
前提:1虚拟机工作环境 2镜像文件准备好 3基础网络配置
安装虚拟机: 1创建虚拟机--挂载镜像 2开机【直接进入bios的开机方式】 3鼠标选择配置
4重启主机看效果
步骤:将前提准备好打开虚拟机【点击创建新的虚拟机】1选择典型安装或者自定义都可以
2点击安装程序光盘映像文件
3下一步选择Linux客户机操作系统“版本选择不重要选哪个都可以”
4命名虚拟机及选择安装位置
5磁盘空间200G的单个文件 完成开机!!!!
进入系统之后会有选择按照自己的需要配置。
加*是重点命令需要熟练使用
2.1.1设置root密码
Ubuntu系统可能没有root超级用户面对这样的情况就得创建root用户并设置root用户密码
sudo passwd root设置root用户密码
[sudo] password for ubuntu:这里输入当前普通用户密码
New password:这里输入想要设置的root用户密码
Retype new password:再次确认密码
2.1.2 linux登陆方式
linux是一个多任务,多用户的开源客户端可以用命令行登录和图像化登录,也可以用虚拟终端登录
在linux里面有两类用户一个是超级用户,一个是普通用户。管理员用户是有权限的普通用户
管理员角色是一个用户组 超级用户root 普通用户是自己装机时创建的用户
0-999是特殊用户
查看当前主机的ip地址
ip a
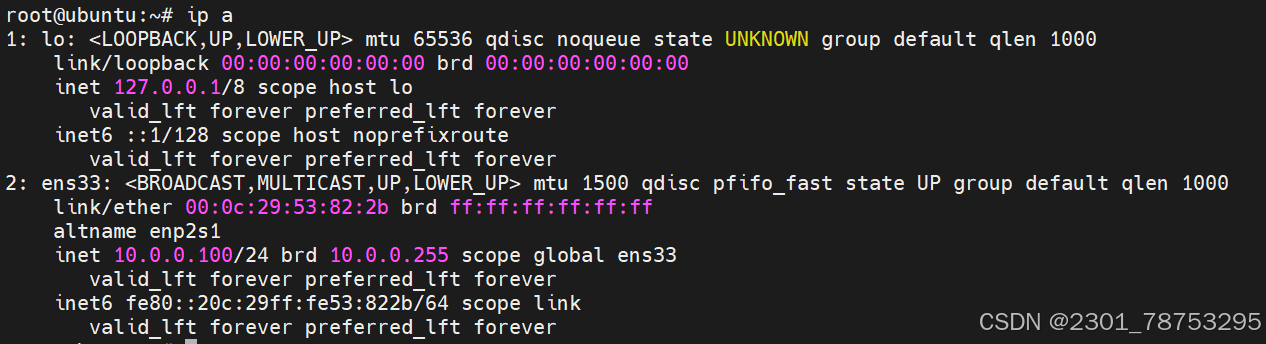
2.1.3 whoami 查看当前系统用户是谁
whoami 查看当前用户是谁
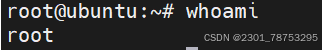
2.1.4 su 切换用户
su 切换用户
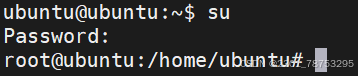
参数:
- 不带上一个用户的记忆切换
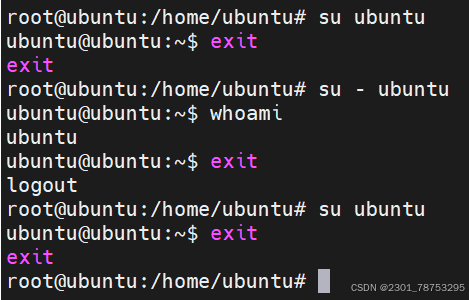
2.1.5 exit 退出
exit 退出

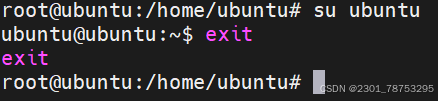
2.1.6 tty 查看当前所在终端
tty 查看当前所在进程

2.1.7 shell 命令解释器
我理解为翻译官将我们打的命令解释给操作系统 shell存在两种操作方式命令行和脚本文件。
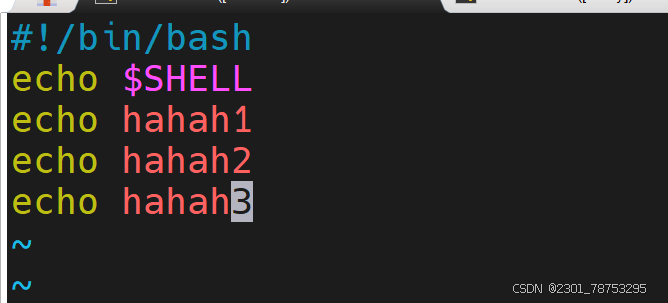
脚本命令中第一行是命令解释器#!/bin/bash 其他的是可以成功执行的命令
root@ubuntu:~# vim a.sh 编辑一个a.sh的文件
root@ubuntu:~# cat a.sh 查看a.sh
#!/bin/bash
echo $SHELL
echo hahah1
echo hahah2
echo hahah3
root@ubuntu:~# /bin/bash a.sh 用/bin/bash命令解释器运行a.sh文件
/bin/bash
hahah1
hahah2
hahah3
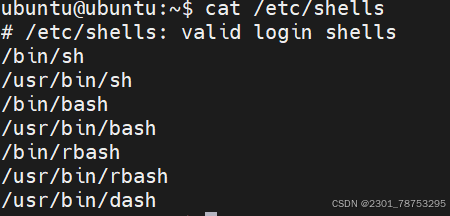
echo $SHELL 查看当前系统的shell类型

cat /etc/shells 查看当前系统的shell类型
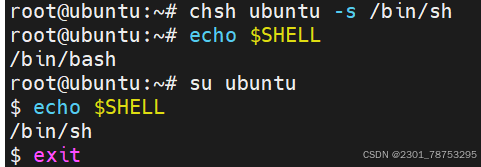
更改系统默认shell
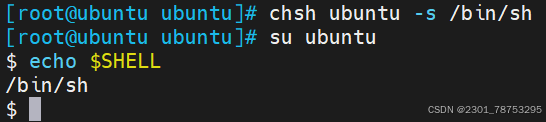
root@ubuntu:~# chsh ubuntu -s /bin/sh 修改Ubuntu默认dashe为sh
root@ubuntu:~# echo $SHELL 查看当前shell类型
/bin/bash
root@ubuntu:~# su ubuntu 切换到Ubuntu用户
$ echo $SHELL 查看当前shell类型
/bin/sh
$ exit 退出
2.1.8 echo 输出
echo 输出
选项
-n 不要在最后自动换行
-e 要是字符出现选项字符,则特别加以处理,而不会将他当成一般文字输出
换行且光标移至行首

echo $变量名获取变量名
![]()
2.1.9 chsh 允许用户更改其登录shell
shell 有很多种
bash
tcsh
sh
csh
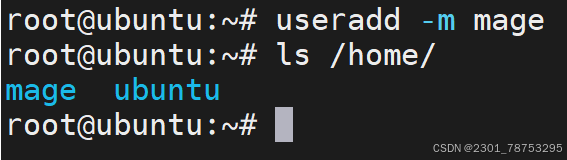
2.2.1 useradd创建用户
useradd 创建用户
选项
-m
2.2.2 PS1 修改默认变量
PS1 修改默认变量
选项
h 显示简写的主机名,如默认主机名localhost
示当前用户
W 显示当前所在的目录的最后一个目录

2.2.3 ls 显示当前目录下的文件
ls 查看当前目录下的文件
选项
-a 将所有隐藏文件显示出来

2.2.4 命令查看帮助
---help 查看命令选项
help 查看内部命令
whereis 查看命令是否在,若在显示命令存放位置
which 查看命令是否存在,若存在显示第一个显示的位置
man 查看命令帮助
2.2.5关机与重启的选项
关机:halt poweroff shutdown -hnow
重启:reboot shutdown - r
2.2.6 ubuntu让root用户远程登陆
1.给root设密码 sudo passwd root
2切换到root用户 su - root或者sudo -i
3安装ssh服务 apt install openssh-server
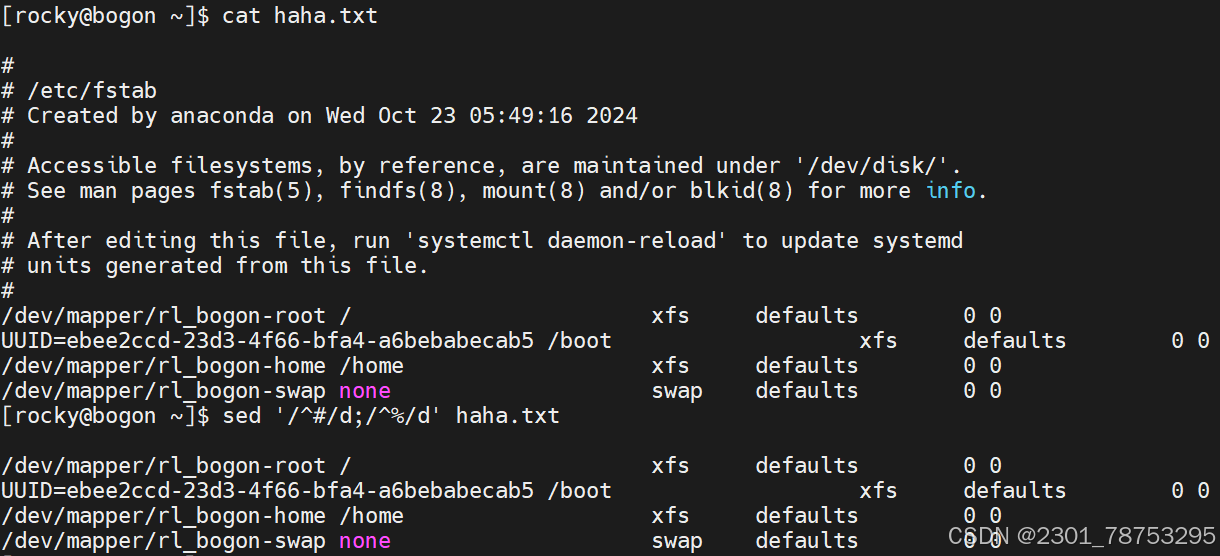
4允许root登录 grep /etc/ssh/sshd_config vim编辑 /etc/ssh/sshd_config 下方图片中#开头这段话改为yes
5重启服务 systemctl restart ssh
![]()
2.2.7软件的安装
安装用install
移除用remove
yum install适用于rocky 以及国产系统
yum 将会被dnf 取代操作方式是一样的
apt install适用于Ubuntu系统中
2.2.8查看用户各种信息
whoami 查看当前登录用户
id 显示用户的身份标识信息
pwd 在哪里 *
who 显示当前登录系统的用户 * 红色常用
w 查看当前用户的启动程序信息
last 显示上次登陆的用户列表信息
2.2.9查看系统信息
cpu 命令lscpu 文件/proc/cpuinfo
mem 命令free 文件/proc/meminfo *
磁盘分区 命令lsblk df 文件/proc/partitions *
磁盘设备 命令blkid
系统架构 命令arch
内核信息 命令uname -r
操作系统发行版本 文件 文件/etc/os-release[rocky操作系统]
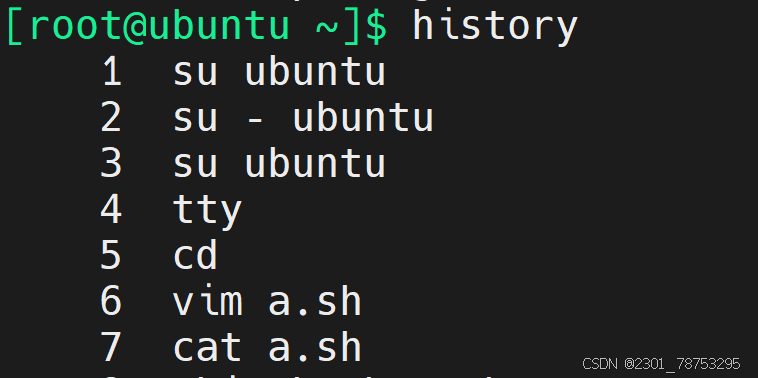
2.3.1 history历史命令
history用过的命令
选项
! 加命令编号快速执行命令
CTRL+R 输入命令前几个字母和TAB键差不多
-c 清除历史命令
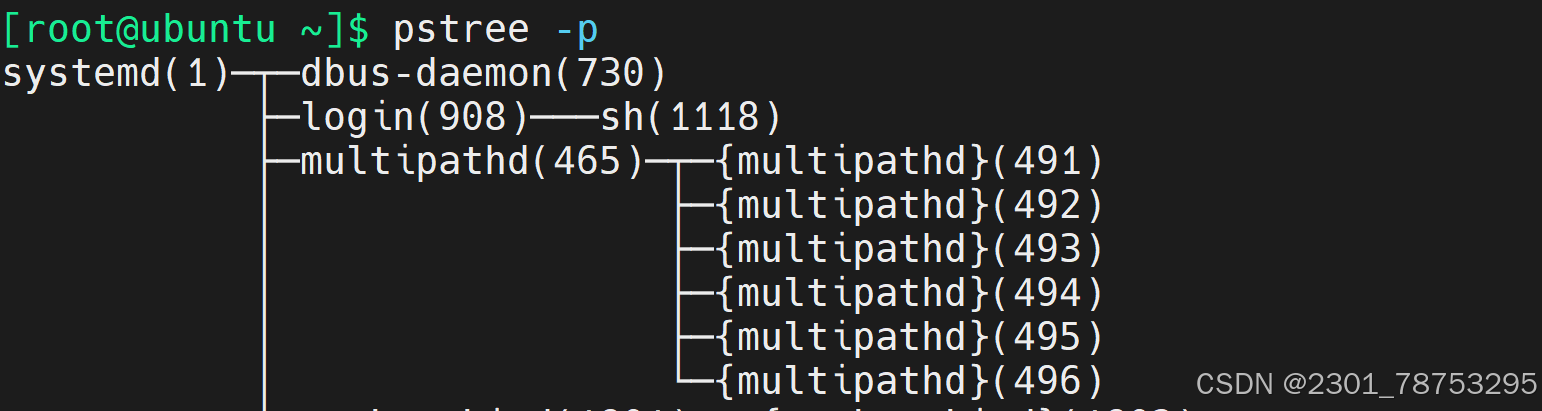
2.3.2 pstree 会话管理
pstree 查看当前系统里的所有进程 参数 -p
screen / tmux 会话解绑
screen -s创建一个独立的会话后面加会话名
screen -ls查看创建的会话
screen -X加丢失的会话名字找回会话
2.3.3 printf 格式
家目录 /root/home/
配置目录 /etc
命令目录 /bin /sbin
临时目录/tmp
根 /
当前目录 .
上一级目录 https://blog.csdn.net/2301_/article/
家目录 ~
各目录相关的文件

系统相关的目录
/boot 存放着启动Linux时使用的一些核心文件
/etc 存放所有的系统管理所需的配置文件和子目录
/lib 存放着系统最基本的动态连接共享库
/sys 存放着2.6内核3种文件信息
命令相关的目录
/bin 存放着常用命令
/sbin 存放着系统管理员使用的系统管理程序
/usr/bin 存放着系统用户使用的应用程序
/usr/sbin 存放着超级用户使用的比较高级的管理程序和系统守护程序
程序相关的目录
/proc 存放着 当前内核运行的一些文件
/srv 存放着服务启动之后需要提取的数据
/usr/src 存放着用户的很多应用程序和文件
/avr 存放着不断扩充着的东西
/run 存放着喜用启动以来的信息
/usr/share 存放着应用程序的帮助所在文件
其他相关的目录
/lost+found 一般是空的系统非法关机后存放着一些文件
/opt 是给主机额外安装软件所摆放的额目录
/selinux 安全机制目录
/tmp 存放临时文件
/run 运动目录
/var 变动文件目录

文件的操作和信息获取
查看文件
ls 目标目录位置
ls -a 查看隐藏文件
ls -l 显示额外信息
ls -R 查看所有目录文件信息
ls -ld 目录和符号链接信息
tree 目标目录位置 查看大目录 -L
创建目录
mkdir 目标位置 选项 -p 递归创建目录
创建文件
touch 文件名
切换目录
cd 目标目录位置
. 当前目录
.. 上级目录
- 回到之前目录月光宝盒
查看当前所在路径
pwd 查看当前所在位置
-p 显示当前工作目录的物理路径解析所有符号链接到他们的指向位置
-L 显示当前工作目录的逻辑路径,包含符号链接的路径
3.1.1 文本编辑工具vi/vim
vim与vi是相同的只不过vim有颜色
3.1.2 不同系统之间文件转换
dos2unix文件转换
3.1.3 正则符号
* 匹配任意字符不包括 “.” 开头的文件
{a..z} 表示a到z所有字符
[a-z] 表示a到z范围里的一个字符
[^a-b] 表示a到b以外的字符
? 隐藏文件匹配任意一个字符一个汉字也算一个字符
~ 表示当前家目录
.* 表示所有字符
[ ] 筛选范围中的一个字符
{ } 范围中的所有字符
() 临时的shell空间
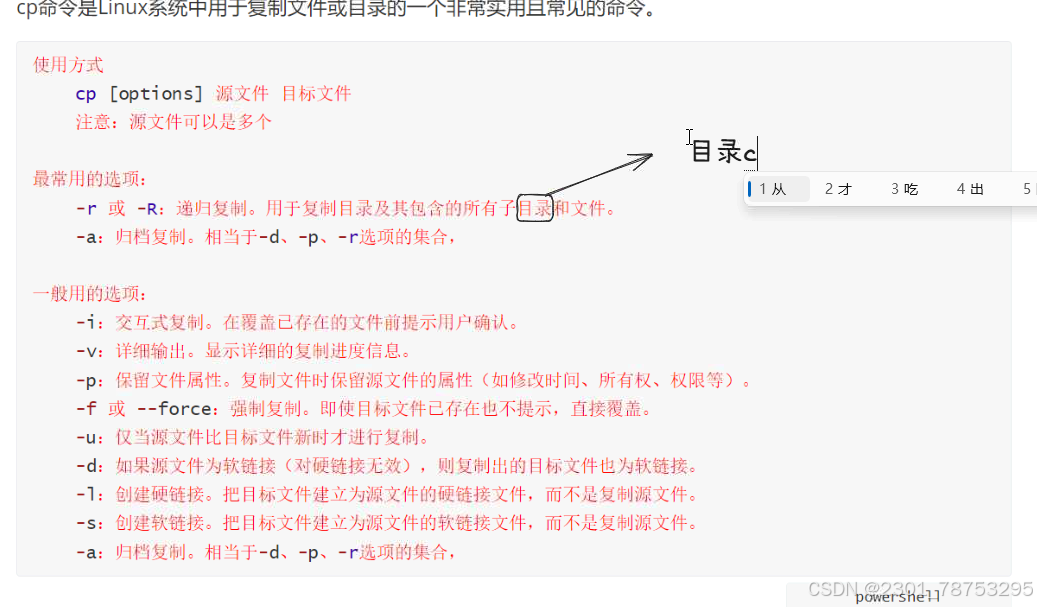
3.1.4 cp拷贝
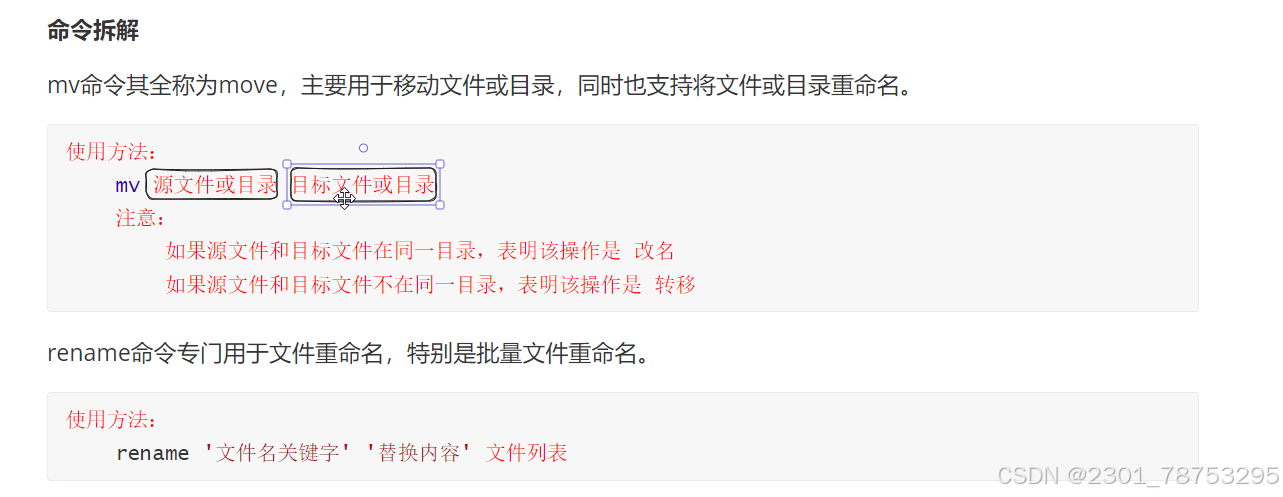
3.1.5 转移和改名
3.1.6 rename 改名
rename 文件改名
rocky系列改名方式如下

Ubuntu改名方式如下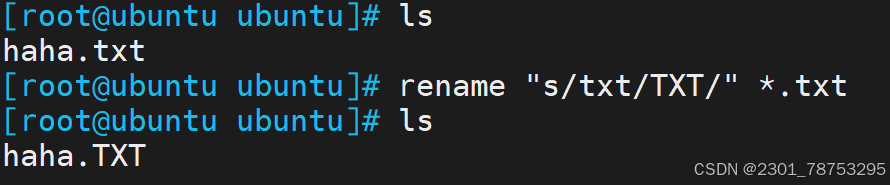
3.1.7 ln 硬链接和软连接
ln 创建硬链接 硬链接所有信息相同inode号也一样,删除源文件inode号不胡会消失
ln -s 创建软链接 软链接只是目标文件指向源文件所有信息和inode号都不同,删除源文件对目标文件没有什么影响
readlink 链接文件

硬链接方式inode号一样其他内容也一样,不支持目录硬链接 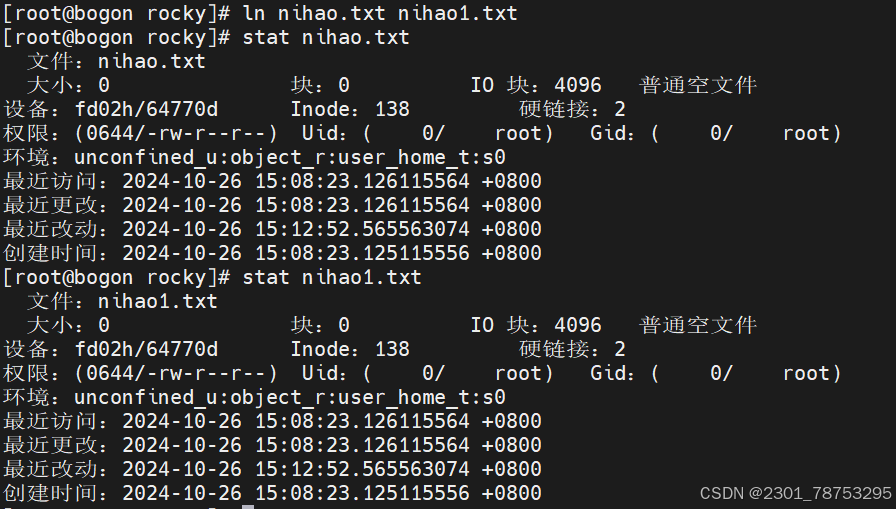
软链接与硬链接不同inode号不相同查看nihao2时其实查看的是nihao1的内容
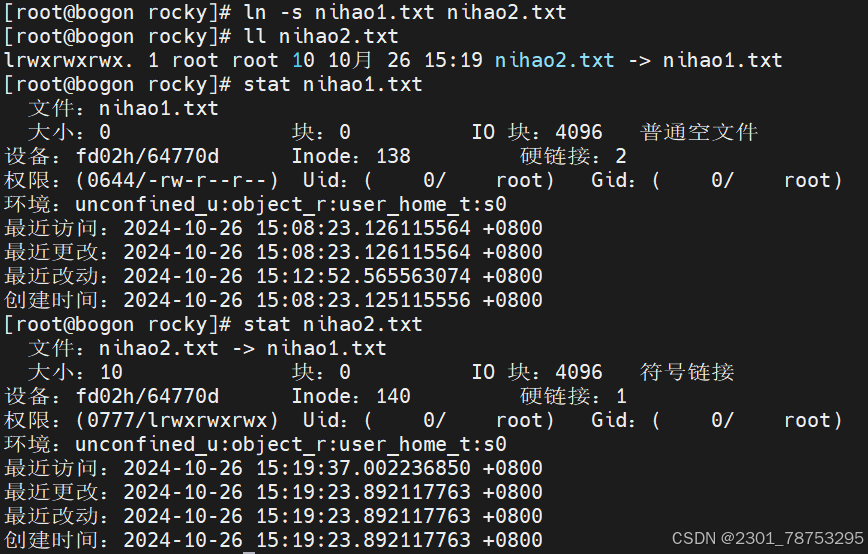
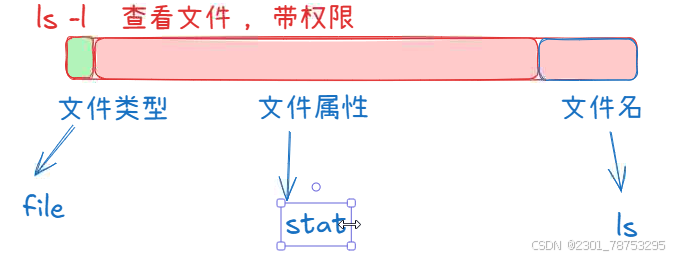
3.1.8 stat 查看文件状态
stat 查看文件状态
获取文件访问时间
修改文件时间
最后一次更改文件时间
inode号等各种信息
3.1.9 file 查看文件类型
file 和 ll 命令效果一样
3.2.1 rm 删除文件
rm -f 删除普通文件
rm -rf 删除目录及所有文件
3.2.2 vim / vi编辑工具
vim / vi 写文件
i 按i键开始编辑
ese 键退出编辑模式
:加 w 保存
:加 q 不保存退出
:加 wq 保存退出
!强制执行
!可以与q / w / qw 任意组合使用
3.2.3 管道符
> 表示将左面的内容以覆盖的方式输出给右面
< 表示将右面的内容以覆盖的方式输出给右面
>> 表示将左面的内容以追加的方式输出给右面
<< 表示将右面的内容以追加的方式输出给右面
| 表示将左面输出的结果传递给右面使用
| grep 过滤信息
3.2.4将成功命令与不成功命令分别装到不同的文件夹
1> 文件名
2> 文件名
1 代表成功命令
2 代表错误命令
2&>1 代表所有输出信息
3.2.5 特殊文件
特殊文件 /dev/null 垃圾桶无限容量
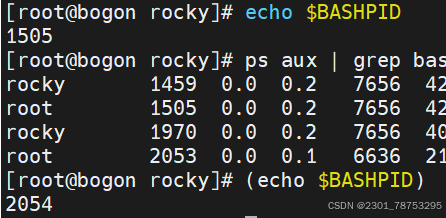
3.2.6 临时shell
临时shell
(命令列表)在shell里执行命令列表,退出shell后,不影响后续环境操作
临时shell环境---不启动子shell
{命令列表} 在shell里执行命令列表,会影响当前shell的后续环境操作
()使用场景,临时划分一个独立的shell环境,安全相关的命令处理,比如加密解密场景

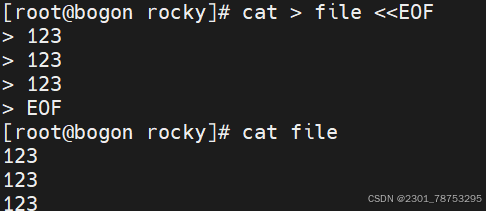
3.2.7 EOF重定向
eof 大写小写都一样只要统一就好
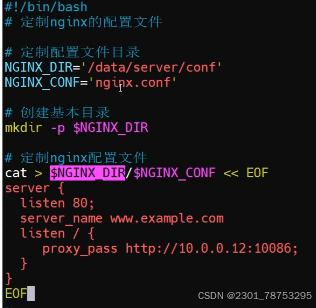
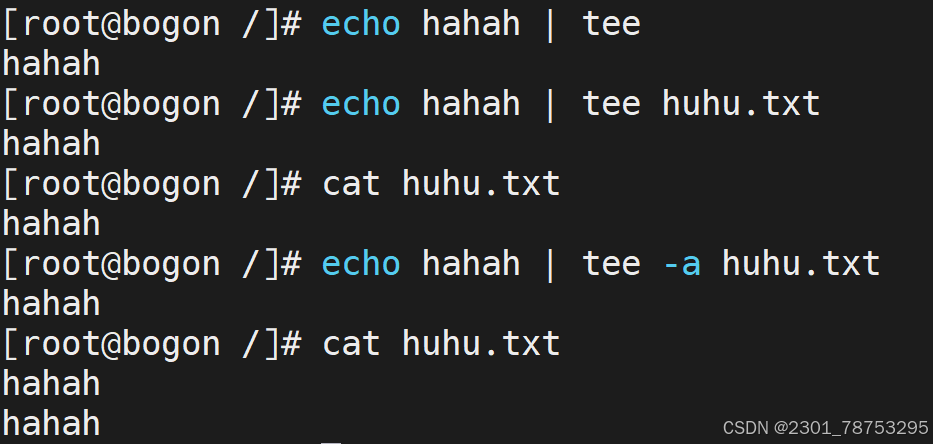
3.2.8 tee 重定向
tee 选项 -a
tee "文件" <<-eof 和 cat "文件" <<-eof 效果一样
tee 命令读取标准输入,把这些内容同时输出到标准输出和(多个)文件中,tee命令可以重定向标准输 出到多个文件。要注意的是:在使用管道线时,前一个命令的标准错误输出不会被tee读取

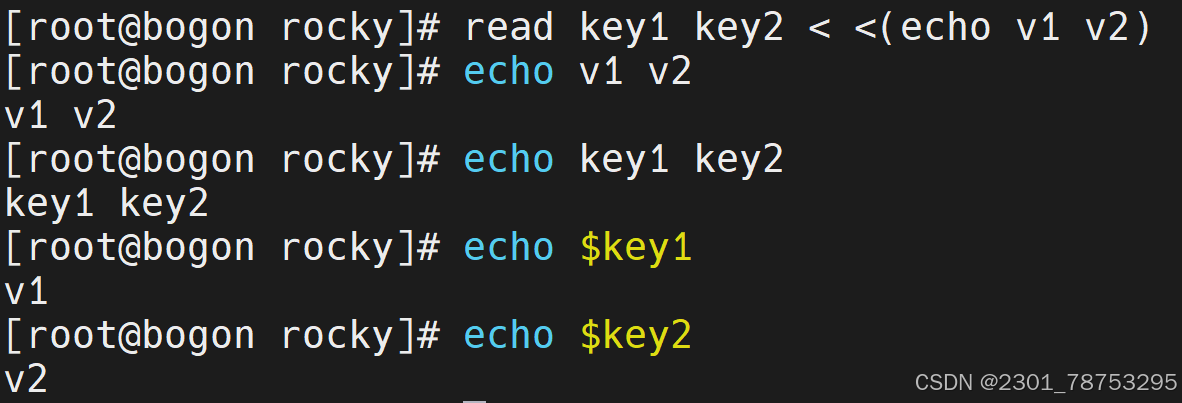
3.2.9 read
read -p "提示信息" 变量名
加 -t 指定时间 指定时间内不输入自动结束
拆解两个变量 read



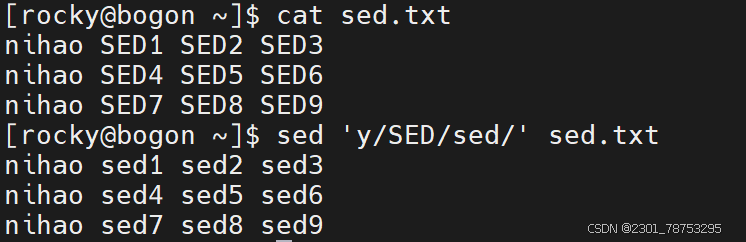
3.3.1 tr 替换
tr 用于替换字符


3.3.2 alias定义别名
alias 定义别名
unalias 取消别名
3.3.3 软件的安装
dnf makecache 更新软件源
dnf search nginx 搜索软件
dnf remove -y nginx 删除软件
dnf install -y nginx 安装软件
3.3.4查看文件系统磁盘使用情况
df -h 查看存储空间
df -i 查看inode号使用情况
4.1.1配置文件
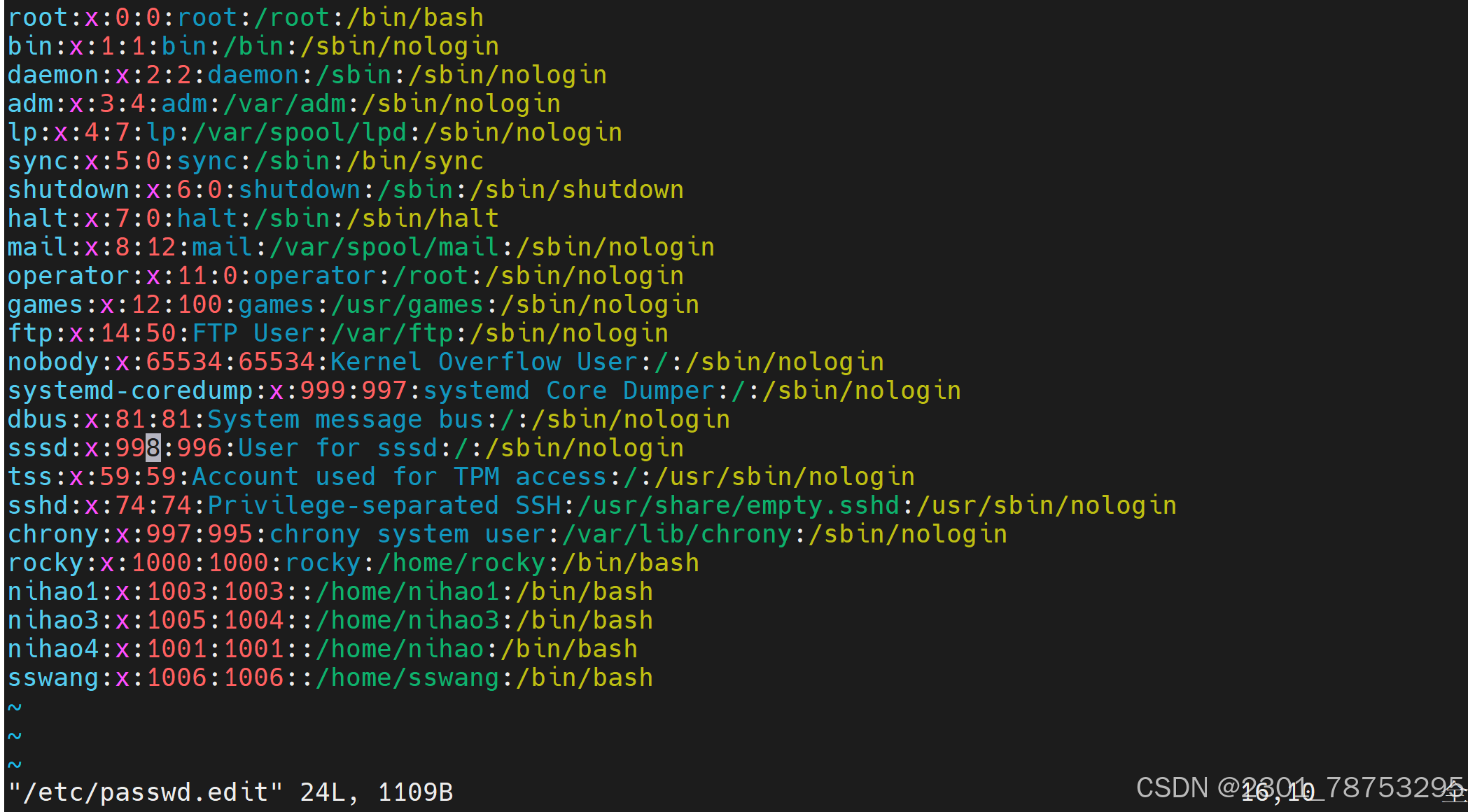
/etc/passwd:用户及其属性信息(名称、UID、主组ID等)
sswang:x:1000:1000:sswang:/home/sswang:/bin/bash
用户名:密码:UID:GID:描述信息:宿主目录:命令解释器
/etc/shadow:用户密码及其相关属性
root:$6$VftC9gu7HNAEIc79$VdxTdcGlQFjiP.RdyZG6js7fHnzj3WDIDb3v6JGqyD1zhh6Rw/J1ik7 M06UFNhZ9ihxjIiKpBwz2UEYc8pOsa.::0:99999:7:::
用户名:密码:最后修改时间:最小时间间隔:最大时间间隔:警告时间:账号闲置时间:失效时间:标志
/etc/group:组及其属性xiang
root:x:0:
组名:组密码:GID:组内用户列表
/etc/gshadow:组密码及其相关属性
root:::
组名:组密码:管理员:组内用户列表
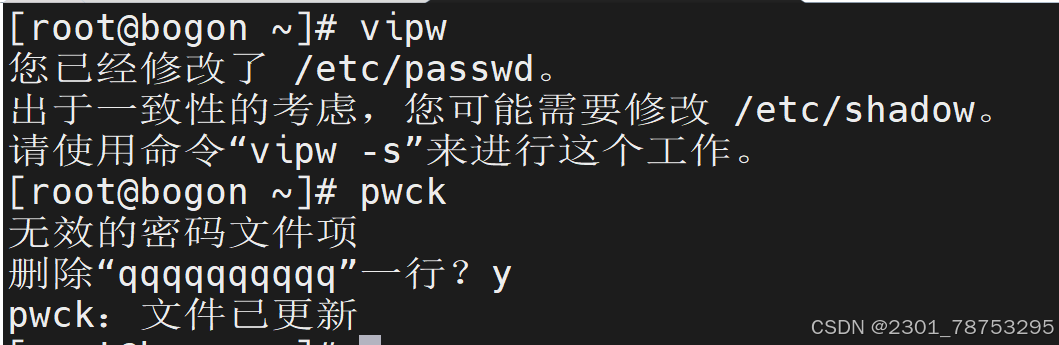
4.1.2 vipw|vigr及pwck
命令用于编辑/etc/passwd,/etc/group,/etc/shadow,/etc/gshadow
vipw 默认编辑 /etc/passwd 文件
vigr 默认编辑 /etc/group 文件
常见选项:
-g |--group #编辑 group 文件
-p |--passwd #编辑 passwd 文件
-s |--shadow #编辑 /etc/shadow 或 /etc/gshadow 文件
pwck
对用户相关配置文件进行检查,默认检查文件为 /etc/passwd 自动找到错误内容并询问是否修改
选项
- q 只报告错误,忽略警告
- r 显示错误和警告,但不改变文件
- R chroot 到的目录
- s 通过 UID 排序项目
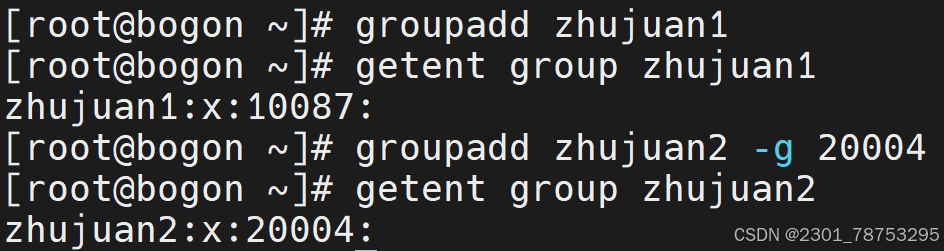
4.1.3 groupadd命令可以创建用户组
命令格式 groupadd 加要创建的组名
getent group 加组名 查看用户组
选项
- g 指定id建组
- r 指创建系统用户组
- f 已有组强制创建用户组


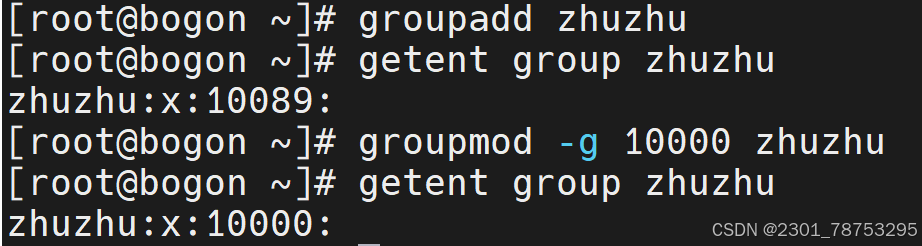
4.1.4 groupmod命令用于修改group属性
groaddmod 选项 要改的组号 要改的组
选项
- g 修改组号
- n 修改组名

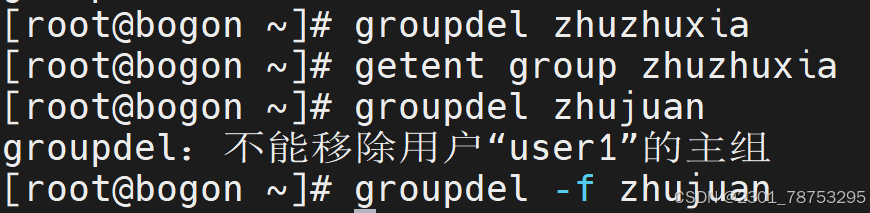
4.1.5 groupdel命令可以删除用户组
选项
- f 强制删除
4.1.6 id用于查看用户的基本信息
选项
- d 查看默认的配置属性 useradd -D
- u 指定UID id uid
- g 指定用户组 id gid
4.1.7 useradd 命令可以创建新的Linux用户
useradd 加想创建的用户
选项
- m 创建用户默认会添加一个组
- g 指定组号创建用户


4.1.8 getent shadow查看用户密码信息
getent shadow 加想查看的用户名
第一部分: 指定加密算法 $6
第二部分: 指定二次校验选项 - salt 盐值 $cKdUJegv4ahdu0CD
第三部分:通过 加密算法(salt值 + 密码) 加密后的一段字符串

4.1.9 crypt 主要用于加密和解密文件或密码
whatis crypt 查看生成密码的算法解读
man 5 crypt man手册查看
根据密码提示,生成对应的passwd密码:
openssl passwd -salt 相同的盐值 加密算法编号 密码

 4.2.1 passwd修改密码
4.2.1 passwd修改密码
命令使用
passwd 用户名
在root用户下修改可以忽略无效的密码: 密码少于 8 个字符

4.2.2 chpasswd 更改用户命令
使用方法 chpasswd < 写一个文件
文件格式:用户名:密码
u1:
4.2.3 usermod命令用于进行用户属性的修改动作
使用方法:
usermod 选项 想改的名字 要改的名
修改shell usermod -s 要改的shell -d /home/要改的家目录名字 原来的名字
选项
- l 更改用户名字
- s 更改用户登录shell以及用户家目录
- L 禁用用户
- U 解禁用户


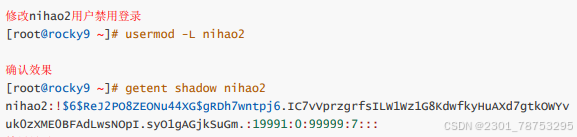

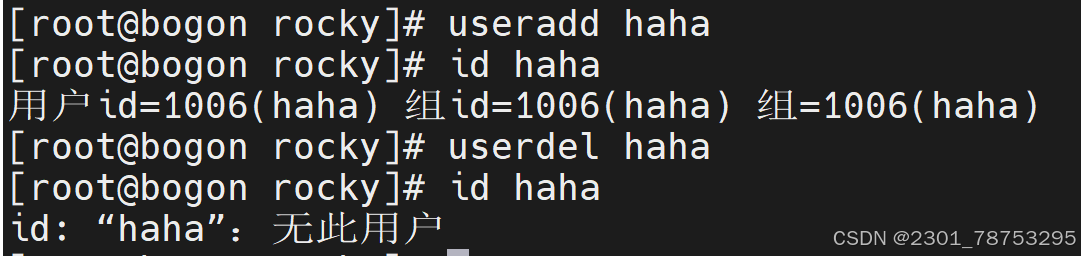
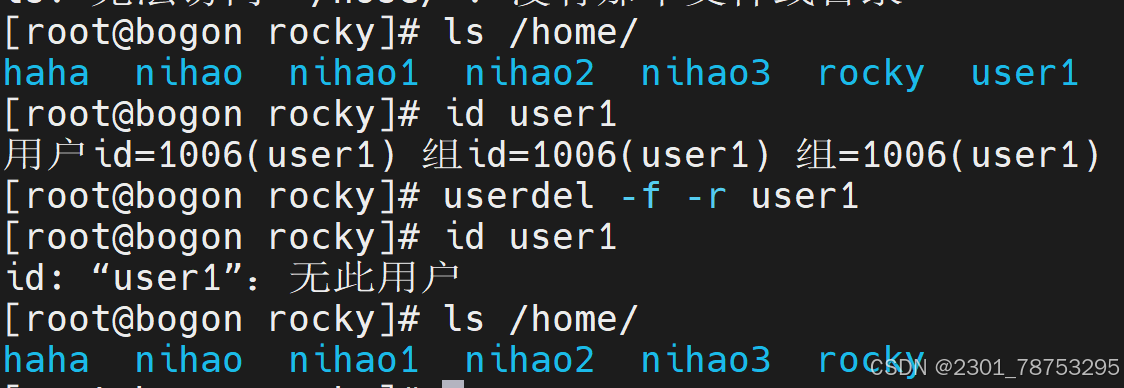
4.2.4 userdel 对用户删除
命令格式 userdel 选项 目标
- f 强制删除
-r

