
目录
2.JRE(java runtime environment)
【三步:取key存到set集合、遍历set、get(key)】
4.1 public File(String pathname)
4.2 public File(String parent,String child)
4.3 public File(File parent,String child)
2.字节缓冲输出流:BufferedOutputStream
2.2.1 ObjectOutputStream特有的成员方法:
3.2.1 ObjectInputStream特有的成员方法:
4.3 TCP通信的服务器端【ServerSocket】实现
6.3.3 Predicate接口的默认方法:and、or、negate方法
一、计算机基础
1.二进制
计算机中全部采用二进制。
2.字节
计算机中的最小存储单元,计算机存储任何数据都以字节的形式存储。
8个bit(二进制位)0000-0000表示1个字节:
8bit=1byte或1B;1024B=1KB;1024KB=1MB;1024MB=1GB;1024GB=1TB。
3.DOS命令
启动:win+R
切换盘符:盘名:
进入文件夹:cd 文件夹名
进入多级文件夹:cd 文件夹1名\文件夹2名\文件夹3...
返回上一级:cd..
直接回根路径:cd\
查看当前文件夹内文件列表:dir
清屏:cls
退出:exit

二、开发环境
1.JVM(java virtual machine)
java虚拟机(翻译官)。不同的操作系统有各自的JVM,给不同的操作系统“翻译”成各自能识别的字符。JVM不跨平台,java程序跨平台。
2.JRE(java runtime environment)
运行环境。包含JVM+核心类库。保证了java程序跨平台。想运行已有的java程序,只需安装JRE即可。
3.JDK(java development kit)
开发工具包。包含JRE和开发人员使用的工具:编译工具(javac.exe)和运行工具(java.exe)。想开发全新的java程序,必须安装JDK。
4. JDK、JRE、JVM三者的关系
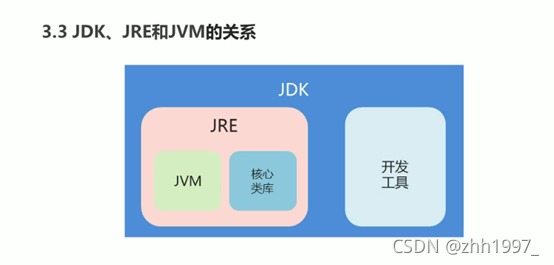
因此只需安装JDK,就包含了JRE和JVM。
5.Path环境变量
告诉小黑窗口(cmd)去哪找命令。开发java程序需要使用JDK提供的开发工具,而这些工具在JDK安装目录的bin目录下,每次写javac和java命令的路径麻烦,为了能够方便的使用javac和java的命令。
6.开发java步骤
编写程序;
编译程序(javac.exe:编译器。编译成java字节码文件:.class,JVM虚拟机可以认识);
运行程序(java.exe)。
三、HelloWorld
1.编写程序
改文件扩展名为.java,写代码(HelloWorld);
2.编译程序
javac.exe编译工具(.java文件—>.class字节码文件)
进入cmd窗口—>进入.java所在目录—>javac HelloWorld.java(javac 完整文件名 后缀)进行编译。 立即会生成.class字节码文件。有c有后缀。
3.运行程序
java.exe运行工具
java HelloWorld(java 文件名,不要写后缀)运行,运行的是.class文件。无c无后缀。
代码如下:
public class HelloWorld{
//public class后面代表定义一个类名称,类是java中所有源代码的基本组织单位
//即第一行的第三个单词必须和所在文件名称完全一致,大小写也要一样
public static void main(String[] args){
//第二行代表程序执行的起点
//第二行内容不变,代表main方法
System.out.println("hello,world!");
//第三行打印输出
} }
4.关键字
都是小写,特殊颜色
5.标识符
自定义,大驼峰:类名; 小驼峰:变量名、方法名。
6.常量
关键字:final,指固定不变的数据:整数常量、小数常量、字符常量 '有且仅能有1个字符'、字符串常量、布尔常量、空常量。
7.数据类型
①基本数据类型:整数、浮点数、字符、布尔。
②引用数据类型:字符串、类、数组、接口。
注1:字符串不是基本类型,是引用类型。浮点型可能只是近似值,并非精确值。
注2:整数默认类型是int,若要使用long类型,需要加后缀 L;
浮点数默认类型是double,若要使用float类型,需要加后缀F。
8.变量
注1:如果创建多个变量,变量之间的名称不可重复;
注2:对于float和long类型,字母后缀不能忘;
注3:如果使用byte和short类型的变量,右侧的数据值不能超过左侧类型的范围;
注4:变量要先赋值后使用;
注5:变量不能超过作用域范围使用;
注6:不推荐一个语句创建多个变量。
【作用域:从定义变量的一行开始,到直接所属的大括号结束为止】
四、数据类型转换
注1:一般不推荐使用强制类型转换,有可能发生精读损失、数据溢出;
注2:byte/short/char这三种类型都可以发生数学运算,如加法;
注3:byte/short/char这三种类型在运算的时候会被首先转换成 int 类型载进行运算;
注4:Boolean类型不能发生数据类型转换。
五、运算符
1.算术运算符
注1:运算中有不同类型的数据,结果会是数据类型范围大的那种类型;
注2:“+”的不同用法:
①对于数值来说是加法;
②char类型计算之前会转换为int然后再计算;
③对于字符串String来说,“+”代表字符串连接操作,任何数据类型+字符串时,结果都会变成字符串。
2.自增自减运算符
注1:①单独使用:不和其他任何操作混合,自己独立成为一个步骤。此时前++和后++没有区别。
②混合使用:和其他操作混合使用,比如和赋值运算符、打印操作混合等。此时有【重大区别】:前++:先加后用。变量立马+1再使用;后++:先用后加。使用变量本来的值之后+1。
注2:只有变量才能使用自增自减运算符,常量不可发生改变。
3.赋值运算符
注1:只有变量才能使用赋值运算符,常量不能进行赋值;
注2:复合赋值运算符中隐含了一个强制类型转换。
4.比较运算符
注1:结果一定是Boolean,成立为true,不成立为false;
注2:不能连着写多次判断,如:1<x<3。编译报错。
5.逻辑运算符
注1:与“&&”、或“||”具有短路效果:如果根据左边已经可以判断 最终结果,那么右边的代码将不再执行,节省性能;
注2:逻辑运算只能用于Boolean值。
注3:与、或两种运算,多个条件可以连写:条件1&&条件2&&..
对于1<x<3的情况,应该拆成两个部分,再使用与运算符连接。
6.三元运算符
注1:必须同时保证表达式1和表达式2都符合左侧数据类型的要求;
注2:三元运算符的结果必须被使用。
六、方法
将一个功能抽取出来,把代码单独定义在一个大括号内,形成一个单独的功能,需要的时候直接调用。
1.定义:
修饰符 返回值类型 方法名 (参数列表){
代码...
return;
}
①修饰符:目前固定写法:public static;
②返回值类型:目前固定void;
③方法名:小驼峰自命名,用来调用方法。
注1:方法定义的先后顺序无所谓;
注2:方法的定义不能产生嵌套包含关系;
注3:方法定义好之后不会执行的,若想执行需要进行方法的调用。
注4:方法的调用:方法名();
七、编译器的两点优化
对于byte/short/char三种类型来说,赋值时:
①如果右侧赋值的数值没有超过左侧变量的范围,编译器会自动补上强转:(byte)(short)(char);
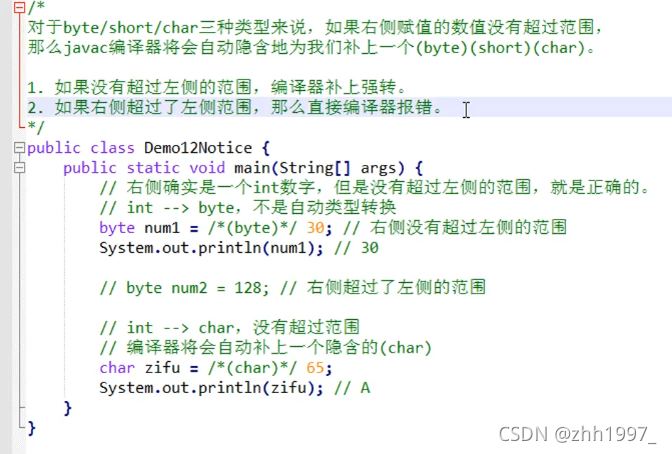
②如果右侧赋值的数值超过了左侧变量的范围,编译器报错。

八、流程控制
1.顺序结构
一条路走到黑;
2.判断语句
if语句; 三元运算符可以和if...else语句替换;
3.选择语句
switch语句;
注1:多个case后面的数值不可以重复;
注2:switch后面的小括号中只能是下列数据类型:①基本数据类型:byte/short/char/int;②引用数据类型:String字符串、enum枚举;
注3:switch语句很灵活,匹配到哪个case就从哪个位置向下执行,直到遇到break或者整体结束为止。
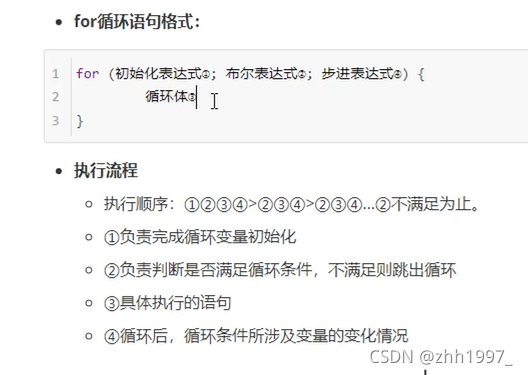
4.循环语句
for,while,do...while
四个组成部分:
①初始化语句:循环最初执行,只做 唯一 一次;
②条件判断:成立循环继续,不成立循环退出;
③循环体:重复做的内容,若干行语句;
④步进语句:每次循环之后都要进行的扫尾工作,每次循环结束之后都要执行一次。
4.1 for循环
4.2 while循环

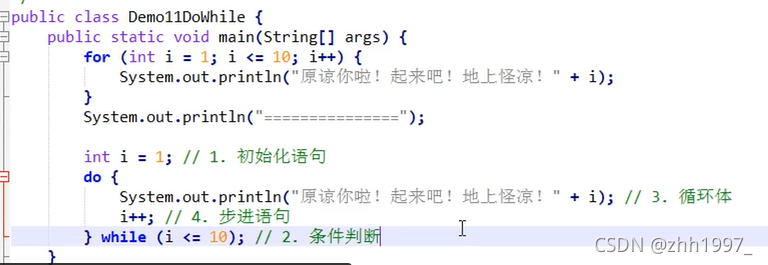
4.3 do-while循环

可以先写成for循环,再转换成while、do-while循环:
4.4 关于循环的选择
凡是次数确定的场景多用for循环,否则多用while循环。do-while循环相对使用较少。
4.5 三种循环的区别
①for循环的变量在小括号()中定义,只能在循环内部使用;
while循环和do-while循环初始化语句本来就在外面,所以出了循环后还可以继续使用;
②若条件判断不满足,for循环和while循环会执行0次,但do-while循环至少执行1次。
4.6 循环控制
①break关键字:
switch语句中:一旦执行,整个switch语句立刻结束;
循环语句中:一旦执行,整个循环语句立刻结束,打断循环。
②continue关键字:
一旦执行,立马跳过当前次循环剩余内容,马上开始下一次循环。
4.7 死循环
标准格式:
while(true){
循环体;
}
4.8 循环嵌套
外层大括号循环执行一次,内层大括号不管执行多少次,外层都只执行一次。
九、开发工具IDEA
- IDE:集成开发环境
- 开发java程序的步骤:1.编写代码;2.启动cmd;3.调用javac编译;4.调用java运行。
- 集成开发环境:一种专门用来提升java开发效率的软件。
- 免费的IDE:Eclipse;收费的IDE:InteliJ IDEA
- IDEA的项目结构:
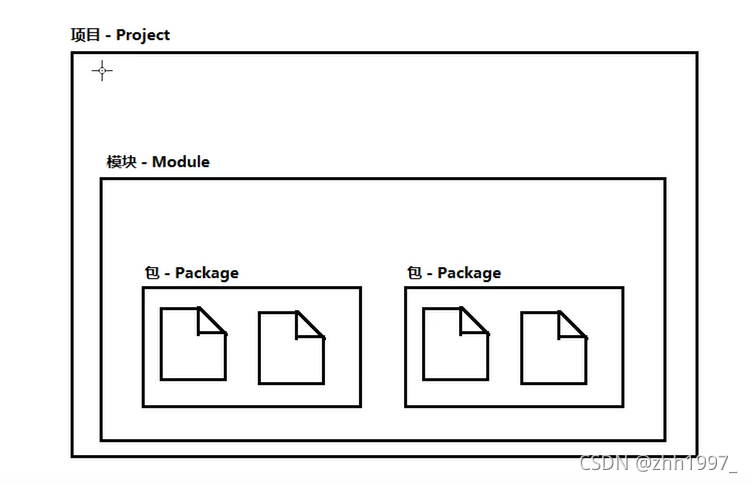
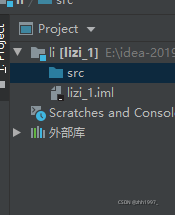
①.iml:IDEA的一些配置;
②外部库:JDK;
③src:所有源代码必须写在这里面;
④包名:英文小写字母+英文句点+数字;(一般是所在公司的域名网址倒过来写)。
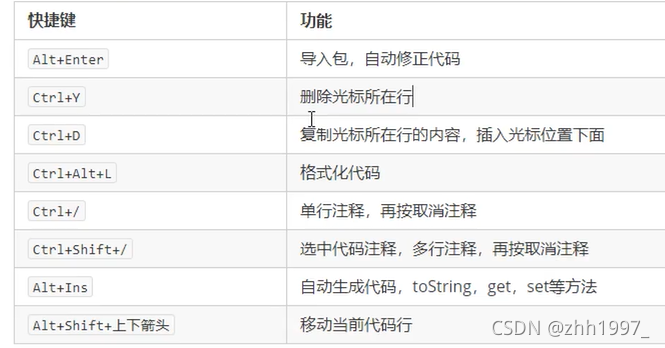
快捷键:
十、方法
概念:若干语句的功能集合。
注:①方法定义的先后顺序无所谓;
②方法定义必须是挨着的,不能嵌套;
③方法定义之后自己不会执行,必须调用,到return语句方法执行结束。
1.方法的定义格式

2.方法的调用
①单独调用;
②打印调用;
③赋值调用;

 3.对比有参数和无参数
3.对比有参数和无参数
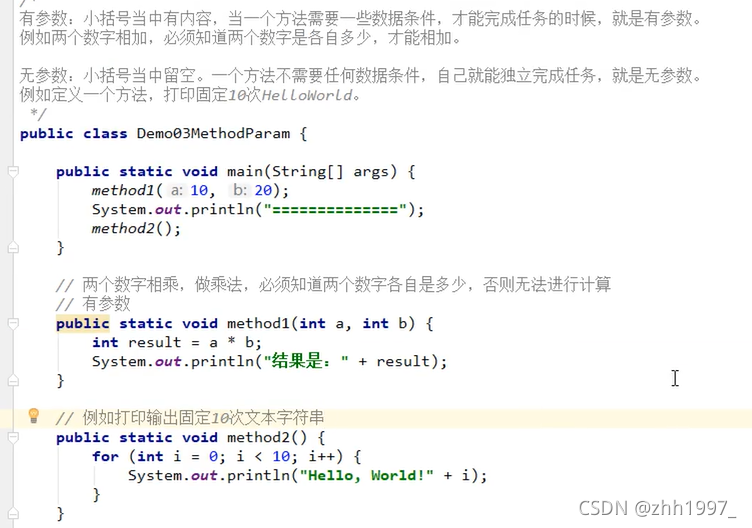
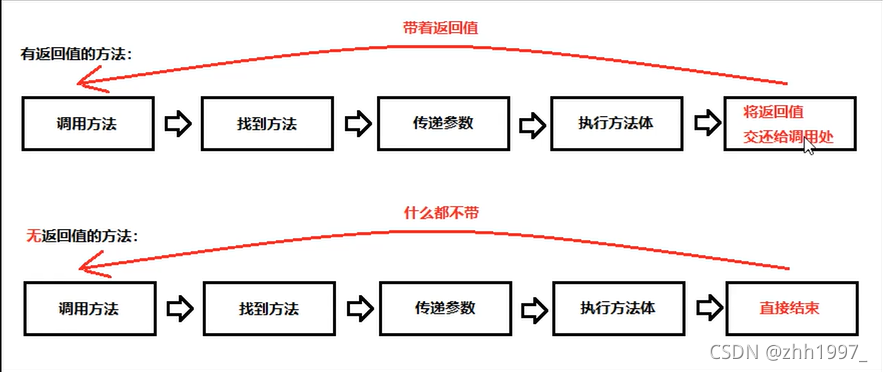
4.对比有返回值和无返回值
无返回值的方法,只能单独调用,不能使用打印调用或者赋值调用。

5.注意事项
①方法应该定义在类中。方法中不能再定义方法,不能嵌套使用;
②方法的定义前后顺序无所谓;
③方法定义后不会自动执行,需要调用:单独调用、打印调用、赋值调用;
④若方法有返回值,必须写上”return 返回值;”,不能没有;
⑤return后面的返回值数据,必须和返回值类型一样;
⑥对于void没有返回值,只能单独调用。且不能写return后面的返回值;
⑦void方法中最后一行的 return; 代表方法结束,可以省略;
⑧一个方法可以有多个return语句,但要保证同时只有一个会被执行,两个return不能连写。
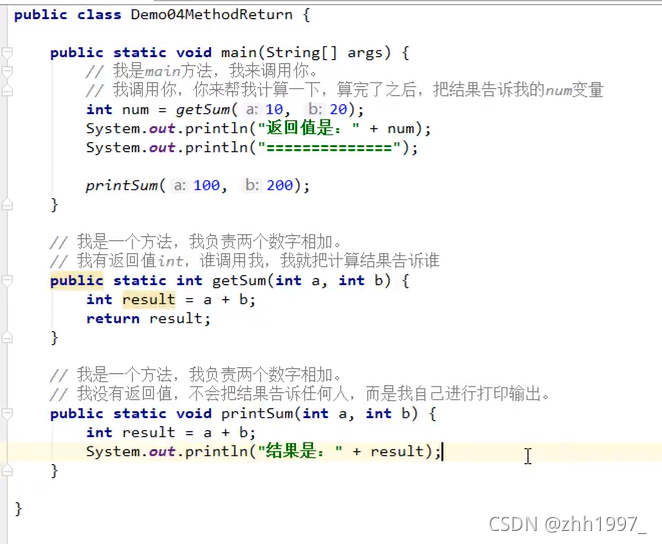
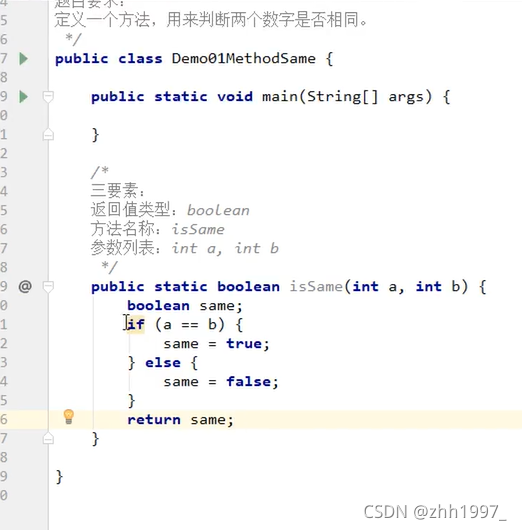
练1:有返回值有参数:
练2:有返回值无参数:数据范围是固定的,方法自己就能完成。

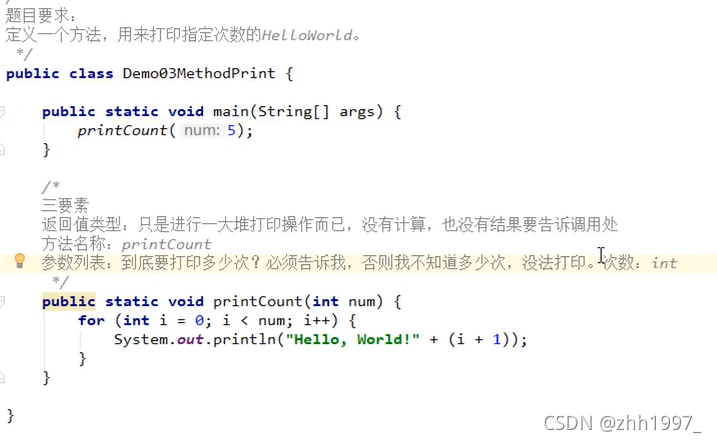
练3:无返回值有参数:没有计算,没有结果需要告诉调用处。
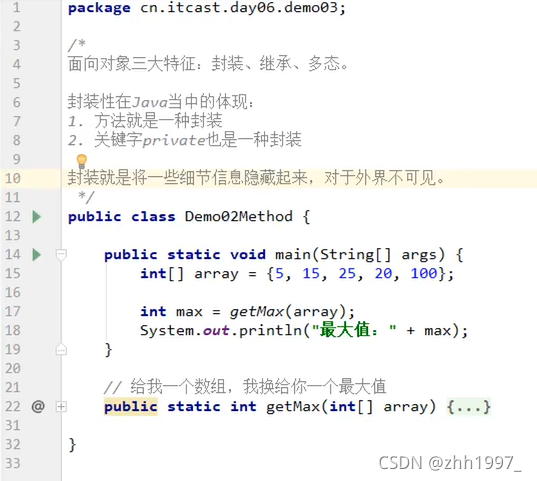
6.方法重载
- 多个方法名称一样,参数个数或者参数类型或者多类型参数顺序不同,只需要记住一个方法名,就可实现类似的多个功能。
- println方法其实就是进行了多种数据类型的重载形式。
- 注意:方法重载与参数名称无关,与方法的返回值类型无关。
十一、数组
1.概念
是一种容器,可以同时存放多个数据值。
2.特点
①数组是一种引用数据类型;
②数组当中的多个数据类型必须统一;
③数组的长度在程序运行期间不可改变。
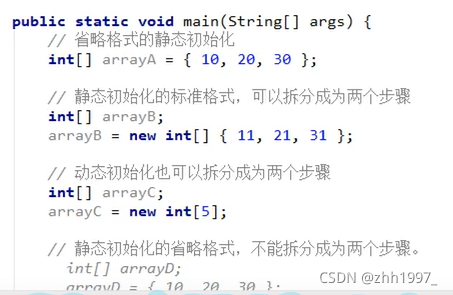
3.初始化
①动态初始化(指定长度);

②静态初始化(指定内容)。

4.注意事项

5.获取数组元素
- 直接打印数组名称,得到的是数组对应的内存地址哈希值。字符数组特例,会显示字符串。

- 访问数组元素格式:

注意事项:

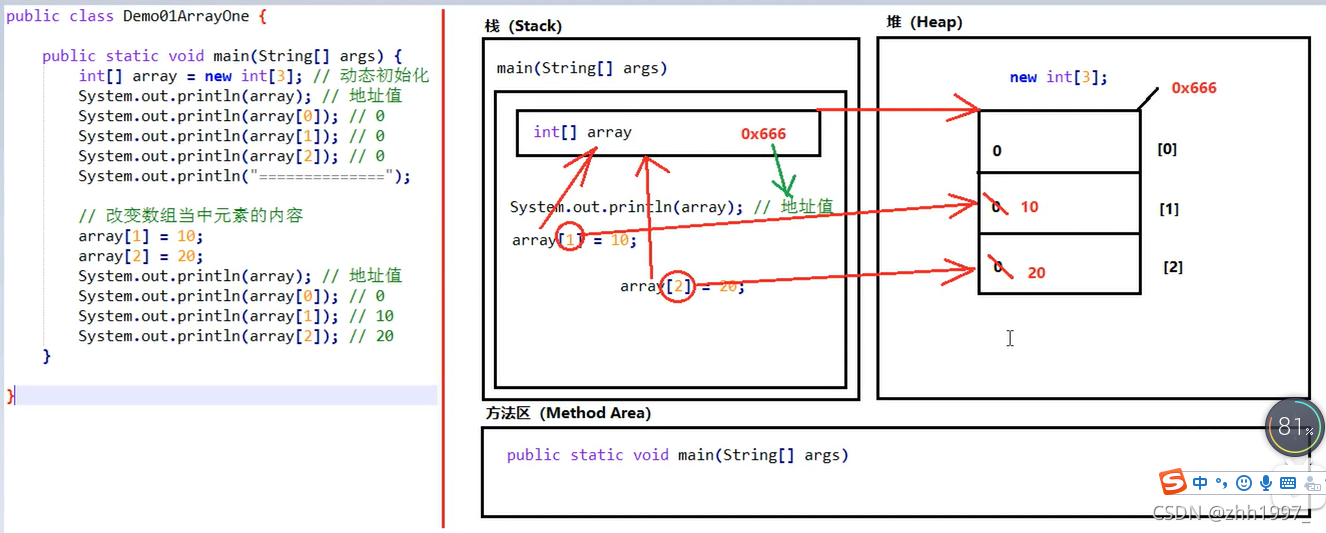
6.java中的内存划分

7.一个数组的内存图(创建、赋值)
方法区:存储.class和方法的信息(main方法);
栈:将方法的信息加载到栈中运行(进栈);
堆:new。
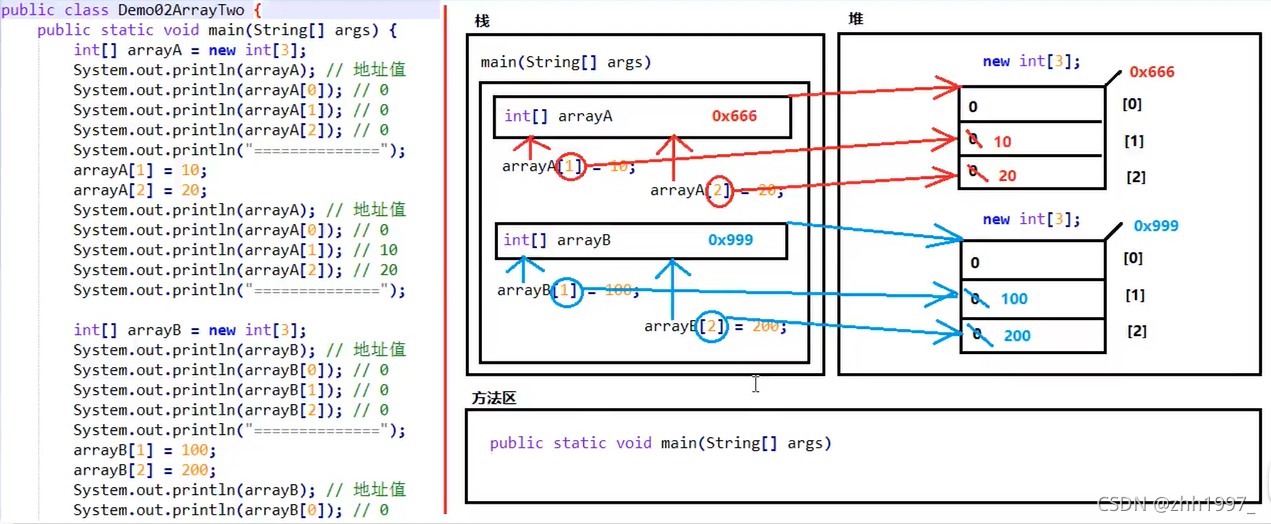
8.两个数组的内存图

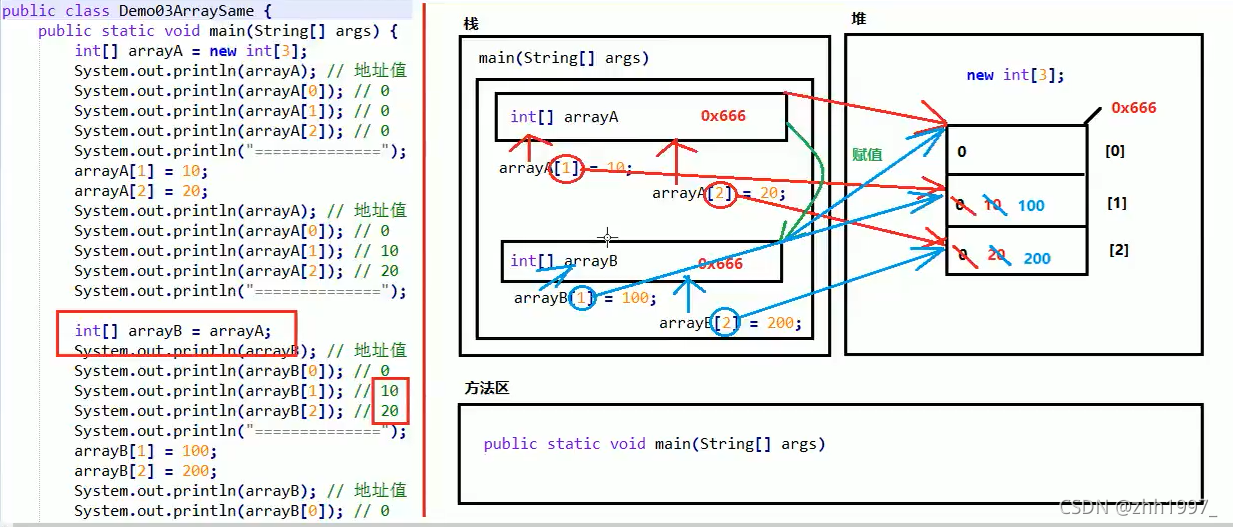
9.两个引用指向同一个数组内存图
10.空指针异常

11.获取数组的长度
获取长度:数组名称.length
遍历数组快捷键:array(数组名).fori
12.求数组中的最值(打擂台)
打擂台:0号元素先上场不用和任何人比,1号上来和0比...2号上来和0和1的胜者比.....依次循环。

13.数组元素反转
要求:不能使用新数组,就用原来的唯一一个数组。
要点:两个索引,对称交换
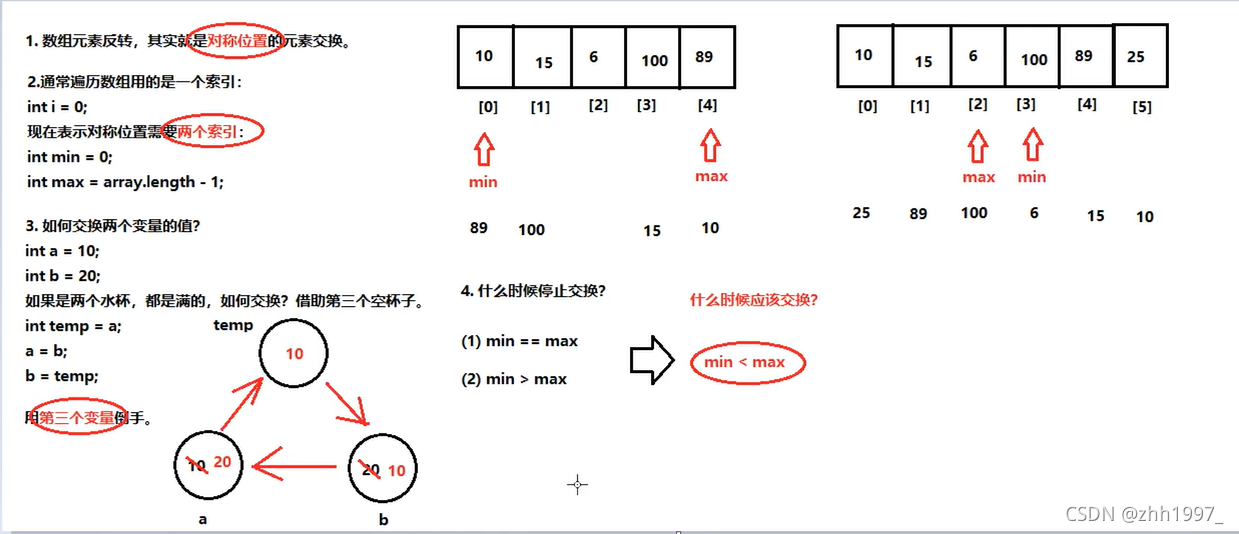
实现:
public class ArrayReverse {
public static void main(String[] args) {
int[] array1 = {1, 2, 3, 4, 5, 6};
//遍历原来的数组
for (int i = 0; i < array1.length; i++) { System.out.println(array1[i]); } System.out.println("==============");
/*for循环:
初始化语句:int min=0,max=array1.length-1
条件判断:min<max
步进表达式:min++,max--
循环体:用第三个变量倒手
*/
for (int min = 0, max = array1.length - 1; min < max; min++, max--) {
int temp = array1[min];
array1[min] = array1[max];
array1[max] = temp;
}
//再次打印遍历输出数组倒序后
for (int i = 0; i < array1.length; i++) { System.out.println(array1[i]);
}
}
}
14.数组作为方法参数_传递地址
数组名存的是数组的内存地址,传递的也是地址值:

上面数组倒序的例子数字遍历输出了两次,复制粘贴不方便,因此可以写为一个方法:
三要素:

15.数组作为方法返回值_返回地址
注:一个方法可以有0、1...多个参数,但只能有0或者1个返回值。如果希望一个方法中产生多个结果数据进行返回,那就是要使用数组作为返回值类型。
注:返回数组名=数组地址!!!!,需要输出数组需要遍历或a[0]...
例:返回三个数的和与平均数:
结果:
重点:任何数据类型都可以作为方法的参数类型或返回值类型
数组作为方法的参数,传递进去的是数组的地址值;
数组作为方法的返回值,返回的也是数组的地址值。
十二、面向对象思想
面向过程:当需要实现一个功能的时候,每一个具体的步骤都要亲力亲为,详细处理每一个细节;
面向对象:当需要实现一个功能的时候,不关心具体的步骤,而是找到一个已经具有该功能的人帮我做事,
三大特征:封装、继承、多态。
例:要求打印输出格式为:[10,20,30,40,50]
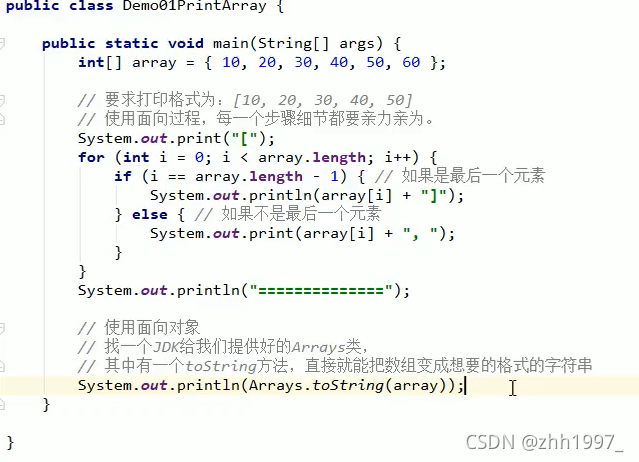

十三、类和对象
1.java中用class描述事物
类是一种【引用数据类型】
成员变量:事物的属性;
成员方法:事物的行为。
变量和方法一旦写在java的类当中就称为成员变量和成员方法。

2.定义类的时候注意事项
①成员变量直接定义在类当中,方法的外面;
②成员方法不写static关键字,带有static是普通方法,不需要对象可以直接调用。
3.对象的创建及使用
类不能直接使用,要根据类创建对象才能使用。(手机图纸和手机)
步骤: ①导包;
②创建;
③使用。


4.手机类练习
手机类:(没有main方法无法运行):
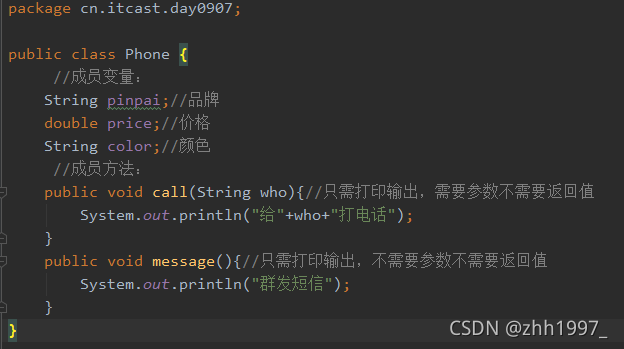
调用、运行一个对象:华为:
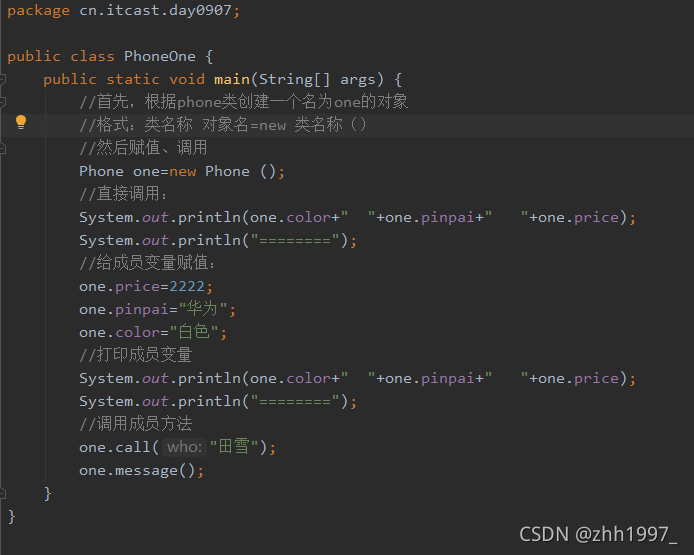
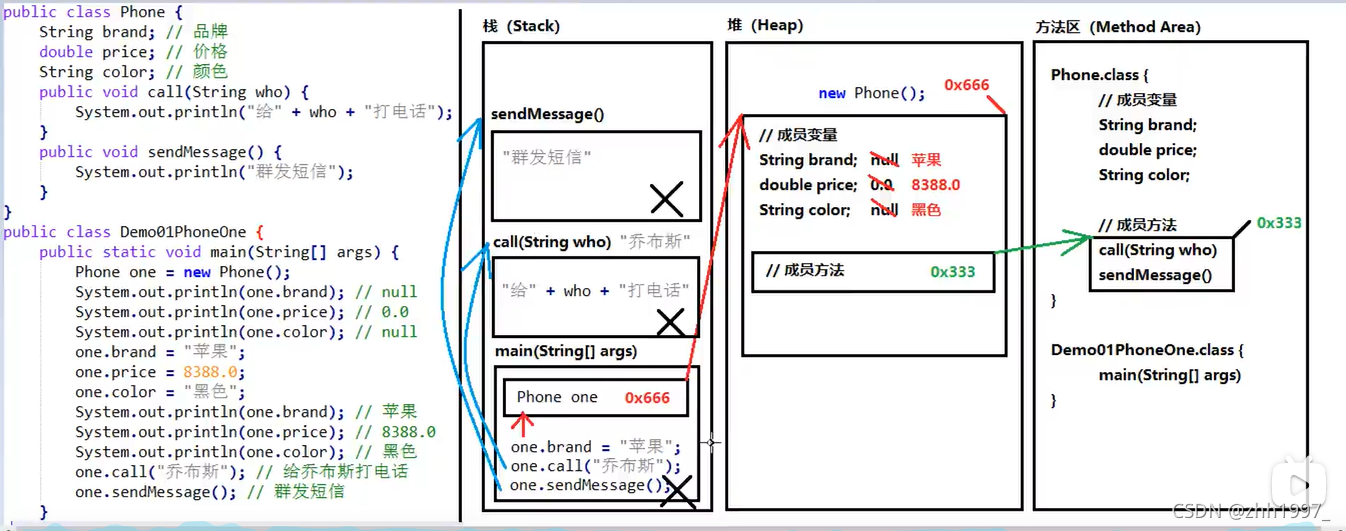
5.一个对象的内存图
方法区:方法、成员变量、成员方法的基本信息;
栈:从main开始从上往下执行。方法区的方法进栈才能运行,方法执行完就出栈,存new的对象堆地址,根据地址找成员变量、成员方法;
堆:成员变量的值、成员方法的地址。
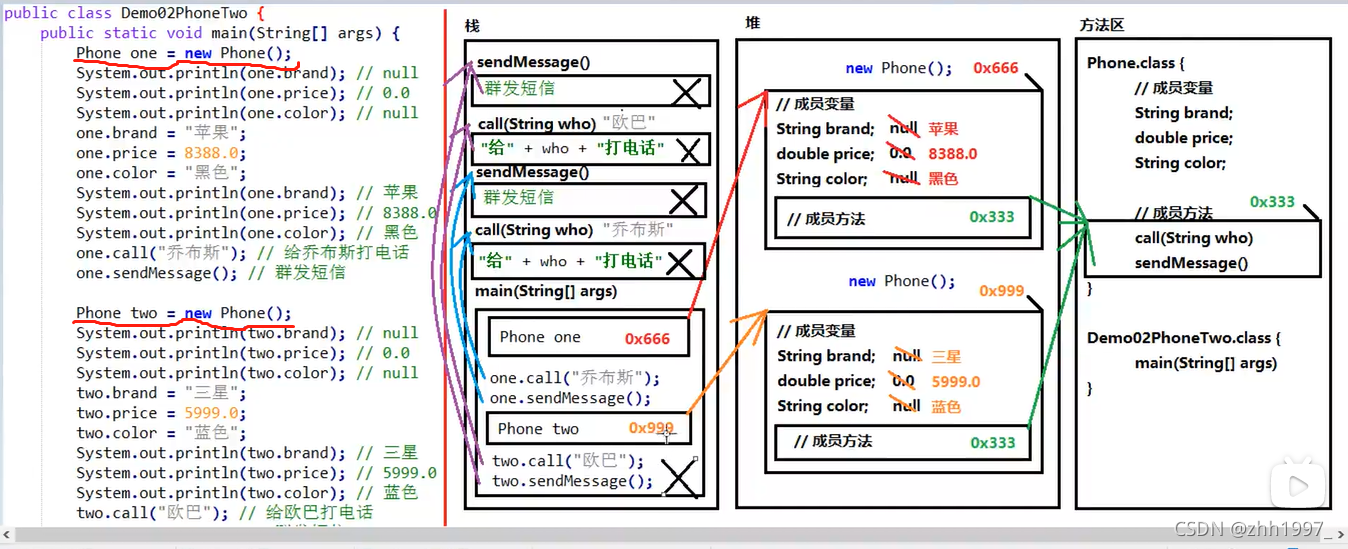
6.两个对象使用同一个方法的内存图
7.两个引用指向同一个对象的内存图
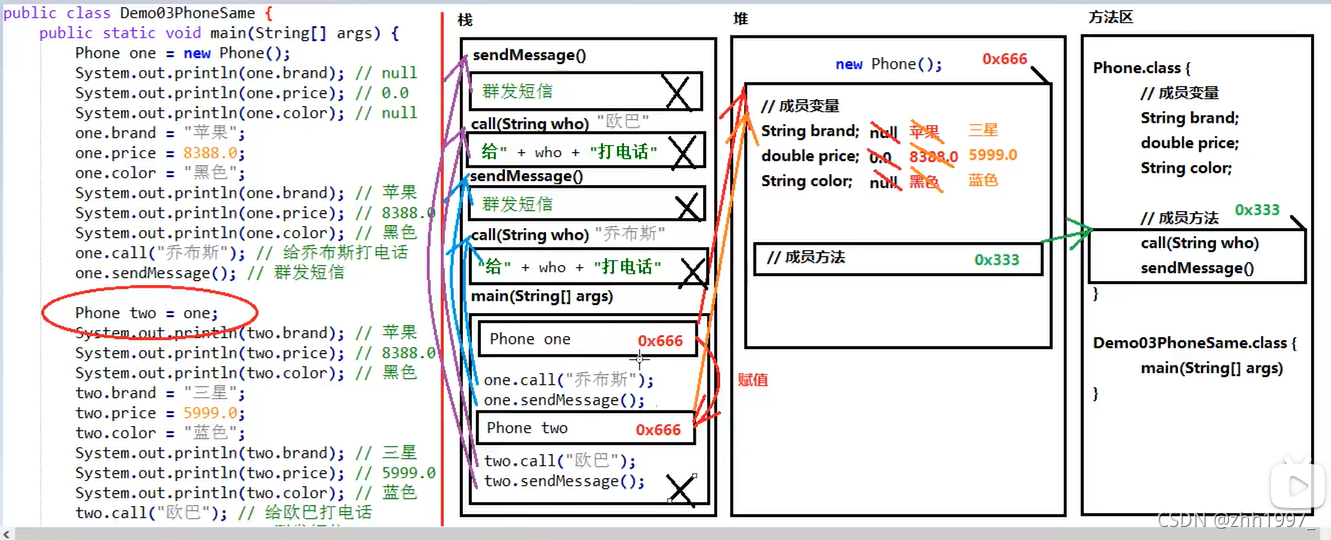
8.使用对象类型作为方法的参数
例子:手机类_苹果手机
带有static是普通方法,不需要对象可以直接调用。如下面method方法:
内存图:
重点:当一个对象或数组类型作为参数,传递到方法当中时,实际上传递的是对象的地址。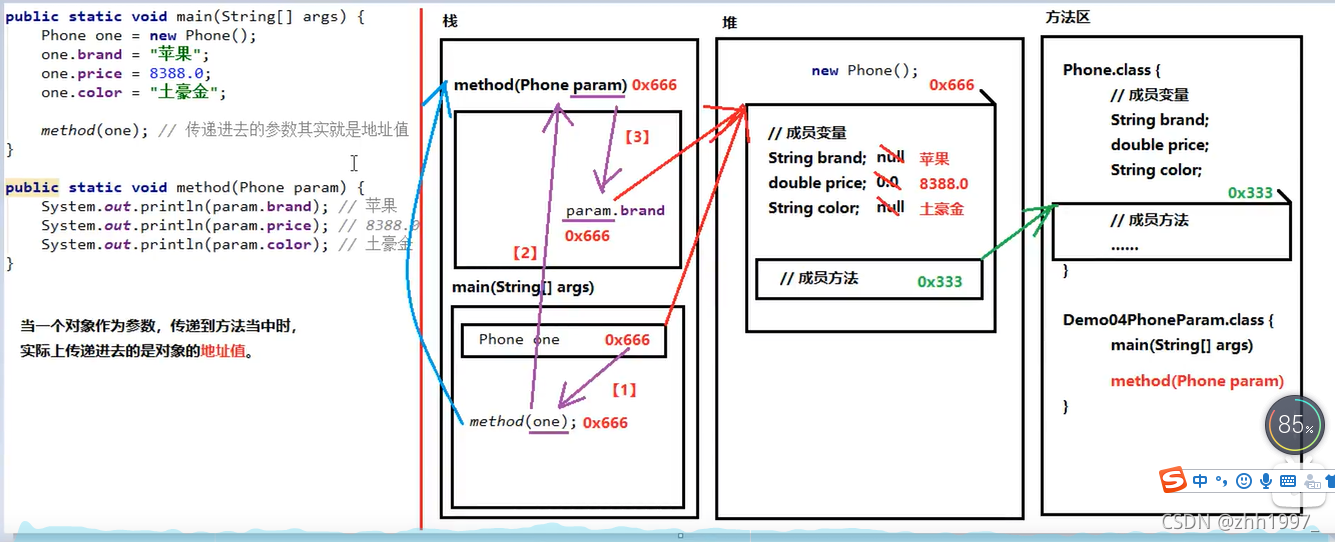
9.用对象类型作为方法的返回值
重点:当一个对象或数组类型作为方法的返回值时,返回值其实就是对象的地址值。
内存图: 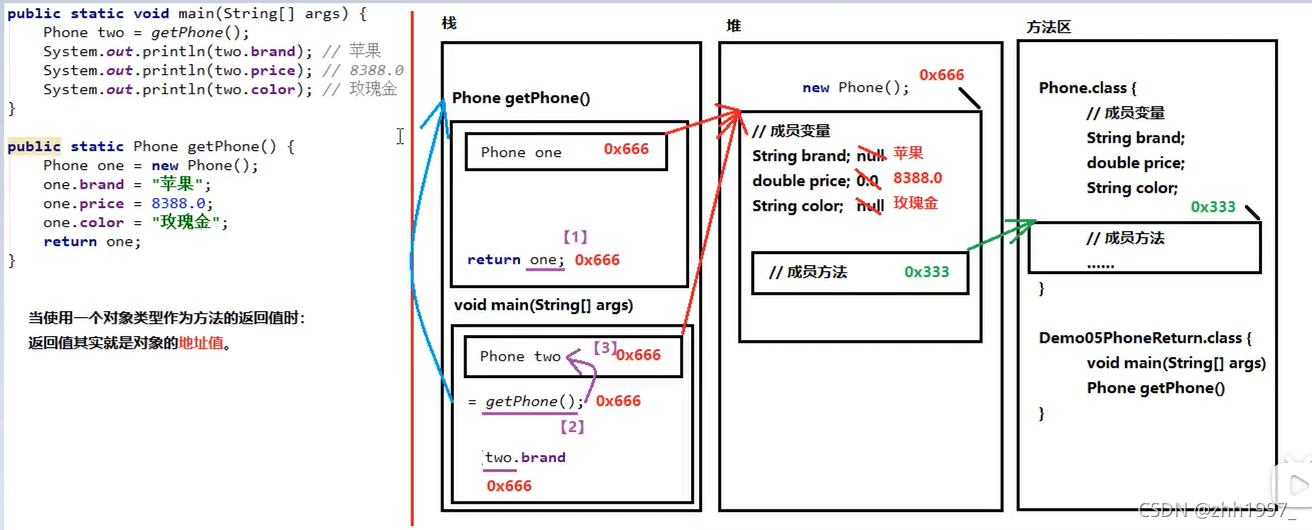
10.成员变量和局部变量的区别(重点!!)
①位置不同;
②作用范围不同;
③默认值不同。


