
1.简介
namenode是整个文件系统的管理节点。他维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
2.NameNode的工作特点
NameNode始终在内存中保存metedata,用于处理“读请求”,到有“写请求”到来时,NameNode首先会写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回。
Hadoop会维护一个人fsimage文件,也就是NameNode中metedata的镜像,但是fsimage不会随时与NameNode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary NameNode就是用来合并fsimage和edits文件来更新NameNode的metedata的。
3.Namenode作用
- 管理、维护文件系统的元数据/名字空间/目录树 管理数据与节点之间的映射关系(管理文件系统中每个文件/目录的block块信息)
- 管理DataNode汇报的心跳日志/报告
- 客户端和DataNode之间的桥梁(元数据信息共享)
DataNode的目录结构
和namenode不同的是,datanode的存储目录是初始阶段自动创建的,不需要额外格式化。
DataNode作用
- 负责数据的读写操作
- 周期性的向NameNode汇报心跳日志/报告
- 执行数据流水线的复制
通俗的来说就是nameNode通过读取我们的配置来配置各个节点所在的机架信息(节点ip和swap交换机
什么时候会用到机架感知?
NameNode分配节点的时候 (数据的流水线复制和HDFS复制副本时)
HDFS副本存放机制
第1个副本存放在客户端,如果客户端不在集群内,就在集群内随机挑选一个合适的节点进行存放;
第2个副本存放在与第1个副本同机架且不同节点,按照一定的规则挑选一个合适的节点进行存放;
第3个副本存放在与第1、2个副本不同机架且距第1个副本逻辑距离最短的机架,按照一定的规则挑选一个合适的节点进行存放;
hadoop 视硬件设备经常损坏为常态
为了防止硬件损坏导致系统不可用,所以构建多副本机制
数据写入之后进行数据首次校验,文件系统周期性进行校验,防止数据丢失。
读取数据之前进行数据校验,若两个校验相同,那么表示数据没有丢失,开始读取数据。
若两个校验不相同,那么表示数据有部分丢失,换到其他节点(相同副本的节点)读取数据。
HDFS 适用场景 一次写入,多次读出的场景,支持文件追加,但不支持在文件中间修改。
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
1、海量数据存储:
HDFS可横向扩展,其存储的文件可以支持PB级别或更高级别的数据存储。
2、高容错性:
数据保存多个副本,副本丢失后自动恢复。
可构建在廉价价(与小型机大型机对比)的机器上,实现线性扩展。
当集群增加新节点之后,namenode也可以感知,进行负载均衡,将数据分发和备份数据均衡到新 的节点上。每个节点磁盘使用容量百分比的差异可以人工设置。
线性扩展:随着节点数量的增加,集群的性能-计算性能和存储性能都会有所增加
负载均衡:集群可将原本使用容量较高的节点上的数据自动写入新的节点上,达到所有节点容量均匀
3、大文件存储:
数据分块存储,将一个大块的数据切分成多个小块的数据。
1、不能做到低延迟数据访问:
由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延 迟,所以对于低延迟访问数据的 业务需求不适合HDFS。
2、不适合大量的小文件存储 :
由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量。
元数据信息中每个文件、目录和数据块的存储信息大约占150字节。(1G 数据存储的元数据信息占用150字节 ,1M的数据元数据信息占用150字节)
受限于内存,元数据信息的存储机制导致无论数据多大,元数据信息中描述这个数据的信息都是150字节。
3、修改文件:
HDFS适合一次写入,多次读取的场景。对于上传到HDFS上的文件,不支持修改文件。Hadoop2.0虽然支持了文件的追加功能,但不建议对HDFS上的文件进行修改。因为效率低下.
4、不支持用户的并行写:
同一时间内,只能有一个用户执行写操作。
5、多次写入,一次读取
特定文件夹下的副本数可以设置、存储容量可以设置,存储的文件个数可以设置。
数量限额
空间大小限额
安全模式是 HDFS 所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求,是一种保护机制,用于保证集群中的数据块的安全性。
Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,namenode开始监听datanode请求。当NameNode统计总模块和发送过来的块报告中的统计信息达到99.999%的之前时间里namenode运行在安全模式,即namenode的文件系统对于客户端来说是只读的
假设我们设置的副本数(即参数 dfs.replication)是 5,那么在 Datanode 上就应该有5 个副本存在,假设只存在 3 个副本,那么比例就是 3/5=0.6。在配置文件 hdfs-default.xml中定义了一个最小的副本的副本率(即参数 dfs.namenode.safemode.threshold-pct)0.999。
我们的副本率 0.6 明显小于 0.99,因此系统会自动的复制副本到其他的 DataNode,使得副本率不小于 0.999.如果系统中有 8 个副本,超过我们设定的 5 个副本,那么系统也会删除多余的 3 个副本。
如果 HDFS 处于安全模式下, 不允许HDFS 客户端进行任何修改文件的操作,包括上传文件,删除文件,重命名,创建文件夹,修改副本数等操作。
在安全模式下集群在做什么?