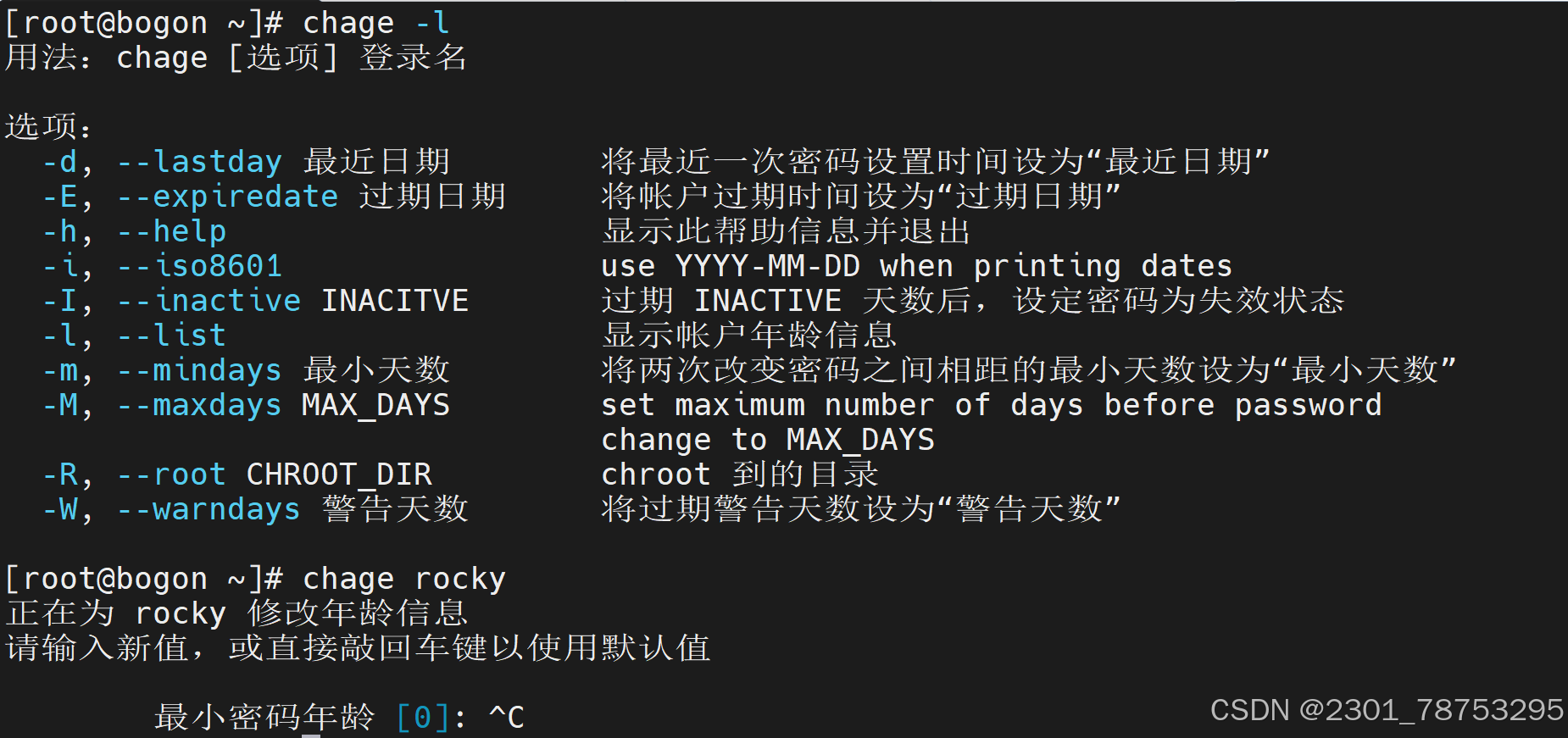
4.2.5 chage修改 密码策略
使用方法 chage 选项 目标
选项
- l 查看当前密码策略
4.2.6 gpasswd 更改组成员密码
使用方法 gpasswd 选项 用户
选项
- a 将用户添加到一个指定的组里面
- d 将用户从组中删除
默认 : gpasswd 加组名 修改组密码
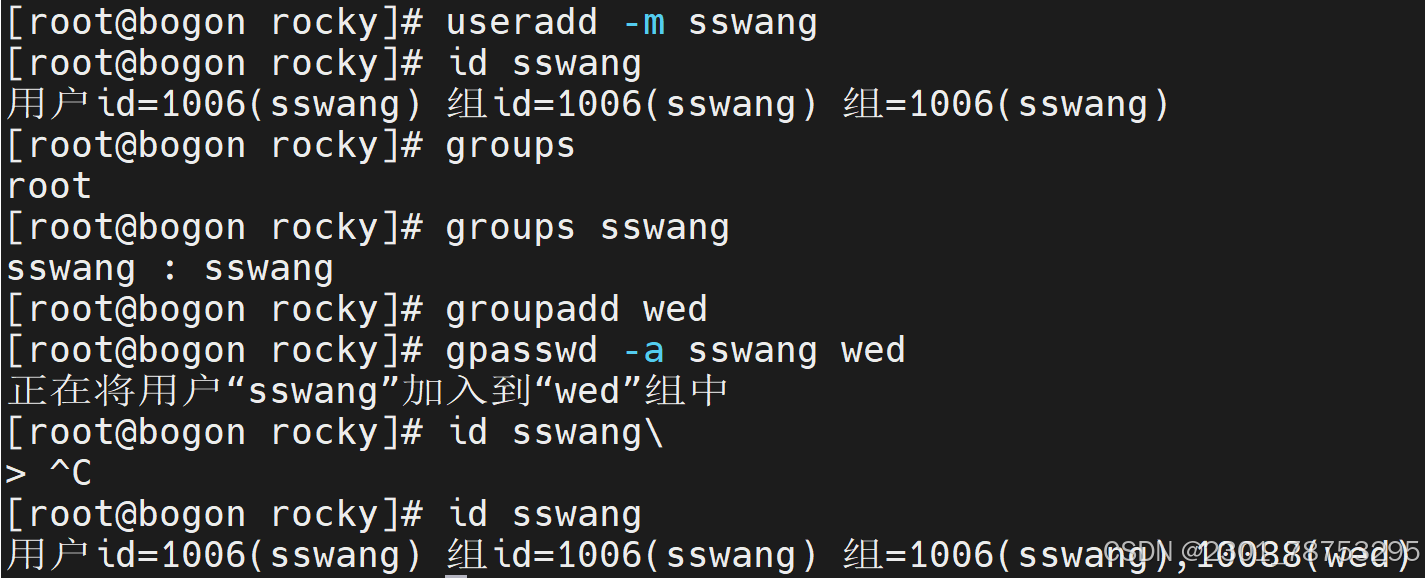


groups查看属主属组
使用方法 groupps 加用户名

4.2.7 groupmems 管理附加组成员信息
使用方法 groupmems 动作 组 选项
- g 指定组
- l 查看组成员列表
- d 从组中删除指定用户
- a 将用户添加到组内
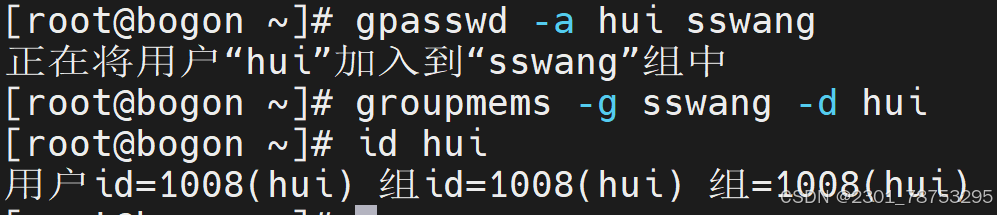
4.2.8 groups 查看用户组关系
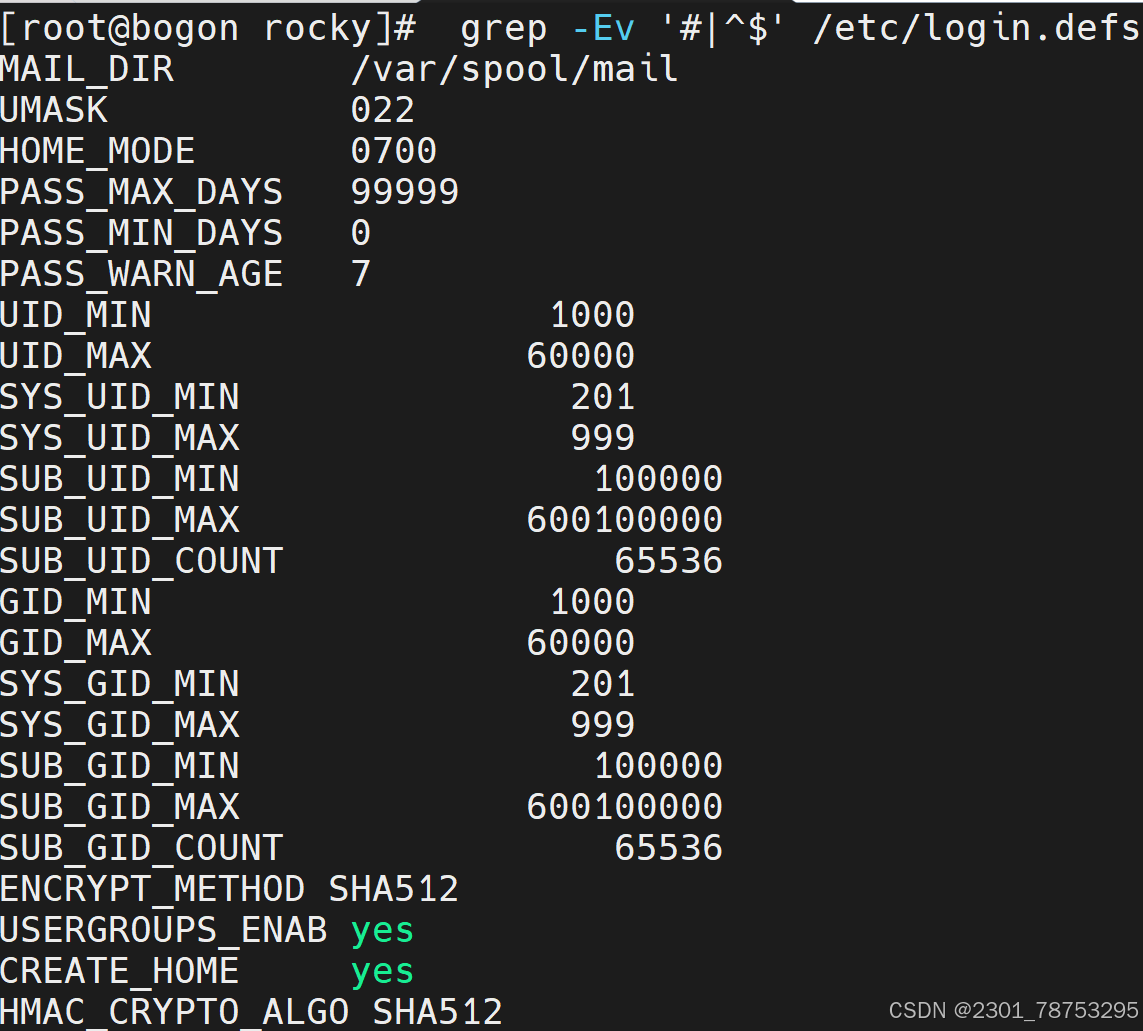
4.2.9 用户登录配置文件/etc/login.defs
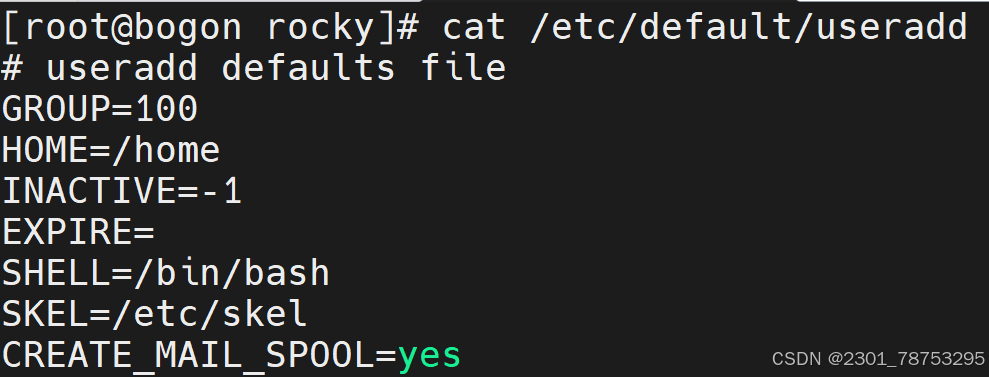
4.3.1 查看创建用户的配置文件 /etc/default/useradd
4.3.2 定制用户基本配置属性
定制用户基本配置属性
[root@rocky9 ~]# ls /etc/skel/
注意: 该目录保存了创建新用户后需要拷贝到 /home 目录下所需的相关文件。
4.3.3 定制用户登录的显示页面
用于设置用户登录系统后显示给用户的提示信息,该文件默认为空。
[root@rocky9 ~]# cat /etc/motd
文件权限解读
rwx rwx rwx 对应数字 421 421 421 - 为 0
第一组rwx对应属主u 第二组rwx对应属组g 第三组rwx对应其他人o
r 读 w 写 x 执行
默认创建的文件权限是 644,也就是说,谁都可以读去文件内容 默认不是可执行文件
默认创建的目录权限是 755,也就是说,谁都可以进入目录查看 默认没有写权限
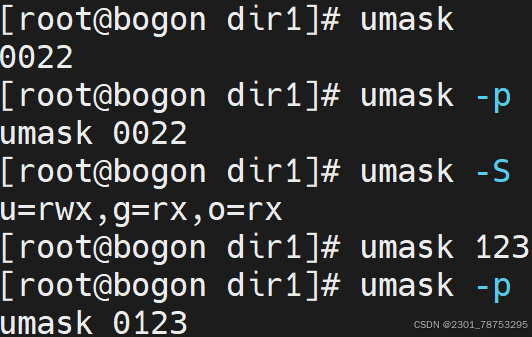
如果修改umask掩码 还是会按照默认状态创建如umask换成123那么
文件权限应该是 6 2 4
目录权限应该是7 5 5
操作示例:
u+r # 属主加读权限
g-x # 属组去掉执行权限
ug=rx # 属主属组权限改为读和执行
o= # other用户无任何权限
a=rwx # 所有用户都有读写执行权限
u+r,g-x # 同时指定
4.3.4 chown 修改文件属主属组
使用方法 chown 要变成的用户或id号 文件名
选项
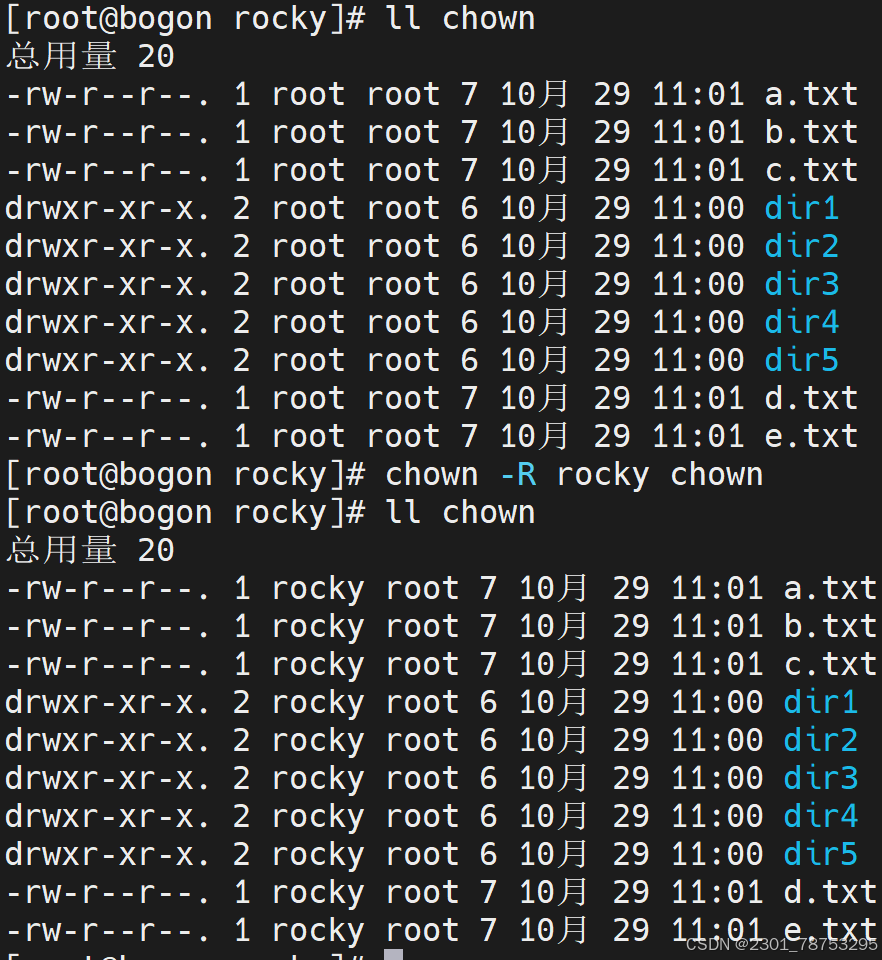
- R 批量修改将一个目录下所有文件修改
用户名后加 : 同时修改属主属组
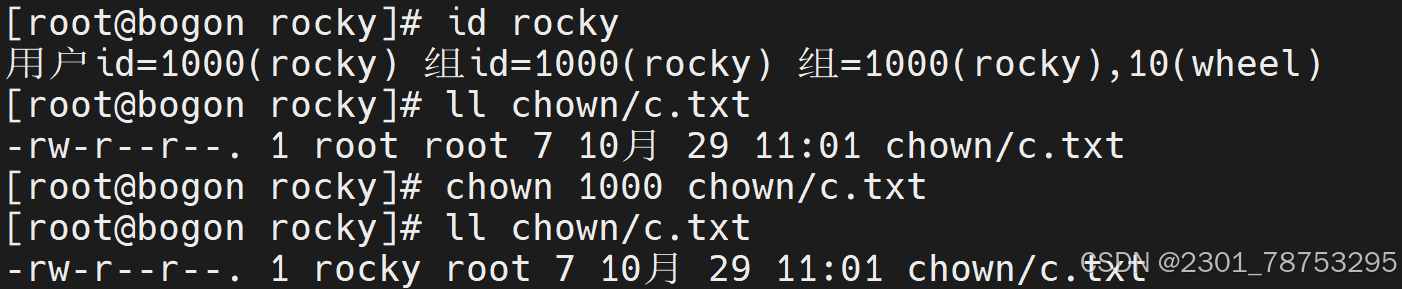
通过用户id的方式修改文件归属
只修改所有者属性
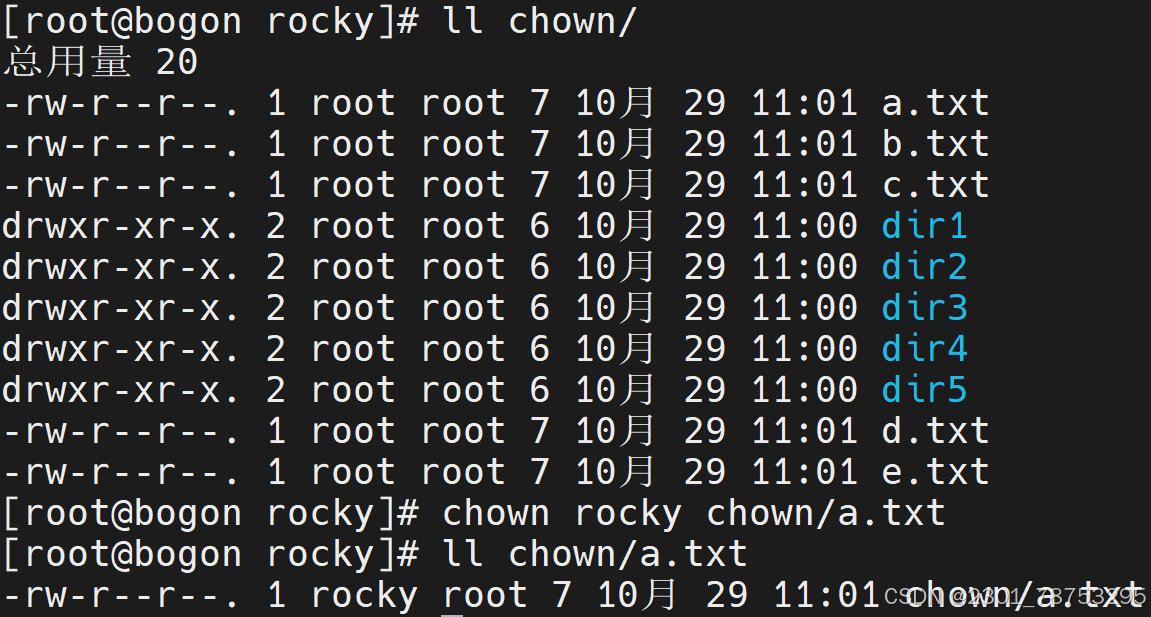
[root@rocky9 ~]# chown sswang chown/a.txt
同时修改所有者和归属组的属性
[root@rocky9 ~]# chown sswang. chown/b.txt # . 的这种方式,虽然管用,但是不推 荐

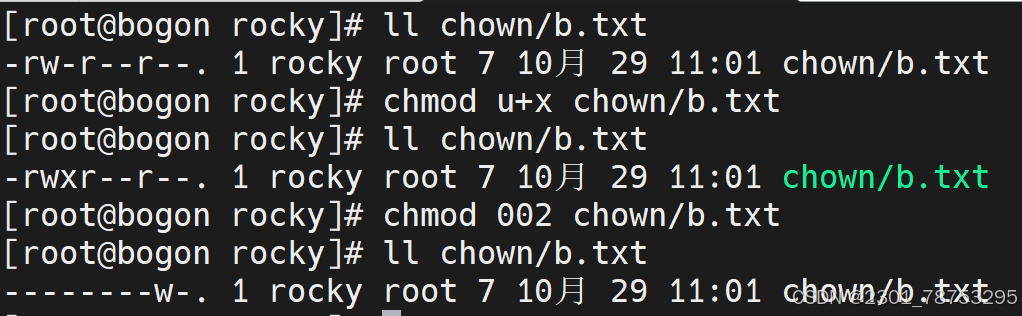
4.3.5 chmod 修改文件操作权限
使用方法 chomd 指定u/g/o加或减权限 文件名 或777这样指定权限
选项
- R 递归操作
+ 加权限
- 减权限
a 等于ugo
u+rwx或7 是加属主权限
g+rwx或7 是加属组权限
o+rwx或7 是加其他用户权限


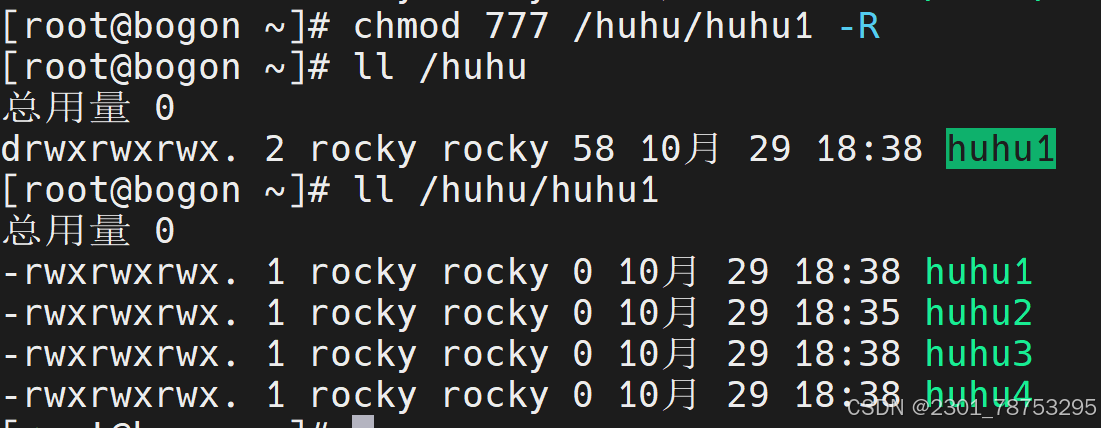
4.3.6 umask修改查看文件创建掩码
使用方式 umask 加选项 或直接输入值
选项
- p 如果省略 MODE 模式,以可重用为输入的格式输入
- S 以字符显示
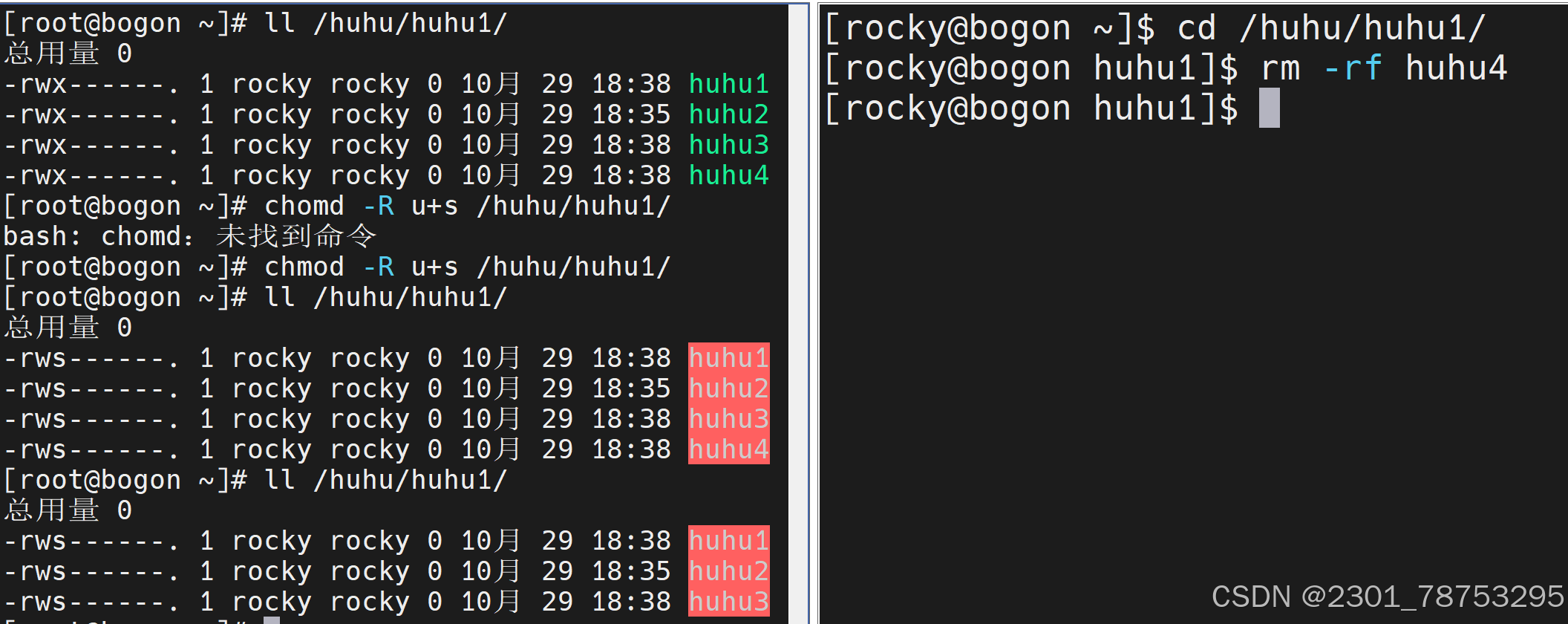
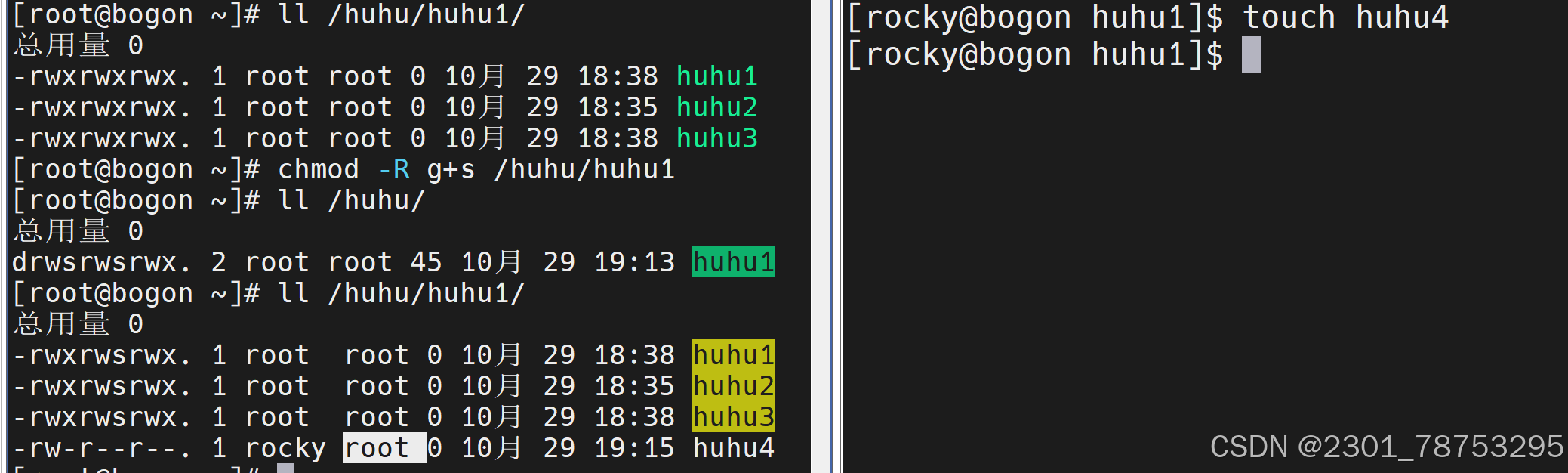
4.3.7 特殊权限
在Linux文件系统中,除了基本的读(r)、写(w)、执行(x)权限外,还存在三种特殊权限,它们分 别是SUID(Set User ID)、SGID(Set Group ID)和Sticky Bit。这些特殊权限用于在特定情况下提 供更灵活的权限控制。
1.SUID权限设置在可执行文件上时,让其他用户拥有为文件所有者的权限
u+s
2. SGID权限可以应用于可执行文件或目录。其他用户在下面创建文件目录会变成所有者的组
g+s
3. Sticky Bit权限仅对目录有效。当一个目录被设置为Sticky Bit时,其他用户只能查看其他都不可以 但是文件所有者和root用户除外
o+t
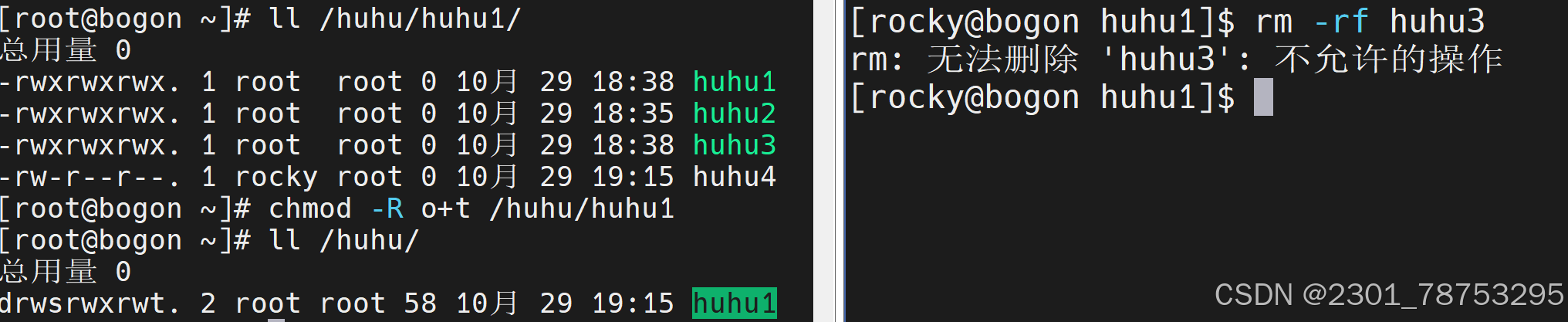
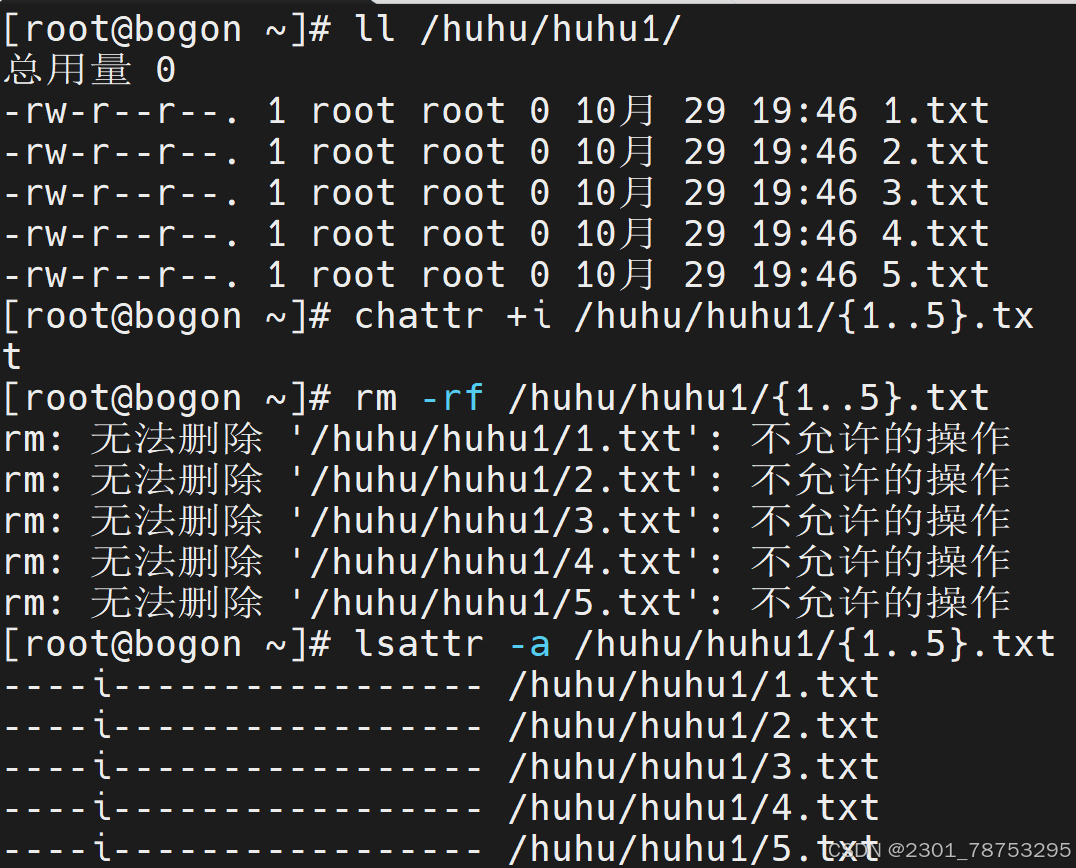
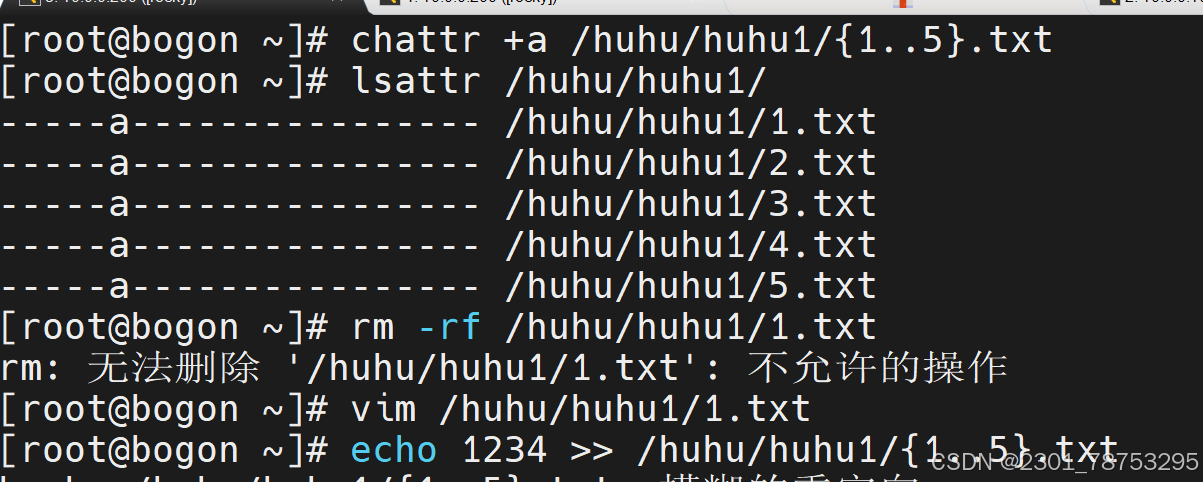
4.3.8 chattr 改变文件目录扩展属性
使用方法 +-= 选项 文件名字
选项
- p
- R
- V
- f
- v
动作
+表示添加属性,-表示移除属性,=表示设置唯一属性,覆盖其他所有属性。
常用属性
a:只允许追加数据,不能删除或修改文件内容。
i:设置文件为不可修改,即不能删除、重命名、修改内容或添加链接。
s:同步写入磁盘,修改立即生效,而非默认的非同步方式。
u:当文件被删除时,其内容仍保留在磁盘上,直到空间被其他文件覆盖。
A:访问文件时不更新访问时间。
c:自动压缩文件。
d:防止目录被dump备份。
这些属性可以增强文件的安全性,防止被意外修改、删除 或重命名。
4.3.9 lsattr命令用于查看文件或目录的扩展属性
使用方法 lsattr 选项 文件目录名
选项
- a 显示所有文件目录属性包括隐藏文件
- d 如果目标是目录只显示目录本身属性不显示目录内文件属性
- R 递归列出目录及目录下所有目录文件属性
4.4.1 ACL权限
5.1.1 vi与vim文本处理
正常模式-默认模式
进入方式: 打开Vim时自动进入命令模式,或者从其他模式(如插入模式或底行模式)通过按Esc键返回命令模式。
操作示例:
光标移动:使用h、j、k、l键分别向左、下、上、右移动光标(或使用方向键)。
删除字符:按x删除光标所在位置的字符,按dd删除整行。
复制粘贴:使用yy复制当前行,p粘贴到光标所在位置。
编辑模式
进入方式: 从命令模式通过如下按键进入插入模式 - 按 i 在当前光标位置插入 - 按 a 在当前光标位置的下一个字符处插入 - 按 o 在当前光标所在行的下一行插入新行 退出方式: 按Esc键退出插入模式,返回到命令模式
命令模式
底行模式允许用户执行一些高级的编辑和搜索操作,如文件保存、退出、搜索替换、设置选项等。
进入方式:
从命令模式通过按:(冒号)或/(表示查找)进入底行模式。
退出方式: 按Esc键退出底行模式,返回到命令模式。
操作示例: 保存文件:输入:w保存当前文件,:wq或:x保存并退出Vim 查找替换:输入:/搜索词进行查找,:s/原词/新词/g进行全局替换。 设置选项:输入:set nu显示行号,:set nonu取消显示行号。
编辑实践
使用方式 vim 加文件名 选项
+ 打开文件后让光标处于尾行
+N 打开文件后让光标处于第N行的行首,+默认尾行 使用频率最高
+/PATTERN 让光标处于第一个被PATTERN匹配到的行行首
-d file1 file2 同时打开多个文件,相当于 vimdiff
qall 同时退出多个文件
从正常模式进入编辑模式的方法
i insert, 在光标所在处输入
I 在当前光标所在行的行首输入
a append, 在光标所在处后面输入
A 在当前光标所在行的行尾输入
o 在当前光标所在行的下方打开一个新行
O 在当前光标所在行的上方打开一个新行
查找内容
使用方法正常模式下直接输入
/关键字 从当前光标所在处向文件尾部查找 搜索完第一次继续按/会出现相同关键字回车向上查找
?关键字 从当前光标所在处向文件首部查找 搜索完第一次继续按/会出现相同关键字回车向下查找
n/N相当于上下键
n 与命令同方向
N 与命令反方向
扩展命令
: wq 写入并退出
: q! 不存盘退出,即使更改都将丢失
下面这些鸡肋可以玩玩
r filename 读文件内容到当前文件中
w filename 将当前文件内容写入另一个文件
!command 执行命令
r!command 读入命令的输
筛选范围
常用属性
M,N 从左侧M表示起始行,到右侧N表示结尾行
$ 最后一行
% 全文, 相当于1,$
/pat1/,/pat2/ 从第一次被pat1模式匹配到的行开始,一直到第一次被pat2匹配到的行结束 其他属性
N 具体第N行,例如2表示第2行
M,+N 从左侧M表示起始行,右侧表示从光标所在行开始,再往后+N行结束
M,-N 从左侧M表示起始行,右侧表示从光标所在行开始,-N所在的行结束
M;+N 从第M行处开始,往后数N行,2;+3 表示第2行到第5行,总共取4行
M;-N 从第M-N行开始,到第M行结束
. 当前行
.,$-1 当前行到倒数第二行 /pattern/ #从当前行向下查找,直到匹配pattern的第一行,即正则匹配
/pat1/,/pat2/ 从第一次被pat1模式匹配到的行开始,一直到第一次被pat2匹配到的行结束 N,/pat/ 从指定行开始,一直找到第一个匹配pattern的行结束
/pat/,$ 向下找到第一个匹配patttern的行到整个文件的结尾的所有行
动作演示
:2d 删除第2行
:2,4d 删除第2到第4行
:2;+3y 复制第2到第5行,总共4行
p 将复制的粘贴
:2;+4w test 将第2到第6行,总共5行内容写入新文件
:5r /etc/issue 将/etc/issue 文件读取到第5行的下一行
:t2 将光标所在行复制到第2行的下一行
:2;+3t10 将第2到第5行,总共4行::内容复制到第10行之后
:.d 删除光标所在行
:$y 复制最后一行
常用动作
d 删除
p 粘贴
y 复制
u 撤销刚才的动作

重点内容替换
使用方法: s/原内容/替换后内容/修饰符
内容替换方法
:s /要查找的内容/替换为的内容/修饰符
:%s 表示全文查找替换
修饰符
i 忽略大小写
g 全局替换,默认情况下,每一行只替换第一次出现
gc 全局替换,每次替换前询问
常用示例
从全文替换
:%s/原内容/替换后内容/g
从当前行到最后一行进行替换
:,$s/原内容/替换后内容/g
正则匹配内容进行全文替换
:/关键字/,$s/原内容/替换后内容/g
从第3到第6行内容进行替换
:3,6s/原内容/替换后内容/g
, 代表当前行
$ 代表末尾行
% 代表全文
%s/xxx/xxx/g常用
常用属性
查看行号
:set nu #显示行号
:set nonu #取消显示行号
复制保留格式
:set paste #复制时保留其他系统格式 作用将格式还原回来原样粘贴
:set nopaste #禁用复制时保留其他系统格式选项
Tab 用空格代替
:set et #使用空格代替Tab,默认8个空格
:set noet #禁用空格代替Tab
Tab用指定空格的个数代替
:set ts=N #指定N个空格代替Tab
查看帮助
:help option-list
:set all
:set cul 表示线
:set nocul 取消标识线
:set ai 启用自动缩进
:set noai 取消自动缩进
:set key=password 设置密码
行首跳转
^ #跳转至行首的第一个非空白字符
0 #跳转至行首
$ #跳转至行尾
行间移动:
:N #跳转至指定行,N表示正整数,比如 10G,或在扩展命令模式下:10,都表示跳转到第10 行
G #最后一行
1G #第一行
当前页跳转:
H #页首
M #页中间行
L #页底
命令模式翻屏操作
Ctrl+f #向文件尾部翻一屏,相当于Pagedown
Ctrl+b #向文件首部翻一屏,相当于Pageup
Ctrl+d #向文件尾部翻半屏
Ctrl+u #向文件首部翻半屏
5.1.2 可视化模式
ctrl-v(小写) 面向块
1、先将光标移动到指定的第一行的行首
2、输入ctrl+v 进入可视化模式
3、向下移动光标,选中希望操作的每一行的第一个字符
4、输入大写字母 I 切换至插入模式 5、输入 # 6、按 ESC 键
1、光标定位到要操作的地方
2、CTRL+v 进入“可视块”模式,选取这一列操作多少行
3、SHIFT+i(I)
4、输入要插入的内容
5、按 ESC 键
5.1.3 cat 查看文件内容
使用方法: cat 选项 文件名
选项:
- n 对显示的每一行编号
- s 压缩连续的空行成一行
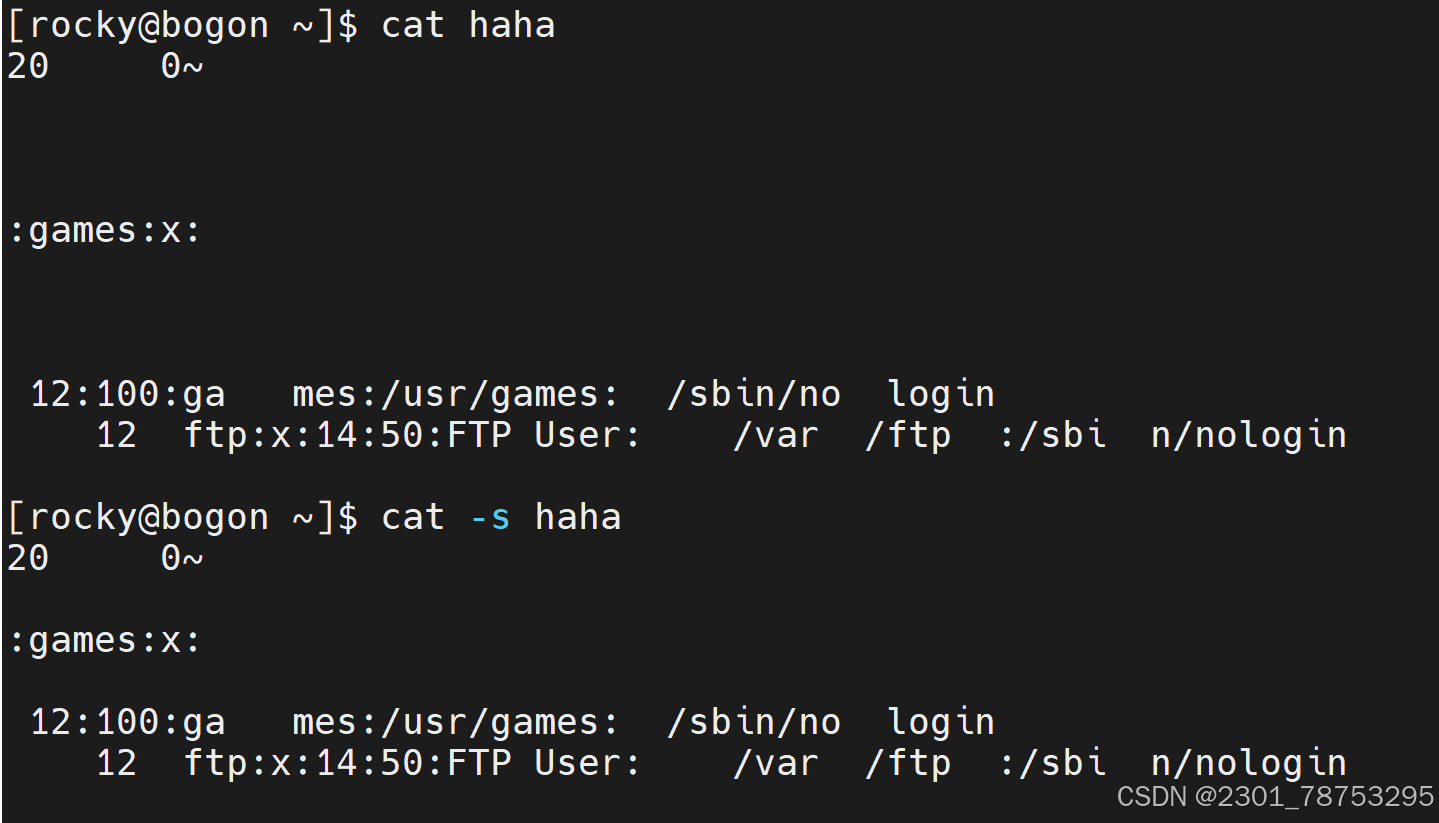
tac 逆向显示文件内容
rev 内容逆向显示,行内容也逆向显示
hexdump 以十六进制方式查看任意文件
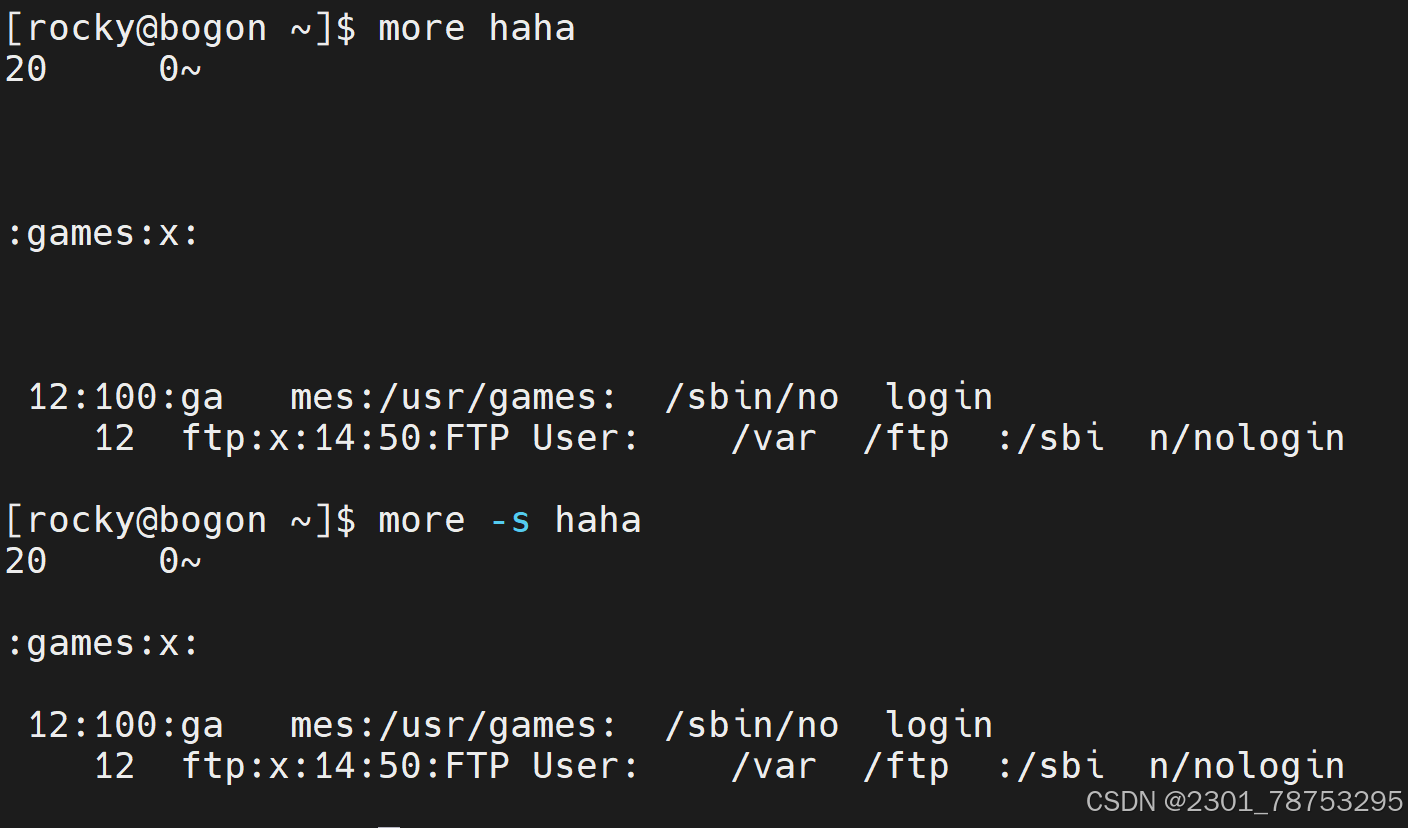
5.1.4 more 分页查看
使用方法: more 选项 文件名
选项:
- d 在底部显示提示
- s 压缩连续空行
常用动作
空格键 #翻页
回车键 #下一行
q #退出
其他动作
!cmd #执行命令,在查看文档的时候,执行相关的命令
h #显示帮助
:f #显示文件名和当前行号
= #显示行号
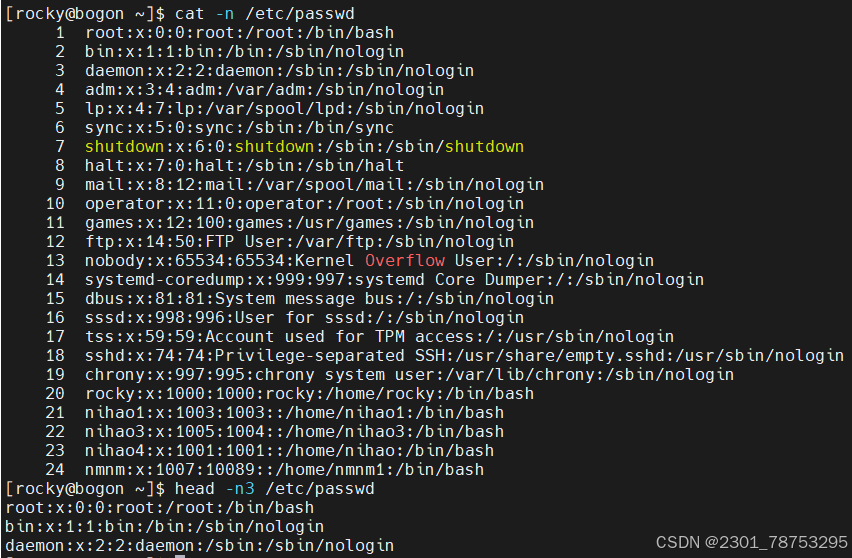
*5.1.5 head 可以显示文件或标准输入的前面行
使用方法 head 选项 文件名
常用选项
- n 指定获取后N行,如果写成n3,表示从第1行到3行
一般选项
-c 指定获取前N字节
-N 同上
-q 不输出文件名
-v 输出文件名
-z 以NULL字符而非换行符作为行尾分隔符
与tail搭配使用
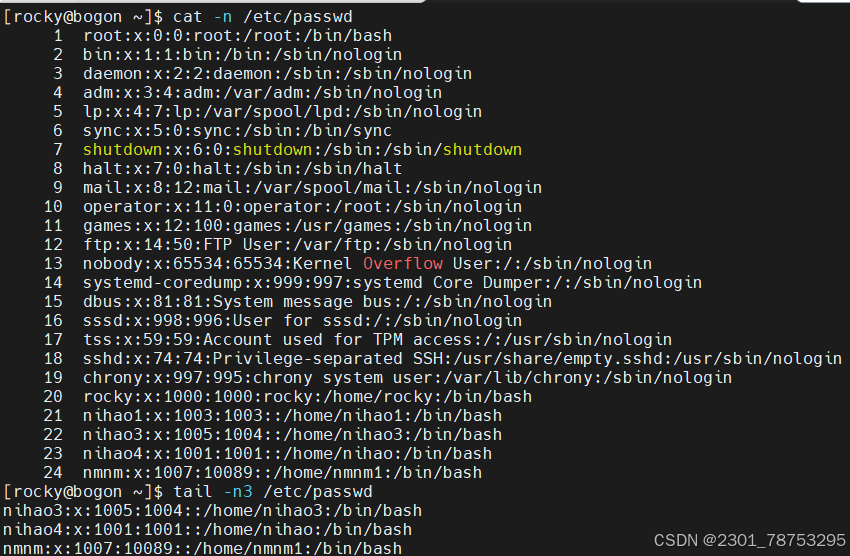
5.1.6 tail 和 head 相反,查看文件或标准输入的倒数行
使用方法 tail 选项 文件
常用选项
-n 指定获取后N行,如果写成n3,表示从第1行到3行
一般选项
-c 指定获取后N字节
-N 同上
-f 跟踪显示文件fd新追加的内容,常用日志监控, #当删除再新建同名文件,将无法继续跟踪
-F 跟踪文件名,相当于--follow=name --retry, #当删除文件再新建同名文件,可继续追踪
-q 不输出文件名
-z 以NULL字符而非换行符作为行尾分隔符
与head搭配使用
head和tail组合使用
查看/etc/passwd文件中第三行
head -n3 将/etc/passwd 前三行取出 | 交给 tail -n1 将三行中的倒数第一行取出
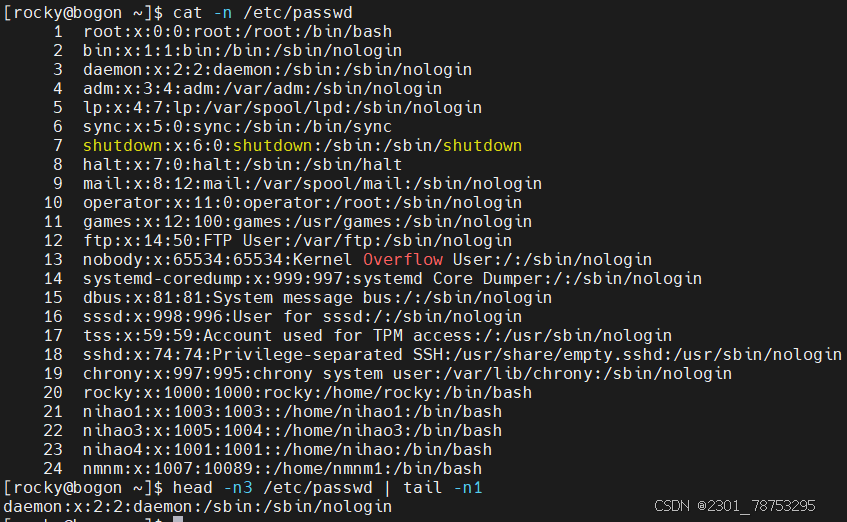
5.1.7cut 命令可以提取文本文件或STDIN数据的指定列
使用方法 cut 选项 选项 文件 或 | cut 选项 选项
常用选项:
- c 选择指定字符
- d 选择指定字符为列分界
必须选项
-f 指定第几列输出f1是第一列
--output-delimiter=字符串 使用指定的字符串作为输出分界符,默认采用输入