④内存的位置不一样:
局部变量:在方法中使用,因此在栈内存;
成员变量:new出来的,因此在堆内存。
⑤生命周期不一样:
局部变量:一般来说,随着方法进栈而诞生,随着方法出栈而消失;
成员变量:一般来说,随着对象创建而诞生,随着对象被垃圾回收而消失。
注:方法的参数也是局部变量,但不赋值不报错。因为:参数在方法调用的时候必然会被赋值。
十四、面向对象三大特征-封装性
1.概念
2.private关键字(私有化)
为了阻止不合理的数据传进去,通过private关键字保护需要修饰的成员变量。就要通过Getter、Setter方法赋值、获取值,这样可以把不合法数据排除 (方法有{},可以写条件语句筛选数据)。
Getter:获取值,没有参数有返回值,返回数值;
Setter:设置值,没有返回值有参数,传递进去值。
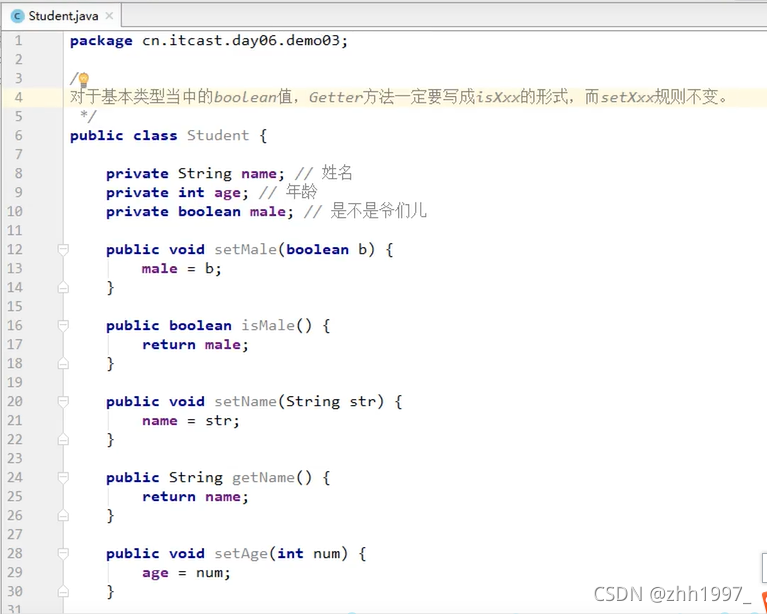
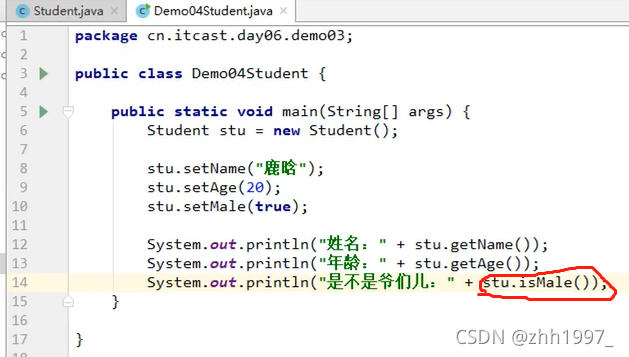
注:对于基本类型当中的Boolean值,Getter方法一定要写成isXxx的格式,而setXxx规则不变,见下例。

示例,学生类:
对于基本类型当中的Boolean值,Getter方法一定要写成isXxx的格式,而setXxx规则不变。
创建类、声明成员变量、成员方法:
main方法创建对象调用:
3.this关键字
通过谁(哪个对象)调用方法,谁就是this。
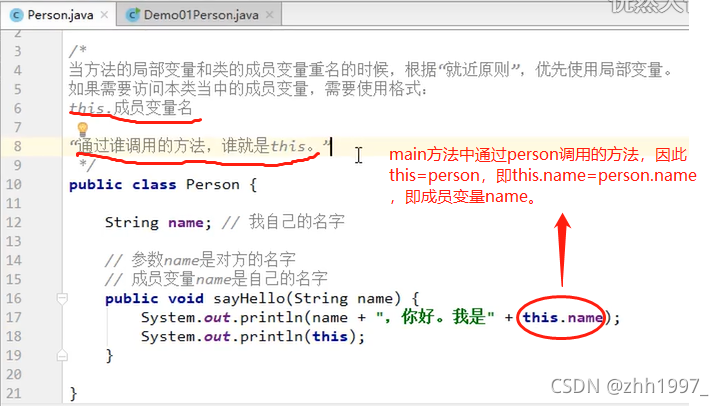
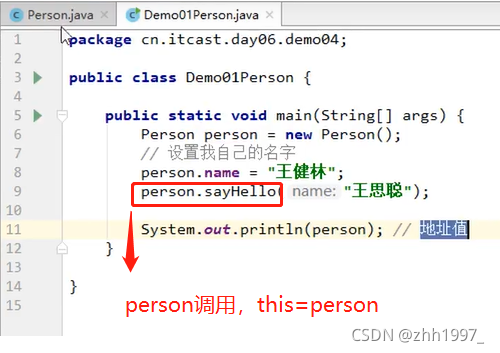
上图示例两个输出地址相同,都是new的对象person的堆地址。
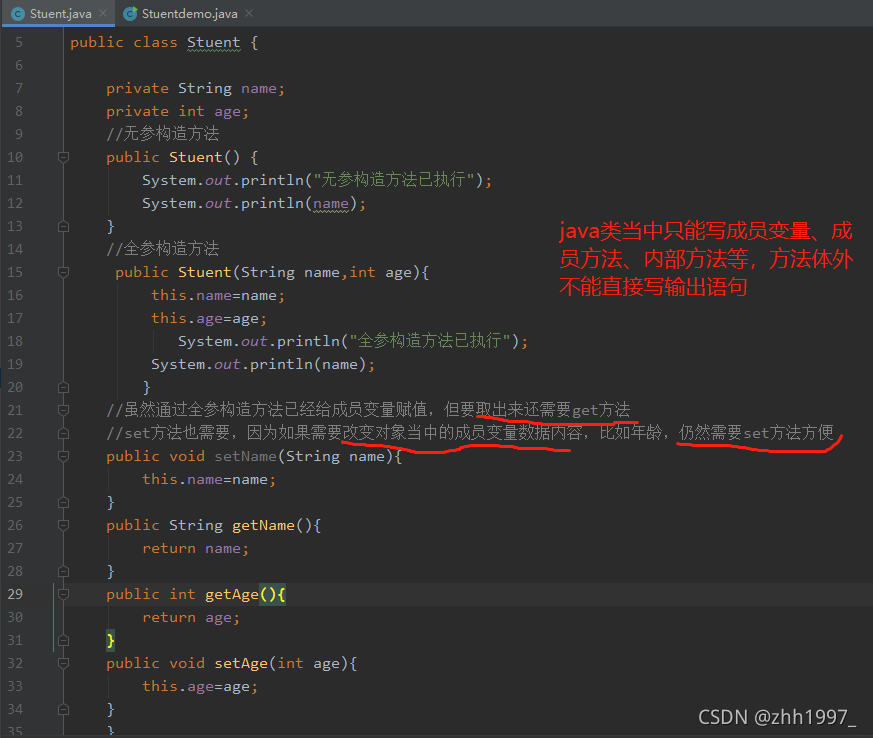
4.构造方法
作用:用来new对象。

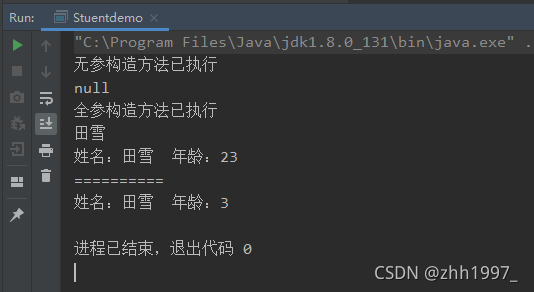
给某个类创建对象时,通过new关键字创建其实就是在调用构造方法。比如格式:Student student=new Student () ; 后面的 new Student () 就是在调用系统自动创建的Student () 方法,构造方法名:public Student () {}。
注:①构造方法的名称必须和所在的类名称完全一样,就连大小写也要一样;
②构造方法不要写返回值类型,就连void都不写;
③构造方法不能return一个具体的返回值;
④如果没有编写任何构造方法,编译器将自动创建一个不带参数的构造方法,方法体什么事情都不做,格式如:public Student () {};
⑤一旦编写了至少一个构造方法,编译器将不再创建;
⑥构造方法也可以重载:方法名相同,参数列表不同。
学生类举例:
student类:
main方法,创建对象调用构造方法、成员方法: 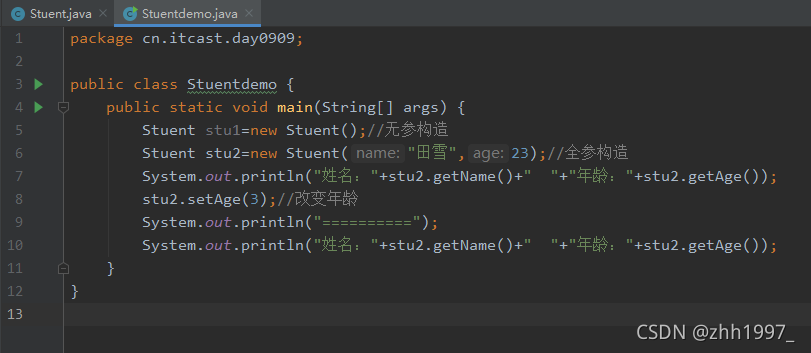 结果:
结果:
5.java中的标准类
标准类,又称Javabean:

十五 、API

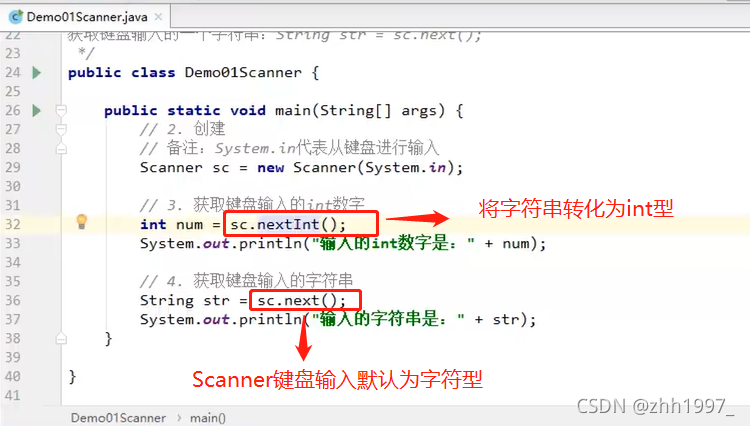
1.Scanner类:键盘输入
Scanner类非基本类型,是引用类型,引用类型使用的一般步骤:①导包;②创建(创建Scanner类的一个对象);③使用(对象.方法),调用API文档中Scanner类中封装的方法,得到的结果可以使用变量接收,也可以直接输出调用。

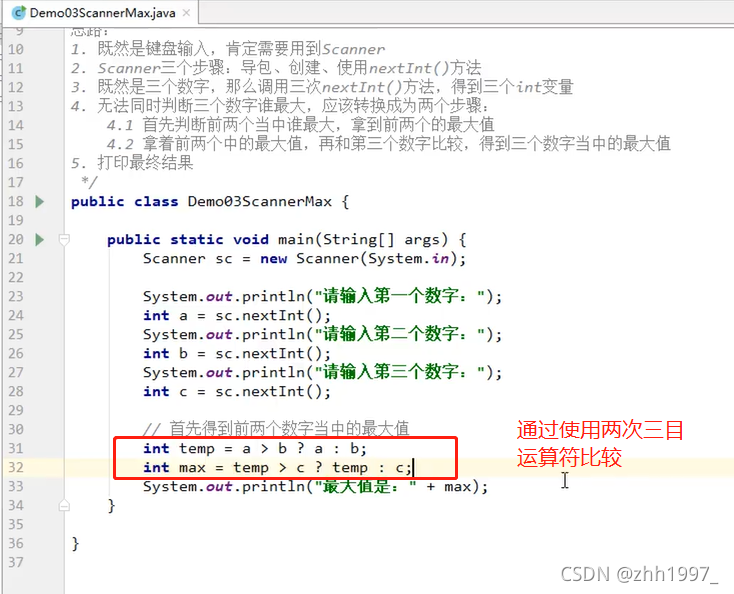
例:键盘输入三个数,输出最大值:
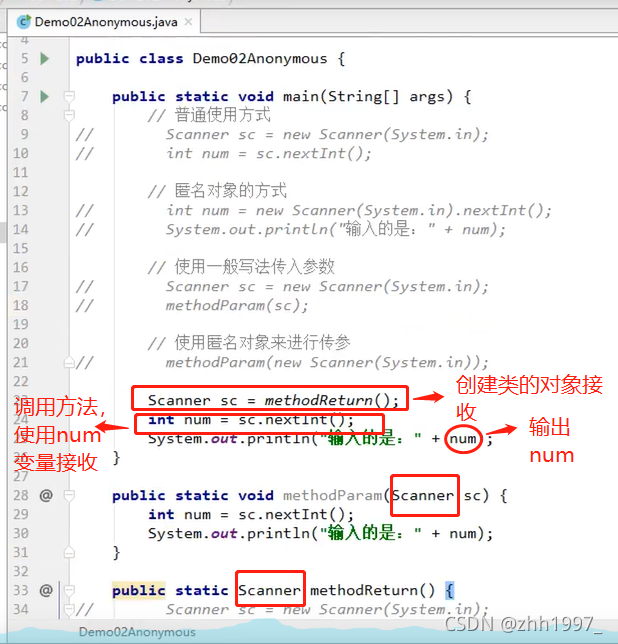
2.匿名对象
创建对象的标准格式:类名称 对象名=new 类名称();
匿名对象:只有右边的对象,没有左边的名字和赋值运算符:new 类名称();
注:匿名对象只能使用唯一的一次,下次再用不得不再创建一个新对象。如:
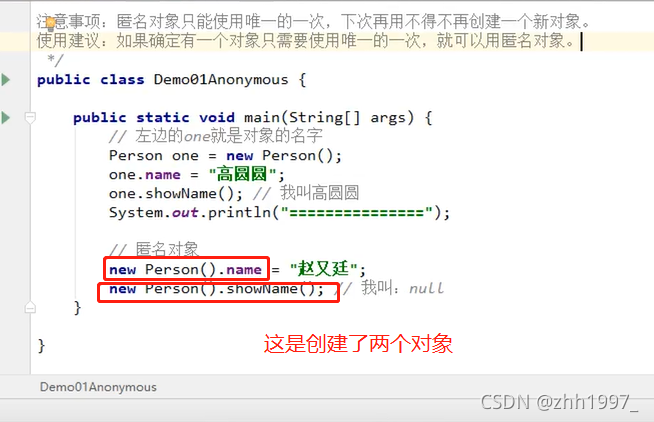
使用建议:如果确定有一个对象只需要使用唯一的一次,就可以用匿名对象。
匿名对象作为方法的参数和返回值:
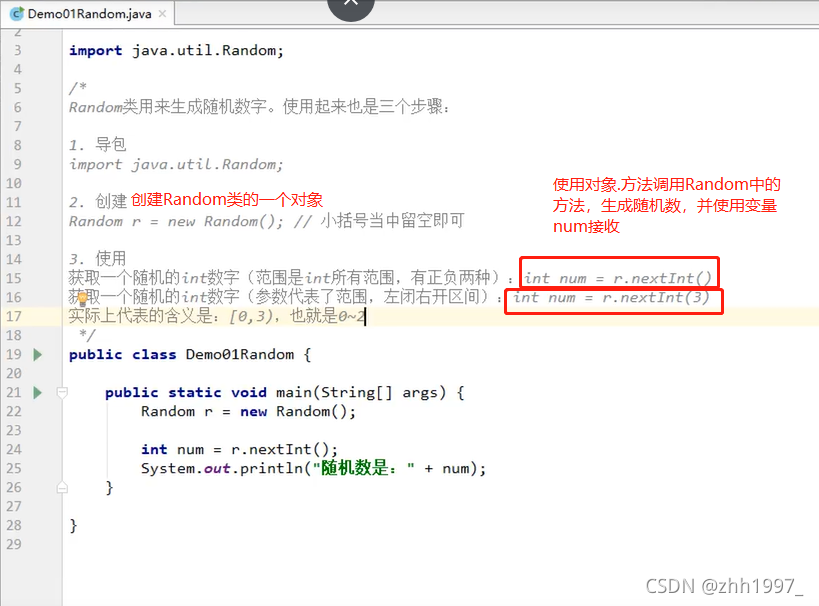
3.Random类
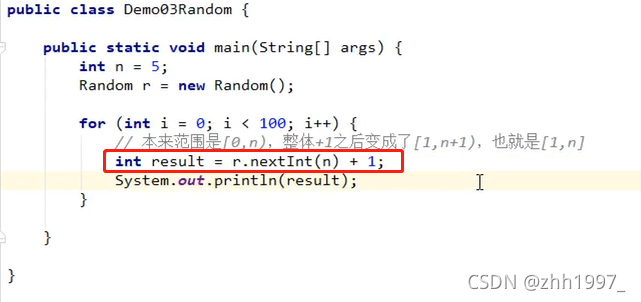
3.1 Random练习题1
生成1-n之间的随机数:

3.2 Random练习题2
猜数字小游戏(二分查找):
思路:

实现:
①无限次循环:
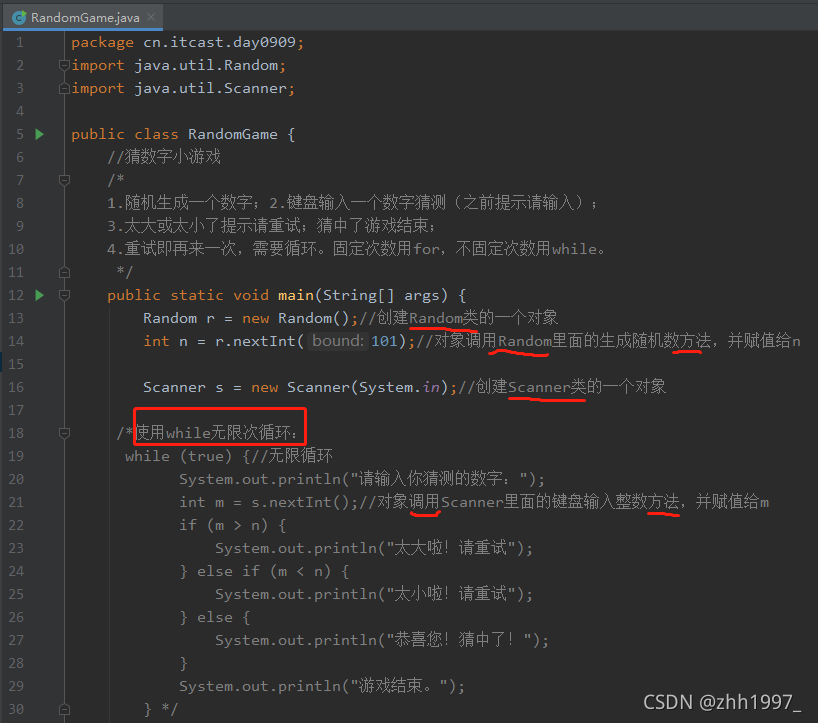 ②有限次循环:
②有限次循环:

4.ArrayList类:可变的数组集合
4.1 引入:对象数组
例:定义一个数组,用来存储3个Person类的对象
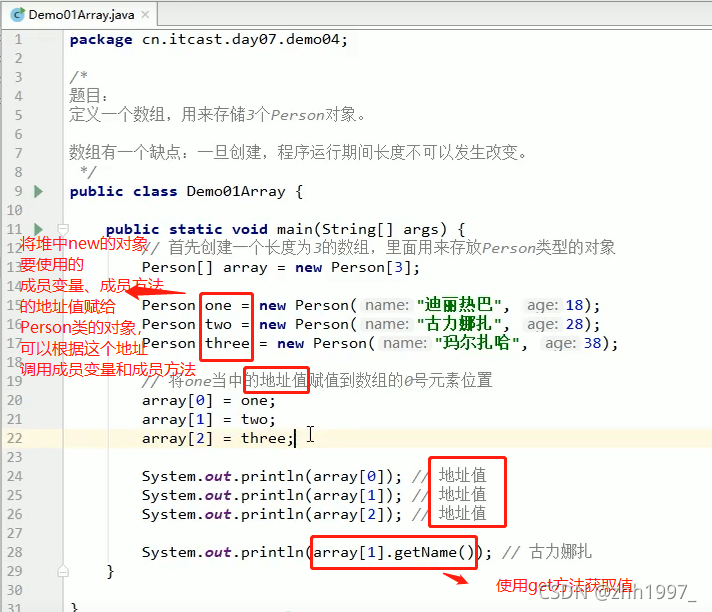
数组的缺点:一旦创建,程序运行期间长度不可以发生改变,长度不一样需要重新创建。为了解决这一问题,下面学习集合类:ArrayList.
ArrayList类:
这个类不同于其他类,多了一个尖括号 <E> 代表泛型。泛型:也就是装在集合当中的所有元素全都是统一的什么类型。
4.2 注意
①泛型只能是引用类型,不能是基本类型。
②对于ArrayList集合来说,直接打印对象名得到的不是地址值,而是集合中的内容。如果内容为空,则会打印空的中括号[](其实集合中存的是地址,只不过作者将这个类特殊处理了)。这是写ArrayList的作者定义的。如下图:

4.3 向集合当中添加数据
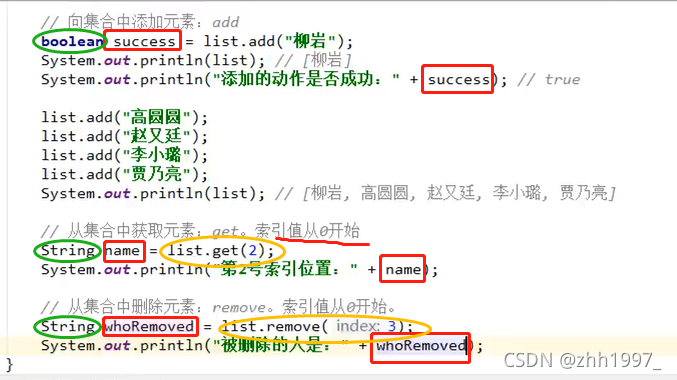
add方法
如上图的例子,添加数据格式:list.add("田雪");
4.4 ArayList 的常用方法和遍历
①常用方法 需要背!!

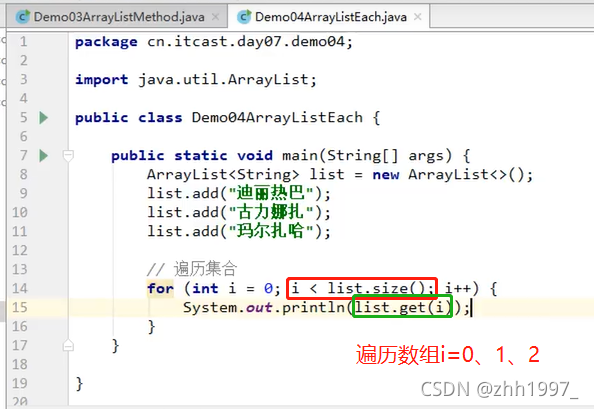
②遍历(和数组格式一样,调用的方法不同)
4.5 ArayList集合存储基本数据类型
因为ArrayList集合中存的是地址,而基本数据类型没有地址,因此不能直接使用,需要使用基本数据类型对应的 ”包装类“:

int型举例:
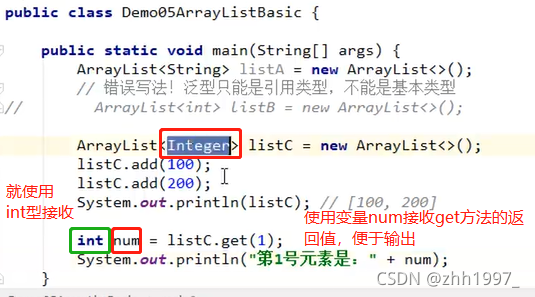
从JDK1.5+开始,支持自动装箱、自动拆箱:、
自动装箱:基本类型—>包装类型
自动拆箱:包装类型—>基本类型
即上图例子中直接写Integer类型,后面直接使用int型接收,JDK会自动转化。
4.6 ArrayList集合练习题
1. 数值添加到集合:
生成6个1~33之间的随机整数,添加到集合,并遍历集合。
思路:①需要存储6个数字,是数字,因此泛型为 <Integer> ;
②使用到随机数Random类,6个随机数即需要循环6次,循环次数确定因此使用for循环;
③添加到集合:add()方法;
④遍历集合:for循环、size()方法和get()方法。
实现:

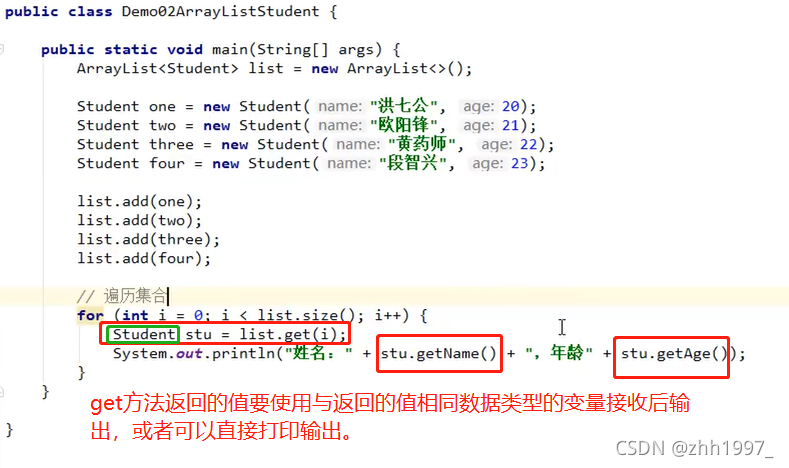
2. 对象添加到集合:
自定义4个学生对象,添加到集合并遍历。
思路:①既然有对象,就要自定义学生类(标准类四个部分);
②创建集合,泛型为: <Student> ;( 泛型指数据类型,类为引用型,对象不是数据类型,因此此处泛型写类名 )
③根据类创建四个对象并赋值;
④将四个学生对象添加到集合:add;
⑤遍历集合:for、size、get。
实现:
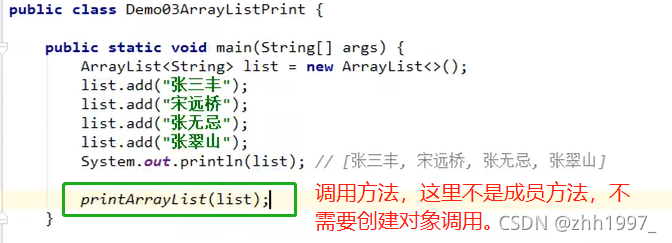
3. 打印集合方法:
定义以指定格式打印集合的方法(ArrayList类型作为参数):使用{}扩起集合,使用@分隔每个元素。格式参照{元素@元素@元素}。
思路:定义方法三要素:
返回值类型:只需要打印,没有运算、没有结果,因此无返回值;
方法名称:自定义即可;
参数列表:ArrayList <String> list。
实现:
main方法:

4. 获取集合方法:
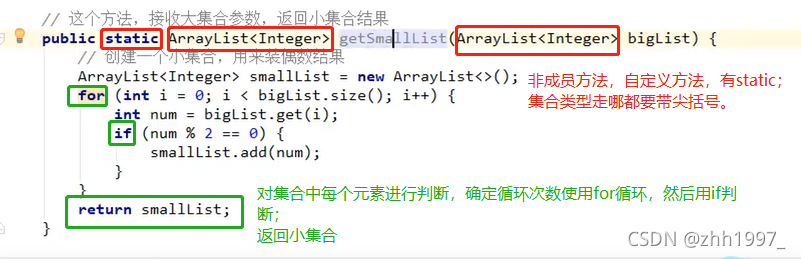
用一个大集合存入20个随机数字,然后筛选其中的偶数元素,放到小集合当中。
思路:

实现:
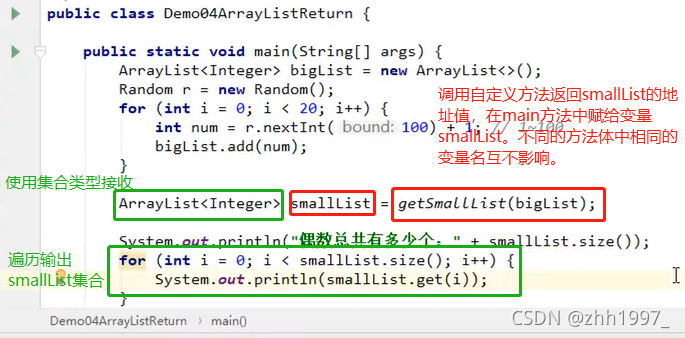
自定义筛选方法:
5.String类
5.1 概述
包:java.lang.String
API文档中String类:java程序中所有的字符串字面值(如:“abc" ) 都作为此类的实例实现。
其实就是说:程序当中所有的双引号字符串,都是String类的对象。(就算没有new,也照样是)
5.2 特点
①字符串的内容永不可变;
②正是因为字符串不可改变,所以字符串是可以共享使用的;
③字符串效果上相当于是char [ ] 字符数组,但是底层原理是byte [ ](字节数组,计算机存储一切数据都是二进制) 。
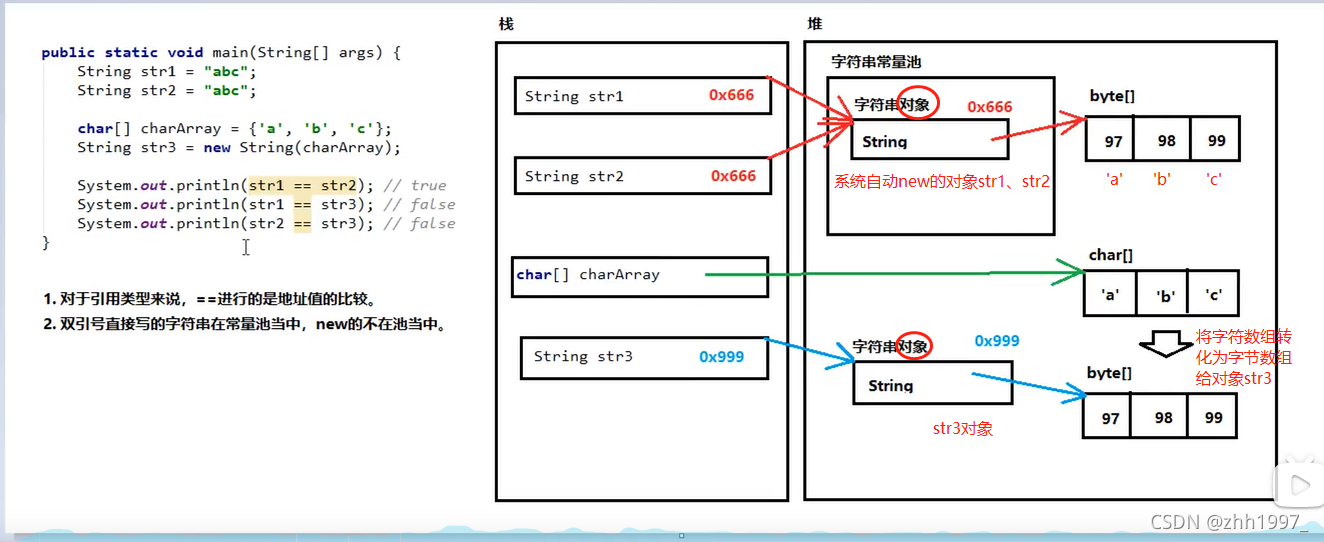
5.3 创建字符串

举例:

5.4 字符串的常量池
字符串常量池(在堆中):程序当中直接写上的双引号字符串,就在字符串常量池当中。
对于基本类型来说,==是进行数值的比较;对于引用类型来说,==是进行【地址值】的比较。
5.5 字符串的比较相关方法

5.6 字符串的获取相关方法
注意每个方法的返回值不同,需要用相同类型的变量接收后再使用!!

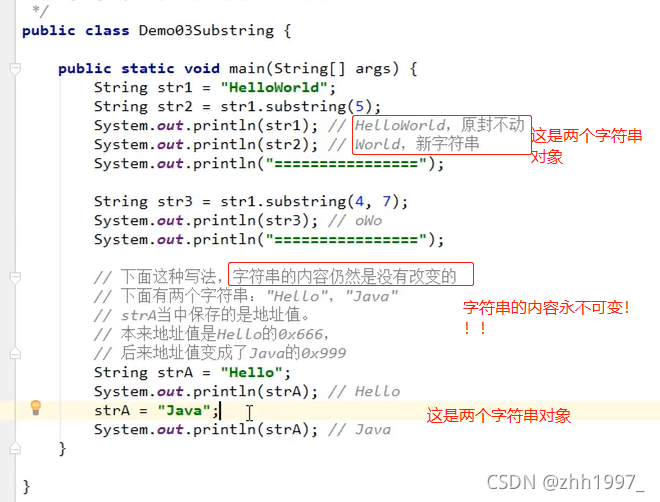
5.7 字符串的截取相关方法
注意每个方法的返回值不同,需要用相同类型的变量接收后再使用!!

举例:
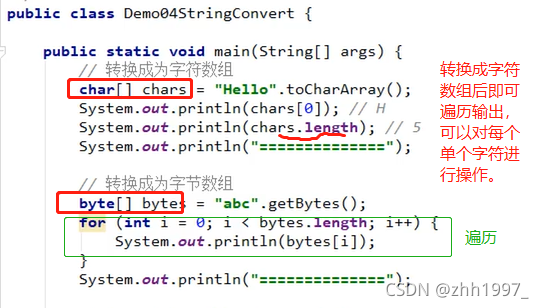
5.8 字符串的转换相关方法
注意每个方法的返回值不同,需要用相同类型的变量接收后再使用!!

三个方法举例:

5.9 字符串的分割相关方法
注意每个方法的返回值不同,需要用相同类型的变量接收后再使用!!
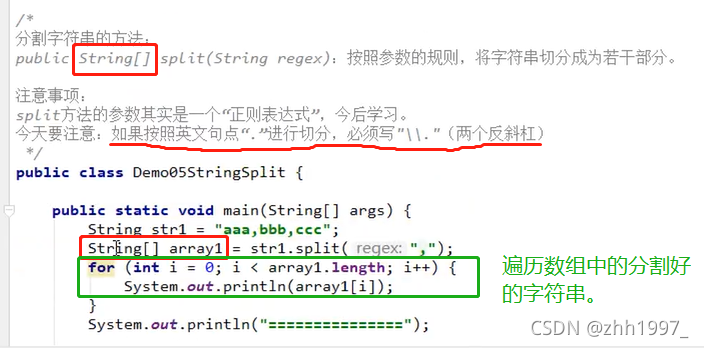
5.10 字符串练习题
1.拼接字符串:
定义一个方法,把数组{1,2,3}按照指定格式拼接成一个字符串,格式参照如下:[word1#word2#word3]。
思路:①准备一个数组,内容为:[1,2,3]
②定义一个方法:返回值类型:字符串;方法名:自定义;参数列表:数组
③拼接字符串:str1.cancat( str2 ) 或者直接 “ + ”
实现:
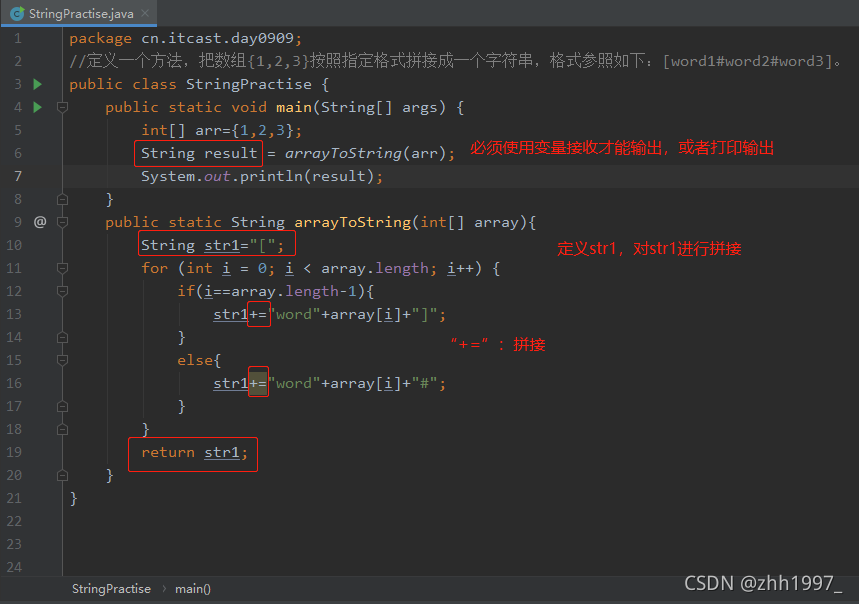
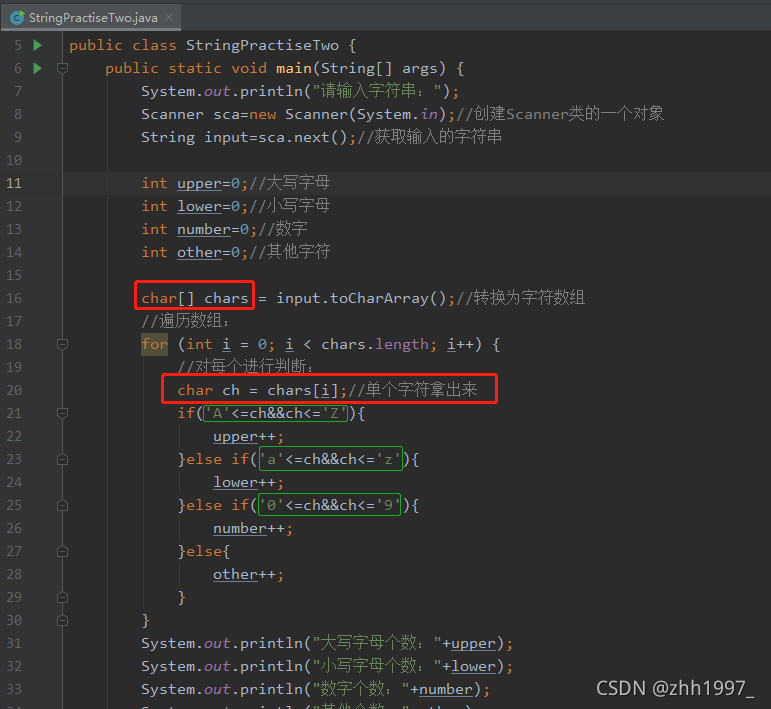
2. 统计字符个数:
键盘输入一个字符串,并且统计其中各种字符出现的次数。种类有:大写字母、小写字母、数字、其他。
思路:①键盘输入:Scanner,两行代码:
Scanner sc=new Scanner( System.in );
String str=sc.next();
②定义四个变量分别代表四中字符出现的次数
③需要对字符串一个字一个字地检查,因此要用到字符串的转换方法:将字符串拆分为字符数组:String—>char[ ]
④遍历char[ ]字符数组,对当前字符种类进行判断,并且四个变量进行++动作
⑤打印输出四个变量,分别代表四个变量出现的次数
实现:
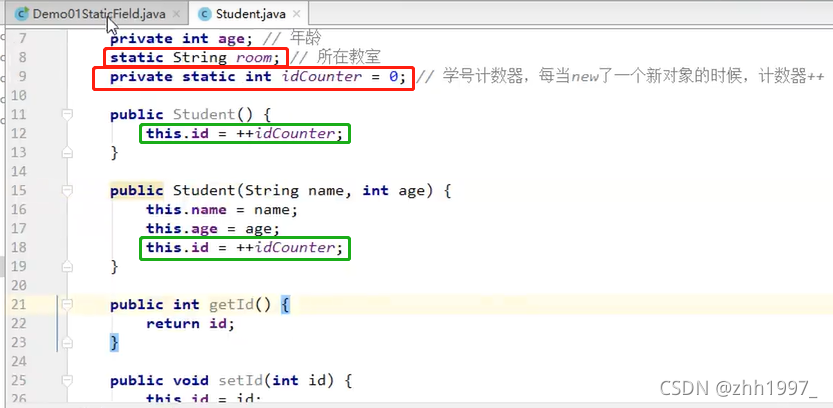
6.static关键字

6.1 static修饰成员变量
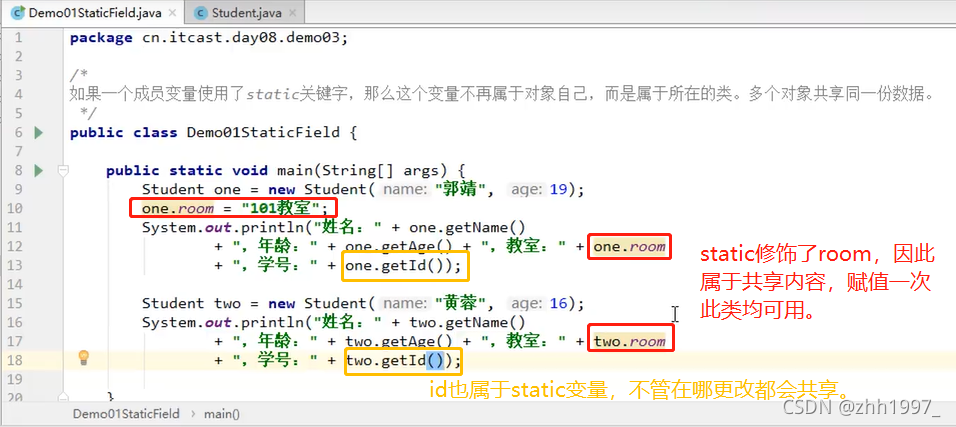
如果一个成员变量使用了static关键字,那么这个变量不再属于对象自己,而是属于所在的类,多个对象共享同一个数据。
举例:
学生类:
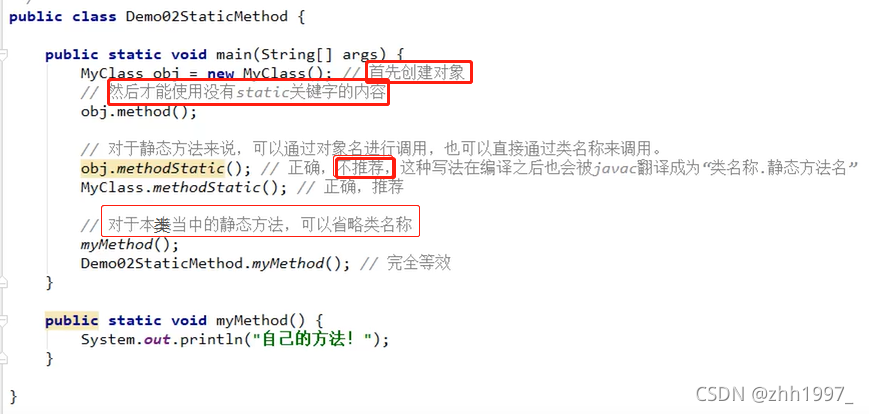
6.2 static关键字修饰成员方法
本类写的方法使用static关键字修饰,这样main方法中调用可以直接使用方法名调用,否则也要创建本类对象才能调用(main方法是静态方法)。
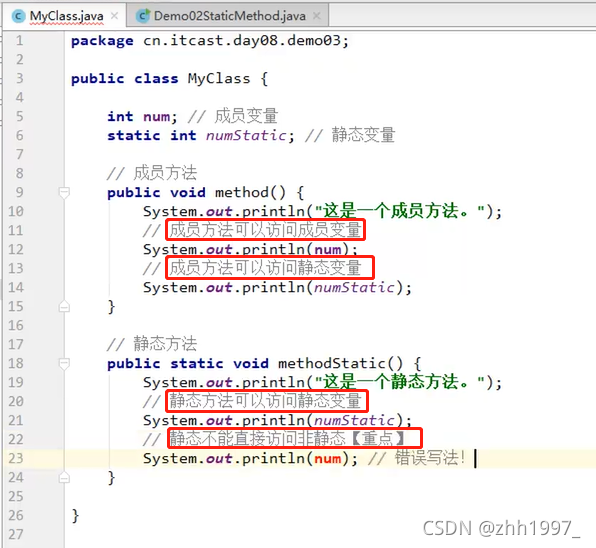
内存中先有静态内容,后有非静态内容!!

