的用户接口;数据库系统提供了数据库的并发控制、数据库的恢复、数据的完整性、数据安全性这四方面的数据控制功能。
除了关系数据库,如今还有一些高级数据库,比如分布式数据库系统、对象数据库系统、网络数据库系统。
分布式数据库通常使用位于不同的地点的较小的计算机系统,通过网络连接构成完整的、全局的大型数据库。每台计算机有DBMS的一份完整拷贝,且具有自己局部的数据库。
对象数据库是用以对象形式表示信息的数据库。对象数据库的管理系统称为ODBMS或OODBMS。
网络数据库由数据和资源共享这两种方式结合在一起而成,也称Web数据库。它以后台(远程)数据库为基础,加上一定的前台(本地计算机)程序,通过浏览器完成数据的存储、查询等操作。
数据库系统的体系结构
数据库系统的结构常采用三级模式结构:外模式、概念模式、内模式。
概念模式简称为模式,它表示了对数据的全局逻辑级的抽象级别,是数据库中全部数据的整体逻辑结构的描述。它由若干个概念记录类型组成,还包含记录间联系、数据的完整性、安全性等要求。在实现中,它可以对应于所有的表格。
内模式也称存储模式,表示了对数据的物理级的抽象级别。它是数据库中全体数据的内部表示或底层描述,是数据库最低一级的逻辑描述,它描述了数据在存储介质上的存储方式和物理结构,对应着实际存储在外存储介质上的数据库。它包括记录类型、索引、文件的组织等,用内模式描述语言来描述、定义。
外模式也称子模式,表示了对数据的局部逻辑级的抽象级别。它对应于用户级,是用户与数据库系统的接口,是用户用到的那部分数据的描述。在实现中可以对应于视图。
三级模式间存在二级映象:
外模式/概念模式映象:局部逻辑级和全局逻辑级的一级映象,提供了逻辑独立性。这样在修改表格时,只需要相应修改映象,而用户程序不会受到影响。
概念模式/内模式映象:全局逻辑级和物理级的一级映象,提供了物理独立性。这样在进行数据库迁移时,比如从mysql到sqlserver,表格并不需要发生变化。
DBMS用于管理数据库。应用程序向DBMS发送请求,DBMS则向DB发出底层指令。DB向DBMS返回数据(查询结果),DBMS对数据进行处理并返回给应用程序数据(处理结果)。
DBMS的主要功能有:数据库的定义功能、数据库的操纵功能、数据库的保护功能(数据库的恢复、数据库的并发控制、数据完整性控制和数据安全性控制)、数据库的维护功能和数据字典(存放数据库的信息,其用途为描述数据,比如一个表的创建者信息,创建时间信息,所属表空间信息,用户访问权限信息等)。
数据库系统的组成:数据库、硬件、软件(DBMS、OS、开发工具等)和数据库管理员。
数据库系统的用户角色有:
DBA(Database Administrator):是控制数据库整体结构的一组人员,负责DBS的正常运行,承担创建、监控和维护数据库的责任。它的职责有:定义模式、定义内模式、与用户的联络(包括定义外模式、应用程序的设计、提供技术培训等专业服务)、定义安全性规则和对用户访问的数据库进行授权、定义完整性规则及监督数据库的运行、数据的转储和恢复工作。
专业用户:使用专用的数据库查询语言操作数据的计算机工作者。
应用程序员:使用主语言和DML语言(Data Manipulation Language,SQL的分类之一,包括:INSERT、UPDATE、DELETE。)编写应用程序的计算机工作者。
终端用户:使用应用程序的非计算机人士。
第二章 数据模型
数据模型的概念
能表示实体类型及实体间联系的模型称为“数据模型”。
数据模型分为两类:概念数据模型、辑数据模型和物理数据模型。
概念数据模型(Conceptual Data Model)贴近于现实世界,它独立于计算机系统,完全不涉及信息在计算机中的表示,只是用来描述某个特定组织所关心的信息结构。
最常用的概念数据模型是E-R(Entity-Relationship)模型,即实体-联系模型。它的数据描述有:
实体:客观存在,可以互相区别的事物。
实体集:性质相同的同类实体的集合。
属性:实体的特性。
实体标识符。
联系:实体之间的相互联系。
ER模型可以用ER图来表示,它看起来如下:
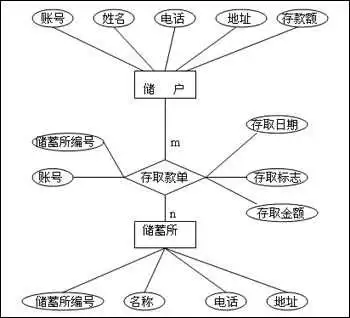
ER图有三个基本成分:矩形框,用于表示实体类型(考虑问题的对象);菱形框,用于表示联系类型;椭圆形框,用于表示实体和联系类型的属性,实体的主键属性里文字下方应该有下划线。从上图可以看到实体和联系都可以有属性。一般说来,ER图里实体都是名词,而联系都是动词。