5.1.8 tr命令实现 字符转换、替换、删除
-c, 首先补足SET1
-d, 删除匹配SET1 的内容,并不作替换
-s 如果匹配连续的空格重复,在替换时会被统一缩为一个字符的长度
-t 先将SET1 的长度截为和SET2 相等
用法1:把commands命令输出做为tr输入进行处理 commands | tr 'string1' 'string2'
用法2:把文件中的内容输入给tr进行处理 tr 'string1' 'string2' < filename
用法3:把文件中的内容输入给tr进行处理,需要使用到选项 tr options 'string1' < filename
用法4: 删除不匹配的所有内容,仅留下有用的信息 tr -dc [:alnum:]
总结head tail cut tr 组合使用
ip a查看用户ip head -n10输出前十行 tail -n1输出倒数第一行 tr -s " " 压缩多个空格为一个空格 cut -d " " 将空格作为分隔符
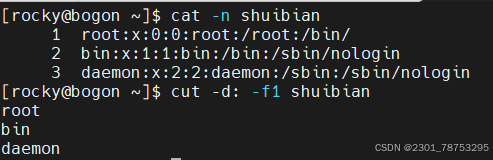
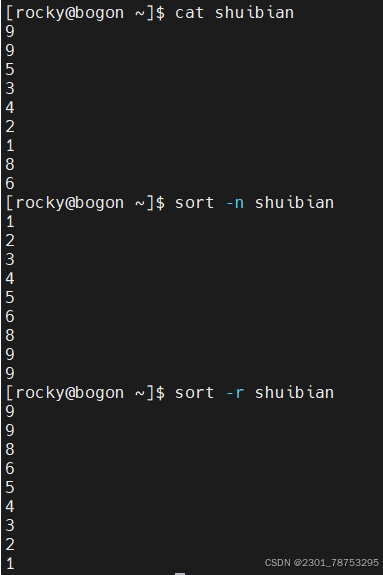
5.1.9 sort将相同信息整 |理在一起排序
使用方式 sort 选项 文件
常见选项:
-u :去除重复行
-r :降序排列,默认是升序
-n :以数字排序,默认是按字符排序 其他选项
其他选项
-o : 将排序结果输出到文件中 类似 重定向符号>
-t :分隔符
-k :第N列
-b :忽略前导空格。
-R :随机排序,每次运行的结果均不同。
只输入sort可以将相同的内容排在一起
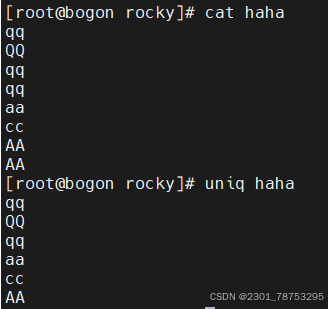
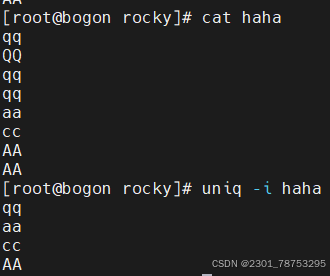
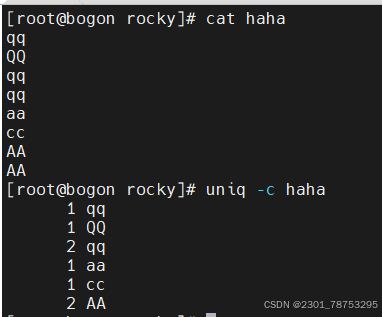
5.2.1 uniq命令 实现连续信息的去重动作
使用方法 uniq 信息
常用选项
空没有
一般选项
-c, --count 统计重复行次数
-d, --repeated 只显示重复行
-i, --ignore-case 忽略大小写
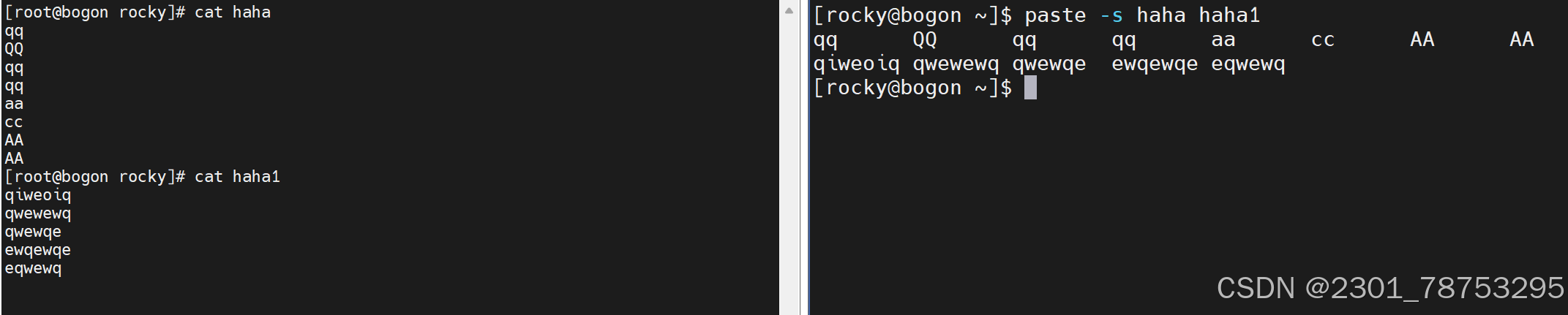
5.2.2 paste合并文件行内容输出到屏幕,不会改动源文件
使用方法paste 文件一 文件二
-d 列表 改用指定列表里的字符替代制表分隔符
-s 不使用平行的行目输出模式,而是每个文件占用一行


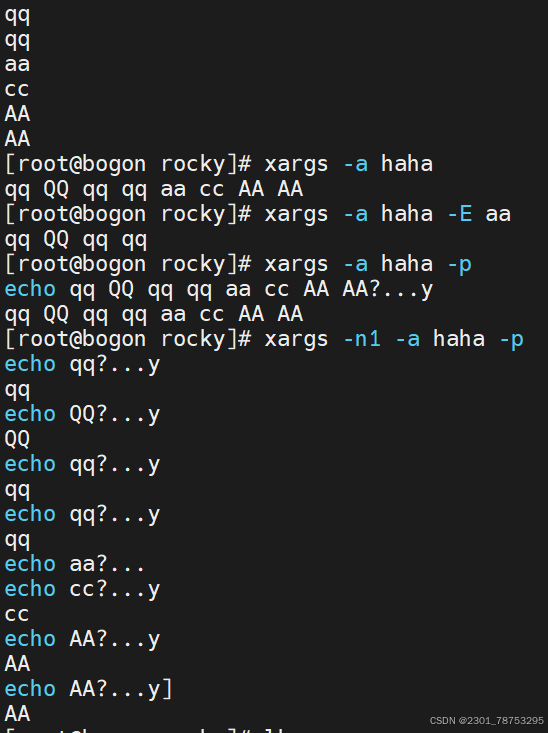
5.2.3 xargs命令
使用方式 xargs 选项 文件
选项
-a file 从文件中读入作为sdtin
-E flag flag必须是一个以空格分隔的标志,当xargs分析到含有flag这个标志的时候就停止。
-p 当每次执行一个argument的时候询问一次用户。
-n num 后面加次数,表示命令在执行的时候一次用的argument的个数,默认是用所有的。
-t 表示先打印命令,然后再执行。
-i 或者是-I,将xargs接收的每项名称,逐行赋值给 {},可以用 {} 代替。
-r no-run-if-empty 当xargs的输入为空的时候则停止xargs,不用再去执行了。
-d delim 分隔符,默认的xargs分隔符是回车,argument的分隔符是空格,这里修改的是xargs的分 隔符。
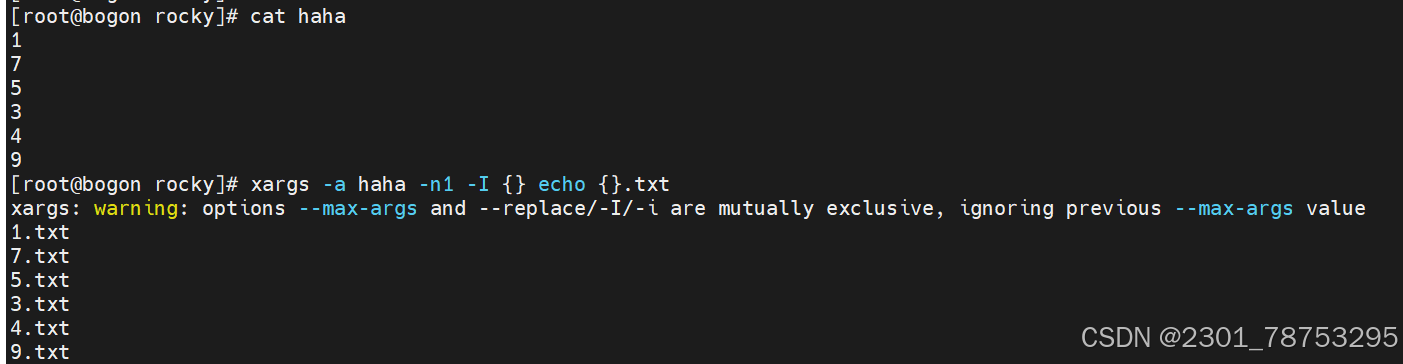
5.2.4 文本三剑客
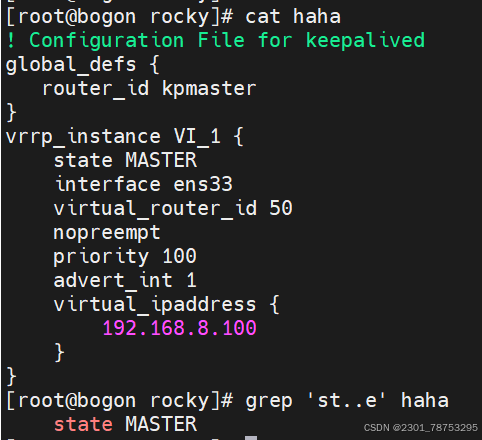
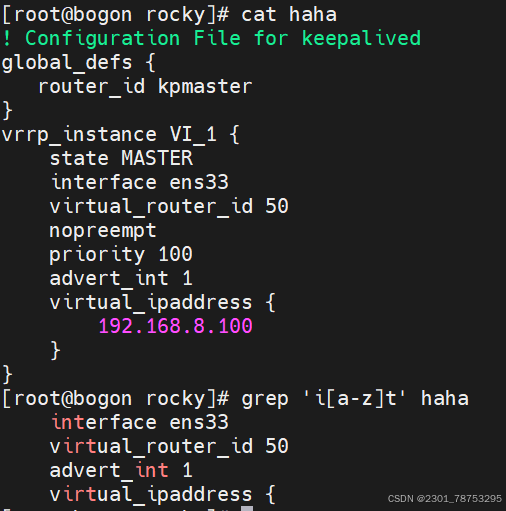
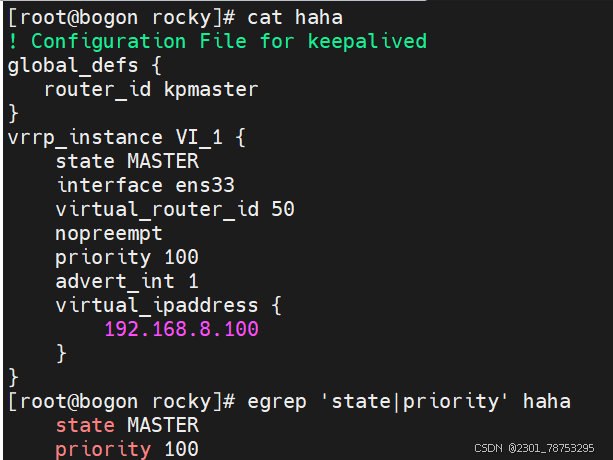
1.grep 负责从数据源中检索对应的字符串,行过滤
使用方法 grep 选项 文件名
常见选项:
-i: 输入要匹配的内容不区分大小写
-n: 输入要匹配的内容显示匹配到的内容在源文件行号
-r: 逐层遍历目录查找
-v: 查找不包含指定内容的行,反向选择
-o: 打印匹配到的关键字
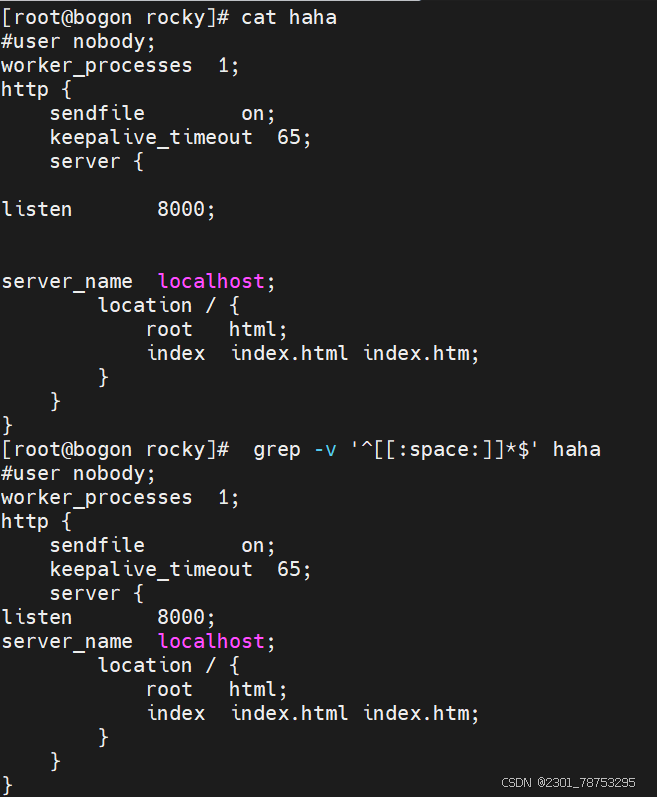
-E: 使用扩展正则匹配 ^key:以关键字开头 key$:以关键字结尾 ^$:匹配空行
一般选项
-w: 按单词搜索
-c: 统计匹配到的次数
-A: 显示匹配行及后面多少行
-B: 显示匹配行及前面多少行
-C: 显示匹配行前后多少行
-l: 只列出匹配的文件名
-L: 列出不匹配的文件名
-e: 使用正则匹配
--color=auto :可以将找到的关键词部分加上颜色的显示
常用命令选项必知必会 示例:
# grep -i root passwd 忽略大小写匹配包含root的行
# grep -w ftp passwd 精确匹配ftp单词
# grep -wo ftp passwd 打印匹配到的关键字ftp
# grep -n root passwd 打印匹配到root关键字的行号
# grep -ni root passwd 忽略大小写匹配统计包含关键字root的行
# grep -nic root passwd 忽略大小写匹配统计包含关键字root的行数
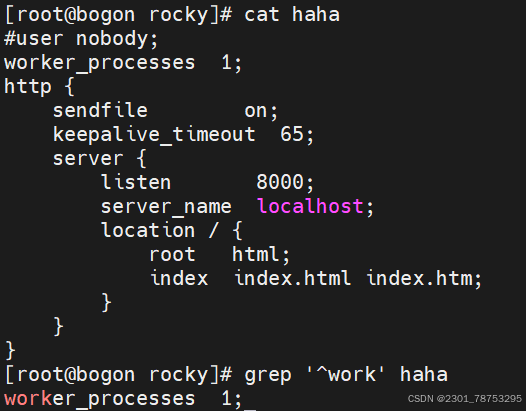
# grep -i ^root passwd 忽略大小写匹配以root开头的行
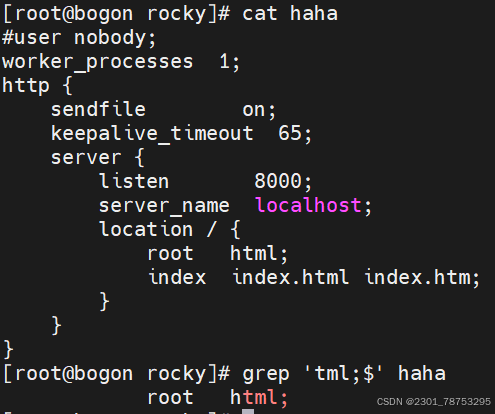
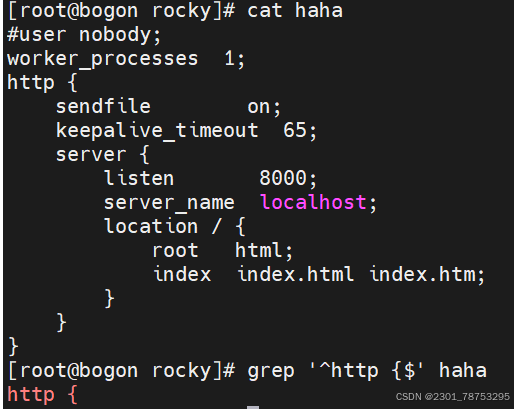
# grep bash$ passwd 匹配以bash结尾的行 # grep -n ^$ passwd 匹配空行并打印行号
# grep ^# /etc/vsftpd/vsftpd.conf 匹配以#号开头的行
# grep -v ^# /etc/vsftpd/vsftpd.conf 匹配不以#号开头的行 # grep -A 5 mail passwd 匹配包含mail关键字及其后5行
2 sed基础
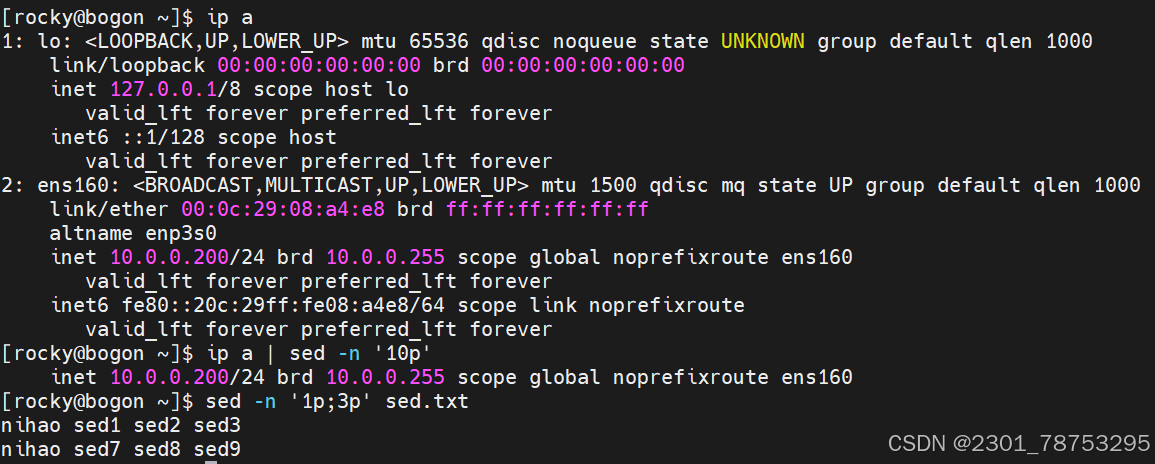
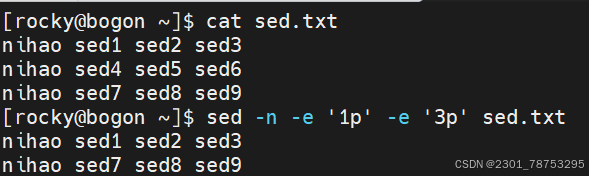
使用方法: sed [参数] ' [动作]' [文件名]
参数:
参数为空 表示sed的操作效果,实际上不对文件进行编辑,缓存区所有信息都显示
-n 不输出模式空间内容到屏幕,即不自动打印所有内容
-e 基于命令实现对文件的多点编辑操作
-f 从指定文件中读取编辑文件的”匹配条件+动作”
-r 支持使用扩展正则表达式
-i.bak 复制文件原内容到备份文件,然后对原文件编辑
-i 表示对文件进行编辑
-g 所有内容
匹配条件分为两种:数字行号或者关键字匹配
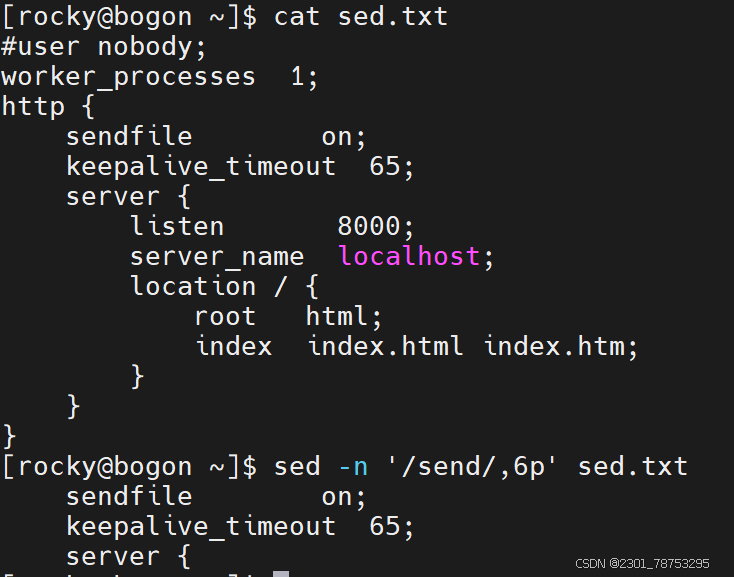
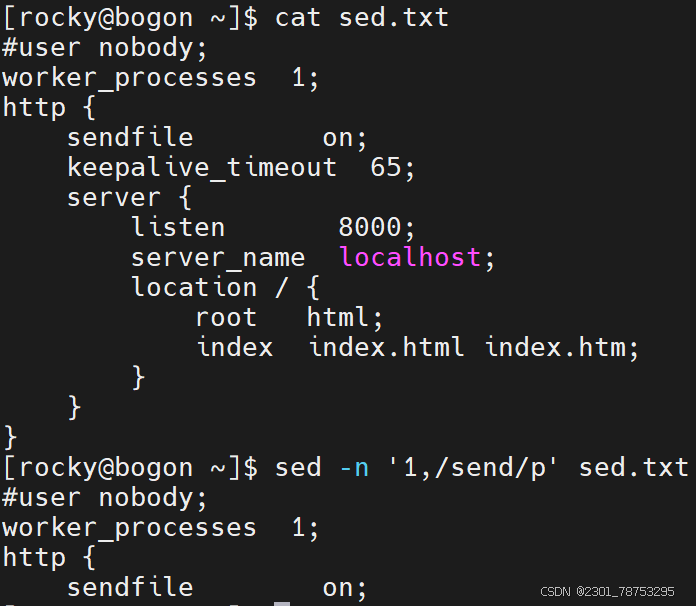
数字行号: 空 表示所有行 n 表示第n行 $ 表示末尾行
n,m 表示第n到m行内容 n,+m 表示第n到n+m行
~步进 1~2 表示奇数行 2~2 表示偶数行
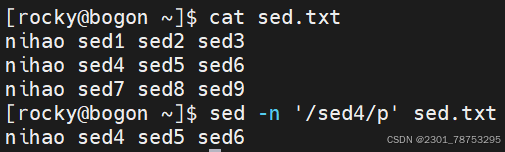
关键字匹配格式
'/关键字/'
注意:
隔离符号 / 可以更换成 @、#、!等符号
根据情况使用,如果关键字和隔离符号有冲突,就更换成其他的符号即可。
/关键字1/,/关键字2/ 表示关键字1所在行到关键字2所在行之间的内容
n,/关键字2/ 表示从第n行到关键字2所在行之间的内容
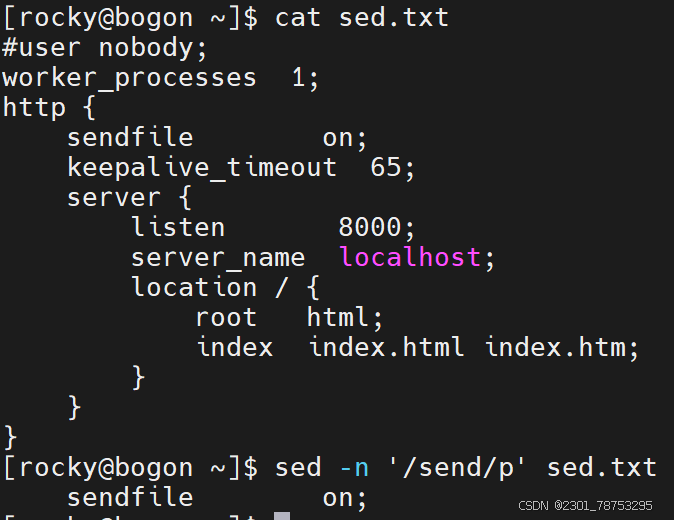
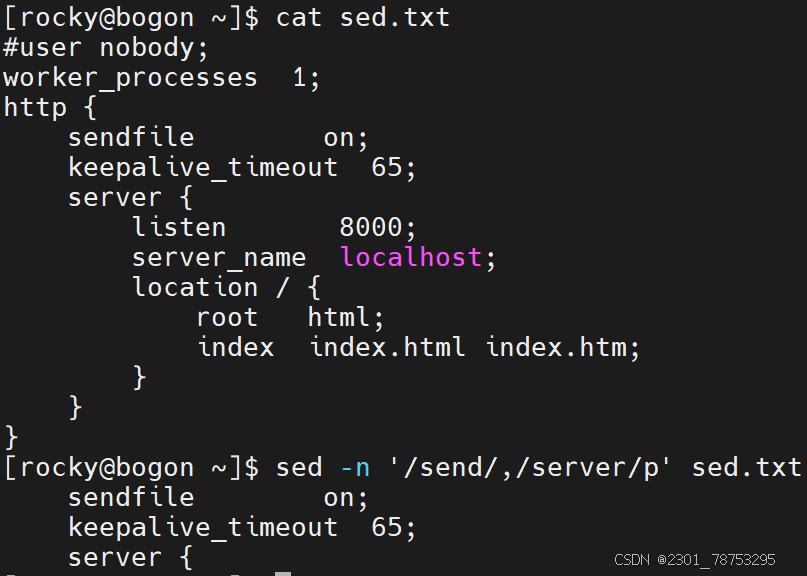
/^/dev/sd/p 第一个 / 是匹配的意思 ^开头 转意 / P打印 打印以/dev/sd 开头的文件
动作详解
-a[ ext] 在匹配到的内容下一行增加内容,支持 实现多行追加
-i[ ext] 在匹配到的内容当前行增加内容
-c[ ext] 在匹配到的内容替换内容
-d|p 删除|打印匹配到的内容
-p 打印匹配到的内容
-s 替换匹配到的内容
W /path/somefile 保存模式匹配的行至指定文件
r /path/somefile 读取指定文件的文本至模式空间中
= 为模式空间中的行打印行号
! 模式空间中匹配行取反处理
注意: 上面的动作应该在参数为-i的时候使用,不然的话不会有效果
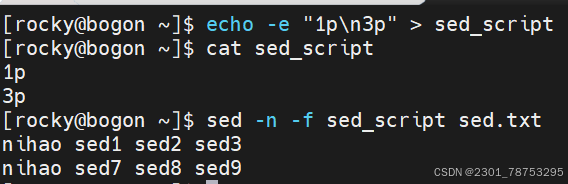
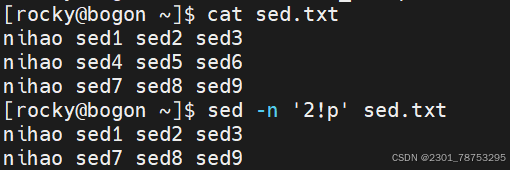
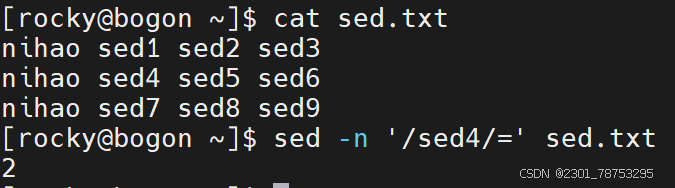
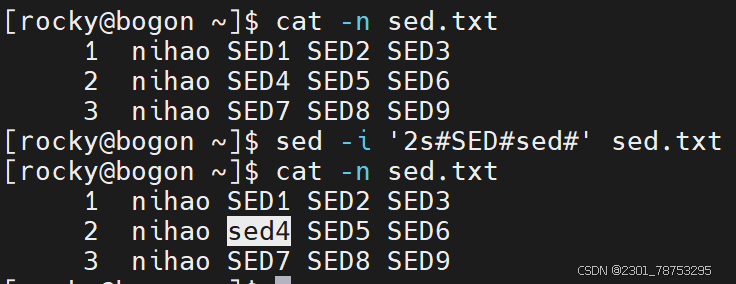
sed替换
命令格式:
sed -i [替换格式] [文件名]
源数据 | sed -i [替换格式]
注意:替换命令的写法
's' ---> 's#原内容' ---> 's#原内容#替换后内容#'
隔离符号 / 可以更换成 @、#、!等符号
表现样式:
样式一:替换指定匹配的内容
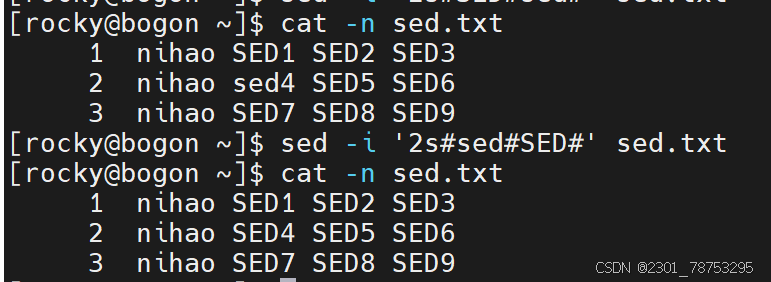
sed -i '行号s#原内容#替换后内容#列号' [文件名]
echo "源数据" | sed -i '行号s#原内容#替换后内容#列号'
样式二:替换所有的内容
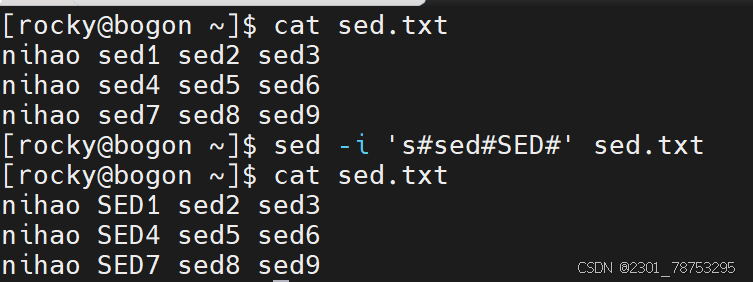
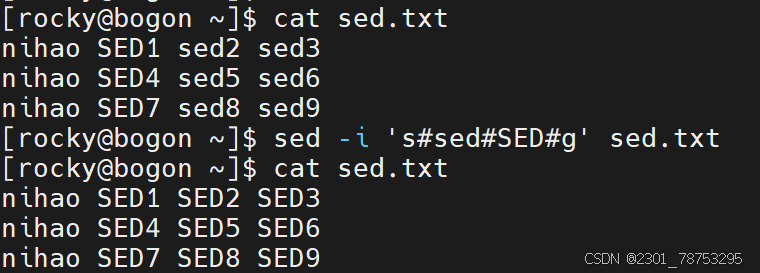
sed -i 's#原内容#替换后内容#g' [文件名]
echo "源数据" | sed -i '行号s#原内容#替换后内容#g'
样式三: 替换指定的内容
sed -i '行号s#原内容#&新增信息#列号' [文件名]
- 这里的&符号代表源内容,实现的效果是 '原内容+新内容'
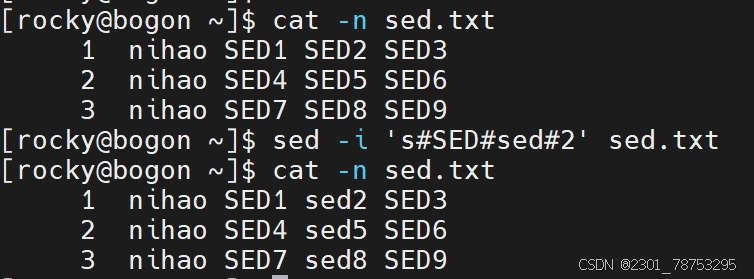
sed增加操作
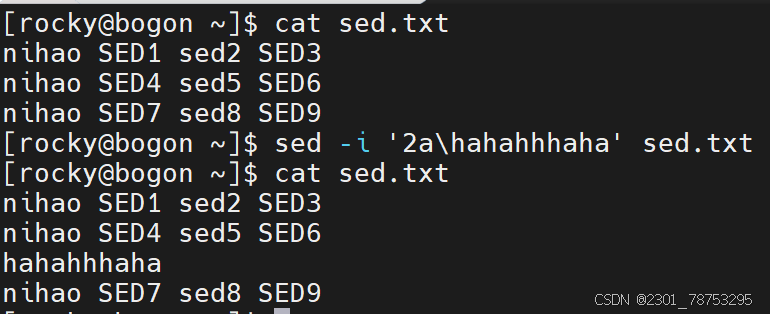
追加
作用:
在指定行号的下一行增加内容
格式:
sed -i '行号a增加的内容' 文件名
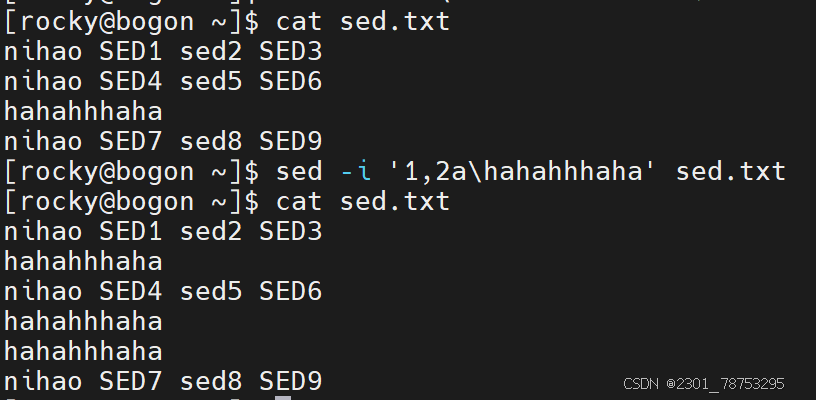
注意:
如果增加多行,可以在行号位置写个范围值,彼此间使用逗号隔开,例如 sed -i '1,3a增加内容' 文件名
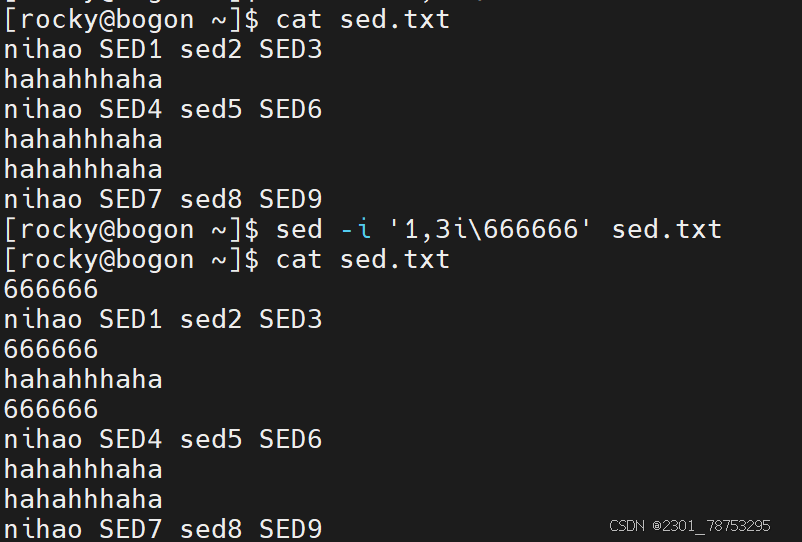
插入
作用:
在指定行号的当行增加内容
格式:
sed -i '行号i增加的内容' 文件名
注意:
如果增加多行,可以在行号位置写个范围值,彼此间使用逗号隔开,例如 sed -i '1,3i增加内容' 文件名
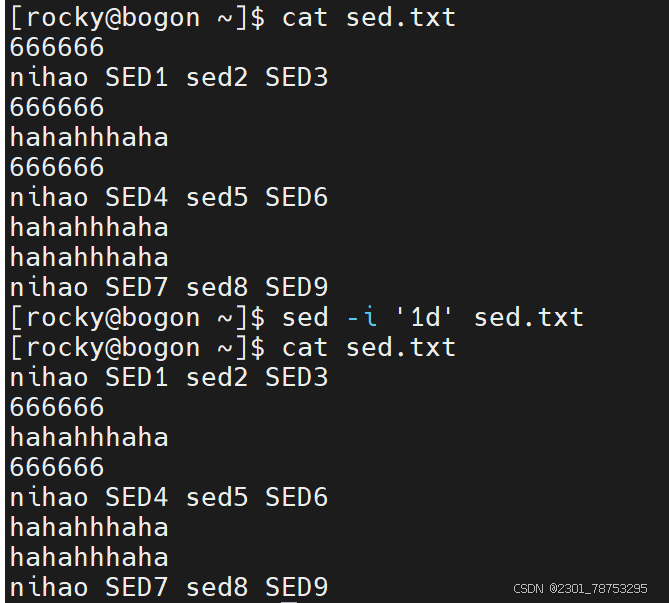
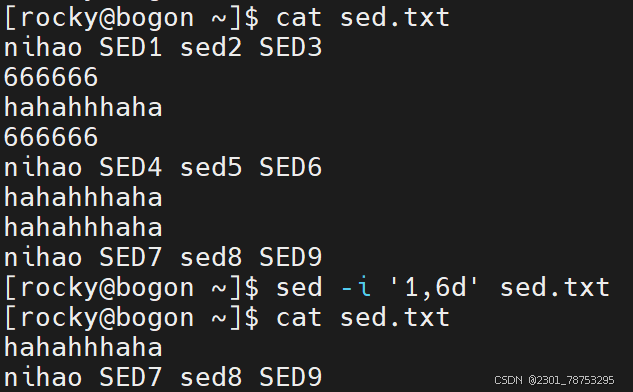
删除替换
作用:
指定行号删除 格式: sed -i '行号d' 文件名
注意:
如果删除多行,可以在行号位置多写几个行号,彼此间使用逗号隔开,例如 sed -i '1,3d' 文件名
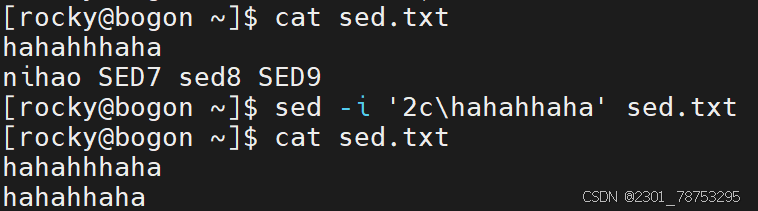
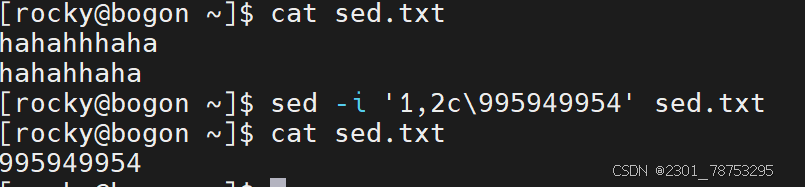
替换
作用:
指定行号进行整行替换
格式:
sed -i '行号c内容' 文件名
注意:
如果替换多行,可以在行号位置多写几个行号,彼此间使用逗号隔开,例如 sed -i '1,3c内容' 文件名
加载保存
作用:
加载文件内容到指定行号的位置
格式:
sed -i '行号r 文件名1' 文件名
注意:
如果在多行位置加载,可以在行号位置多写几个行号,彼此间使用逗号隔开,例如 sed -i '1,3r 文件名1' 文件名
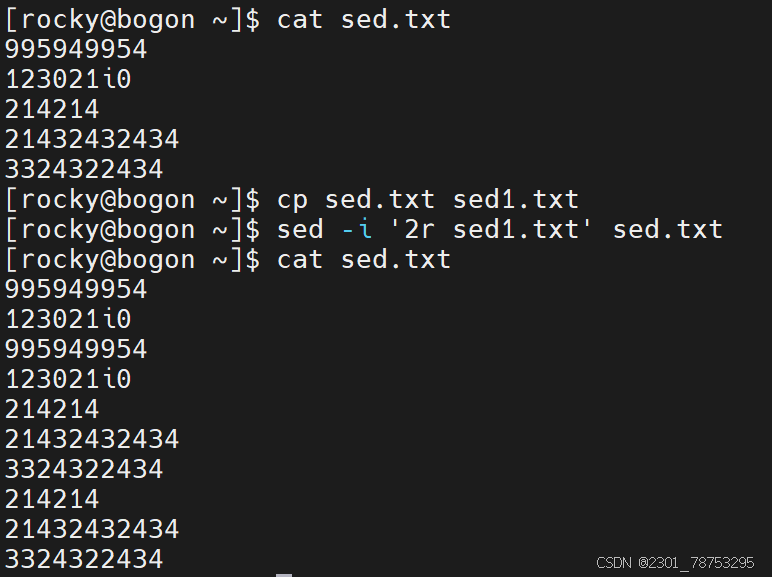
保存实践
作用:
指定行号保存到其他位置
格式:
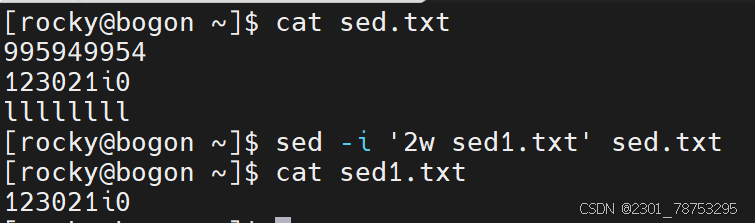
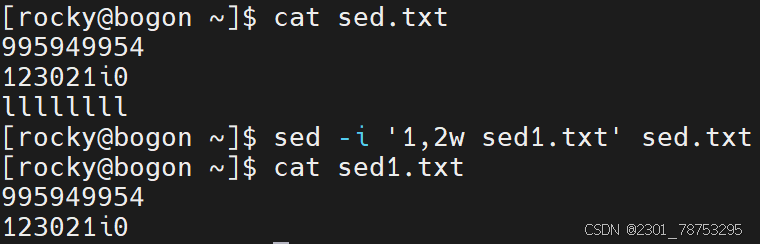
sed -i '行号w 文件名' 文件名
注意:
如果多行保存,可以在行号位置多写几个行号,彼此间使用逗号隔开,例如 sed -i '1,3w 文件名' 文件名 文件名已存在,则会覆盖式增加
匹配进阶
内容匹配:
'/关键字内容/'
注意:
隔离符号 / 可以更换成 @、#、!等符号
根据情况使用,如果关键字和隔离符号有冲突,就更换成其他的符号即可。
/关键字1/,/关键字2/ 表示关键字1所在行到关键字2所在行之间的内容
n,/关键字2/ 表示从第n行到关键字2所在行之间的内容
/关键字1/,n, 表示从关键字1所在行到第n行之间的内容
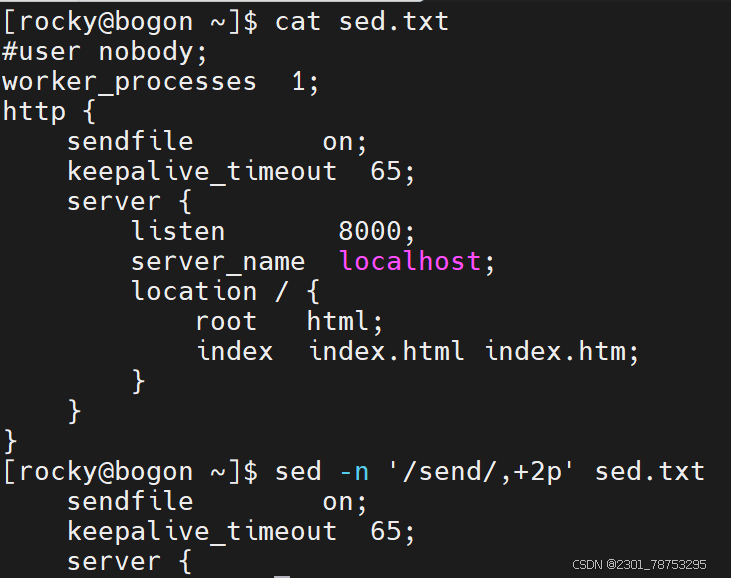
/关键字1/,+n, 表示从关键字1所在行到(所在行+n行)之间的内容
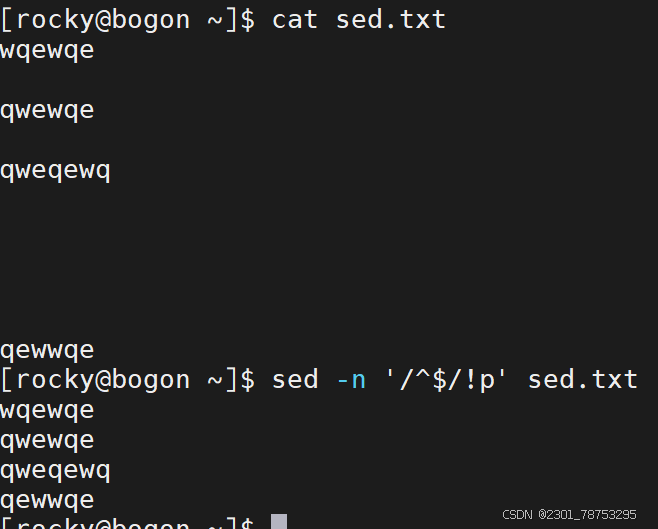
文件处理
我们可以借助 '动作1;动作2' 或者 -e '动作1' -e '动作2' 的方式实现多操作的并行实施
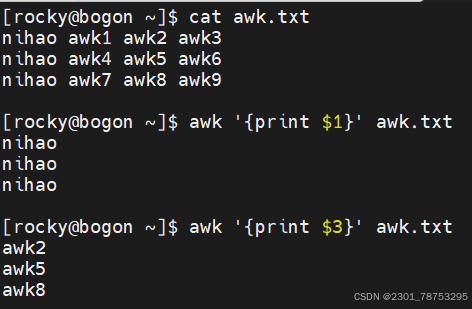
5.2.5AWK基础
使用方法:
awk [参数] '[动作]' [文件名]
awk [参数] –f 动作文件 var=value [文件名]
awk [参数] 'BEGIN段 [动作] END段' [文件名]
注意:
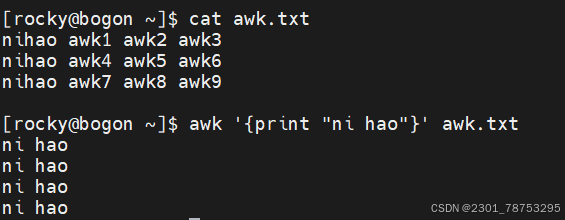
动作的格式 '匹配条件{打印动作}'
常见参数:
-F 指定列的分隔符,默认一行数据的列分隔符是空格
-f file 指定读取程序的文件名
-v var=value 自定义变量
常见动作
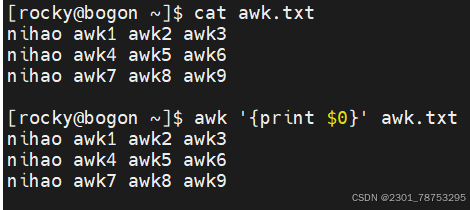
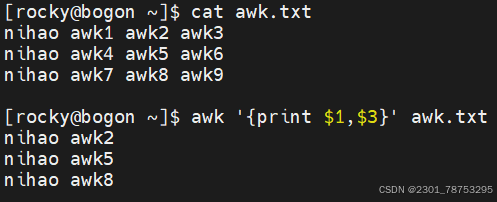
print 显示内容
$0 显示当前行所有内容
$n 显示当前行的第n列内容,如果存在多个$n,它们之间使用逗号(,)隔开
注意:
如果打印的内容是变量,则无需在变量两侧加上双引号,其他的都应该加双引号
字段提取:提取一个文本中的一列数据并打印输出,它提供了相关的内置变量。
$0 表示整行文本
$1 表示文本行中的第一个数据字段
$2 表示文本行中的第二个数据字段
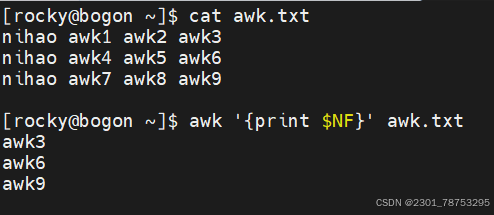
$N 表示文本行中的第N个数据字段
$NF 表示文本行中的最后一个数据字段
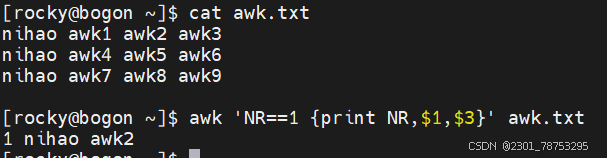
NR 代表行的行号,在动作外部表示特定行
注意:
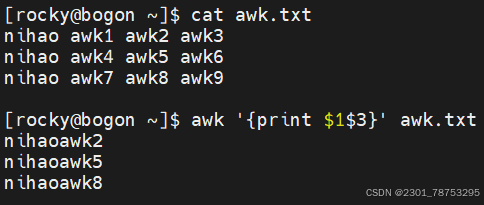
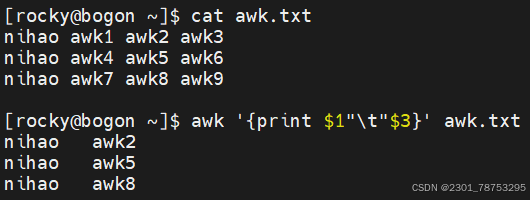
如果打印多列信息,需要使用逗号隔开,否则是内容合并