内存中先有静态内容,后有非静态内容!!静态不能直接访问非静态!!【后人知先人,先人不知后人】如下例:
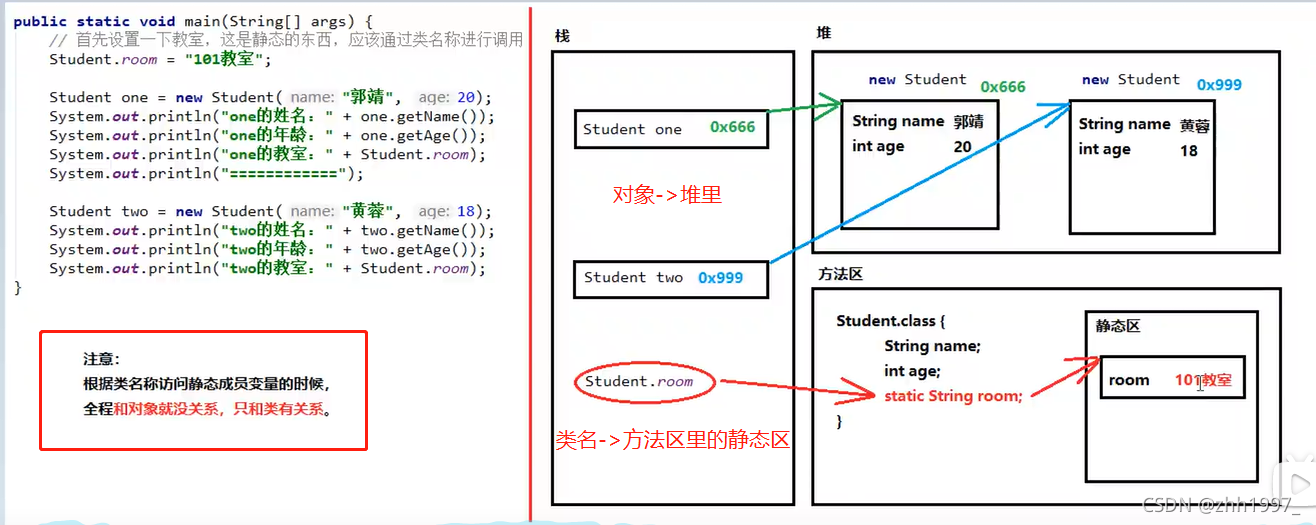
6.3 静态static的内存图
所有静态的东西不需要对象,和对象没关系,直接使用类名进行调用。
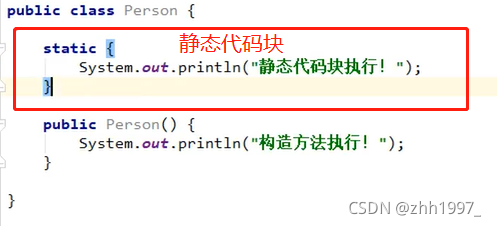
6.4 静态代码块
①静态代码块不写在方法中,直接写在类当中。当第一次用到本类时,静态代码块会执行唯一的一次。
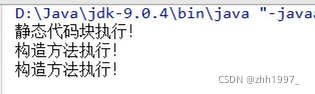
②静态内容总是优先于非静态内容。所以静态代码块比构造方法先执行。
③静态代码块的典型用途:用来一次性地对静态成员变量进行赋值。
举例:
Person类:
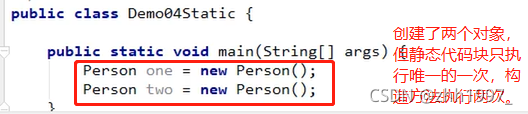
调用:
结果:
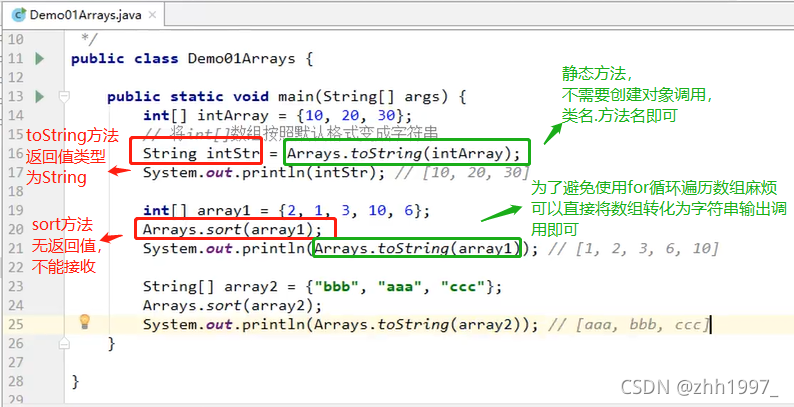
6.5 Arrays:数组工具类
①java.util.Arrays是一个与数组有关的工具类,里面提供了大量静态方法,用来实现数组常见的操作。
②方法:
public static String toString(数组):将参数数组变成字符串(按照默认格式:[元素1,元素2, 元素3....])
public static void sort(数组):按照默认升序(从小到大)对数组的元素进行排序
注意:【1】如果是数值,sort默认按照升序从小到大
【2】如果是字符串,sort默认按照字母升序
【3】如果是自定义类型,那么这个自定义的类需要有Comparable或者
Comparator接口的支持。(今后学习)
举例:
Arrays练习题:
请使用Arrays相关的API,将一个随机字符串中的所有字符升序排列,并倒序打印。
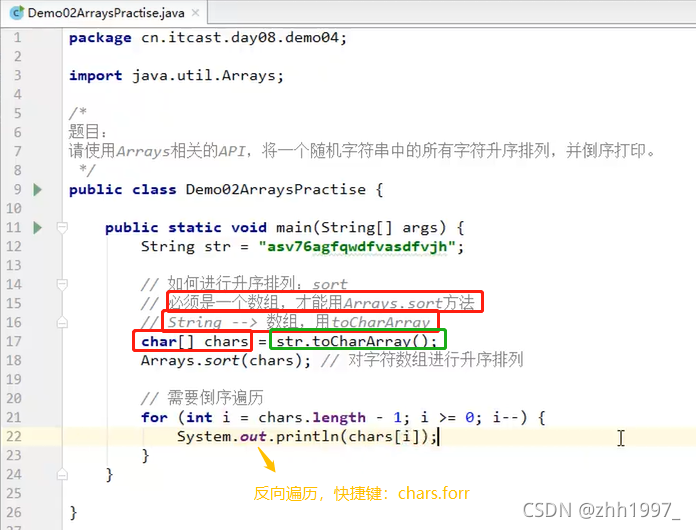
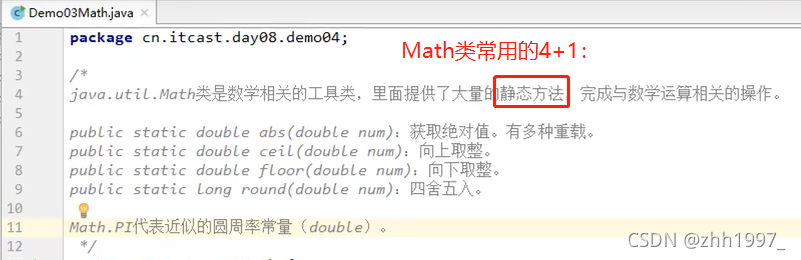
6.6 Math类
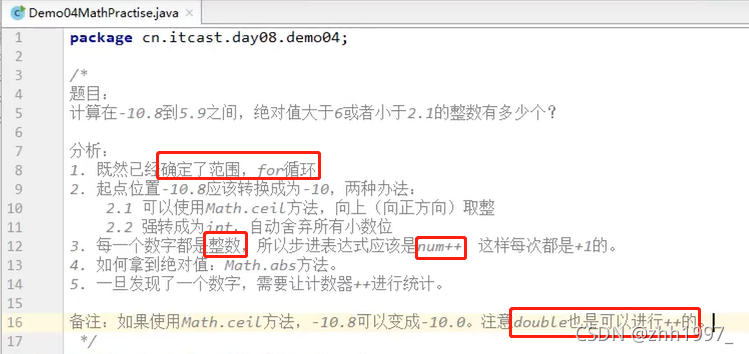
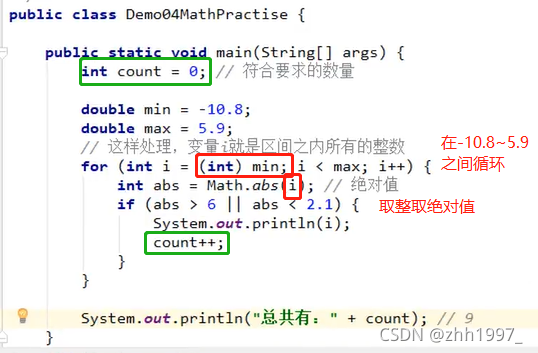
练习:
计算在-10.8~5.9之间,绝对值大于6或者小于2.1的整数有多少个。
十六、面向对象三大特征-继承性
1.概念
继承是多态的前提,如果没有继承,就没有多态。
继承主要解决的问题就是:共性抽取。
在继承关系中,“子类就是一个父类”,也就是说子类可以被当做父类看待。例如父类是员工,子类是讲师,那么“讲师就是一个员工”。关系:is-a。
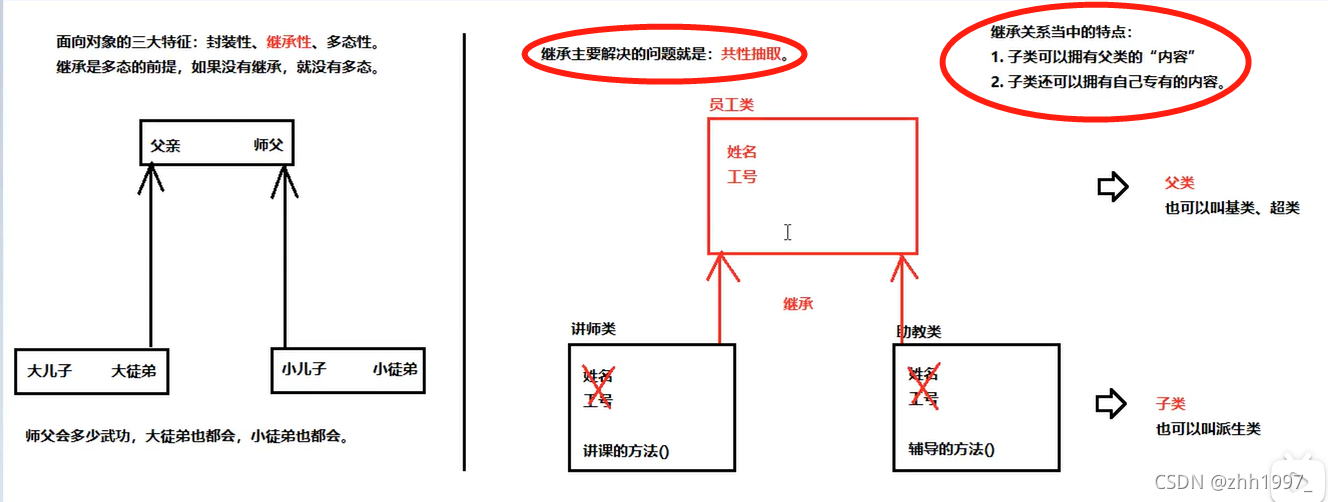
2.格式
①定义父类的格式:就是一个普通的类定义格式
public class 父类名称 {
//...(成员变量成员方法构造方法等)
}
②定义子类的格式:
public class 子类名称 extends 父类名称 {
//...(成员变量成员方法构造方法等)
}
3.继承中成员变量的访问特点
3.1 变量名不重名
父类对象只能使用父类自己的变量,子类对象可以使用自己和父类的变量。
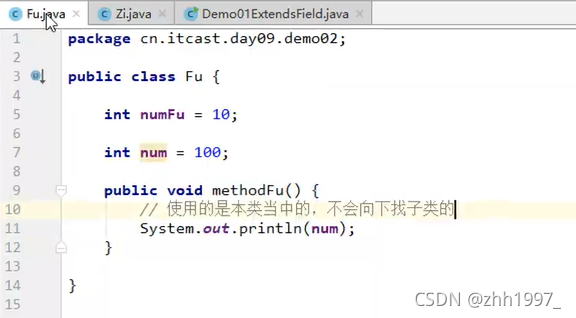
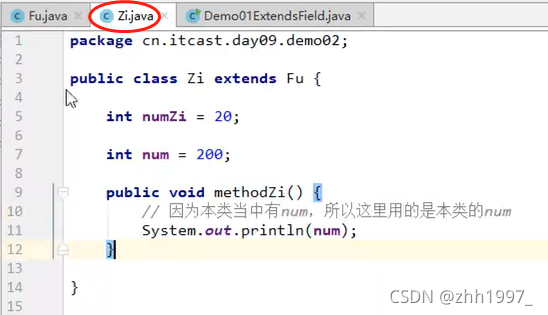
3.2 变量名重名
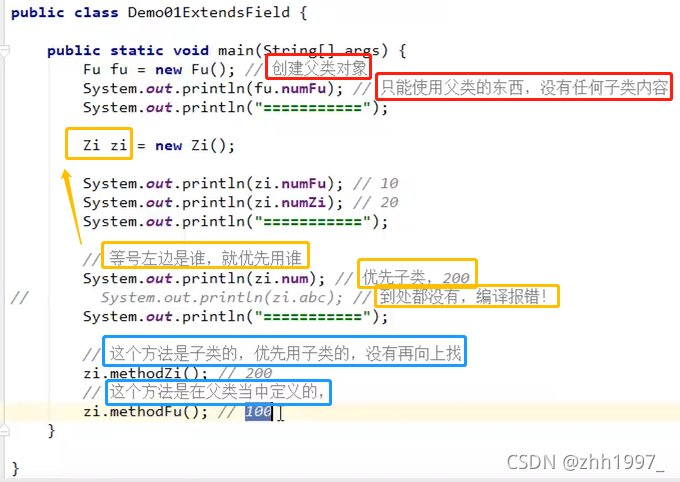
在父子类的继承关系当中,如果成员变量重名,则创建子类对象时,访问有两种方式:
①直接通过子类对象访问成员变量:等号左边是谁,就优先用谁,没有则向上找;
②间接通过成员方法访问成员变量:该方法属于谁(在子类还是父类中定义?),就优先用谁,没有则向上找。
举例:
main函数创建对象调用:
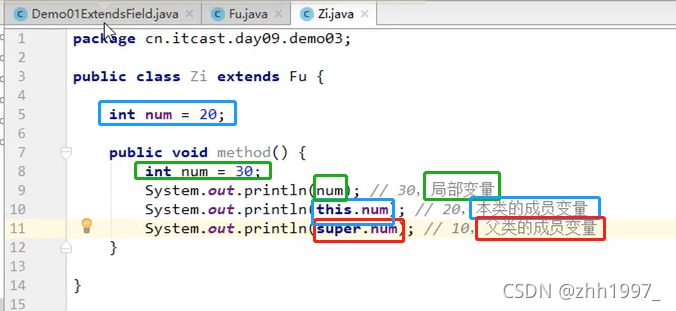
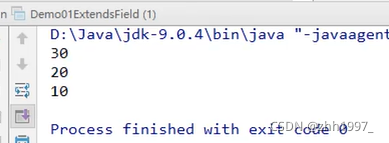
3.3 区分三种变量重名
局部变量:直接写成员变量名调用,就近使用局部变量;
本类的成员变量:this.成员变量名;
父类的成员变量:super.成员变量名。
举例:
子类:
main方法:
结果:
4.继承中成员方法的访问特点
4.1 方法名不重名
父类对象只能使用自己的方法,子类对象可以使用自己和父类的方法。
4.2 方法名重名
在父子类的继承关系中,创建子类对象,访问成员方法的规则:创建的对象是谁,就优先用谁,如果没有则向上找。
4.3 注意事项
无论是成员变量还是成员方法,如果没有都是向上找父类,绝对不会向下找子类。
举例:
父类:
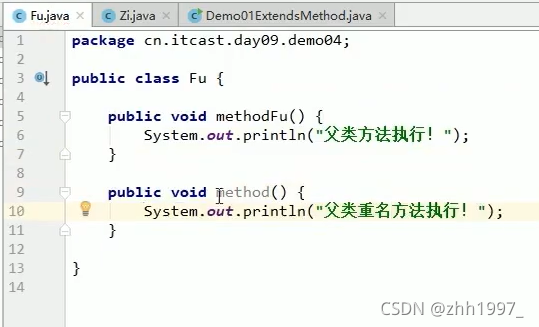
子类:
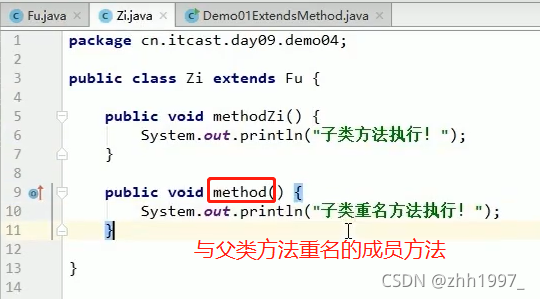
main方法:
结果:
5.方法的重写(覆盖、覆写)
5.1 概念
在继承关系中,方法的名称一样,参数列表也一样。
5.2 对比重写和重载
重写:(Override):方法的名称一样,参数列表【也一样】,推荐叫覆盖、覆写;
重载:(Overload):方法的名称一样,参数列表【不一样】。
5.3 特点
创建的是子类对象,则优先用子类方法。(new谁用谁)
5.4 注意事项
①必须保证父子类之间方法的名称相同,参数列表也相同。
② @Override:写在方法前面,用来检测是不是有效的正确覆盖重写。这个注解就算不写,只要满足要求,也是正确的方法覆盖重写。
③子类方法的返回值必须【小于等于】父类方法的返回值范围。
java.lang.Object类是所有类的公共最高父类(祖宗类),java.lang.String就是Object的子类。
④子类的方法的权限必须【大于等于】父类方法的权限修饰符。
public > protected > (default) >private
(default)不是关键字 default,而是什么都不写,默认类型。
5.5 应用场景
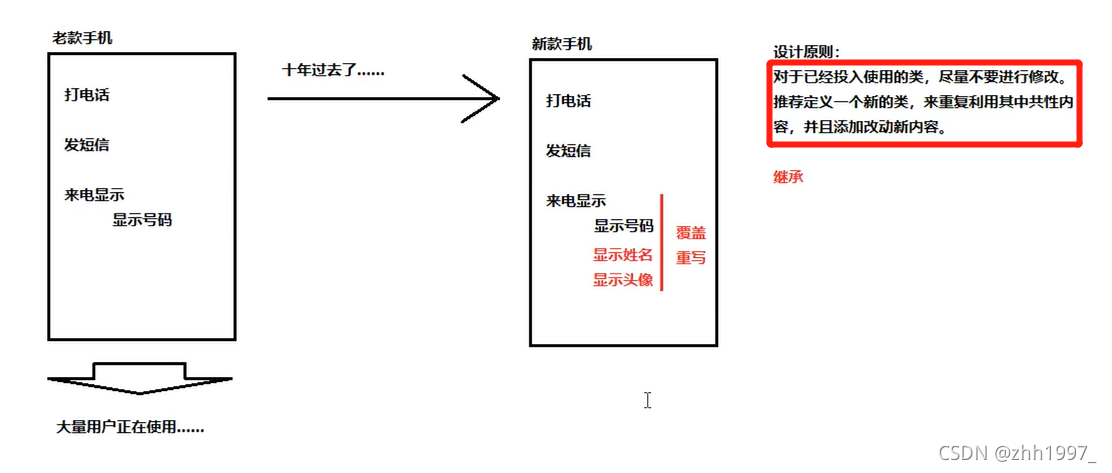
举例:
原来的方法:
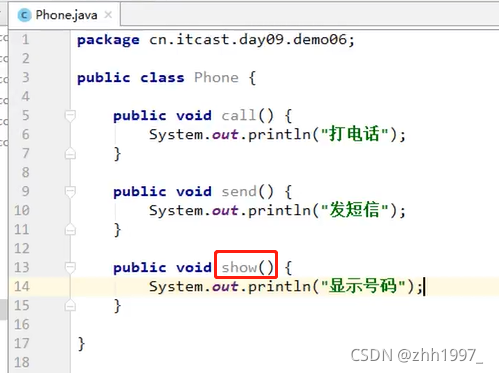
新手机show方法覆盖:
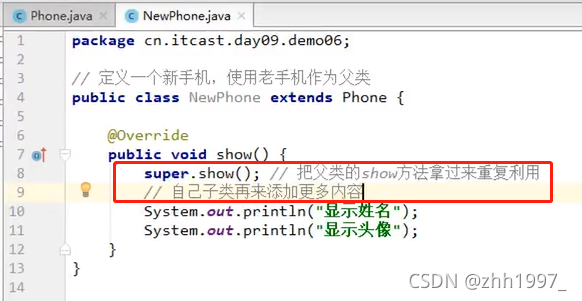
6.继承中构造方法的访问特点

7.super关键字的三种用法:(访问父类)
①在子类的成员方法中,访问父类的成员变量;
①在子类的成员方法中,访问父类的成员方法;
①在子类的构造方法中,访问父类的构造方法。
举例:

8.this关键字的三种用法:(访问本类)
①在本类的成员方法中,访问本类的成员变量;
②在本类的成员方法中,访问本类的另一个成员方法;
③在本类的构造方法中,访问本类的另一个构造方法。
注:A. this(...)调用也必须是构造方法的第一个语句,唯一一个;
B. super和this两种构造调用不能同时使用。
举例:①②
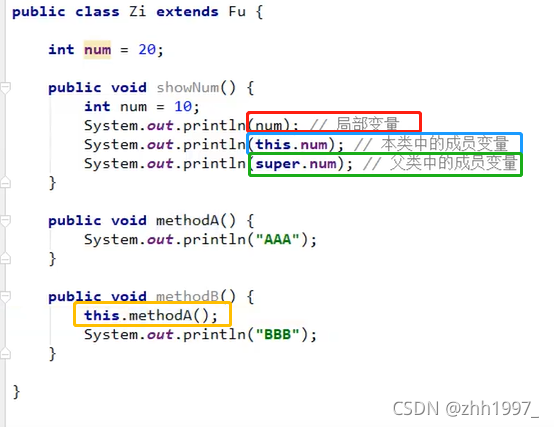
举例③:
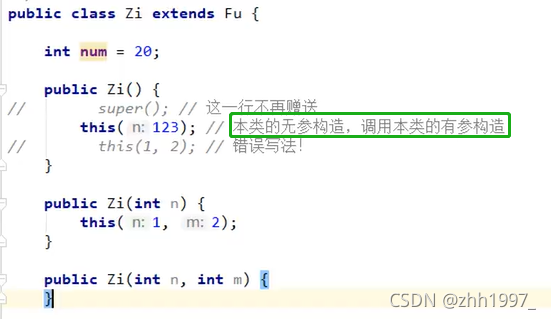
9.super与this关键字图解
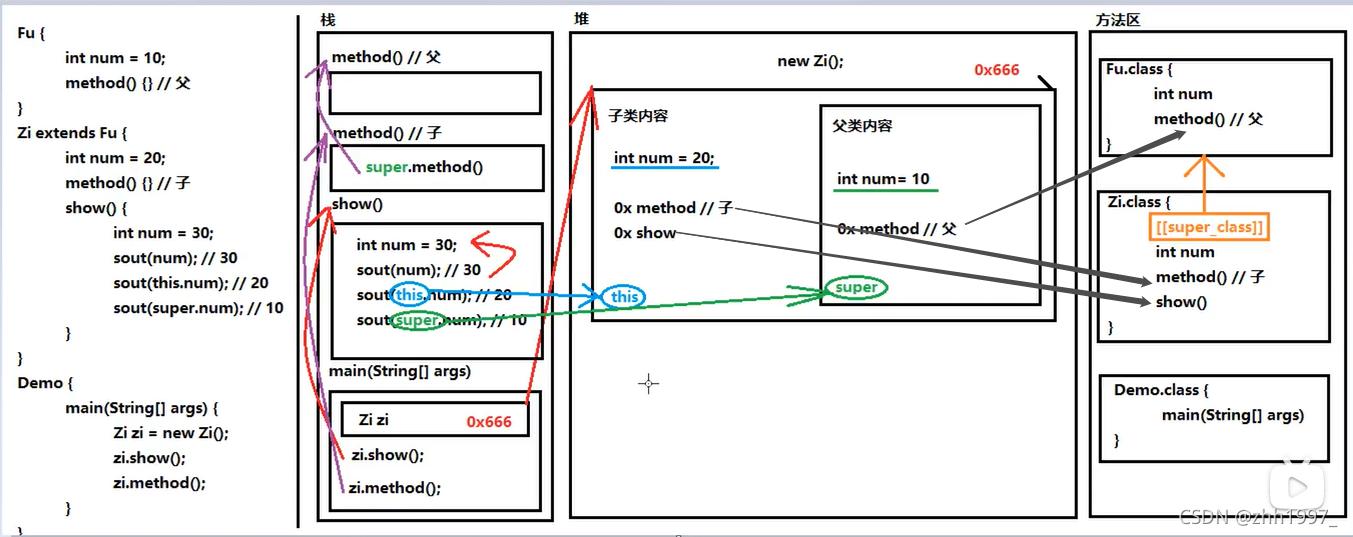
10.java继承的三个特点
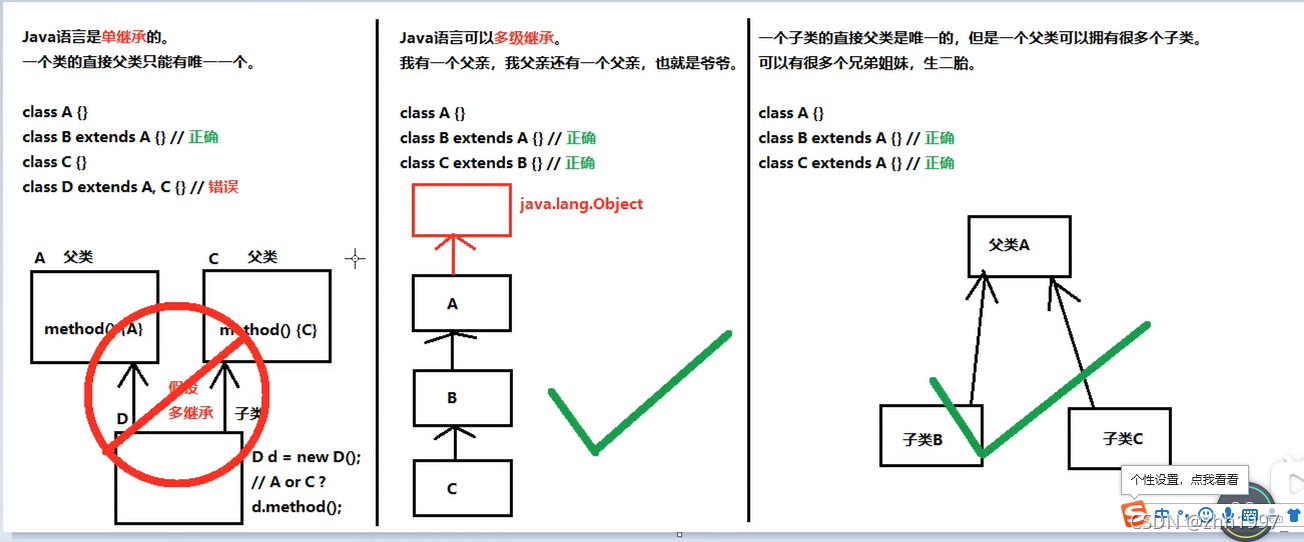
①java语言是单继承的,即一个类的直接父亲只能有唯一一个;
②java语言可以多级继承;
③一个子类的直接父亲是唯一的,但是一个父类可以拥有很多个子类。
如下图:
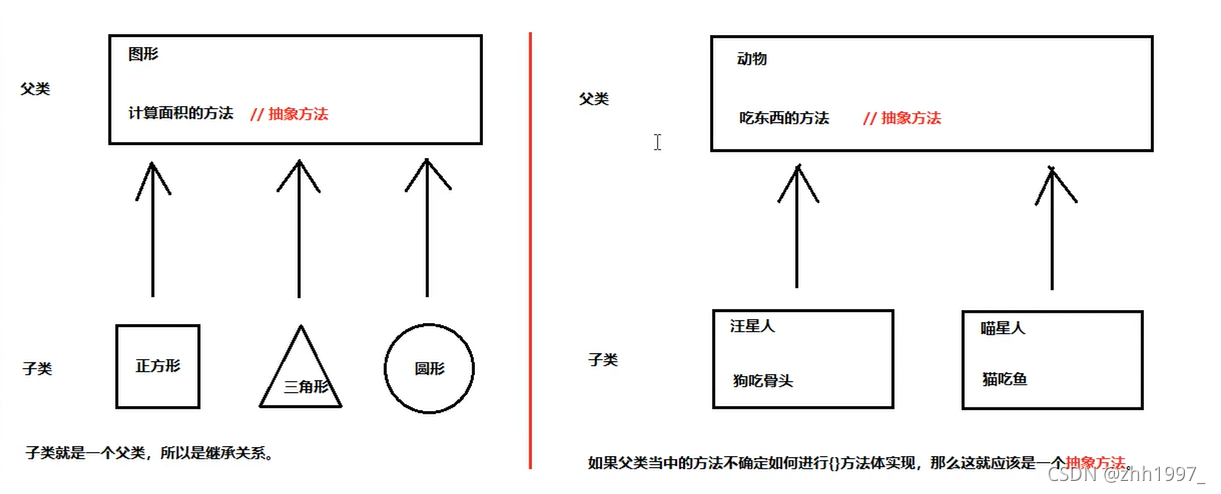
11.抽象的概念
如下图:
问图形的面积?—>抽象方法。
问动物吃什么?—>抽象方法。
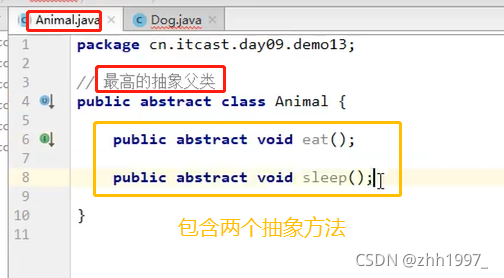
如果父类当中的方法不确定如何进行 { } 方法体实现,那么这就应该是一个抽象方法。
12.抽象方法和抽象类
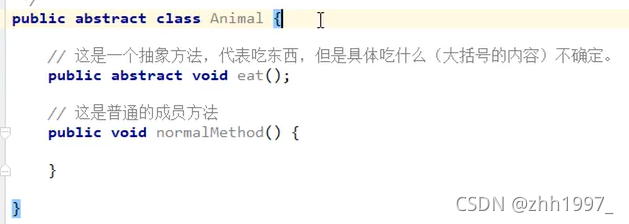
12.1 格式
①抽象方法:返回值前加上abstract关键字,去掉大括号,直接分号结束;
②抽象类:抽象方法所在的类必须是抽象类才行,在class之前写上abstract。
举例:
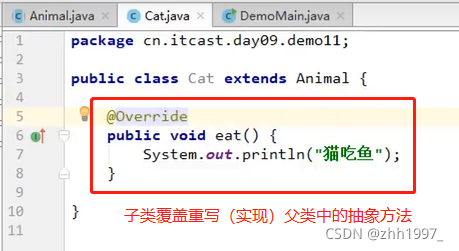
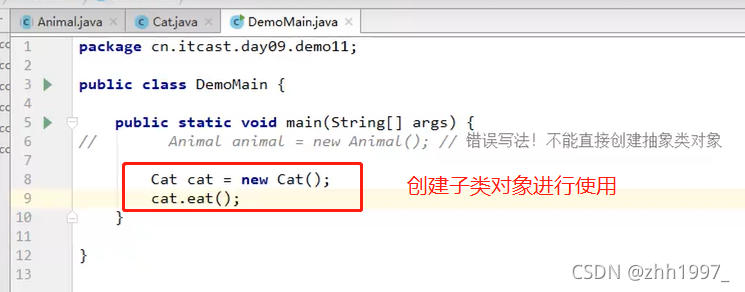
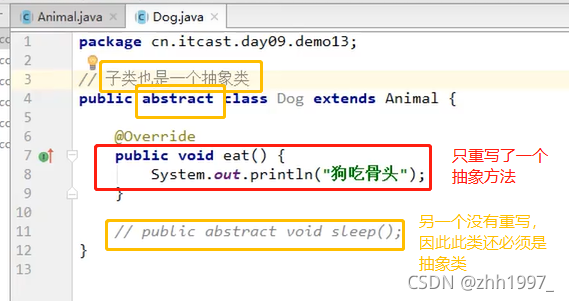
12.2 使用
①不能直接创建抽象类对象(比如创建一个动物?要么创建一只狗要么创建一只猫,不能创建一只动物,抽象不能单独存在);
②必须用一个子类来继承抽象父类(子类就是一个父类);
③子类必须覆盖重写(实现)抽象父类中的所有的抽象方法。覆盖重写(实现):去掉抽象方法的abstract关键字,然后补上方法体大括号;
④创建子类对象进行使用。
举例:
12.3 注意事项

举例②:
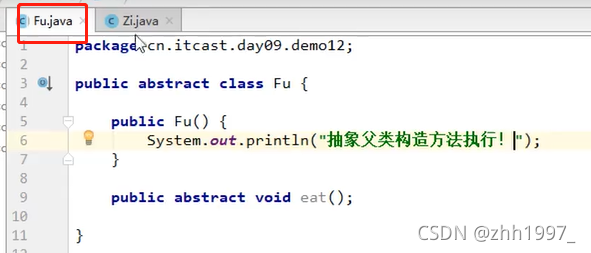
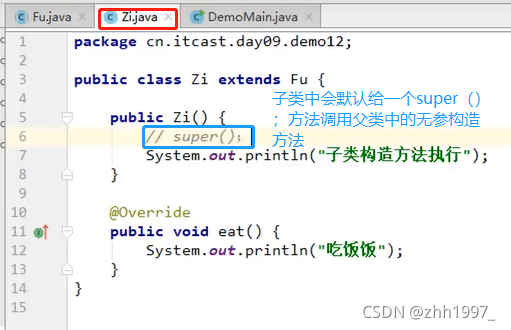
main方法中创建对象使用:
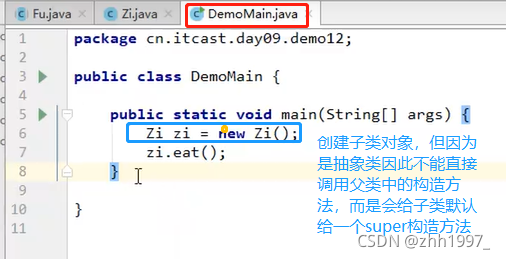
结果:
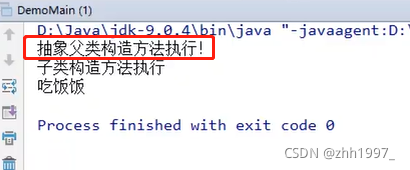
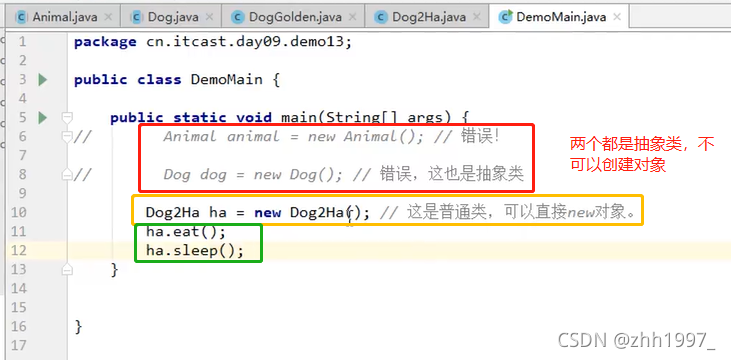
举例④:含有抽象方法的类必须是抽象类!抽象类的子类必须重写所有抽象方法!抽象类不能直接创建对象!
父类:
子类:
孙子辈类:重写了sleep方法,不含抽象方法。
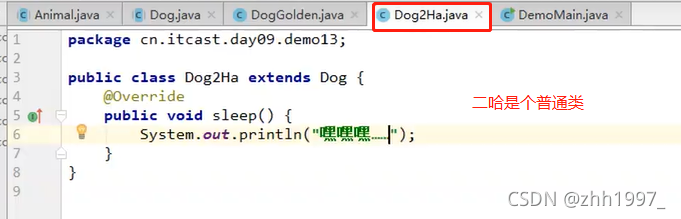
main方法:
12.4 继承综合案例
发红包案例还没完全搞明白,看视频吧。
13.接口
接口和类是两个并列的结构,类只能单继承,接口可以多实现。
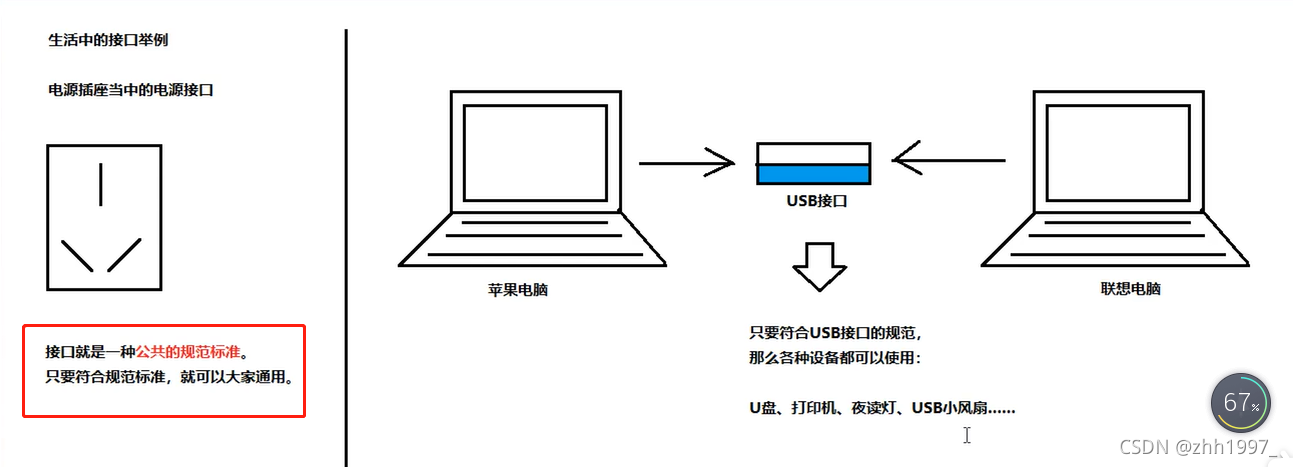
统一的规范标准。是一种【引用数据类型】
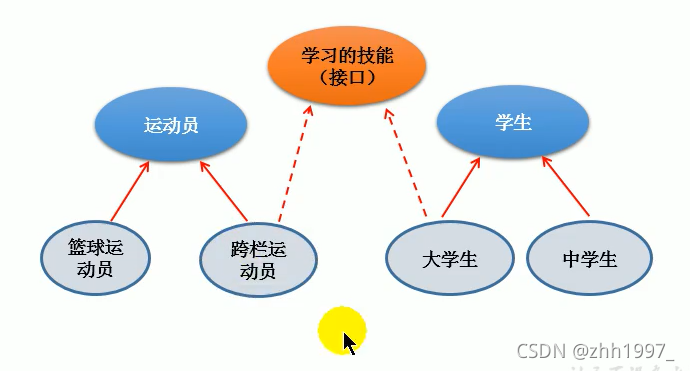
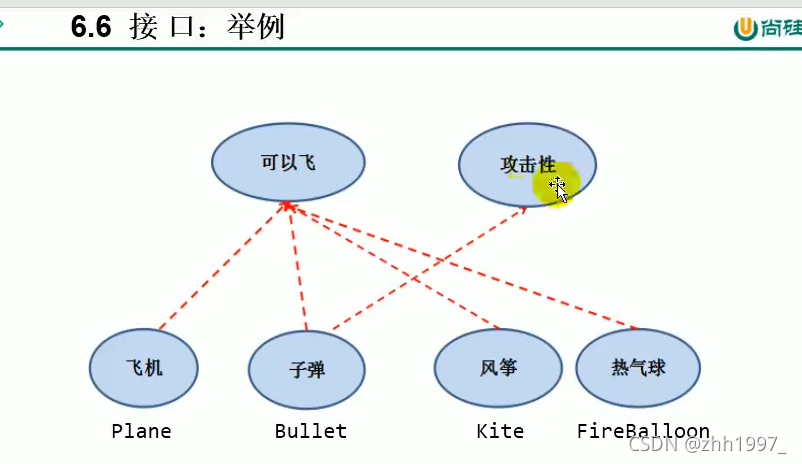
13.1 接口概述
13.2 接口的定义基本格式
接口就是多个类的公共规范,是抽象类的延伸,是一种【引用数据类型】,最重要的内容就是其中的:抽象方法。
格式:
public interface 接口名称{
// 接口内容
}
备注:class关键字换成了interface之后,编译生成的字节码文件仍然是.java—>.class
接口内容:
JAVA7:
1.常量
2.抽象方法
JAVA8:
3.默认方法
4.静态方法
JAVA9:
5.私有方法
使用步骤:
1.接口不能直接使用,必须有一个“实现类”来实现该接口(和子类差不多);
格式:public class 实现类名称 implements 接口名称{
//...
}
2.接口的实现类必须覆盖重写(实现)接口中所有的抽象方法:去掉abstract关键字,加上方法体大括号;
3.创建实现类的对象,进行使用。
下面一一学习:
13.3 接口的抽象方法定义和使用
基本格式:
在任何版本的java中 ,接口都能定义抽象方法。格式:
public abstract 返回值类型 方法名称(参数列表);
使用:
创建实现类的对象名 . 重写的抽象方法名
注意事项:
①.接口当中的抽象方法,修饰符必须是两个固定的关键字:public abstract;
②.这两个关键字修饰符,可以选择性地省略;
③.方法的三要素(返回值类型、方法名、参数列表)可以随意定义;
④.如果实现类并没有覆盖重写接口中所有的抽象方法,那么这个实现类自己就必须是抽象类。
举例②:

13.4 接口的默认方法定义和使用
JAVA8开始。
格式:
Public default 返回值类型 方法名称(参数列表){
方法体
}
备注:
接口当中的默认方法,可以解决接口升级的问题。
即当接口中新添加方法时,若添加了抽象方法,则以前所有已经使用的实现类需要重新覆盖这个方法,否则会报错。但新添加的方法写成默认方法则不用重写,而且可以直接通过其他实现类的对象直接调用(对象.方法名),实现类中没有会往上找接口。但是实现类要是重写了这个默认方法,则优先使用实现类中的方法。
使用:
①接口的默认方法,可以通过接口实现类对象直接调用,实现类没有则向上找接口中的方法;
②接口的默认方法,也可以被接口实现类进行覆盖重写,一旦重写优先使用实现类中的方法。
13.5 接口的静态方法定义及使用
JAVA8开始。
格式:
public static 返回值类型 方法名称(参数列表){
方法体
}
提示:
就是将abstract或者default换成static即可,带上方法体。
静态方法和对象没有关系!!不能通过接口实现类的对象来调用接口中的静态方法。
正确用法:
通过接口名称,直接调用其中的静态方法:接口名.静态方法名(参数);
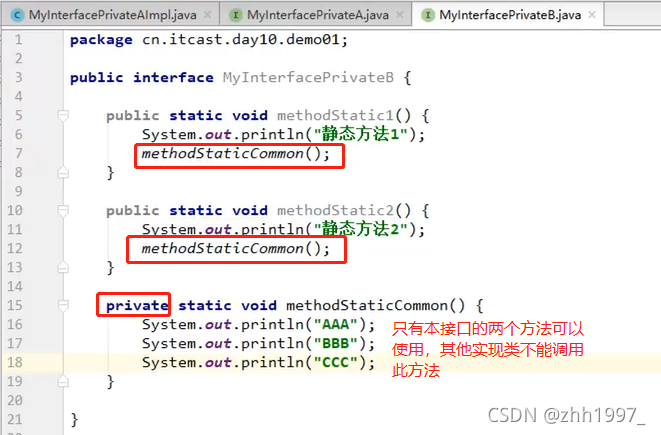
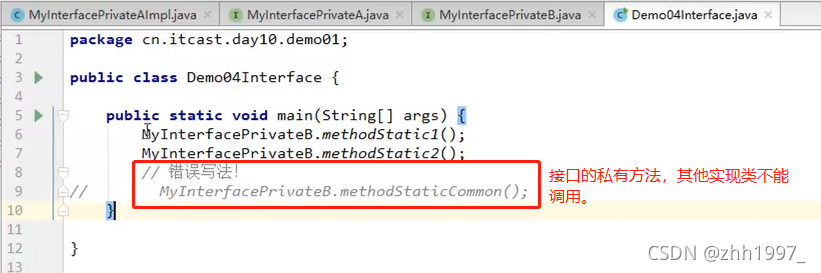
13.6 接口的私有方法定义及使用
JAVA9开始。
问题描述:
需要抽取一个共有方法,用来解决两个方法之间重复代码的问题,但是这个共有方法不应该让实现类使用,应该是私有化的。
使用:
①普通私有方法:解决多个默认方法之间重复代码的问题;
格式:
private 返回值类型 方法名称(参数列表){
方法体
}
②静态私有方法:解决多个静态方法之间的重复代码问题。
格式:
private static 返回值类型 方法名称(参数列表){
方法体
}
举例:
13.7 接口的常量定义及使用
接口当中也可以定义“成员变量”,但是必须使用public static final三个关键字进行修饰。从效果上看,这其实就是接口的【常量】。
格式:
public static final 数据类型 常量名称=数据值;
备注:
一旦使用final关键字进行修饰,说明不可改变。
使用:
因为有static修饰:接口名.变量名;
注意事项:
①接口当中的常量,可以省略public static final。注意,不写也默认这样;
②接口当中的常量,必须进行赋值,不能不赋值;
③接口中常量的名称,使用完全大写的字母,用下划线进行分割。(推荐)
13.8 接口内容小结:

继承父类并实现多个接口:
1.接口不能有静态代码块或者构造方法(抽象类中可以有构造方法,因为抽象类可以有成员变量,构造方法的作用就是对成员变量赋值,而接口中不能有成员变量,因此不能有构造方法);
2.一个类的直接父类是唯一的(所有类都是object的子类),但是一个类可以同时实现多个接口;格式:

3.如果实现类所实现的多个接口当中,存在重复的抽象方法,那么只需要覆盖重写一次即可;
4.如果实现类所实现的多个接口当中,存在重复的默认方法,那么实现类一定要对冲突的默认方法进行覆盖重写;
5.如果实现类没有覆盖重写所有接口当中的抽象方法,那么实现类就必须是一个抽象类;
6.一个类如果直接父类中的方法和接口当中的默认方法产生了冲突,优先使用父类当中的方法。
接口之间的多继承关系:
1.类与类之间是单继承的,直接父类只有一个;
2.类与接口之间是多实现的,一个类可以实现多个接口;
3.接口与接口之间是多继承的(一个接口可以继承多个接口)。
注意:1.多个父接口当中的抽象方法如果重复,没关系(抽象方法没有方法体,需要覆盖重写);
2.多个父接口当中的默认方法如果重复,那么子接口必须进行默认方法的覆盖重写,【而且带着default关键字】。
十七、面向对象三大特征-多态性
1.概述
面向对象三大特征:封装性,继承性,多态性,其中继承性是多态性的前提。
继承性在Java中的体现除了extends继承之外还有implements实现,因此extends继承或者implements实现,是多态性的前提(类与类之间的继承,接口与接口之间的继承,类与接口之间的实现,总之需要产生这样的上下关系)。
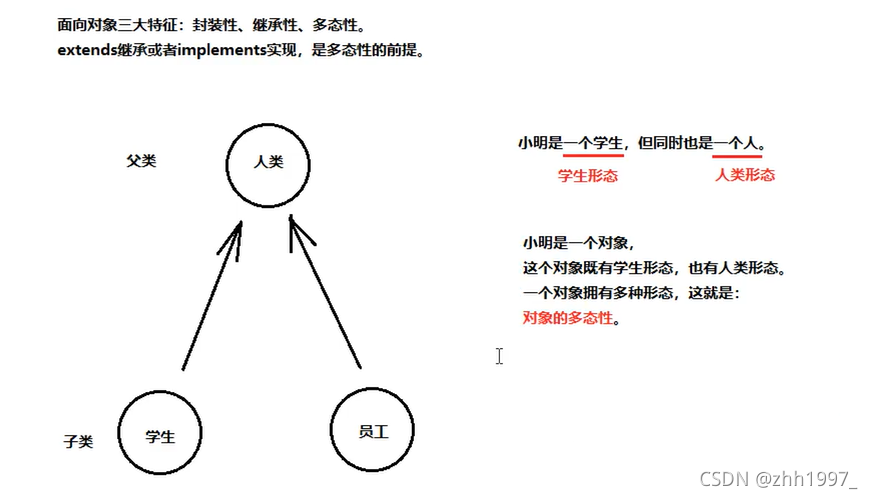
2.使用
代码中体现多态性其实就是一句话:父类引用指向子类对象。(即子类对象被当做父类来使用了,如一只猫被当做动物使用了)
格式【上下关系】:
父类名称 对象名 = new 子类名称; 或者:接口名称 对象名 = new 实现类名称;
举例:
父类:
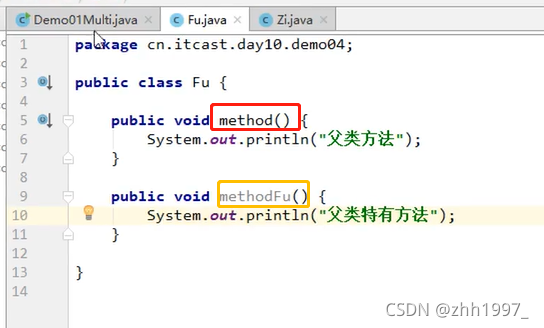
子类:
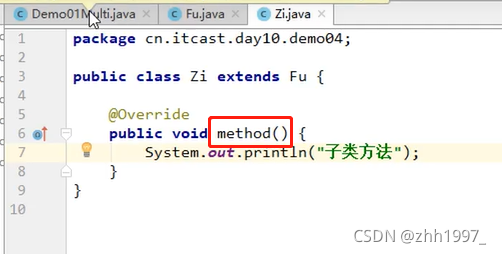
main方法:
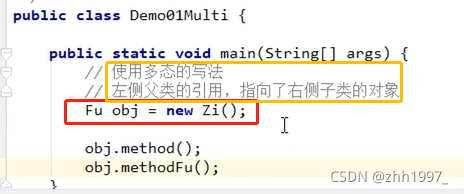
结果:

3.多态中成员变量的使用特点
多态中成员变量的访问规则和继承的使用规则一模一样!!
父类和子类变量名重名:
口诀:编译看左边,运行还看左边。
【直接访问看等号左边的类,间接访问看方法属于的类,变量不能重写,方法可以重写】
①直接通过对象名访问成员变量:等号左边是谁,优先用谁,没有则向上找,绝不会向下找;

②间接通过成员方法访问成员变量:该方法属于谁(在子类还是父类中定义?),就优先用谁,没有则向上找。
4.多态中成员方法的使用特点
多态中成员方法的访问规则和继承的使用规则一模一样!!
创建的对象是谁,就优先用谁,如果没有则向上找。
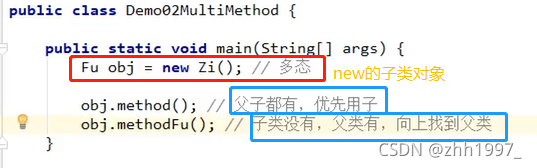
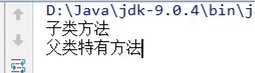
口诀:编译看左边,运行看右边。
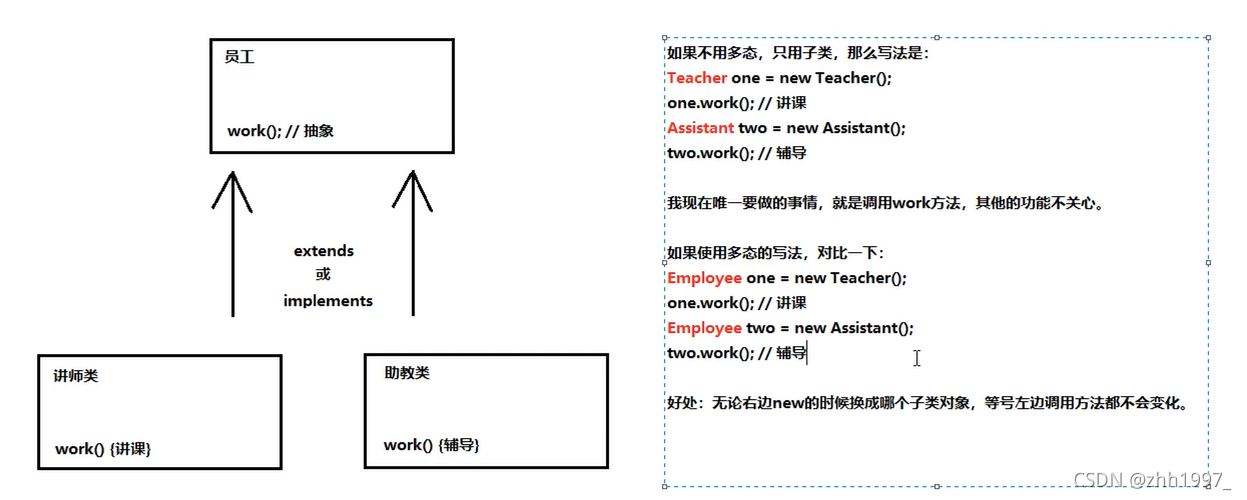
5.使用多态的好处
无论右边new的是哪个子类对象,等号左边对象调用方法不会变化。可以使程序具有良好的扩展性,易于维护,可以对所有类对象进行通用的处理。
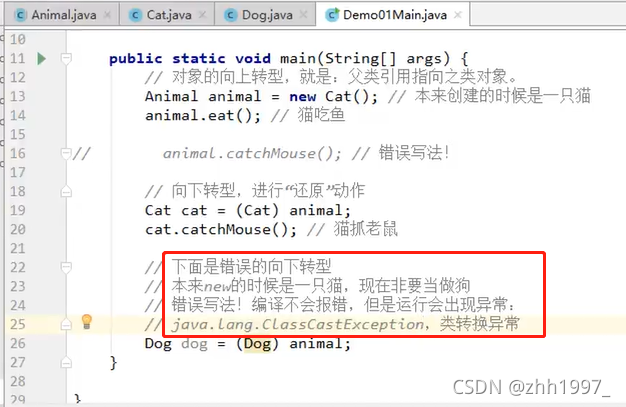
6.对象的向上转型
格式:
父类名称 对象名 = new 子类名称 ( );
把子类对象当做父类看待使用。
向上转型一定是安全的。但对象一旦向上转型为父类,就无法调用子类原本特有的方法。
7.对象的向下转型
向上转型一定是安全的。但对象一旦向上转型为父类,就无法调用子类原本特有的方法。
解决方案:用对象的向下转型【还原】。
格式:
子类名称 对象名=(子类名称) 父类对象;
含义:
将父类对象,【还原】成为本来的子类对象。
注意事项:
①必须保证对象本来创建的时候就是猫,才能向下转型成为猫;
②如果对象创建的时候本来不是猫,非要向下转型为猫,则会报错。

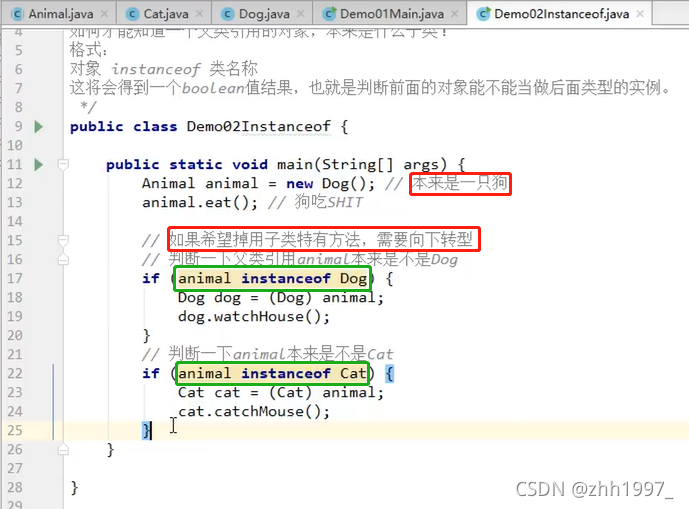
8.使用instanceof关键字判断对象类型
怎么判断父类动物的引用指向的对象是猫还是狗?即如何判断一个父类引用的对象是什么子类?
格式:
对象 instanceof 类名称
这将会得到一个Boolean值(if语句)结果,也就是判断前面的对象能不能当做后面类型的实例。
举例:
9.多态与接口相关的案例
案例要求:

分析:
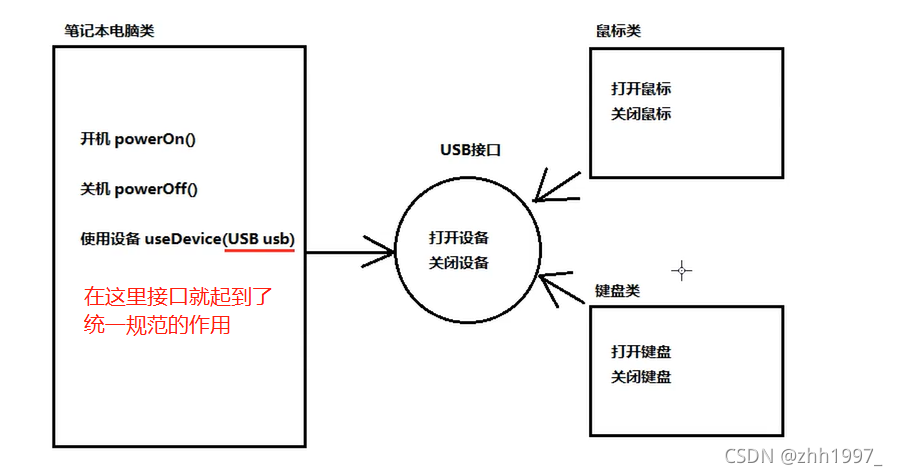
实现:
USB接口【里面封装了打开设备、关闭设备两个抽象方法,实现类必须重写才可使用】:
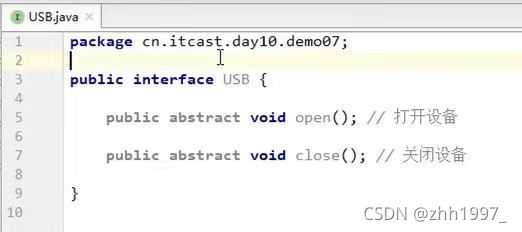
鼠标类实现USB接口【是一个USB设备,重写了USB接口中的抽象方法,也有自己特有的鼠标点击方法】:
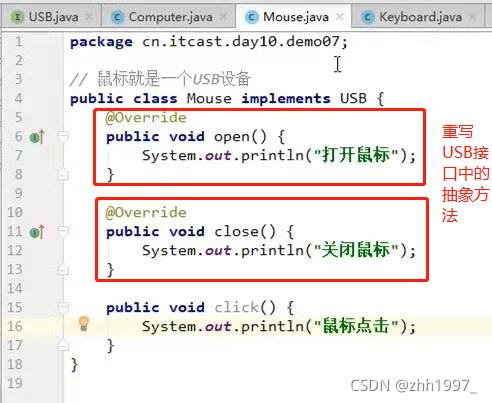
键盘类实现USB接口【是一个USB设备,重写了USB接口中的抽象方法,也有自己特有的键盘输入方法】:

电脑类【有自己的开机、关机方法,而且可以使用USB,USB接口是个引用类型,可以传参,接口的实现类对象也可以传递,会自动转型】:
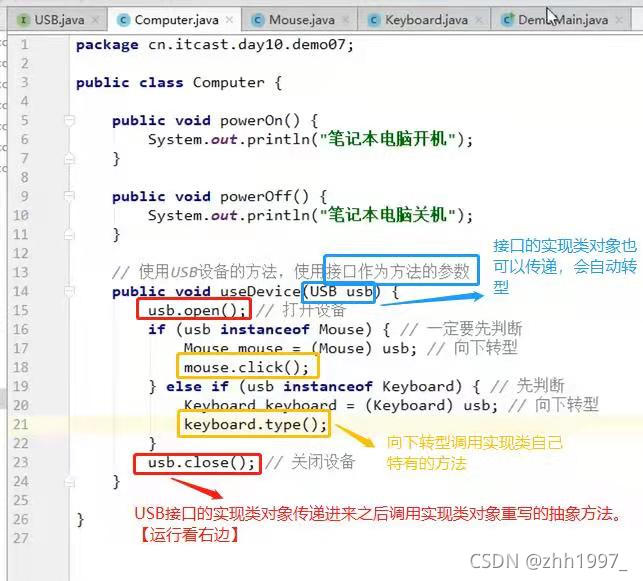
main方法【创建电脑类的对象进行开关机操作,创建USB接口对象(多态写法)或鼠标类、键盘类对象(不用多态写法)传递参数到电脑类的使用USB接口方法中,进行使用USB接口的操作】:
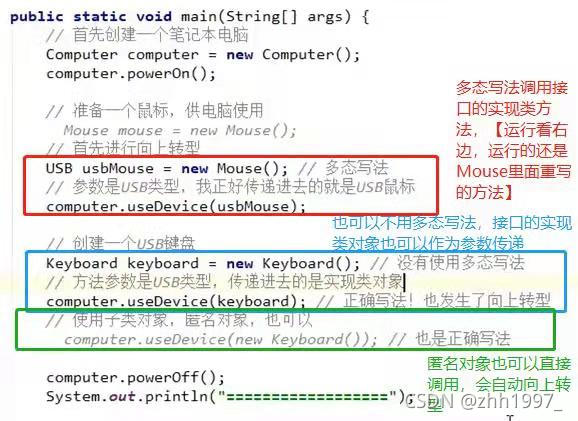
结果:
十八、类 的高级特性
1.final关键字
最终的、不可改变的。
四种用法:
①可以修饰一个类;
②可以修饰一个方法;
③可以修饰一个局部变量;
④可以修饰一个成员变量。
1.1 修饰类
当使用final关键字修饰一个类时,这个类就是最终类,成为太监类,即【不能有子类】,但他自己有父类(object)。而且final类中的所有的成员方法都无法进行覆盖重写(因为无子类),但final类可以覆盖重写他自己父类的方法。
格式:
public final class 类名称{
//...
}
1.2 修饰成员方法
当使用final关键字修饰一个方法时,这个方法就是最终方法,也就是【不能被覆盖重写】。
格式:
修饰符 final 返回值类型 方法名称(参数列表){
//方法体
}
注意事项:
对于final类、final方法来说,abstract关键字和final关键字不能同时使用,因为矛盾(一个必须有子类实现、方法必须覆盖重写,一个不能有子类,方法不能覆盖重写)。
1.3 修饰局部变量
局部变量:方法的大括号之内的变量。
当使用final关键字修饰一个局部变量时,那么这个变量就不能进行更改,不能进行二次赋值。【一次赋值,终生不变】
注意事项:
对于基本类型来说,不可变指变量中的数据值不可改变;
对于引用类型来说,不可变指变量中的地址值不可变,数据内容可以通过调用方法改变。
举例:

1.4 修饰成员变量
成员变量和局部变量的区别:成员变量有默认值【0/null】,局部变量必须赋值使用。
当使用final关键字修饰一个成员变量时,那么这个变量也照样不可变,但由于成员变量有默认值,所以用了final关键字之后必须手动赋值,因为加了final之后就不会默认给值。
对于final的成员变量,要么使用直接赋值,要么通过构造方法赋值,【二者选其一】。要是使用构造方法赋值,必须保证类当中的所有重载的构造方法都最终会对final的成员变量进行赋值。
2.四种权限修饰符修饰变量
java中有四种权限修饰符修饰变量时:
public > protected > ( default ) > private
同一个类(我自己) YES YES YES YES
同一个包(我邻居) YES YES YES NO
不同包子类(我儿子) YES YES NO NO
不同包非子类(陌生人) YES NO NO NO
注意:( default )并不是关键字“default”,而是什么修饰符都不写。
3.内部类
如果一个事物的内部包含另一个事物,那么这就是一个类内部包含另一个类。例如:身体和心脏的关系、汽车和发动机的关系,发动机离开汽车就没用了,装在火车上也没用。
分类:
①成员内部类;
②局部内部类(包含匿名内部类)。
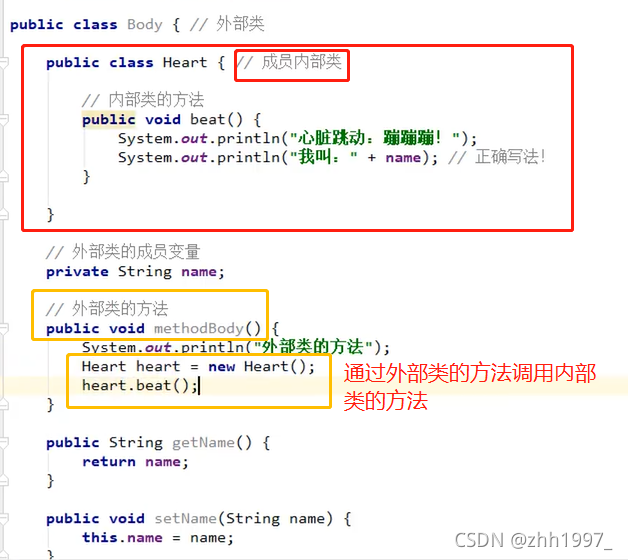
3.1 成员内部类:【类的内部,方法的外部】
①定义格式:
修饰符 class 外部类名称{
修饰符 class 内部类名称{
//...
}
//...
}
②注意:
内用外,随意访问;外用内,需要内部类对象。
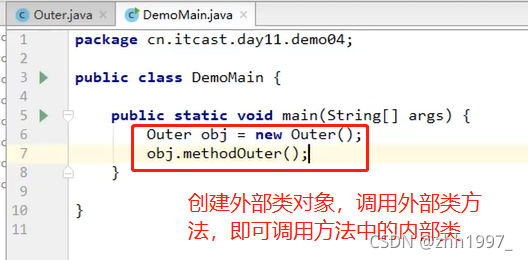
③使用:
1.间接方式:在外部类的方法中,使用内部类,然后main只是调用外部类的方法;
2.直接方式:不借助外部类的方法,直接创建内部类的对象使用,格式:外【点】内。
普通类:类名称 对象名=new 类名称();
内部类:外部类名称 . 内部类名称 对象名=new 外部类名称(). new 内部类名称();
举例:
Body类中有Heart类:
main方法:
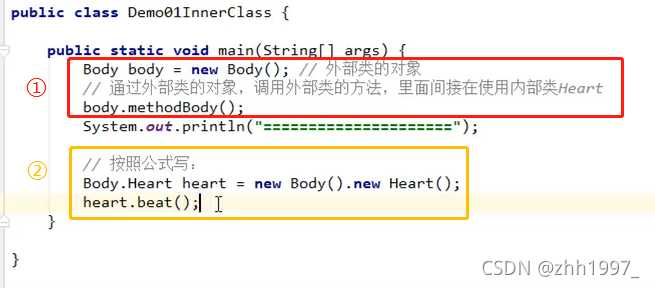
.class文件: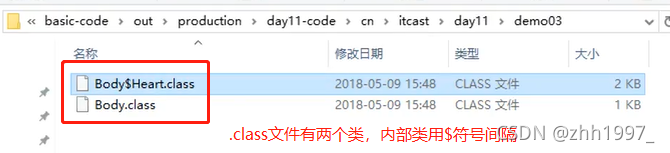
④重名变量访问问题:
如果出现了重名现象:
局部变量:就近原则(方法体内)
内部类的成员变量:this
外部类的成员变量:外部类名称 . this . 外部类成员变量名
举例: 
main方法及结果:
3.2 局部内部类
如果一个类是定义在一个方法内部的,那么这就是一个局部内部类。“局部”:只有当前所属的方法才能使用它,出了这个方法外面就不能用了。
①格式:
修饰符 class 外部类名称{
修饰符 返回值类型 外部类方法名称(参数列表){
class 局部内部类名称{
//...
}
}
}
②注意事项:
#局部内部类只有本方法可以使用。
#局部内部类如果希望访问所在方法的局部变量,那么这个局部变量必须是【有效final的】。从java8+开始,只要局部变量事实不变,那么final关键字可以省略。
原因:

举例:
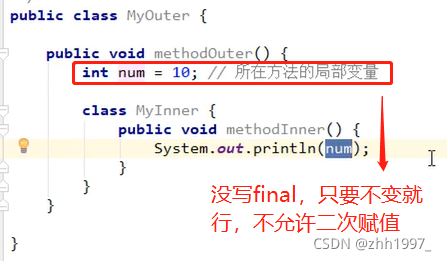
举例:局部内部类:

main方法及结果:
3.3 匿名内部类【重点】
如果 接口 的 实现类 (或者是父类的子类)只需要使用唯一的一次,那么这种情况下就可以省略掉该类的定义,而改为使用【匿名内部类】。
①定义格式:【多态写法,左接口右实现类】
接口名称 对象名 = new 接口名称(){
//覆盖重写所有抽象方法
};
举例:
接口:
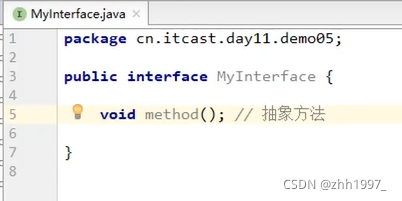
main方法:

②注意事项:
对格式“new 接口名称(){...}”进行解析:
1.new代表创建对象的动作;(实现类的对象)
2.接口名称就是匿名内部类需要实现哪个接口;
3.{...}这才是匿名内部类的内容。
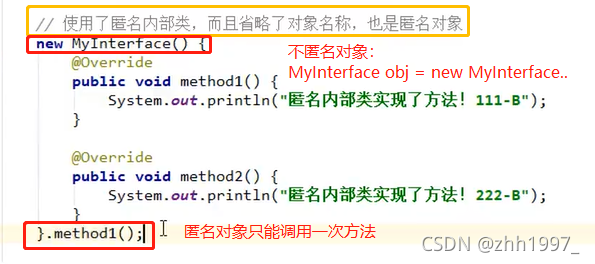
同时注意:
1.匿名内部类在【创建对象】的时候,只能使用唯一的一次。如果希望多次创建对象【多个对象】,而且类的内容一样的话还是使用单独定义的实现类吧;
2.匿名对象在【调用方法】的时候,只能调用唯一的一次。如果希望同一个对象调用多个方法,必须给对象起名字;
3.匿名内部类是省略了【实现类 / 子类名称】,但是匿名对象是省略了【对象名称】,它两不是一回事!!
举例:
4.类的权限修饰符
定义一个类的时候,权限修饰符规则:
public > protected > ( default ) > private
1.外部类:public、(default)
2.成员内部类: public、protected 、( default )、 private
3.局部内部类:【什么都不能写】,只有本方法可以使用。
5.类作为成员变量类型
任何一种数据类型【基本、引用】都可作为成员变量的类型。类也可以作为成员变量的类型,像String类一样。
举例:
英雄类:
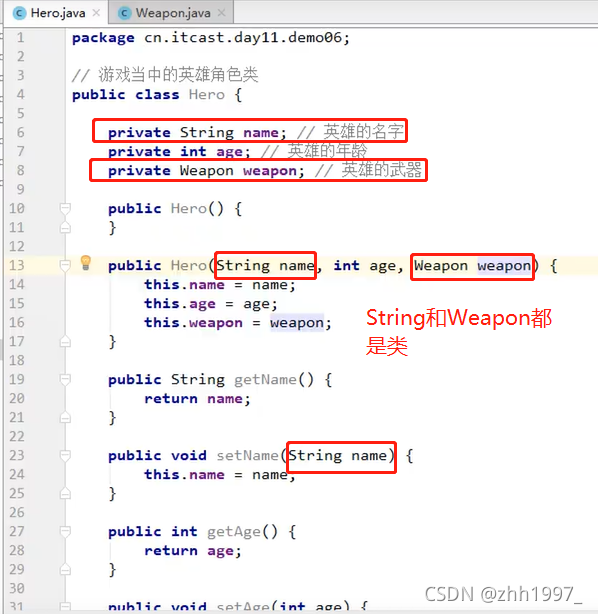
武器类:
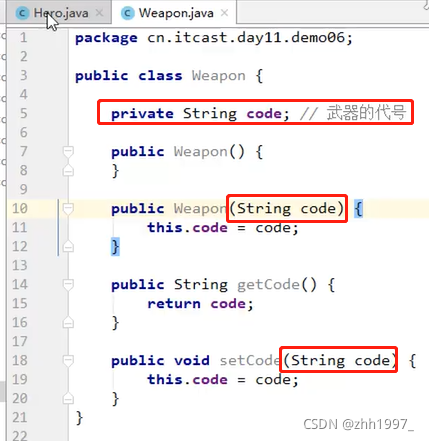
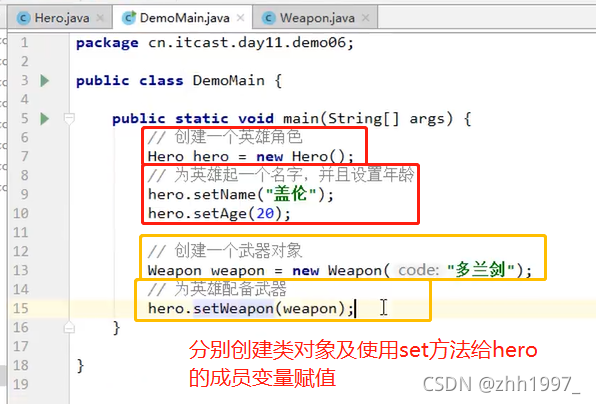
main方法:
6.接口作为成员变量类型
任何一种数据类型【基本、引用】都可作为成员变量的类型。接口也可以作为成员变量的类型。
举例:
英雄类:
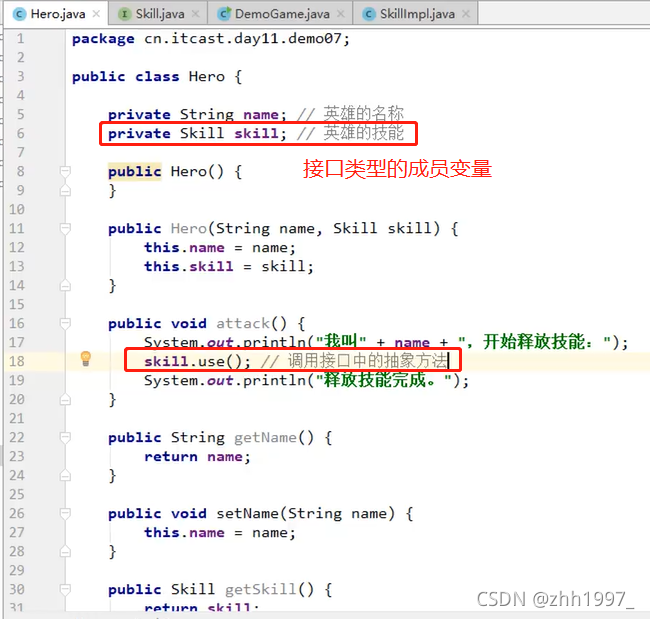
技能接口:
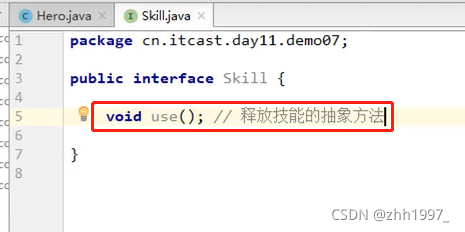
技能接口的一个实现类:
main方法: 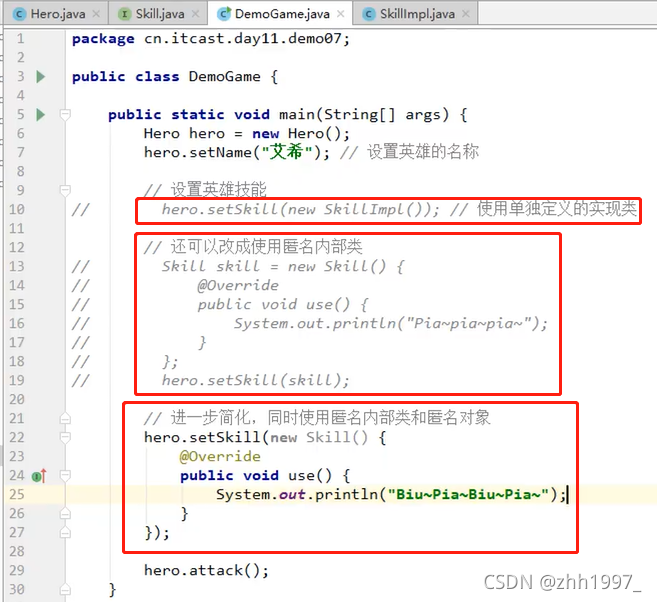
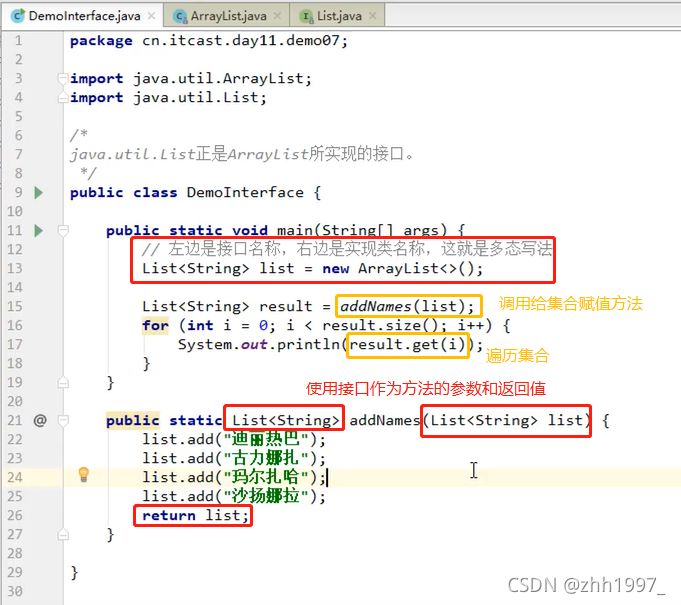
7. 接口作为方法的参数或返回值
举例:
8.发红包案例-升级版
没看太懂
十九、API各种类
1.object类
1.1 概述
java.lang.Object类是java语言中的根类,即所有类的父类。它中描述的所有方法子类都可以使用。在对象实例化的时候,最终找的父类就是Object。
类Object是类层次结构的根(最顶层)类,每个类都使用Object作为超(父)类。所有对象(包括数组)都实现这个类的方法。
重点介绍Object类中的两个方法:① toString方法;②equals方法。【所有类继承Object类,因此所有类都可以使用Object中的方法】
1.2 toString方法
方法摘要
用来打印对象的信息。
String toString():返回该对象的字符串表示。
以后写类不仅要写构造方法、get、set方法,还要重写toString方法。
覆盖重写
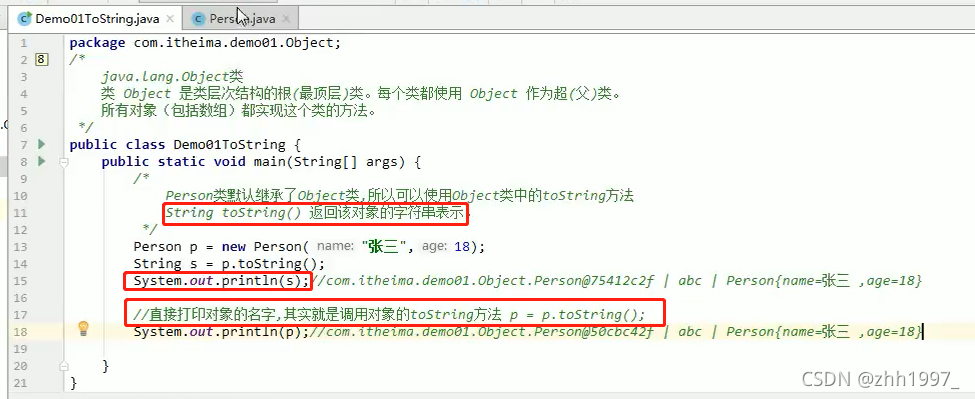
打印对象名就是在调用toString方法,默认打印包名类名@地址值,没有实际意义,因此一般都要对toString方法进行覆盖重写,打印类的属性。
判断一个类是否覆盖重写了toString方法,直接打印这个类对应对象的名字即可:
若没有重写toString方法,那么打印的就是对象的地址值(默认);
若重写了toString方法,那么则会按照重写的方式打印【对象的属性值】。 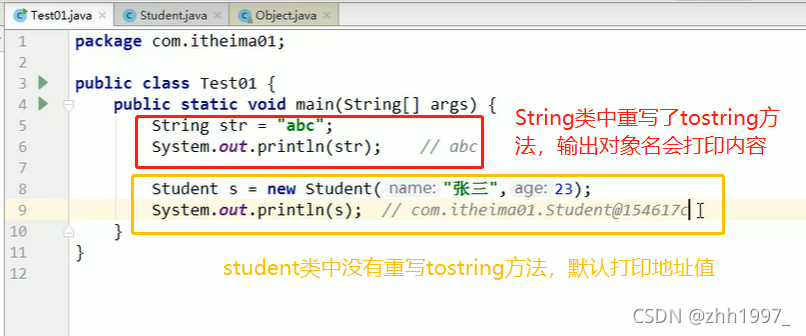
举例:
Person类: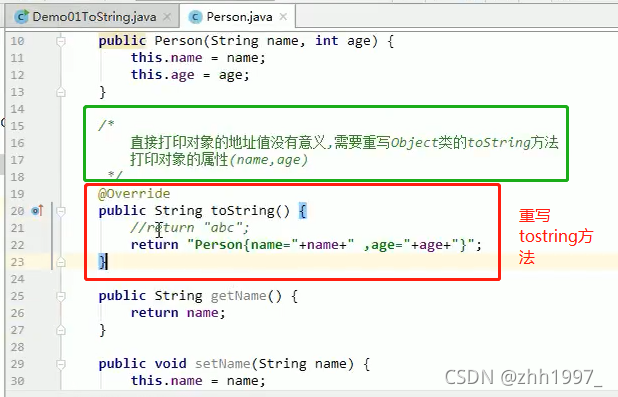
main方法及结果:
1.3 equals方法
方法摘要:
boolean equals ( Object obj) 指示其他某个对象是否与此对象“相等”,默认比较的是两个对象的地址值。【如果是基本数据类型则比较的是数值,本节重点介绍引用类型-对象】
使用:
Object类的equals方法的源码:
public boolean equals(Object obj ){
return ( this==obj );
}
参数:
Object obj:可以传递任意的对象。
方法体:
==:比较较运算符,返回的就是一个布尔值;
基本数据类型:比较的是数据值;
引用数据类型:比较的是两个对象的地址值;
this:哪个对象调用的方法就是this;如p1调用的equals,this就是p1
obj:传递过来的参数p2。
举例:
Person类:
如上例子。
main方法【没有重写equals方法,默认比较的是两个对象的堆地址值,但基本数据类型是比较数值】: 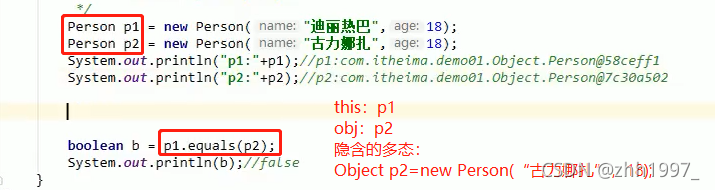
覆盖重写 equals方法:
因为equals方法默认比较的是两个对象的地址值,没有意义,因此需要覆盖重写,比较两个对象的属性值。
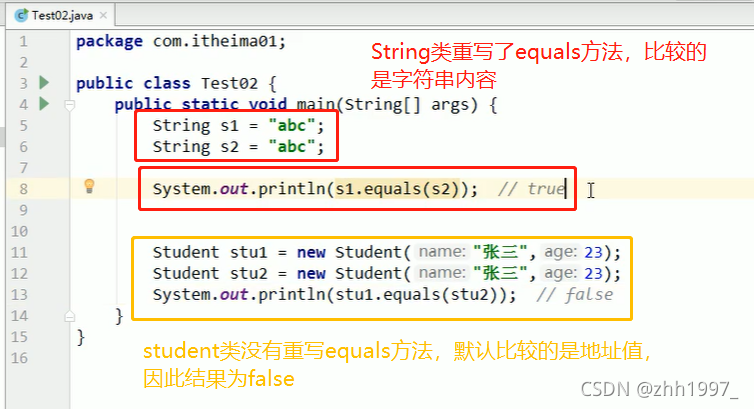
注意:
equals方法里面隐含着一个多态:Object obj=p2=new Person(“古力娜扎”,18);
多态的弊端:无法使用子类特有的内容(属性,方法);解决方法:使用向下转型(强转)把
Object类型转换为Person类。
举例:
Person类中重写equals方法:
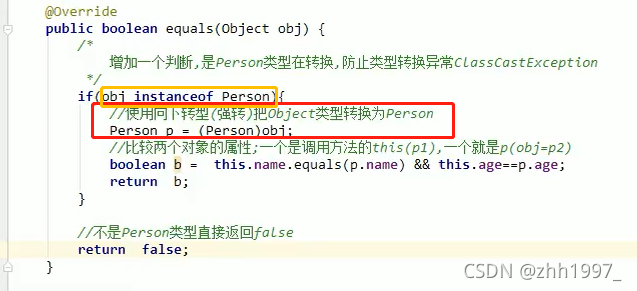

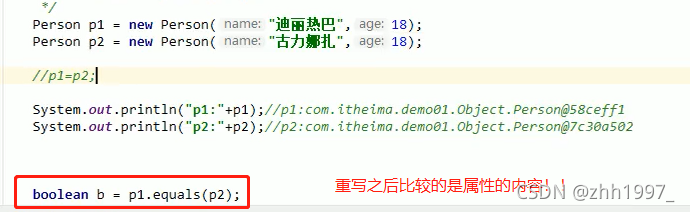
main方法【重写之后比较的是对象的属性】:
1.4 Objects类
概述【一个工具类,提供了一些静态方法,可以直接类名.方法名调用】:
其中的equals方法:容忍空指针,空值也可以进行比较。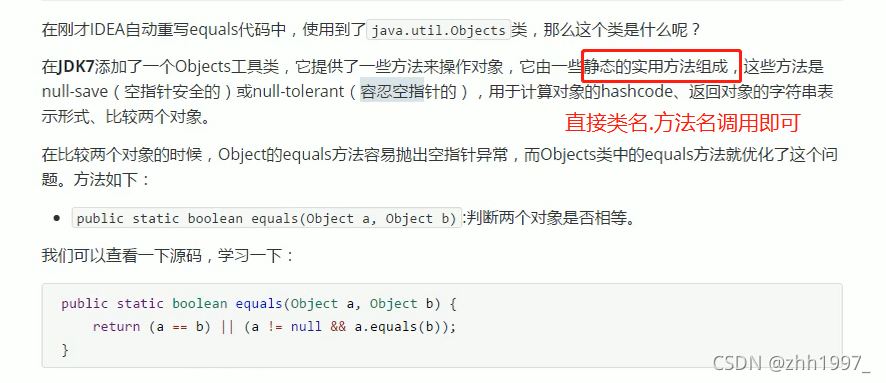
举例:
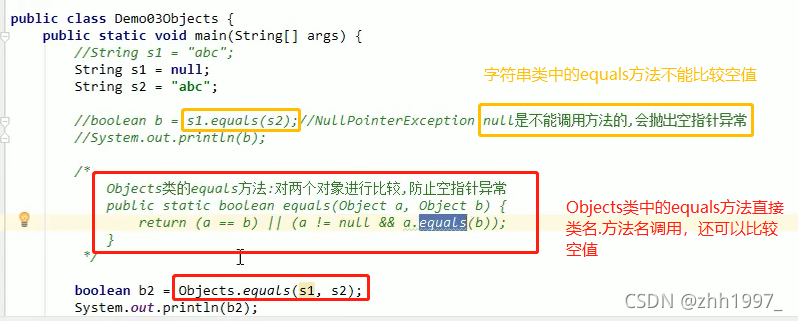
结果:false
2.日期和时间类
2.1 Date类
概述:
表示特定的瞬间,精确到毫秒。
java.util.Date:表示日期和时间的类,在util包中,不在lang包,因此使用前需要导包。
毫秒值的概念和作用:
1000毫秒=1秒
毫秒值的作用:可以对时间和日期进行计算。将日期转为毫秒进行计算,计算完毕再把毫秒转换为日期。时间原点:1970年1月1日0点,注意中国是东八区,会把时间加8个小时,即时间原点:1970年1月1日8点。
日期转换为毫秒:计算当前日期到时间原点(1970年1月1日8点)之间一共经历了多少毫秒。
毫秒转换为日期:1天=24×60×60×1000毫秒。
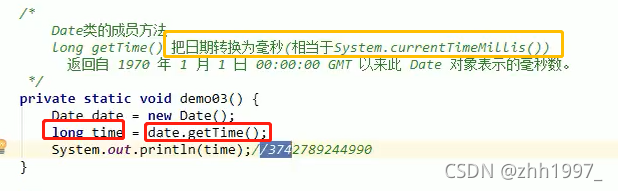
Date类的构造方法和成员方法:
①空参数构造方法,获取当前系统的日期和时间:

②带参数构造方法:Date (long date),根据传递的毫秒值,把毫秒转换为Date日期。


③成员方法: long getTime ( ):把日期转换为毫秒。返回自1970年1月1日0点以来Date对象的毫秒数。
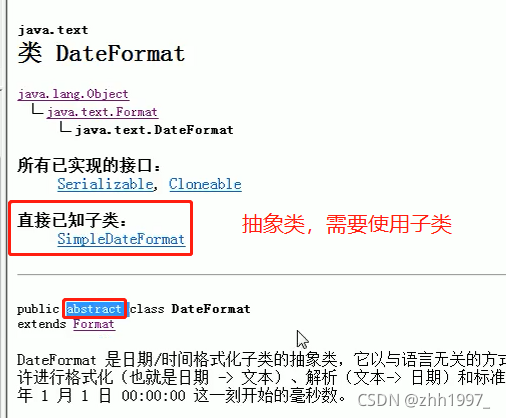
2.2 DateFormat类
java.text.DateFormat类的作用:
①格式化:日期—>文本
②解析: 文本—>日期

常用方法:
①format方法:
String format ( Date date ):按照指定格式把Date日期格式化为符合模式的字符串;
②parse方法:
Date parse ( String sourse ):把符合模式的字符串解析为Date日期。
simpleDateFormat类:
DateFormat类是一个抽象类,无法直接创建对象使用,可以使用DateFormat的子类:simpleDateFormat类。
即创建simpleDateFormat类的对象来调用format方法和parse方法。
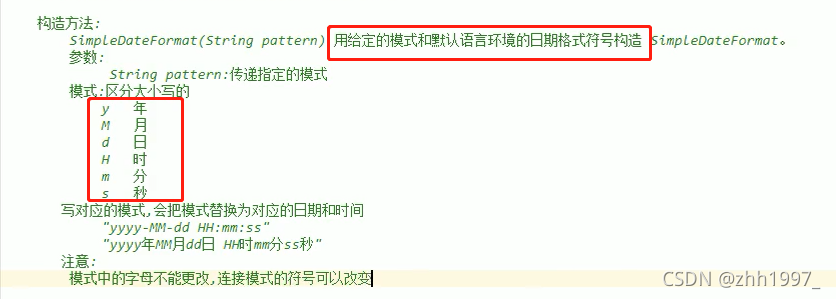
主要研究simpleDateFormat类的构造方法:
simpleDateFormat (String s);根据指定模板日期格式化对象。
举例1: 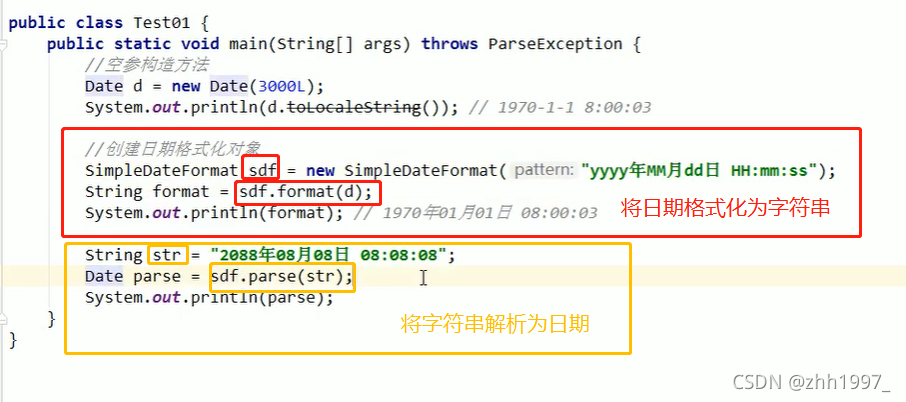
举例2:
①格式化:日期—>文本
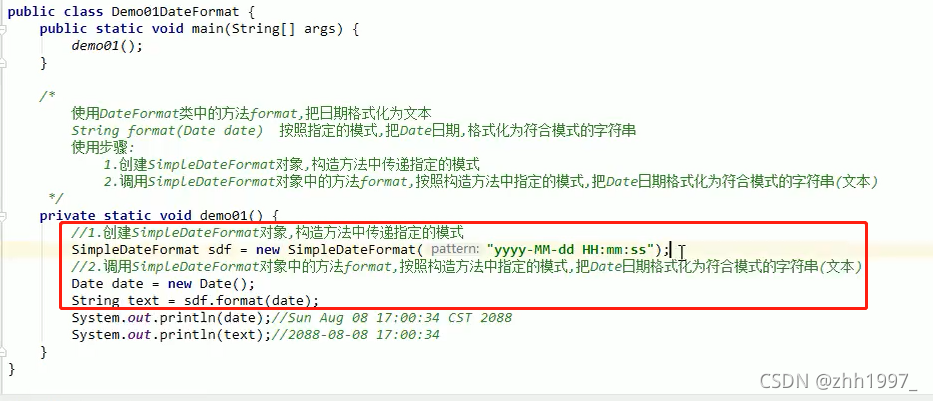
②解析: 文本—>日期

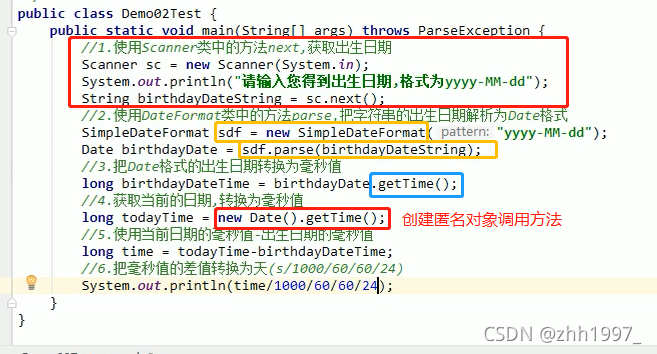
2.3 日期和时间类练习
题目:

实现:

2.4 Calendar类
概念:
日历类,是个抽象类。里面提供了很多操作日历字段的方法(YEAR、MONTH、DAY_OF_MONTH、HOUR)
获取对象的方式:
Calendar类无法直接创建对象使用,里面有一个静态方法【类名.方法名调用】:getInstance(),该方法返回了 Calendar类的子类对象【多态】。
static Calendar getInstance ():使用默认时区和语言环境获得一个日历。
举例:
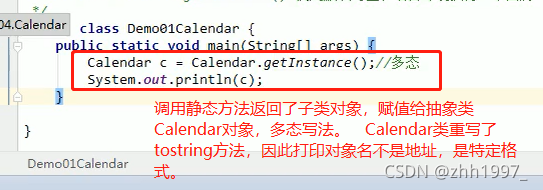
输出【时区、年份月份等信息】:

Calendar类常用成员方法:
4个常用的成员方法: 
举例:
①get方法:

②set方法:
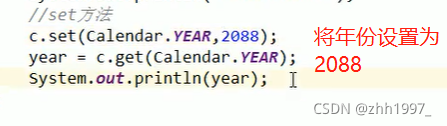
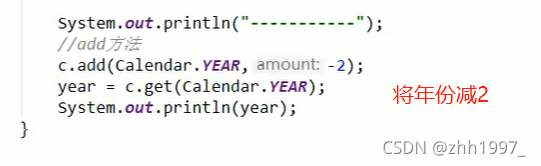
③add方法:
3.System类【静态方法】
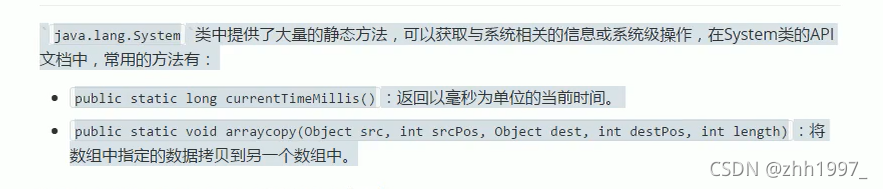
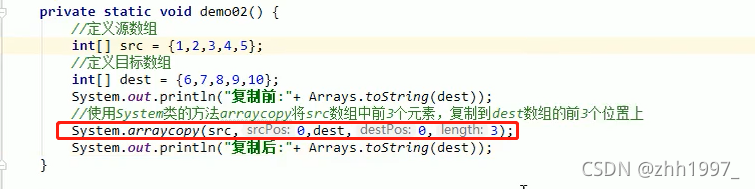
第二个数组复制方法的参数:

举例方法1【静态方法,不用创建对象,直接用类名调用】:
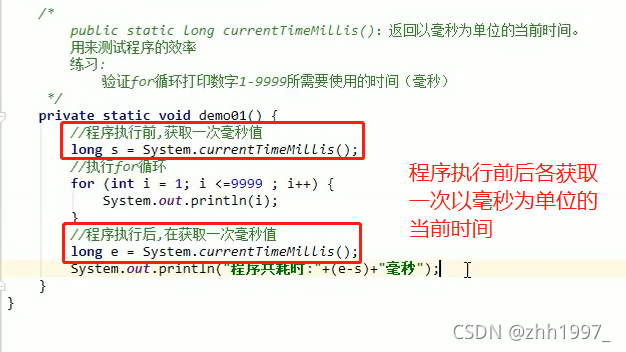
举例方法2:


4.StringBuilder类【字符串生成器】
字符串缓冲区。字符串是常量,它们的值在创建后不可更改,字符串缓冲区支持可变的字符串,可以提高字符串的效率。

4.1 构造方法【2个】: 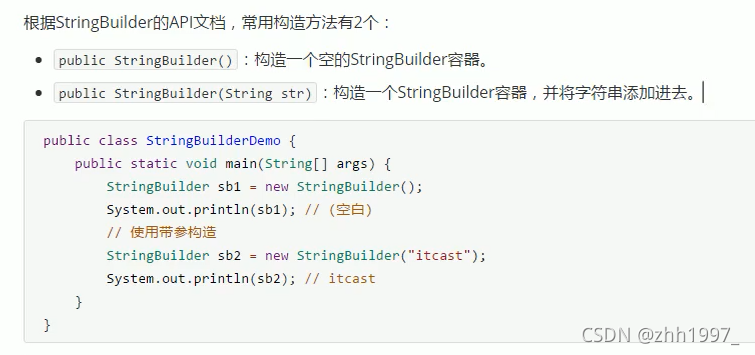
4.2 成员方法【2个】:
注意【StringBuilder和String相互转换】:
String—>StringBuilder:使用StringBuilder的构造方法,创建StringBuilder对象;
StringBuilder—>String:使用StringBuilder中的toString方法。

①举例append方法【返回的是当前对象本身】:
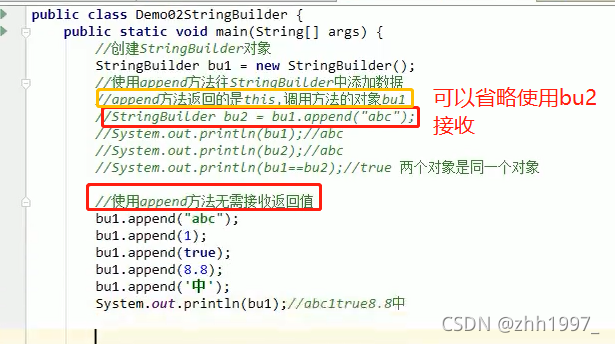
可以使用链式编程:

②toString方法举例1【 StringBuilder—>String】:
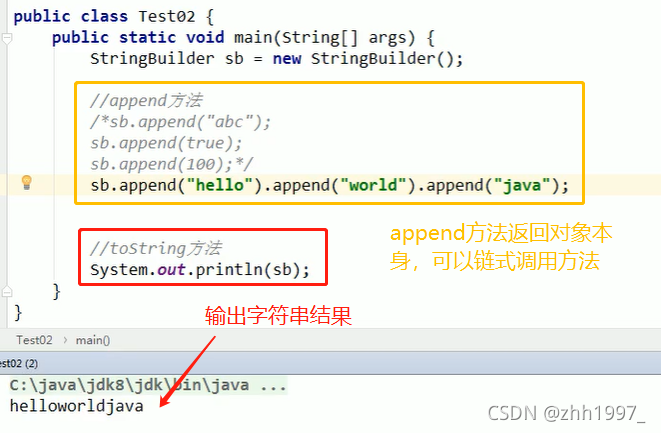
toString方法举例2:
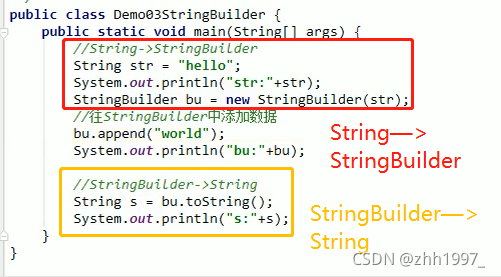
③reverse方法:翻转字符串


5.包装类
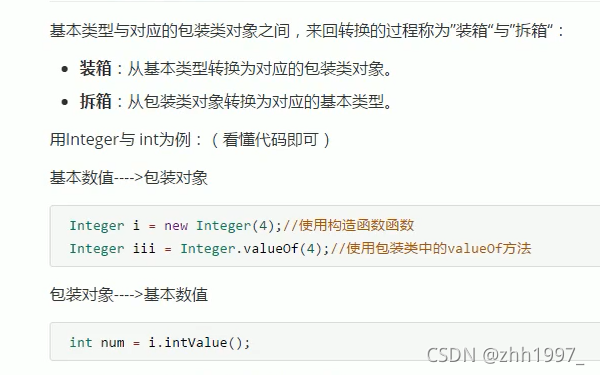
5.1 概念
让基本类型像对象一样操作,在lang包中,无需导包直接使用。
基本数据类型的数据很方便使用,但没有对应的方法来操作这些数据,包装类中可以定义方法来操作基本类型的数据。 
5.2 装箱与拆箱
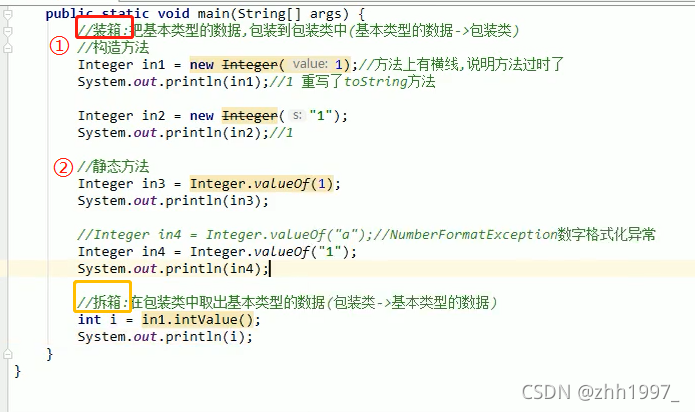
装箱的方法:
①通过构造方法【已过时】;②通过静态方法。
拆箱的方法:
成员方法。
如下图,注意:以String型传参数时要用数值型String变量作为参数,否则会报格式化异常【NumberFormatException】。
举例:
5.3 自动装箱与自动拆箱
JDK1.5以后。
举例:

5.4 基本类型与字符串之间的转换
注意:以String型传参数时要用数值型String变量作为参数,否则会报格式化异常【NumberFormatException】。
①基本类型转换为String
【连接符“+”即可】
或者使用静态方法:

举例【100变为字符串后+200结果为:】:
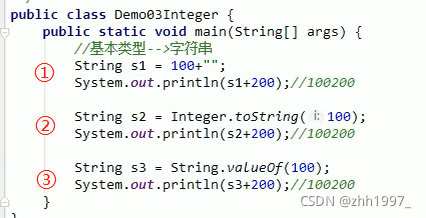
②String转换为对应的基本类型:
【parseXxx方法,除了Character类之外】
举例【字符串100变为int后+200的结果:300】: 
二十、集合
1.概述
变量可存储可变数据,数组可以存储多个同类型数据,但是长度不可改变【内容可变】,集合的长度是可变的。
数组:长度不可变,可以存储基本数据类型和引用数据类型;
集合:长度可变,只能存储引用数据类型。
此时的存储都是内存层面的存储,不涉及持久化的存储。
2.集合框架
集合按存储结构分为单列集合和双列集合。

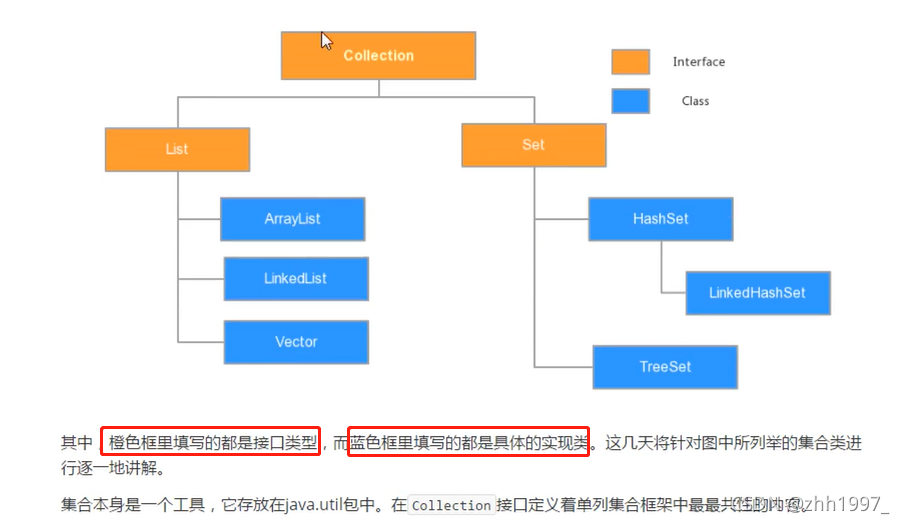
学习集合的目标:
①会使用集合存储数据;②会遍历集合;③掌握每种集合的特性。
集合框架的学习方式:
①学习顶层:学习顶层的接口/抽象类中的共性方法,所有的子类都可以使用;
②使用底层:顶层不是接口就是抽象类,无法创建对象使用,需要使用底层的子类创建对象使用。
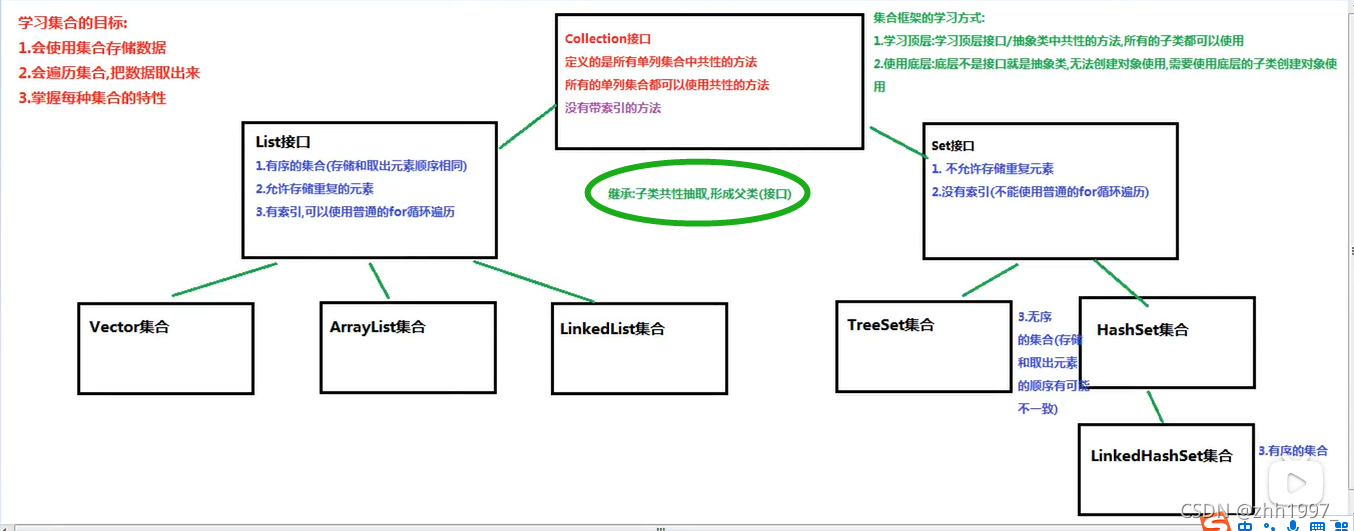
二十一、Collection集合
java.util.Collection接口:所有单列集合的最顶层接口,里面定义了所有单列集合共性的方法。任意单列集合都可以使用Collection接口中的方法。
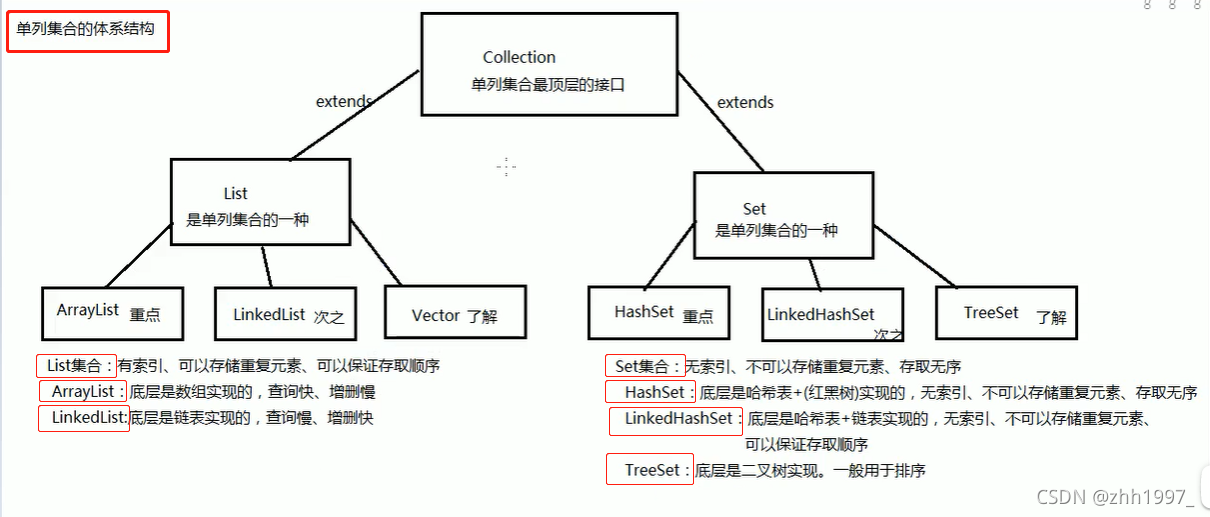
1.Collection集合中的通用方法
学习Collection集合中的共性方法,所有Collection的集合子类都可以使用。

举例:
main方法: 
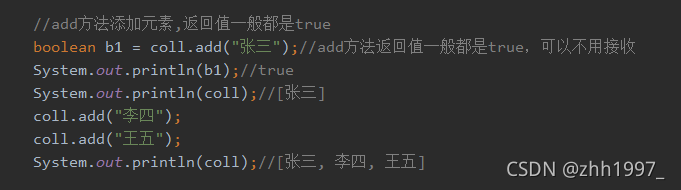
①add方法:
②remove方法:
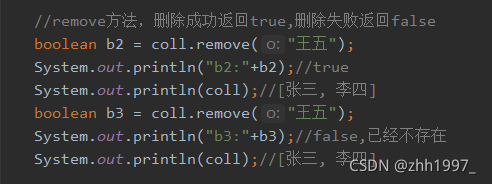
③contains方法:
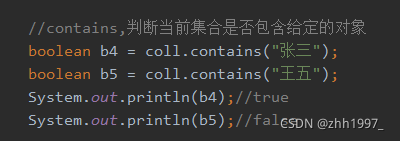
④isEmpty方法:
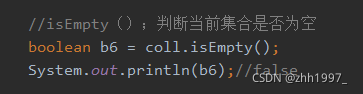
⑤size方法:
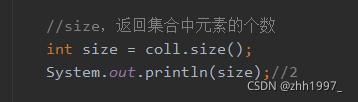
⑥toArray方法: 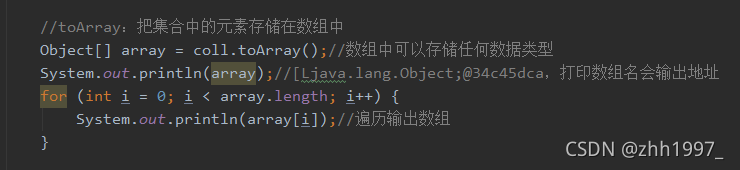
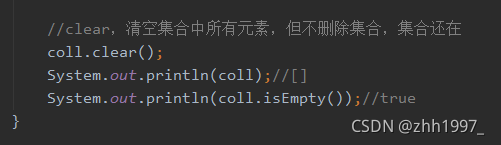
⑦clear方法:
2.Iterator迭代器
用来遍历集合中的所有元素,因为每种集合存储的元素类型不一样,因为迭代器设置了通用的遍历集合元素的方法。
迭代:即Collection集合元素的通用获取方式,在取元素之前要判断集合中有没有元素,如果有就取出来,继续再判断再取,知直到取出集合中所有元素。这种方式叫迭代。
想要遍历集合,先要获取该集合对应的迭代器:
public Iterator iterator()
2.1 Iterator接口
概念:
针对遍历集合中的元素的需求,JDK专门提供了一个接口 java.util.Iterator,它与Collection接口、Map接口不同,这两接口主要用来存储元素,而Iterator接口用来迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
两个常用的方法:
boolean hasNext ():判断集合中还有没有下一个元素,有就返回true,没有就返回false;
E next ():返回集合中的下一个元素。
使用:
Iterator是一个接口,无法直接使用,需要使用Iterator接口的实现类对象。它获取实现类的方式比较特殊:Collection接口中有一个方法叫iterator(),这个方法返回的就是迭代器的实现类对象。
Iterator<E> iterator():返回在此Collection的元素上进行迭代的迭代器,迭代器的泛型跟着集合走,集合是什么泛型,迭代器就是什么泛型。
使用步骤:
1.使用集合中的方法 iterator()获取迭代器的实现类对象,使用Iterator接口接收(使用接口接收实现类,多态);
2.使用Iterator接口中的方法hasNext () 判断还有没有下一个元素;
3.使用Iterator接口中的方法next () 取出集合中的下一个元素,并把指针(索引)向后移动一位。【集合中使用next取元素相当于剪切,取了就没了】
代码实现:
1.使用迭代器取出集合中的元素的代码是一个重复的过程,原始代码:
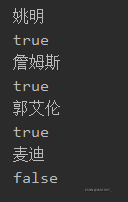
public static void main(String[] args) { //使用多态创建一个对象 Collection<String> coll=new ArrayList<>(); //往集合中添加元素 coll.add("姚明"); coll.add("詹姆斯"); coll.add("郭艾伦"); coll.add("麦迪"); //使用集合中的方法 iterator()获取迭代器的实现类对象 Iterator<String> ite = coll.iterator();//多态,实现类对象给接口 //判断还有没有下一个元素 boolean b = ite.hasNext(); System.out.println(b);//true //取出集合中的下一个元素 String s = ite.next(); System.out.println(s);//取出姚明 b = ite.hasNext(); System.out.println(b);//true,判断是否还有元素 s = ite.next(); System.out.println(s);//取出詹姆斯 b = ite.hasNext(); System.out.println(b);//true,判断是否还有元素 s = ite.next(); System.out.println(s);//取出郭艾伦 b = ite.hasNext(); System.out.println(b);//true,判断是否还有元素 s = ite.next(); System.out.println(s);//取出麦迪 b = ite.hasNext(); System.out.println(b);//false,判断是否还有元素 s = ite.next(); System.out.println(s);//NoSuchElementException,元素已经取完,再取会报没有元素异常
2.发现使用迭代器取出集合中的元素的代码是一个重复的过程,可以使用循环优化。因为不知道集合中有多少个元素,不知道循环次数,因此使用while循环。循环结束的条件:hasNext方法返回false。
public static void main(String[] args) { //使用多态创建一个对象 Collection<String> coll=new ArrayList<>(); //往集合中添加元素 coll.add("姚明"); coll.add("詹姆斯"); coll.add("郭艾伦"); coll.add("麦迪"); //使用集合中的方法 iterator()获取迭代器的实现类对象 Iterator<String> ite = coll.iterator();//多态,实现类对象给接口
while (ite.hasNext()){ String next = ite.next(); System.out.println(next); } boolean b = ite.hasNext(); System.out.println(b);//false,判断是否还有元素
3.for循环也可以,但麻烦,了解一下:
for(Iterator<String> ite2 = coll.iterator(); ite2.hasNext();){ String next = ite2.next(); System.out.println(next); boolean b = ite2.hasNext(); System.out.println(b); }
结果:
3.增强for
就是迭代器的简化版本。
3.1 概念
增强for循环(也称for each循环)是JDK1.5以后出来的高级for循环,专门用来遍历数组和集合。它的内部原理其实就是个Iterator迭代器,使用for循环的格式简化了迭代器的书写。所以在遍历的过程中,不能对集合中的元素进行增删操作。
3.2 格式
for(集合/数组的数据类型 变量名:Collection集合名/数组名){
//sout(变量名);
}
它用于遍历Collection集合和数组,通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
API中:Collection<E> extends Iterable<E>,因此所有的单列集合都可以使用增强for。Iterable接口:实现这个接口允许对象成为“foreach”语句的目标。
3.3 使用
public static void main(String[] args) { // demo01(); demo02(); } //遍历数组 private static void demo01(){ int[] arr={1,2,3,4,5}; for (int i:arr) { System.out.println(i);//1 2 3 4 5 } } //遍历集合 private static void demo02(){ ArrayList<String> list=new ArrayList<>();//创建集合数组 list.add("aa"); list.add("bb"); list.add("cc"); for (String s:list ) { System.out.println(s);//aa bb cc } }
4.泛型
泛型没有继承概念。
4.1 概述
可以看成一种未知的数据类型。当不知道使用什么数据类型的时候可以使用泛型。泛型也可以看成是一个变量,用来接收数据类型。
前面学习集合中可以存放任意对象【泛型】,只要把对象存储集合中就会被提升为Object类型。当取出每个对象并进行相应的操作必须采用类型转换。
E e:Element 元素
T t:Type 类型
4.2 举例
ArrayList集合在定义的时候不知道会存储什么类型的数据,所以类型使用泛型。
如:

创建对象的时候,就会确定泛型的数据类型:

会把数据类型作为参数传递,把String赋值给泛型E:

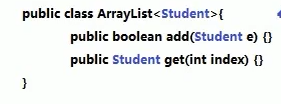
再如,把Student类型赋值给泛型E:
4.3 使用泛型的好处
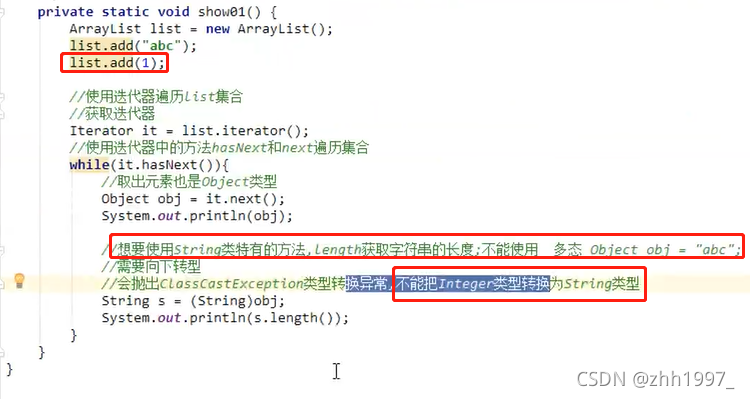
1.创建集合对象不使用泛型:
好处:不使用泛型,默认的类型是object类型,可以存储任意类型的数据;
弊端:不安全,会引发异常。
2.创建集合对象使用泛型:
好处:①避免了类型转换的麻烦,存储的是什么类型,取出的就是什么类型;
②把运行期异常(代码运行之后会抛出的异常),提升到了编译器(写代码的时候会报错)
弊端:泛型是什么类型,只能存储什么类型的数据。
4.4 泛型的定义与使用

1.定义和使用含有泛型的类
概念:
可以不受数据类型的限制,在创建对象时自由确定数据类型即可。
定义一个含有泛型的类,模拟ArrayList集合:

定义格式:
修饰符 class 类名 <代表泛型的变量> { }

使用:
创建对象的时候确定泛型的数据类型。
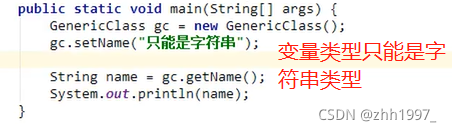
①不使用泛型的类【不写泛型默认为object类型】:
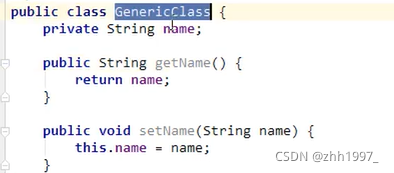
main方法:
②使用泛型的类:
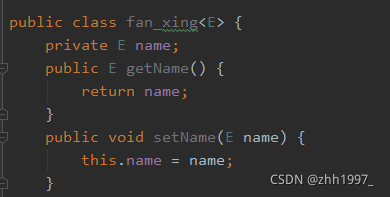
main方法【创建对象的时候确定类型】:
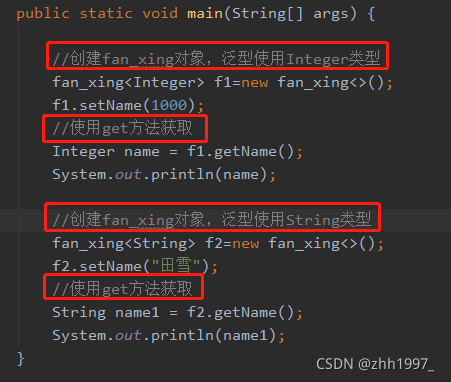
2.定义和使用含有泛型的方法
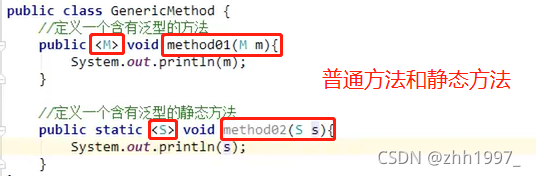
概念:
泛型定义在方法的修饰符和返回值类型之间,什么符号都可以。 调用方法的时候确定泛型的数据类型。传递什么类型的参数,泛型就是什么类型。
定义格式:
修饰符 <泛型> 返回值类型 方法名(参数列表(使用泛型)){
//方法体;
}

使用:
调用方法的时候确定泛型的数据类型。传递什么类型的参数,泛型就是什么类型。
main方法:

结果:

3.定义和使用含有泛型的接口
使用:【两种使用方式】
①【实现类指定数据类型】:定义接口的实现类实现接口,实现类指定接口的泛型;
☆②【对象指定数据类型】:接口使用什么泛型,实现类就使用什么泛型,类跟着接口走。相当于定义了一个含有泛型的类,创建对象的时候确定泛型的类型。
举例①:
定义含有泛型的接口:

定义接口的实现类【实现类指定泛型的数据类型】:

main方法:
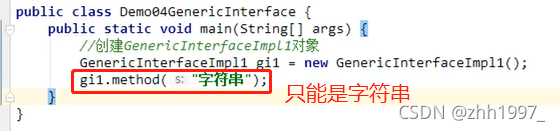
结果:字符串
举例②:
定义含有泛型的接口:
定义接口的实现类【实现类也和接口一样使用泛型】:

main方法【创建对象指定泛型】:
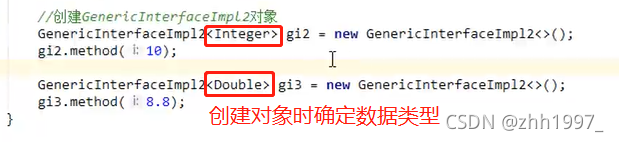
4.5 泛型通配符
?:代表任意的数据类型。不能创建对象使用,只能作为方法的参数使用。
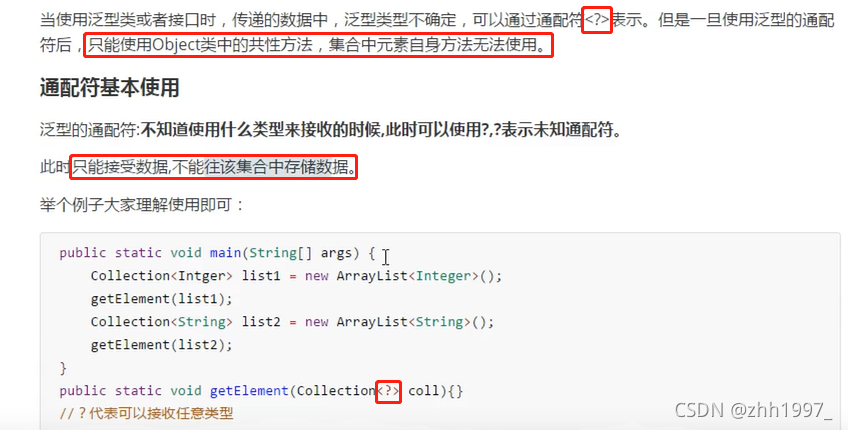
举例:

5.综合案例:斗地主
按照斗地主的规则,完成洗牌发牌的动作。具体规则:使用54张牌打乱顺序,三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留底牌。
分析:
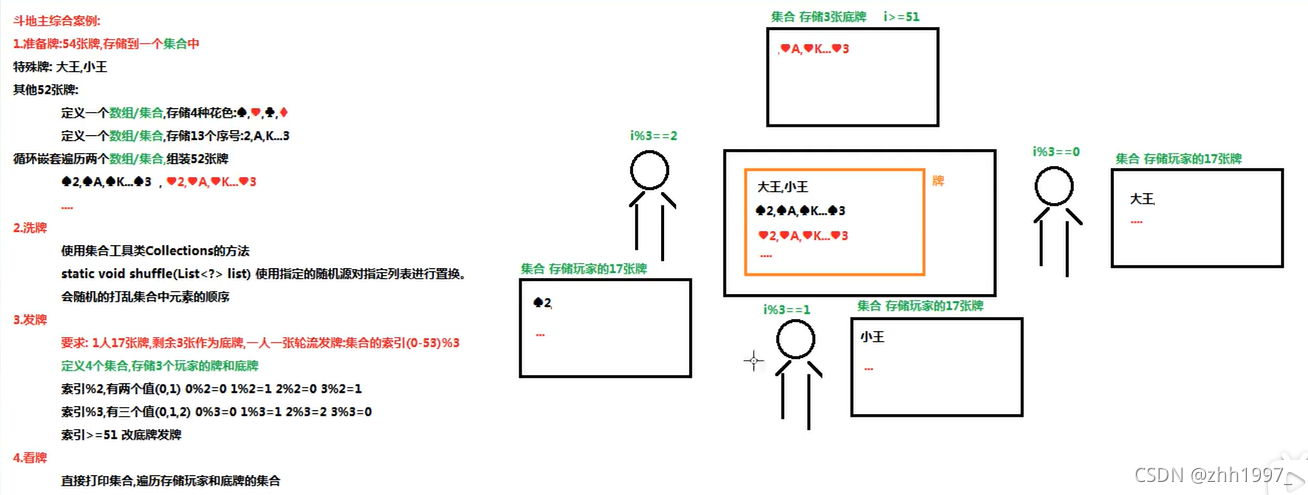
实现:
①准备54张牌: 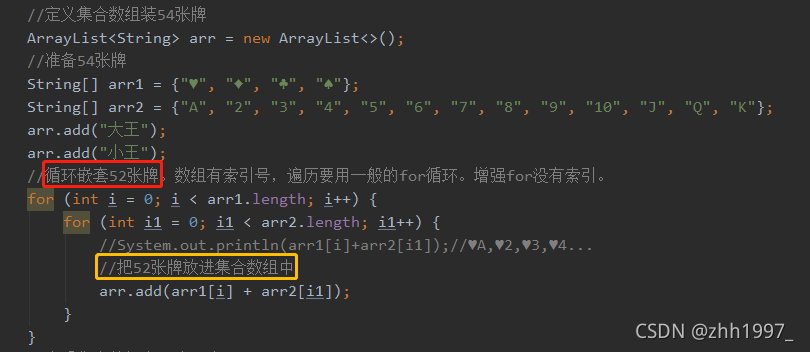
②洗牌,打乱集合中的顺序:

③发牌、拿牌、看牌【注意:要查看/拿到集合中每个元素,必须使用遍历!!】
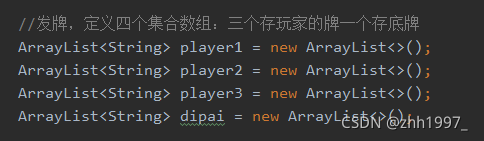

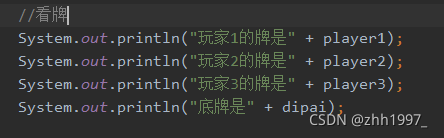
6.List集合
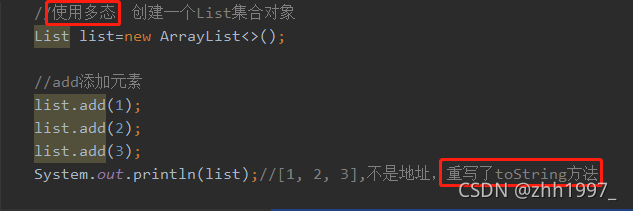
6.1 List接口介绍 
6.2 List接口中常用的方法
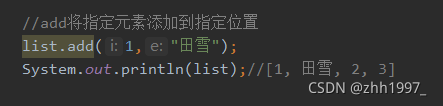
因为List接口带索引,所以有带索引的方法【特有】:
add添加元素;get获取元素;remove移除元素;set替换元素。
list集合遍历有三种方式:
1.使用普通的for循环遍历;2.使用迭代器遍历;3.使用迭代器的简化版本-增强for循环遍历。
注意:操作索引的时候,一定要防止索引越界异常。
IndexOutOfBoundsException:索引越界异常,集合会报;
ArrayIndexOutOfBoundsException:数组索引越界异常;
StringIndexOutOfBoundsException:字符串索引越界异常;
举例:
①创建list集合对象:
② add方法:
③remove方法: 
④set方法:
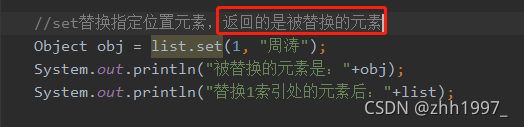
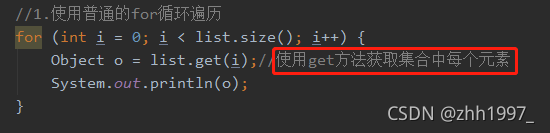
⑤list集合遍历:
使用普通for循环遍历:
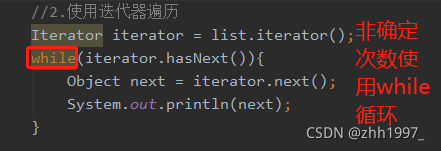
使用迭代器遍历:
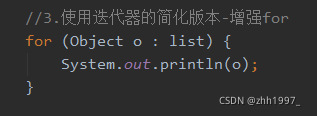
使用迭代器的简化版本-增强for循环:
⑥索引越界异常:
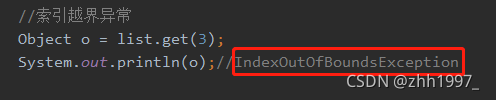
6.3 List接口的子类
1.ArrayList集合【此实现不是同步的,多线程】
底层使用了数组。比如add方法:底层为新建一个数组并长度+1然后复制原来数组的值给新数组再加值,因此元素增删慢,查找快。

2.LinkedList集合【此实现不是同步的,多线程】
双向链表,查询慢,增删快。

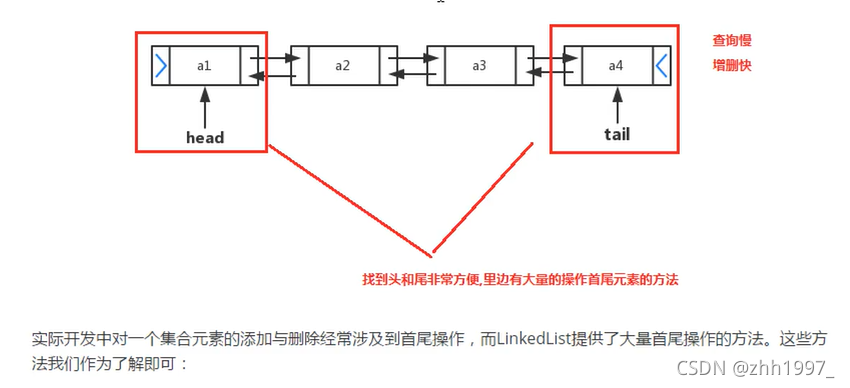
常用方法:
双向链表找到头和尾非常方便,里面有大量操作头尾元素的方法。
注意:使用LinkedList集合特有的方法不能使用多态。 
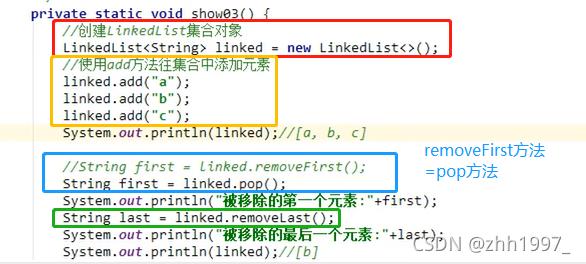
举例:
addFirst =push方法、addLast方法。

getFirst、getLast、isEmpty方法。 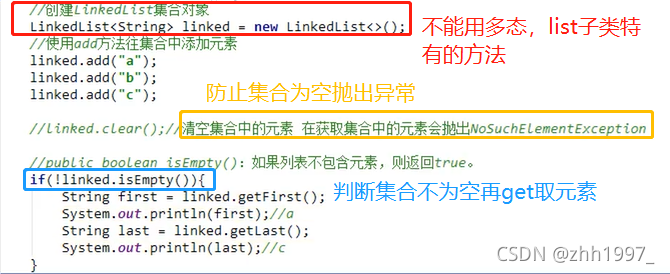
pop=removeFirst方法、removeLast方法。
3.Vector集合
底层是一种可增长对象数组,查询快、增删慢,线程安全,同步。现已被ArrayList集合替代。
7.Set集合
7.1 概念
继承了collection接口,特点:
1.不允许存储重复的元素;
2.没有索引,没有带索引的方法,不能使用普通的for循环遍历。

遍历两种方法:
1.迭代器;2.增强for(简化的迭代器)。
7.2 HashSet集合【不同步】

特点:【包含set集合的两个特点】
3.是一个无序集合,存储元素和取出元素的顺序可能不一致;
4.底层是一个哈希表结构【查询速度非常快】。
举例:
7.3 HashSet集合存储数据的结构(哈希表)
1.哈希值:
十进制的整数,由系统随机给出,是模拟的地址(逻辑地址),不是实际的存储的物理地址。
2.哈希表:
JDK1.8之前:哈希表=数组+链表;
JDK1.8开始:哈希表=数组+链表/红黑树,当链表长度超过8时,将链表转换为红黑树。

存储数据到集合中时,先计算元素的哈希值,然后:用数组把元素进行分组(相同哈希值为一组),用链表/红黑树结构把相同哈希值的元素连接到一起(长度超过8用红黑树)。
7.4 set集合存储元素不重复的原理
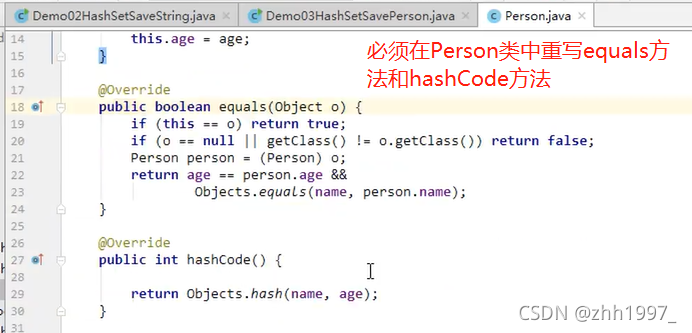
set集合在调用add方法添加元素的时候,add方法会先调用元素的hashCode方法和equals方法,判断元素是否重复。前提:存储的元素必须重写hashCode方法和equals方法。
哈希值在集合中没有存储过:存;
哈希值存过,相同(哈希冲突),但equals方法比较不同(值不同返回false):存;
哈希值存过,相同(哈希冲突),且equals方法比较相同(值相同返回false):不存。
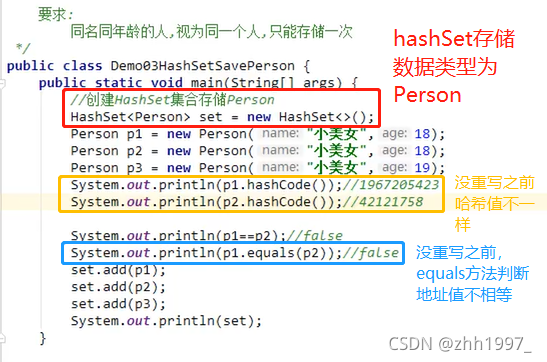
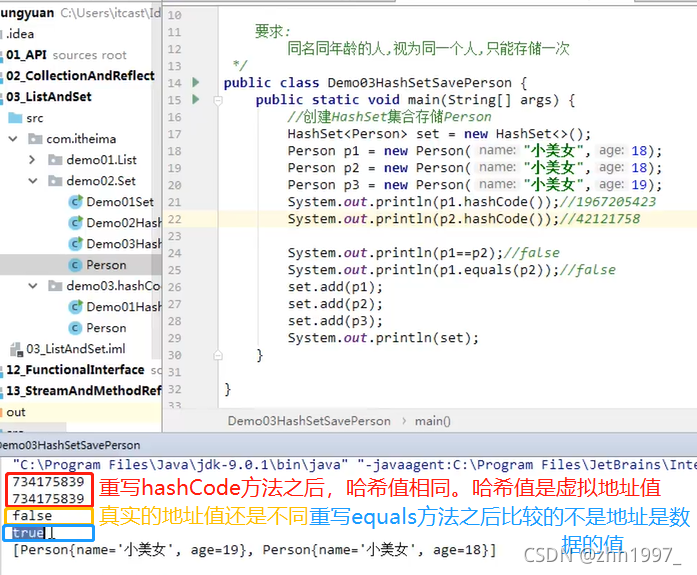
7.5 HashSet存储自定义类型元素

举例:Person类
前提:重写两个方法:
main方法中创建对象使用:
【不重写两个方法之前的结果】:
【重写两个方法之后的结果】:
7.6 LinkedHashSet集合
底层是一个哈希表【数组+链表/红黑树】+链表。多了一条链表记录元素存储的顺序,保证元素有序。
举例:
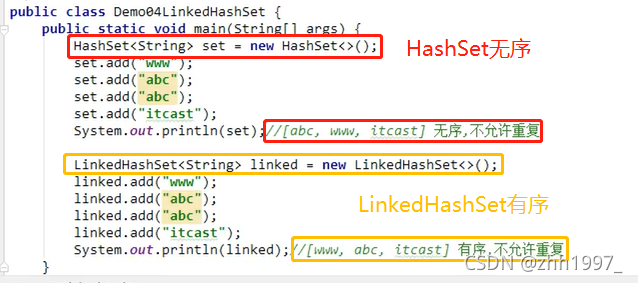
8.可变参数
JDK1.5之后出现的新特性。 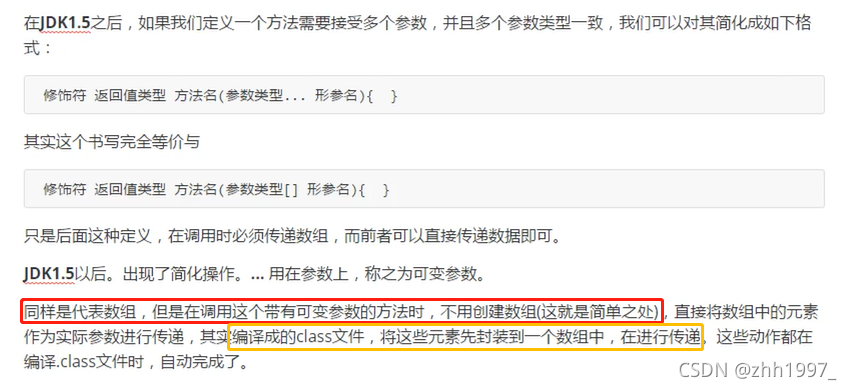
使用前提:
当方法的参数列表数据类型已经确定,但是参数的个数不确定,就可以使用可变参数。比如已知计算整数的和,数据类型已经确定为int型,但是不知道计算几个整数的和。
使用格式:【定义方法时使用】
修饰符 返回值类型 方法名(数据类型...变量名){ }
终极写法:

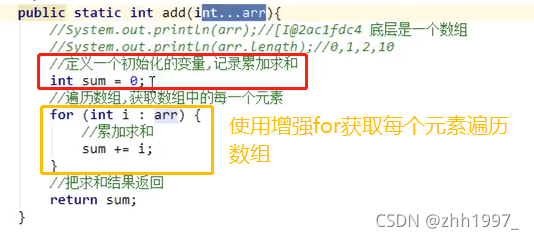
可变参数的原理:
可变参数底层是一个数组,根据传递参数个数不同,会创建不同长度的数组存储这些参数。传递的参数个数可以是0个(不传递)、1个,2个...多个。
注意事项:
1.一个方法只能有一个可变参数;
2.一个方法的参数类型有多个时,可变参数必须写在参数列表的末尾。
 :
:
使用,整数求和:

9.Collections集合工具类
9.1 常用功能
Collections集合工具类提供了一些静态方法对集合进行操作。
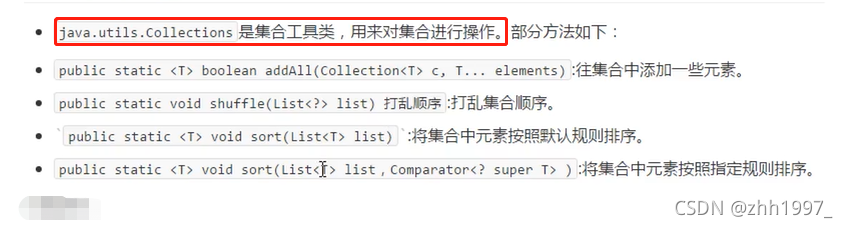
9.2 方法简介:
1.以上4个方法,除了addAll方法【使用了可变参数】,其他3个方法只能对List集合使用。
2.对于默认规则排序的sort方法:sort (List<T> list)方法使用前提:被排序的集合里面存储的元素,必须实现Comparable接口,重写接口中的comparaTo方法定义排序的规则。Comparable接口的排序规则:自己(this)-参数:升序排序;参数-自己(this):降序排序。
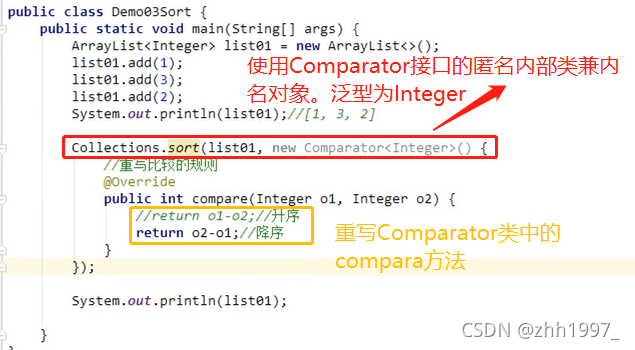
3.对于指定规则排序的sort方法:在创建集合对象,调用sort方法时,调用Comparator接口【创建匿名内部类对象】中的compara方法,必须重写compara方法。Comparator接口的compara方法排序规则:o1-o2:升序;o2-o1:降序;
4.Comparable接口和Comparator接口的区别: Comparable接口是在自己的类里继承接口,重写comparaTo方法;Comparator接口是在外部调用第三方,具体看举例。
9.3 举例
举例(添加元素和打乱顺序): 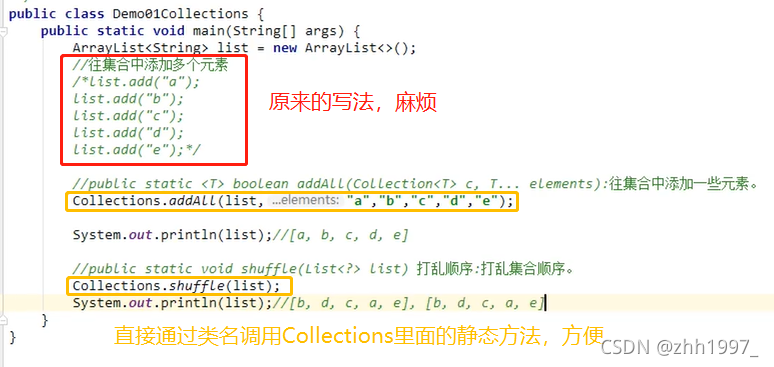
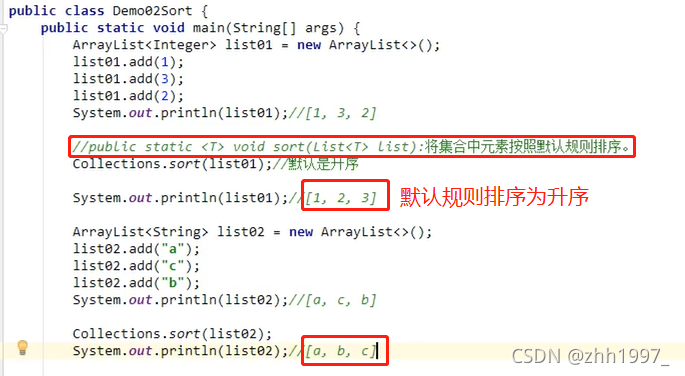
举例(默认规则排序和指定规则排序):
①默认规则排序【String和int】:泛型String和Integer已经实现了Comparable接口,并重写了接口中的comparaTo方法,因此可以直接调用方法。
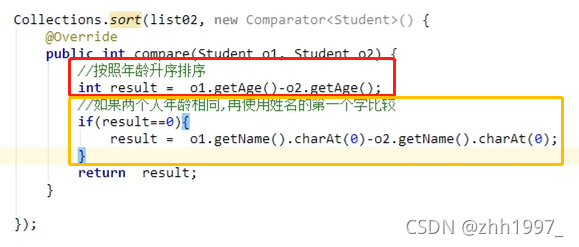
②默认规则排序【自定义类型Person类】:实现Comparable接口,重写接口中的comparaTo方法定义排序的规则。排序规则:自己(this)-参数:升序排序;参数-自己(this):降序排序


 ③指定规则排序【int型】:
③指定规则排序【int型】:
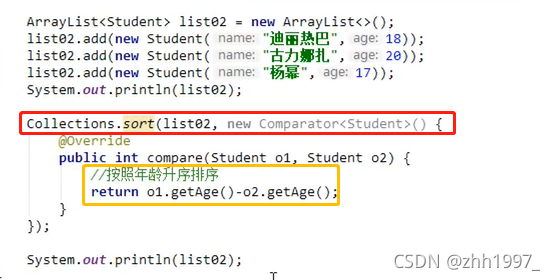
④指定规则排序【自定义Student类型按照年龄排序】:
结果:

⑤指定规则排序【多种规则排序】:
二十二、 Map集合
此前学的Collection集合是单列集合,而Map集合是双列集合。
1.概述



特点:

注意事项:

Collection集合【单身集合】和Map集合【夫妻对儿集合】存储数据的形式不同:

2.Map集合常用子类
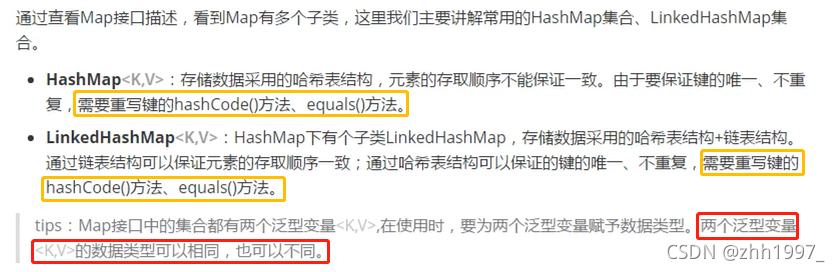
两个集合的特点:
一个底层是哈希表,无序;一个底层是哈希表+链表,有序。

HashMap集合是不同步的,即多线程。
3.Map接口常用的方法

举例:
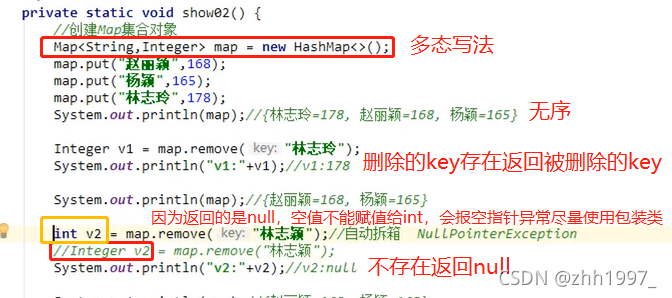
①put方法【存储键值对的时候,key不重复返回null,key重复会用新的value替换Map集合中重复的value,返回被替换的value,一般此方法返回值无需接收】: 

②remove方法【key存在返回被删除的值,key不存在返回null】:

③get方法【对应的key存在返回其value值,不存在返回null】:


④ containsKey方法【包含返回true,不包含返回false】:


4.Map集合遍历的方式【两种】
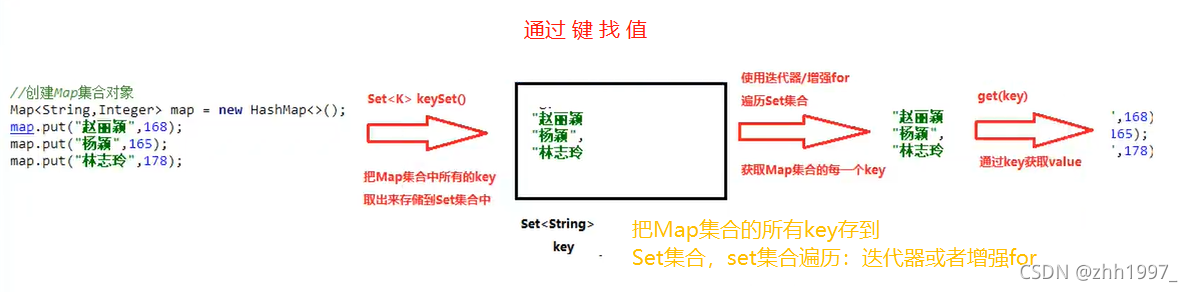
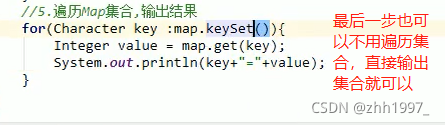
4.1 键找值的方式
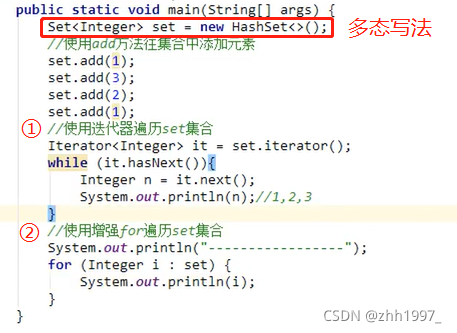
【三步:取key存到set集合、遍历set、get(key)】
把Map集合的所有key存到Set集合中,Set集合遍历方式:迭代器、增强for【简化的增强for】。
步骤:


举例:
①使用迭代器遍历:
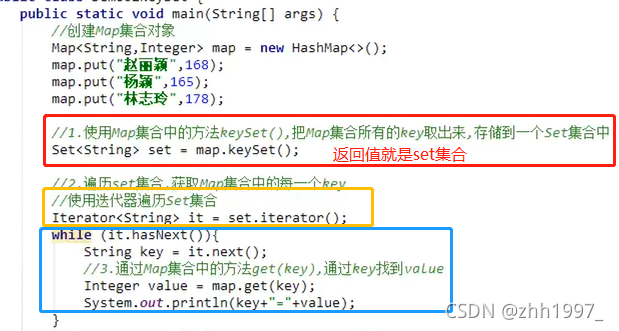
②使用增强for遍历【前2步一样】:

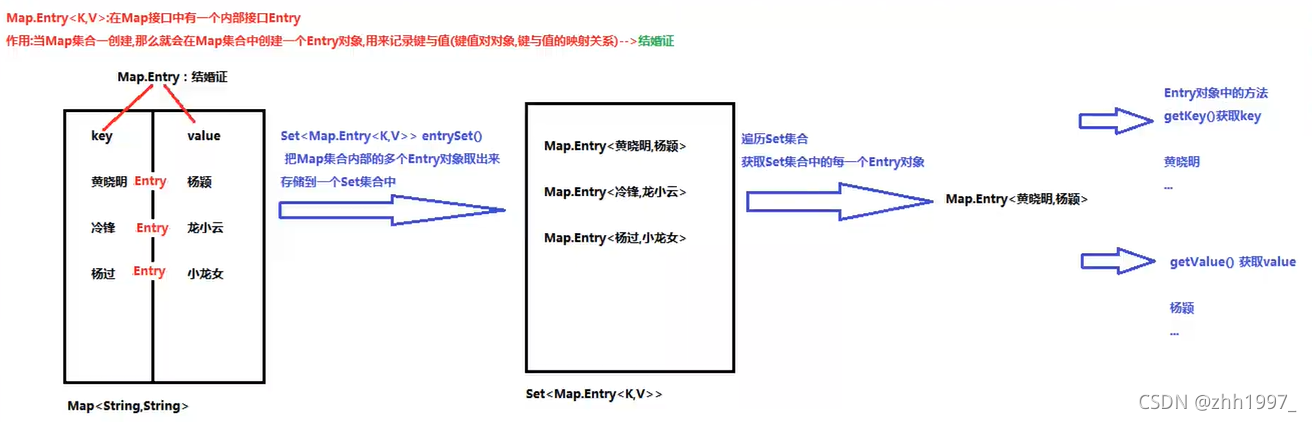
4.2 Entry键值对 对象
在Map接口中有一个内部接口Entry,作用:当Map集合一创建,就会在Map集合中创建一个Entry对象,用来记录键与值【】。
步骤:


举例:
①使用迭代器遍历: 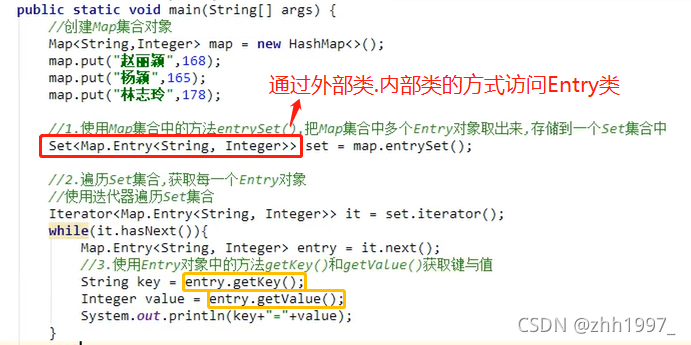
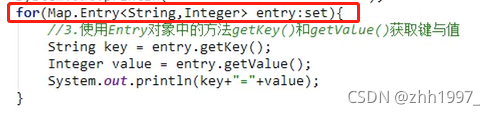
②使用增强for遍历【前2步一样】:
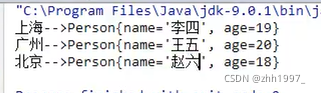
5.HashMap存储自定义类型键值

分析:
①key为String类型,value为Person类型:
key必须唯一,因此String类要重写hashCode方法和equals方法;value可以重复,因此Person类不用重写。

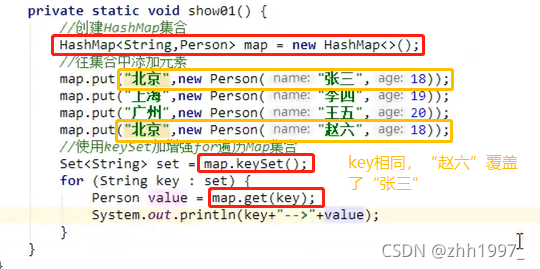
结果:
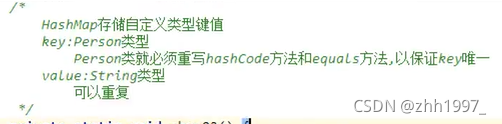
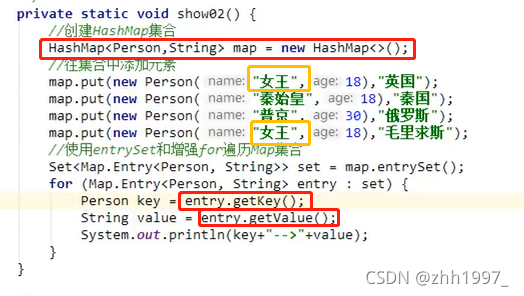
②key为Person类型,value为String类型:
key必须唯一,因此Person类要重写hashCode方法和equals方法;value可以重复,因此String可以重复。
若不重写Person类中的hashCode方法和equals方法,结果:
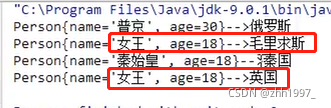
重写后:

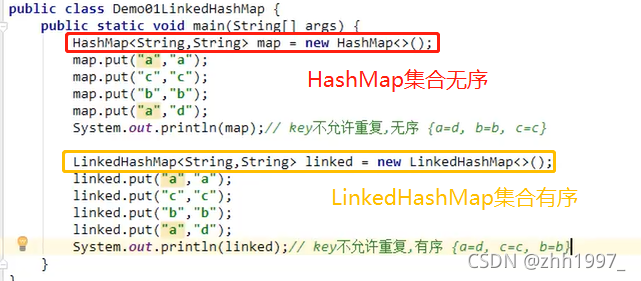
6.LinkedHashMap集合:
LinkedHashMap集合是HashMap集合的子类,底层比HashMap多了一条链表。由哈希表+链表组成【链表用来记录顺序】,有序。
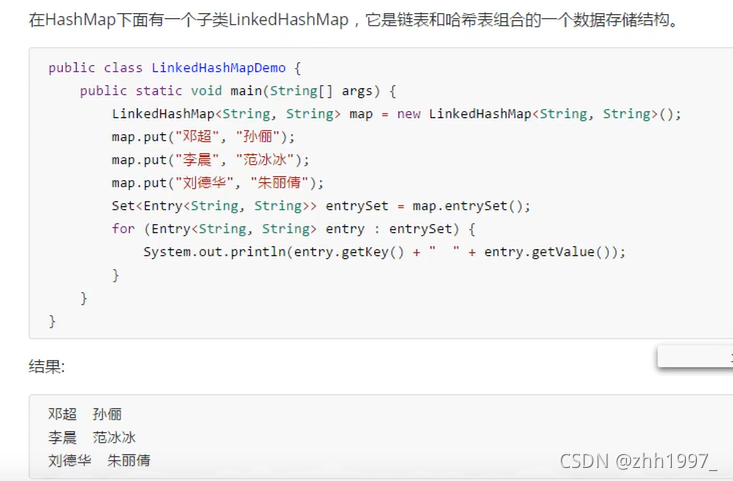 举例:
举例:
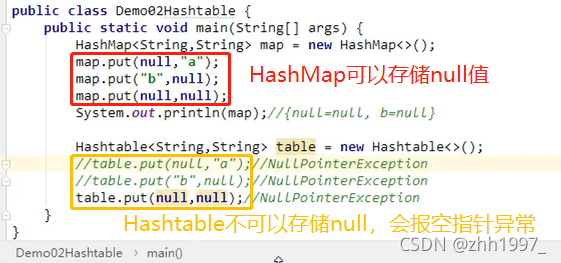
7. Hashtable集合
实现了Map接口,底层和HashMap一样是哈希表,是最早的双列集合。区别:①不能存null值;②Hashtable是同步的【安全,单线程,慢】。

7.1 Hashtable集合和HashMap集合的区别:

举例:
8.Map集合练习:
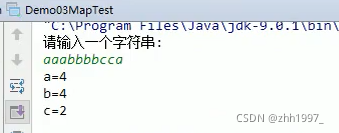
因为每个字符不能重复只统计一次,每个字符的个数可以重复,因此使用Map集合。



实现:【str.toCharArray方法把字符串转换为字符数组,返回值为字符类型的数组。】

结果:
9.斗地主综合案例
二十三、补充知识点
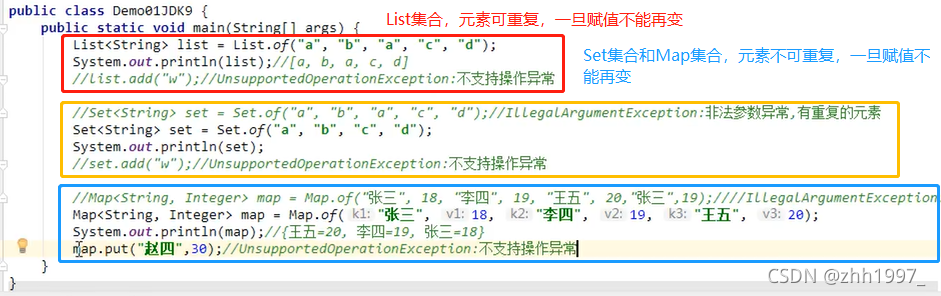
1.JDK9对集合添加元素的优化
之前学习集合添加元素add方法【List集合、Set集合】、put方法【Map集合】比较麻烦。

举例:
2.Debug追踪
Debug:调试bug。使用IDEA的断点调试功能,查看程序的运行过程。
使用:

二十四、异常
1.概念
异常也是一个类。
超类:java.lang.Throwable类。
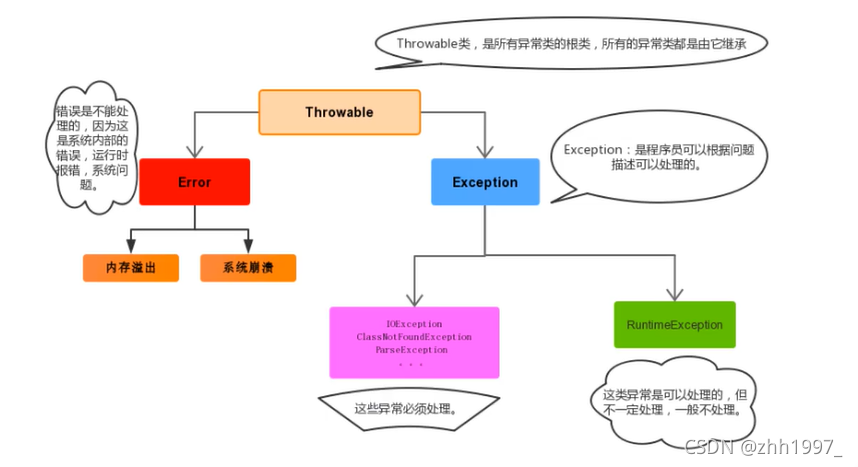
2.异常的体系
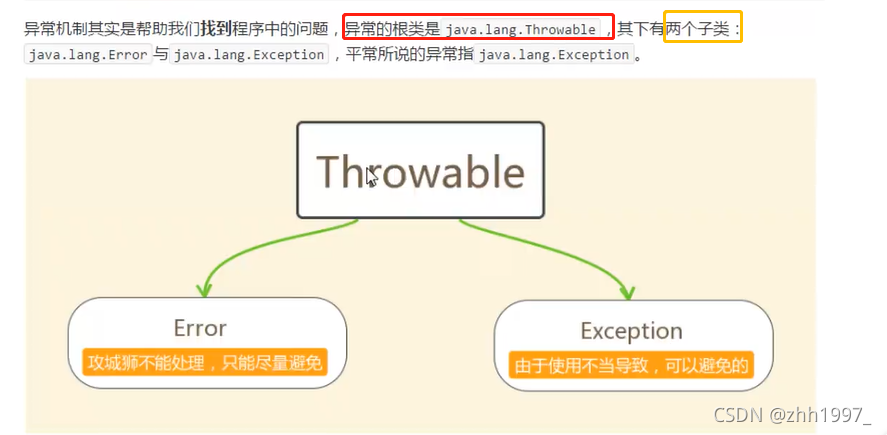
 异常【Exception】相当于程序得了小毛病,把异常处理掉,程序可以继续执行。
异常【Exception】相当于程序得了小毛病,把异常处理掉,程序可以继续执行。
错误【Error】相当于程序得了无法治愈的毛病,必须修改源代码,程序才能继续执行。
3.异常【Exception】的分类
Exception:编译时期异常。
其中一个子类:RuntimeException:运行时期异常。

4.异常的产生过程
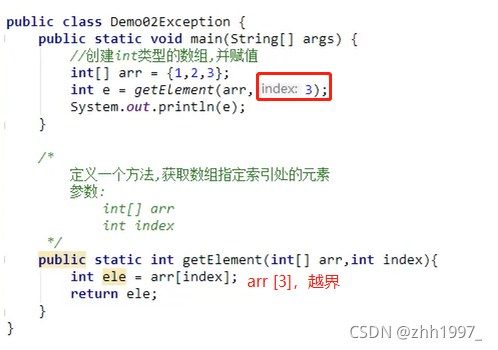
举例:数组越界异常
运行结果:
 过程解析:
过程解析:
1.getElement方法把异常对象抛出给main方法:
在getElement方法中访问了数组中的3索引,数组长度为3没有3索引,JVM就会检测出程序出现异常,此时JVM会做两件事:
①JVM会根据异常产生的原因创建一个异常对象:new ArrayIndexOutOfBoundsException ("3");这个异常对象包含了异常产生的【内容、原因、位置】,如上图运行结果;
②getElement方法中没有异常的处理逻辑(try...catch),那么JVM就会把异常对象抛出给方法的调用者:main方法,来处理这个异常。
2.main方法把异常对象抛出给JVM:
main方法接收到了这个异常对象:new ArrayIndexOutOfBoundsException ("3");main方法也没有异常的处理逻辑,继续把这个异常对象抛出给main方法的调用者JVM处理。
3.JVM处理异常:
JVM接收到了这个异常对象,做了两件事:
①把异常对象【内容、原因、位置】以红色的字体打印在控制台;
②JVM会终止当前正在执行的java程序——中断处理。
5.异常的处理
java异常处理的五个关键字:try、catch、finally、throw、throws
异常处理的两种方式:
异常处理的第一种方式:throws关键字声明异常,继续向上抛出。
异常处理的第二种方式:try...catch自己处理异常。
5.1 throw关键字:抛出异常
作用:
throw关键字用来在指定的方法中抛出异常。
使用格式:
throw new xxxException(“异常产生的原因”);
注意:
1.throw关键字必须写在方法的内部;
2.throw关键字后面new的对象必须是Exception或者Exception的子类对象;
3.throw关键字抛出指定的异常对象,就必须处理这个异常对象:
①throw关键字后面创建的是RuntimeException或者是RuntimeException的子类对象,我们可以不处理,默认交给JVM处理(打印异常对象、中断程序);
②throw关键字后面创建的是编译异常【写代码的时候报错】,我们就必须处理这个异常:要么throws,要么try...catch。
tip:
①以后工作中我们首先必须对方法传递过来的参数进行合法性校验。如果参数不合法,那么我们就必须使用抛出异常的方式,告知方法的调用者,传递的参数有问题。
②空指针异常NullPointerException、数组索引越界异常ArrayIndexOutOfBoundsException等是运行期异常,可以不用处理,默认交给JVM处理。
举例:获取数组指定索引处的元素
创建异常对象:

传递空数组:

结果【使用throw抛出的异常原因会打印在控制台】: 
5.2 Objects非空判断方法
Objects类中的静态方法:
public static <T> requireNonNull ( T obj ) :查看指定引用对象不是null。可以简化代码。
源码:
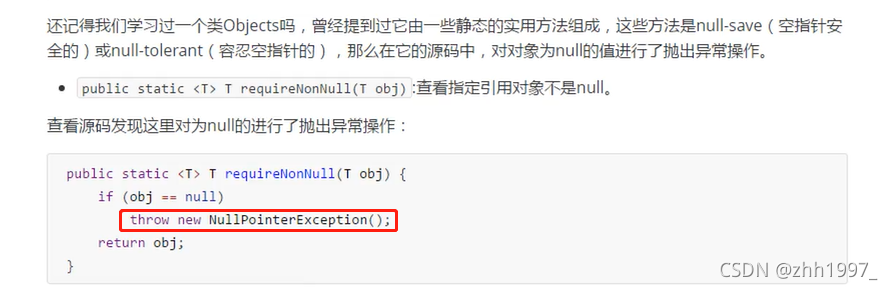
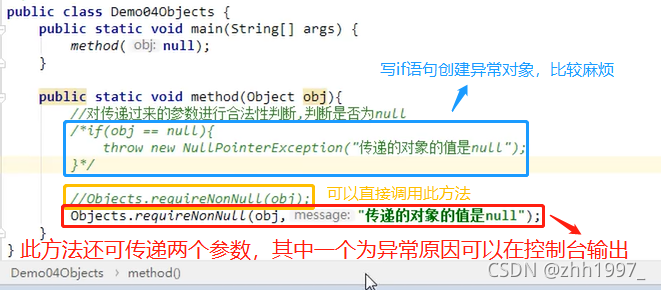
举例:
一般判断非空要写 if 语句,此方法可以直接用。
结果:
5.3 throws关键字:声明异常
异常处理的第一种方式:throws关键字。交给别人处理。
使用格式:【在方法声明时使用,一般配合throw关键字使用】
修饰符 返回值类型 方法名(参数列表)throws AAAException,BBBException...//声明异常{
throw AAAException(“产生原因”);//抛出异常
throw BBBException(“产生原因”);//抛出异常
...
}
作用:
当方法内部抛出异常对象时,我们必须处理这个异常对象。当使用throws关键字处理异常对象,会把异常对象声明抛出给方法的调用者处理【自己不处理,给别人处理】,最终交给JVM处理——中断处理。
注意事项:
1.throws关键字必须写在方法声明处;
2.throws关键字关键字后面的声明异常必须是Exception或者Exception的子类对象;
3.方法内部如果抛出了多个异常,那么throws后面也必须声明多个异常;如果抛出的多个异常对象有子父类关系,那么直接声明父类异常即可;
4.如果调用了一个声明抛出异常的方法,就必须处理声明的异常:
要么继续使用throws声明抛出,交给方法的调用者处理,最终交给JVM;
要么try...catch自己处理异常。
举例:判断传递的文件路径不是C:\\a.txt,就抛出文件找不到异常对象,告知方法的调用者。
声明方法:
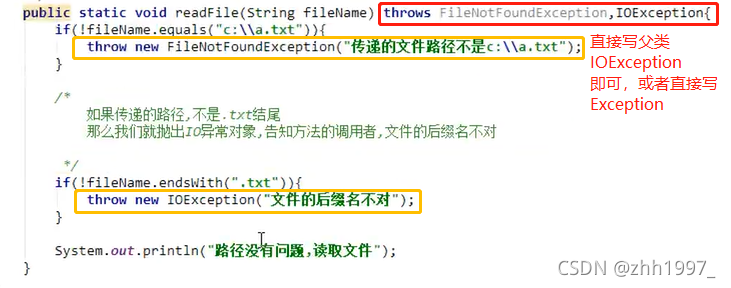
调用方法:
 结果:文件路径更改后
结果:文件路径更改后

5.4 try...catch:捕捉异常
异常处理的第二种方式:自己处理异常。try...catch方式自己处理异常,异常后面的代码会继续执行。
第一种通过throws声明异常的缺点:向上抛出最终交给JVM虚拟机处理,会中断程序,异常后面的代码将不会执行。
使用格式:
try{
可能产生异常的代码【预防】
}catch(定义一个异常的变量,用来接收try中抛出的异常对象){
异常的处理逻辑。产生异常对象之后,怎么处理异常对象。
一般在工作中,会把异常的信息记录在一个日志中。
}
...
catch(异常类名 变量名){
}
注意事项:
1.try中可能会抛出多个异常对象,就可以使用多个catch来处理这些异常对象;
2.如果try中产生了异常,那么就会执行catch中的异常处理逻辑,执行完catch中的处理逻辑,继续执行try...catch之后的代码;
如果try中没有产生异常,那么就不会执行catch中的异常处理逻辑,执行完try中的代码,继续执行try...catch之后的代码。
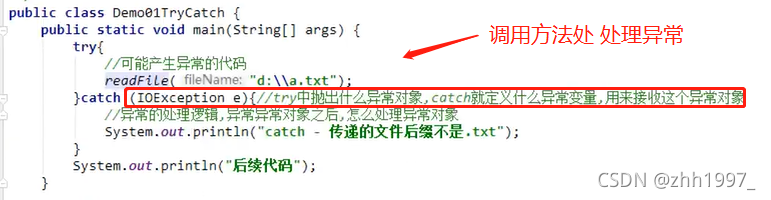
举例:同上例,读取文件

调用方法处处理异常,try捕获了异常给catch:
运行结果:
①文件后缀不正确:

②文件后缀正确:
5.5 Throwable类中3个异常处理方法
其中printStackTrace方法是JVM打印异常信息默认的调用方法,打印的异常信息最全面。
举例:和上例一样
①使用getMessage方法:
抛出异常:
捕获处理异常:
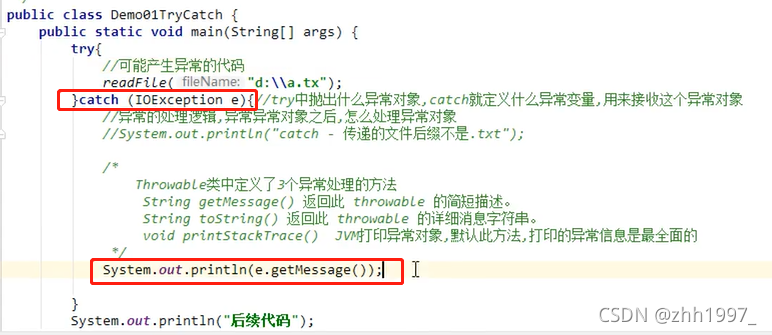
结果:
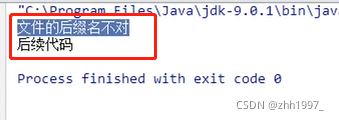
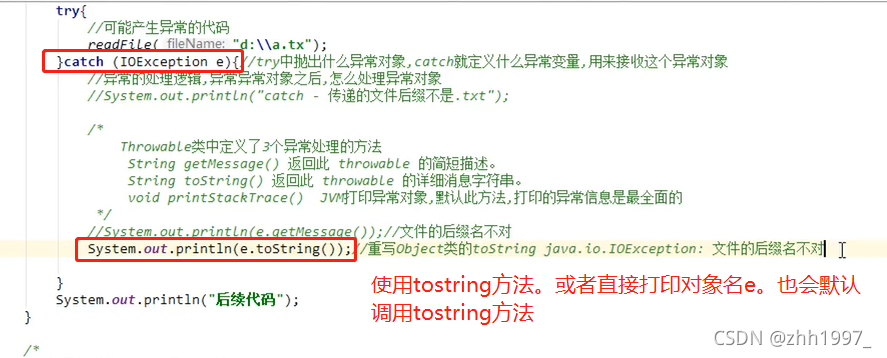
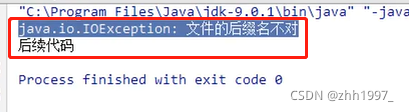
②使用toString方法:
捕获处理异常:
结果:
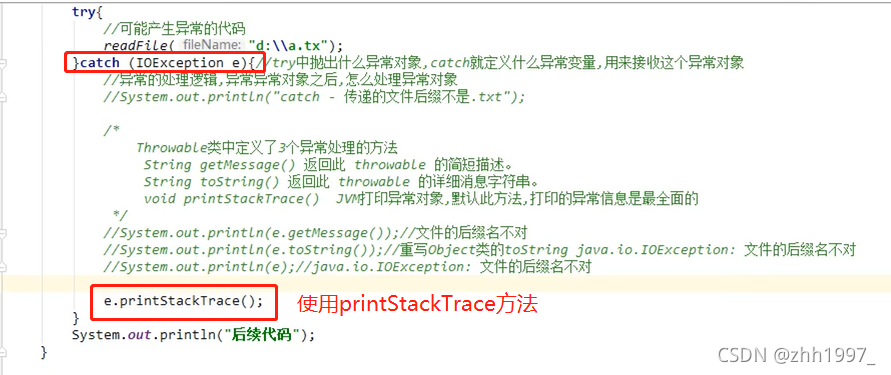
③使用printStackTrace方法:
结果:【异常信息最全面】

5.6 finally代码块
有一些特定的代码无论异常是否发生都需要执行,就使用到了finally代码块。

使用格式:
try{
可能产生异常的代码【预防】
}catch(定义一个异常的变量,用来接收try中抛出的异常对象){
异常的处理逻辑。产生异常对象之后,怎么处理异常对象。
一般在工作中,会把异常的信息记录在一个日志中。
}
...
catch(异常类名 变量名){
}finally{
无论是否出现异常都会执行
}
注意事项:
1.finally不能单独使用,必须和try一起使用;
2.finally一般用于资源释放【资源回收】,无论程序是否出现异常,最后都要资源释放(IO)。
举例:同上例
文件读取方法抛出了异常,在main方法中进行处理:
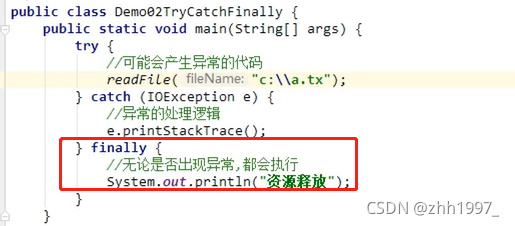
结果:

5.7 异常的注意事项
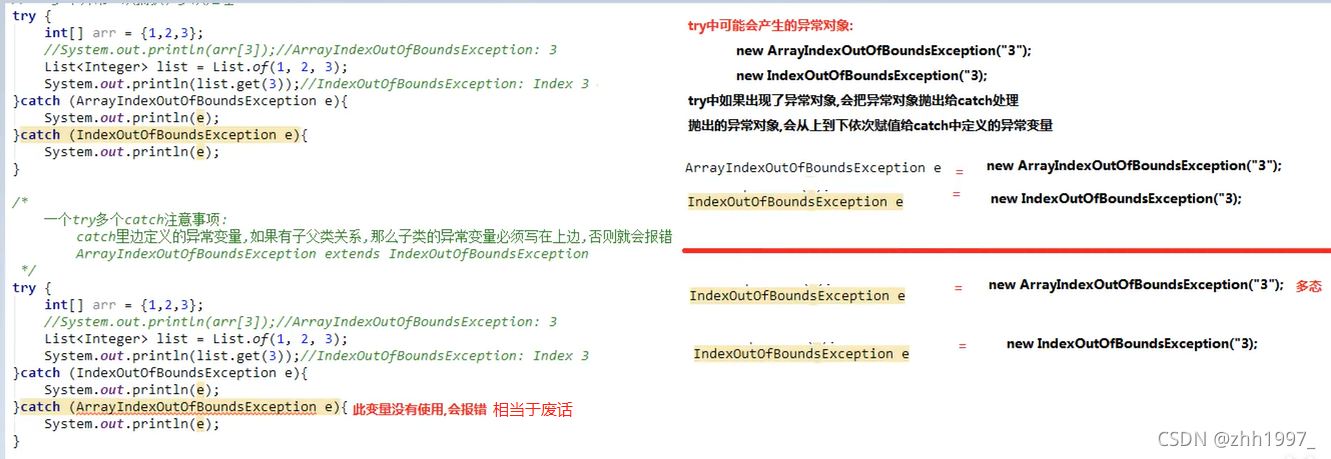
5.7.1 多异常的捕获处理
①多个异常分别处理;
②多个异常一次捕获,多次处理;
③多个异常一次捕获,一次处理。
其中②一次捕获,多次处理【一个try,多个catch】有注意事项:
此时catch里面定义的异常变量,如果有子父类关系,那么子类的异常变量必须写在上面的catch中,否则会报错。原因如下图:
举例:
两个异常:数组索引溢出、集合索引溢出

①多个异常分别处理
 结果:
结果:
②多个异常一次捕获,多次处理
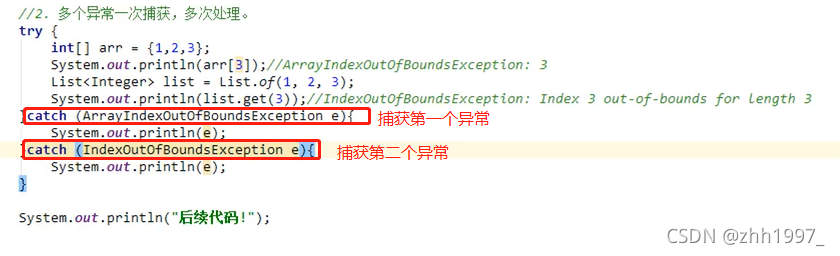
结果:

③多个异常一次捕获,一次处理

结果;

这个例子是运行时异常:运行时异常被抛出可以不处理,既不捕获也不声明抛出,默认交给JVM虚拟机处理。终止程序,什么时候不抛出运行时异常了再继续执行程序。
5.7.2 finally代码块有return语句
如果finally有return语句,会永远返回finally中的结果,要避免该情况。
5.7.3 子父类异常
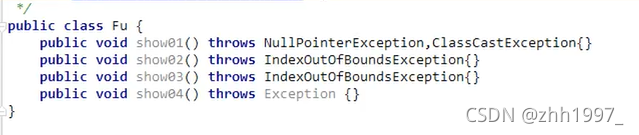
1.【父类有异常,子类抛出的异常范围小于等于父类的异常】:如果父类抛出了多个异常,子类重写父类方法时。抛出和父类相同的异常或者父类异常的子类或者不抛出异常;
2.【父类没有异常,子类只能捕获异常,不能抛出】:父类方法没有抛出异常,子类重写父类该方法时也不可抛出异常。此时子类产生该异常,不能声明抛出。
举例:
父类:声明异常
子类:


5.8 自定义异常
概述:
java提供的异常类不够我们使用,需要自己定义一些异常类。
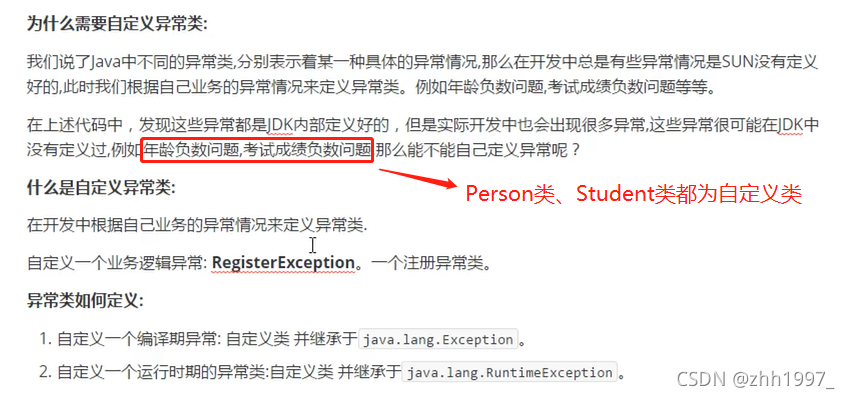
格式:
public class XxxException extends Exception / RuntimeException {
添加一个空参数的构造方法
添加一个带异常信息的构造方法
}
注意:
1.自定义异常类一般都是以Exception结尾,说明该类是一个异常类;
2.自定义异常类,必须继承Exception类或者RuntimeException类:
继承Exception类:自定义异常类是编译期异常。若方法内部抛出了编译期异常,就必须处理这个异常。要么throws,要么try...catch;
继承RuntimeException类:自定义异常类是运行期异常,无需处理,交给虚拟机JVM处理【中断处理】。
举例:
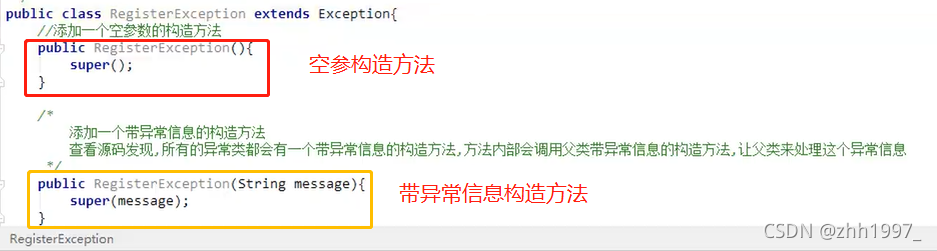
5.9 自定义异常练习
模拟注册操作,如果用户名已存在,则抛出异常并提示:亲,该用户名已经被注册。
分析:

实现:
①继承Exception类,必须处理:throws或try...catch
throws: 
try...catch:

②继承RuntimeException类,无需处理,默认给JVM,最后中断程序


二十五、多线程
1.并发与并行
并发:
指两个或者多个事件在同一个时间段内发生【交替执行】。
并行:
指两个或多个事件在同一时刻发生【同时发生】,速度快。
2.线程与进程

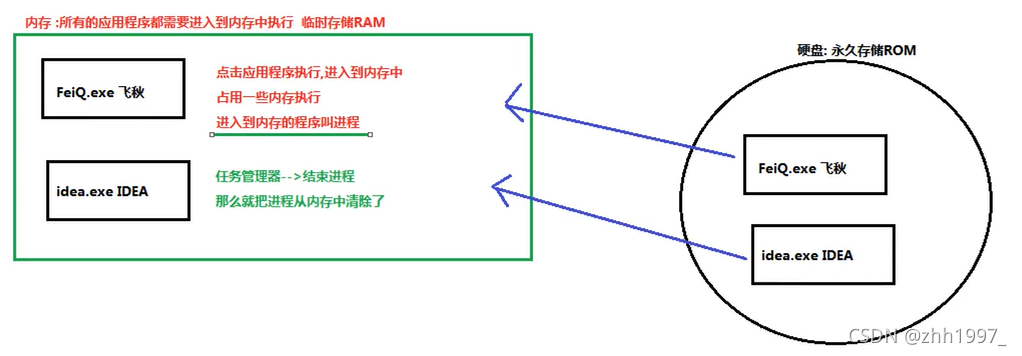
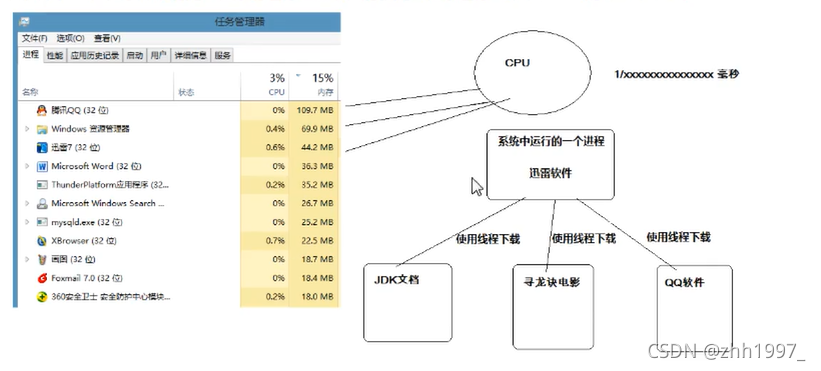
进程:
比如此时正在执行的浏览器、微信、记事本、搜狗输入法等。【应用程序存储在磁盘(ROM,永久存储)中,运行应用程序在内存(RAM,临时存储)中,进入到内存中运行的程序叫进程】
线程:
比如电脑管家可以同时病毒查杀、清理垃圾等,因此电脑管家为多线程程序。点击功能(病毒查杀、清理垃圾等)执行,就会开启一条应用程序到CPU的执行路径,CPU可以通过这个路径执行功能,这个路径就叫线程。线程属于进程,是进程的一个执行单元,负责程序的执行。
单核心单线程CPU:CPU在多个线程之间高速的切换,轮流执行多个线程,效率低,切换的速度1/n毫秒;4核心8线程CPU:有8个线程,可以同时执行8个线程。8个线程在多个任务之间做高速的切换,速度是单线程CPU的8倍(每个任务执行到的几率都被提高了8倍)。
多线程好处:
1.效率高;2.多个线程之间互不影响。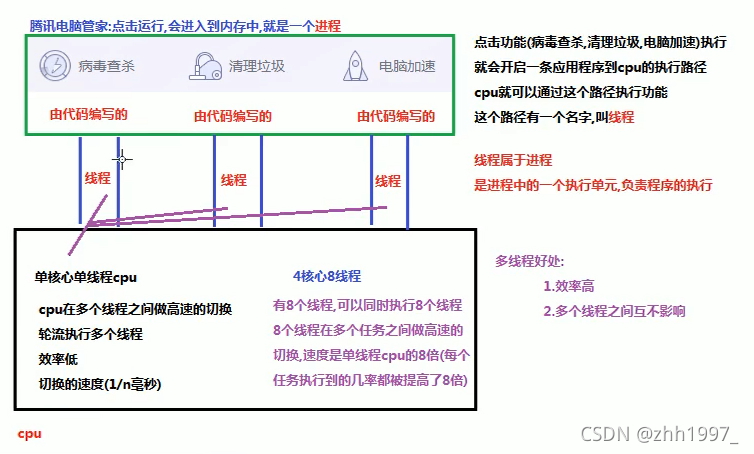
3.线程调度
分时调度:
所有CPU轮流使用CPU的使用权,平均分配每个线程占用CPU时间。
抢占式调度:
优先让优先级高的线程使用CPU,如果线程的优先级相同,那么会随机选择一个【线程随机性】,java使用的为抢占式调度。