与一个联系有关的实体集个数被称为元数。一个联系可以是一元联系、二元联系或多元联系。上图展示的联系就是二元联系。根据实体参与的数量,二元联系又可分为一对一(1:1,乘客和座位)、一对多(1:N,车间和工人)和多对多(M:N,学生和课程)。上表中的联系上m和n表示多对多的关系。一元联系的一个例子是零件的组合关系,一个零件可以用若干子零件组成。
属性的分类
根据属性的可分性,属性有基本属性和复合属性。比如地址可以包含邮编、街道、门牌号,它是一个复合属性。
根据属性的值的数量,属性有单值属性和多值属性。比如一个人的姓名是一个单值属性,而他的网名是多值属性。多值属性在ER图里用双线椭圆表示。
此外,还有导出属性(派生属性),它通过具有相互信赖的属性推导出来,比如一个学生的平均成绩。导出属性在ER图里用虚线椭圆表示。
注意属性的值可以是空值。
存在依赖(Existence Dependency):如果实体x的存在依赖于实体y的存在,则称x存在依赖于y。y称作支配实体,而x称作从属实体(弱实体)。弱实体主键的一部分或全部从被依赖实体获得。如果y被删除,那么x也要被删除。从属实体的集合便称为弱实体集。弱实体在ER图里用双线矩形表示。比如某单位的职工子女信息,如果职工不在该单位了,其子女信息也没有意义了,所以职工子女信息是一个弱实体。
逻辑数据模型贴近于计算机上的实现,是用户从数据库看到的模型,是具体DBMS所支持的数据模型。此模型既要面向用户,又要面向系统,主要用于DBMS的实现。逻辑模型有层次模型、网状模型和关系模型。
层次模型:用树形结构表示实体类型及实体间联系的数据模型,盛行于20世纪70年代。缺点是只能表示1:N的关系,且查询和操作很复杂。
网状模型:用有向图表示实体类型及实体间联系的数据模型,盛行于70年代至80年代中期。它的特点是记录之间联系通过指针实现,M:N也容易实现,查询效率较高。缺点是数据结构复杂,编程复杂。
关系模型:用二维表格表示实体集;用关键码而不是用指针导航数据。SQL语言是具有代表性的语言。
物理数据模型()面向于计算机物理表示,描述了数据在存储介质上的组织结构,不仅和具体的DBMS有关,还与操作系统和硬件有关。每一种逻辑数据模型在实现时都有起对应的物理数据模型。DBMS为了保证其独立性与可移植性,大部分物理数据模型的实现工作由系统自动完成,而设计者只设计索引、聚集等特殊结构。
ER模式的设计的过程为:设计局部ER模式、设计全局模式和全局ER模式的优化。
局部ER模式设计基于需求分析的结果,1、确定局部结构范围;2、实体定义;3、联系定义;4、属性分配;5、查看是否还有待分析的局部结构,若有则跳到第2步,否则进入全局ER模式设计阶段。
全局ER模式设计基于局部ER模式,1、确定公共实体类型;2、合并两个局部的ER模式;3、检查并消除冲突;4、重复第3步直到不再有冲突;5、检查是否还有未合并的局部ER模式,若有则跳到第2步,否则便完成了ER模式设计。
全局ER模式的优化有:实体类型的合并(一般的可以把1:1联系的两个实体类型合并);冗余属性的消除;冗余联系的消除(通常利用规范化理论中的函数依赖的概念消除冗余联系)。
在ER模式的设计过程中,常常要对ER模型进行种种变换。变换包括:分裂、合并和增加删除。
实体的分裂有水平分裂和垂直分裂。水平分裂根据应用对象的不同,分成两个具有相同属性的实体,比如书店的书可以水平分裂成“有库存”和“无库存”两个实体,这样方便对两种实体进行不同的操作。垂直分裂根据属性的使用频率,分成两个属性不同的实体,比如图书有作者、版次、价格等属性,分成包含常用的作者、版次属性的图书和包含不常用的价格属性的图书。垂直分裂的好处是可以减少每次存取的数据量。
联系的分裂可以细化联系,比如程序员和项目的联系“参与”,可以分裂成“开发”和“维护”。
合并是分裂的逆过程。注意合并的联系类型只能是定义在相同的实体类型上的。
ER模型向关系模型的转换规则
实例类型的转换:将每个实体类型转换成一个关系模型,实体的属性即为关系模型的属性,实体的标识符即为关系模型的键。
二元联系类型的转换:
1:1联系:在由实体转换成的两个关系模式之间选任一个加上一个属性来表示另一个关系模式的键和联系。也就是结果只有两张表,其中一张表里会有外键表示联系。
1:N联系:在N端实体转换成的关系模式里加上1端实体类型的键和联系类型和属性。最终的结果也是两个表,N端的表有外键。
M:N联系:将联系类型转换成关系模式,其属性为两端实体类型的键加上联系类型的属性,而键为两端实体键的组合。最终的结果有三张表,其中一张表专门表示联系,包含另两个表的外键。
第三章 关系数据库理论
关系模型是用二维表格表示实体,用键码进行数据导航的数据模型。数据导航是指从已知数据查找未知数据的方法。在关系模型中,记录称为元组,为行(Row);字段称为属性,为列(Column)。