定制查看
常见参数:
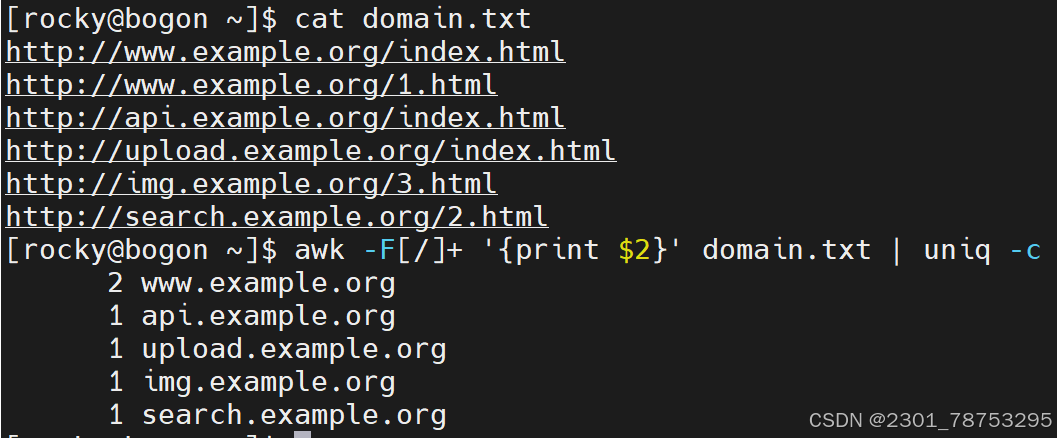
-F 指定列的分隔符,默认一行数据的列分隔符是空格 常见内置变量
FS 输入文件的列分隔符,缺省是连续的空格和Tab
RS 输入的分隔符,指定输入时的 原换行符($)仍有效
注意:
一般情况下,在输出信息之前进行格式的调整,需要在BEGIN{}部分设定


显示语法
属性方法
OFS 输出格式的列分隔符,缺省是空格
ORS 输出记录分隔符,输出时用指定符号代替换行符
print方法
printf [-v var] format [item1,item2,...]
注意:
printf输出需要指定换行符号,format的格式必须与后面item对应
常见格式:
%c 显示字符的ASCII码 %d|i 显示十进制整数
%e|E 显示科学计数法数值 퉳无符号整数
%f 显示浮点数 %s 显示字符串
%% 显示%本身
修饰符:
%#[.#] 第一个#控制显示宽度,第二个#表示小数点后的精度,例如%3.1f
%- 左对齐,%-15s
%+ 显示数值的正负符号,%+d
BEGIN 先执行预处理



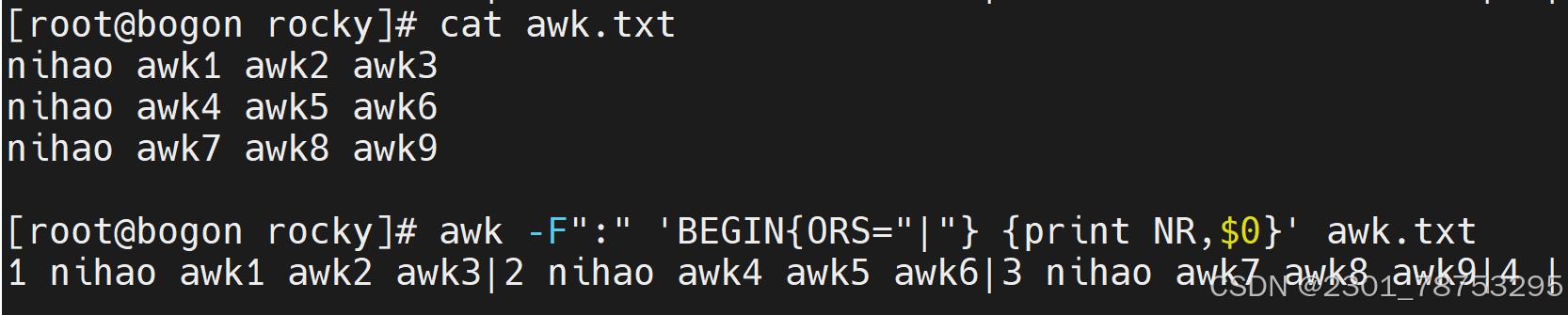
NR输出加行号 $0输出每一行的全部信息
printf格式化输出实践

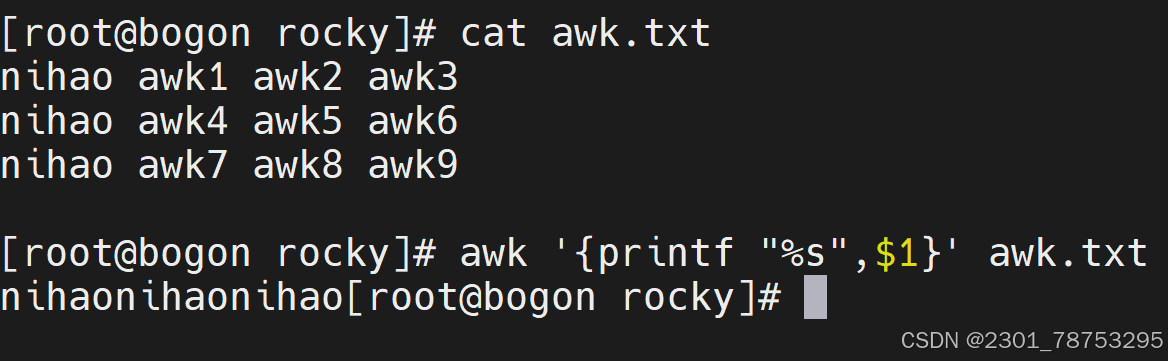
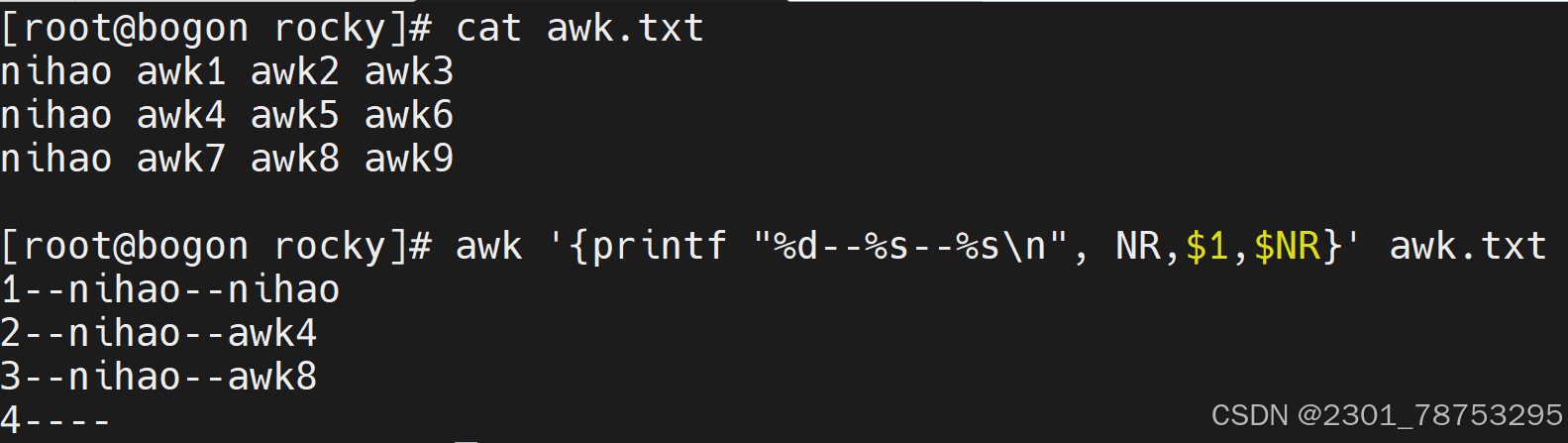
$1取第一列 $NR随着行号变化行号是1他就取第一列是二就取第二列 是三就取第三列
优先级
格式显示:
BEGIN{}: 读入第一行文本之前执行的语句,一般用来初始化操作
{}: 逐行处理的执行命令
END{}: 处理完最后以行文本后执行,一般用来处理输出结果
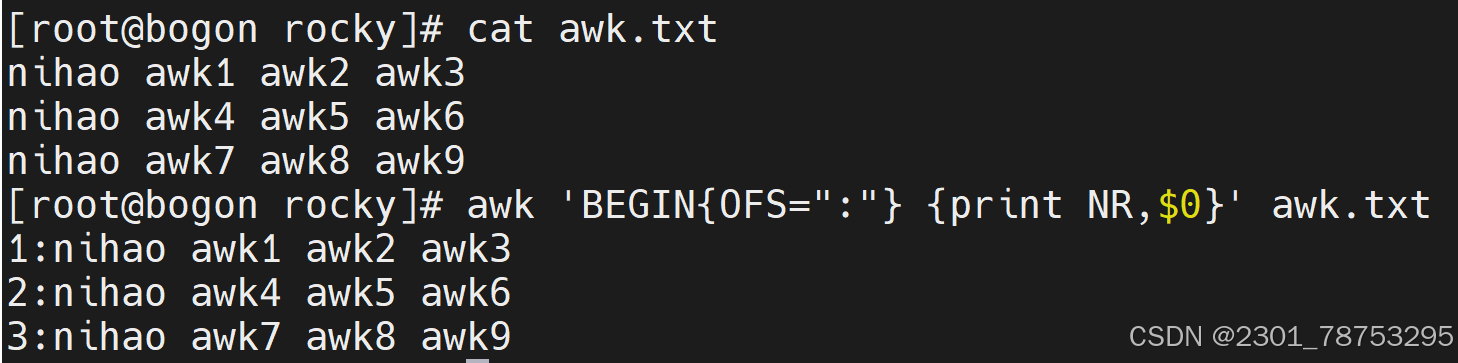
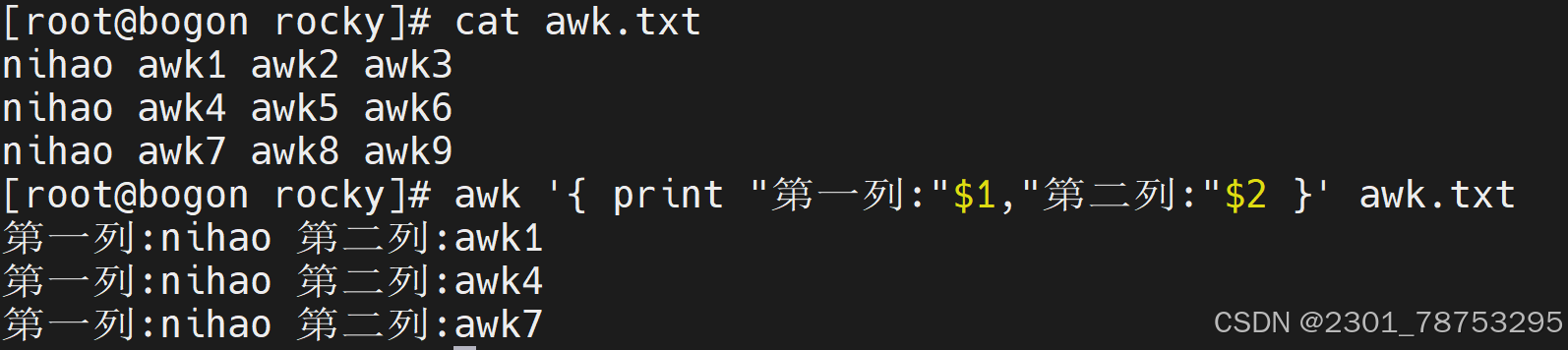


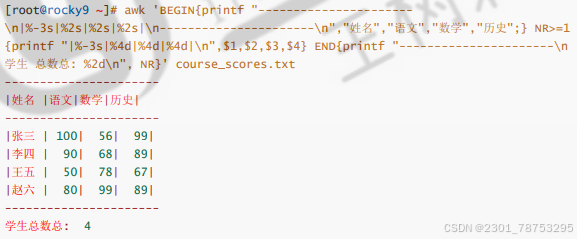
变量实践
内置变量
所谓的内置变量主要就是awk内部已经定制好的变量,我们可以直接拿过来使用,这些常见的方法我们基 本上都演示过了,比如:
FILENAME 当前输入文件的文件名,该变量是只读的
FIELDWIDTHS 以空格分隔的数字列表,用空格定义每个数据字段的精确宽度
NR 指定显示行的行号
FNR 多文件时候,分别计数
NF 表示字段数量
OFS 输出格式的列分隔符,缺省是空格
FS 输入文件的列分隔符,缺省是连续的空格和Tab
RS 输入记录分隔符,指定输入时的换行符,原换行符($)仍有效
ORS 输出记录分隔符,输出时用指定符号代替换行符
ARGC|ARGV[n] 获取命令的参数个数|参数内容
自定义变量
所谓的自定义变量,主要是根据实际情况,自己定义一些所谓的变量,然后再awk逻辑操作的过程中作为 辅助性的措施。自定义变量的定制方法:
-v var=value
它可以在 命令行、BEGIN、{}、END 等位置进行使用
整个awk选项就记住 NR NF OFS 这三个选项就可以其他的用不上



5.2.6正则表达式
通配符和正则
1 正则表达式用来在文件中匹配符合条件的字符串,主要是目的是包含匹配。
- grep、awk、sed 等命令可以支持正则表达式。
2 通配符用来匹配符合条件的文件名,通配符是完全匹配。
- ls、find、cp 之类命令不支持正则表达式,可以借助于shell通配符来进行匹配。
.:匹配任意一个字符
*:匹配任意内容
?:匹配任意一个内容
[]:匹配中括号中的一个字符



字符匹配
单字符匹配
. 匹配任意单个字符,当然包括汉字的匹配
[] 匹配指定范围内的任意单个字符
- 示例:[shuji]、[0-9]、[a-z]、[a-zA-Z]
[^] 匹配指定范围外的任意单个字符 - 示例:[^shuji]
| 匹配管道符左侧或者右侧的内容

锚定匹配
常见符号
^ 行首锚定, 用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^ PATTERN$ 用于模式匹配整行
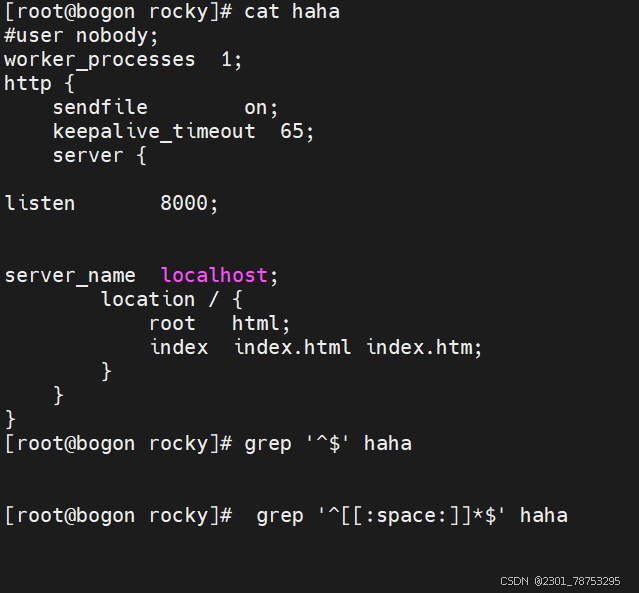
^$ 空行
^[[:space:]]*$ 空白行
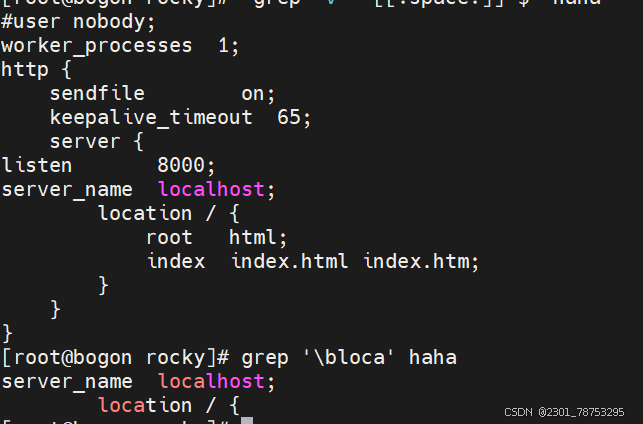
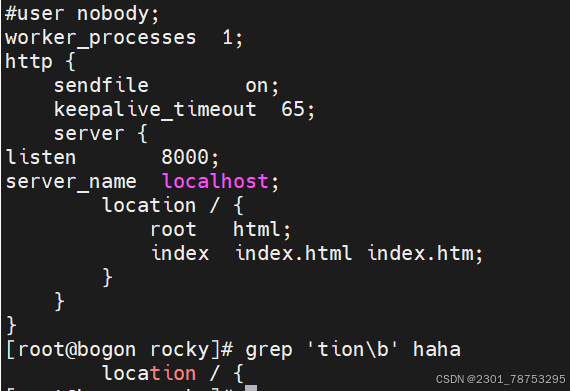
< 或 b 词首锚定,用于单词模式的左侧
> 或 b 词尾锚定,用于单词模式的右侧
<PATTERN> 匹配整个单词
- v 取反
注意:
单词是由字母,数字,下划线组成
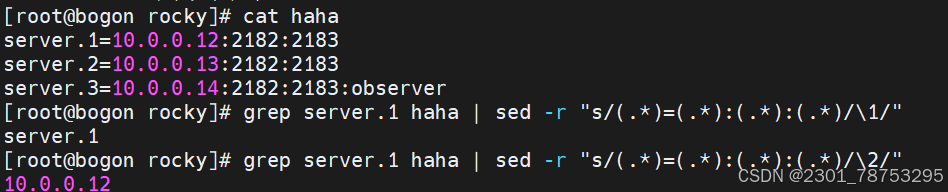
分组符号
所谓的分组,其实指的是将我们正则匹配到的内容放到一个()里面
- 每一个匹配的内容都会在一个独立的()范围中
- 按照匹配的先后顺序,为每个()划分编号
- 第一个()里的内容,用 1代替,第二个()里的内容,用2代替,依次类推
- 0 代表正则表达式匹配到的所有内容
注意:
() 范围中支持|等字符匹配内容。从而匹配更多范围的信息
关于()信息的分组提取依赖于文件的编辑工具,我们可以借助于 sed、awk功能来实现
提示: sed -r 's/原内容/修改后内容/'

限定符号
常见符号
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
? 匹配其前面的字符出现0次或1次,即:可有可无
+ 匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
{m} 匹配前面的字符m次
{m,n} 匹配前面的字符至少m次,至多n次
{,n} 匹配前面的字符至多n次,<=n
{n,} 匹配前面的字符至少n次
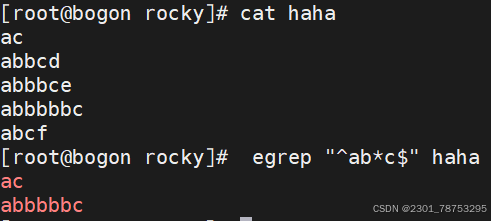
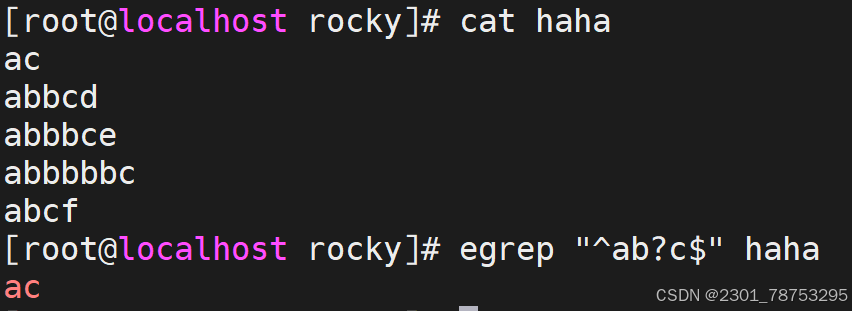
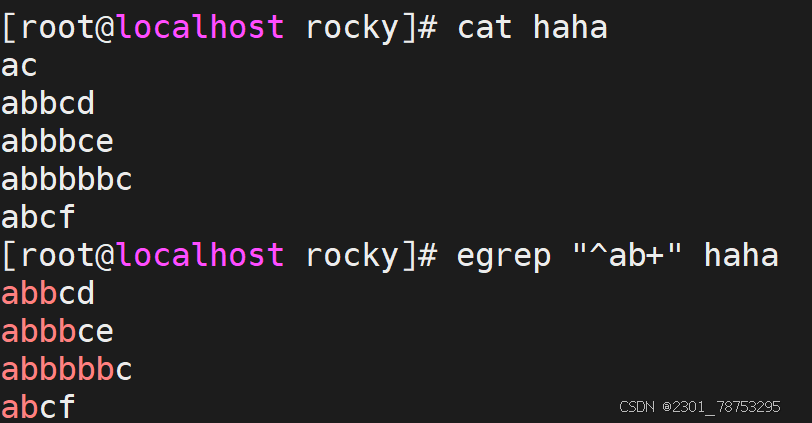
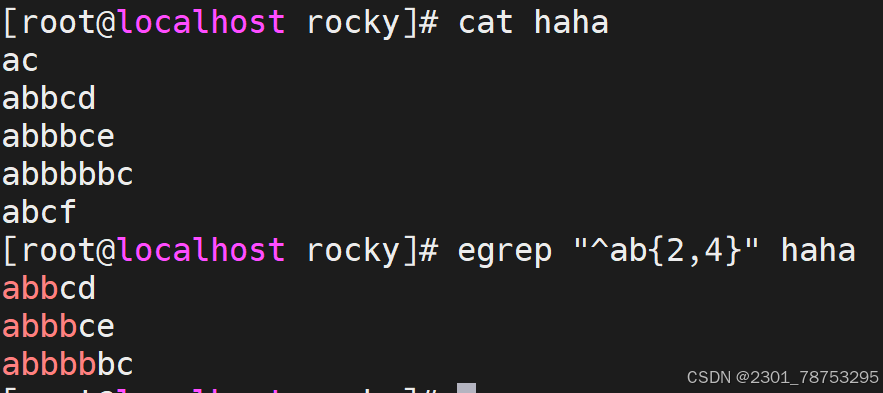
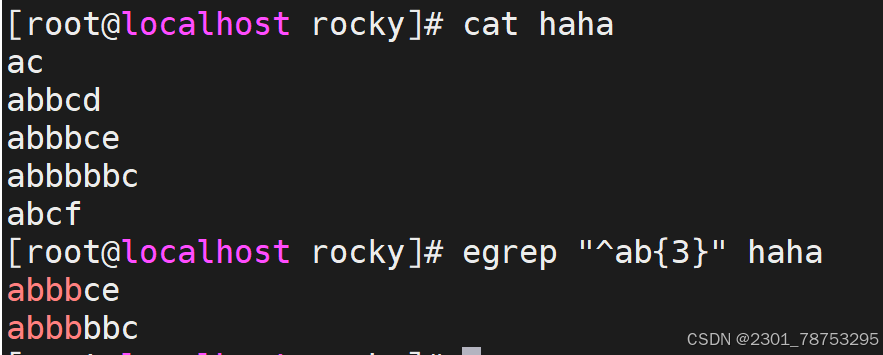
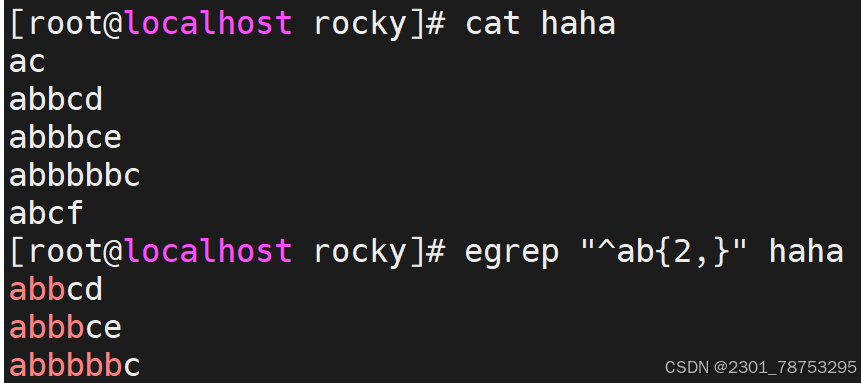
扩展符号
字母模式匹配
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
数字模式匹配
[:digit:] 十进制数字
[:xdigit:]十六进制数字
符号模式匹配
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:graph:] 可打印的非空白字符
[:print:] 可打印字符 [
:punct:] 标点符号
注意:
在使用该模式匹配的时候,一般用[[ ]],
- 第一个中括号是匹配符[] 匹配中括号中的任意一个字符
- 第二个[]是格式 如[:digit:]
就记这两个
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白
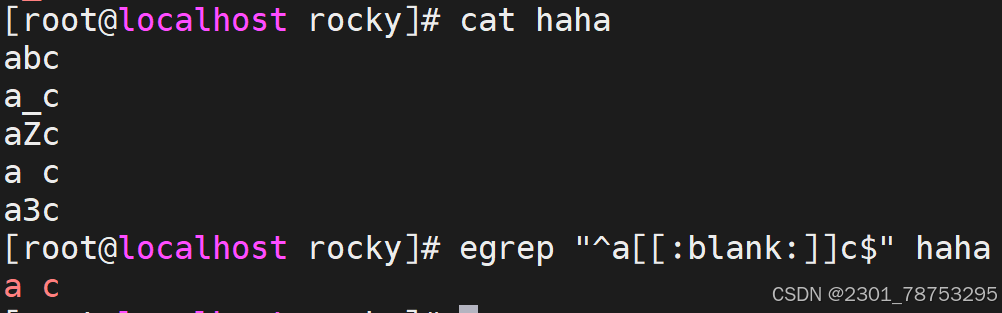
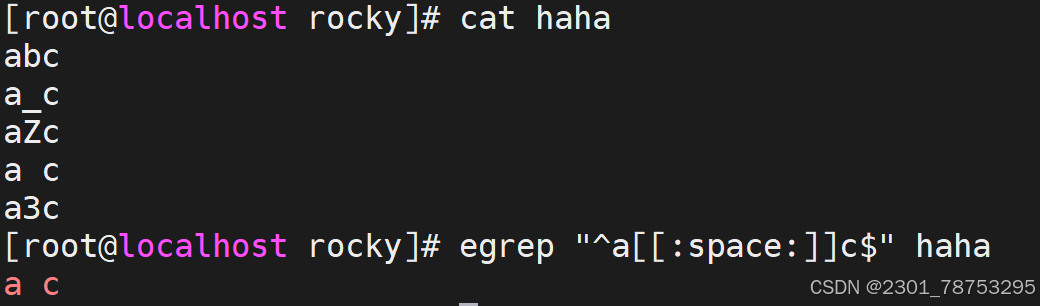
目标检测
定制站点或目标主机的检测平台,在对站点域名和主机ip检测之前,判断输入的语法是否正确。


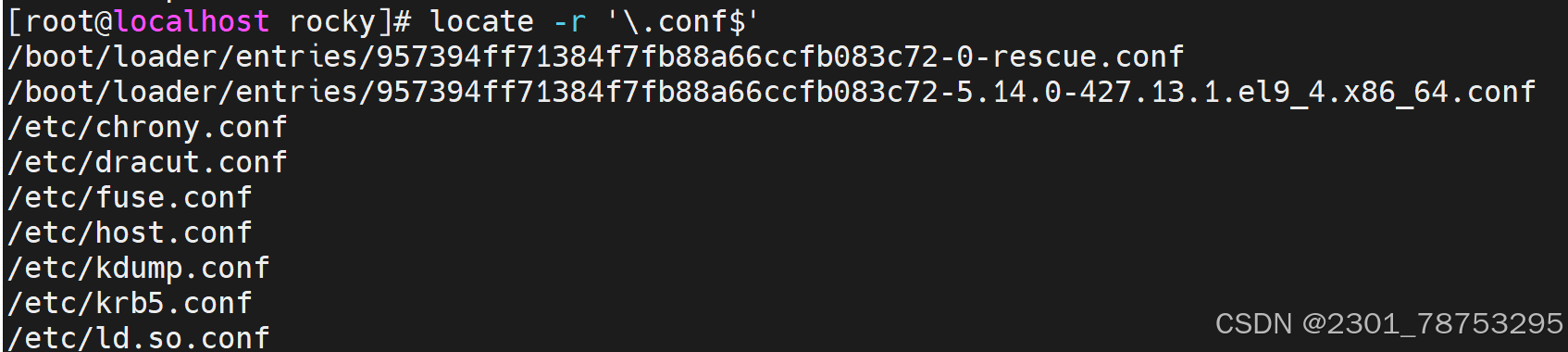
6.1.1 locate命令
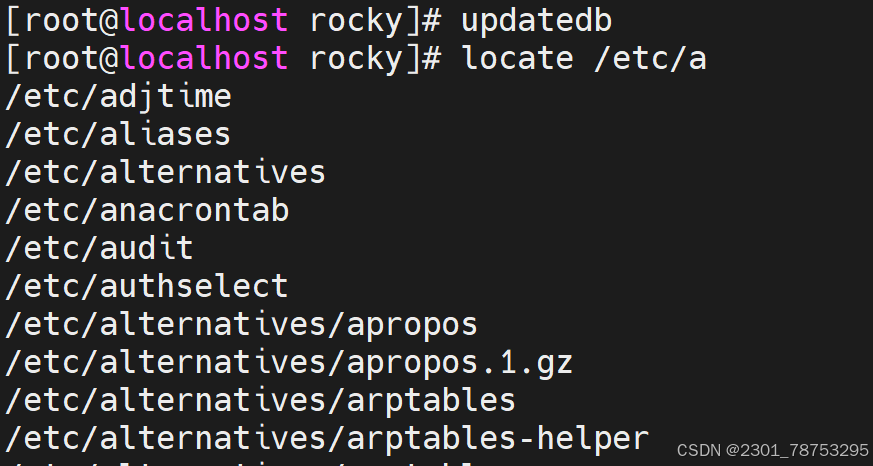
命令格式: locate [OPTIONS] PATTERN
一般选项
-i: 忽略大小写地匹配模式。例如,locate -i myfile会同时匹配"myfile"、"MyFile"等。
-c: 只显示匹配项的数量(count),而不是文件名。
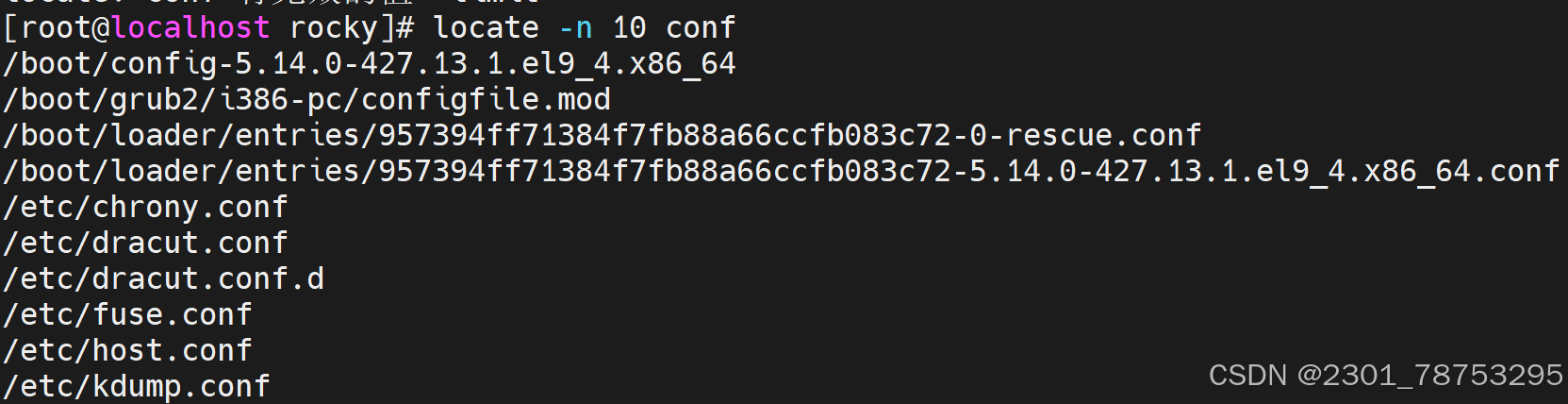
-l NUM: 限制输出的行数,每行显示一个匹配项。
-n NUM: 限制输出的匹配项数目,只显示前NUM个结果。
-r: 使用正则表达式模式匹配。例如,locate --regex '.*.txt$'会匹配所有以".txt"结尾的文 件。
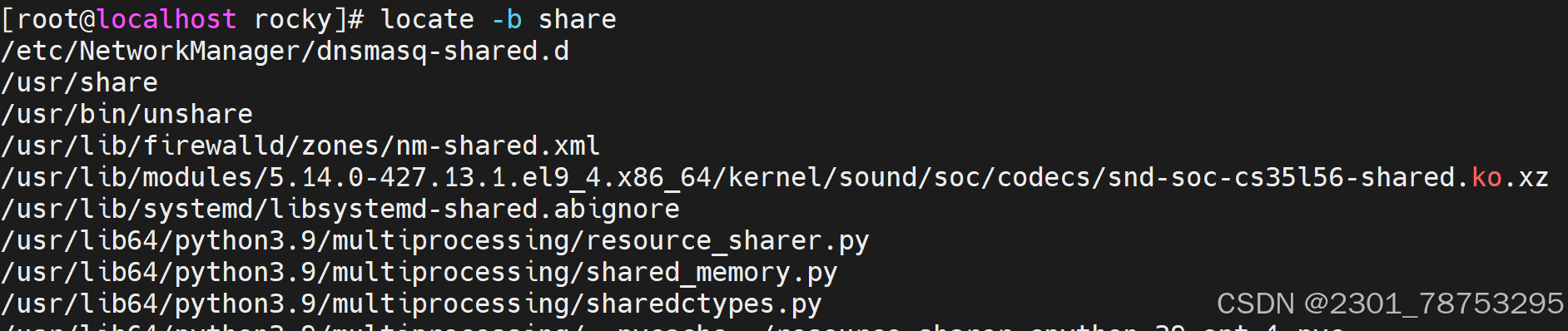
-b: 只匹配基准名,忽略路径。
-w: 仅匹配完整单词。
-A|--all #输出所有能匹配到的文件名,不管文件是否存在
-b|--basename #仅匹配文件名部份,而不匹配路径中的内容
-c|--count #只输出找到的数量
-d|--database DBPATH #指定数据库
-e|--existing #仅打印当前现有文件的条目
-L|--follow #遇到软链接时则跟随软链接去其对应的目标文件中查找 (默认)
-i|--ignore-case #忽略大小写 -l|--limit|-n N #只显示前N条匹配数据
-P|--nofollow, -H #不跟随软链
-r|--regexp REGEXP #使用基本正则表达式
--regex #使用扩展正则表达式
-s|--stdio #忽略向后兼容
-w|--wholename #全路径匹配,就是只要在路径里面出现关键字(默认)
updatedb 更新数据库
安装环境
Rocky系统 yum install -y mlocate
ubuntu系统 apt install -y Plocate
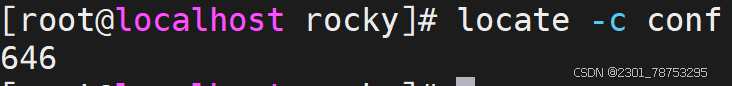
6.1.2 find命令
使用方法; find [搜索路径] [选项] [表达式]
常用选项
-name:按文件名匹配,区分大小写。支持使用glob,如:*, ?, [], [^],通配符要加双引号引起来
-type:按文件类型搜索。常用类型包括f(普通文件)、d(目录)、l(符号链接)等。
-size:按文件大小搜索。单位可以是c(字节)、k(千字节)、M(兆字节)、G(千兆字节)等。例 如,-size +10M查找大于10MB的文件。
-mtime:按天数查找文件最后修改时间。例如,-mtime -7查找最近7天内修改的文件
-user:按文件所有者查找。
-group:按文件所属组查找。
-perm:按文件权限查找。
-maxdepth:限制搜索的最大深度。
-mindepth:限制搜索的最小深度。
-regextype type: 正则表达式类型,emacs|posix-awk|posix-basic|posiegrep|posixextended
-regex pattern: 正则表达式


类型查找
-empty #空文件或空目录
-prune #跳过,排除指定目录,必须配合 -path使用 -path路径
-type TYPE #指定文件类型 *
type 值
f #普通文件
d #目录文件
l #符号链接文件
s #套接字文件
b #块设备文件
c #字符设备文件
p #管道文件




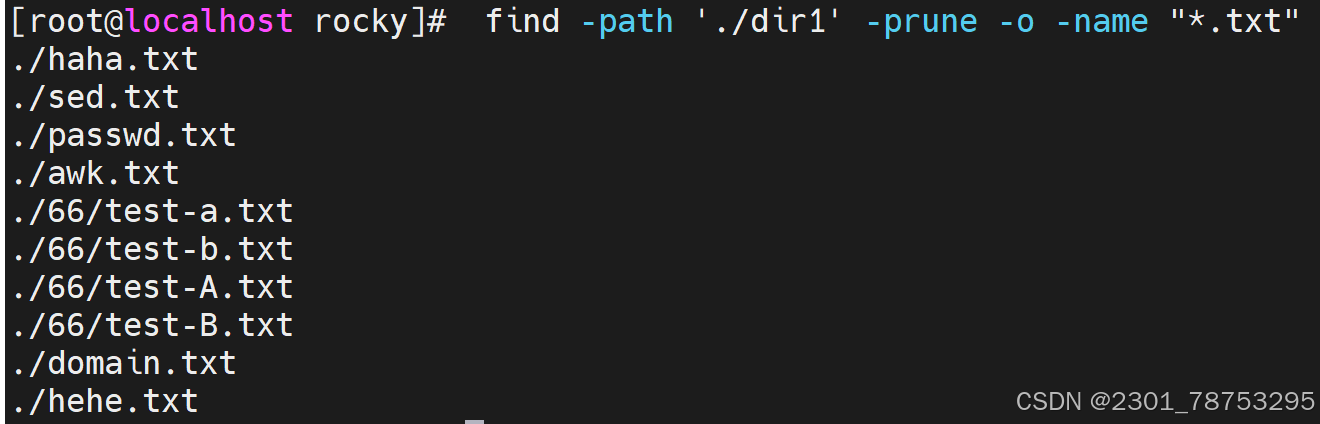
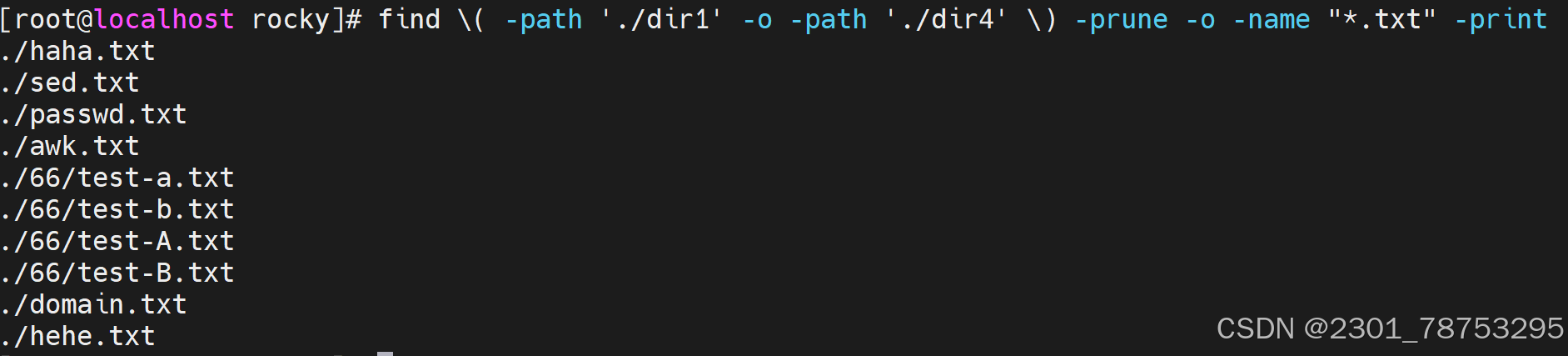
组合查找
-a #与,多条件默认就是与关系,可省略
-o #或
-not|! #非