4.主线程
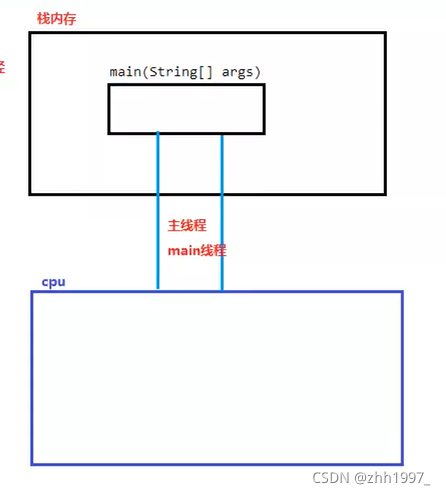
主线程:
执行主方法(main方法)的线程。JVM执行main方法,main方法会进入到栈内存。JVM会找操作系统开辟一条main方法通向CPU的执行路径,CPU就可以通过这个路径执行main方法,这个路径就叫main【主】线程。
单线程程序:
java程序中只有一个线程。执行方式:从main方法开始,从上到下依次执行。
单线程程序只有一个主线程,一旦有异常,后面的代码将不再执行,因此需要使用多线程。
5.创建多线程程序的第一种方式
第一种方式:创建Thread类的子类。
java.lang.Thread类:是描述线程的类,想要实现多线程程序,就必须继承Thread类。
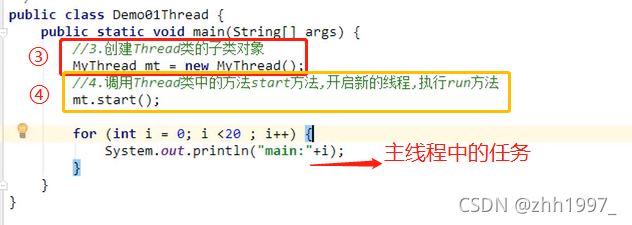
实现步骤:
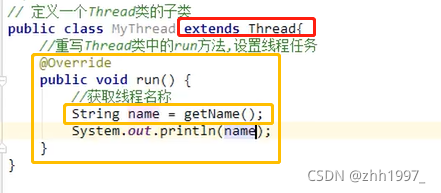
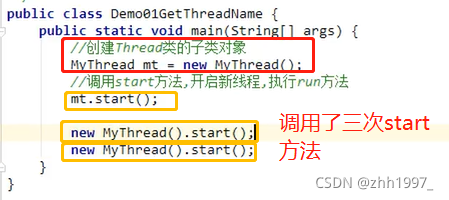
1.创建一个Thread类的子类;
2.在Thread类的子类中重写Thread类中的run方法,设置线程任务(开启线程要做什么);
3.创建Thread类的子类实例,即创建线程对象;
4.调用Thread类中的start()方法,开启新的线程,执行run方法。
注意:
1.Start()方法两个作用:void start( ):
①使该线程开始执行;②Java虚拟机调用该线程的run方法
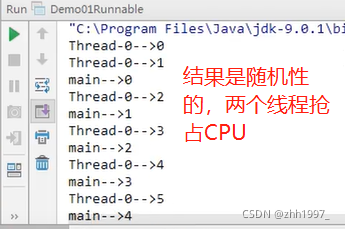
2. 结果是两个线程并发地执行【两个线程在同一时间抢占执行】:当前线程(main线程)和另一个线程(创建的新线程,执行run方法)。
3.多次启动同一个线程【对象】是非法的,特别是当线程已经结束执行后,不能再重新启动。即一个线程对象只能start一次,需要再使用的话就要new该线程的新对象调用start。
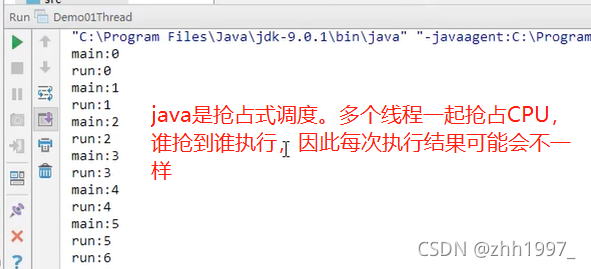
java使用的为抢占式调度,优先级高的线程先执行,优先级一样随机选择一个执行,因此每次执行的结果可能不一样,如下例。
举例:
创建新线程并重写run方法: 
main线程中创建自定义线程的对象并开启线程:
结果【以上两个线程在同一时间抢占执行】:
6.多线程原理
1.随机打印结果
上例中每次运行结果可能不一样,是随机性的,两个线程抢占CPU,谁抢到谁执行,原理如下:第308个视频
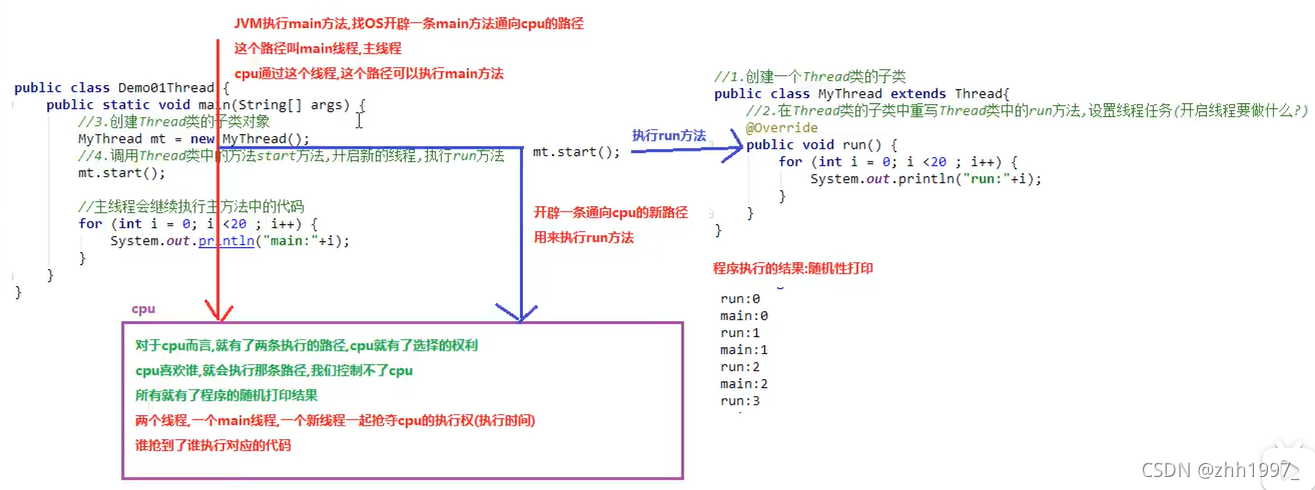
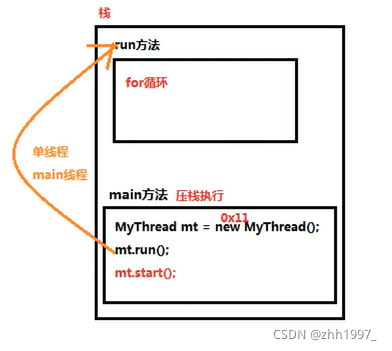
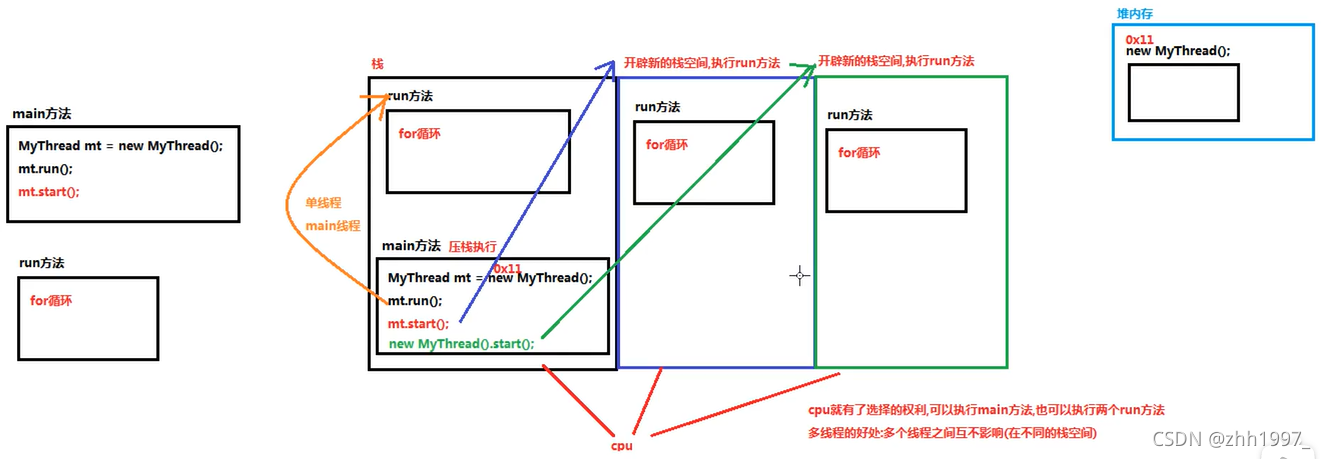
2.内存图解
过程:
Main方法先压栈执行。如果直接调用run()方法,run方法会和main方法进入同一个栈,就是单线程程序,只有一个主(main)线程,会先执行完run方法中的代码,后执行main方法中的其他代码。
但要调用start()方法,会开辟新的栈空间执行run方法,调用几次run方法就会新开辟几个栈。因此具有多个栈,CPU有了选择的权利,可以执行main方法也可以执行别的栈中的run方法。 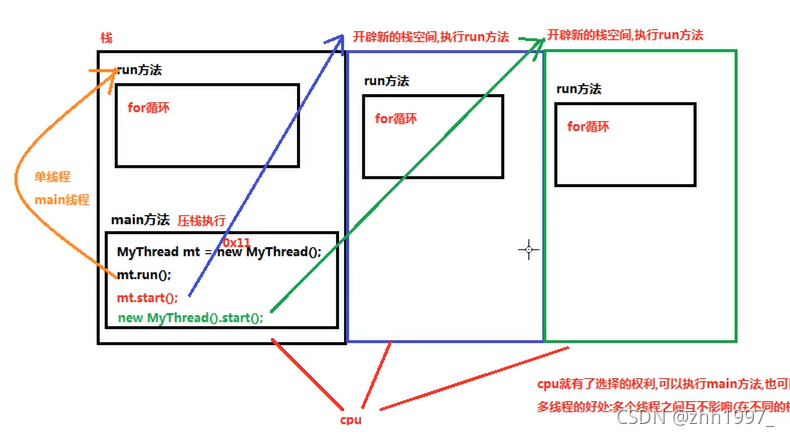
多线程的好处:
多个线程之间互不影响(在不同的栈空间。)
7.Thread类的常用方法

7.1 获取线程名称两种方法
1. 【继承Thread类才可以使用】:使用Thread类中的getName方法。
String getName():返回该线程的名称、
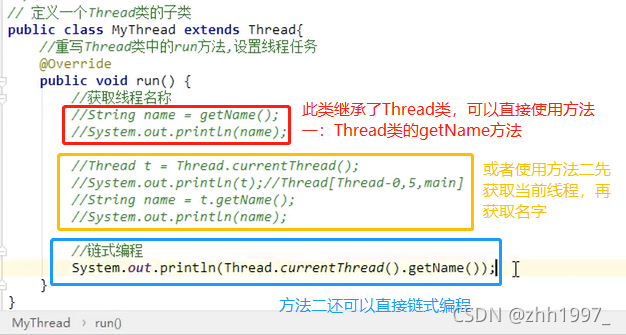
2. 【任何类都可以使用】:先获取目前正在执行的线程【static Thread currentThread():返回对当前正在执行的线程对象的引用】,再使用线程中的的方法getName()获取线程名称。
举例:
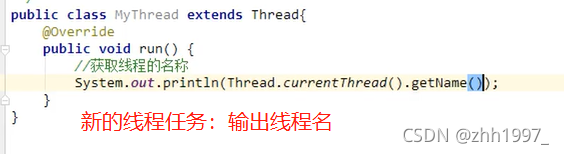
方法1:
定义新线程,重写run方法,使用getName方法获取线程名称
在主线程中创建对象,开启线程;
结果:
方法2:
新线程:
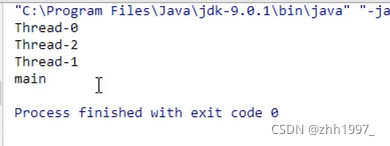
主线程:
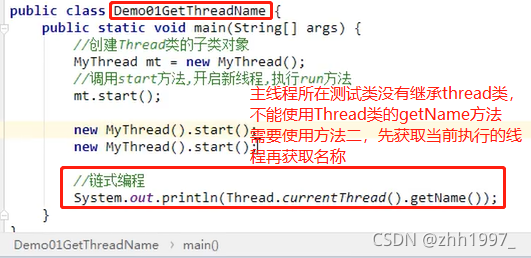
结果:
7.2 设置线程名称的两种方法
1. 【继承Thread类才可以使用】:使用Thread类中的setName方法:
Void setName(String name):改变线程的名称,使之与参数name相同。
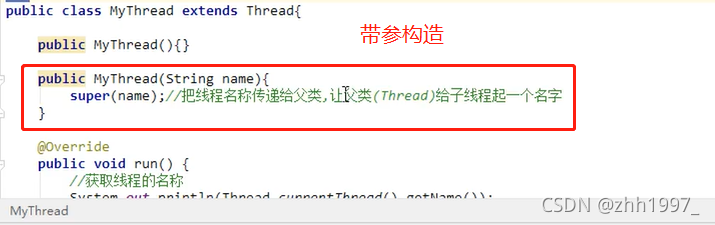
2.创建一个带参数的构造方法,参数传递线程的名称。调用父类的带参构造方法,把线程名称传递给父类,让父类(Thread)给子线程起一个名字。
Thread(String name):分配新的Thread对象。
举例:
方法1:
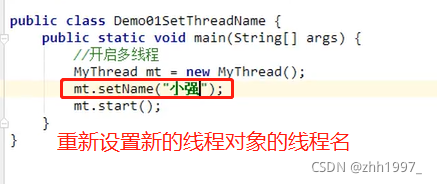
结果:
方法2:
在新线程中创建带参数的构造方法:
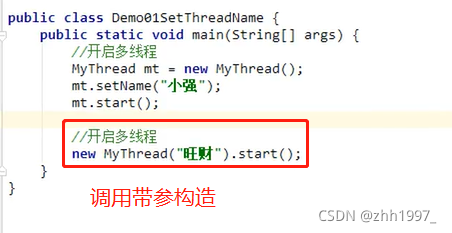
结果:

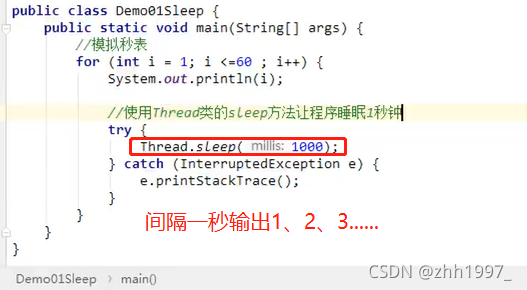
7.3 sleep方法:暂时停止执行
public static void sleep(long millis):使当前正在执行的线程以指定的毫秒数暂停(暂时停止运行),毫秒数结束之后线程继续执行。
举例:间隔一定时间输出
7.4 线程的优先级

8.创建多线程程序的第二种方式
第二种方式:实现Runnable接口。
java.lang.Runnable:
Runnable接口应该由那些打算通过某一线程执行其 实现类的类来实现。类必须定义一个称为run的无参数方法。
java.lang.Thread类的构造方法【可以传递Runnable接口的实现类对象】:
Thread(Runnable target):分配新的Thread对象
Thread(Runnable target,String name):分配新的Thread对象
创建线程的步骤:
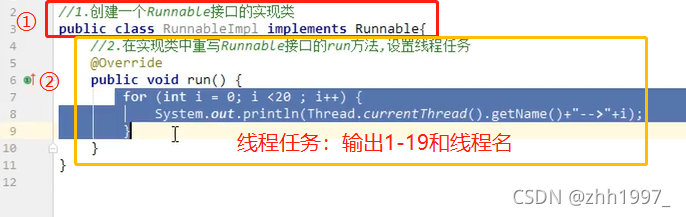
- 创建一个Runnable接口的实现类;
- 在实现类中重写Runnable接口的run方法,设置线程任务;
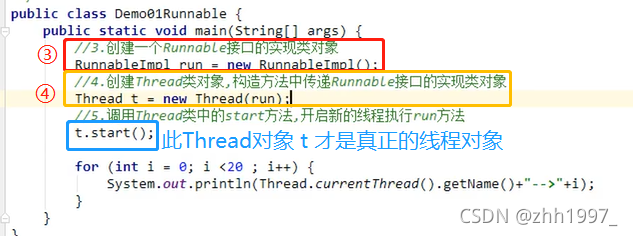
- 创建一个Runnable接口的实现类对象,并以此实例对象作为Thread的构造方法的target来创建Thread对象,该Thread对象才是真正的线程对象【构造方法中传递Runnable接口的实现类对象】;
- 调用Thread类中的start方法,开启新的线程执行run方法。
举例:
结果:
9.Thread和Runnable的区别
9.1 两种方式创建并启动线程的格式
1.继承Thread类:
创建Thread类子类的对象,直接调用start方法。

2.实现Runnable接口:
此接口中无start方法,需要使用Runnable接口的实现类对象作为参数传递到Thread的构造方法中,来创建Thread对象,再调用start方法启动线程。

9.2 使用Runnable方式的好处
1.避免了单继承的局限性。
一个类只能继承一个类,继承了Thread类就不能再继承其他类,但实现Runnable接口,还可以继承其他类、实现其他接口;
2.增强了程序的扩展性,降低了程序的耦合性(解耦)。
实现Runnable接口的方式,把设置线程任务和开启新线程进行了分离(解耦):给Thread构造方法传递不同的Runnable实现类对象会开启不同的线程。
10.匿名内部类方式实现线程的创建
使用线程的匿名内部类方式,可以方便的实现每个线程执行不同的线程任务操作。匿名:没有名字。内部类:写在其他类内部的类。
作用:
把子类继承父类、重写父类的方法、创建子类对象合为一步完成。
把实现类实现接口、重写接口的方法、创建实现类对象合为一步完成。
因此。匿名内部类的最终产物:子类或者实现类的对象。
格式:
new 父类/接口(){
重写父类/接口中的方法
};
举例:
1.匿名内部类:Thread方式
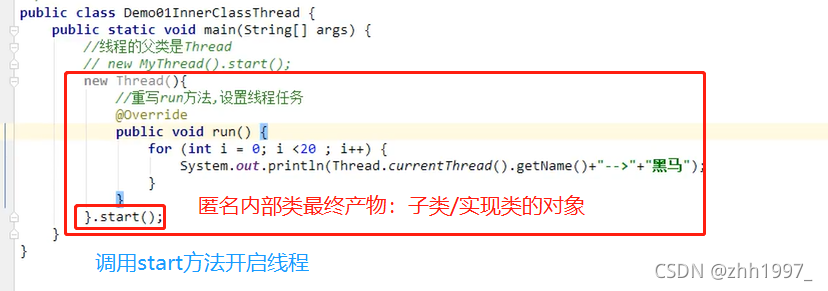
结果:只有一个Thread0线程,因为main线程里面无线程任务。
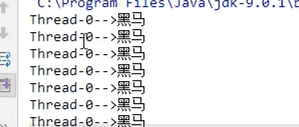
2. 匿名内部类:Runnable方式

结果:

继续简化:

结果:

11.线程安全
11.1 线程安全
多线程访问了共享数据就会产生线程安全问题。即多个线程在同时运行,这些线程可能会同时运行这段代码,要使程序每次运行结果和单线程运行的结果一样,而且其他变量的值也和预期一样,就是线程安全的。
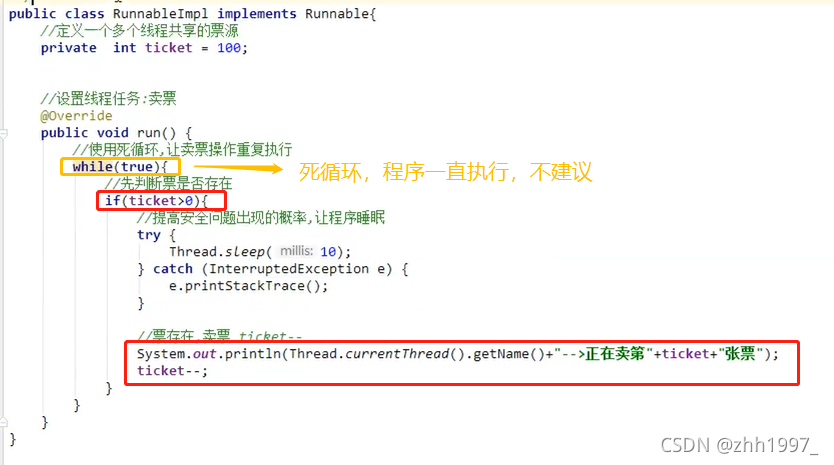
举例:卖票案例
三个线程卖100张票:
创建三个线程对象并开启线程【此时只创建了1个线程对象run来创建3个线程,因此相当于3个线程卖100张票】,要是改为new三个对象run1、run2、run3,则为3个线程卖300张票:
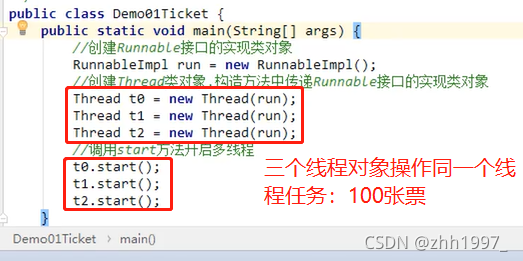
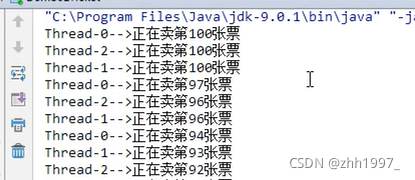
原理:
开启了3个线程,一起抢夺CPU的执行权,谁抢到谁执行。比如线程1抢到了CPU执行权,进入到run方法后休眠失去了CPU的执行权,此时别的线程进入到了run方法执行了线程任务,导致数据不同步。
注意:
线程安全问题是不能产生的。可以让一个线程在访问共享数据的时候,无论是否失去了CPU执行权,其他的线程都只能等待当前线程执行完毕再执行。
11.2 线程同步
同步机制:
要解决多线程并发访问一个资源的安全性问题,java中提供了同步机制(synchronized)来解决。
解决线程安全问题的三种方案:
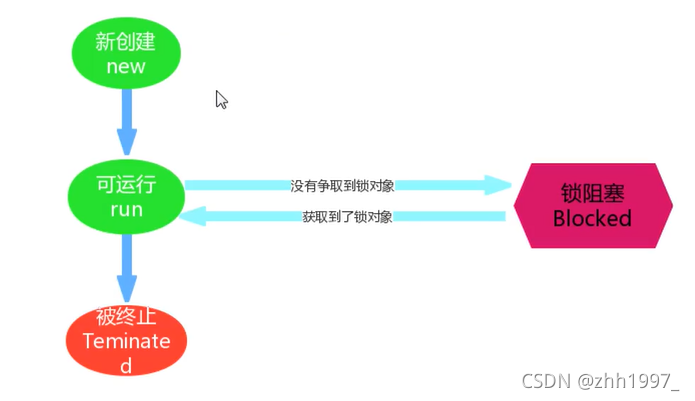
1.同步代码块;2.同步方法;3.锁机制

11.3 同步代码块
概述:
Synchronized关键字可以用于方法中的某个区块中,表示只对这个区块的资源实行互斥访问。
格式:
Synchronized(锁对象【同步监视器】){
可能会出现线程安全问题的代码(访问了共享数据的代码)
}
注意:
- 代码块中的锁对象,可以使用任意类的对象;
- 必须保证多个线程使用的锁对象是同一个【锁对象要定义在线程任务外面,否则每个线程会各自创建一个锁对象,线程还是不安全】;
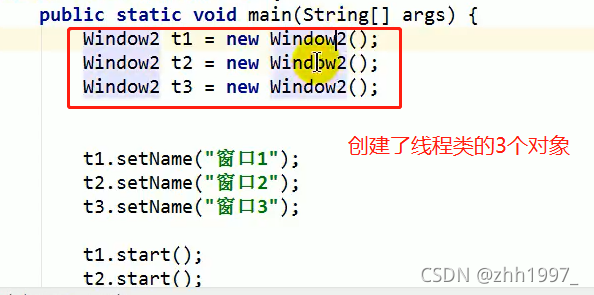
- 锁对象的作用:把同步代码块锁住,只让一个线程在同步代码块中执行。
举例:
买票案例加同步代码块【把while(true)写在了同步代码块外面,每次运行3个线程抢占监视器对象,一旦抢到别的线程都等待】: 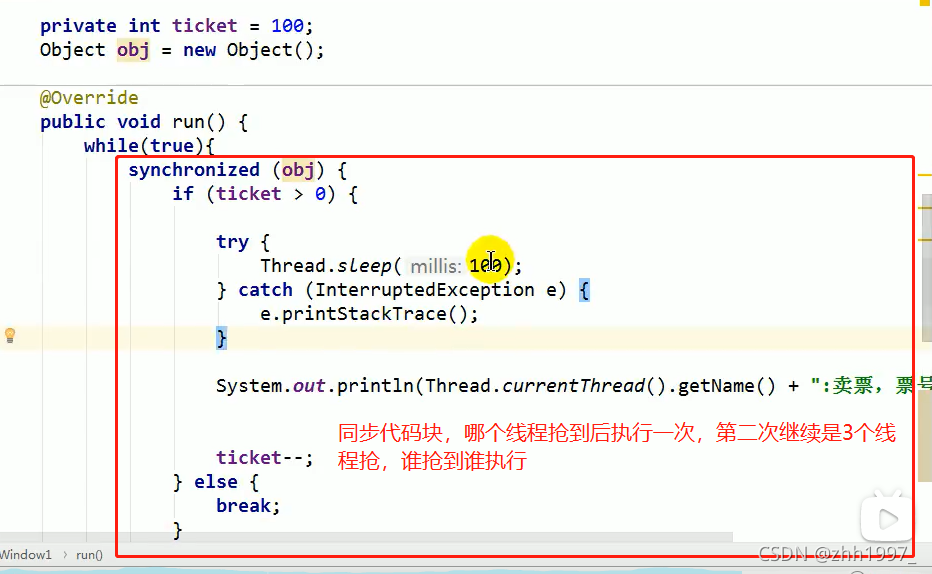
买票案例加同步代码块【此案例同步代码块把while(true)写在了同步代码块内,因此结果是一个线程一直卖完票】: 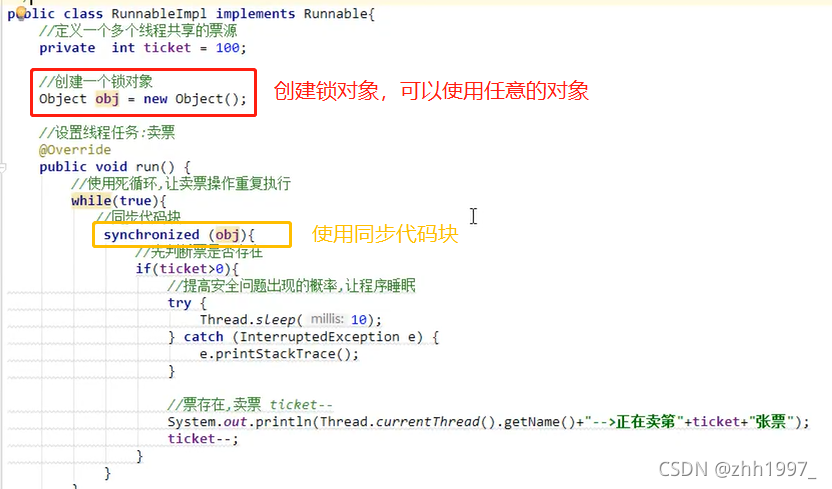
原理:
使用了一个锁对象(上例中obj),这个锁对象叫同步锁,也叫对象锁,也叫对象监视器。
3个线程一起抢夺cpu的执行权,谁抢到了谁执行run方法进行卖票操作。
若t0抢到了cpu的执行权,执行run方法,遇到Synchronized代码块,这时t0会检查Synchronized代码块是否有锁对象,发现有,就会获取到锁对象,进入到同步代码块中执行。
若此时t1抢到了cpu执行权,执行run方法,遇到Synchronized代码块,这时t1会检查Synchronized代码块是否有锁对象,发现没有,t1会进入到阻塞状态,一直等待t0归还锁对象,一直到t0执行完同步代码块就会把锁对象归还给同步代码块,t1才能获取锁对象进入到同步代码块中执行。
总结:
同步中的线程没有执行完毕就不会释放锁,同步外的线程没有锁进不去同步。
优缺点:
同步保证了只能有一个线程在同步代码块中执行共享数据,保证了线程安全。但因为程序要频繁地判断锁、获取锁、释放锁,程序的效率会降低。
注意:
Runnable方式创建一个对象即可,天然共享。Thread方式每创建一个线程必须创建一个新的对象,因此锁对象要保证唯一必须使用静态变量将锁对象变为类变量。
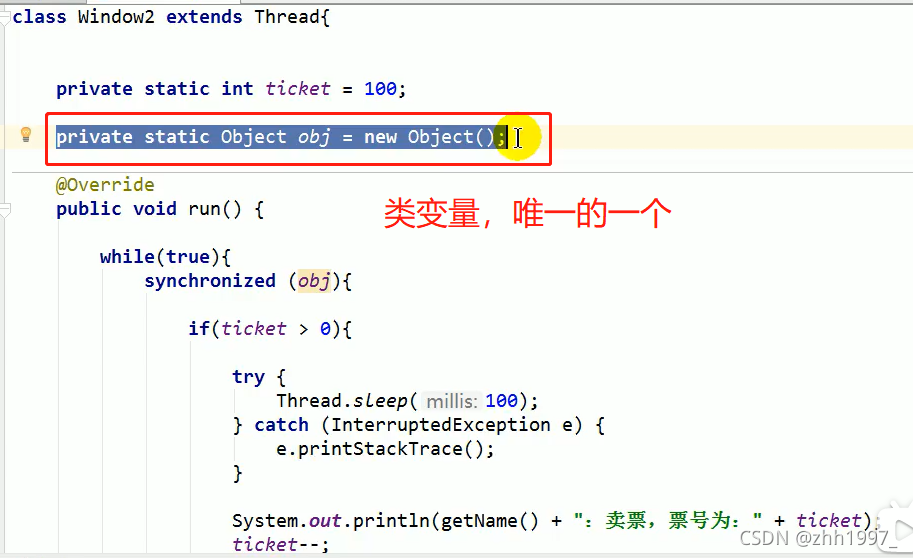
11.4 同步方法
概述:
使用Synchronized修饰的方法就叫做同步方法,保证A线程执行该方法的时候,其他线程只能在方法外等着。
格式:
修饰符 Synchronized 返回值类型 方法名(参数列表){
可能会出现线程安全问题的代码(访问了共享数据的代码)
}
使用步骤:
- 把访问了共享数据的代码抽取出来,放到一个方法中;
- 在方法上添加Synchronized修饰符。
注意:
定义一个同步方法,也会把方法内部的代码锁住,只让一个线程执行。
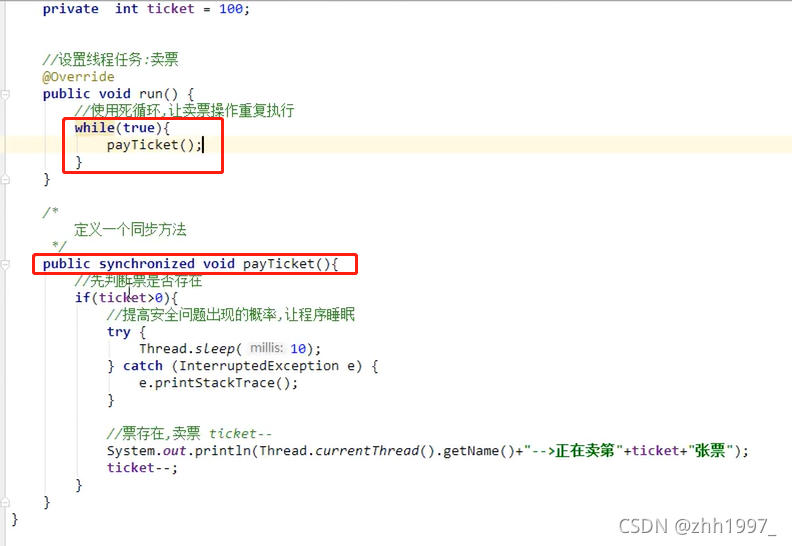
锁对象是谁?谁调用同步方法就是谁【this】,就是new的实现类对象,注意只能new一个。
静态同步方法:
静态同步方法锁对象不能是this,this是创建对象之后产生的,静态方法优先于对象。静态方法的锁对象是本类的class属性—>class文件对象(反射)。
举例:
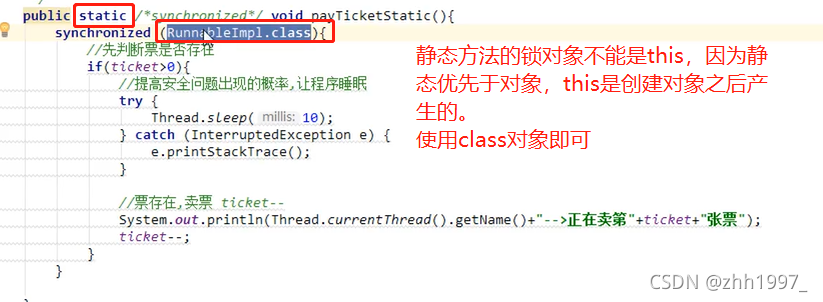

注意:
Runnable方式可以简化使用this作为锁对象,因为Runnable方式只用创建一个实现类对象,天然共享。Thread方式不行,Thread方式每创建一个线程必须创建一个新的对象,因此不能使用this,因为this不唯一,和静态方法一样只能使用class对象。
举例:

11.5 Lock锁
概述:
Java.util.concurrent.locks.lock:接口。提供了比Synchronized代码块和Synchronized方法更广泛的操作,同步代码块/同步方法具有的功能Lock都有,除此之外更强大,更体现面向对象。

Lock接口中的方法:
void lock ():获取锁
void unlock ():释放锁
Lock接口的实现类【接口不能直接创建对象使用】:
Java.util. concurrent.locks.ReentrantLock implements Lock接口
使用步骤:
- 在成员位置创建一个ReentrantLock对象;
- 在可能出现安全问题的代码前调用Lock接口中的lock方法获取锁;
- 在可能出现安全问题的代码后调用Lock接口中的unlock方法释放锁。
11.6 Synchronized方式与Lock方式异同:
相同:
都可以解决线程安全问题。
不同:
Synchronized机制在执行完相应的同步代码以后,自动地释放同步监视器;
Lock需要手动地启动同步(lock方法),同时结束同步也需要是手动实现(unlock方法)。

12.线程状态
12.1 概述

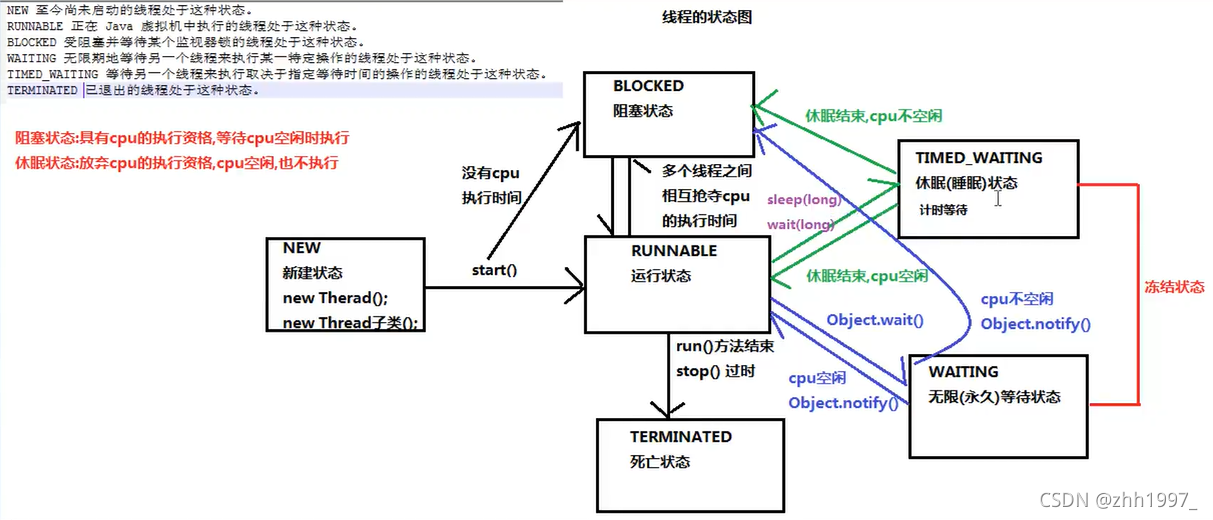
12.2 计时等待

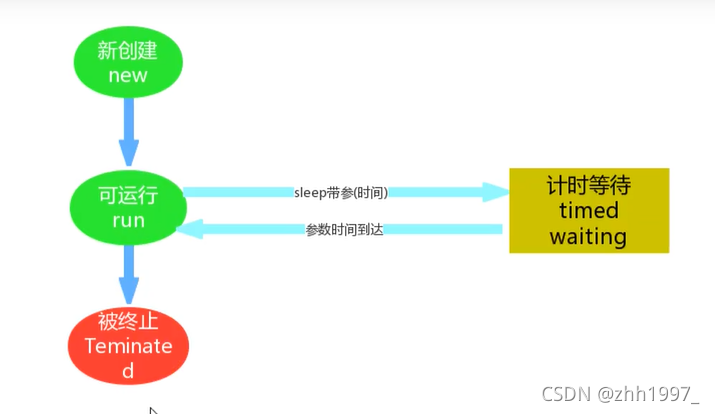
12.3 锁阻塞

12.4 无限等待
在API中介绍:一个正在无限期等待另一个线程执行一个特别的(唤醒)动作的线程处于这一状态。
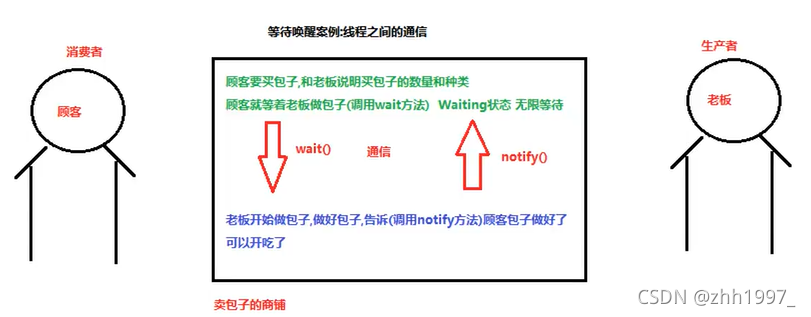
12.5案例:等待唤醒,也叫线程间的通信
分析:
创建一个顾客线程(消费者):告知老板要的包子种类和数量,调用wait方法,放弃CPU的执行,进入到WAITING状态(无限等待);
创建一个老板线程(生产者):花了5秒做包子,做好包子之后,调用notify方法,唤醒顾客吃包子。
注意:
- 顾客和老板线程必须使用同步代码块包裹起来,保证等待和唤醒只能有一个在执行;
- 同步使用的锁对象必须保证唯一;
- 只有锁对象才能调用wait方法和notify方法。
Object类中的wait、notify方法:
void wait():在其他线程调用此对象的notify()方法或notifyAll()方法前,导致当前线程等待;
void notify():唤醒在此对象监视器上等待的单个线程。继续执行wait方法之后的代码。
实现:
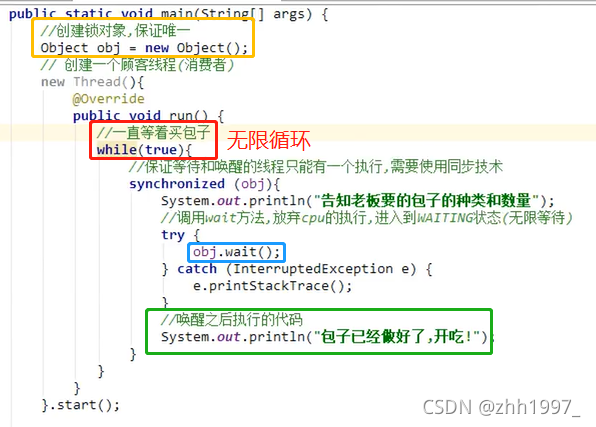
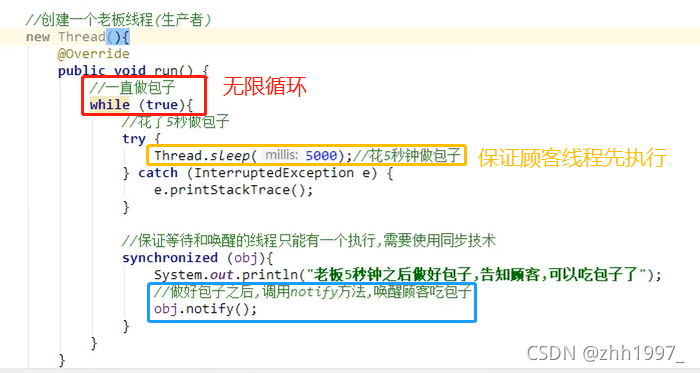
结果:一直循环

12.6 wait带参方法和notifyAll方法
进入到TimeWaiting(计时等待)有两种方式:
- 使用sleep(long m)方法,在毫秒值结束之后,线程睡醒进入到Runnable/Blocked状态;
- 使用wait(long m)方法,如果在毫秒值结束之后,还没有被notify唤醒,就会自动醒来,线程睡醒进入到Runnable/Blocked状态。
两种唤醒的方法:
1.void notify():唤醒此对象监视器上等待的单个线程;
2.void notifyAll():唤醒此对象监视器上等待的所有线程。
13.等待唤醒机制【线程间通信】
13.1 线程间通信
概念:
多个线程在处理同一个资源,但是处理的动作(线程的任务)不相同。



13.2 等待唤醒机制




14.线程池
14.1 概述
线程池和集合一样是一个容器。因此可以使使用集合:ArrayList、HashSet、LinkedList、HashMap。最常用:LinkedList<Thread>


14.2 底层原理

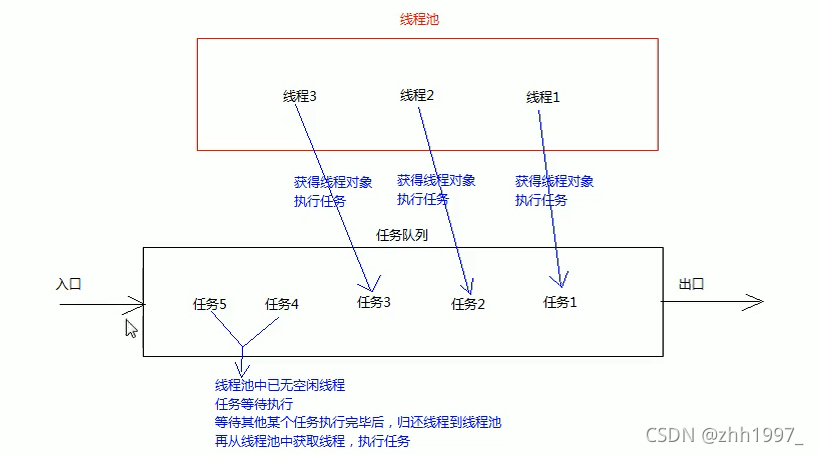
14.3 好处
14.4 使用
概述:
JDK1.5之后提供的。使用生产线程池的工程类:Executors类。Executors类有生产线程池的静态方法。

创建线程池的方法:
Public static ExecutorService newFixedThreadPool(int nThreads):创建一个可重用固定线程数的线程池。
参数:
int nThreads:创建线程池中包含的线程数量;
返回值:
ExecutorService:是一个接口。返回的是ExecutorService接口的实现类对象,可以使用ExecutorService接口接收【多态,面向接口编程】。
Java.util.concurrent, ExecutorService:线程池接口
用来从线程池中获取线程,调用start方法执行线程任务。submit (Runnable task)提交一个Runnable任务用于执行。
关闭/销毁线程池的方法:
void shutdown()

线程池的使用步骤:

- 使用线程池的工厂类Executors提供的静态方法newFixedThreadPool生产一个指定线程数量的线程池;
- 创建一个类,实现Runnable接口,重写run方法,执行线程任务;
- 调用ExecutorService中的方法submit,传递线程任务(实现类),开启线程,执行run方法;
- 调用ExecutorService中的方法shutdown销毁线程池(不建议执行)。
举例:
【传递了3个线程任务,因此线程池里的2个线程一共抢占执行3次。】
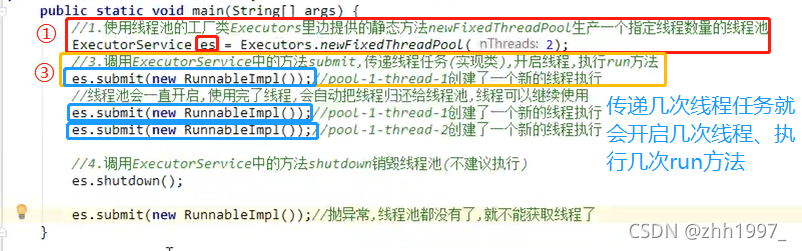

15.Lambda表达式
15.1 函数式编程思想概述
在数学中,函数就是有输入量、输出量的一套计算方案,也就是“拿什么东西做什么事情”。相对而言,面向对象过分强调“必须通过对象的形式来做事情”,而函数式思想则尽量忽略面向对象的复杂语法——强调做什么,而不是以什么形式做。
面向对象思想:做一件事情要找一个能解决这个事情的对象,调用对象的方法完成事情;
函数式编程思想:只要能获取到结果,谁去做的、怎么做的都不重要,重视结果、不重视过程。
15.2 冗余的Runnable代码
举例:
传统写法使用匿名内部类的方式实现多线程:



代码分析:
使用匿名内部类,可以帮助我们省去实现类的定义。但另一方面,匿名内部类的语法太复杂!