超键(Super Key)是可以唯一标识元组的属性集。候选键(Candicate Key)是不含多余属性的超键。主键(Primary Key)是用户选做元组标识的候选键。外键(Foreign Key)是当模式R中的属性K是其它模式的主键,那么K在R中称为键。
关系是一个属性集相同的元组的集合。由于是集合,因此:
1、关系中没有重复的元组;
2、关系中的元组是无序的,即没有行序;(理论上属性集也是无序的,但使用时习惯考虑列的顺序)。
每个属性都是不可分解的整体,比如只能是整型、字符这种简单类型,而不能是结构体这样的复杂的类型。
根据元组的数目,关系可分为有限关系和无限关系。
关系模式有三类完整性规则:
1、实体完整性规则,即主键的值不能是空值;
2、参照完整性规则,即不允许(通过外键)引用不存在的实体;
3、用户定义的完整性规则,比如属性“性别”只能接受“男”和“女”作为合法值,其它的输入都是非法的。
2、受限删除:仅当参数关系中没有外键与被参照关系中要删除的元组主键值相同时才允许删除,否则拒绝删除操作;
3、置空值删除:删除被参照关系中的元组,并将参照关系中相应的外键值置空值。
而向参照关系插入元组时,有两种策略:
1、受限插入:仅当被参照关系存在相应的元组,且其主键和要插入的元组的外键值相同时才允许插入,否则拒绝插入操作;
关于实体完整性,主键的修改操作有两种方法:一种是不允许修改主键;另一种是允许修改主键,但必须保证修改后的主键唯一且非空。当修改的主键是参照关系的外键时,可以使用三种策略:级联修改、受限修改和置空值删除。
关系代数的运算有多种。
五个基本操作:并(Union,∪)、差(set difference,−)、笛卡儿积(Cartesian product,×)、投影(Projection,Π)和选择(Selection,σ);
四个组合操作:交(Intersection,∩)、连接(-Join)、自然连接()和除法();
七个扩充操作:改名、广义投影、赋值(←)、外连接(Outer joins,、外部并、半连接、聚集操作。
选择运算:从关系中选择满足给定条件的元组。比如σA<5(R)在关系R中选择属性A的值小于5的元组。
投影运算:从关系中取出若干列组成新的关系,投影结果里要删除重复的元组。比如ΠA,B(R)从关系R中取出属性集(A、B)。
并运算:合并两个关系,即元组合并。这两个关系必须是同构的,即属性集应该相同。
S1∪S2的结果为:
交运算:得到同时出现在两个关系的元组集合。
例如,
S1∩S2的结果为:
差运算:得到出现在一个关系而不在另一个关系的元组集合。
例如:
S1−S2的结果为:
换句话说,(S1−S2)∩S2=,而(S1−S2)∪S1=S1。
笛卡儿乘积运算:把一个关系中的每个元组和另一个关系的所有元组连接成新关系中的一个元组。新关系的元组数是两个关系的元组数之积。
运算中的查询优化:尽可能早地执行选择操作和投影操作;避免直接做笛卡儿乘积,把笛卡儿乘积之前和之后的一连串操作和投影合并起来做。
除运算:它类似于(但不完全是)笛卡儿乘积的逆运算,被除关系的属性集(M,N)真包含除关系的属性集(N),得到的结果关系的属性集为被除关系的属性集与除关系的属性集的差集(M),且结果关系是与除关系的笛卡儿乘积被包含于被除关系的最大关系。换句话说,若R1(M,N) R2(N) = R3(M),则R3(M) × R2(N) ⊆ R1(M,N),而在ΠM(R1)−R3里,没有任何子集能足这样的关系。
结果其实为选修了所有课程的学生号。
除运算的另一种形式表达为:r s = ΠR-S(r) -ΠR-S((ΠR-S(r) × s) - ΠR-S,S(r)) (小写r、s为关系名,而大写R、S分别为r、s的属性集)。
更名运算:x(E)可以返回关系表达式的结果,并重命名这个表达式为x。x(A1,A2,...,An)(E)同时将各属性更名为A1、A2……,An。例如数学成绩比王红同学高的学生:ΠS.姓名(σR.成绩<S.成绩 ∧ R.课程=数学 ∧ S.课程=数学 ^ R.姓名=王红(R ×)。其实更名运算就是SQL里的as。
连接:从两个关系的广义笛卡儿积中选取给属性间满足一定条件的元组通常写法为:
自然连接:从两个关系的广义笛卡儿积中选取在相同属性列上取值相等的元组,并去掉重复的列。比如前面的S1表和SC1表的自然连接的结果为:
赋值运算:用于存储临时变量,比如r s的过程可写成:
temp1 ΠR-S(r)
temp2 ←ΠR-S(tmp1 × s) - ΠR-S,S(r))
result ←temp1 - temp2
广义投影:在投影列表中使用算术表达式来对投影进行扩展:ΠF1, F2, ..., Fn(E),其中F1,F2,...Fn是算术表达式。比如:ΠA*5, B+3(R)。
