
Linux驱动调试主要有以下几种方法:
1、利用printk。
2、查看OOP消息。
3、利用strace。
4、利用内核内置的hacking选项。
5、利用ioctl方法。
6、利用/proc 文件系统。
7、使用kgdb。
这是驱动开发中最朴实无华,同时也是最常用和有效的手段。scull驱动的main.c第338行如下,就是使用printk进行调试的例子,这样的例子相信大家在阅读驱动源码时随处可见。
printk的功能与我们经常在应用程序中使用的printf是一样的,不同之处在于printk可以在打印字符串前面加上内核定义的宏,例如上面例子中的KERN_ALERT(注意:宏与字符串之间没有逗号)。
第一个6表示级别高于(小于)6的消息才会被输出到控制台,
第二个4表示如果调用printk时没有指定消息级别(宏)则消息的级别为4,
第三个1表示接受的最高(最小)级别是1,
第四个7表示系统启动时第一个6原来的初值是7。
因此,如果你发现在控制台上看不到你程序中某些printk的输出,请使用
echo 8 > /proc/sys/kernel/printk来解决。
我们在复杂驱动的开发过程中,为了调试会在源码中加入成百上千的printk语句。
而当调试完毕形成最终产品的时候必然会将这些printk语句删除。
最要命的是,如果我们将调试用的printk语句删除后,用户又报告我们的驱动有bug,所以我们又不得不手工将这些上千条的printk语句再重新加上。所以,我们需要一种能方便地打开和关闭调试信息的手段。看看scull驱动或者leds驱动的源代码吧!
这样一来,在开发驱动的过程中,如果想打印调试消息,我们就可以用PDEBUG(“address of i_cdev is %p ”, inode->i_cdev);,如果不想看到该调试消息,就只需要简单的将PDEBUG改为PDEBUGG即可。而当我们调试完毕形成最终产品时,只需要简单地将第1行注释掉即可。
上边那一段代码中的__KERNEL__是内核中定义的宏,当我们编译内核(包括模块)时,它会被定义。当然如果你不明白代码中的…和是什么意思的话,就请认真查阅一下gcc关于预处理部分的资料吧!如果你实在太懒不愿意去查阅的话,那就充当VC工程师把上面的代码copy到你的代码中去吧。
OOP意为惊讶。当你的驱动有问题,内核不惊讶才怪:嘿!小子,你干吗乱来!好吧,就让我们来看看内核是如何惊讶的。
根据faulty.c(编译出faulty.ko,并 insmod faulty.ko。执行echo yang >/dev/faulty,结果内核就惊讶了。内核为什么会惊讶呢?因为faulty驱动的write函数执行了*(int *)0 = 0,向内存0地址写入,这是内核绝对不会容许的。
1行惊讶的原因,也就是报告出错的原因。
2-4行是OOP信息序号。
5行是出错时内核已加载模块。
6行是发生错误的CPU序号。
7-15行是发生错误的位置,以及当时CPU各个寄存器的值,这最有利于我们找出问题所在地。
16行是当前进程的名字及进程ID。
17-23行是出错时,栈内的内容。
24-29行是栈回溯信息,可看出直到出错时的函数递进调用关系(确保CONFIG_FRAME_POINTER被定义)。
30行是出错指令及其附近指令的机器码,出错指令本身在小括号中。
反汇编faulty.ko( arm-linux-objdump -D faulty.ko > faulty.dis ;cat faulty.dis)可以看到如下的语句如下:
定位出错位置以及获取相关信息的过程:
出错代码是faulty_write函数中的第5条指令((0xbf00608c-0xbf00607c)/4+1=5),该函数的首地址是0xbf00607c,该函数总共6条指令(0×18),该函数是被0xc0088eb8的前一条指令调用的(即:函数返回地址是0xc0088eb8。这一点可以从出错时lr的值正好等于0xc0088eb8得到印证)。调用该函数的指令是vfs_write的第49条(0xc4/4=49)指令。
达到出错处的函数调用流程是:
write(用户空间的系统调用)–>sys_write–>vfs_write–>faulty_write
OOP消息不仅让我定位了出错的地方,更让我惊喜的是,它让我知道了一些秘密:
1、gcc中fp到底有何用处?