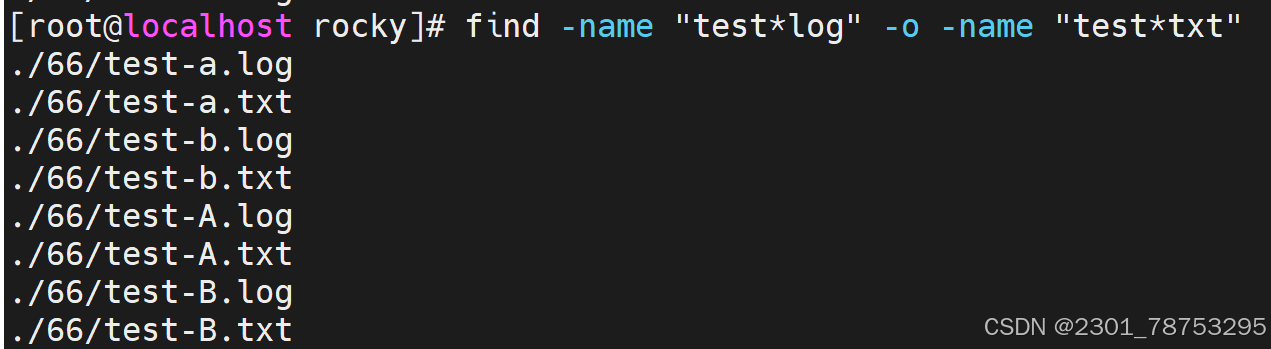
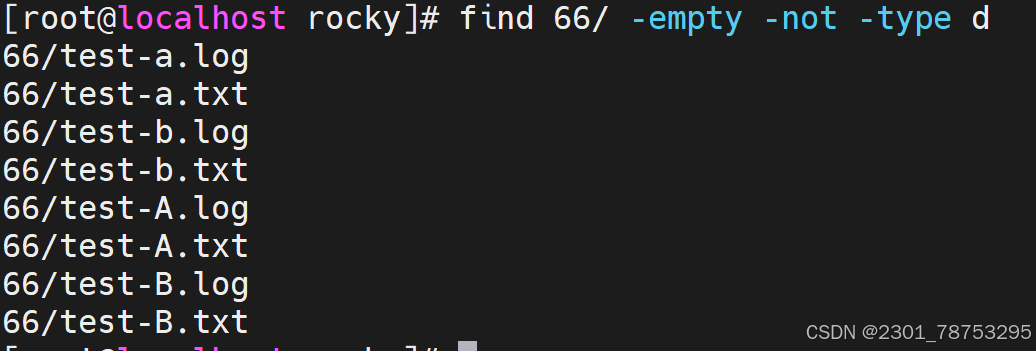
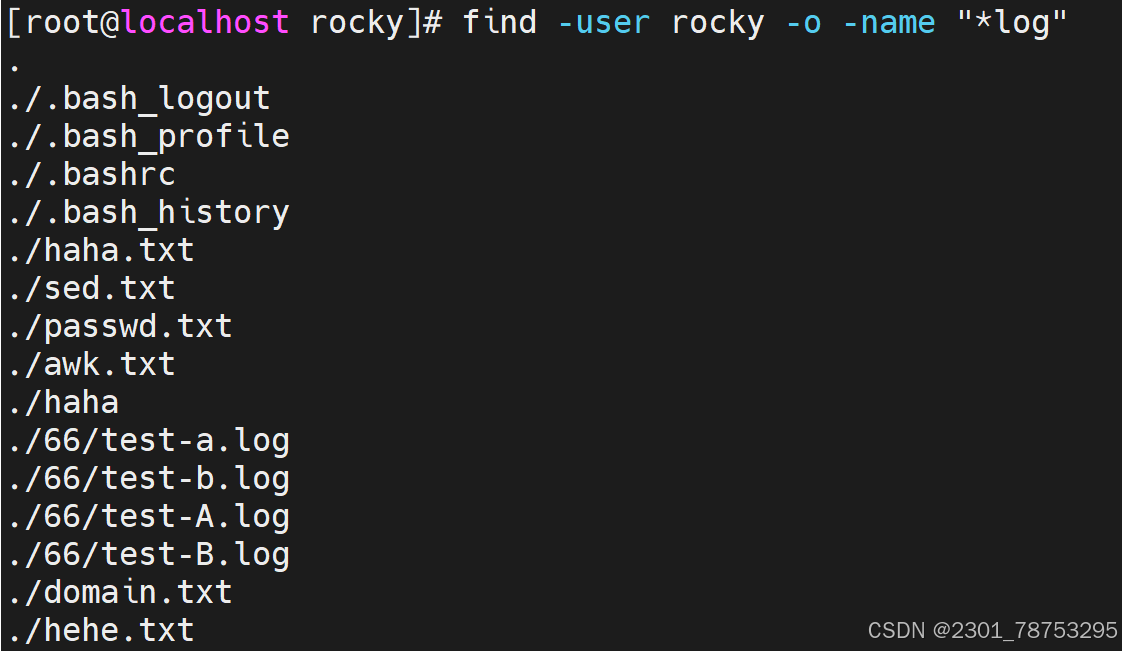

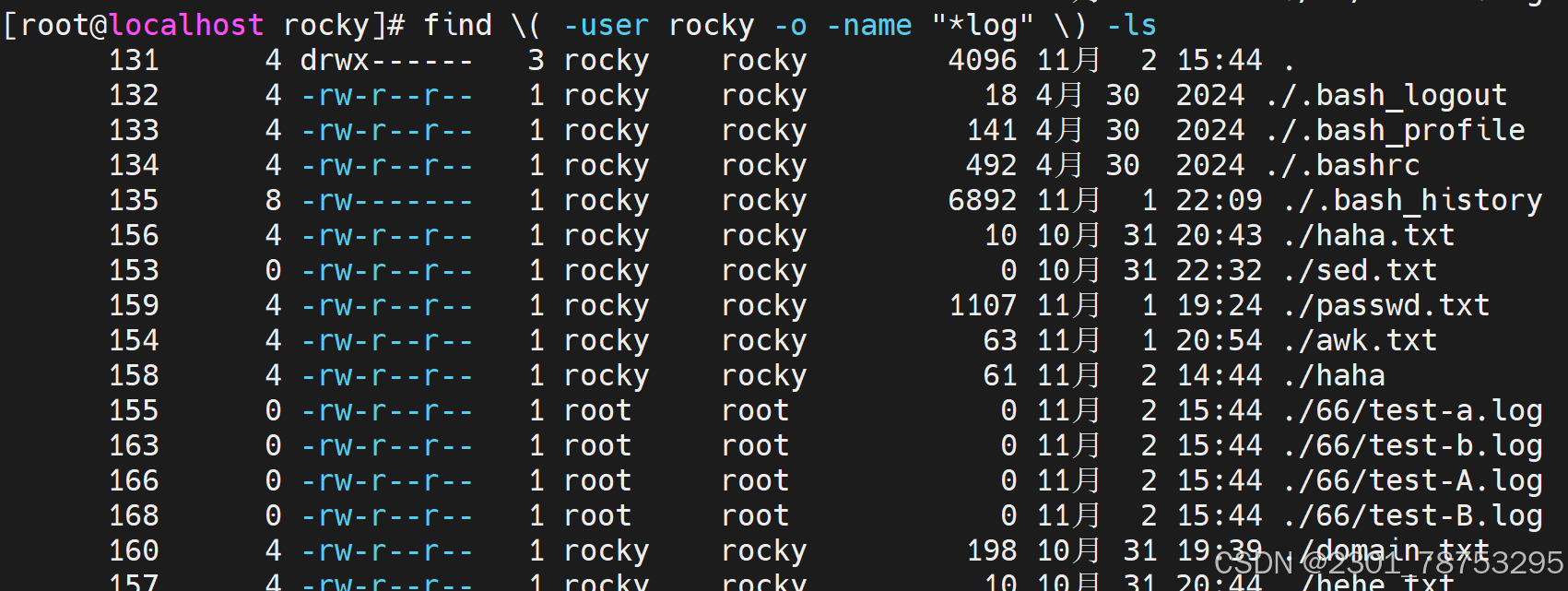
文件属性查找
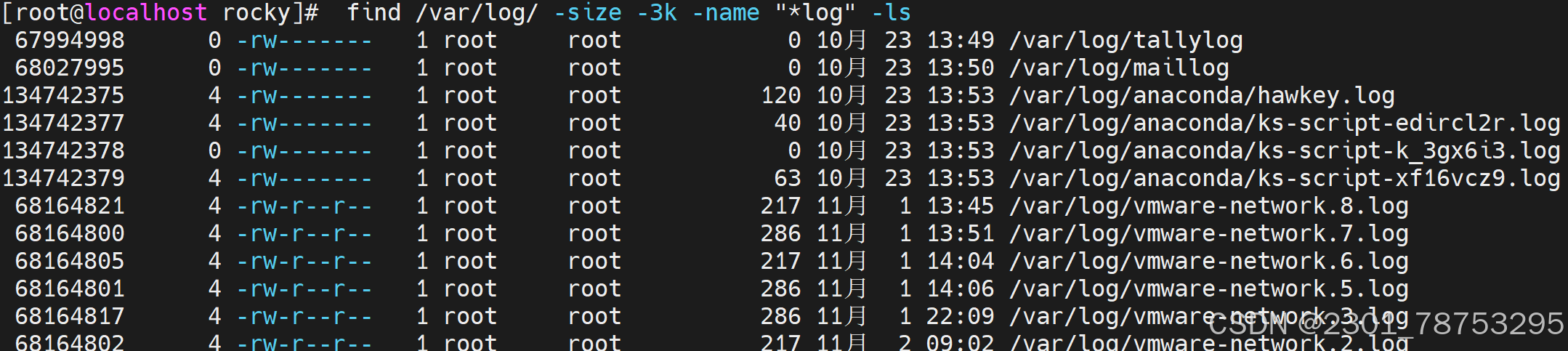
-size [+|-]N UNIT # N为数字,UNIT为常用单位 k, M, G, c(byte) 等
#解释
10k #表示(9k,10k],大于9k 且小于或等于10k
-10k #表示[0k,9k],大于等于0k 且小于或等于9k
+10k #表示(10k,∞),大于10k
文件时间属性解读
以天为单位
-atime [+|-]N -mtime [+|-]N -ctime [+|-]N
以分钟为单位
-amin [+|-]N -mmin [+|-]N -cmin [+|-]N
#解释
N #表示[N,N+1),大于或等于N,小于N+1,表示第N天(分钟)
+N #表示[N+1,∞],大于或等于N+1,表示N+1天之前(包括)
-N #表示[0,N),大于或等于0,小于N,表示N天(分钟)内

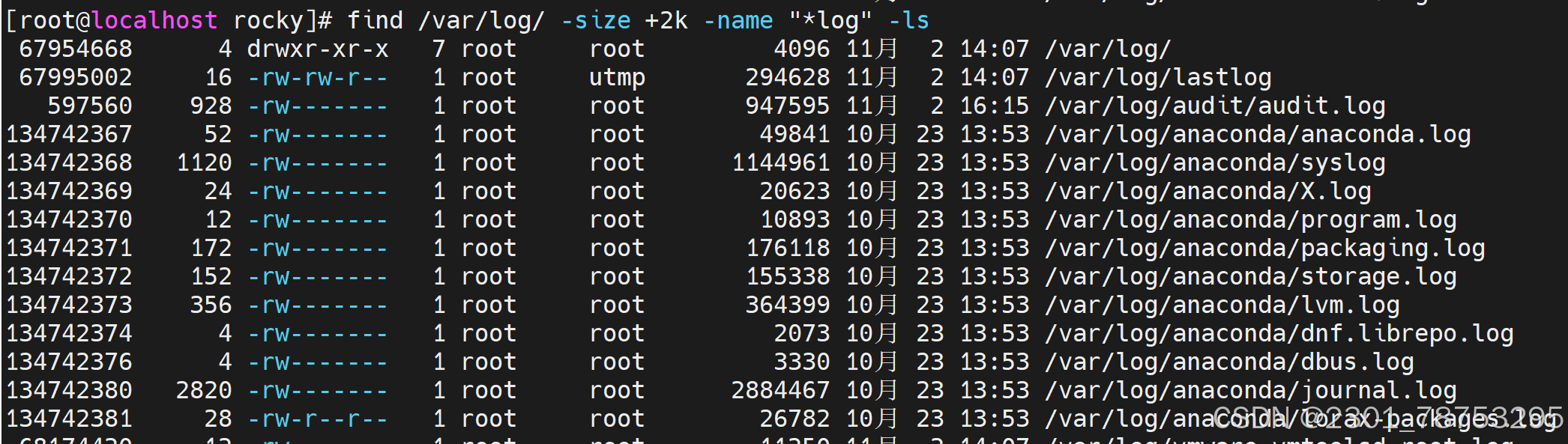


动作进阶
-print #默认的处理动作,显示至屏幕
-print0 #不换行输出,常用于配合xargs
-ls #类似于对查找到的文件执行"ls -ils"命令格式输出
-fls file #查找到的所有文件的长格式信息保存至指定文件中,相当于 -ls > file
-delete #删除查找到的文件,慎用!
-ok COMMAND {} ; #对查找到的每个文件执行由COMMAND指定的命令,对于每个文件执行命令之 前,都会交互式要求用户确认
-exec COMMAND {} ; #对查找到的每个文件执行由COMMAND指定的命令
{} #用于引用查找到的文件名称自身




6.1.3 xargs组合
使用方法 xargs 选项 文件
#常用选项
-0|--null #用 assic 中的0或 null 作分隔符
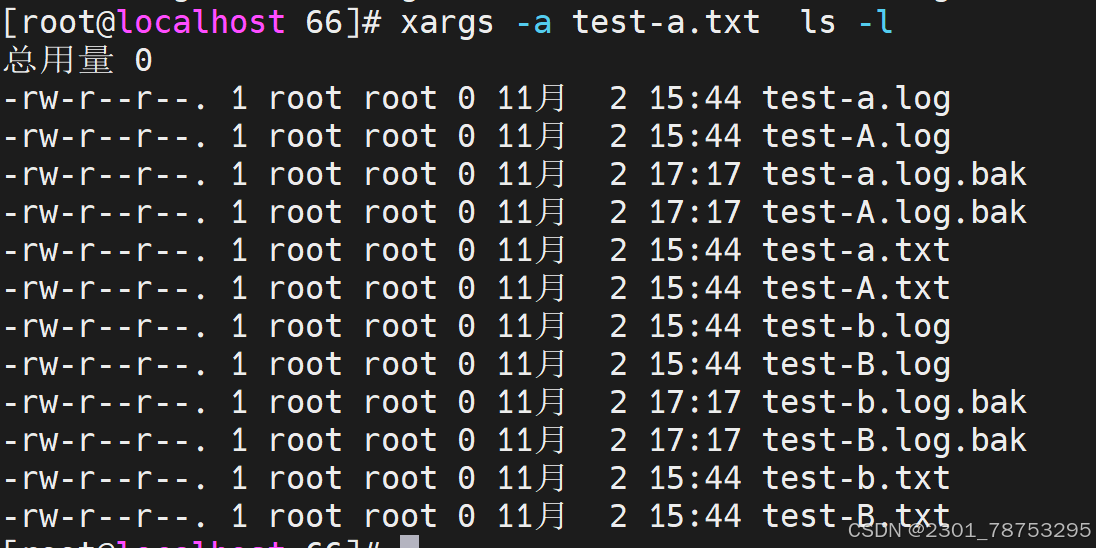
-a|--arg-file=FILE #从文件中读入作为输入
-d|--delimiter=CHARACTER #指定分隔符
-E END #指定结束符,执行到此处时停止,不管后面的数据
-L|--max-lines=N #从标准输入一次读取N行送给 command 命令
-l #同上
-n|--max-args=MAX-ARGS #一次执行用几个参数
-p|--interactive #每次执行前确认
-r|--no-run-if-empty #当xargs的输入为空的时候则停止xargs,不用再去执行了
-s|--max-chars=MAX-CHARS #命令行最大字符数
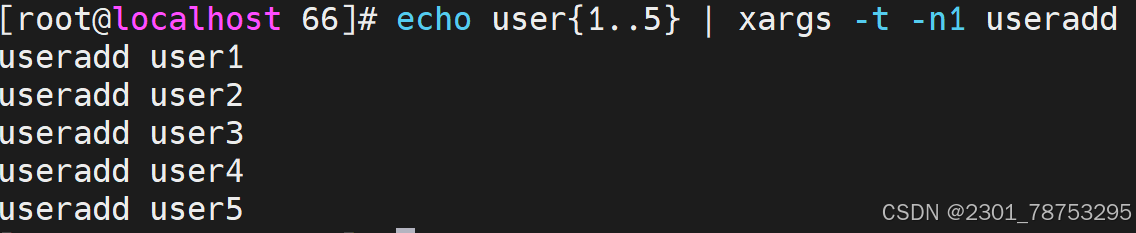
-t|--verbose #显示过程,先打印要执行的命令
-x|--exit #退出,主要配合-s使用

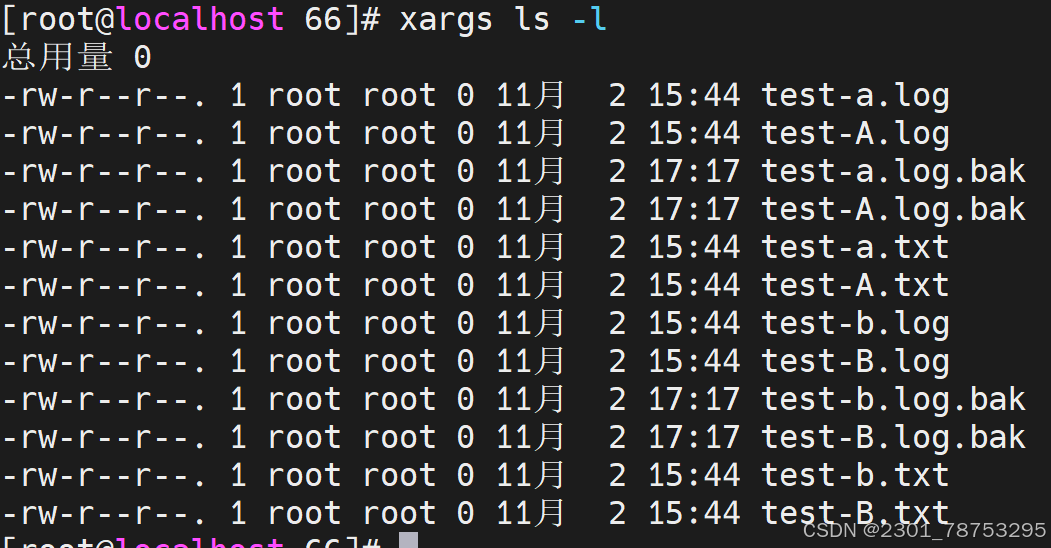
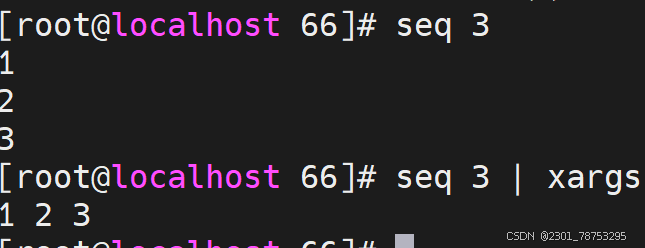




6.1.4打包压缩
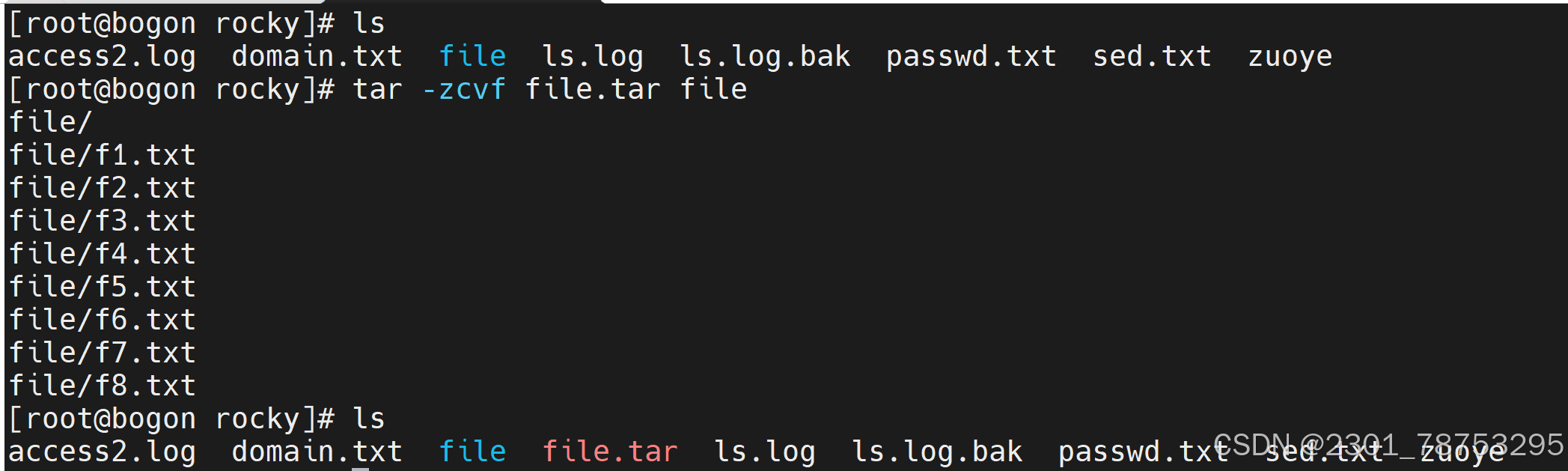
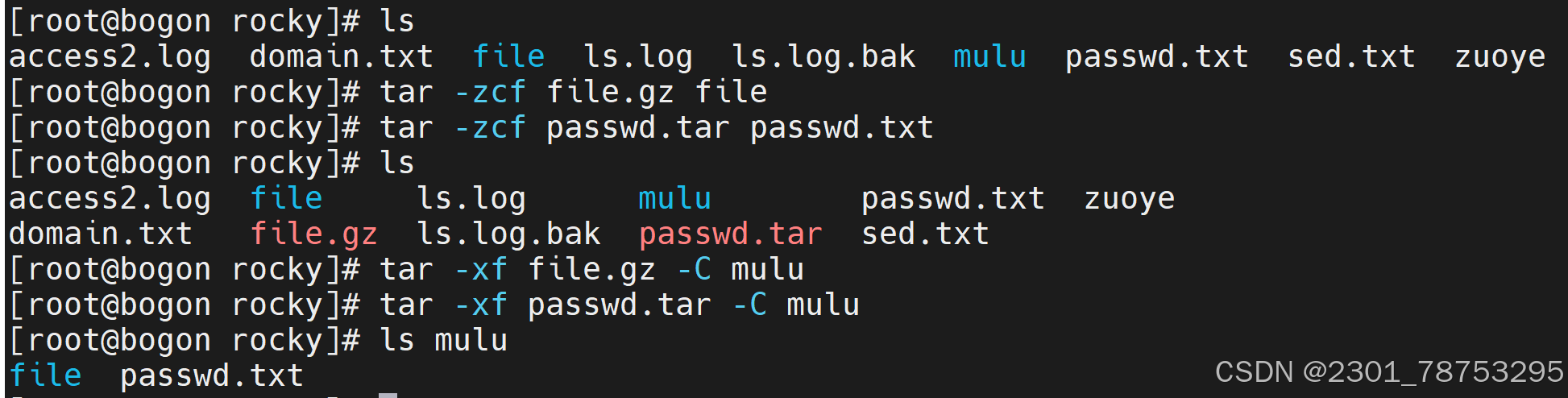
tar包
使用方法 tar 选项 (包类型.tar) 目标文件
tar命令常见选项:
- c 创建一个压缩包
- t 不解压查看压缩包的文件列表
- z tar.gz类型格式的压缩包
- v 显示压缩过程|解压过程
- x 解压一个压缩文件
- f 指定压缩包文件名
解压场景有专属选项 -C 我要解压到那个目录下
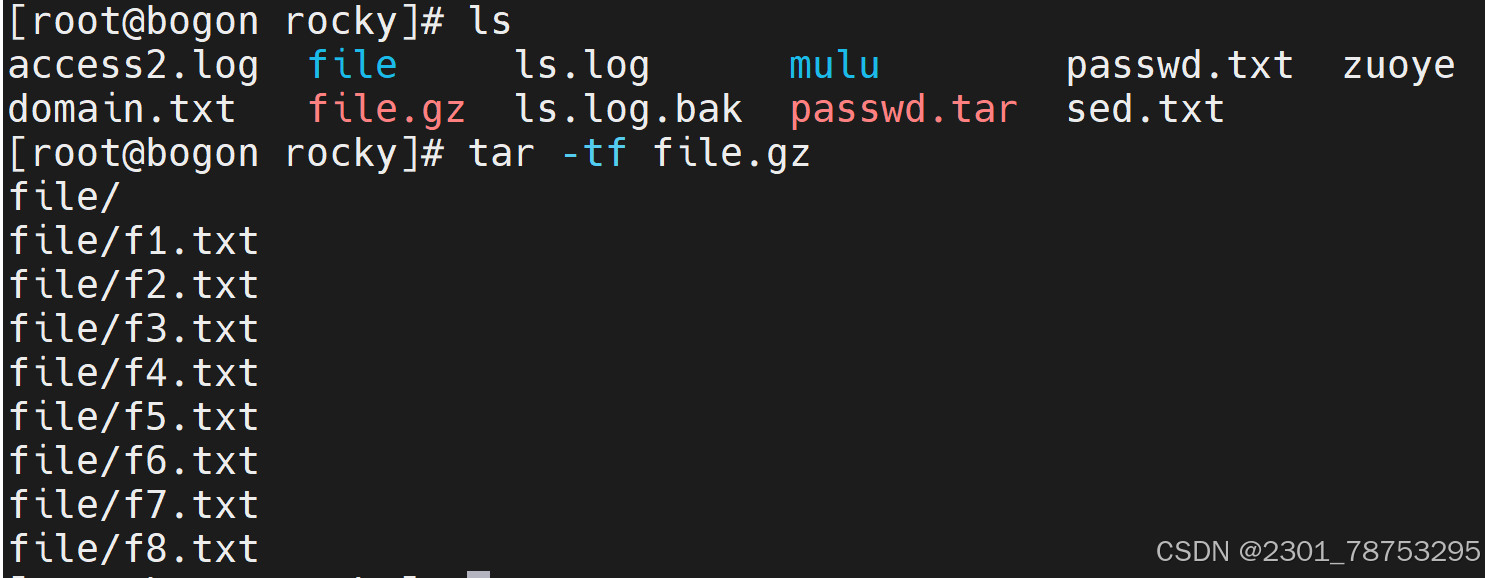
tar -tf 压缩为文件名 在不解压的情况下查看文件目录


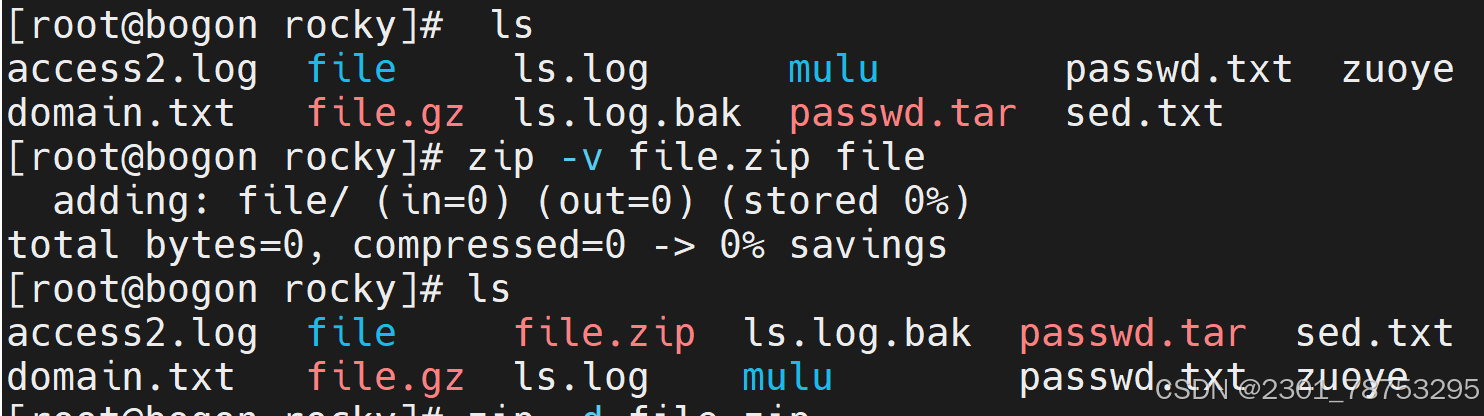
zip包
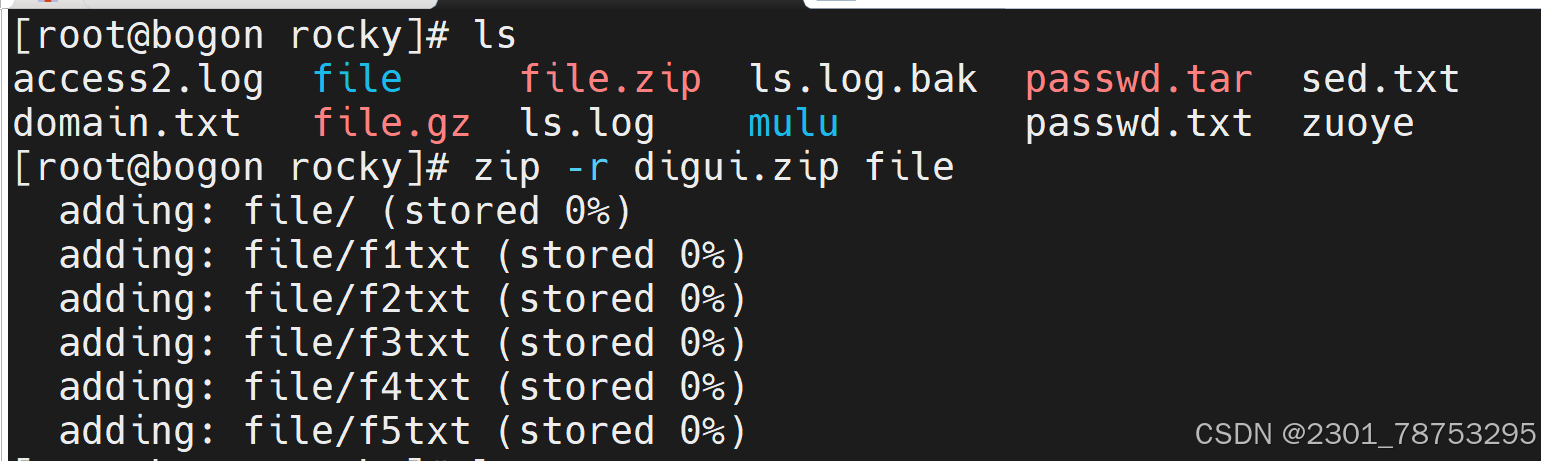
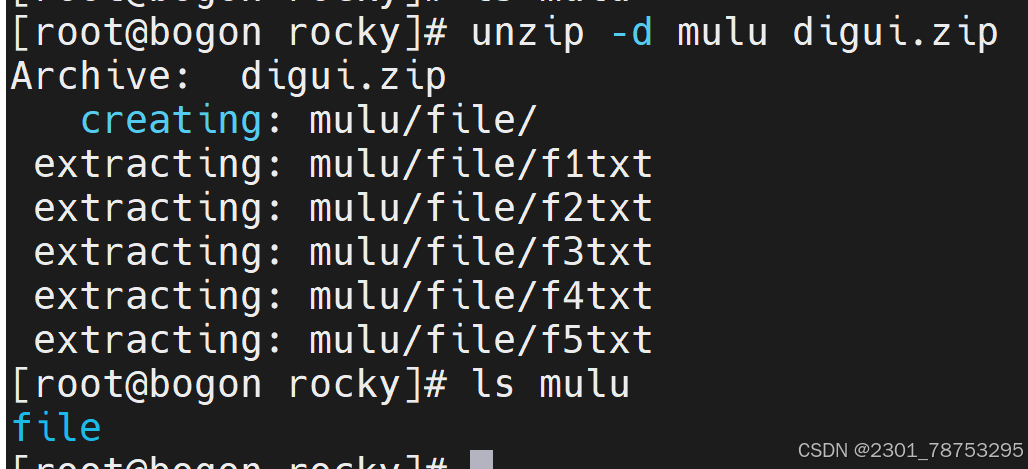
使用方法:zip 选项 (指定名字。zip) 要压缩的文件名
选项:
-d 指定解压到哪里
-v 压缩文件
-r 递归压缩
unzip 解压文件
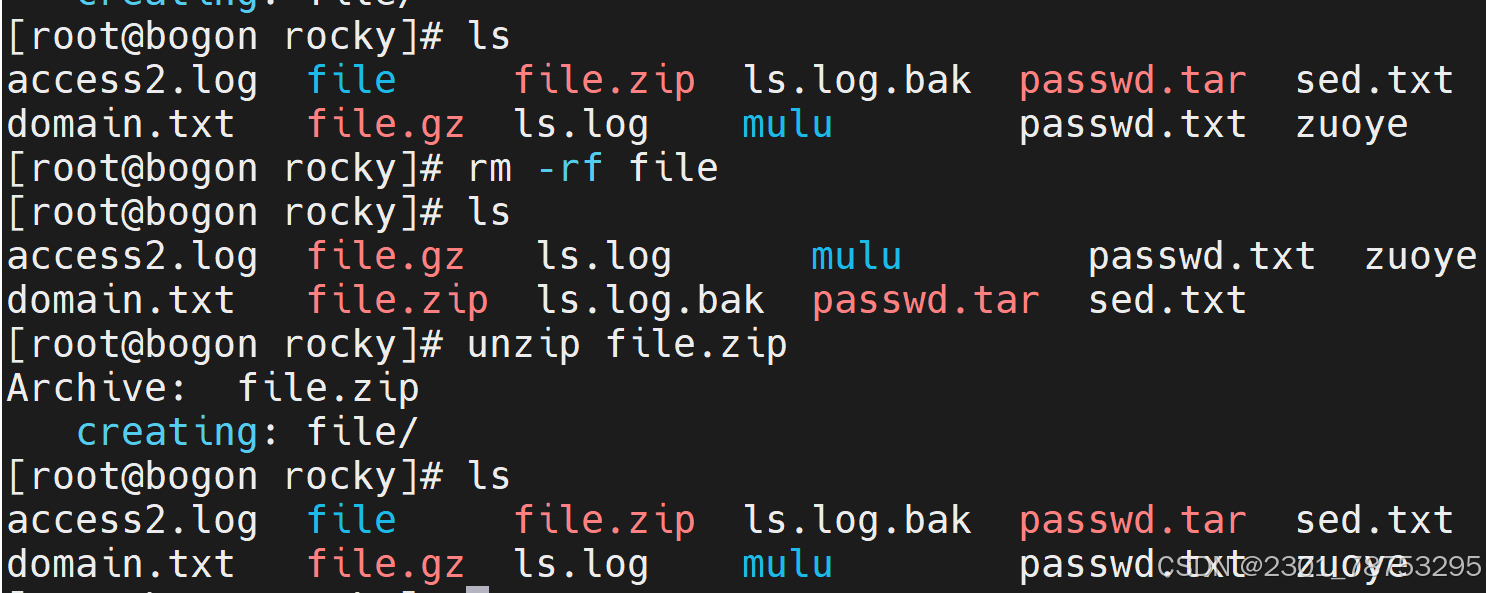
zcat查看压缩内容
使用方法 zcat 选项 要查看的压缩文件
选项:
- l 查看压缩包的基本情况
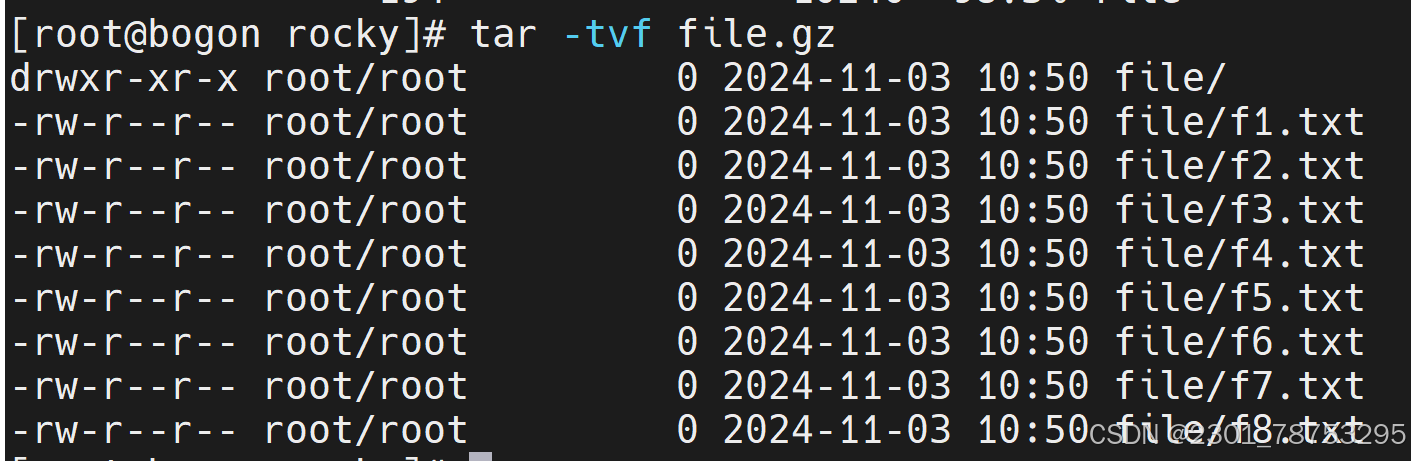
tar -tvf 查看压缩文件详情

6.2shell基础
6.2.1 脚本执行
方法1:
bash /path/to/script-name 或 /bin/bash /path/to/script-name (强烈推荐使 用)
方法2:
/path/to/script-name 或 https://blog.csdn.net/2301_/article/details/script-name (当前路径下执行脚本)
方法3:
source script-name 或 . script-name (注意“.“点号)
方法1变种:
cat /path/to/script-name | bash
bash /path/to/script-name
方法1:
[root@rocky9 ~]# /bin/bash get_netinfo.sh
IP: 10.0.0.12
NetMask: 255.255.255.0
Broadcast: 10.0.0.255
MAC Address: 00:0c:29:23:23:8c
方法2:
[root@rocky9 ~]# https://blog.csdn.net/2301_/article/details/get_netinfo.sh
bash: https://blog.csdn.net/2301_/article/details/get_netinfo.sh: 权限不够
[root@rocky9 ~]# ll get_netinfo.sh
-rw-r--r-- 1 root root 521 6月 7 20:41 get_netinfo.sh
[root@rocky9 ~]# chmod +x get_netinfo.sh
[root@rocky9 ~]# https://blog.csdn.net/2301_/article/details/get_netinfo.sh
IP: 10.0.0.12
NetMask: 255.255.255.0
Broadcast: 10.0.0.255
MAC Address: 00:0c:29:23:23:8c
方法3:
[root@rocky9 ~]# source get_netinfo.sh
IP: 10.0.0.12
NetMask: 255.255.255.0
Broadcast: 10.0.0.255
MAC Address: 00:0c:29:23:23:8c
[root@rocky9 ~]# chmod -x get_netinfo.sh
[root@rocky9 ~]# ll get_netinfo.sh
-rw-r--r-- 1 root root 521 6月 7 20:41 get_netinfo.sh
[root@rocky9 ~]# source get_netinfo.sh
IP: 10.0.0.12
NetMask: 255.255.255.0
Broadcast: 10.0.0.255
MAC Address: 00:0c:29:23:23:8c
6.2.2 脚本调试
使用方法 /bin/bash 选项 要执行的文件
-n 检查脚本中的语法错误
-v 先显示脚本所有内容,然后执行脚本,结果输出,如果执行遇到错误,将错误输出。
-x 将执行的每一条命令和执行结果都打印出来
记住x就好
[root@rocky9 ~]# /bin/bash -x get_netinfo-error.sh
+ :
+ ifconfig eth0 + awk '{print $2}'
+ grep -w inet
+ xargs echo 'IP: ' IP: 10.0.0.12
+ ifconfig eth0
+ grep -w inet
+ awk '{print $4}'
+ xargs echo 'NetMask: ' NetMask: 255.255.255.0
+ ifconfig eth0
+ grep -w inet
+ xargs echo 'Broadcast: '
+ awk '{print $6}' Broadcast: 10.0.0.25
6.2.3脚本开发规范
1、脚本命名要有意义,文件后缀是.sh
2、脚本文件首行是而且必须是脚本解释器 #!/bin/bash
3、脚本文件解释器后面要有脚本的基本信息等内容 脚本文件中尽量不用中文注释; 尽量用英文注释,防止本机或切换系统环境后中文乱码的困扰 常见的注释信息:脚本名称、脚本功能描述、脚本版本、脚本作者、联系方式等
4、脚本文件常见执行方式:bash 脚本名
5、脚本内容执行:从上到下,依次执行
6、代码书写优秀习惯;
1)成对内容的一次性写出来,防止遗漏。
如:()、{}、[]、''、``、""
2)[]中括号两端要有空格,书写时即可留出空格[ ],然后再退格书写内容。
3)流程控制语句一次性书写完,再添加内容
7、通过缩进让代码易读;(即该有空格的地方就要有空格)
shell脚本开发规范重点 2,4, 5
shell开发小技巧 3,6,7
6.2.4 shell 变量
变量场景: 用过变量名,快速获取对应的值
变量定义: 变量名=变量值
基本操作:
1,创建变量
2,查看变量:$变量名 "$变量名" ${变量名} "${变量名}" 标红这两个最标准 脚本里的环境变量最好使用最后这两个标红的
删除变量: unset 变量名
变量分类
shell 中的变量分为三大类:
本地变量 变量名仅仅在当前终端有效 自定义变量
全局变量 变量名在当前操作系统的所有终端都有效 系统级变量
shell内置变量 shell解析器内部的一些功能参数变量 man bash 自己创建了一些变量,我们可以直接拿过来用
定义全局变量
全局变量是什么
全局变量就是:在当前系统的所有环境下都能生效的变量
定义全局变量:
export 变量名=变量值
查看全局变量
echo $变量名
删除变量名
unset 变量名
嵌套shell
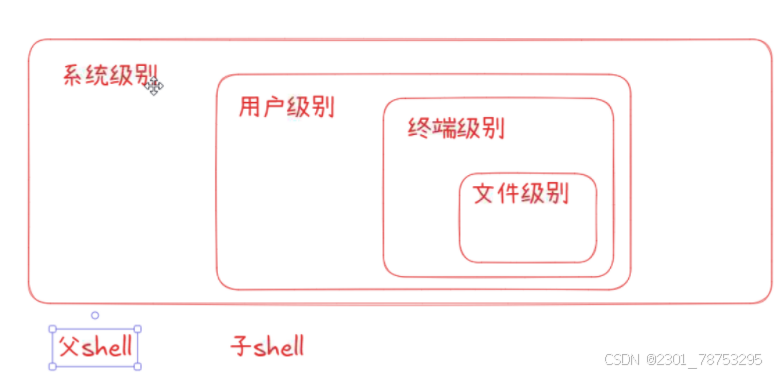
父shell可以给子用 子shell只能自己用
脚本相关
$0 脚本文件名 $1第一个参数 $#所有参数的总数

字符串相关
字符串计数
${#file} 获取字符串的长度
字符串截取
- 语法为${var:pos:length} 表示对变量var从pos开始截取length个字符,pos为空标示0 ${file:0:5} 从0开始,截取5个字符
${file:5:5} 从5开始,截取5个字符
${file::5} 从0开始,截取5个字符
${file:0-6:3} 从倒数第6个字符开始,截取之后的3个字符
${file: -4} 返回字符串最后四个字节,-前面是"空格"

默认值相关
格式一:${变量名:-默认值}
变量a如果有内容,那么就输出a的变量值
变量a如果没有内容,那么就输出默认的内容
格式二:${变量名+默认值}
无论变量a是否有内容,都输出默认值
实践1 - 有条件的默认值
购买手机的时候选择套餐:
如果我输入的参数为空,那么输出内容是 "您选择的套餐是: 套餐 1"
如果我输入的参数为n,那么输出内容是 "您选择的套餐是: 套餐 n"
子shell基础
临时shell
临时shell环境 - 启动子shell
(命令列表),在子shell中执行命令列表,退出子shell后,不影响后续环境操作。 临时shell环境 - 不启动子shell {命令列表}, 在当前shell中运行命令列表,会影响当前shell环境的后续操作。
7.1运算符
7.1.1运算符基础
表达式
语法格式
格式
真实值 操作符 真实值 比较运算符 预期值
示例
3 + 4 > 6
要点:
表达式应该具有判断的功能
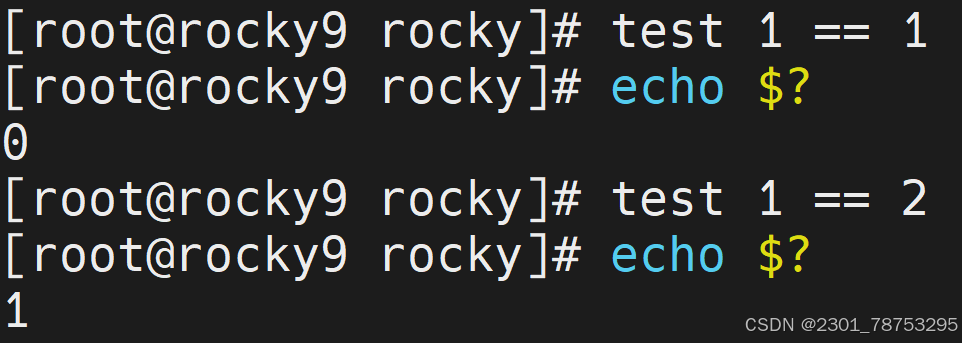
样式1:
test 条件表达式
样式2: [ 条件表达式 ]
注意:
以上两种方法的作用完全一样,后者为常用。
但后者需要注意方括号[、]与条件表达式之间至少有一个空格。
test跟 [] 的意思一样
条件成立,状态返回值是0
条件不成立,状态返回值是
test -v 语法测试变量有没有被设置值,亦可理解为变量是否为空。
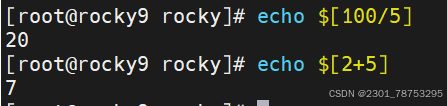
7.1.1简单计算
简介:
$[]方法,常用于整数计算场景,适合不太复杂的计算,运算结果是小数的也会自动取整。 后面的几种也是一样
格式
方法1:
$[计算表达式]
方法2:
a=$[变量名a+1]
注意:
这里的表达式可以不是一个整体

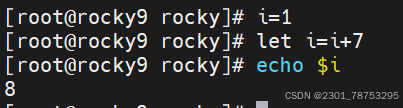
let 简介
简介
let是另外一种相对来说比较简单的数学运算符号了
格式
let 变量名a=变量名a+1
注意:
表达式必须是一个整体,中间不能出现空格等特殊字符
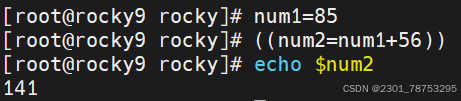
简介
(())的操作与let基本一致,相当于let替换成了 (())
格式
(())简介
简介
(())的操作与let基本一致,相当于let替换成了 (())
格式
((变量计算表达式))
注意:
对于 $(())中间的表达式,可以不是一个整体,不受空格的限制
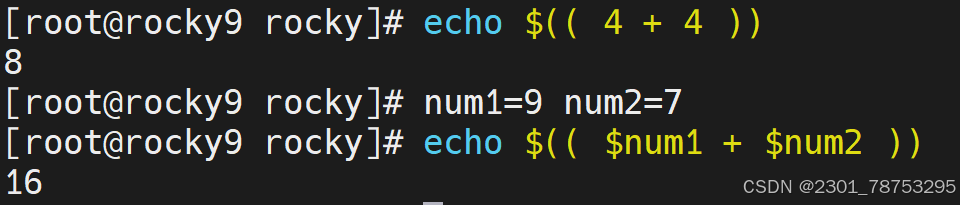
$(()) 简介
简介
$(())的操作,相当于 (()) + echo $变量名 的组合
格式
echo $((变量计算表达式))
注意:
对于 $(())中间的表达式,可以不是一个整体,不受空格的限制

