
Beautiful Soup 简称 BS4(其中 4 表示版本号)是一个 Python 第三方库,它可以从 HTML 或 XML 文档中快速地提取指定的数据。Beautiful Soup 语法简单,使用方便,并且容易理解.

图1:BS4官网LOGO图
由于 Bautiful Soup 是第三方库,因此需要单独下载,下载方式非常简单,执行以下命令即可安装:
由于 BS4 解析页面时需要依赖文档解析器,所以还需要安装 lxml 作为解析库:
Python 也自带了一个文档解析库 html.parser, 但是其解析速度要稍慢于 lxml。除了上述解析器外,还可以使用 html5lib 解析器,安装方式如下:
该解析器生成 HTML 格式的文档,但速度较慢。
“解析器容错”指的是被解析的文档发生错误或不符合格式时,通过解析器的容错性仍然可以按照既定的正确格式实现解析。
创建 BS4 解析对象是万事开头的第一步,这非常地简单,语法格式如下所示:
上述代码中,html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 ‘lxml’ 或者 ‘html5lib’,示例代码如下所示:
输出结果:
如果是外部文档,您也可以通过 open() 的方式打开读取,语法格式如下:
下面对爬虫中经常用到的 BS4 解析方法做详细介绍。
Beautiful Soup 将 HTML 文档转换成一个树形结构,该结构有利于快速地遍历和搜索 HTML 文档。下面使用树状结构来描述一段 HTML 文档:
树状图如下所示:
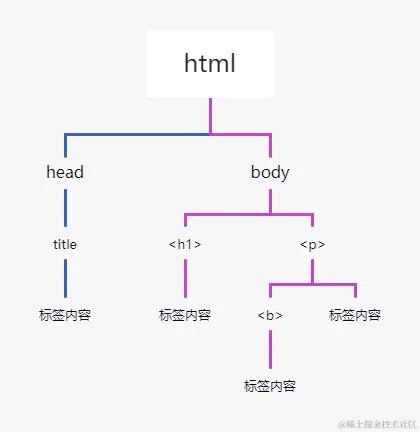
图1:HTML文档树结构图
文档树中的每个节点都是 Python 对象,这些对象大致分为四类:Tag , NavigableString , BeautifulSoup , Comment 。其中使用最多的是 Tag 和 NavigableString。
- Tag:标签类,HTML 文档中所有的标签都可以看做 Tag 对象。
- NavigableString:字符串类,指的是标签中的文本内容,使用 text、string、strings 来获取文本内容。
- BeautifulSoup:表示一个 HTML 文档的全部内容,您可以把它当作一个人特殊的 Tag 对象。
- Comment:表示 HTML 文档中的注释内容以及特殊字符串,它是一个特殊的 NavigableString。
1) Tag节点
标签(Tag)是组成 HTML 文档的基本元素。在 BS4 中,通过标签名和标签属性可以提取出想要的内容。看一组简单的示例:
到此这篇bs4解析数据(bs4库详解)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/sjkxydsj/15436.html