在安全模式下集群在进行恢复元数据,即在合并fsimage和edits log,并且接受datanode的心跳信息,恢复block的位置信息,将集群恢复到上次关机前的状态
手动控制安全模式命令
hdfs的文件权限机制与linux系统的文件权限机制类似
r:read w:write x:execute 权限x对于文件表示忽略
如果linux系统用户zhangsan使用Hadoop命令创建一个文件,那么这个文件在HDFS当中的owner就是zhangsan
准备新节点
第一步:复制一台新的虚拟机出来
将我们纯净的虚拟机复制一台出来,作为我们新的节点
第二步:修改mac地址以及IP地址
修改mac地址命令
修改ip地址命令
第三步:关闭防火墙,关闭selinux
第四步:更改主机名
更改主机名命令
第五步:四台机器更改主机名与IP地址映射
四台机器都要添加hosts文件
vim /etc/hosts 192.168.52.100 node01 192.168.52.110 node02 192.168.52.120 node03 192.168.52.130 node04
第六步:node04服务器关机重启并生成公钥与私钥
node04执行以下命令关机重启
node04执行以下命令生成公钥与私钥
node04执行以下命令将node04的私钥拷贝到node01服务器
node01执行以下命令,将authorized_keys拷贝给node04
第七步:node04安装jdk
node04统一两个路径
然后解压jdk安装包,配置环境变量,或将集群中的java安装目录拷贝一份,并配置环境变量。
第八步:解压Hadoop安装包
在node04服务器上面解压Hadoop安装包到/export/servers
node01执行以下命令将Hadoop安装包拷贝到node04服务器
第九步:将node01关于Hadoop的配置文件全部拷贝到node04
node01执行以下命令,将Hadoop的配置文件全部拷贝到node04服务器上面
服役新节点具体步骤
第一步:在主机点上创建dfs.hosts文件
第二步:node01 编辑hdfs-site.xml 添加一下配置