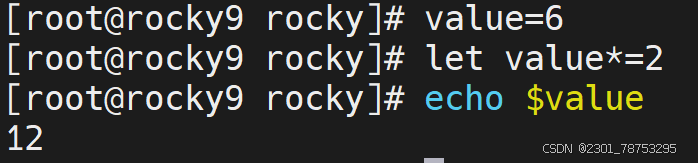
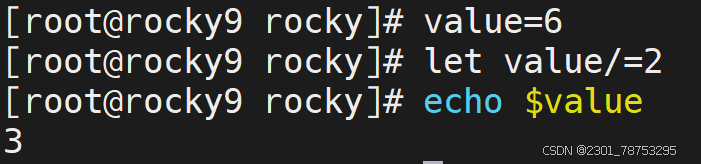
7.1.2 赋值运算进阶
二元运算
简介
所谓的二元运算,指的是 多个数字进行+-*/%等运算
加减乘除格式都一样
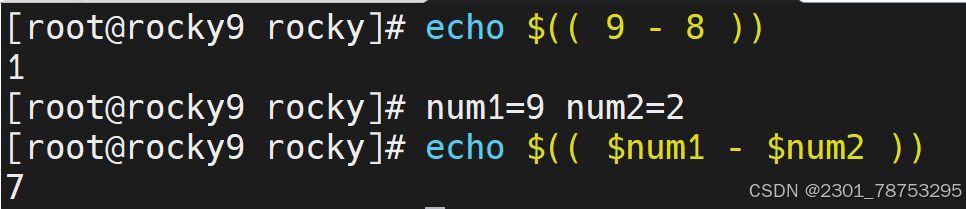
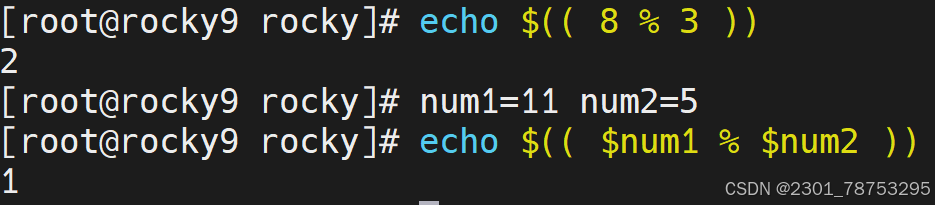
赋值运算
这里的赋值运算,是一种进阶版本的复制操作,常见的样式如下:
样式1:+=、-=、*=、/=
- 在自身的基础上进行二元运算,结果值还是自己
样式2:++、--
- 在自身的基础上进行递增和递减操作,结果值还是自己
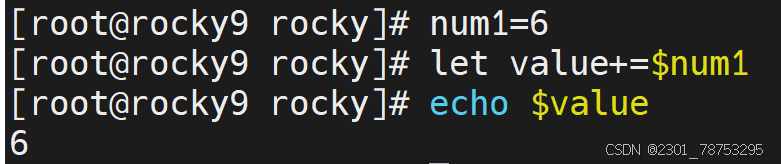
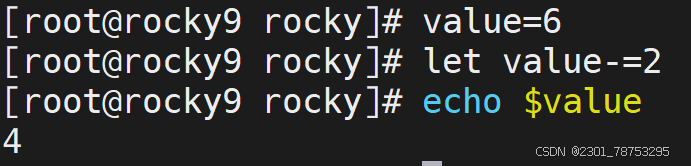
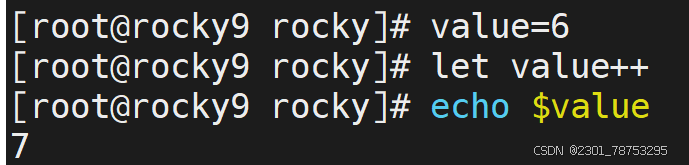
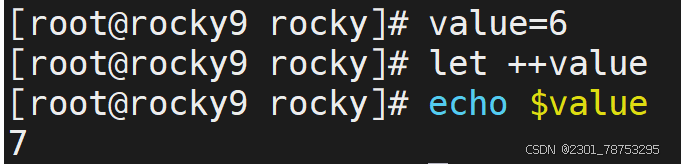
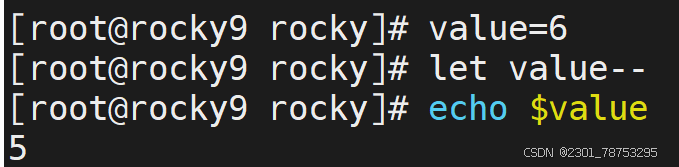
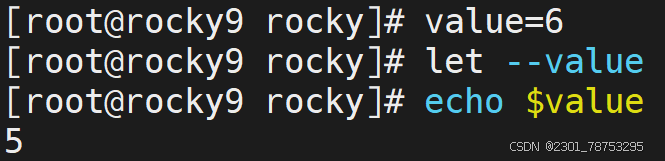
7.1.3 基础知识
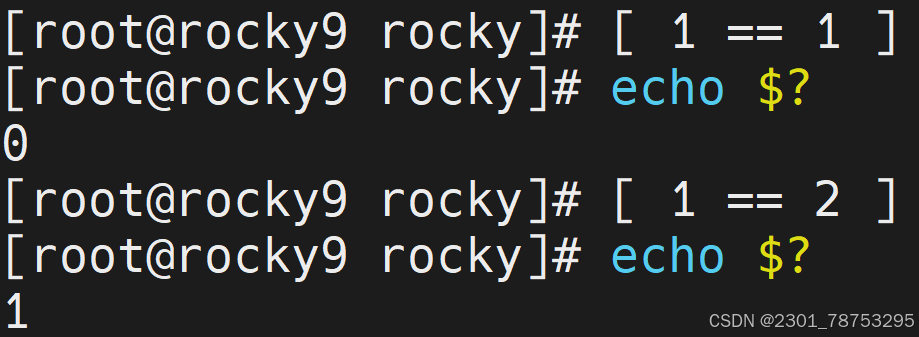
表达式
语法格式
格式
真实值 操作符 真实值 比较运算符 预期值
示例
3 + 4 > 6
要点:
表达式应该具有判断的功能
样式1:
test 条件表达式
样式2: [ 条件表达式 ]
注意:
以上两种方法的作用完全一样,后者为常用。
但后者需要注意方括号[、]与条件表达式之间至少有一个空格。
test跟 [] 的意思一样
条件成立,状态返回值是0
条件不成立,状态返回值是
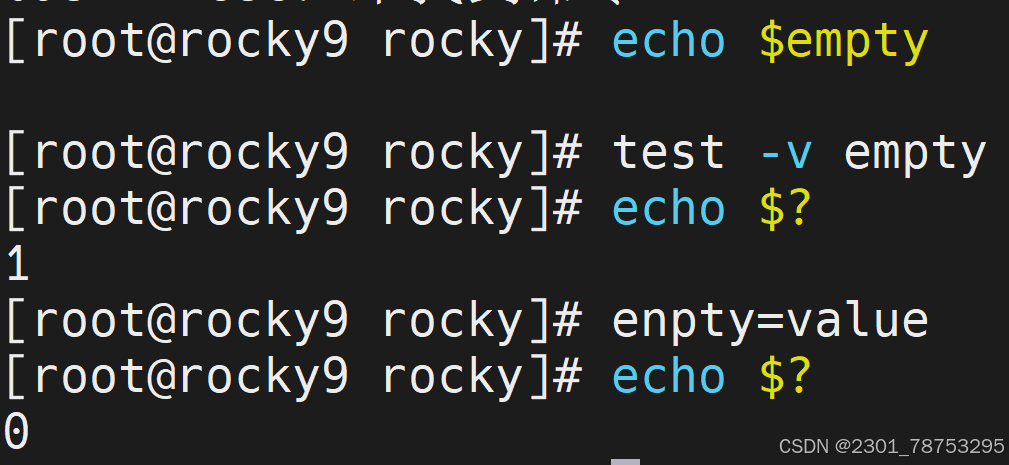
test -v 语法测试变量有没有被设置值,亦可理解为变量是否为空。
7.1.4逻辑表达式
&&
示例:命令1 && 命令2
如果命令1执行成功,那么我才执行命令2 -- 夫唱妇随
如果命令1执行失败,那么命令2也不执行
||
示例:命令1 || 命令2
如果命令1执行成功,那么命令2不执行 -- 对着干
如果命令1执行失败,那么命令2执行
!
示例:! 命令
如果命令执行成功,则整体取反状态
使用样式:
命令1 && 命令2 || 命令3
方便理解的样式 ( 命令1 && 命令2 ) || 命令3
功能解读:
命令1执行成功的情况下,执行
命令2 命令2执行失败的情况下,执行命令3
注意:
&& 必须放到前面,|| 放到后面
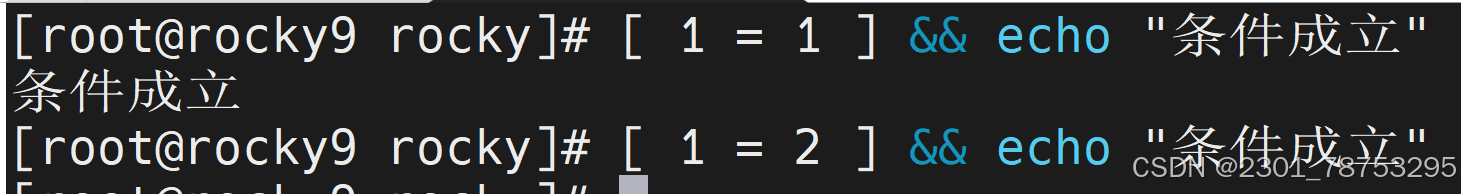
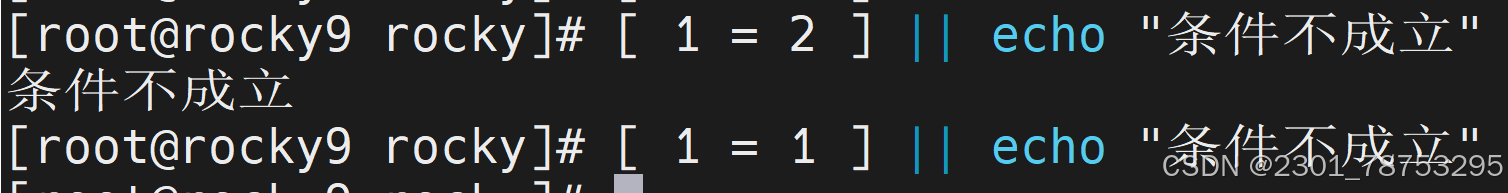
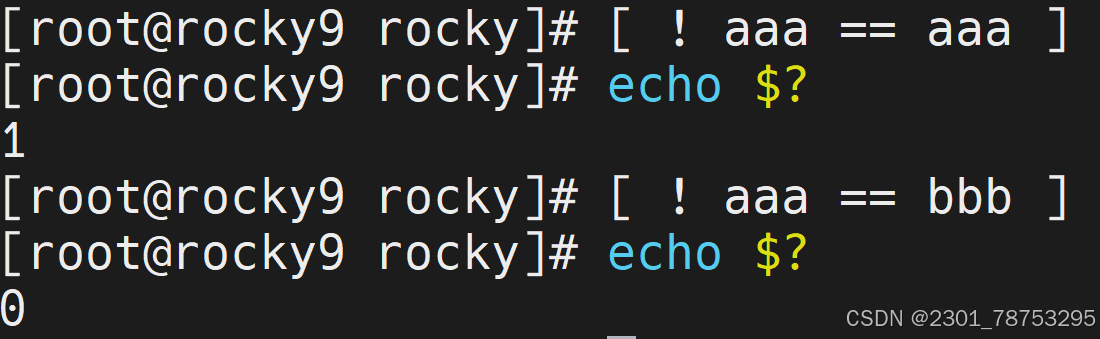


7.1.5字符串表达式
所谓的字符串表达式,主要是判断 比较运算符 两侧的值的内容是否一致,由于bash属于弱类型语言, 所以,默认情况下,无论数字和字符,都会可以被当成字符串进行判断。
符号解读
内容比较判断
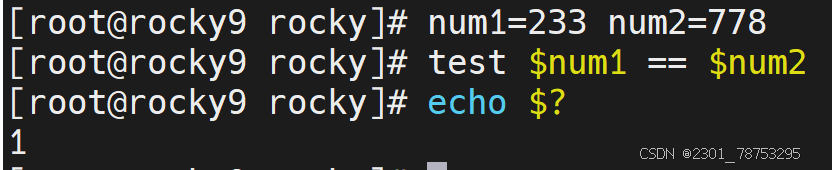
str1 == str2 str1和str2字符串内容一致
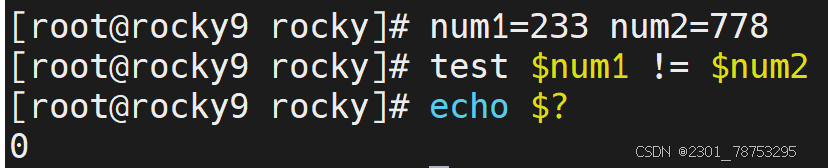
str1 != str2 str1和str2字符串内容不一致,!表示相反的意思
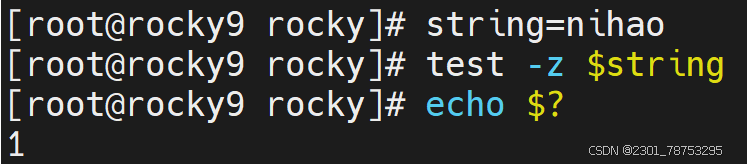
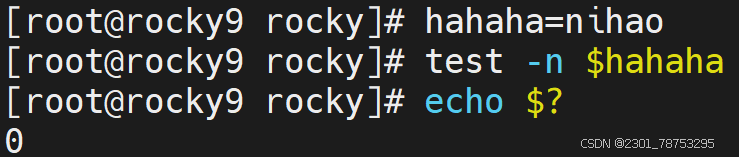
内容空值判断
-z str 空值判断,获取字符串长度,长度为0,返回真
-n "str" 非空值判断,获取字符串长度,长度不为0,返回真
注意:str外侧必须携带"",否则无法判断
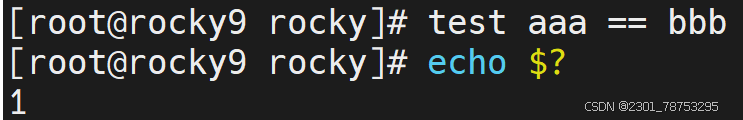


7.1.6 文件表达式
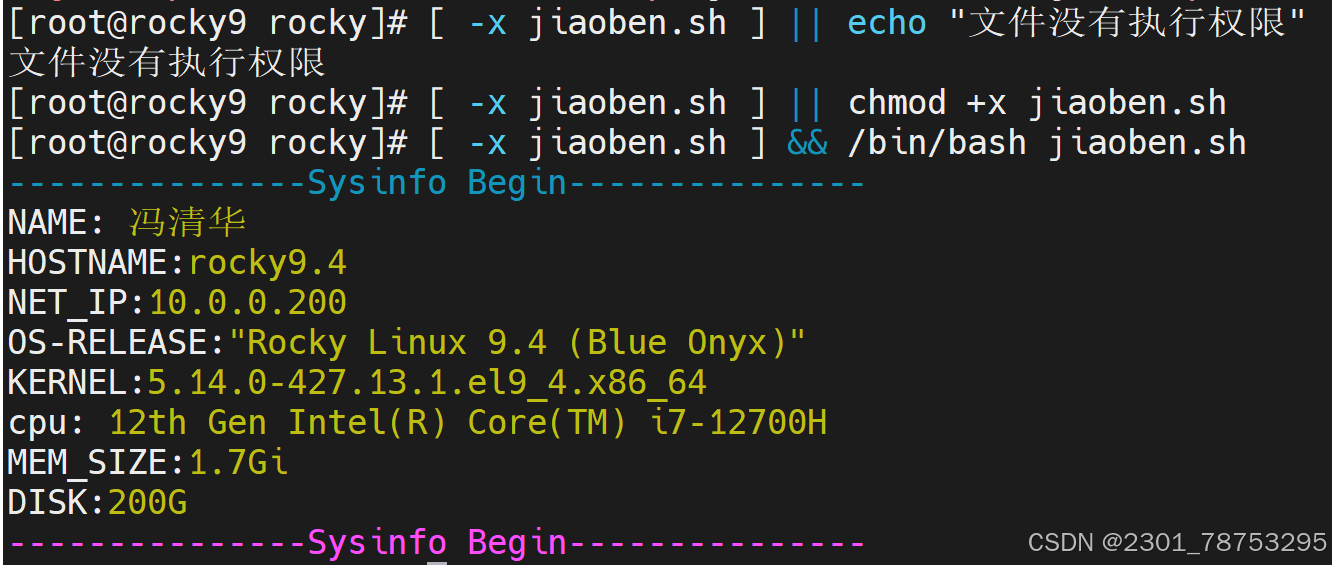
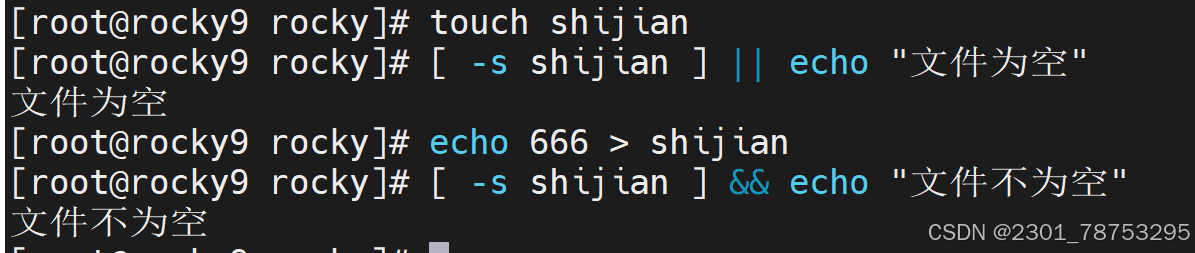
文件属性判断
-d 检查文件是否存在且为目录文件
-f 检查文件是否存在且为普通文件
-S 检查文件是否存在且为socket文件
-L 检查文件是否存在且为链接文件
-O 检查文件是否存在并且被当前用户拥有
-G 检查文件是否存在并且默认组为当前用户组
文件权限判断
-r 检查文件是否存在且可读
-w 检查文件是否存在且可写
-x 检查文件是否存在且可执行
文件存在判断
-e 检查文件是否存在
-s 检查文件是否存在且不为空
文件新旧判断
file1 -nt file2 检查file1是否比file2新
file1 -ot file2 检查file1是否比file2旧
file1 -ef file2 检查file1是否与file2是同一个文件,判定依据的是i节点



7.1.7 数字表达式
简介:
主要根据给定的两个值,判断第一个与第二个数的关系,如是否大于、小于、等于第二个数。
语法解读
n1 -eq n2 相等 n1 -ne n2 不等于 n1 -ge n2 大于等于
n1 -gt n2 大于 n1 -lt n2 小于 n1 -le n2 小于等于


7.1.8 表达式进阶
简介:
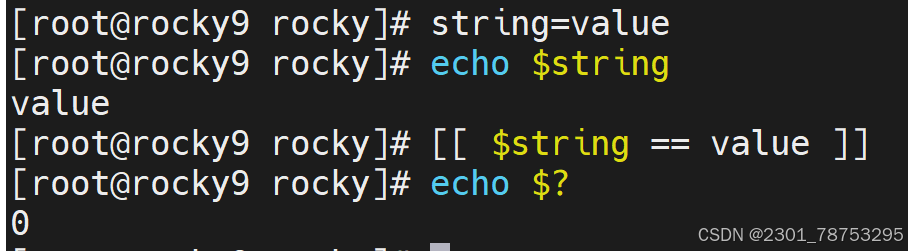
我们之前学习过 test 和 [ ] 测试表达式,这些简单的测试表达式,仅仅支持单条件的测试。如果需 要针对多条件测试场景的话,我们就需要学习[[ ]] 测试表达式了。
我们可以将 [[ ]] 理解为增强版的 [ ],它不仅仅支持多表达式,还支持扩展正则表达式和通配符。
基本格式:
[[ 源内容 操作符 匹配内容 ]]
操作符解析:
== 左侧源内容可以被右侧表达式精确匹配
=~ 左侧源内容可以被右侧表达式模糊匹配



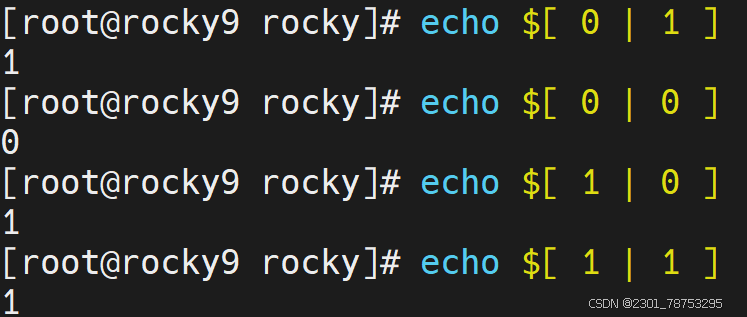
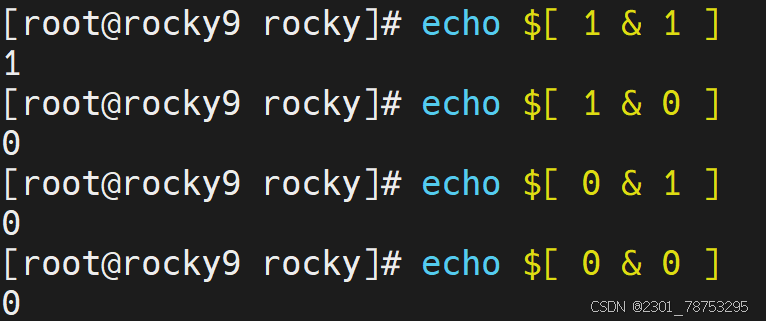
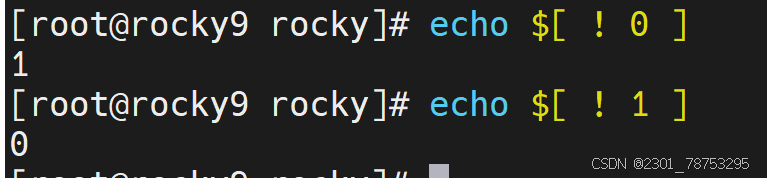
7.1.9集合基础
表现样式:
两个条件
1 - 真 0 - 假
三种情况:
与 - & 或 - | 非 - !
注意:
这里的 0 和 1 ,千万不要与条件表达式的状态值混淆 !!!!!!!!!!!!!!
与关系:
0 与 0 = 0 0 & 0 = 0
0 与 1 = 0 0 & 1 = 0
1 与 0 = 0 1 & 0 = 0
1 与 1 = 1 1 & 1 = 1
或关系:
0 或 0 = 0 0 | 0 = 0
0 或 1 = 1 0 | 1 = 1
1 或 0 = 1 1 | 0 = 1
1 或 1 = 1 1 | 1 = 1
非关系:
非 1 = 0 ! true = false
非 0 = 1 ! false = true
7.2.1 逻辑组合
简介:
所谓的条件组合,指的是在同一个场景下的多个条件的综合判断效果
语法解析:
方法1:
[ 条件1 -a 条件2 ] - 两个条件都为真,整体为真,否则为假
[ 条件1 -o 条件2 ] - 两个条件都为假,整体为假,否则为真
方法2:
[[ 条件1 && 条件2 ]] - 两个条件都为真,整体为真,否则为假
[[ 条件1 || 条件2 ]] - 两个条件都为假,整体为假,否则为真




8.1.1获取软件包
软件官网、github、第三方软件镜像站
系统发版的光盘或官方网站
CentOS镜像:
https://www.centos.org/download/
http://mirrors.aliyun.com
http://mirrors.sohu.com
http://mirrors.163.com
Ubuntu镜像:
http://cdimage.ubuntu.com/releases/
http://releases.ubuntu.com
第组织提供
Fedora-EPEL:Extra Packages for Enterprise Linux
https://fedoraproject.org/wiki/EPEL
https://mirrors.aliyun.com/epel/?spm=a2c6h..0.0.3bc47dfaZpesAr
Rpmforge:RHEL推荐,包很全,即将关闭
http://repoforge.org/
Community Enterprise Linux Repository:支持最新的内核和硬件相关包
http://www.elrepo.or
软件项目官方站点
http://yum.mariadb.org/10.4/centos8-amd64/rpms/
http://repo.mysql.com/yum/mysql-8.0-community/el/8/x86_64/
搜索引擎
注意:第三方包建议要检查其合法性,来源合法性,程序包的完整性 http://pkgs.org http://rpmfifind.net
http://rpm.pbone.net
https://sourceforge.net/
8.1.2包管理器rpm
安装
命令格式
rpm {-i|--install} [install-options] PACKAGE_FILE…
常用选项
-q # 检查软件是否安装
-ivh # 安装软件
-evh # 卸载软件
-Uvh # 有旧版程序包,则“升级”,如果不存在旧版程序包,则“安装”
-Fvh # 有旧版程序包,则“升级”,如果不存在旧版程序包,则不执行安装操作








8.1.3 查询
命令格式:
rpm {-q|--query} [select-options] [query-options]
常用选项
-i #information
-l #查看指定的程序包安装后生成的所有文件
-f #查看指定的文件由哪个程序包安装生成
-a #所有包
-d #查询程序的文档
常用组合:-qi、-qf、-ql、-qa
qa 查看所有安装好的包
-qi 查看已安装的包信息
-qf -qf 根据命令反查包文件
-ql -ql 查看已安装软件生成的所有软件文件
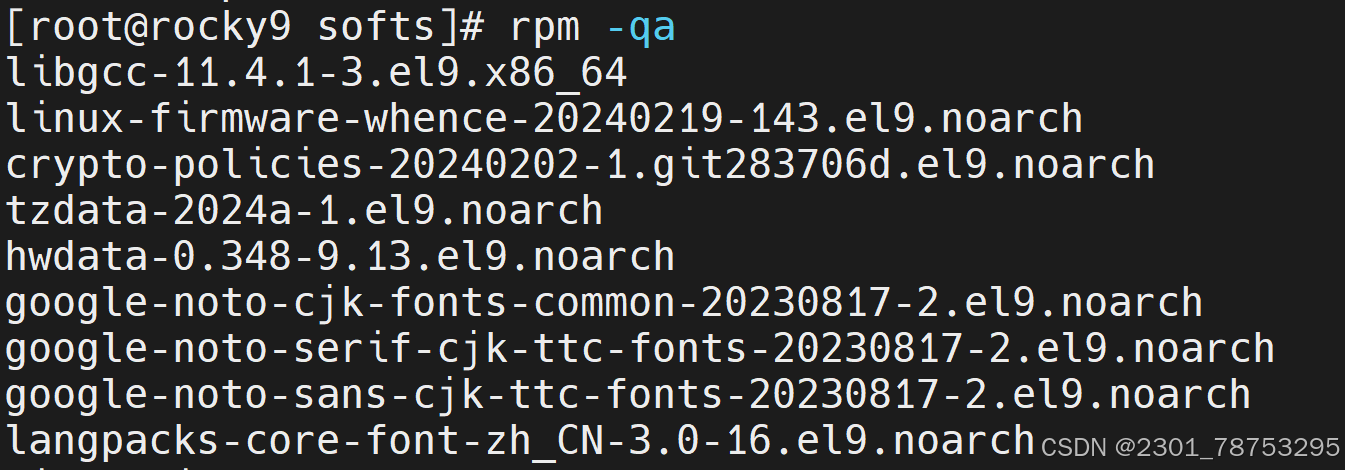

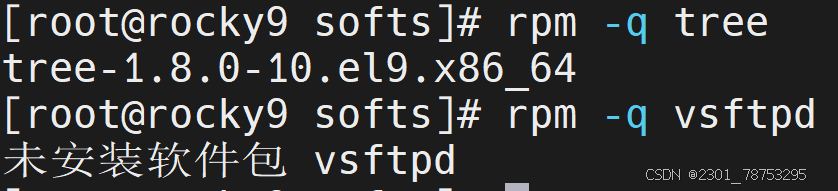
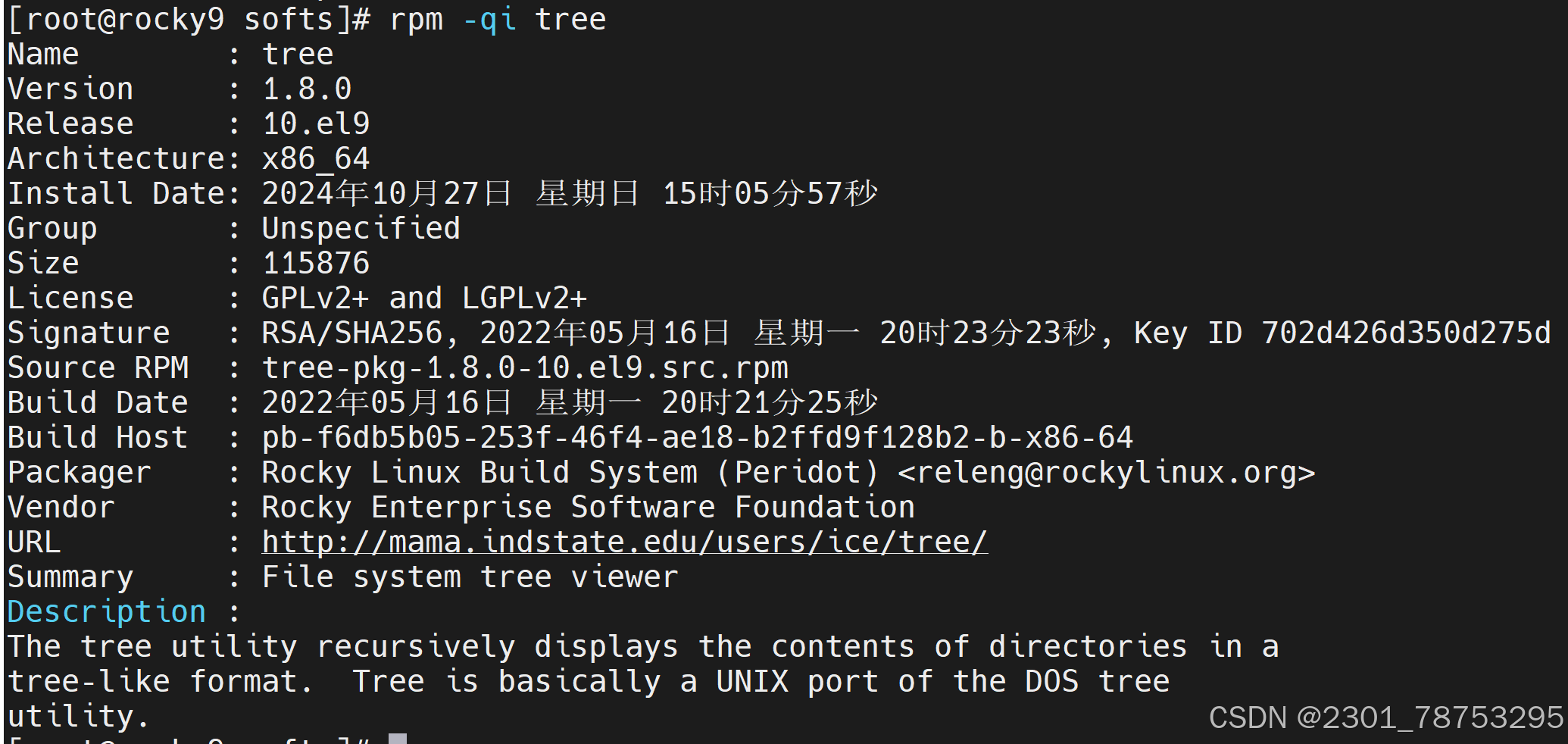




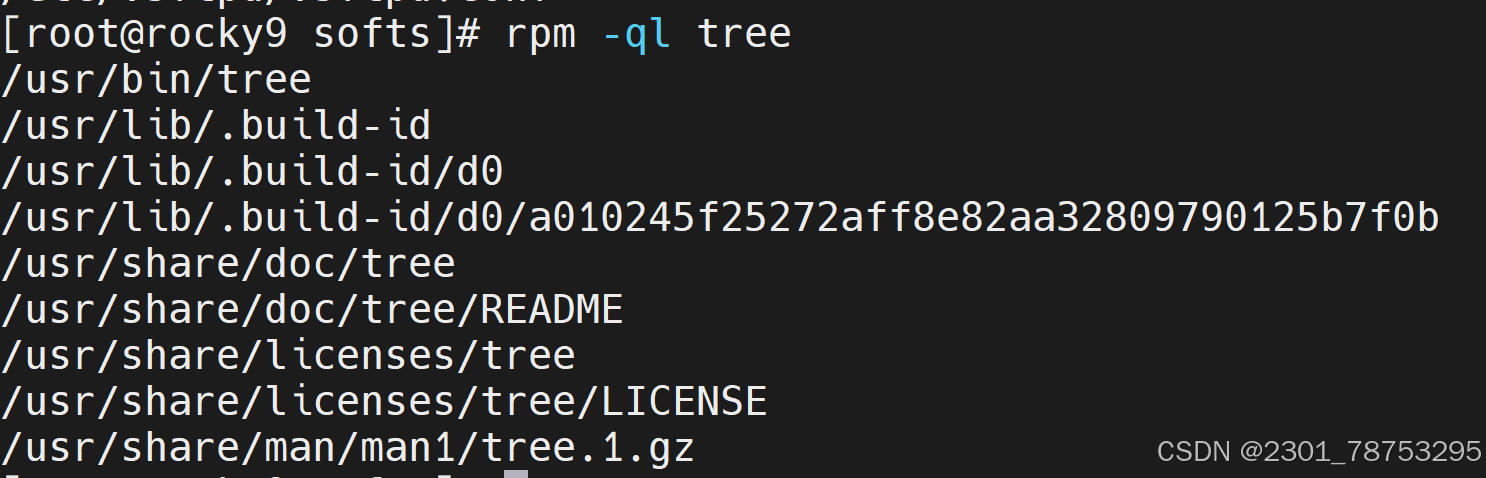

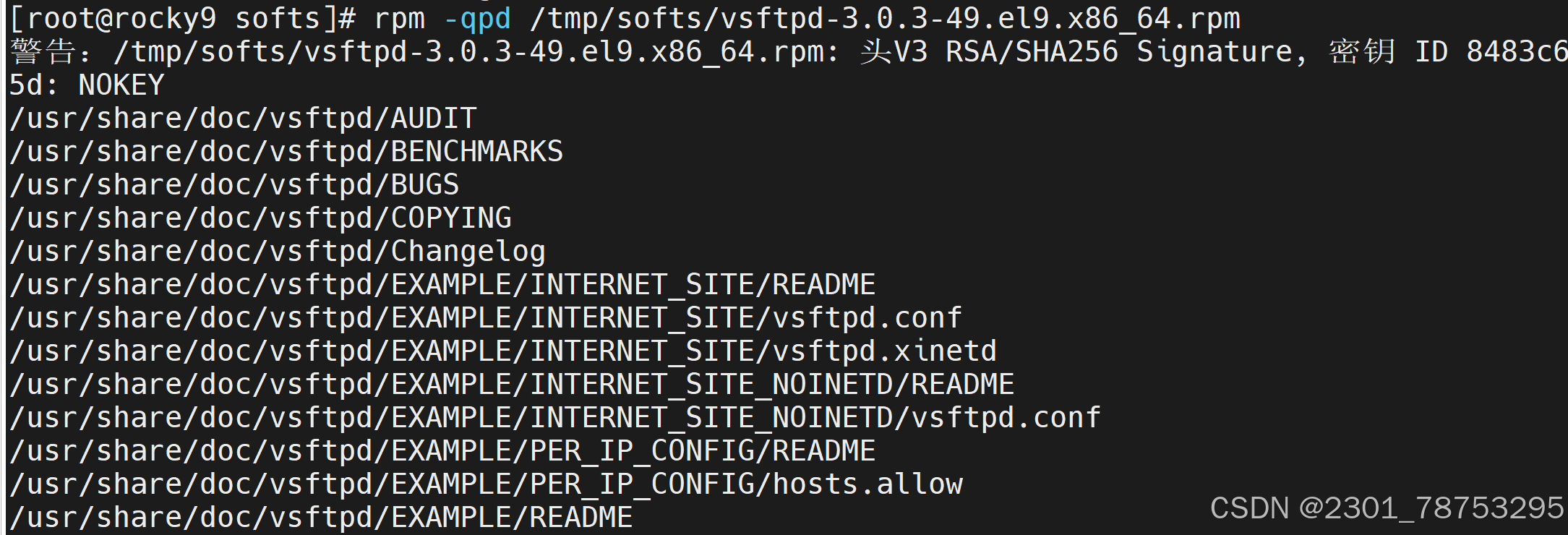

8.1.4yum和dnf
架构模式
yum/dnf 是基于C/S 模式
- yum 服务器存放rpm包和相关包的元数据库
- yum 客户端访问yum服务器进行安装或查询等
yum实现过程
先在yum服务器上创建 yum repository(仓库),在仓库中事先存储了众多rpm包,以及包的相关的 元数据文件(放置于特定目录repodata下),当yum客户端利用yum/dnf工具进行安装包时,会自动下载 repodata中的元数据,查询元数据是否存在相关的包及依赖关系,自动从仓库中找到相关包下载并安装。
配置环境
客户端配置
yum客户端配置文件
/etc/yum.conf #为所有仓库提供公共配置
/etc/yum.repos.d/*.repo #为每个仓库的提供配置文件
查看帮助
man 5 yum.conf
获取软件源信息 同步软件源基本信息更新软件源
yum makecache 谐音梅卡司
清理软件源信息
yum clean all 除了清理软件源信息的功能还有自动清理无用软件的功能
谐音颗粒奥
查看仓库的信息
yum repolist 查看仓库当前信息
yum repolist -v # 查看更多信息


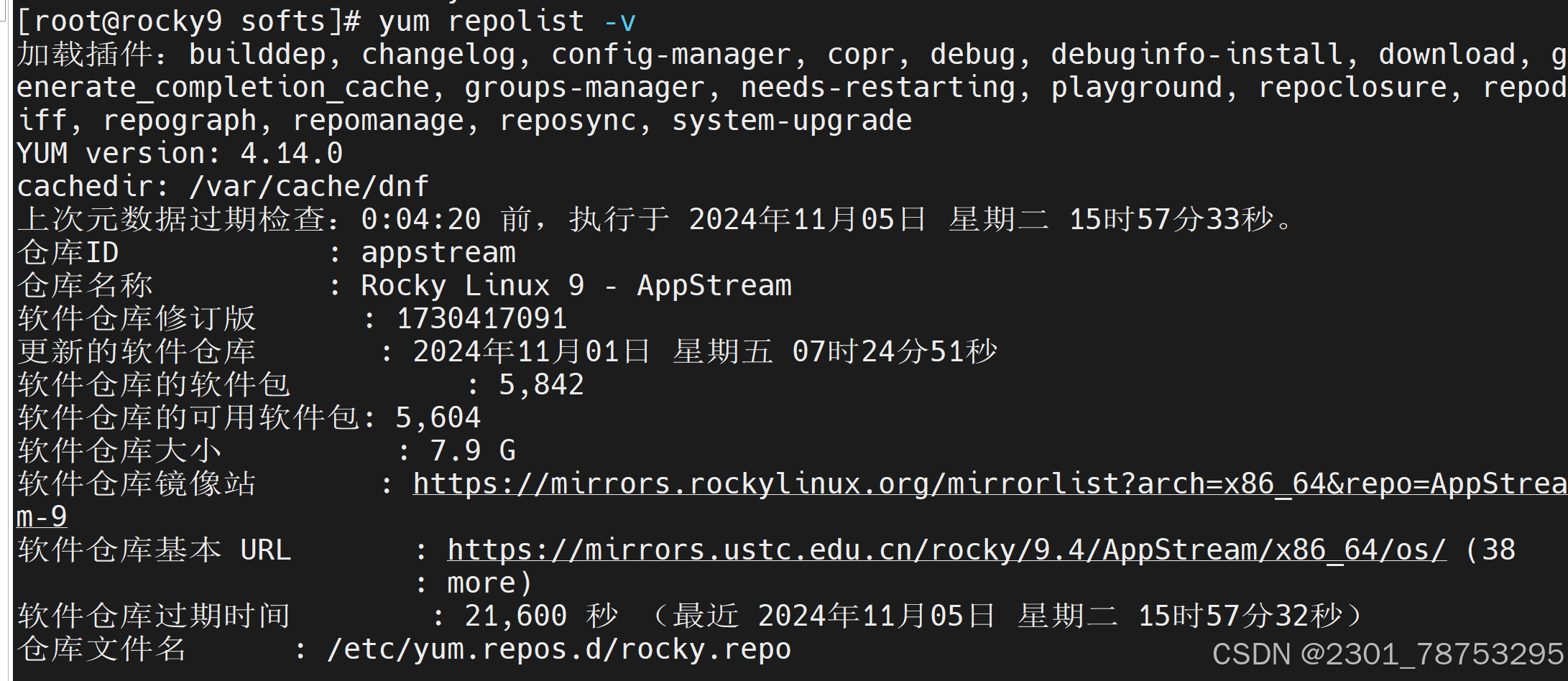


定制软件源
Rocky9.4上配置aliyun的repo源
1, cd /etc/yum.repos.d/ 切换到 /etc/yum.repos.d/ 下
2, mkdir bak 创建一个文件夹
3, mv *.repo bak/ 将所有以 .repo后缀的文件转移到bak目录中
4, yum clean all 清理软件源信息
5, yum makecache 获取软件源信息 看看还有没有仓库
6, vim aliyun-baseos.repo 创建文件并在里面编写内容内容如下:
[aliyun-baseos] 阿里云 baseos
name=aliyun baseos 名字阿里云 baseos
baseurl=https://mirrors.aliyun.com/rockylinux/9.4/BaseOS/x86_64/os/ 仓库地址
gpgcheck=0 0是不需要校验
[aliyun-Appstream]
name=aliyun appstream
baseurl=https://mirrors.aliyun.com/rockylinux/9.4/AppStream/x86_64/os/
gpgcheck=0 0是不需要校验7,yum makecache 同步软件源
本地源配置
保证光盘是挂载的 设备状态 已连接 启动时连接
1, mount /dev/cdrom /mnt 将光盘文件挂载到mnt目录下
2 vim local-image.repo 创建文件并在里面编写内容内容和aliyun一样改名字
3 开启一个新终端 ls /mnt/AppStream/ ls /mnt/BaseOS/
分别对应 file///mnt/AppStream/ file///mnt/BaseOS/ 网址
其他与上面一样
4 yum makecache 同步软件源
8.1.5yum命令
命令格式: yum [options] COMMAND
常用子命令
autoremove #卸载包,同时卸载依赖 个别配置文件可能不会被删除
clean #清除本地缓存
install #包安装
localinstall 安装本地下载好的包
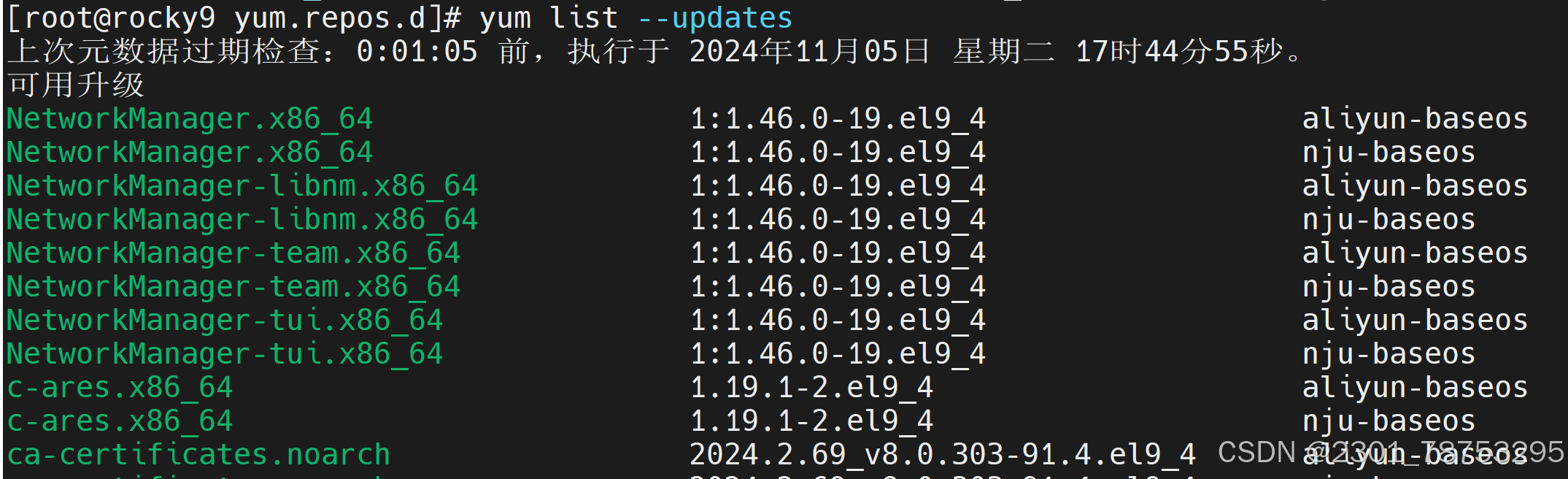
list #列出所有包 list --updates 可以让那些软件更新到最新版本
list --showduplicates 加软件名 可以查看有哪些可以安装的软件
修丢不累坎特
makecache #重建缓存
search #包搜索,包括包名和描述
一般子命令
check-update #检查可用更新
downgrade #包降级 命令实践 显示仓库列表
group #包组相关
help #显示帮助信息
history #显示history
info #显示包相关信息
reinstall #重装
remove #卸载
repolist #显示或解析repo源 search