外连接:为避免自然连接时因失配而发生的信息丢失,可以假定往参与连接的一方表中附加一个取值全为空值的行,它和参与连接的另一方表中的任何一个未匹配上的元组都能匹配,称之为外连接。
外连接 = 自然连接 + 未匹配元组
外连接的形式有:左外连接、右外连接和全外连接。
左外连接 = 自然连接 + 左侧表中未匹配元组
右外连接 = 自然连接 + 右侧表中未匹配元组
考虑两张表“学生借书信息”(R)
和“学生会信息”(S):
左外连接:RS
右外连接:RS
体育部
全外连接:RS
半连接:类似于自然连接,但R ⋉ S 的连接的结果只是在 S 中有在公共属性名字上相等的元组所有的R 中的元组,而RS刚好相反。
还是以前面的“学生借书信息”和“学生会信息”为例:
R ⋉ S:
R S:
聚集函数:求一组值的统计信息,返回单一值。使用聚集的集合可以是多重集,即一个值可以重复出现多次。如果想去除重复值,可以用连接符“-”将“distinct”附加在聚集函数 名后,如sum-distinct。
聚集函数包括:
sum:求和。例如求001号学生的总成绩:sumscore(σs#=001(SC))
avg:求平均数。
count:计数。
max:求最大值。
min:求最小值。
聚集函数可以使用分组,将一个元组集合分为若干个组,在每个分组上使用聚集函数。它的形式是:属性下标G聚集函数属性下标(关系)。例如
“学号G avg分数(成绩表)”得到每个学生的平均成绩。
分组运算G的一般形式是:G1,G2,...,GnGF1(A1),F2(A2),...,Fm(Am)(E)。在关系表达式E里,所有在G1,G2,...,Gn上相等的元组分成一组,分别在属性A1上执行F1,属性A2上执行F2,…,属性Am上执行Fm。
第四章 结构化查询语言
SQL可以分为两类:数据操作语言(Data Manipulation Language,DML)和数据定义语言(Data Definition Language,DDL)。
DML由查询和更新命令组成:
- SELECT:从数据库中取出数据。
- UPDATE:更新数据库的数据。
- DELETE:从数据库中删除数据。
- INSERT INTO:向数据库插入新数据。
DDL创建和删除数据库、创建和删除表、定义索引(关键字)、指定表之间的联系、定义表之间的约束。SQL里最重要的DDL的语句有:
- CREATE DATABASE:创建一个新的数据库
- ALTER DATABASE:修改一个数据库。
- CREATE TABLE :创建一张新的表。
- ALTER TABLE :修改一张表。
- DROP TABLE :删除一张表。
- CREATE INDEX :创建一个索引。
- DROP INDEX :删除一个索引。
用SELECT进行查询时,可以会有重复的记录。使用DISTINCT语句可以消除重复数据。比如:select distinct name from persons。使用WHERE可以指定查询的目标,比如:select * from persons where age >= 18。
Note: In some versions of SQL the <> operator may be written as !=
IN的语法是
BETWEEN的语法是:
在对字符串比较时,需要用单引号包围字符串常量(多数据数据库系统也接受双引号),数值不应该使用绰号。
LIKE比较时可以使用的通配符有:
在进行条件判断时,可以使用AND和OR来连接逻辑表达式。
可以使用ORDER BY对查询的结果进行排序,它的语法为
ORDER BY column_name(s) ASC|DESC
注意limit和top都不是SQL标准。
INSERT用来插入数据,语法为:
The second form specifies both the column names and the values to be inserted:
UPDATE更新数据,语法为:
AS 可以为表起别名:- JOIN:自然连接;
- LEFT JOIN:左外连接;
- RIGHT JOIN:右外连接;
- FULL JOIN:全外连接。
INNER JOIN 语法
LEFT JOIN 语法
RIGHT JOIN 语法
FULL JOIN 语法
UNION 求并集,语法为:
Note: The UNION operator selects only distinct values by default. To allow duplicate values, use UNION ALL.