第三步:刷新namenode
第四步:更新resourceManager节点
第五步:namenode的slaves文件增加新服务节点主机名称
第六步:单独启动新增节点
第七步:浏览器查看
http://192.168.100.131:50070/dfshealth.html#tab-overview
http://192.168.100.131:8088/cluster
第八步:使用负载均衡命令,让数据均匀负载所有机器
第一步:创建dfs.hosts.exclude配置文件
第二步:编辑namenode所在机器的hdfs-site.xml
第三步:刷新namenode,刷新resourceManager
第四步:查看web浏览界面
http://192.168.100.131:50070/dfshealth.html#tab-datanode
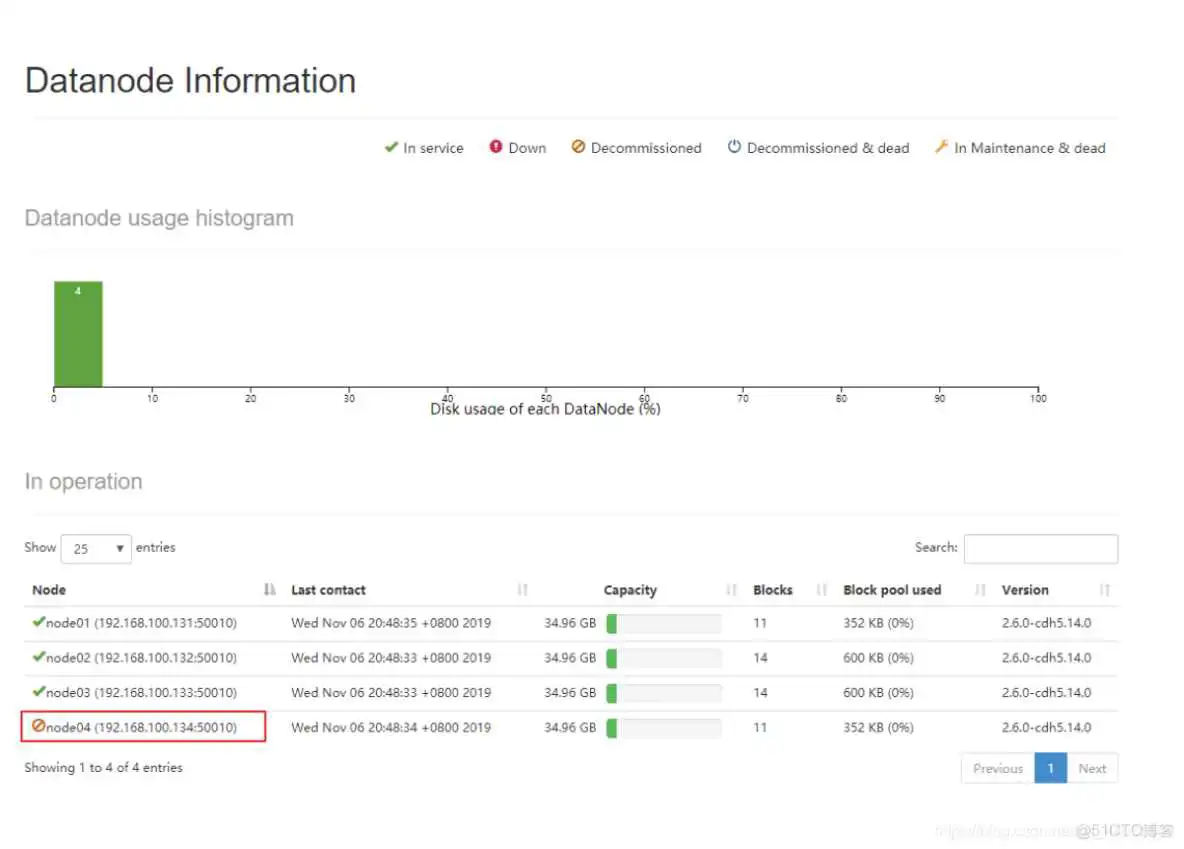
第五步:节点退役完成,停止该节点进程
第六步:从include文件中删除退役节点
第七步:从namenode的slave文件中删除退役节点
第八步:如果数据负载不均衡,执行以下命令进行均衡负载
第一步:上传一个大于128M的文件到hdfs上面去
第二步:web浏览器界面查看jdk的两个block块id
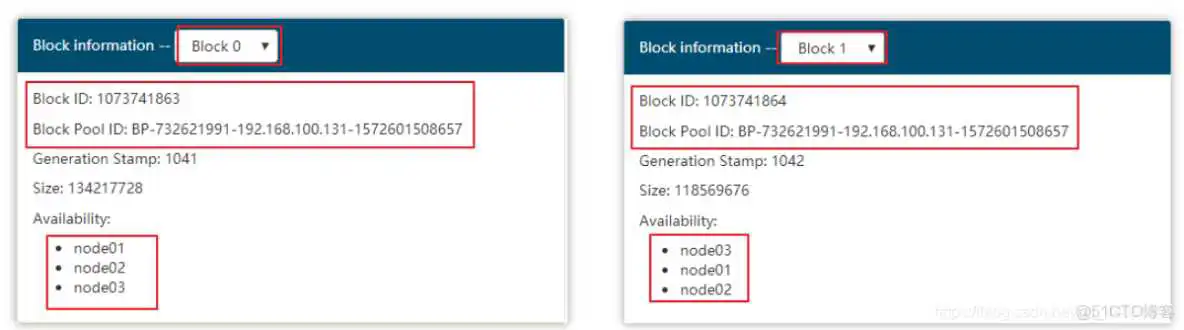
第三步:根据配置文件找到block块所在的路径
第四步:执行block块的拼接
1、启用回收站
修改所有服务器的core-site.xml配置文件
2、查看回收站
3、通过javaAPI删除的数据,不会进入回收站,需要调用moveToTrash()才会进入回收站
通过shell命令行删除的数据,会进入回收站。
4、恢复回收站数据
trashFileDir :回收站的文件路径
hdfsdir :将文件移动到hdfs的哪个路径下
5、清空回收站
到此这篇文件管理安装包在哪个文件夹里(文件管理的文件怎么安装)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/jszy-cpgl/62709.html