软件组管理
常用:
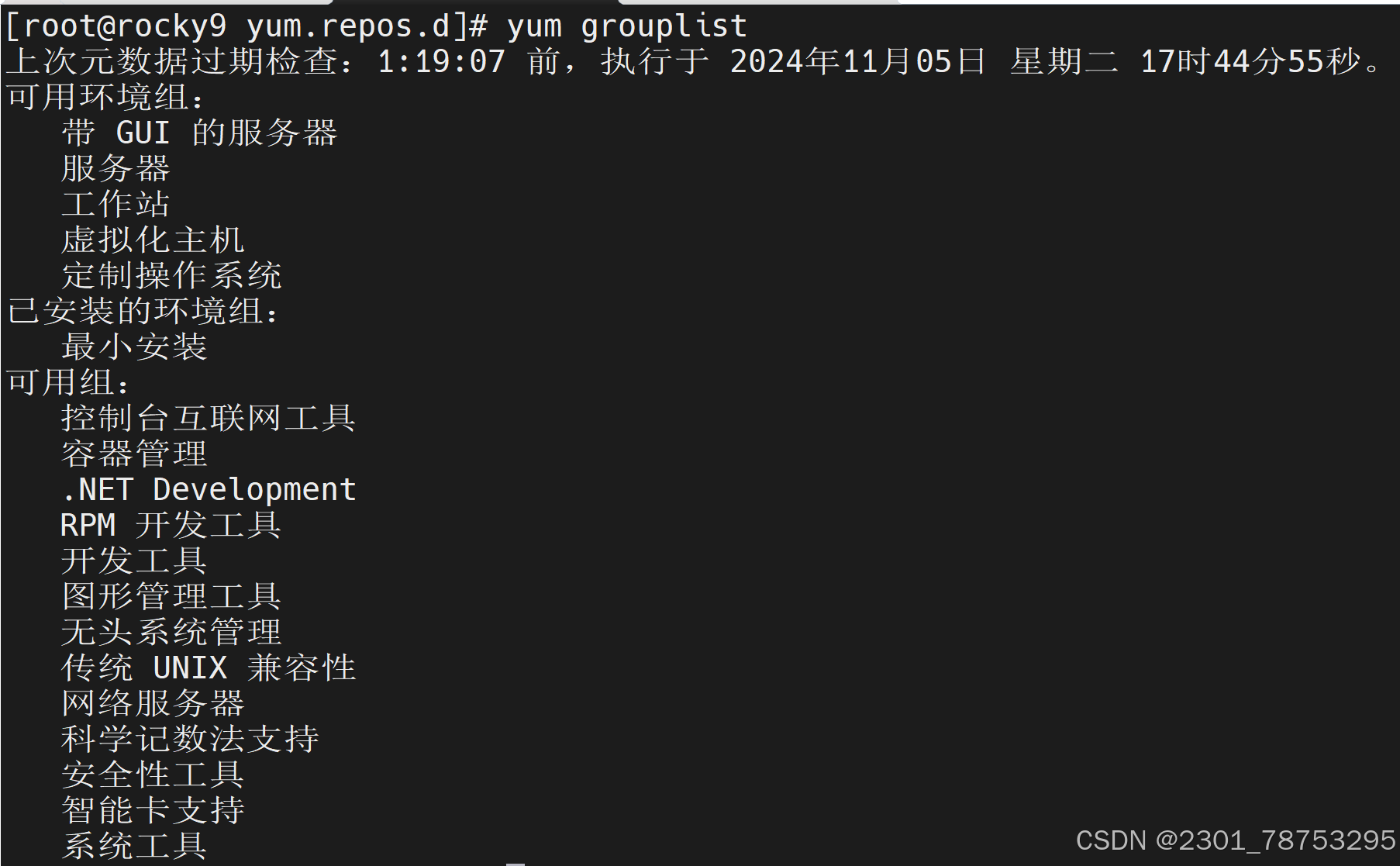
yum grouplist #列出所有包组
yum groupinstall #包组安装
一般命令:
yum groupupdate [options] group1 [...] #包组升级
yum groupremove [options] group1 [...] #包组卸载
yum groupinfo [options] group1 [...] #包组查询
yum grouplist #列出所有包组操作 安装组
1, echo $LANG
2 LANG=EN
3 yum groupinstall "Development Tools" "Security Tools" "System Tools"
安装软件包组 开发工具 安全工具 System工具
8.1.6自建yum仓库
准备
1, 准备web环境
2, 准备rpm软件----------从互联网获取-------从本地光盘获取
3, 创建repodate数据库
4, 测试 ------客户端准备软件源配置为文件----------测试
操作流程
1,yum install -y httpd 下载httpd
2,systemctl disable --now firewalld.service 关闭防火墙
3,systemctl enable --now httpd.service 开启
4,yum reposync --repoid=nju-extras --download-metadata -p /var/www/html/ 将阿里云的extras源的相关数据下载到本地 给客户端使用
5,cd /etc/yum.repos.d/ 创建文件
文件内容:
[private-extras1]
name=private extras1
baseurl=http://10.0.0.13/nju-extras/
gpgcheck=0
6,yum makecache 更新软件源
7, yum list --repo="private-extras2" anaconda-live
列出所有 repo仓库 列出所有仓库="后面是仓库名"软件名
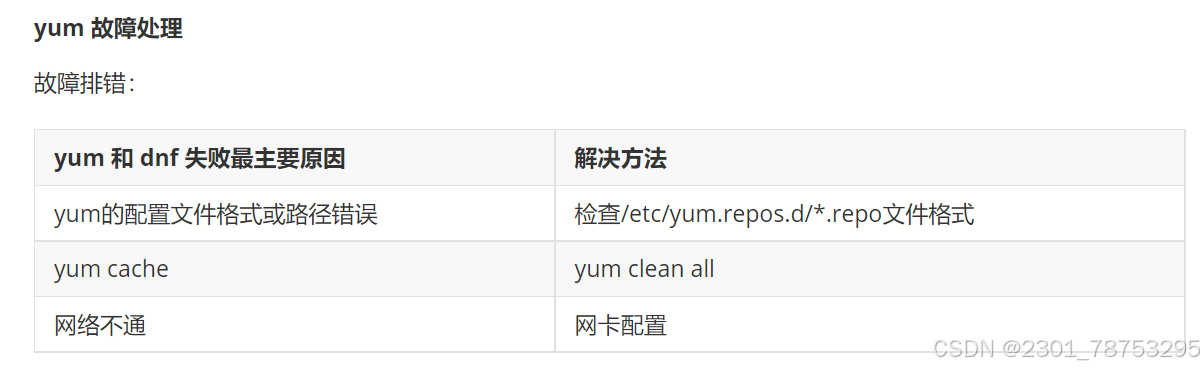
yum 故障处理
8.1.8Ubuntu软件管理
基础知识
Debian 软件包通常为预编译的二进制格式的扩展名“.deb”,类似 rpm 文件,因此安装快速,无需编 译软件。包文件包括特定功能或软件所必需的文件、元数据和指令
dpkg:
package manager for Debian,类似于rpm, dpkg是基于Debian的系统的包管理器。可以安装, 删除和构建软件包,但无法自动下载和安装软件包或其依赖项
apt:
Advanced Packaging Tool,功能强大的软件管理工具,甚至可升级整个Ubuntu的系统,基于客户/ 服务器架构(c/s)
APT
APT工作原理
在服务器上先复制DEB包,然后用APT的分析工具genbasedir根据每个DEB 包的包头(Header) 信息对所有的DEB包进行分析,并将该分析结果记录在文件夹base内的一个DEB 索引清单文件中,一旦APT 服务器内的DEB有所变动,要使用genbasedir产生新的DEB索引清单。
客户端在进行安装或升级时先要查询DEB索引清单,从而获知所有具有依赖关系的软件包,并一同下载到 客户端以便安装。当客户端需要安装、升级或删除某个软件包时,客户端计算机取得DEB索引清单压缩文件 后,会将其解压置放于 /var/cache/apt/,而客户端使用apt-get install或apt-get upgrade命令的 时候,就会将这个文件夹内的数据和客户端计算机内的DEB数据库比对,知道哪些DEB已安装、未安装或是可以 升级的。
APT包索引配置文件
ubuntu 22.04 系统
root@ubuntu24:/etc/apt# cat /etc/apt/sources.list
deb https://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ jammy main restricted universe
multiverse
解读:
deb 代表二进制包的地址标识
deb-src 代表源码包的地址标识
配置文件格式说明
deb URL section1 section2
#字段说明
deb #固定开头,表示是二进制包的仓库,如果deb-src开头,表示是源码库
URL #库所在的地址,可以是网络地址,也可以是本地镜像地址
section1 #Ubuntu版本的代号,可用 lsb_release -sc 命令查看,也可以用 cat
/etc/os-release
section2 #软件分类,main完全自由软件 restricted不完全自由的软件,universe社区支持 的软件,multiverse非自由软件
section1 #主仓
section1-backports #后备仓,该仓中的软件当前版本不一定支持
section1-security #修复仓,主要用来打补丁,有重大漏洞,需要在当前版本中修复时,会放此 仓
section1-updates #非安全性更新仓,不影响系统安全的小版本迭代放此仓
section1-proposed #预更新仓,可理解为新版软件的测试放在此仓,
#测试一段时间后会移动到 updates仓或security仓,非专业人士勿用
APT包结构
在ubuntu库中,有两个重要目录,分别是dists和 pool
dists 目录中存放的是该源仓库中的元数据,包括软件包的名称,适用的架构平台,版本号,依赖关系 等
pool 目录中存放的是具体包文件
8.1.9 dpkg 包管理器
dpkg命令
使用方式:dpkg 选项 要安装的包
选项:
-i |--install package.deb #安装包
-r |--remove packageName #删除包,不建议,不自动卸载依赖于它的包
前提将包下载好


8.2.1本地安装 命令用法
使用方法: apt 选项 软件名
常见命令
list #根据名称列出软件包 不加名默认列出全部
search #搜索软件包描述
show|info #显示软件包细节
install #安装软件包
remove #移除软件包
autoremove #卸载所有自动安装且不再使用的软件包
update #更新可用软件包列表,只更新索引文件,不具体
apt-cache madison 查看版本
apt-cache depends 查看依赖
当遇到apt install 异常严重报错的时候,可以通过下面的命令来修复。
apt --fix-broken install
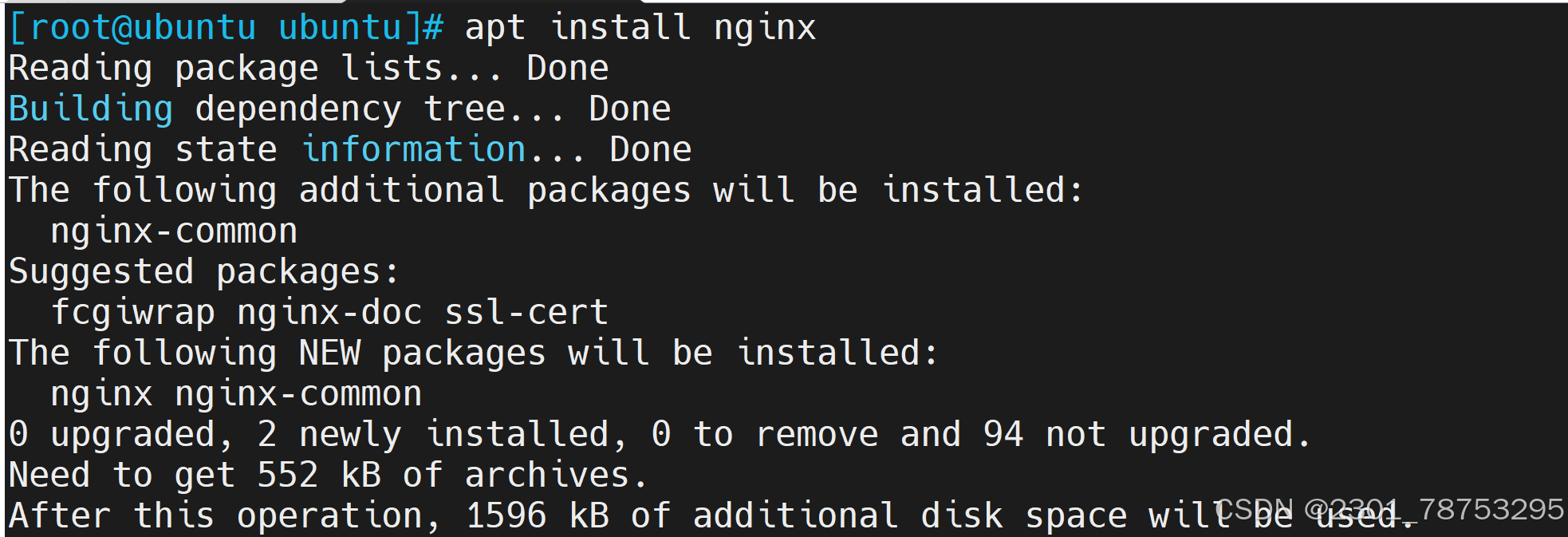
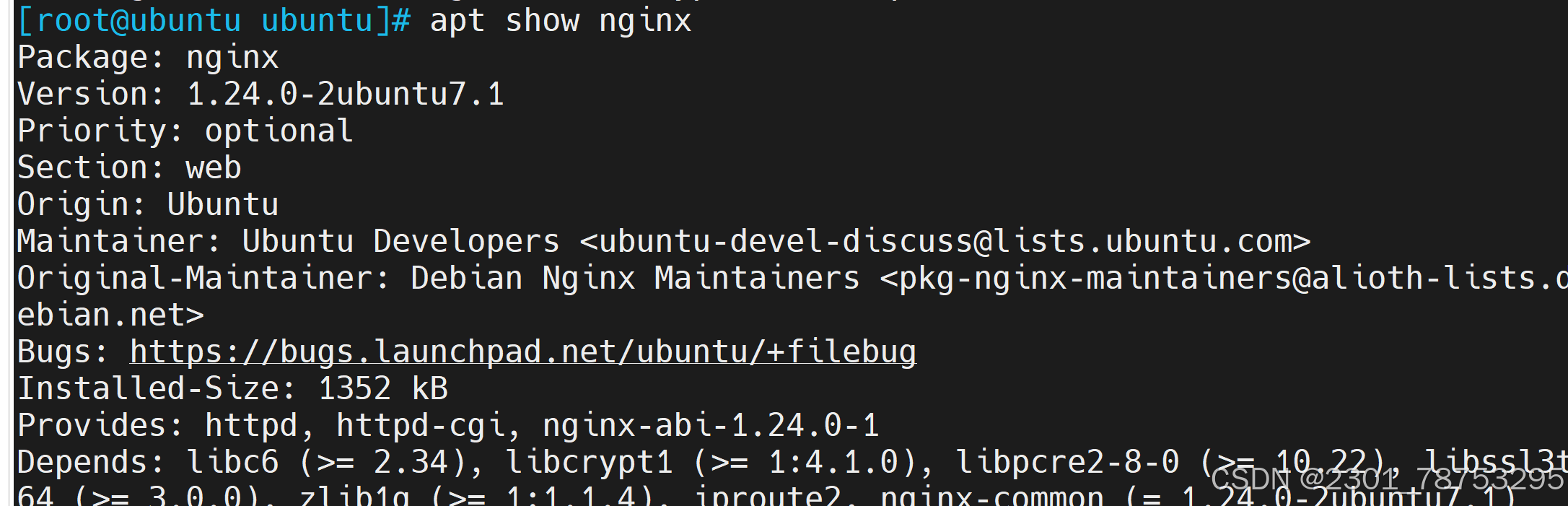
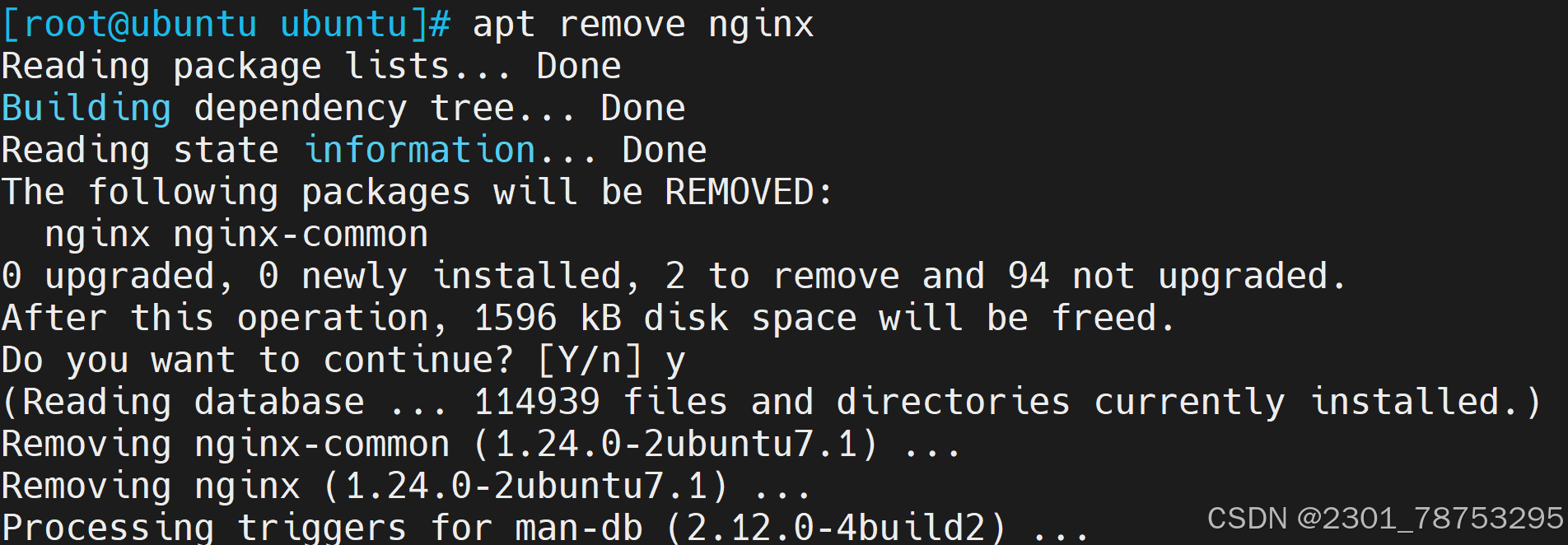
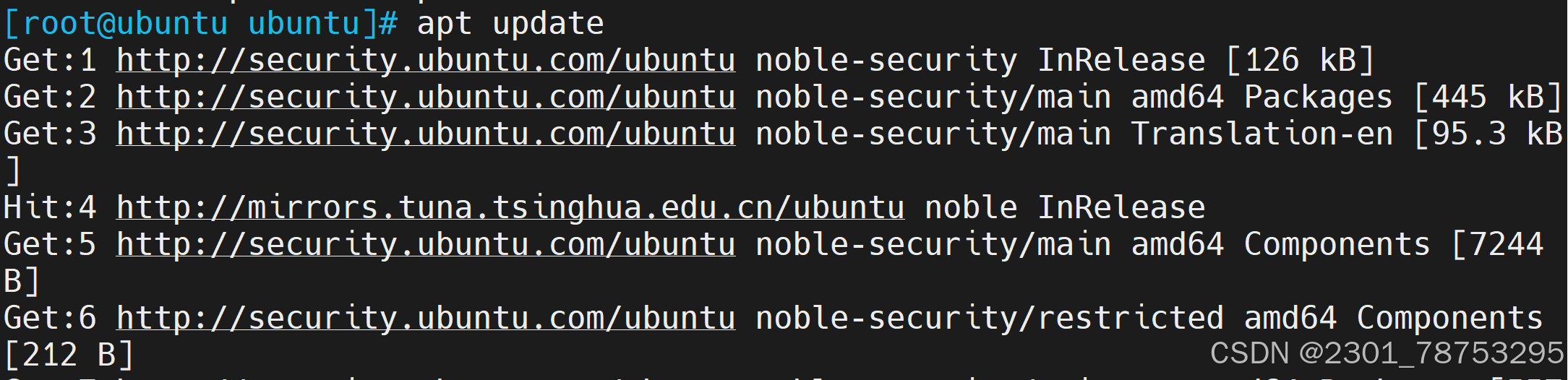

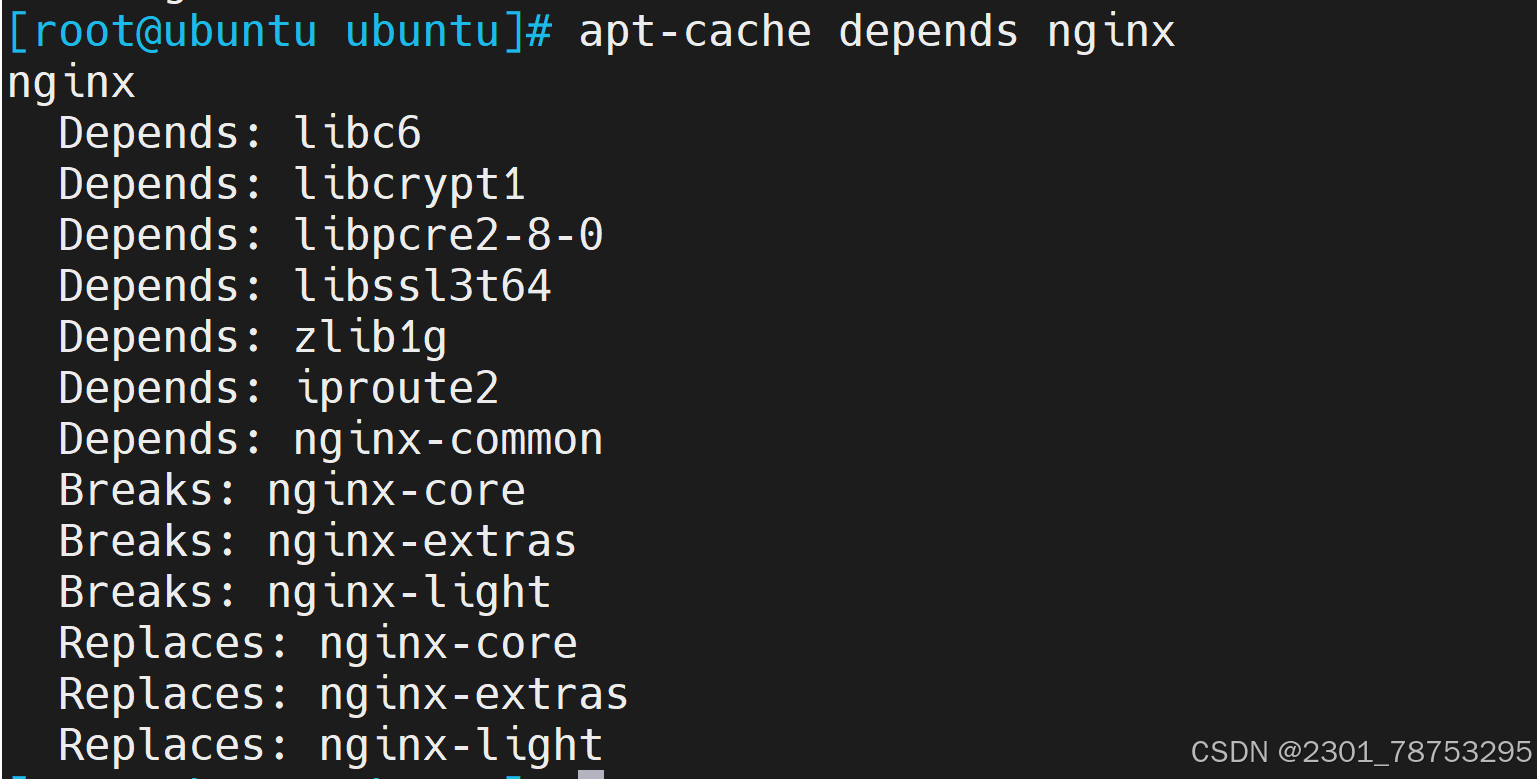
8.2.2 源码包部署
流程:
1 部署make编译环境
2 获取项目源代码文件
3 解压软件包
4 编译安装软件 - configure定制配置 -> make编译生成配置文件 -> make install转移文件到安装目录
5 将可执行文件路径加入PATH环境变量
6 测试效果
注意:
如果没有configure可执行文件
- autoconf: 生成confifigure脚本
对于大部分的开源软件项目来说,他们的编译工具是 make
对于特殊的编程语言来说,比如 java语言项目,编译工具是 ant|maven等专用工具
配置环境
Centos系统: 和基础编译环境有关系的软件 yum install gcc make gcc-c++ glibc glibc-devel pcre pcre-devel openssl openssldevel systemd-devel zlib-devel
和常用工具有关系的命令软件 yum install vim lrzsz tree tmux lsof tcpdump wget net-tools iotop bc bzip2 zip unzip nfs-utils man-pages
工具组方式 yum groupinstall "Development Tools" "System Tools"
Ubuntu系统:
和基础编译环境有关系的软件 apt install build-essential gcc g++ libc6 libc6-dev libpcre3 libpcre3-dev libssl-dev libsystemd-dev zlib1g-dev
和常用工具有关系的命令软件 apt install vim lrzsz tree tmux lsof tcpdump wget net-tools iotop bc bzip2 zip unzip nfs-common manpages-dev
软件组方式 apt install build-essential
1,下载
创建文件夹mkdir /softs; cd /softs
下载 wget http://nginx.org/download/nginx-1.23.0.tar.gz
2, 解压
tar xf nginx-1.23.0.tar.gz
3, 配置
默认配置https://blog.csdn.net/2301_/article/details/configure
4, 编译
make
5,转移
make install
6, 环境变量
export PATH=/usr/local/nginx/sbin:$PATH
启动 nginx
9.1.1磁盘存储
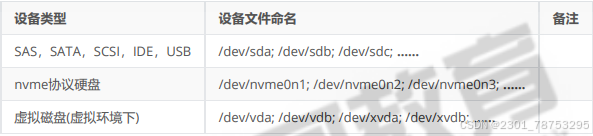
设备文件
设备文件有自己的标识主设备号,次设备号
设备标号 sd | nvme | vd
设备号
设备文件类型
磁盘设备的设备文件命名


硬盘
简介:
硬盘是计算机系统中一个至关重要的非易失性存储设备,即使计算机关闭,存储的数据也不会丢失。它主 要由一个或多个以铁氧体为材料的盘片组成,盘片表面涂有磁性材料,用于存储和检索大量的二进制数据。 硬盘负责长期存储大量数据,包括操作系统、应用程序、文档、图片、视频等。用户可以随时读取和写入 数据,以满足各种计算任务的需求。
硬盘接口类型:
- IDE:133MB/s,并行接口,早期家用电脑
- SCSI:640MB/s,并行接口,早期服务器
- SATA:6Gbps,SATA数据端口与电源端口是分开的,即需要两条线,一条数据线,一条电源线
- SAS:6Gbps,SAS是一整条线,数据端口与电源端口是一体化的,SAS中是包含供电线的,而 SATA中不包 含供电线。SATA标准其实是SAS标准的一个子集,二者可兼容,SATA硬盘可以插入SAS主板上,反之不行
- USB:480MB/s
- M.2:
注意:
速度不是由单纯的接口类型决定,支持Nvme协议硬盘速度是最快的
磁盘大小
- LFF:3.5寸,一般见到的那种台式机硬盘的大小
- SFF:Small Form Factor 小形状因数,2.5寸,注意不同于2.5寸的笔记本硬盘
注意:
L、S分别是大、小的意思,纯粹是物理层面的含义 目前服务器或者盘柜采用sff规格的硬盘主要是考虑增大单位密度内的磁盘容量、增强散热、减小功耗
机械硬盘(HDD)
Hard Disk Drive,即是传统普通硬盘,主要由:盘片,磁头,盘片转轴及控制电机,磁头控制器,数 据转换器,接口,缓存等几个部分组成。 机械硬盘中所有的盘片都装在一个旋转轴 上,每张盘片之间是平行的,在每个盘片的存储面上有一个磁 头,磁头与盘片之间的距离比头发丝的直径还小,所有的磁头联在一个磁头控制器上,由磁头控制器负责各个 磁头的运动。磁头可沿盘片的半径方向运动,加上盘片每分钟几千转的高速旋转,磁头就可以定位在盘片的指 定位置上进行数据的读写操作。数据通过磁头由电磁流来改变极性方式被电磁流写到磁盘上,也可以通过相反 方式读取。 硬盘为精密设备,进入硬盘的空气必须过滤。
固态硬盘(SSD)
Solid State Drive,用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH芯片、 DRAM芯片)组成。固态硬盘在接口的规范和定义、功能及使用方法上与普通硬盘的完全相同,在产品外形和尺 寸上也与普通硬盘一致
关联区别
硬盘(Hard Disk Drive, HDD) 传统的硬盘类型,采用磁性存储技术,通过盘片的旋转和磁头的移动来读写数据。 存储容量大、价格相对较低,但读写速度相对较慢,且存在机械结构,易受震动影响。 固态硬盘(Solid State Drive, SSD) 采用闪存芯片作为存储介质的新型硬盘,没有机械结构,因此读写速度极快,抗震性能优越。 价格相对较高,但随着技术进步逐渐亲民;存储容量虽然有限,但已能满足大多数应用需求;适用于需要 高读写速度和稳定性的场景。
磁盘容量
硬盘容量以兆字节(MB)或千兆字节(GB)为单位,主流硬盘容量可达数TB(太字节)。硬盘容量的实 际值可能会因计算方法的差异(硬盘厂商采用1000进制而操作系统采用1024进制)而略小于标称值。例如, 标称1TB的硬盘在操作系统中可能显示为约0.93TB
存储术语
磁盘上寻址的两种方式
CHS(Cylinder-Head-Sector 柱面-磁头-扇区)也称为3D模式
- 它通过提供柱面号、磁头号和扇区号来唯一确定一个扇区的位置。
- CHS采用 24 bit位寻址
- 其中前10位表示cylinder,中间8位表示head,后面6位表示sector
- 最大寻址空间 8 GB
- 是硬盘最早采用的寻址模式之一。
LBA (logical block addressing)
- LBA是一个整数,通过转换成 CHS 格式完成磁盘具体寻址
- ATA-1规范中定义了28位寻址模式,以每扇区512位组来计算,ATA-1所定义的28位LBA上限达到 128 GiB。2002年ATA-6规范采用48位LBA,同样以每扇区512位组计算容量上限可达128 Petabytes
- 它基于扇区的线性编号来定位数据,不受柱面、磁头和扇区的限制。
- 在现代硬盘中,LBA寻址方式已经成为主流。
在磁盘容量小于大概8GB时,可以使用CHS寻址方式或是LBA寻址方式;
在磁盘容量大于大概8GB时,则只能使用LBA寻址方式
磁盘术语
MBR 硬盘的第一个扇区(0道0头1扇区)
ZBR 区位记录,是一种物理优化硬盘存储空间的方法
常见命令
文件管理工具
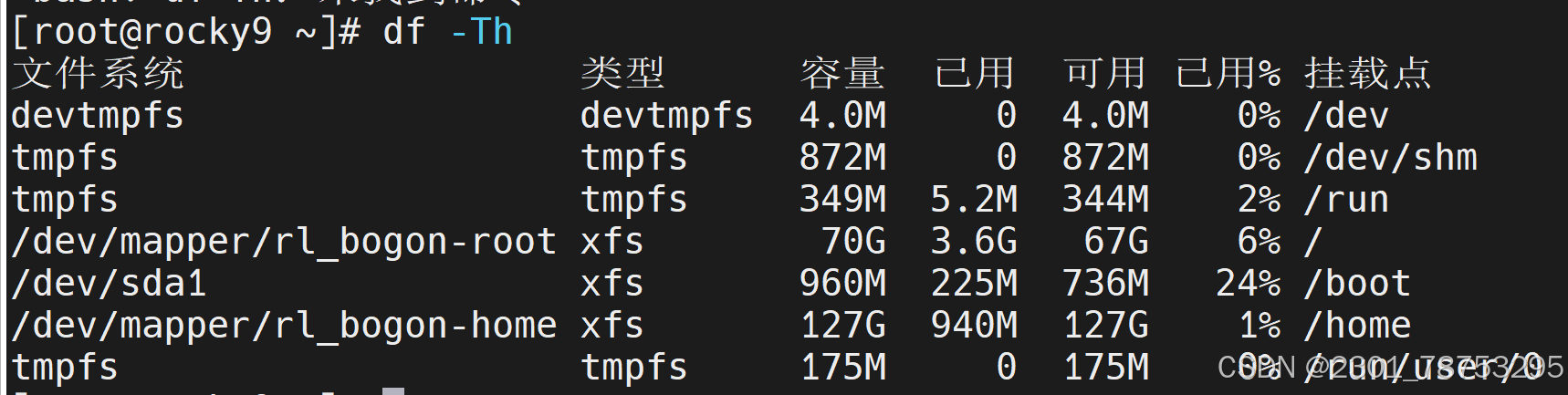
文件系统查看工具df
df -Th df查看文件系统
文件系统目录信息统计工具du
du -sh /etc du查看文件系统目录
文件系统定制工具dd
dd if=SRC of=DEST bs=N count=N dd定制文件系统文件
skip=blocks 从开头忽略blocks个ids大小得块
seek=blocks 从开头忽略blocks个ids大小得块
if=file #从所命名文件读取而不是从标准输入
of=file #写到所命名的文件而不是到标准输出
bs=size #指定块大小(既是是ibs也是obs)
count=n #复制n个bs
hexdump -n 512 -Cv /dev/sda | tail -5 以十六进制方式展示查看文件二进制内容-n指定查看多少字节
-v 表示以“verbose”模式显示
-c 表示以十六进制和ASCII字符混合显示
-n 512表示只显示前512字节

9.1.2 存储管理
基础知识
基本步骤:
当我们拿到一块物理磁盘的时候,我们可以按照如下的步骤,实现在服务器中使用使用磁盘空间的效果
1. 设备分区
2. 文件系统格式化
3. 挂载新的文件系统
磁盘分区
磁盘分区是指将一个硬盘划分为多个独立的存储区域,每个区域都拥有自己的文件系统和卷标。这种划分 方式使得用户可以更方便地管理和存储不同类型的文件。磁盘分区是计算机存储管理的重要基础,对于提高数 据存储的效率和安全性具有重要意义
为什么要磁盘分区
使用磁盘分区的原因主要有以下几点:
数据管理:通过分区,用户可以将不同类型的文件存放在不同的分区中,便于分类管理和查找。
系统安全:将操作系统和用户数据分别存放在不同的分区中,可以在系统崩溃或需要重装时保护用户数据 不受影响。
性能优化:合理的分区策略可以减少磁盘碎片,提高磁盘的访问速度和效率。
多操作系统支持:通过分区,用户可以在同一台计算机上安装并运行多个操作系统,满足不同的应用需 求
分区类型
分区类型: 主分区 扩展分区 逻辑分区

分区实现方式
MBR 分区方式
简介
MBR是一种传统的分区模式,最早在1983年随着PC DOS 2.0对硬盘的支持而出现。它是IBM兼容机硬盘 或可移动磁盘分区时,在驱动器最前端的一段引导扇区。这段扇区包含了分区表、引导加载程序代码等重要信 息。
分区数量:
MBR分区表最多支持4个主分区,或者3个主分区和1个扩展分区(扩展分区下可以创建多个逻辑分区)。 容量限制:
由于MBR使用32位的LBA(Logical Block Addressing)寻址方式,其最大可寻址的存储空间只有 2TB(2^32个扇区,每个扇区512字节)。虽然一些硬盘制造商通过提高扇区大小(如4KB扇区)将MBR的有效 容量上限提升到16TiB,但这仍然是一个显著的限制。
MBR分区方式在一些老旧的操作系统和硬件平台上具有较好的兼容性,如Windows 7、XP以及更早的 Windows版本。然而,随着硬件和软件的发展,MBR的兼容性优势逐渐减弱。
GPT 分区方式
GPT是一种现代的磁盘分区方案,由EFI(Extensible Firmware Interface,可扩展固件接口)标 准提出并推广。GPT旨在克服MBR所存在的一些限制,并提供更多的功能和灵活性。
大容量支持:
GPT使用64位LBA寻址方式,理论上可以支持最大容量为9.4ZB(1ZB=1024^7字节)的硬盘,远超MBR 的2TB限制。 更多分区支持:
GPT可以支持最多128个分区(在Windows系统中),而MBR最多只能有4个主分区(或3个主分区+1个扩 展分区)。 数据冗余与校验:
GPT在硬盘两端各保存一份分区表副本,以及CRC32校验,有助于提高数据完整性和容错性。 兼容性:
GPT不仅支持现代的操作系统和硬件平台(如Windows 10/11、macOS、Linux等),还提供了对 UEFI(Unified Extensible Firmware Interface,统一可扩展固件接口)的更好支持。
9.1.3 MBR方案
特点:
每个扇区512字节
第一扇区:
- 446bytes: boot loader 启动相关
- 64bytes:分区表,其中每16bytes标识一个分区
- 2bytes: 55AA,标识位
分区标识:dos
分区样式:
最多四个分区,三个主分区一个扩展分区,扩展分区中可以有n个逻辑分区
3主分区+1扩展分区(N个逻辑分区)
GPT 分区
特点:源自EFI标准的较新磁盘分区表结构,支持大硬盘、分区数量无限制、启动方便,分区标识gpt
结构:保护MBR,GPT头、分区表、GPT分区 、备份区域,分区表备份、GPT头备份
9.1.4 命令解读
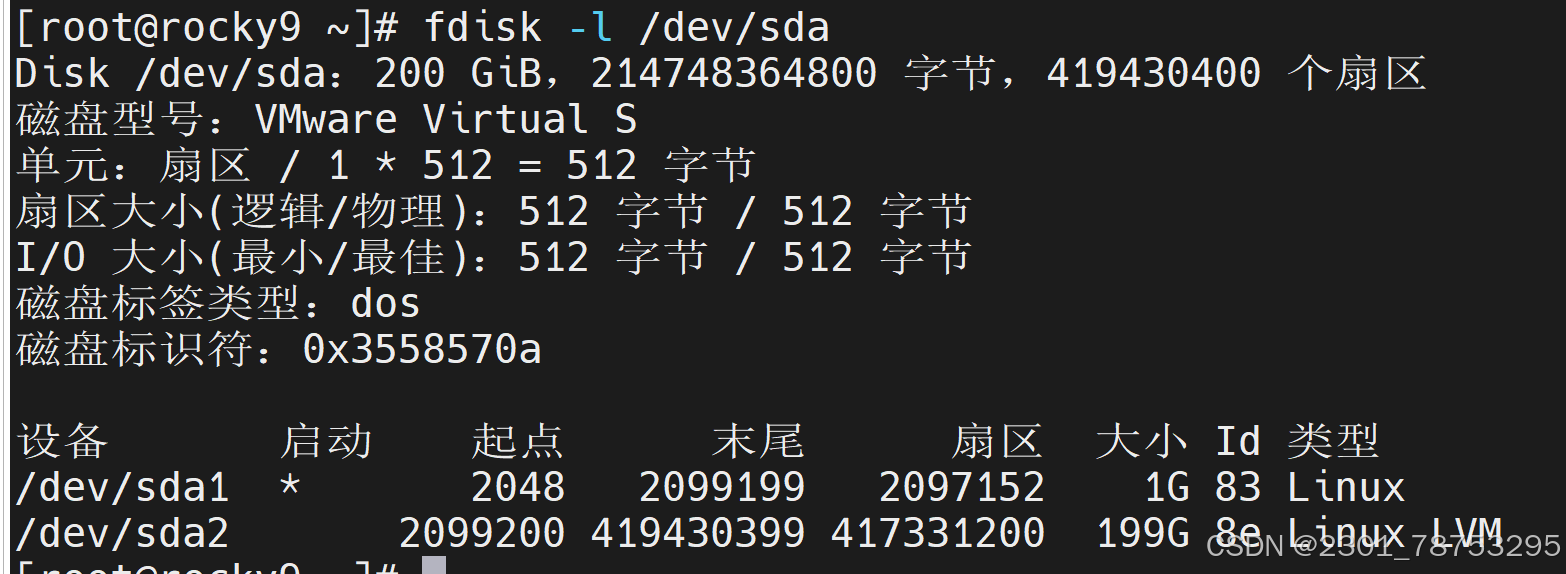
fdisk命令用于操作管理分区
命令格式:fdisk [options] -l []
创建分区:
前提:fdisk /dev/sda
进入分区操作:创建分区 n 选择分区:类型 p主 | 扩展 分区号: 默认是一而且是递增
起始扇区号 ;回车 结束扇区号: 回车 检查 p 保存 w
lsblk命令用于查看设备信息
命令格式: lsblk [options] [ ...]
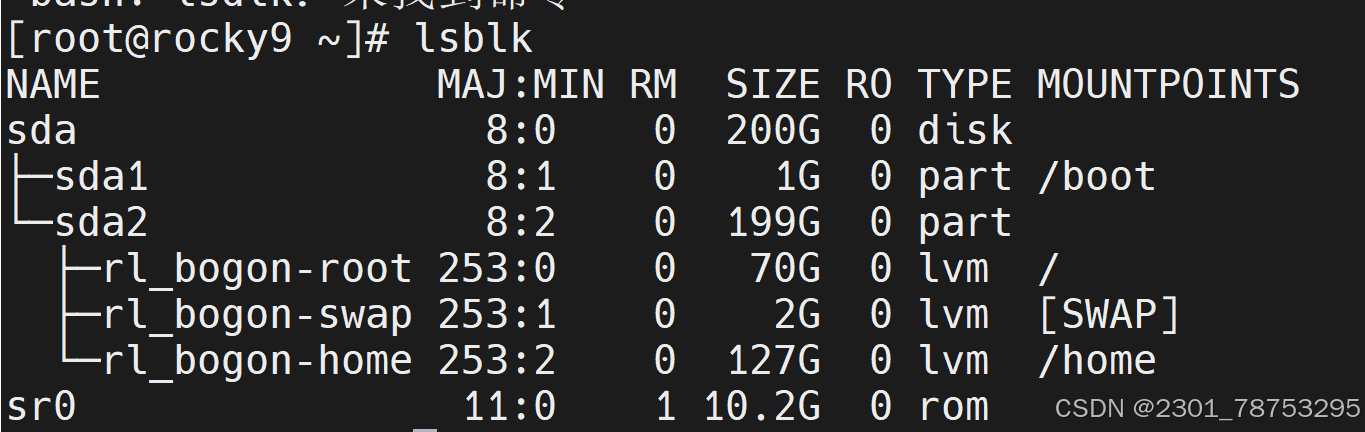
9.1.5 创建分区
fdisk分区
fdisk是一个创建和维护分区表的程序,它兼容DOS类型的分区表、BSD或者SUN类型的磁盘列表。它常 被用于创建、删除、调整磁盘分区,以及更改分区类型等操作。 fdisk主要使用传统的MBR(主引导记录)分区表格式。MBR分区表有一些限制,例如最多支持4个主分区 或
3个主分区和1个扩展分区
分区创建标准流程
进入手动分区交互模式
fdisk /dev/sdb
命令(输入 m 获取帮助):m # 输入m 查看命令帮助
进入分区操作:创建分区 n 选择分区:类型 p主 | 扩展 分区号: 默认是一而且是递增
起始扇区号 ;回车 结束扇区号: 回车或者+10G 检查 p 保存 w
更改分区类型标识
更改标识 t
选择分区 4
确定分区标识号 86
保存 w
非交互模式创建分区
echo -e 'n p +10G w' | fdisk /dev/sdb
删除三个分区
echo -e 'd d d w' | fdisk /dev/sdb
gdisk 分区
gdisk是GPT(GUID分区表)磁盘分区工具 - "GPT fdisk",适用于使用GPT分区表的系统。GPT是一 种新一代的磁盘分区方案,可以解决MBR的一些限制。与MBR相比,GPT支持更大的磁盘容量、更多的分区、更 可靠的数据恢复等特性。
进入手动分区交互模式
gdisk /dev/nvme0n1
其他与fdisk分区
9.1.6文件系统
文件系统基础
基础知识
操作系统中负责管理和存储文件信息的软件结构称为文件管理系统,简称文件系统
从系统角度来看,文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行 保护和检索的系统。具体地说,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,安 全控制,日志,压缩,加密等。
文件系统的组成
- 内核中的模块:ext4, xfs, vfat
- Linux的虚拟文件系统:VFS
- 用户空间的管理工具:mkfs.ext4, mkfs.xfs,mkfs.vfat
常见文件系统类型
Linux常见文件系统类型:
ext4 ext 文件系统的最新版
xfs 支持最大8EB的文件系统
- EXT4是Linux系统下的日志文件系统,是EXT3文件系统的后继版本
- Ext4的文件系统容量达到1EB,而支持单个文件则达到16TB
- 理论上支持无限数量的子目录
- Ext4文件系统使用64位空间记录块数量和 inode数量
- Ext4的多块分配器支持一次调用分配多个数据块 - 修复速度更快
XFS
- 根据所记录的日志在很短的时间内迅速恢复磁盘文件内容
- 用优化算法,日志记录对整体文件操作影响非常小
- 是一个全64-bit的文件系统,最大可以支持8EB的文件系统,而支持单个文件则达到8EB
- 能以接近裸设备I/O的性能存储数据
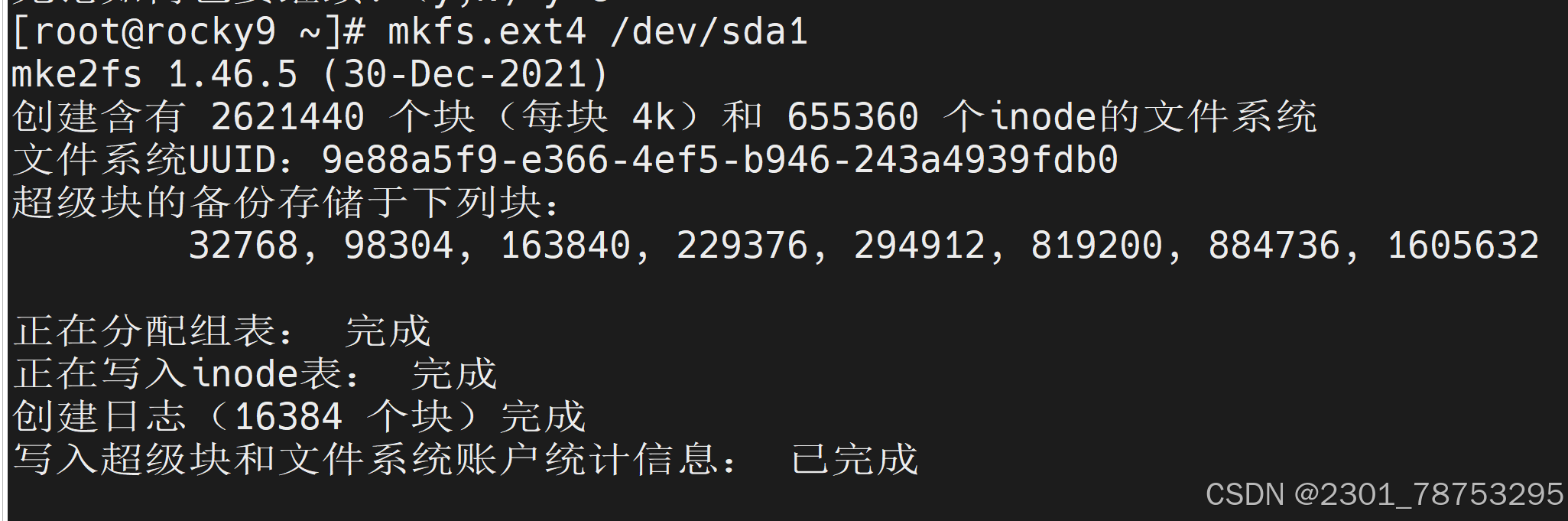
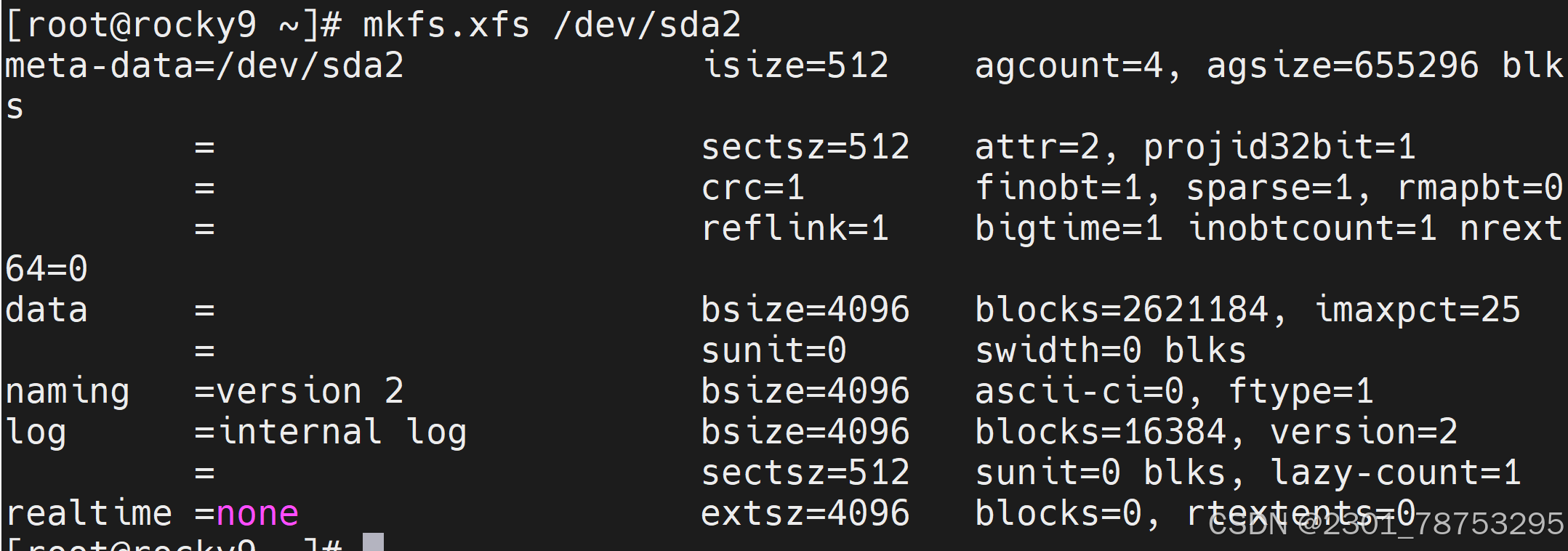
9.1.7mkfs [必会] 格式化文件系统
命令格式 mkfs [options] [-t ] [fs-options] []
使用:
mkfs.ext4 /dev/sdb
mkfs.xfs /dev/nvme0n1p1
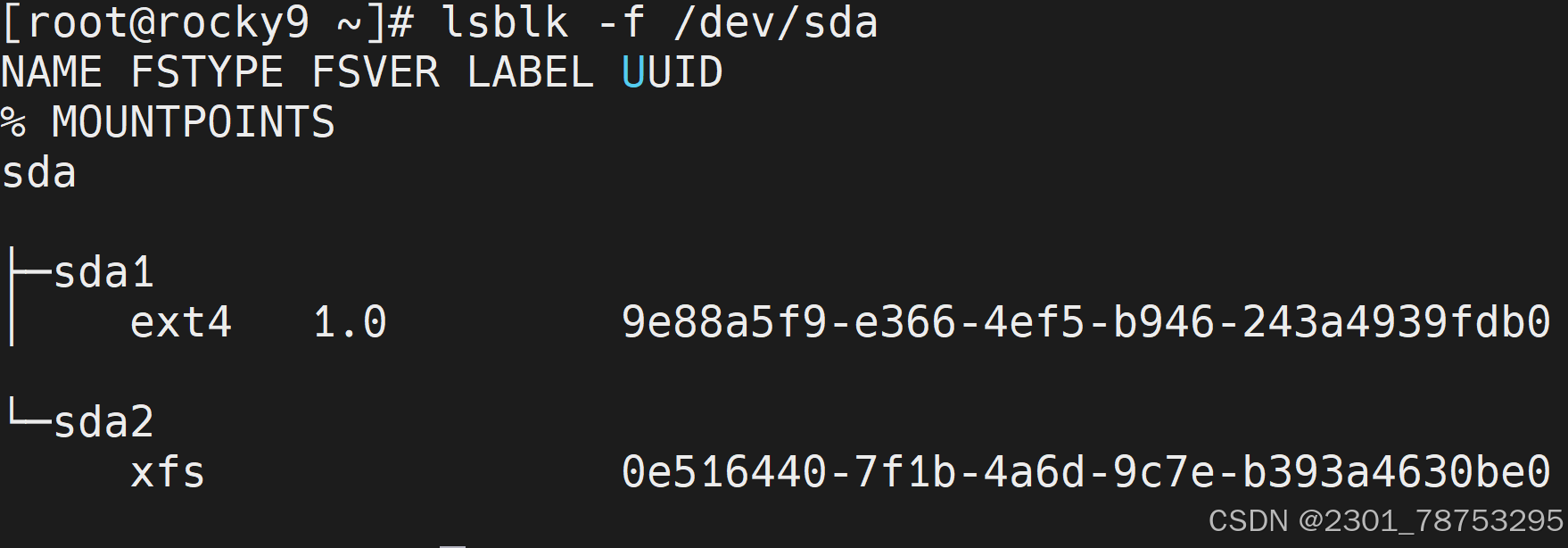
查看:
lsblk -f /dev/sdb
9.1.8mount挂载文件系统命令解读
挂载命令格式:mount [-t 文件系统类型] [-o 特殊选项] 源文件系统 目标挂载点
只读挂载:mount /dev/sdb1 -o ro /mount/ext
xfs挂载 :mount -t xfs /dev/nvme0n1p2 /mount/xfs
卸载命令格式:umount [-f] [-l] [-n] 挂载点
卸载:umount /dev/sdb1
查看已挂载的所有文件系统 mount