UNION ALL保留重复的记录:
NOT NULL约束强制某一列不接受NULL值。比如:
UNIQUE约束保证某列没有重复记录。在mysql中可以在创建表时有两种方法指定:
或:
在表创建后加入UNIQUE约束的方法是:
注意:如果该列中已经有重复的记录,那么加入约束会失败
删除UNIQUE约束:
创建PRIMARY KEY约束:
修改表来加入PRIMARY KEY约束:
删除PRIMARY KEY约束:
创建外键 FOREIGN KEY:
修改表以创建FOREIGN KEY :
删除FOREIGN KEY约束:
创建 CHECK 约束: 或
修改表以创建CHECK约束:
删除CHECK约束:
或
创建DEFAULT约束:
My SQL / SQL Server / Oracle / MS Access:
修改表以创建DEFAULT约束:
或
删除DEFAULT约束:
在表上创建一个允许重复值的索引:
在表上创建唯一的索引:
删除INDEX:
一个表上的约束可以通过
来查看。mysql上可以通过修改一个列来增加约束:
br />
br />
DROP TABLE
删除一张表:br />
DROP DATABASE
删除一个数据库:br />
TRUNCATE TABLE
可以删除一张表的所有数据而不删除该表:br />
br />
br />
br />
视图
是基于一个SQL语句的结果集的一张虚拟表。视图的优点有:br />
创建视图
:
br />
br />
MySQL的日期函数
:br />
br />
br />
IS NULL
br />
IS NOT NULL
操作符判断非空值:br />
MySQL
没有ISNULL函数,所以它使用
IFNULL
:br />
COALESCE
()函数:br />
Text types:
br />
Number types:
Date types:
br />
br />
SQL聚集函数
计算某列的各值,返回单一值。br />
DISTINCT
来消除重复,比如:select sum(distinct
age) from persons。
AS
来起别名,比如select sum(age) as MySum from persons。
br />
br />
br />
br />
br />
GROUP BY
可以根据记录在某列上的值把表的记录分组,然后分别计算各组的聚集函数的值。它也能指定多个列比如:br />
br />
br />
标量函数
基于输入值返回单个值。有用的标量函数有:
br />
br />
br />
br />
第五章 数据库设计
是指从软件的规划、研制、实现、测试、投入运行后的维护,直到它被新的软件所取代而停止使用的整个历程。
。它包括
。
br />
br />
:系统调查、可行性分析、确定数据库系统的总目标和制定项目开发计划。
:分析用户活动,产生业务流程图;确定系统范围,产生系统范围图;分析用户活动设计的数据,产生数据流图;分析系统数据,产生数据字典。
:进行数据抽象,设计局部概念模式;将局部概念模式综合成全局概念模式。
:从之前得到的概念模式出发,1、导出初始DBMS模式说明;2、子模式设计和应用程序设计草图;3、模式评价;4,如果处理结束,则进入物理设计阶段,否则进入下一步;5、检查模式是否需要修正,如果需要则修正模式,并回到第2步,否则回到前面的阶段。
:存储记录结构设计;确定数据存放位置;存取方法的设计;完整性和安全性考虑;程序设计。
:定义数据库结构;数据装载(大型应用和小型应用);编制和调试应用程序;数据库试运行。
:数据库的转储和恢复;数据安全性、完整性控制;数据库性能的监督,分析和改进;数据库的重组织和重构造。
br />
br />
第六章 关系数据库的规范化理论
br />
br />