2、为什么gcc编译任何函数的时候,总是要把3条看上去傻傻的指令放在整个函数的最开始?
3、内核和gdb是如何知道函数调用栈顺序,并使用函数的名字而不是地址?
4、我如何才能知道各个函数入栈的内容?哈哈,我渐渐喜欢上了让内核惊讶,那就再看一次内核惊讶吧。
执行 cat /dev/faulty,内核又再一次惊讶!
不过这次惊讶却令人大为不解。OOP竟然说出错的地方在vfs_read(要知道它可是大拿们千锤百炼的内核代码),这怎么可能?哈哈,万能的内核也不能追踪函数调用栈了,这是为什么?其实问题出在faulty_read的43行,它导致入栈的r4、r5、r6、fp全部变为了0xffffffff,ip、lr的值未变,这样一来faulty_read函数能够成功返回到它的调用者——vfs_read。但是可怜的vfs_read(忠实的APTCS规则遵守者)并不知道它的r4、r5、r6已经被万恶的faulty_read改变,这样下去vfs_read命运就可想而知了——必死无疑!虽然内核很有能力,但缺少了正确的fp的帮助,它也无法追踪函数调用栈。
有时小问题可以通过监视程序监控用户应用程序的行为来追踪,同时监视程序也有助于建立对驱动正确工作的信心。例如,在看了它的读实现如何响应不同数量数据的读请求之后,我们能够对scull正在正确运行感到有信心。
有几个方法来监视用户空间程序运行。你可以运行一个调试器来单步过它的函数,增加打印语句,或者在 strace 下运行程序。这里,我们将讨论最后一个技术,因为当真正目的是检查内核代码时,它是最有用的。
strace 命令是一个有力工具,它能显示所有的用户空间程序发出的系统调用。它不仅显示调用,还以符号形式显示调用的参数和返回值。当一个系统调用失败, 错误的符号值(例如, ENOMEM)和对应的字串(Out of memory) 都显示。
strace 有很多命令行选项,其中最有用的是
-t 来显示每个调用执行的时间,
-T 来显示调用中花费的时间,
-e 来限制被跟踪调用的类型(例如strace –eread,write ls表示只监控read和write调用),
以及-o 来重定向输出到一个文件。缺省情况下,strace 打印调用信息到 stderr。
strace 从内核自身获取信息。这意味着可以跟踪一个程序,不管它是否带有调试支持编译(对 gcc 是 -g 选项)以及不管它是否被strip过。此外,你也可以追踪一个正在运行中的进程,这类似于调试器连接到一个运行中的进程并控制它。
跟踪信息常用来支持发给应用程序开发者的故障报告,但是对内核程序员也是很有价值的。我们已经看到驱动代码运行如何响应系统调用,strace 允许我们检查每个调用的输入和输出数据的一致性。
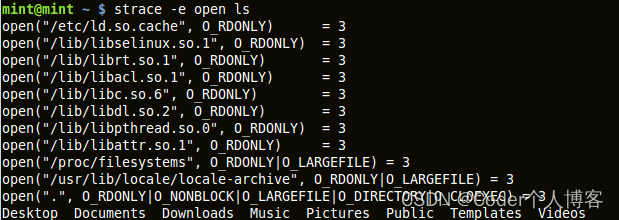
例如,运行命令strace ls /dev > /dev/scull0将会在屏幕上显示如下的内容:
从第一个 write 调用看, 明显地, 在 ls 结束查看目标目录后,它试图写 4KB。但奇怪的是,只有 4000 字节被成功写入, 并且操作被重复。但当我们查看scull 中的写实现,发现它一次最多只允许写一个quantum(共4000字节),可见驱动本来就是期望部分写。几步之后, 所有东西清空, 程序成功退出。正是通过strace的输出,使我们确信驱动的部分写功能运行正确。
作为另一个例子, 让我们读取 scull 设备(使用 wc scull0 命令):
如同期望的, read 一次只能获取 4000 字节,但是数据总量等同于前个例子写入的。
这个例子,意外的收获是:可以肯定,wc 为快速读进行了优化,它因此绕过了标准库(没有使用fscanf),而是直接一个系统调用以读取更多数据。这一点,可从跟踪到的读的行里看到wc一次试图读取16 KB的数据而确认。
