
主线为 Alec Radford 与 Luke Metz 等人的论文“Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”1。
摘要
近年来,计算机视觉应用中使用卷积网络的监督学习被广泛采用。相比之下,无监督学习受到更少关注。本文帮助缩小有监督学习与无监督学习中成功应用 CNNs 的差距。引入一类名为对抗的深度卷积生成网络 (DCGANs) 的卷积网络,该类网络有一定的结构约束,且表明它可很好地用于无监督学习。训练不同的图像数据集证明对抗的深度卷积对可学习到判别器和生成器中从物体局部到场景的分层表示。此外,针对新任务学到的特征表明它们作为通用图像表示的适用性。
1. 简介
从大量未标记数据集学习可重用的特征表示的研究活跃。计算机视觉中,可利用无数未标记图像和视频来学习不错的中间表示,诸如图像分类等不同的有监督学习任务可使用这些表示。训练对抗的生成网络 (GANs),然后利用部分的判别网络和生成网络为有监督任务提取特征。GANs 漂亮地替代了最大似然方法。此外可认为 GANs 的学习过程和缺少启发式损失函数 (像素间相互独立的均方误差) 对表示学习很有吸引力。据知 GANs 训练不稳定,往往使生成器的输出无意义。试图理解和可视化 GANs 所学和多层 GANs 的中间表示的已发表研究有限。
本文,有如下贡献
- 卷积 GANs 的拓扑结构上,提出和评估一系列约束来使大多数设置中的网络训练稳定。 命名该类结构为深度卷积 GANs。
- 为图像分类任务训练判别器,相比其它无监督算法,该判别器的效果很好。
- 可视化 GANs 学到的滤波器,经验表明特定的滤波器已学到绘制特定的物体。
- 生成器有趣的数值属性便于操作很多不同语义的生成样本。
2. 相关工作
2.1 从未标记数据学习表示
一般的计算机视觉和图像上下文中,无监督表示学习问题被研究得很好。一个无监督表示学习的经典方法是对数据聚类 (如用 K-means),并利用所得簇来提高分类分数。图像上下文中,分层聚类图像块来学习有力的图像表示。另一个流行的方法是训练自编码器 (卷积,堆叠),自编码器分离码的含义和位置,将图像编码为简洁的码,且解码来尽可能精确地恢复图像。这些方法可从图像像素学到很好的特征表示。深度置信度网络在学习分层表示中效果不错。
2.2 生成自然图像
图像生成模型的研究分为两类:参数的和非参数的。
从现有图像的数据库中,非参数模型往往匹配图像块来匹配图像,并用于合成纹理,超像素和绘画。
生成图像上参数模型的研究 (如 MNIST 数字或合成纹理) 广泛。然而,直到最近,生成真实世界中的自然图像才有进展。变分采样方法来生成图像取得一定的成功,但采样往往模糊。另一方法是用迭代的前向传播过程来生成图像。对抗的生成网络生成的图像易受噪声影响且生成图像的内容难以理解。该方法的 Laplacian 金字塔扩展版可生成更高质量的图像,但串联多个模型引入的噪声仍使生成图像中的物体看起来不稳定。最近循环网络方法和反卷积方法也在生成自然图像上取得一定的成功。然而,有监督任务上还未用这些方法的生成器。
2.3 可视化 CNNs 内部
神经网络为黑盒方法一直为人所批判,使用时不会以简单的人类处理的形式来理解网络的作用。CNNs 中,用反卷积和最大激活单元滤波可大致了解网络中每个滤波器的作用。类似地,输入用梯度下降,可观察激活了的部分滤波器的目标图像。
3. 方法与模型结构
曾有人尝试用 CNNs 缩放 GANs 来生成图像,结果失败了。这使得 LAPGAN 的作者开发一种可替换缩放的方法,通过迭代上采样低分辨率的生成图像,从而使网络模型更可靠。且我们试图用有监督学习中常用的 CNN 结构来缩放 GANs 时也遇到困难。然而,经过大量模型探索,确定有一类模型在一系列数据集上训练稳定,且可训练更高分辨率和更深的生成模型。
方法的核心是利用和修改最近 CNN 结构的 3 个可见的变化。
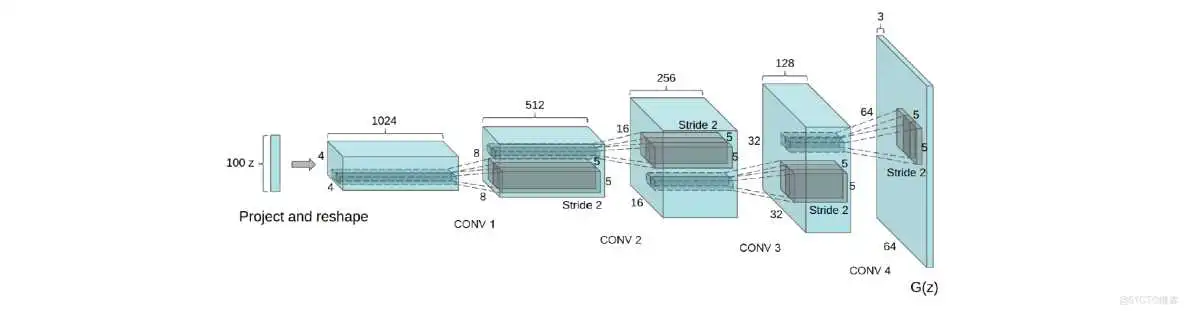
第 3 个变化为 Batch 归一化,通过归一化每个输入使其均值为0,方差为1来使学习稳定,从而有助于解决差的初始化引起的训练问题,且有助于深层模型中的梯度流动。证明使深度生成器开始学习,防止生成器从所有样本崩溃至单个点 (GANs 中常见的一种失败状况)。然而所有层直接用 batchnorm 将导致样本振荡和模型不稳定。不对生成网络的输出层和判别网络的输入层应用 batchnorm 来避免样本振荡和模型不稳定。
生成网络除了输出层用 Tanh 函数,其它层用 ReLU 激活函数。观察到有界的激活函数可使模型学习更快饱和及覆盖训练分布的颜色空间。发现判别器中的漏 (leaky) ReLU 激活函数尤其在高分辨率模型中的效果不错。与这里相反,原有的 GAN 论文用 maxout 激活函数。
稳定的深度卷积 GANs 的结构指南
- 用生成器的跨 (strided) 卷积和判别器的部分跨 (fractional strided) 卷积来替换所有的池化层;
- 判别器和生成器中都用 batchnorm;
- 删除深度结构中的全连接隐含层;
- 生成器中除了输出层用 Tanh,所有其它层用 ReLU 激活函数;
- 判别器中所有层用漏 ReLU 激活函数。
4. 对抗训练的细节
3 个数据集 (Large-scale Scene Understanding (LSUN),Imagenet-1k 和新组合的 Faces) 上训练 DCGANs。每个数据集的使用细节如下。
训练图像仅缩放至 Tanh 函数的范围[−1,1],无预处理。用 mini-batch 大小为 128 的随机梯度下降来训练所有的模型。均值为0,标准差为0.02的正态分布来初始化所有权重。漏 ReLU 中,所有模型中漏 (leak) 的斜率设为0.2。以前的 GAN 网络用动量加快训练,这里用 Adam 优化器。建议学习率为0.001,如果太高则改用0.0002。当动量项β1为建议值0.9时会导致训练振荡,而降为0.5有助于稳定训练。
4.1 LSUN
随着图像生成模型生成的样本质量的提高,会出现过拟合与训练样本的记忆。为演示更多数据和更高分辨率生成时模型如何缩放,用包含超过三百万训练图像的 LSUN 卧室数据集来训练模型。最近的分析显示模型学习的速度与模型泛化性能间有直接的关系。模仿在线学习,下图显示每个训练时期的样本和收敛后的样本来证明模型并未通过简单地过拟合或记忆训练实例来生成高质量样本。