姓名 电话 参与的俱乐部 俱乐部的活动 A 123 乒乓club 打乒乓球 A 123 登山club 爬山 B 456 乒乓club 打乒乓球 B 456 英语club 学习英语 C 789 登山club 爬山 C 789 英语club 学习英语
:一个人参与几个俱乐部,那么他的电话会重复几次;同样,一个俱乐部被几个人参加,它的活动就会重复几次。
:一旦一个人的手机号变化,那么对应于他参与的每个俱乐部的各行里的电话都需要修改,如果有遗漏,那么会造成数据不一致;俱乐部的活动也是如此。
:如果一个新人到来,还未参加任何俱乐部,那么他的信息和电话就无法插入到这张表里,因为参与的俱乐部是主属性,不能为空。
:如果某人暂时退出了所有的俱乐部,那么必须把所有的元组都删去,这样这个人的姓名和电话信息也不存在了。
br />
姓名 电话 A 123 B 456 C 789
俱乐部 活动 乒乓club 打乒乓球 英语club 学习英语 登山club 爬山
姓名 参与的俱乐部 A 乒乓club A 登山club B 乒乓club B 英语club C 登山club C 英语club
br />
函数依赖
(FD,Functional Dependency)br />
函数依赖的概念
为:设有关系模式R(U),X和Y是属性集U的子集,函数依赖是形为X
Y的一个命题,只要有r是R的当前关系,对r中的任意两个元组t和s,都有t[X] = s[X]蕴涵t[Y] = s[Y],那么称函数依赖X
Y在关系模式R(U)中成立。比如前面的U是(姓名,电话,参与的俱乐部,俱乐部的活动),子集X为(姓名),子集Y为(电话)。
函数依赖的文字化定义
:设R(U)是属性集U上的关系模式,X、Y是U的子集,若对于R(U)的任意一个可能的关系r,R中不可能存在两个元组在X的属性值上相等,而在Y上的属性值不等,则称“X函数确定Y”,或“Y函数依赖于X”,记作X
Y。例如
姓名
→
电话。br />
FD的推理规则
有:
自反性
:Y⊆X
X
Y
增广性
:XZ
YZ
传递性
:X
Y, Y
Z
X
Z
合并性
:{X
Y, X
Z}
X
Y
Z分解性
:{X
Y, Z ⊆ Y}
X
Z
伪传递性
:{X
Y, WY
Z}
WX
Z
复合性
:{X
Y, W
Z}
WX
Y
Zbr />
br />
有:
Y,但X ⊄ Y,则称X
Y是非平凡的函数依赖,一般不特殊指明的情况下,我们总是讨论非平凡函数依赖。
Y,则称X是决定因素。
Y
Y,Y
X,
则称X与Y一一对应,记为XY。
Y,并且对于X的任意一个真子集X',都有X'
Y,则称Y
于X,或Y对X完全函数依赖,记作
-
->
,否则称Y对X
,
-
->
。
Y,(X ⊄ Y),Y
Z,则称Z对X
传递函数依赖
。
-
->
,则K为R的
候选码
,若候选码多于一个,则选其中一个作为
主码
。特殊情况:所有属性构成码,称为
全码
。包含在任何一个候选码中的属性,叫
主属性
(Prime Attribute),不包含在任何码中的属性为
非主属性
,或
非码属性
。
外码(Foreign Key)
。关系间是通过主码和外码进行联系的。
br />
规范化理论
第一范式1NF(Normal Form)、2NF、3NF、BCNF及4NF
,逐步消除更新异常问题。
规范化
。
={R1,……,Rk}。用
代替R的过程为
关系模式的分解
。
br />
1NF
指每一个分量都是不可分的,这是最基本的规范化。即关系的所有属性都只能是预定义的简单变量,如整型,而不能是结构体。
2NF
的定义为:如果R∈1NF,且每个非主属性完全函数依赖于码,则R∈2NF。如本章最开始提出的问题,在属性性(姓名,电话,参与的俱乐部,俱乐部的活动)里,候选码为(姓名,参与的俱乐部),即姓名和参与的俱乐部是主属性,但是“电话”部分函数依赖于“姓名”,并没有完全函数依赖于码;“俱乐部的活动”同样也部分函数依赖于“俱乐部”。它便是由于违反了2NF,才造成了更新异常。而表的拆分便是