内核开发者在make menuconfig的Kernel hacking提供了一些内核调试选项。这些选项有助于我们调试驱动程序,因为当我们启用某些调试选项的时候,操作系统会在发现驱动运行有问题时给出一些错误提示信息,而这些信息非常有助于驱动开发者找出驱动中的问题所在。下面就举几个简单例子。
先启用如下选项:
例如,如果我们忘记了初始化scull驱动中的信号量(将main.c的第717行注释掉),则在open设备scull时只会产生OOP,而没有其它信息提示我们有信号量未初始化,因此此时我们很难定位问题。相反,如果启用了上述选项,操作系统则会产生相关提示信息,使我们知道有未初始化的信号量或者自旋锁。从而,我们就可以去驱动代码中初始化信号量和自旋锁的地方修正程序。
这个测试,我们的意外收获是:信号量的实现,其底层仍然是自旋锁。这与我们之前的大胆推测一致。
Kernel debugging — Spinlock debugging: sleep-inside-spinlock checking (NEW) 可以检查出驱动在获取自旋锁后又睡眠以及死锁等状况
345 ssleep(5);
87 #define usespin
例如,如果第1个进程在获得自旋锁的情况下睡眠(去掉main.c第345行的注释,去掉scull.h第87行的注释),当第2个进程试图获得自旋锁时将死锁系统。但如果启用了上面的选项,则在死锁前操作系统可以给出提示信息。
Magic SysRq key可以在已经死锁的情况下,打印一些有助于定位问题的信息。
魔键 sysrq在大部分体系上都可用,它是用PC 键盘上 alt 和 sysrq 键组合来发出的, 或者在别的平台上使用其他特殊键(详见 ), 在串口控制台上也可用。
一个第三键, 与这2 个一起按下, 进行许多有用的动作中的一个:
例如,在系统死锁的情况下,期望能知道寄存器的值,则可以使用该魔法键。
SysRq : Show Regs
Debug shared IRQ handlers可用于调试共享中断
由于驱动中的ioctl函数可以将驱动的一些信息返回给用户程序,也可以让用户程序通过ioctl系统调用设置一些驱动的参数。
所以在驱动的开发过程中,可以扩展一些ioctl的命令用于传递和设置调试驱动时所需各种信息和参数,以达到调试驱动的目的。如何在驱动中实现ioctl,请参见“驱动程序对ioctl的规范实现”一文
/proc文件系统用于内核向用户空间暴露一些内核的信息。因此出于调试的目的,我们可以在驱动代码中增加向/proc文件系统导出有助于监视驱动的信息的代码。
这样一来,我们就可以通过查看/proc中的相关信息来监视和调试驱动。如何在驱动中实现向/proc文件系统导出信息,请参见《Linux Device Driver》的4.3节。
kgdb是在内核源码中打用于调试内核的补丁,然后通过相应的硬件和软件,就可以像gdb单步调试应用程序一样来调试内核(当然包括驱动)。
至于kgdb如何使用,就请你google吧,实在不行,必应一下也可以。
这是一个基本的调试问题的方法。 我们在程序中怀疑的地方插入print语句来了解程序的运行流程控制流和变量值的改变。 这是一个最简单的技术, 它的缺点。 需要进行程序编辑,添加'print'语句,必须重新编译,重新运行来获得输出。若需要调试的程序比较大,这将是一个耗时费力的方法。
strace拦截和记录系统调用及其接收的信号。对于用户,它显示了系统调用、传递给它们的参数和返回值。strace的可以附着到已在运行的进程或一个新的进程。它作为一个针对开发者和系统管理员的诊断、调试工具是很有用的。它也可以用来当做一个通过跟踪不同的程序调用来了解系统的工具。这个工具的好处是不需要源代码,程序也不需要重新编译。
使用strace的基本语法是:strace 命令
strace有各种各样的参数。可以检查看strace的手册页来获得更多的细节。 strace的输出非常长,我们通常不会对显示的每一行都感兴趣。我们可以用'-e expr'选项来过滤不想要的数据。
用 '-p pid' 选项来绑到运行中的进程.
