
由复旦大学计算机科学技术学院王鹏老师、汪卫老师、王泽宇同学和法国巴黎大学的Themis Palpanas教授、王齐童同学合作的论文《Dumpy: A Compact and Adaptive Index for Large Data Series Collections》被ACM SIGMOD 2023(International Conference on Management of Data)接收, ACM SIGMOD 会议关注数据库管理系统和数据管理技术的原理、技术和应用,是数据库领域具有最高学术地位的国际性学术会议。
论文针对超大规模(TB级)的时间序列数据相似性索引提出新方法,大幅提高了索引的近似查询精度、查询性能和构建速度。相似性查询是许多基于距离的时间序列数据挖掘算法的基础,论文方法的提出将直接增强这些算法的精确性、效率和可扩展性,并使得未来在大数据集上基于距离的新方法的提出成为可能。

论文首次指出了当前时间序列数据相似性查询索引的两个结构性问题: (1) 固定扇出的树结构不能在索引节点的质量和紧凑性上达到最优的权衡,严重限制了索引的准确性和效率; (2)不能有效处理倾斜数据。为了克服这些问题,论文创新性地设自适应多叉索引,即根据父节点的数据分布决定扇出大小与分裂决策,使得子节点内部数据邻近性和节点负载率同时达到更高的水平。
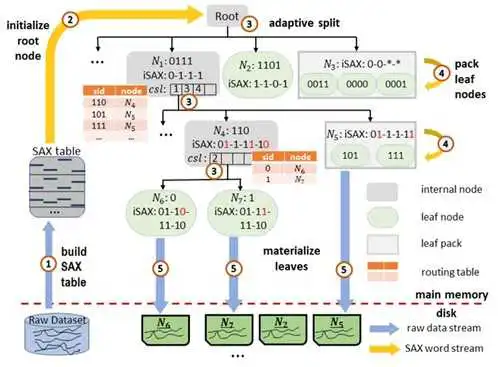
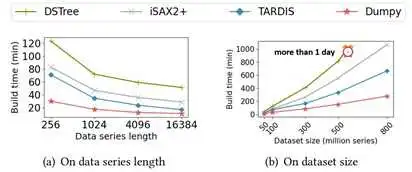
另一方面,论文针对磁盘读写特性设计了高效的索引构建和搜索工作流,在不引入额外代价的情况下,充分利用全局信息控制索引构造,并设计了能够保留邻近性的节点合并算法,使得构建和查询过程中的随机I/O次数大量减少。实验表明,即使在普通性能机器的资源配置上,论文的方法也能有几乎线性的可伸缩性。并且,Dumpy在精确和近似相似性查询方面,性能均优于同类算法iSax、DSTree、Tardis等。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/jszy-gxgz/56317.html