关系模式的分解
。
3NF
的定义:关系模式R<U,F>中若不存在这样的码X,属性组Y及非主属性Z(Z⊄Y),便利X
Y,Y
Z成立,则称R∈3NF。
员工 所在分公司 分公司总裁
所在分公司,所在分公司
分公司总裁。所以它违反了3NF。它造成的问题有修改异常:员工换了分公司的话,总裁属性也必须修改。遗漏会造成数据不一致。我们可以把它模式分解为:
员工 所在分公司
分公司 总裁
非主属性
的部分函数依赖或传递函数依赖,但并没有对主属性进行限制。
学号 姓名 课程名
主属性
。如果我们选取(学号,课程名)作为主码,有(学号,姓名)
学号
,学号姓名
的传递依赖,也可以理解为部分依赖,但是因为姓名是主属性,所以这个关第符合2NF、3NF。然而,它有之前讨论过的冗余和更新异常的问题。BCNF(Boyce Codd Normal Form)
是由Boyce和Codd提出的,比3NF又进一步,通常认为BCNF是修正的第三范式,有时也称为3NF。它的定义为:如果关系模式R是1NF,且每个属性(包括主属性)都不传递依赖于R的候选键,那么称R是BCNF范式。若R∈BCNF,则R∈3NF。
br />
br />
第七章 数据存储
:现今的AMD和Intel的CPU都在芯片内部集成了数据高速缓存和指令高速缓存,通称了L1高速缓存;比L1更大的L2高速缓存曾放在CPU外部的主板或CPU接口上,现在已经成为CPU内部的标准部件了;高端家用机或工作站甚至配备了L3缓存器。高速缓存使用
静态随机存取存储器
(
S
tatic
R
andom
A
ccess
M
emory,
SRAM
)技术,比主存的DRAM技术快。
br />
:使用
技术,性价比很高,扩展性也不错。DRAM里面所储存的数据需要周期性地更新,所以比SRAM较慢。最近生产的(2010年后)计算机主要使用的主存是DDR 3 SDRAM(
第三代双倍资料率同步动态随机存取内存
,Double-Data-Rate Three Synchronous Dynamic Random Access Memory)。
br />
:一种
EEPROM
芯片,
EEPROM
,或写作
E
2PROM
,全称
电子抹除式可复写只读内存
(
span lang="en">
Electrically-Erasable Programmable Read-Only Memory),是一种可以通过电子方式多次复写的半导体存储设备。相比
(
span lang="en">Erasable Programmable Read Only Memory
可擦除可编程式只读内存
span lang="en">
),EEPROM不需要用紫外线照射,也不需取下,就可以用特定的电压,来抹除芯片上的信息,以便写入新的数据。EEPROM被广泛用于需要经常擦除的BIOS芯片,以及
快闪存储器
(
span lang="en">
Flash Memory,简称
闪存
),并逐步替代部分有断电保留需要的RAM芯片,甚至取代部份的硬盘功能(固态硬盘
span lang="en">Solid State Disk
、
span lang="en">Solid State Drive
,简称
SSD
)。
span lang="en">
span lang="en">
:利用磁记录技术在涂有磁记录介质的旋转圆盘上进行数据存储的辅助存储器。具有存储容量大、数据传输率高、存储数据可长期保存等特点。
br />
:由光盘驱动器和光盘片组成的光盘驱动系统,光存储技术是一种通过光学的方法读写数据的一种技术,它的工作原理是改变存储单元的某种性质的反射率,反射光极化方向,利用这种性质的改变来写入存储二进制数据.在读取数据时,光检测器检测出光强和极化方向等的变化,从而读出存储在光盘上的数据.由于高能量激光束可以聚焦成约0.8μm的光束,并且激光的对准精度高,因此它比硬盘等其他存储技术具有较高的存储容量.