用'-o'选项,命令的输出可以被重定向到文件。
转存失败重新上传取消
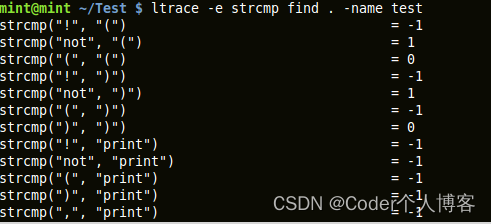
ltrace跟踪和记录一个进程的动态(运行时)库的调用及其收到的信号。它也可以跟踪一个进程所作的系统调用。它的用法是类似与strace。
ltrace command
'-i' 选项在调用库时打印指令指针。
'-S' 选项被用来现实系统调用和库调用
所有可用的选项请参阅ltrace手册。
转存失败重新上传取消
Valgrind是一套调试和分析工具。它的一个被广泛使用的默认工具——'Memcheck'——可以拦截malloc(),new(),free()和delete()调用。换句话说,它在检测下面这些问题非常有用:
1、内存泄露
2、重释放
3、访问越界
4、使用未初始化的内存
5、使用已经被释放的内存等。
它直接通过可执行文件运行。
Valgrind也有一些缺点,因为它增加了内存占用,会减慢你的程序。它有时会造成误报和漏报。它不能检测出静态分配的数组的访问越界问题。
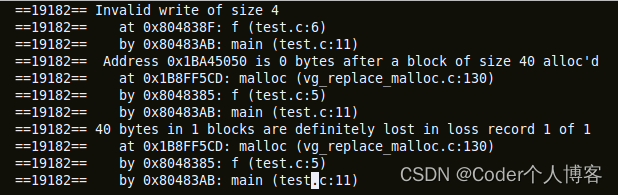
valgrind –tool=memcheck –leak-check=yes test
转存失败重新上传取消
valgrind显示堆溢出和内存泄漏的输出
正如我们在上面看到的消息,我们正在试图访问函数f未分配的内存以及分配尚未释放的内存。
GDB是来自自由软件基金会的调试器。它对定位和修复代码中的问题很有帮助。当被调试的程序运行时,它给用户控制权去执行各种动作, 比如:
1、启动程序
2、停在指定位置
3、停在指定的条件
4、检查所需信息
5、改变程序中的数据 等。
你也可以将一个崩溃的程序coredump附着到GDB并分析故障的原因。
GDB提供很多选项来调试程序。 然而,我们将介绍一些重要的选择,来感受如何开始使用GDB。
如果你还没有安装GDB,可以在这里下载:GDB官方网站。
如果你在Linux下碰到比较复杂的性能问题,记住,按照下面的4步走,会让你解决linux性能问题的时候事半功倍。
1、先用top命令看linux系统总体的cpu使用情况。如果有异常,用pidstat -u查看细粒度的各个进程的cpu使用情况;否则,转向下一步。
2、用vmstat命令查看linux系统总体的内存使用情况。如果有异常,用smem查看细粒度的各个进程的内存使用情况;否则,转向下一步。
3、用iostat命令查看linux系统总体的IO使用情况。如果有异常,用iotop查看细粒度的各个进程的IO使用情况;否则,转向下一步。
4、用iftop命令查看linux系统总体的网络使用情况。如果有异常,用nethogs查看细粒度的各个进程的网络带宽使用情况。
Linux下应用程序的cpu使用率较高,如何找到是哪段代码引起的?给你介绍这5个linux工具试试看!
1、先看整体。通过top命令查看linux系统整体的cpu使用率和整体的平均负载;
2、然后再看进程个体。通过pidstat -u 1查看linux下各个进程的cpu使用率,找到可疑进程;
3、pstree -p {pid}查看进程的继承关系,这一步是可选的,但可以让我们清楚了解进程的族谱;
4、strace -f -p {pid} 追踪进程的系统调用情况,确认是否存在频繁的系统调用?如果存在,就说明找到了根本原因;否则,继续下一步;
5、pstack {pid}显示应用程序的实时的函数调用堆栈,从而找出性能瓶颈点;
到此这篇linux驱动开发常用的调试技术(linux驱动调试方法)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/kotlinkf/66327.html