1 个训练周期后生成的卧室。理论上,模型可记忆训练样本,但当用小学习率和 minibatch SGD 训练时却不是这样。据我们了解,无任何实验表明 SGD 和小学习率的训练有记忆。

5 个训练周期后生成的卧室。多个样本间的噪声纹理重复表明视觉上欠拟合。
4.1.1 删除重复数据
删除简单的图像重复数据来进一步减少生成器记忆输入实例的可能。训练实例经过32∗32中心裁剪后,用其拟合一个 3072−128−3072
4.2 FACES
随机查询人名的网络图像,抓取人脸图像。从 dbpedia 获取人名。数据集来自10K人的3M张图像。运行 OpenCV 检测人脸,检测到的人脸仍有足够高的分辨率,共约350K个人脸边界框。训练时用人脸边界框,无数据增广。
4.3 IMAGENET-1K
Imagenet-1K为无监督学习的自然图像来源,按图像较小边长缩放,且中心裁剪大小为32∗32的图像用于训练,无数据增广。
5. DCGANs 性能的实验验证
5.1 GANs 提取特征来分类 CIFAR-10
串联的向量大小为(1024+512+256)∗(4∗4)=28672。
与基于 K-means 的技术相比,判别器的特征图少得多 (最顶层有512个特征图) ,但多层4∗4的空间位置使整个特征向量大小更大。DCGANs 的表现不如典型 CNNs (无监督方式训练常规 CNNs 来区分具体选择,增广和来自源数据集的示例样本)。微调判别器的表示可进一步改善表现。此外,DCGANs 使用 Imagenet-1k (而非 CIFAR-10) 训练,表明学到的特征的区域鲁棒性。

根据上面的描述,典型 CNNs 的向量维度应该是1024; 虽 DCGAN 的判别网络顶层特征图数目为512个,但送入 SVM 的却是展平的28672 维向量,如果4∗4的网格为单个特征图,那么特征单元的数目应为1792个。Table 2 第2列大多数为判别特征送入分类器的最大数目。但是,比较浅层,仅用到的深层顶层和联合多层时的深层顶层的数目,Table 2 似乎对前两者不太公平呢~
5.2 GANs 提取特征来分类 SVHN 数字
为数据标签稀少时的有监督学习,街景门牌号数据集 (SVHN) 上用 DCGAN 判别器的特征。类似 CIFAR-10 实验中准备数据的规则,从源数据集分离出 10K 张验证示例,并用其选择所有的超参数和模型。随机选择 1000 类均匀分布的训练样本,与 CIFAR-10 相同的流程提取训练样本的特征,用这些特征来训练 L2 正则的线性 SVM 分类器。此时验证误差达到22.48%。另外,相同数据上用相同的结构来完全有监督地训练 CNN,随机搜索 64 个超参数优化模型后的验证误差为28.87%。所以,模型结构和超参数并不是验证误差被降低的关键因素。