9.1.9持久挂载
步骤:
1 打开/etc/fstab文件
2 添加挂载信息 挂载信息为要挂载的UUID /mount/xfs xfs defaults 0 0
3 保存并关闭文件
4 验证挂载配置mount | grep /mount mount -a mount | grep /mount
fstab格式 : <文件系统设备> <挂载点> <文件系统类型> <挂载选项> <dump> <fsck>
fstab配置生效 :
新增|删除属性:mount -a
修改属性:mount -o remount

9.2.1异常修复
检测ext4
fsck.ext4 /dev/sdb1
e2fsck /dev/sdb1
检测xfs
xfs_repair -n /dev/nvme0n1p2
修复硬盘
e2fsck /dev/sdb1
9.2.2交换分区
简介:
交换分区是虚拟内存的一种特殊分区当物理内存不满足当前运行时操作系统会将暂时不使用的数据交换到虚拟分区中释放RAM空间供其他程序使用。但是配置过多的swap空间会造成浪费。
9.2.2.1交换分区的实现过程
1. 创建交换分区或者文件
2. 使用mkswap写入特殊签名
3. 应用交换分区
- 永久使用:在/etc/fstab文件中添加适当的条目
- 临时使用:使用swapon|swapoff -a 激活|禁用交换空间
- 参数使用:/proc/sys/vm/swappiness的值为 0~100
9.2.2.2启动swap分区命令解读
swapoff -a 临时禁用
swapon -a 临时启用
sed -i.bak '/swap/d' /etc/fstab 永久禁用
vm.swappiness=0 内核禁用
swap使用策略:
CentOS7和8默认值为30
对于ubuntu和Rocky linux9来说,默认值是60
9.2.3RAID
定位:
在多个磁盘上分配数据,从而提升数据传输速度和存储性能
原理:
物理层面: 磁盘阵列
逻辑层面: 存储资源池动态管理
实现方式:
外接式磁盘阵列:通过扩展卡提供适配能力
内接式RAID: 主板集成RAID控制器,安装OS前在BIOS里配置
软件RAID:通过OS实现,比如:群晖的NAS
分类:
硬件RAID:
硬件驱动的RAID系统 :一个RAID控制器芯片 一组附加的驱动器组成
RAID类型
常见类型:
RAID-0:n块盘的总容量的使用,没有冗余功能 其中一块盘坏了所有文件都没法使用了50%的使用率
RAID-1:n块盘的一半容量的使用,有冗余能力 一个使用一个做备份50%的使用率
RAID-5:数据和奇偶校验信息分散在多个磁盘上容错一个磁盘的故障 磁盘利用率高综合性能最佳
RAID-10:两组RAID-1组成RAID-0来使用 RAID-10也被称为RAID 1+0,是RAID 1与RAID 0的结合体。它首先创建多个RAID 1镜像对,然后将 这些镜像对组合成一个RAID 0阵列。这种结构既提供了RAID 0的高性能,又具备了RAID 1的数据冗余和容 错能力。 由于采用了RAID 0的条带化技术,RAID-10能够并行读写多个磁盘,从而显著提高数据传输速度
9.2.4LVM
简介:
LVM(Logical Volume Manager)即逻辑卷管理器
特点:
LVM在硬盘分区和文件系统之间添加了一个逻辑层
原理解读:
物理存储介质:
指系统的存储设备,如硬盘,是存储系统的最低层存储单元。
-----
PV(Physical Volume,物理卷):
是LVM存储管理的最底层,可以是整个物理硬盘或实际物理硬盘上的分区。
物理卷在加入LVM之前需要经过特殊处理,以便LVM能够识别和管理。
VG(Volume Group,卷组):
是建立在物理卷之上的一个逻辑层,它包含了一个或多个物理卷。
卷组将多个物理卷组合在一起,形成一个可管理的单元,类似于非LVM系统中的物理硬盘。
LV(Logical Volume,逻辑卷):
是建立在卷组之上的一个逻辑层,它类似于非LVM系统中的硬盘分区。
逻辑卷可以在其上建立文件系统,并挂载到不同的挂载点,用于存储数据。
-----
PE(Physical Extent,物理区域):
是物理卷中可用于分配的最小存储单元。PE的大小是可配置的,默认为4MB。
在建立卷组时,物理区域的大小会被指定,并且一旦确定就不能更改。
同一卷组中的所有物理卷的物理区域大小必须一致。
LE(Logical Extent,逻辑区域):
是逻辑卷中可用于分配的最小存储单元。
逻辑区域的大小取决于逻辑卷所在卷组中的物理区域的大小,即一个LE对应一个PE。
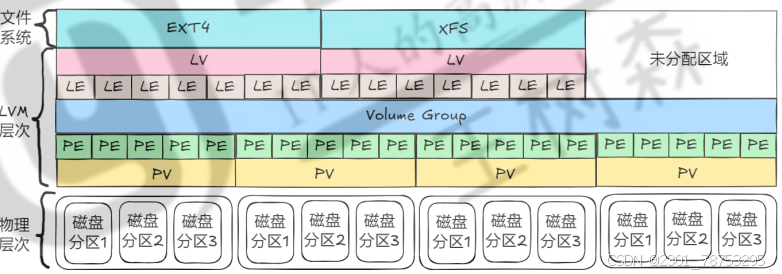
9.2.4.1创建实践
准备工作:添加5块盘,然后进行分区
创建pv:
pvcreate /dev/sdb1 /dev/sdc1
查看信息 pvs pvdisplay /dev/sdb1
创建vg:lvcreate -l 5G -n lv1 testvg
查看信息; lvs lvscan lvdisplay /dev/testvg/lv1
挂载实践:
格式化:mkfs.ext4 /dev/testvg/lv1
挂载:mount /dev/testvg/lv1 /mount/lvm/
9.2.4.2管理实践
扩容实践:
增加新pv vgextend testvg /dev/sdd1
扩展逻辑卷 : lvextend -L +1G /dev/testvg/lv1
扩容文件系统; resize2fs /dev/testvg/lv1
扩展所有容量 : lvresize -r -l +100%FREE /dev/testvg/lv1
缩容实践:
取消挂载:umount /dev/resrvg/lv1
文件系统检测 : e2fsck -f /dev/testvg/lv1
缩减文件系统: resize2fs /dev/testvg/lv1 3G
缩减逻辑卷: lvreduce -L 3G /dev/testvg/lv1
重新挂载: mount /dev/testvg/lv1 /mount/lvm
精简动作:umount /dev/testvg/lv1
lvreduce -L 1G -r /dev/testvg/lv1
mount /dev/testvg/lv1 /mount/lvm
9.2.4.3删除实践
逻辑:
解除 挂载:umount /mount/lvm
删除逻辑卷; lvremove /dev/testvg/lv1
删除卷组:vgremove testvg
删除物理卷:pvremove /dev/sdb1 /dev/sdc1 /dev/sdd1
删除指定pv:
数据转移:pvmove /dev/sdb1
移出vg:vgreduce testvg /dev/sdb1
删除pv: pvremove /dev/sdb1
9.2.4.4lvm快照
定位:对逻辑卷(LV)进行备份或创建数据的时间点副本
基本流程:
准备工作:lvs /dev/testvg/lv1
创建快照:lvcreate -n lv1_snapshot -s -L 100M -p r /dev/testvg/lv1
挂载快照:mount /dev/testvg/lv1_snapshot /mount/lvm_snapshot/
备份数据:对数据进行还原操作
恢复数据:
取消挂载:umount /mount/lvm umount /mount/lvm_snapshot
恢复数据:lvconvert --merge /dev/testvg/lv1_snapshot
测试效果:mount /dev/testvg/lv1 /mount/lvm
10.1.1网络分层
分层的目与意义
简化设计:
通过将复杂的网络通信过程分解为若干个相对独立、功能明确的层次,可以简化网络的设计、实现和维 护。
模块化:
每一层都实现一种相对独立的功能,降低系统的复杂度,便于开发人员理解和实现。
可扩展性:
各层之间界面清晰,易于添加新的功能或协议,提高网络的扩展性。
灵活性:
各层功能的精确定义独立于具体的实现方法,可以采用最合适的技术来实现。
层次划分的方法
网络的层应当具有相对独立的功能
梳理功能之间的关系,使一个功能可以为实现另一个功能提供必要的服务,从而形成系统的层次结构 为提高系统的工作效率,相同或相近的功能仅在一个层次中实现,而且尽可能在较高的层次中实现 每一层只为相邻的上一层提供服务
OSI七层模型
ISO发布著名的OSI标准定义了网络互联的7层框架
1,物理层: 负责传输比特流,提供物理连接和传输介质,如电缆、光缆等。 包括了针脚、电压、线缆规范、集线器、中继器、主机接口卡等。
2,数据链路层: 在相邻的两个节点之间建立、维持和释放数据链路,进行差错控制和流量控制。 例如以太网、无线局域网(Wi-Fi)和通用分组无线服务(GPRS)等。
3,网络层: 为分组交换网上的不同主机提供通信服务,实现网络互联和路由选择。 例如:互联网协议(IP)等。
4,传输层: 为应用程序提供端到端的通信服务,确保数据在传输过程中的完整性和可靠性。 例如:传输控制协议(TCP)等。
5,会话层: 负责建立、管理和终止会话,实现数据同步等功能。
6,表示层: 负责数据的表示和转换,确保数据在不同系统之间的兼容性。
7,应用层:为应用软件提供网络服务,如文件传输、电子邮件等。 例如: HTTP、HTTPS、FTP、TELNET、SSH、SMTP、POP3、MySQL等
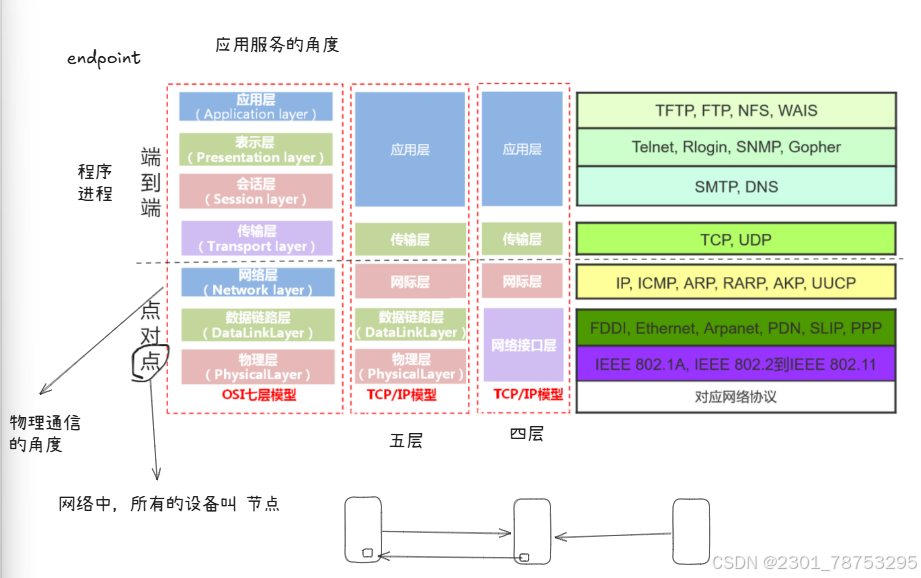
OSI七层:
应用层: 应用软件生成的数据
表示层: 数据的表示和转换
会话层:
传输层: 端口 --- 传输协议 TCP|UDP
网络层: 路由器 IP
数据链路层:网卡 身份表示 MAC
物理层: 网卡 ,网络 ,等设备
TCP/IP四层模型
1,网络接口层(相当于OSI的物理层和数据链路层):负责物理连接和数据链路层的功能,如帧的封装和解封装 等。
2,网络层:与OSI模型的网络层功能相同,负责路由选择和分组转发。
3,传输层:与OSI模型的传输层功能相同,负责端到端的数据传输和流量控制。
4,应用层:与OSI模型的应用层功能相同,为用户提供网络服务,如HTTP、FTP等。
10.1.2组网设备
常见的组网设备包括路由器(Router)、交换机(Switch)、集线器(Hub)、中继器(Repeater) 以及线缆等,它们在构建和管理网络中发挥着各自独特的作用。
超五类线:
传输带宽为100MHZ近距离情况下传输速率可达1000Mbps,具有衰减小,串扰少,比五类线增加了近端串音功率和测试要求,所以它是当前应用最为广泛的网线
六类线:
传输带宽为250MHZ最适用于传输速率为1Gbps的应用改善了在串扰以及回波损耗方面的性能这一点对于新一代全双工的高速网络应用而言是极重要的还有一个特点是在4个双绞线中间加了十字形骨架
超六类线:
超六类线是六类线的改进版,同样是ANSI/TIA-568C.2和ISO/IEC 11801超六类/EA级标准中规定的一种双绞电缆主要应用于万兆网络中传输频率500MHZ 最大传输速度也可达10Gbpas,在外部串扰等方面有较大改善
目前使用范围最广的是超五类,六类等网线
10.1.3 分层网络
层次划分与功能
核心层:
位于网络架构的最顶层,负责告诉转发数据包,提供网络之间的连接。核心层设备通常具有高雄能和高速转发能力以确保网络的高吞吐量和低延迟。
汇聚层:(也称为分发层或会聚层)
位于核心和接入层之间,负责处理和分发来自接入层的数据,并将其发送到核心层。汇聚层设备需要具有较高的处理能力,因为他们需要进行更复杂的决策,如基于网络策略的路由选择。汇聚层还负责实施安全策略和服务质量(QoS)控制,以及流量聚合和分发。
接入层(也称边缘层):
位于网络的最外层,扶着连接终端用户设备,如电脑,手机和其他网络设备。接入层设备通常处理大量的低速,低容量的连接,并提供各种服务,如动态主机配置协议(DHCP)和网络地址转换(NAT)。
·应用场景:
分层网络架构广泛应用与各种网络环境中,包括企业网络,数据中心,服务提供商网络等。在企业网络中,分层网络架构可以帮助企业实现网络隔离,优化性能和增强安全性。在数据中心中,分层网络架构可以提高网络的可靠性和性能,满足高负载和实施性要求。在服务提供商网络中,分层网络架构可以为不同用户提供独立的虚拟网络环境,满足其特定的网络需求。
10.1.4应用端
TCP/IP
TCP/IP往往指的是网络层和传输层
TCP/IP传输控制协议/因特网互联协议,由于这两个协议在传输层和网络层用的非常的多,所以将这两者提取出来作为传输层+网络层的通信功能代号。所以说,我们一般说的TCP/IP 其实是一个protocol stack,包括TCP,IP,UDP,ICMP,RIP,TELNET,FTP,SMTP等许多协议。
TCP协议是一种面向连接的,可靠的,基于字节流的传输层通信协议它通常与IP一起使用构成了互联网中最核心的网络协议之一即TCP/IP协议簇。TCP协议在传输数据之前,会先建立一条虚拟的连接,然后会在这条连接上可靠的传输数据,并在数据传输结束后释放连接。
数据传输:
TCP端口是数据传输的通道,它允许不同进程之间的数据传输。在TCP连接建立后,数据可以通过端口在 客户端和服务器之间传输。网络控制 流量控制 数据完整性
服务标识:
每个TCP端口都对应一个特定的服务或应用程序。通过端口号,客户端可以请求连接到特定的服务。
安全性:
TCP端口的安全性对于整个网络通信至关重要。通过限制哪些端口可以打开和哪些数据可以通过这些端口 传输,可以提高系统的安全性。
端口信息:
常用服务及端口对应关系 cat /etc/services
查看非特权用户可以使用起始端口
cat /proc/sys/net/ipv4/ip_unprivileged_port_start
查看客户端动态端口起始
cat /proc/sys/net/ipv4/ip_local_port_range
10.1.5
三开四断
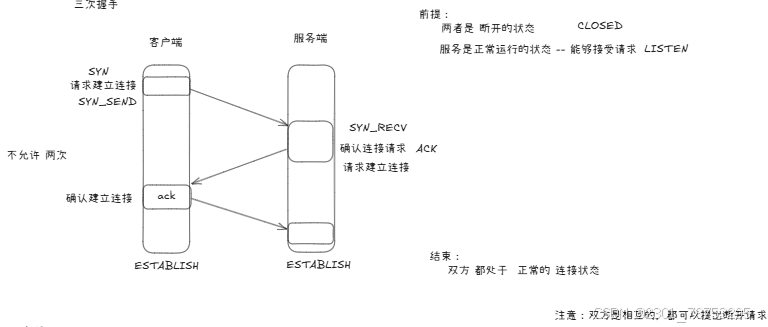
三次握手
第一次握手:
A首先向B发起连接,这时TCP头部中的SYN标识位值为1,然后选定一个初始序号seq=x(一般是随机 的),消息发送后,A进入SYN_SENT状态,SYN=1的报文段不能携带数据,但要消耗一个序号。
第二次握手:
B收到A的连接请求后,同意建立连接,向A发送确认数据,这时TCP头部中的SYN和ACK标识位值均为1, 确认序号为ack=x+1,然后选定自己的初始序号seq=y(一般是随机的),确认消息发送后,B进入SYN_RCVD 状态,与连接消息一样,这条消息也不能携带数据,同时消耗一个序号。
第三次握手:
A收到B的确认消息后,需要给B回复确认数据,这时TCP头部中的ACK标识位值为1,确认序号是 ack=y+1,自己的序号在连接请求的序号上加1,也就是seq=x+1,此时A进入ESTABLISHED状态,当B收到A 的确认回复后,B也进入ESTABLISHED状态,至此TCP成功建立连接,A和B之间就可以通过这个连接互相发送 数据了。
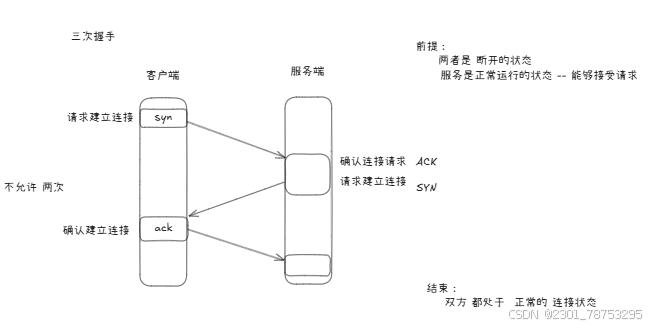
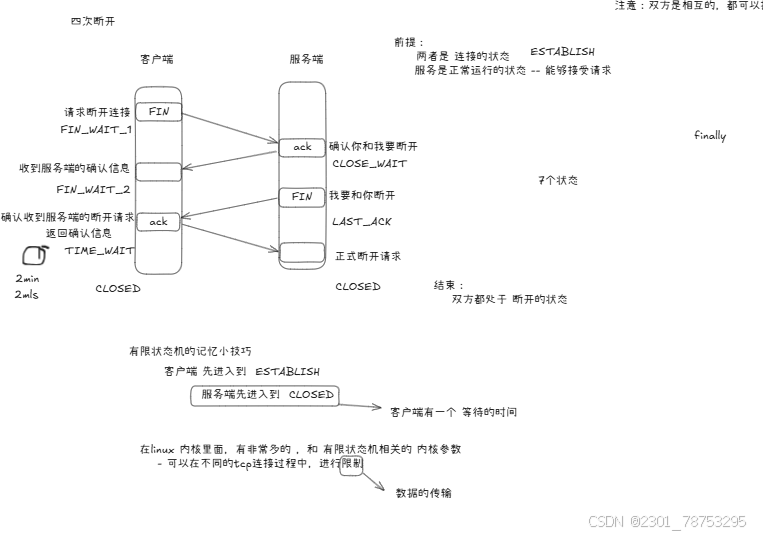
四次断开
第一次挥手:
A首先向B发送断开连接消息,这时TCP头部中的FIN标识位值为1,序号是seq=m,m为A前面正常发送数 据最后一个字节序号加1得到的,消息发送后A进入FNI_WAIT_1状态,FIN=1的报文段不能携带数据,但要消 耗一个序号。
第二次挥手:
B收到A的断开连接请求需要发出确认消息,这时TCP头部中的ACK标识位值为1,确认号为ack=m+1,而 自己的序号为seq=n,n为B前面正常发送数据最后一个字节序号加1得到的,然后B进入CLOSE_WAIT状态,此 时就关闭了A到B的连接,A无法再给B发数据,但是B仍然可以给A发数据(此处存疑),同时B端通知上方应用 层,处理完成后被动关闭连接。然后A收到B的确认信息后,就进入了FIN_WAIT_2状态。
第三次挥手:
B端应用层处理完数据后,通知关闭连接,B向A发送关闭连接的消息,这时TCP头部中的FIN和ACK标识位 值均为1,确认号ack=m+1,自己的序号为seq=k,(B发出确认消息后有发送了一段数据,此处存疑),消息 发送后B进入LAST_ACK状态。
第四次挥手:
A收到B的断开连接的消息后,需要发送确认消息,这是这时TCP头部中的ACK标识位值为1,确认号 ack=k+1,序号为m+1(因为A向B发送断开连接的消息时消耗了一个消息号),然后A进入TIME_WAIT状态, 若等待时间经过2MSL后,没有收到B的重传请求,则表明B收到了自己的确认,A进入CLOSED状态,B收到A的 确认消息后则直接进入CLOSED状态。至此TCP成功断开连接。
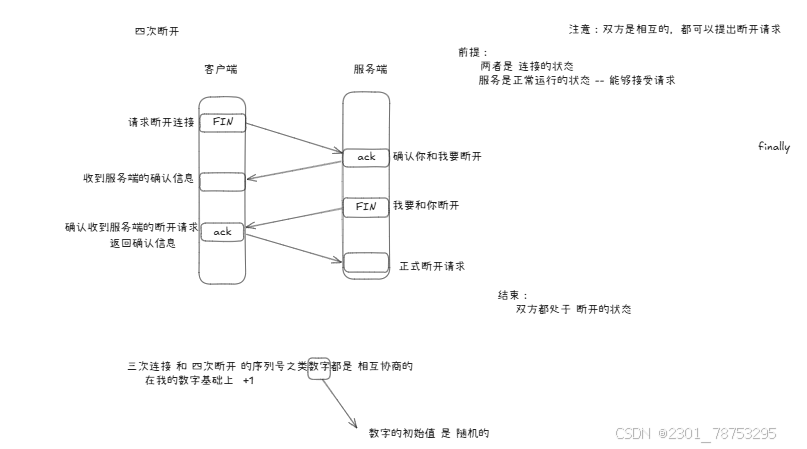
常见面试问题:
1.三次握手能不能减少一次
2.四次断开能不能减少一次
回答:
1.不能
2.TCP协议是可靠性连接请求连接和断开连接都是双方需要确认的少一次都不行
10.1.6有限状态机
简介:
TCP有限状态机【FSM:Finite State Machine】是一个数学模型,用于描述TCP连接在生命周期内的 各种状态以及状态之间的转换。这些状态包括初始状态、连接建立状态、数据传输状态和连接关闭状态等。每 个状态都有特定的行为和条件,当满足特定条件时,TCP连接将从当前状态转换到下一个状态。
作用:
TCP有限状态机的作用是确保TCP连接的可靠性和稳定性。通过定义各种状态和状态转换条件,TCP有限 状态机能够处理各种网络异常情况,如报文丢失、网络拥堵等。同时,它还能够确保数据传输的完整性和顺序 性,避免数据丢失和重复传输。
状态切换:
TCP有限状态机的状态转换是通过各种事件触发的。这些事件包括发送和接收报文段、超时等。例如:
当客户端发送SYN报文后,进入SYN_SENT状态。
当服务端接收到SYN报文并发送SYN+ACK报文后,进入SYN_RCVD状态。
当客户端接收到SYN+ACK报文并发送ACK报文后,进入ESTABLISHED状态。
当一方发送FIN报文后,进入FIN_WAIT_1状态或CLOSE_WAIT状态(取决于发送方是客户端还是服务 端)。
当另一方接收到FIN报文并发送ACK报文后,发送方进入FIN_WAIT_2状态或LAST_ACK状态(取决于发 送方是客户端还是服务端)。
当接收方发送完所有剩余数据并发送FIN报文后,进入TIME_WAIT状态或CLOSED状态(取决于发送方是 客户端还是服务端)。
10.1.7进程间通信
Socket简介:
Socket是网络编程中一种重要的通信机制,它提供了在网络上进行通信的接口。Socket本质上是一种通 信的端点,它在网络上标识了一个通信链路的两端,并提供了通信双方所需的接口和功能。 通过使用Socket,可以在不同计算机之间建立连接,并进行数据的传输和交换(网络通信)。
类型:
TCP Socket: 基于TCP(传输控制协议),使用三次握手建立连接,确保数据的可靠性和顺序性。TCP是一种面向连接 的协议,适用于需要可靠传输的场景。 UDP Socket: 基于UDP(用户数据报协议),无需建立连接,提供了简单的数据传输服务,但不保证数据的可靠性和顺 序性。UDP适用于一些实时性要求高、允许一定数据丢失的应用场景。
工作原理:
客户端:
首先创建一个Socket对象,用于与服务器端建立连接。 然后调用connect方法来连接服务器, - 并通过send方法发送数据, - recv方法接收数据。 通信结束后,调用close方法来关闭连接并释放资源。
服务器端:
首先创建一个Socket对象,用于监听客户端的连接请求。 然后将Socket对象绑定到一个特定的地址和端口上,以便客户端能够连接到该地址和端口。 接着调用listen方法来开始监听客户端的连接请求。 一旦客户端发起连接请求,服务器端会调用accept方法来接受连接, 并创建一个新的Socket对象用于与该客户端进行通信。 之后,服务器端就可以通过新创建的Socket对象来接收和发送数据了。
常见方法
系统信号:用于通知进程某个事件已经发生
管道: 用于具有亲源关系进程间的数据传递
套接字:不仅可用于一台计算机上的进程间通信,还可以用于不同计算机之间的网络通信
文件锁:用于进程间对共享文件的同步访问
消息队列:允许一个或多个进程向它写入或从中读取信息
信号灯:用于进程间的同步与互斥
10.1.8网络层协议
主要功能:
定义逻辑地址:网络层定义了基于IP协议的逻辑地址,即IP地址,用于标识网络中的设备。 连接不同网络:网络层能够连接不同的网络媒介类型,实现不同网络之间的通信。
路径选择:网络层负责选择数据通过网络的最佳路径,确保数据能够高效、准确地到达目的地。
数据包格式:网络层规定了IP数据包的格式,包括固定部分和可变长部分,用于封装和传输数据。
核心协议:
IP协议:
IP(Internet Protocol,互联网协议)是网络层的核心协议,它定义了数据包的格式、寻址方式和 路由选择等。IP协议使得不同网络之间的设备能够进行通信,是互联网的基础。
ICMP协议:
ICMP(Internet Control Message Protocol,互联网控制消息协议)是一个“错误侦测与回馈机 制”,用于发送错误和控制消息。ICMP协议封装在IP数据包中,用于测试两台主机之间的连通性,如ping命令 就使用了ICMP协议。
ARP协议:
ARP(Address Resolution Protocol,地址解析协议)用于将IP地址解析成MAC地址,实现局域网 中主机之间的通信。ARP协议通过发送ARP请求和ARP应答消息,使得设备能够获取对方的MAC地址,从而进行 数据传输。 注意: mac 属于物理地址,mac 地址不可变,一出厂就写死,标识惟一设备
10.1.9 ip地址
IP地址由两部分组成:
- 网络ID:标识网络,每个网段分配一个网络ID,处于高位
- 主机ID:标识单个主机,由组织分配给各设备,处于低位
IP地址是指互联网协议地址又称网络协议地址。IP地址是IP协议提供的一种统一的地址格式,为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异
作用
网络寻址:IP地址是互联网上的设备惟一标识符,用于路由数据包并确保他们到达正确的目的地
广域网连接:IP地址允许设备在全球范围内进行广域网连接,包括互联网,公司内部网络和云服务
IPV4,即互联网协议第4版,是互联网工程任务组(IETF)在1981年开发完成的网络协议版本
IPV4使用32位二进制数字表示IP地址,通常呈现为4个由点分开的十进制整数,每个整数的取值范围为0到255
IPV4的地址空间有限,只有约42亿个地址是可用的,随着互联网的快速发展IPV4地址空间在数年内就会被消耗完。
特点:
IPV4的地址易于理解和配置,已经广泛应用与各种网络环境
IPV4的地址格式已于扩展,允许不同的设备使用同一IP地址(通过NAT等技术实现)。
IPV4的安全性有限,缺乏内置的安全保护机制
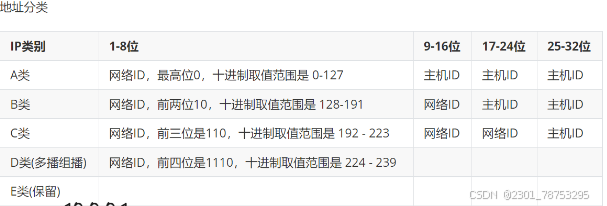
IPV4地址按用途和范围分为A,B,C,D,E类,其中A类用于大型网络,B类用于中型网络,C类用于小型网络,D类用于组播,E类保留为实验用途
IP地址分类是根据IP地址的范围划分为不同的类别,共有5个不同的IP地址分类,分别是A类、B类、C类、D类和E类。
A类IP地址范围为1.0.0.0到126.0.0.0,用于较大规模的网络,可以分配给全球范围内的大型机构和公司。
B类IP地址范围为128.0.0.0到191.255.0.0,用于中等规模的网络,分配给大中型机构和公司。
C类IP地址范围为192.0.0.0到223.255.255.0,用于小型网络,分配给小型公司和组织。
D类IP地址范围为224.0.0.0到239.255.255.255,用于多播(Multicast)通信,用于向多个目标发送数据。
E类IP地址范围为240.0.0.0到255.255.255.255,保留作为未分配的地址空间,用于特殊用途。
通过IP地址分类,可以对不同规模的网络进行有效的管理和划分。
IPV4使用32位二进制数表示IP地址,通常呈现为4个由点分开的十进制整数每个整数的取值范围为0到255它有两种表现样式:
表现形式1:
IPADDR=192.168.1.1
NETMASK=255.255.255.0
表现形式2:
IPADDR=192.168.1.1/24
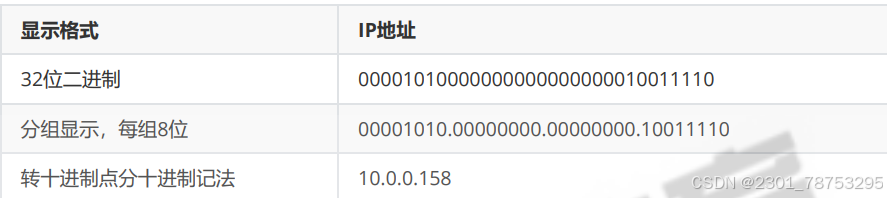
IP地址
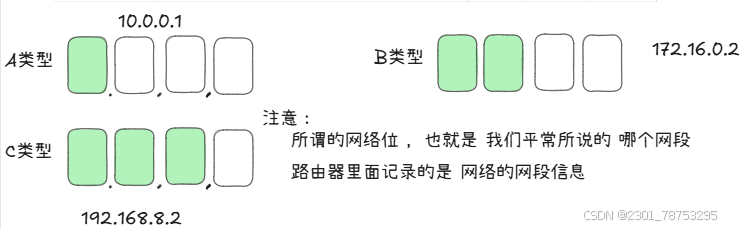
IP地址由两部分组成
-网络ID:标识网络,每个网段分配一个网络ID,处于高位
-主机ID:标识单个主机,由组织分配给各设备,处于低位
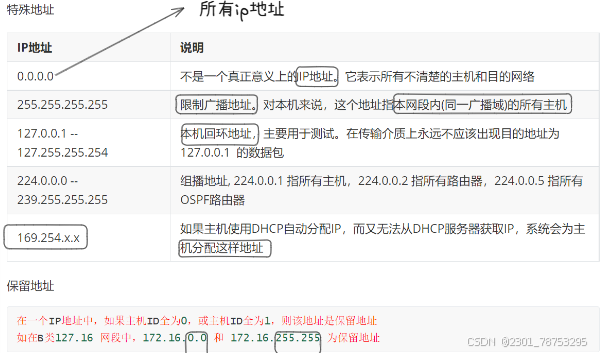
特殊地址;
10.2.1子网掩码
简介:
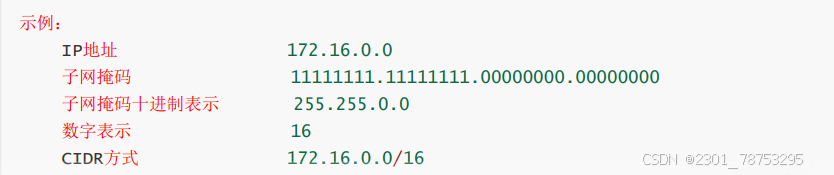
CIDR是互联网中一种新的寻址方式,旨 在更高效地分配和管理IP地址空间。
CIDR无类域间路由表示法:IP/网络ID位数,如:172.16.0.100/16
CIDR通过变化的子网掩码来允许更加精细地划分和分配IP地址。子网掩码定义了IP地址中哪部分属于网 络地址,哪部分属于主机地址
在CIDR中子网掩码不再局限于传统的A类、B类、C类地址的固定格式(如255.0.0.0、 255.255.0.0、255.255.255.0等),而是可以根据需要灵活变化,从而创建包含不同数量主机的子网。
CIDR采用斜线记法来表示IP地址和网络ID的位数,即“IP地址/前缀长度”。前缀长度表示了网络前缀中 包含的连续比特数,也就是子网掩码中1的个数。例如,10.0.0.0/8表示子网掩码为255.0.0.0,对应网段 为10.0.0.0~10.255.255.255。
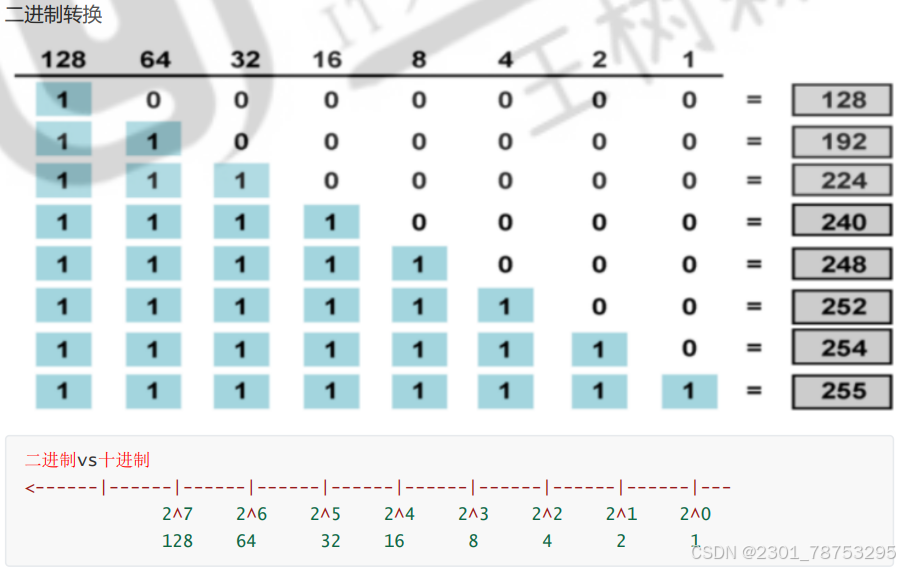
子网掩码:
netmask子网掩码:
32位或128位(IPv6)的数字,和IP成对使用,用来确认IP地址中的网络ID和主机ID,对应网络ID的 位为1,对应主机ID的位为0,范例:255.255.255.0 ,表现为连续的高位为1,连续的低位为0
相关公式:
- 一个网络的最多的主机数 =2 ^ 主机ID位数 - 2
- 网络(段)数 = 2 ^ 网络ID中可变的位数
- 网络ID = IP 与 netmask
10.2.2 子网划分
划分子网:将一个大的网络(主机数多)划分成多个小的网络(主机数少),主机ID位数变少,网络ID位数变 多,网络ID位向主机ID位借n位,将划分2^n个子网
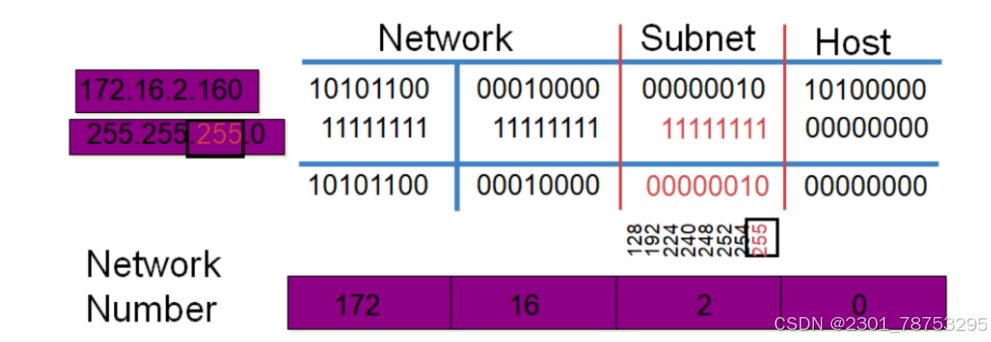
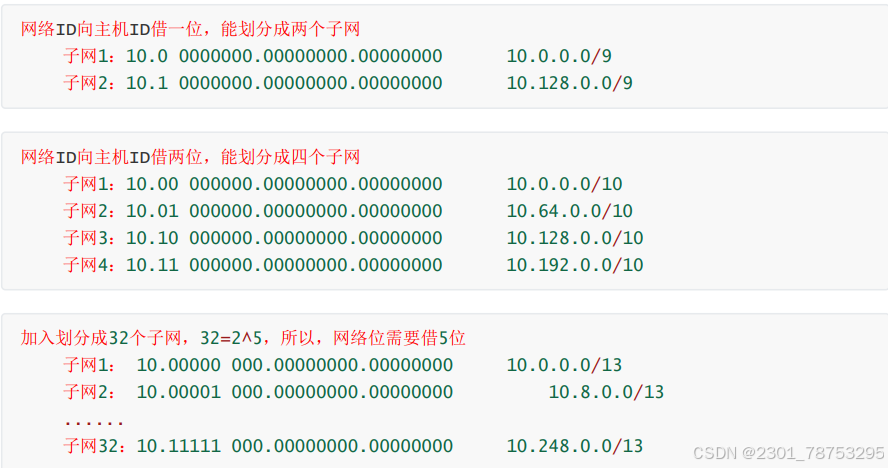
示例1:10.0.0.0/8
主机数: 2^24-2=
主机范围:10.0.0.1 -- 10.255.255.254

黑客帝国的屏保效果
root@ubuntu24:~# apt install cmatrix
root@ubuntu24:~# cmatrix
root@ubuntu24:~# cmatrix -C blue | red | yellow

好莱坞大片的屏保效果
root@ubuntu24:~# apt install hollywood
root@ubuntu24:~# hollywood
面试题:我在创建用户的时候,如何为新创建的用户,提供一个通用的提示文件
在 /etc/skel/ 目录下提供一个提示文件,这样每个新创建用户,都会在自动包含该文件。
Linux中的目录和文件的权限区别?分别说明读,写和执行权限的区别
目录初始权限是755 文件初始权限是644 权限与umask默认值022(用户文件创建掩码)紧密相关
新文件的权限为666 - 022 = 644,
新目录的权限为777 - 022 = 755。
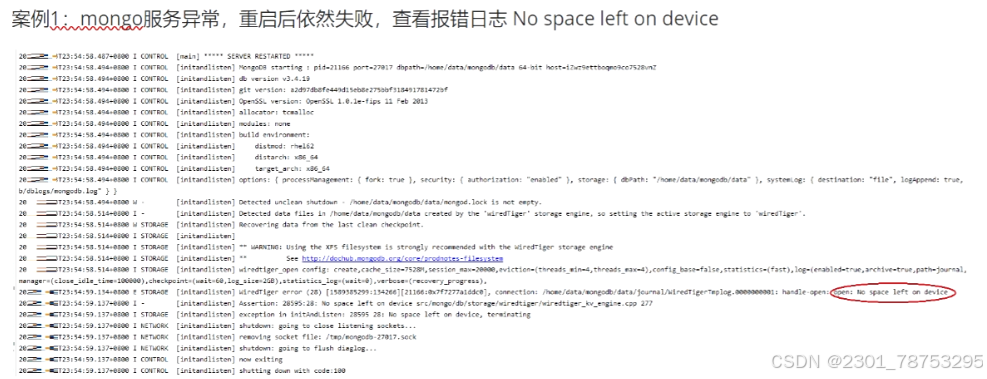
MongoDB服务启动异常
磁盘空间有但是显示没内存了 是inode号用完了
df -h 查看存储空间使用情况
df -i 查看inode号使用情况
1 Linux下一个每一个文件就会占用一个inode资源
2 inode资源数量是在格式化磁盘的时候就指定的(不指定的话,会有默认值)
3 如果某个磁盘的inode资源用尽,即便磁盘有空间,也不能进行任何文件或者文件夹的新增 4 删除一个文件夹或者文件就能释放一个inode资源 根据上面的过程分析,应该是/dev/vdb1在进行格式化的时候,用户不小心指定了一个比较小的inode 的范围值,导致明明有400G的存储空间,但是因为inode值过小,才65万个,导致inode空间没有了,从而无 法再该块空间进行文件增加了 -- 因为MongoDB服务启动的时候,应用到了该目录
解决方法:
1 删除不用的文件和文件夹,释放被占用的inode
2 格式化新的磁盘,指定一个大一点的inode值
3 迁移部分数据到新的磁盘上。
4 根据服务配置文件的属性配置,对新磁盘的目录结构进行软连接配置,避免大规模数据迁移导致的配置路径 异常。

Jeenkins应用异常
jenkins运行的时候发现jenkins执行项目任务报错No space left on device
杀程序
1 df -h 查看磁盘占用空间大小
2 cd /var/log/jenkins 检查jenkins日志数据
3 du -sh https://blog.csdn.net/2301_/article/details/*
4 rm -f 删除相关日志文件
5 df -h 再次查看磁盘占用空间大小
如果空间任被占用是因为是虽然文件删除了,但是服务程序运行的时候,依然在使用这些文件,也就 是说,这些文件的inode文件一直被占用,可以通过 lsof 来检测死文件效果
6 lsof | gerg delete 删除大量jenkins占用的进程id
7 ki11 -9 2397
8 systemctl restart jenkins 成功起jenkins服务
问题改善
对于jenkins服务器上,产生非常多日志问题的原因就找到了,因为程序上启用了DNS解析的功能,我们 只需要直接进入jenkins 系统日志管理页面,将javax.jmdns日志级别调整为 OFF即可。 这样,后期的设备没有空间的问题就彻底解决了。
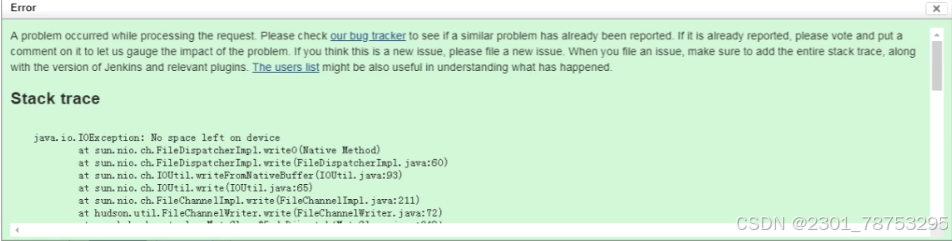

软件安装失败
到此这篇redhat linux 7.2系统安装详细过程(怎么安装redhat linux)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!
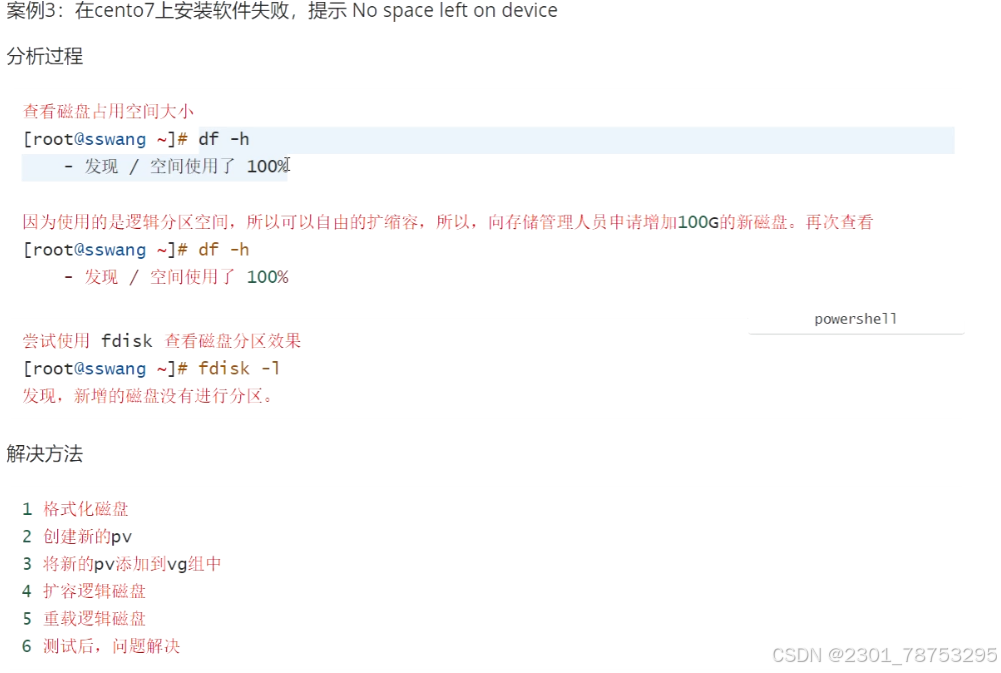
df -h 查看磁盘占用空间大小 如果满了的话
因为使用的是逻辑分区空间,所以可以自由的扩缩容,所以,向存储管理人员申请增加100G的新磁盘。再次查看
df -h 查看磁盘占用空间大小 还满的话
fdisk -i 查看磁盘分区效果 发现,新增的磁盘没有进行分区。对的话
解决办法
1 格式化磁盘
2 创建新的pv
3 将新的pv添加到vg组中
4 扩容逻辑磁盘
5 重载逻辑磁盘
6 测试后,问题解决fenqufen'qu
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/qdvuejs/55446.html