br />
br />
:一种用于记录声音、图像、数字或其他信号的载有磁层的带状材料,是产量最大和用途最广的一种磁记录材料。作为数字信息的存贮具有容量大、价格低的优点。主要大量用于计算机的外存贮器。目前仅在专业设备上使用(比如车床控制机)。
br />
数据存储文件的组织结构
:Heap File。插入的记录被 添加到文件的末尾,因此文件是无序的。记录被删除时,会在文件中间留下空白行,所以堆文件需要周期性地压缩来恢复空间。
br />
:Sequential File。记录以查找键的升序或降序的顺序存储。文件在载入到内存里时,可以以随机方式读取数组,比如可用二分查找法来优化查找时间。但把新记录写入到文件时,必须以顺序方式。
:Hash File。记录存储的地址(块号)是记录的某个属性值通过散列函数求得的值。
:Cluster File。“聚集(Clustering)”的意义是为了访问的效率把相关的数据存储在一起。多个数据库和多上表被合并(join)被称为聚集(cluster)。共享同一个聚集关键字的表被存储在一起,在相同或相邻的数据块里。这样可以提升表在聚集关键字上进行的聚集操作的效率。
br />
第八章 索引机制
br />
索引的概念
:在数据文件中,根据记录建立的一种数据结构,以次线性时间查找(sublinear time lookup)来加快查询速度。索引也用来监管数据库约束,比如unique、exclusion、primary key和foreign key。:数据以任意序表示,但索引指明了它的逻辑序(logical ordering)。数据行无视被索引的列的值而遍布在表中,但非簇集索引树包含排好序的索引关键字,并在叶子级包含记录的指针(页结构引擎(page-organized engines)里的页和数据页里的行号;文件结构引擎(file-organized engines)里的行偏移量)。
br />
:数据块以特定的顺序聚集来匹配索引,导致行数据顺序存储。因此,一张表只能创建一个簇集索引。如果文件记录以非码字段排序,那么这个字段称为簇集字段(cluster field)。
br />
br />
:一种特殊的索引,把它的大块数据存储在位数组(bit array)里,也就是位图里。多数查询都通过位逻辑操作来完成。如果索引的值不重复或只重复较少的次数时,那么最普遍使用的索引,比如b+tree,是最高效的。相反,位图索引被设计用在变量值频繁重复的情况下。比如只有“男”和“女”的性别属性。
br />
:数据文件里的每个
所对应的“关键字-指针”对所组成的文件。也就是说,数据文件里每个记录都有索引。在有重复关键字的簇集索引里,稠密索引指向该关键字的第一条记录。
:或非稠密索引(nondense index)。数据文件里的每个
都有相应的“关键字-块”对。在有重复关键字的簇集索引里,块指针指向每个块的最小的搜索键(
lowest search key
)。
br />
:在把关键字插入到索引之前,把关键字翻转。比如:值12345在索引里成为54321。它对于索引诸如序号(sequence number,单调增加的值)的值非常有用,特别是在大容量的事务处理系统(Transaction processing system)上,因为它们可以减少索引块的竞争。
br />
建立在有序文件中的排序码字段上。
指定在文件的任何非排序字段上。同一个文件只能有一个主存取方式,但是可以有多个辅助索引,从而有多个索引字段。当辅索引建立在码上时,该码字段被称为辅码(Secondary Key)。
br />
br />
索引文件的组织
:线性索引、树形索引和散列索引。br />
br />
第九章 并发控制和故障恢复
br />
是构成单一逻辑工作单元的操作集合。
。并发可能导致的问题有:丢失更新问题、读胀数据问题、错误求和问题、和不可重复读问题等等。
负责协调并发事务的执行,保证数据库的完整性,同时避免用户得到不正确的数据。
br />
:一个事务对数据库的所有操作,是一个不可分割的工作单元。这些操作要么全部执行,要么什么也不做。
:一个事务独立执行的结果,应保持数据库的一致性,即数据不会因事务的执行而遭到破坏。
:在多个事务并发执行时,系统应保证与这些事务先后独立执行的结果一样。
:一个事务一旦完成全部操作后,他对数据库的所有更新应永久地反映在数据库中。
。其中原子性是最主要的根本目标;其它三个是辅助的属性。
br />
第十章 数据库完整性机制
br />
br />
完整性子系统
br />
br />
br />
:在域定义中定义的一种约束。域约束与在特定域中定义的任何列有关。
br />
:在断言定义中定义一种约束。断言可以与一个或多个表进行关联。
br />
br />
:它是在表定义中定义的一种约束。该约束可以被定义为列定义的一部分,或者定义为表定义中的一个元素。在表级别定义的约束可以应用于一个或多个列。
br />
第十一章 数据库安全机制
br />
数据库安全性机制的概念
br />
安全性的级别
br />
授权子系统
br />
自主访问控制(DAC)
DAC
通过授权列表(或访问控制列表)来限定哪些主体针对哪些客体可以执行什么操作。如此将可以非常灵活地对策略进行调整。由于其易用性与可扩展性,自主访问控制机制经常被用于商业系统。
br />
br />
强制访问控制(MAC)
br />
视图机制
br />
数据加密
库外加密
、库内加密
、硬件加密
。 到此这篇数据库技术基础知识(数据库基础知识点总结)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sjkxydsj/40176.html