1000
虽 CIFAR-10 数据集上没赢过相同结构的有监督 CNN,但 SVHN 数据集上超过6.37%。但个人觉得有监督 CNNs 实验为何要用相同的数据呢?数据增广的有监督 CNNs 的实验结果并未给出。总的来说,与有监督学习相比,该方法有竞争力。
6. 网络内的研究与可视化
研究用不同的方式训练生成器和判别器。训练集上不使用最近邻搜索。小的图像变换一般会欺骗像素的最近邻域或特征空间。对数似然是个差的指标,所以不用它来定量评价模型。
6.1 潜在 (latent) 空间中游走
第 1 个实验为理解潜在空间的流形。游走在学好的流形上可了解记忆的指示 (如有急剧的过渡) 和空间分层折叠的方式。如果潜在空间中游走导致生成图像的语义变化 (增加或删除的物体) ,则模型学到与物体相关的有趣表示,如下图。

Z中用一系列的9个随机点插值,使学到的空间平滑。最后一行,可看到电视逐渐转换成窗户。
6.2 可视化判别特征

右侧为判别器最后一个卷积层的前6个学到的卷积特征,可视化引导反向传播中最大轴对齐响应 (axis-aligned responses)。注意到很少的特征反应为床— LSUN 卧室数据集的中间物体。左侧为随机滤波器的基线,与前面的响应相比,无判别性和随机结构。
6.3 操作生成表示
6.3.1 遗忘绘制特定物体

上一行:未删除窗户的生成样本。下一行:经过删除窗户滤波的生成样本。一些窗户被移除,一些窗户被替换为视觉表面相似的物体 (如门和镜子)。尽管图像质量下降,场景的整体组成依然相似,表明生成器可很好地从物体表示来抽出场景表示。也可从图像中删除其它物体,并修改生成器绘制的物体。
6.3.2 向量操作人脸样本
评价学到的词表示时,表明简单的算术运算可在词表示空间中显示丰富的线性结构。典型的例子有向量("王")−向量("人")+向量("女人")为一个与向量("女王")最近邻的向量。研究生成器的Z表示中是否出现类似的结构。每个概念仅用单个样本的实验不稳定,但3个实例上平均Z向量,表明遵从该语义运算生成的图像一致且稳定。

视觉概念的向量运算。每列平均3个样本的Z向量,算术运算得到的向量输出一个新向量Y。右侧中间的样本为Y,送入生成器。为表明生成器的插值效果,添加±0.25的采样均匀的噪声来生成其它8个样本。下面两行:输入空间中2个样本间的算术运算因误配准引起噪声重叠。
此外,物体的运算证明脸部姿态在Z空间中呈线性。
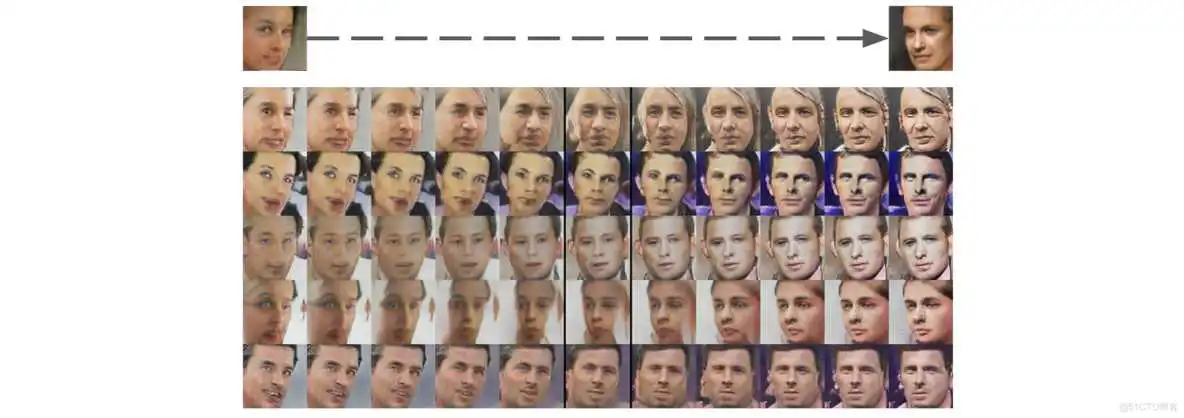
从4张左看 vs 右看的平均脸样本中获得“转向”向量。沿转向轴插值随机样本,可变换脸的姿态。
7. 总结与未来工作
小结
到此这篇cnn无监督分类(无监督nlp)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/rgzn-zryycl/62040.html