语义分析:
15.3 编程思想转换
15.4 体验Lambda的更优写法


JDK8:Lambda表达式
上例使用Lambda表达式的写法:
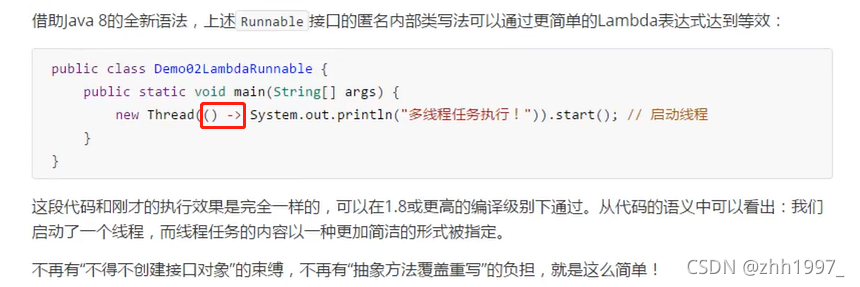
15.5 Lambda表达式的使用前提
15.6 Lambda标准格式
Lambda省去面向对象的条条框框,格式由3部分组成:
- 一些参数
- 一个箭头
- 一段代码
Lambda表达式的标准格式为:
(参数类型 参数名称)-> { 一些重写方法的代码 }
格式说明:
():接口中抽象方法的参数列表,没有参数就空着;有参数就写出参数;多个参数使用逗号分隔;
->:传递的意思,把参数传递给方法体{ };
{ }:重写接口的抽象方法的方法体。
15.7 使用Lambda标准格式:无参无返回
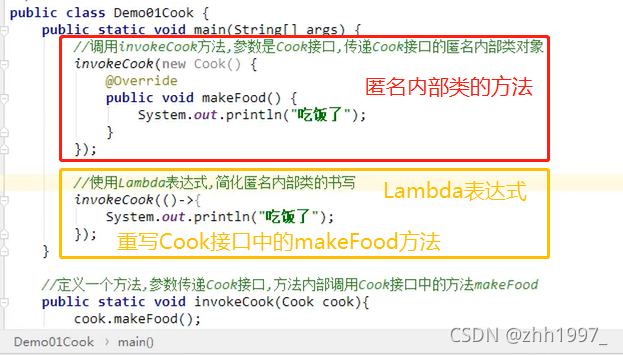
给定一个厨子Cook接口,内含唯一的抽象方法makeFood,且无参数、无返回值,使用Lambda表达式的标准格式调用invokeCook方法,打印输出“吃饭啦!”字样。
定义Cook接口,内含唯一的抽象方法makeFood:

使用Lambda表达式调用invokeCook方法【invokeCook方法的参数是个接口,可以使用匿名内部类->Lambda】:
15.8 使用Lambda标准格式:有参有返回
举例1:
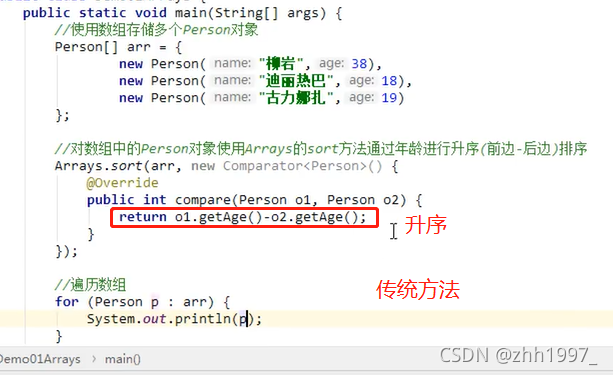
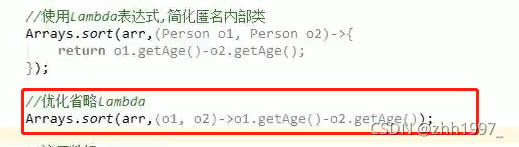
使用数组存储多个Person对象,对数组中的Person对象使用Arrays的sort方法通过年龄进行升序排序。
创建Person类:

使用数组存储多个Person对象:
调用Arrays里面的方法【sort方法的参数是个接口,可以使用匿名内部类->Lambda】:
匿名内部类的方式:
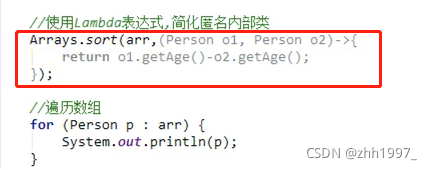
使用Lambda表达式简化匿名内部类:
举例2:
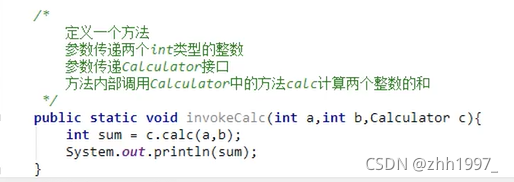
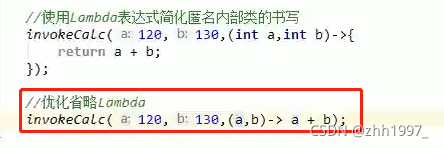
给定一个计算器Calculator接口,内含抽象方法calc可以将两个int数字相加得到和,使用Lambda的标准格式调用invokeCalc方法,完成120和130的相加计算。
定义Calculator接口:

定义方法:
调用【方法的参数是个接口,可以使用匿名内部类->Lambda】:
匿名内部类:
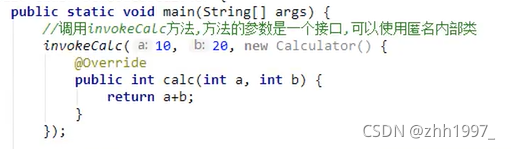
使用Lambda表达式简化匿名内部类:

15.9 Lambda省略格式
Lambda表达式:可推导、可省略。凡是根据上下文推导出来的内容,都可以省略书写。


注意:
要省略 { }、return、分号,必须三个一起省略,不能只省略一个。

省略举例:

二十六、File类
1.概述
Java.io.File类是文件和目录(目录=文件夹)路径名的抽象表示,主要用于文件和目录(文件夹)的创建、查找和删除等操作。
Java把电脑中的文件和文件夹(目录)封装为了一个File类,我们可以使用File类对文件和文件夹进行操作。可以使用File类的方法:创建一个文件/文件夹;删除文件/文件夹;获取文件/文件夹;判断文件/文件夹是否存在;对文件夹进行遍历;获取文件的大小。
注意:
1.File类是一个与系统无关的类,任何的操作系统都可以使用这个类中的方法。
2.记住三个单词:file:文件;directory:文件夹/目录;path:路径。
2. File类的静态成员变量
静态成员变量,直接使用File .变量名调用。
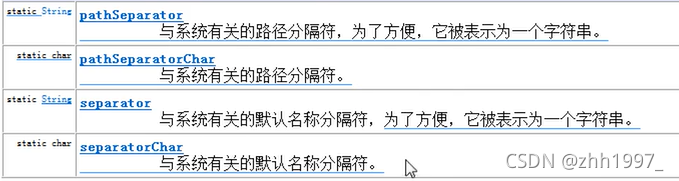
使用:
pathSeparator:与系统有关的路径分隔符


separatorChar:与系统有关的文件名称分隔符

注意:
以后写操作路径不能写死,不能直接写反斜杠或正斜杠,因为使用的操作系统不同格式不一样,可以使用separator方法获取该操作系统的格式:

3.绝对路径和相对路径
概念:
绝对路径:是一个完整的路径。以盘符(C:,D:)开始的路径;
相对路径:是一个简化的路径。相对指的是相对于当前项目的根目录。如果使用当前项目的根目录,路径可以省略项目的根目录。
注意:
- 在Windows中,路径不区分大小写;
- 在Windows中,路径中的文件名称分隔符使用反斜杠,因为反斜杠是转义字符,所以两个反斜杠代表一个普通的反斜杠。
4.构造方法【初始化文件/文件夹的路径】

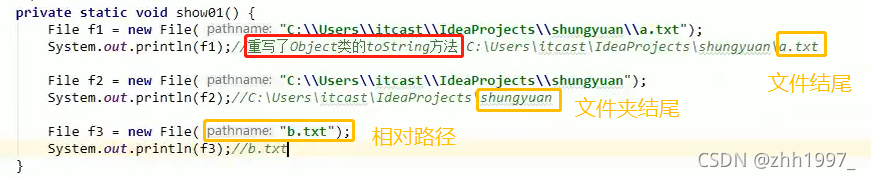
4.1 public File(String pathname)
通过将给定路径名字符串转化为抽象路径来创建新的File实例。
参数:
String pathname:字符串的路径名称;
路径可以是文件结尾,也可以是文件夹结尾;路径可以是相对路径,也可以是绝对路径;路径可以存在,也可以不存在;
创建File对象,只是把字符串路径封装为File对象,不考虑路径的真假情况。
举例:
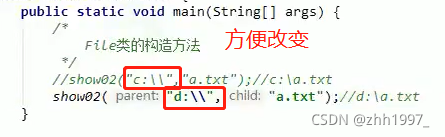
4.2 public File(String parent,String child)
以 父路径名 字符串和子路径名 字符串创建新的FIile实例。
参数:
String parent:父路径;
String child:子路径;
父路径和子路径可以单独书写,使用起来非常灵活,父路径和子路径都可以变化。
举例:
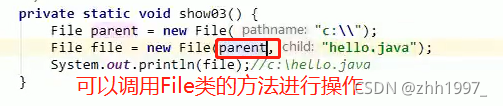
4.3 public File(File parent,String child)
参数:
File parent:父路径;
String child:子路径;
父路径和子路径可以单独书写,使用起来非常灵活,父路径和子路径都可以变化;父路径是File对象,可以使用File的方法对路径进行一些操作,再使用路径创建对象。
举例:
5.常用方法
5.1 获取功能的方法

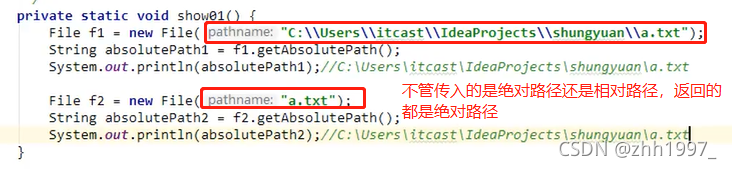
①getAbsolutePath():
获取构造方法传递的路径【File对象】,无论传递的是绝对路径还是相对路径,返回的都是绝对路径。
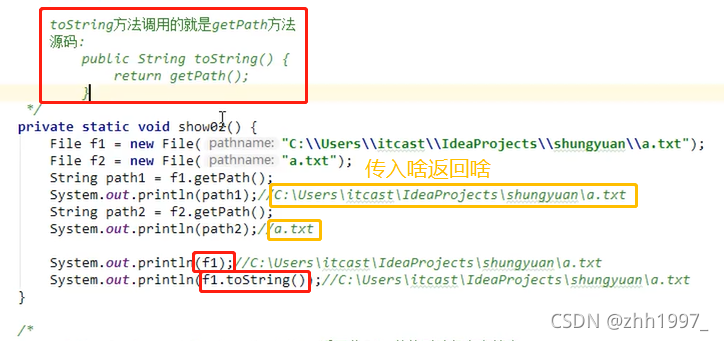
②getPath():
获取构造方法中传递的路径【File对象】,传啥调啥。
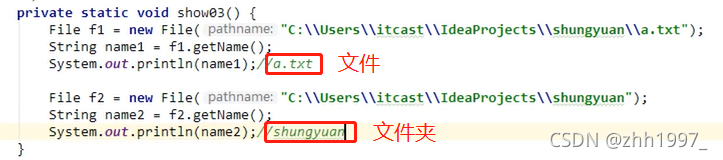
③getName():
获取构造方法的传递路径【File对象】的结尾部分(文件/文件夹),绝对路径、相对路径都可以。
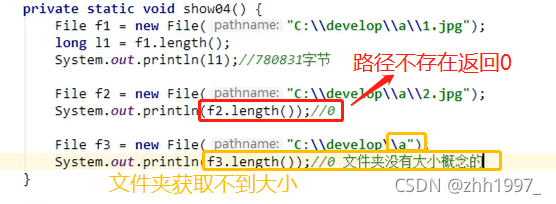
④length():
获取的是构造方法指定的路径【File对象】的文件的大小,以字节为单位。
注意;
- 文件夹没有大小概念,不能获取文件夹的大小;
- 如果构造方法中给出的路径不存在,length方法返回0。
5.2 判断功能的方法

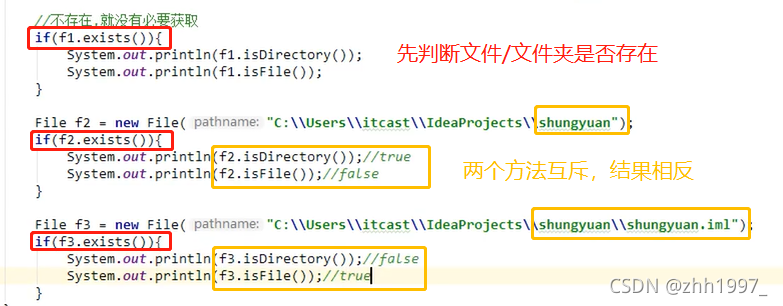
①exists():
用于判断构造方法中的路径【File对象】是否存在。绝对路径、相对路径都可以。存在:true;不存在:false。

②isDirectory()、isFile():
用于判断构造方法中给定的路径【File对象】是否以文件夹/文件结尾。是:true;不是:false。
注意:
电脑硬盘中只有文件/文件夹,两个方法互斥。这两个方法的使用前提:路径必须是存在的,否则都返回false。
5.3 创建删除功能的方法

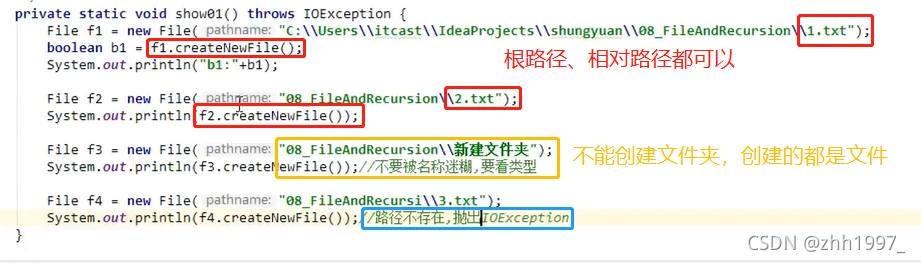
①creatNewFile():
创建文件。创建文件的路径和名称在构造方法中给出【File对象】。绝对路径、相对路径都可以。
返回值:
true:文件不存在,创建成功;
false:文件存在,创建失败。
注意:
- 此方法只能创建文件,不能创建文件夹;
- 创建文件的路径必须存在,负责会抛出异常。
- 此方法声明抛出了IOException异常,调用这个方法就必须处理这个异常,要么throws,要么try…catch。
②mkdir()、mkdirs():
前者只能创建单级空文件夹,后者既可以创建单级空文件夹,也可以创建多级空文件夹。创建文件夹的路径和名称在构造方法中给出(构造方法的参数)。绝对路径、相对路径都可以。
返回值:
true:文件夹不存在,创建成功;
false:文件存在,创建失败;构造方法中给出的路径不存在(mkdir会返回false,mkdirs会创建文件夹并返回true)。
注意:
此方法只能创建文件夹,不能创建文件。
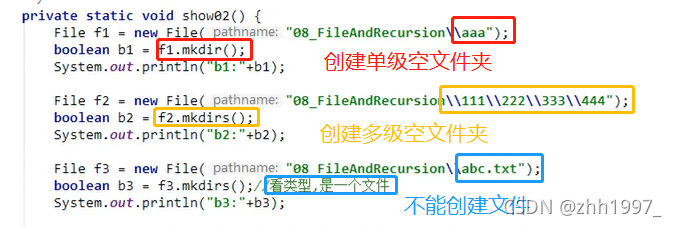
构造方法中给出的路径不存在的情况:mkdir方法会创建失败并返回false;mkdirs方法会创建文件夹并返回true。
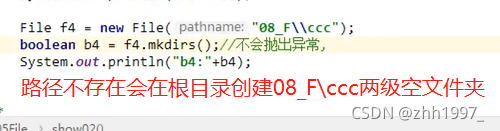
③delete():
删除构造方法给出的路径中的文件/文件夹。
返回值;
true:文件/文件夹删除成功。
false:文件夹中有内容不会删除;构造方法中路径不存在。
注意:
delete方法会直接在硬盘删除文件/文件夹,不走回收站,删除要谨慎。

5.4 目录/文件夹的遍历

注意:
1.list方法和listFiles方法遍历的是构造方法中给出的路径【File对象】的文件夹,如果构造方法中给出的文件夹的路径不存在,会抛出空指针异常;
2.如果构造方法中给出的路径不是一个文件夹,也会抛出空指针异常。
3.隐藏的文件夹或者文件也会被遍历。
①List():
遍历构造方法中给出的路径【File对象】的文件夹,会获取文件夹中所有的文件/文件夹的名称,把获取到的多个名称存储到一个String类型的数组中。

打印的是文件的名称:
②listFiles():
遍历构造方法中给出的路径的文件夹,会获取文件夹中所有的文件/文件夹,把文件/文件夹封装为File对象【文件/文件夹的路径】,多个File对象存储到File数组中。

打印的是文件/文件夹的路径:

6.递归
概述:
使用前提:当调用方法的时候,方法的主体不变,每次调用方法的参数不同,可以使用递归。构造方法禁止递归,会编译报错。

举例1:
栈内存溢出的情况
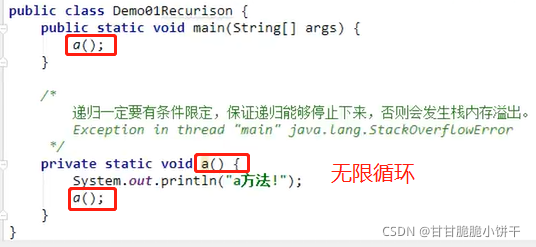 、
、
结果,栈内存溢出:
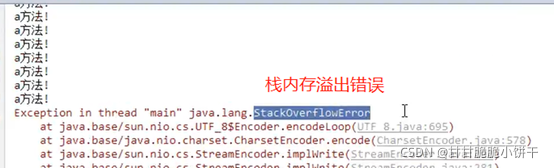
原理:没有new对象,只有栈内存。

a方法会在栈内存中一直调用a方法,导致栈内存中无数个a方法,超出栈内存的大小就会导致内存溢出。
注意:
当一个方法调用其他方法的时候,如果被调用的方法没有执行完毕,当前方法会一直等待调用的方法执行完毕才会继续执行。
举例2:
使用递归计算1~n的和
分析:
使用方法才能递归调用。
已知:最大值:n;最小值:1。使用递归必须明确:1.递归的结束条件:获取到1的时候结束;2.递归的目的:获取下一个被加的数字(n-1)。 1+2+3+…+n=n+(n-1)+(n-2)+(n-3)+…1
实现:
main方法:
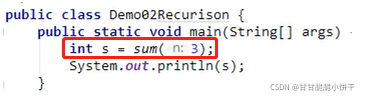
求和的方法【递归调用】,n=1为递归结束条件:

原理:没有new对象,只有栈内存。
main方法调用先压栈执行:

main调用sum方法再入栈执行。比如n=3:

sum(3-1)再次调用sum方法入栈,此时n=2:

sum(2-1)再次调用sum方法入栈,此时n=1:

方法调用完毕后,sum(2-1)方法return1到方法调用处后弹栈;sum(3-1)方法return3到方法调用处后弹栈;sum(4-1)return6到方法调用处后弹栈;main方法调用sum方法处得到6,main方法执行完毕后弹栈。
注意:
使用递归求和,main方法调用sum方法,sum方法会继续调用sum方法,导致内存中有多个sum方法(频繁地创建方法、调用方法、销毁方法),效率低下。
如果仅仅是计算1-n之间的和,不推荐使用递归,使用for循环即可。
举例3:
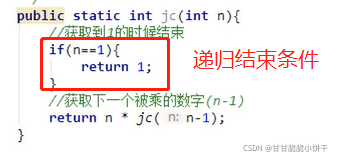
使用递归求阶乘。
分析:
同上例加法阶乘思想相同。n的阶乘:n!= n*(n-1)*(n-2)*…*1
例如计算5的阶乘:
main方法:
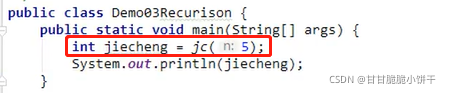
求阶乘的方法【递归调用】,n=1为递归结束条件:
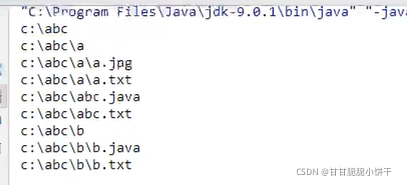
举例4:
递归打印多级目录。
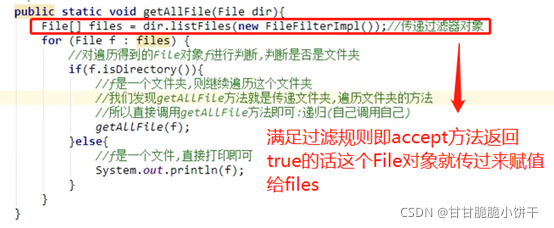
分析:
要使用递归就需要定义方法。参数传递File类型的目录,方法中对目录进行遍历。
需求目录:

普通遍历:
发现只能遍历abc文件夹下的文件夹/文件。遍历不到子文件夹a、b中的内容,遍历不完全。
解决方法:
对遍历得到的File对象f进行判断,判断是否是文件夹。
If(f.isDirectory){
//f是文件夹,继续遍历这个文件夹
//发现getAllFile方法就是传递文件夹,遍历文件夹的方法
//所以直接调用getAllFile方法即可:递归(自己调用自己)
getAllFile(f);
} else {
//是一个文件,直接打印即可
System.out.println(f);
}
使用递归:

7.综合案例:文件搜索
搜索D:\aaa目录中的.java文件。
分析:
- 不同目录遍历方法,无法判断多少级目录,所以使用递归遍历所有目录;
- 遍历目录时,获取的子文件,通过文件名称判断是否符合条件。
实现:上例实现文件夹遍历的代码:

只需要对上例改进即可。即else中如果是文件的话,需要判断是否以 .java结尾,是的话才输出。
如下:

上图中3步调用3个方法可以简化为链式编程:

8.文件过滤器
8.1 FileFilter过滤器
概述:
Java.io.FileFilter:接口,是File的过滤器。用于抽象路径名(File对象)的过滤器。作用:用来过滤文件即File对象。
方法:
FileFilter接口中只有一个方法:accept(File pathname)方法。
boolean accept(File pathname):测试指定抽象路径名是否应该包含在某个路径名列表中。
参数:File pathname:使用ListFiles方法遍历目录得到的每一个文件对象。
8.2 FilenameFilter过滤器
概述:
Java.io. FilenameFilter:接口。用于过滤文件名称。
方法:
FileFilter接口中只有一个方法:accept(File dir,String name)方法。
boolean accept(File dir,String name):测试指定文件是否应该包含在某一文件列表中。
参数:File dir:构造方法中传递的被遍历的目录;String name:使用ListFiles方法遍历目录得到的每一个文件/文件夹名称。
8.3 注意
两个过滤器是没有实现类的,需要自己写实现类,重写过滤的方法accept方法,在方法中自己定义过滤的规则。
8.4 使用
在File类中有两个和ListFiles重载的方法,方法的参数就是两个过滤器:

- ListFiles(FileFilter fileFilter):参数是FileFilter接口;
- ListFiles(FilenameFilter fileFilter):参数是FilenameFilter接口。
8.5 原理
调用ListFiles方法(参数是过滤器),此方法会一共做3件事:
1.ListFiles方法对构造方法中传递的目录进行遍历,获取目录中的每个文件/文件夹的路径->封装为File对象;
2.然后调用过滤器中的accept方法;
3.最后把遍历得到的每个File对象传递给accept方法的参数pathname。
accept方法返回值是一个布尔值,返回true就会把此File对象返回给调用ListFiles方法处的File数组,反之则不传。
8.6 举例
还是上例遍历文件夹的例子。
创建FileFilter接口实现类,重写accept方法的过滤规则【是.java结尾就返回true,反之为false】:

调用ListFiles方法(参数是过滤器):
结果:
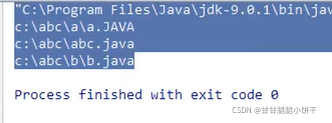
继续优化:
不用创建过滤器的实现类—>使用匿名内部类—>再优化使用Lambda表达式:
使用匿名内部类:
FileFilter过滤器:

FilenameFilter过滤器:

使用Lambda表达式:
FileFilter过滤器:


FilenameFilter过滤器:


二十七、IO
1.IO概述
1.1 什么是IO

电脑上硬盘是永久存储,内存是临时存储,比如正在执行的软件就会存放在内存中,关机后内存中的软件就清空,而硬盘上的东西不会删除。
I:input:输入(读取),把硬盘中的数据,读取到内存中使用;
O:output:输出(写入),把内存中的数据,写入到硬盘中保存;
流:流的是数据(分为字符、字节),1个字符=2个字节,1个字节=8个二进制位。
1.2 IO分类
因为数据分为字符和字节,因此有字符流、字节流:
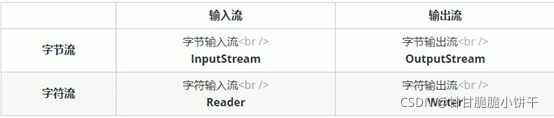
2.字节流
一切皆为字节。计算机只能识别二进制,全部采用二进制存储。因此字节流可以传输任意文件数据。
1个字节=8个bit(二进制位):0000-0000
8bit=1byte或1B;1024B=1KB;1024KB=1MB;1024MB=1GB;1024GB=1TB。.
3.字节输出流【OutputStream】
3.1 概述
java.io.OutputStream:抽象类,字节输出流的所有类的超类。把内存中的数据以字节的形式写入硬盘中。
3.2 写入数据的原理
Java程序->JVM(java虚拟机)->OS(操作系统)->OS调用写数据的方法->把数据写入到文件中
3.3 子类和方法
子类:
重点学习FileOutputStream子类。

方法:
里面定义了一些子类共性的方法,所有的输出字节流都可以使用。重点是学习write方法(一次写一个字节、一次写多个字节)和close方法。

3.4 FileOutputStream类
3.4.1 概述
Java.io.FileOutputStream extends OutputStream:文件字节输出流。作用:把内存中的数据写入到硬盘的文件中。
3.4.2 构造方法

先看两个:
FileOutputStream(String name):创建一个向具有指定路径名name中写入数据的输出文件流;
FileOutputStream(File file):创建一个向指定File对象【路径】表示的文件中写入数据的文件输出流。【有File对象:允许把文件连接输出流之前做进一步分析处理】
参数:写入数据的目的地
String name:写入数据的目的地是一个文件的路径;
File file:写入数据的目的地是File对象指定的路径名处的文件。
作用:
1.会创建一个FileOutputStream对象;
2.会根据构造方法中传递的文件/文件夹路径,创建一个空的文件;
3.会把FileOutputStream对象指向创建好的文件。
3.4.3 使用步骤【重点】
1.创建一个FileOutputStream对象,构造方法中传递写入数据的目的地;
2.调用FileOutputStream类中的方法write,把数据写入到文件中;
3.释放资源(流使用会占用一定内存,使用完毕要把内存清空,提高程序的效率)。
3.4.4 举例(一次写入一个字节)
两个构造方法的使用举例:
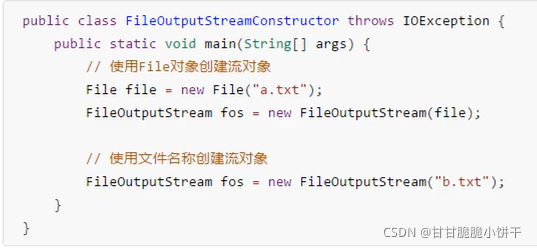
FileOutputStream(String name):指定路径名name和创建的文件名为a.txt。
write(int b):一次写一个字节。
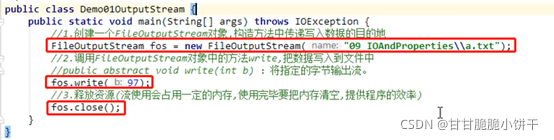
3.4.5 文件存储、记事本打开文件的原理
如上例,创建FileOutputStream对象后,根据构造方法中传递的文件/文件夹路径创建一个空的文件:a.txt,并把FileOutputStream对象指向此文件。
硬盘中存储的都是字节,1个字节=8个二进制/8个比特位(0000 0000)。写数据的时候,会把十进制的数转换为二进制(97->0110 0001)。
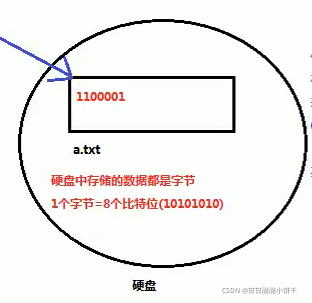
任意的文本编辑器(记事本、notepad++…),在打开文件的时候都会查询编码表,把字节转换为字符表示,方便查看。
转换规则:正整数0-127:查询ASCII表;因此此例中97->a,记事本中打开看到的是a。若为其他值:查询系统默认码表(中文系统->GBK编码表)。即如果写的第一个字节是正数(0-127),文件显示时会查询ASCII表;如果写的第一个字节是负数,那么每两个字节会组成一个中文显示,查询系统默认码表(GBK)。
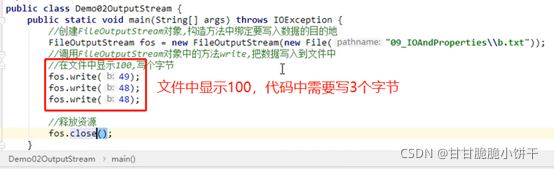
比如要在记事本中要显示100,则代码中需要写3个字节:
3.4.6 一次写多个字节、字节流对象写入字符的方法
1. 一次写多个字节的方法:
①public void write(byte[] b):将b.length字节从指定的字节数组写入输出流;
②public void write(byte[] b,int off,int len):从指定的字节数组写入len(写几个)字节,从偏移量off(哪个字节开始)开始输出到此输出流。
举例:
write(byte[] b):

write(byte[] b,int off,int len):写字节数组的一部分

2. 字节流对象写入字符的方法:
可以使用String类中的方法把字符串转换为字节数组:
Byte[] getBytes():把字符串转换为字节数组。

3.4.7 字节流数据的续写和换行
1.数据的续写
FileOutputStream类的另外两个构造方法:
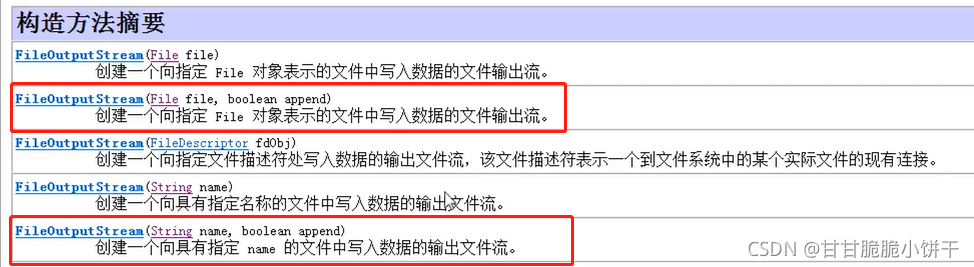
①FileOutputStream(String name,boolean append):创建一个向具有指定路径名name的文件中写入数据的文件输出流;
②FileOutputStream(File file,boolean append):创建一个向指定File对象【路径】表示的文件中写入数据的文件输出流【有File对象:允许把文件连接输出流之前做进一步分析处理】。
参数:
String name、File file:写入数据的目的地路径;
boolean append:追加写开关。true:创建对象不会覆盖源文件,继续在文件内容的末尾追加写数据;false:创建一个新文件覆盖源文件。
举例:
FileOutputStream(String name,boolean append):指定路径名name和创建的文件名为c.txt。

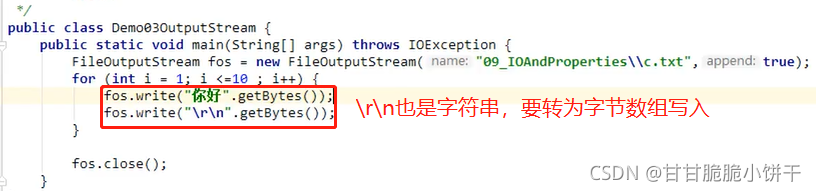
2.换行:写换行符号
Windows:\r\n
Linux:/n;Mac:\r
举例:
4.字节输入流【InputStream】
4.1 概述
java.io.InputStream:抽象类,字节输入流的所有类的超类。把硬盘文件中的数据以字节的形式读取到内存中。
4.2 读取数据的原理
Java程序->JVM(java虚拟机)->OS(操作系统)->OS调用读取数据的方法->读取文件
4.3 子类和方法
子类:
重点学习FileInputStream子类。 
方法:
里面定义了一些子类共性的方法,所有的输入字节流都可以使用。重点学习read方法(一次读取一个字节、一次读取多个字节)、close方法。
注意:read方法返回值为int型,必须使用int型变量接收,读取单个字节时返回的是读到的字节,读取多个字节时返回的是读取到的有效字节的个数。

4.4 FileInputStream类
4.4.1 概述
java.io.FileInputStream extends InputStream:文件字节输入流。作用:把硬盘文件中的数据读取到内存中使用。
4.4.2 构造方法
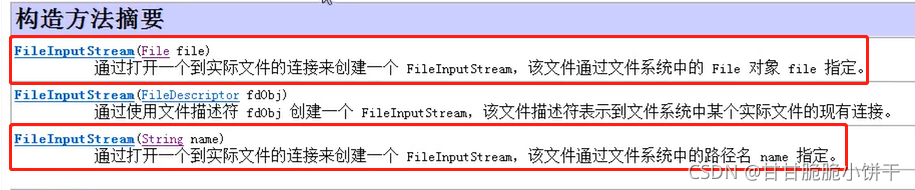
FileInputStream(String name):读取指定路径名name;
FileInputStream(File file):指定File对象【路径】表示的文件中读取数据【有File对象:允许把文件连接输入流之前做进一步分析处理】。
参数:读取文件的数据源
String name:文件的路径
File file:文件
作用:
1.会创建一个FileInputStream对象;
2.会把FileInputStream对象指向构造方法中要读取的文件。
4.4.3 使用步骤【重点】
1.创建一个FileInputStream对象,构造方法中传递要读取的数据源;
2.调用FileInputStream类中的read方法,读取文件;
3.释放资源(流使用会占用一定内存,使用完毕要把内存清空,提高程序的效率)。
4.4.4 举例(一次读取一个字节)
两个构造方法的使用举例:
比如读取a.txt文件:
构造方法:FileInputStream(String name):指定路径名name。
read()方法:一次读取一个字节,返回值必须用int型变量接收。
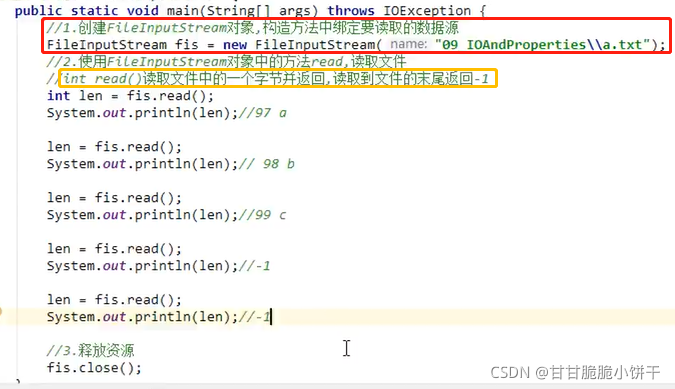
发现读取文件的代码是重复的,因此可以使用循环优化。由于不知道文件中有多少字节,使用while循环,循环结束条件:读取到-1。
注意:
使用read方法读文件时必须使用int型变量接收,否则读出的内容不完全,原因如下。

aaa.txt文件中写的内容:010,对应ASCII码:48 49 48
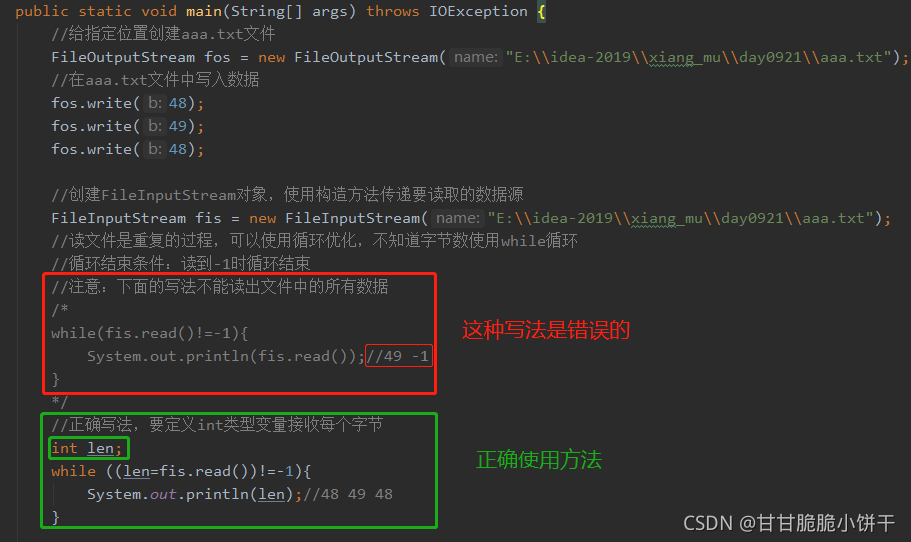
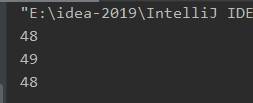
因为是int型,可以直接把字节强转为字符显示:
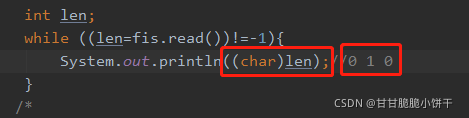
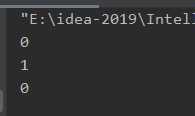
4.4.5 字节输入流一次读取一个字节的原理
read()方法:一次读取一个字节。文件末尾有看不到的结束标记。指针每次读完自动往后移动一位。
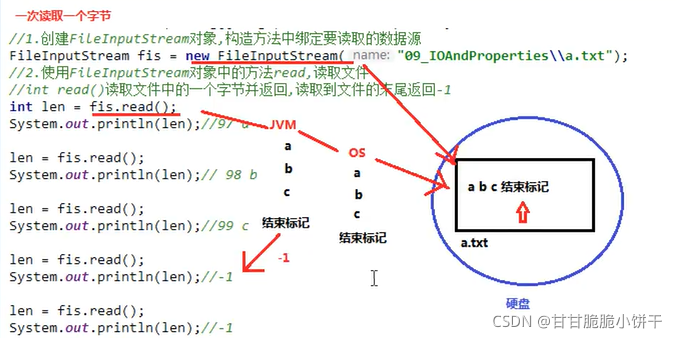
4.4.6 字节输入流一次读取多个字节
1.字节数组转为字符串的方法:
String(byte[] bytes):把字节数组转化为字符串;
String(byte[] bytes,int offset,int length):把字节数组的一部分转换为字符串,offset为开始索引,length为转换的字节个数。
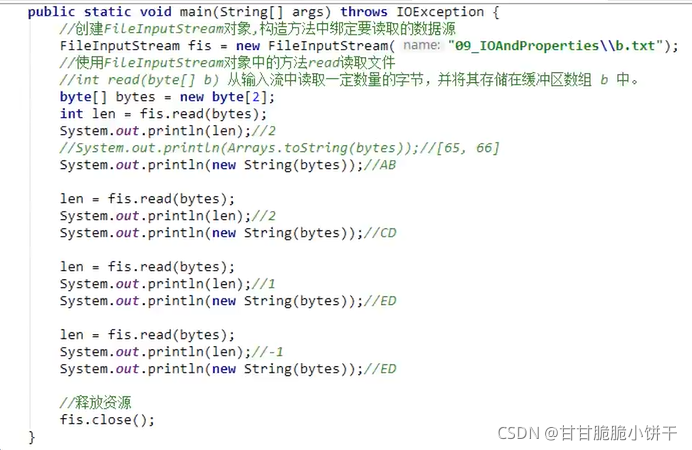
2.一次读取多个字节的方法
int read(byte[ ] b):从输入流中读取一定数量的字节,并将其存储在缓冲区数组b中。
明确两件事:
①.方法的参数 byte[ ] 的作用?
起到缓冲作用,存储每次读取到的多个字节。数组的长度一般定义为1024(1kb)或者1024的整数倍。
②.方法的返回值int是什么?
每次读取的有效字节个数。
举例:
原理:
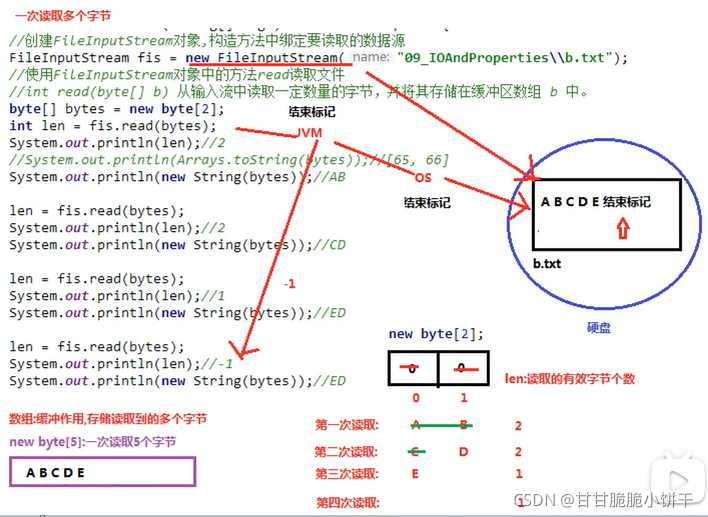
创建的字节数组长度的为2,字节数组初始值为0。
第一次读取指针指向A,读取到A、B,字节数组中内容变为A、B,len为读取的有效字节个数2;
第二次读取指针指向C,读取到C、D,字节数组中内容变为C、D,len为2;
第三次读取指针指向E,E后面没内容了,只读到了了一个,len为1,E覆盖了C,因此打印内容为E、D。
最后指针移动到结束标记,读取不到数据返回-1。
优化:
发现以上读数据部分代码是一个重复的过程,可以使用循环优化。不知道文件中有多少字节,要使用while循环。循环结束的条件:读取到-1结束。

5.字节流练习:图片复制
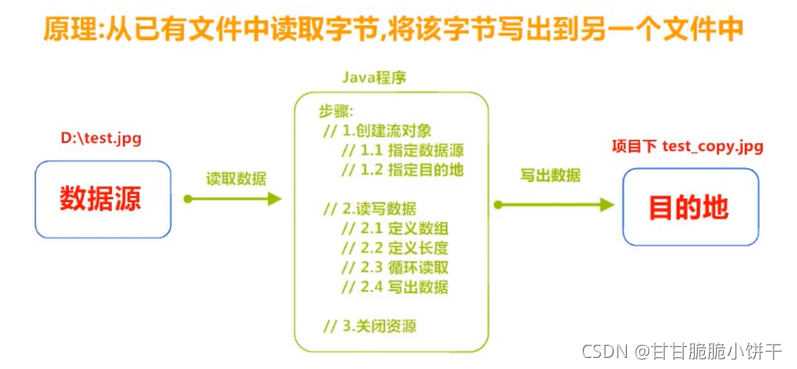

实现:
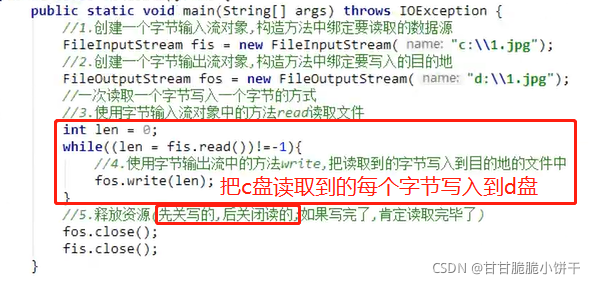
①采用一次读取一个字节、写入一个字节的方式:速度慢。read每次读取一个字节时,len表示读到的字节。
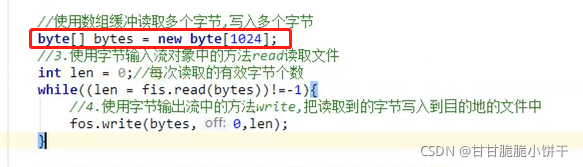
②使用数组缓冲,一次读取多个字节、写入多个字节的方式:速度快。read每次读取多个字节时,len表示读到的有效字节个数。
6.字符流

使用字节流读取中文文件时:GBK编码:1个中文占用2个字节;UTF-8编码:1个中文占用3个字节。因此读取中文字符可能会出现显示不了字符的情况,因为一个字符占多个字节。
7.字符输入流【Reader】
7.1 概述
java.io.Reader:抽象类,字符输入流的所有类的超类。把硬盘中的数据以字符的形式读取到内存中。
7.2 子类和方法
子类:
重点学习InputStreamReader子类的子类FileReader类。 
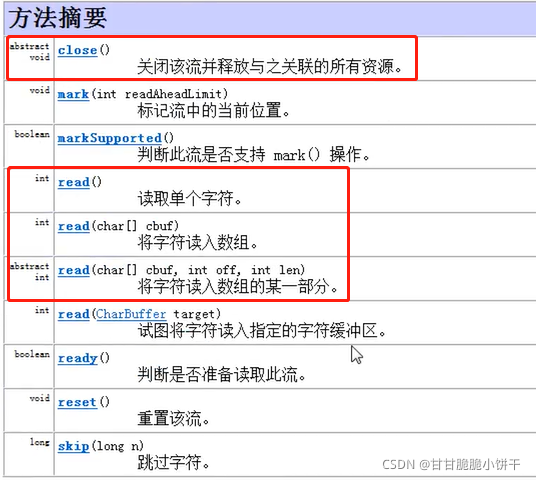
方法:
里面定义了一些子类共性的方法,所有的字符输入流都可以使用。重点是学习read方法(一次读取一个字节、一次读取多个字节)和close方法。
注意:read方法返回值为int型,必须使用int型变量接收,读取单个字节时返回的是读到的字节,读取多个字节时返回的是读取到的有效字节的个数。
7.3 FileReader类
7.3.1 概述
Java.io.FileReader extends InputStreamReader extends Reader:文件字符输入流。作用:把硬盘文件中的数据以字符的方式读取到内存中。
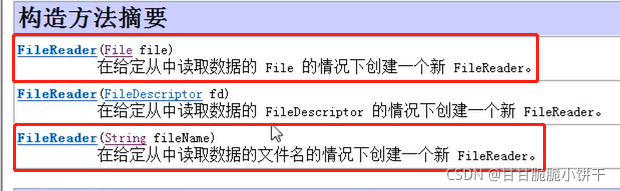
7.3.2 构造方法
参数:读取文件的数据源
String name:文件的路径
File file:文件
作用:
1.会创建一个FileReader对象;
2.会把FileReader对象指向构造方法中要读取的文件。
7.3.3 使用步骤【重点】
1.创建一个FileReader对象,构造方法中传递要读取的数据源;
2.调用FileReader类中的read方法,读取文件;
3.释放资源(流使用会占用一定内存,使用完毕要把内存清空,提高程序的效率)。
7.3.4 举例(一次读取一个字节)
两个构造方法的使用举例:
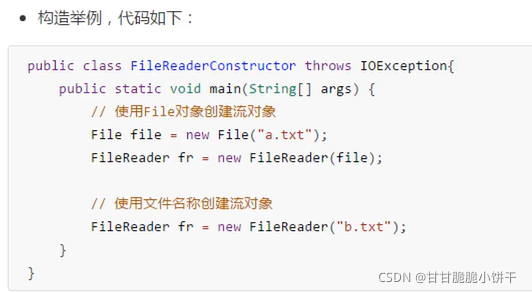
读取c.txt文件:
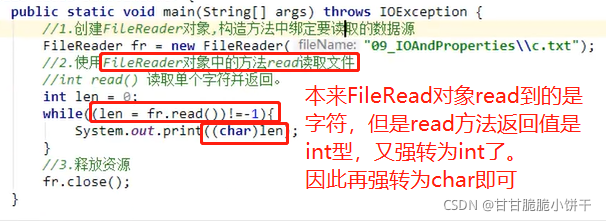
7.3.5 字符输入流一次读取多个字节
1.字符数组转为字符串的方法:
String(char[ ] value):把字符数组转化为字符串;
String(char[ ] value,int offset,int length):把字符数组的一部分转换为字符串,offset为开始索引,length为转换的字节个数。
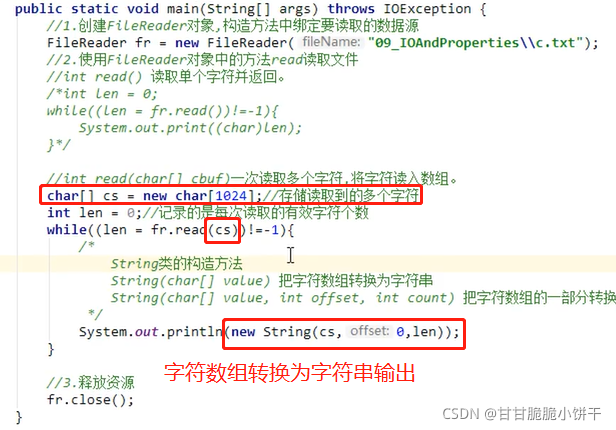
2.一次读取多个字符的方法:
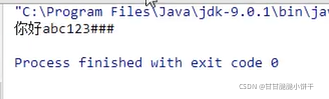
int read(char[ ] cbuf):从输入流中读取多个字符,将字符读入数组。
举例:
8.字符输出流【Writer】
8.1 概述
java.io.Writer:抽象类,字符输出流的所有类的超类。把内存中的数据以字符的形式写入硬盘中。
8.2 子类和方法
子类:
重点学习OutputStreamWriter子类的子类FileWriter类。 
方法:
里面定义了一些子类共性的方法,所有的输出字符流都可以使用。重点是学习write方法(一次写一个字符、一次写多个字符、写入字符串)和close方法。

8.3 FileWriter类
8.3.1 概述
Java.io.FileWriter extends OutputStreamWriter extends Writer:文件字符输出流。作用:把内存中的字符写入到硬盘的文件中。
8.3.2 构造方法

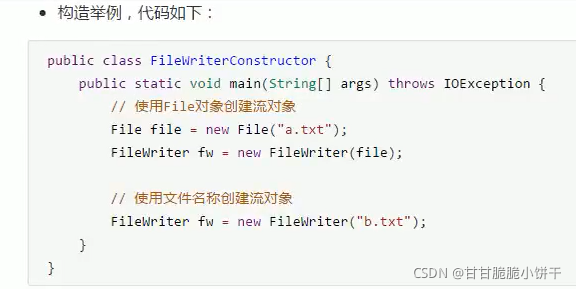
先看其中两个:
FileWriter(File file):根据给定的File对象构造一个FileWriter对象。
FileWriter(String fileName):根据给定的文件名构造一个对象。
参数:写入数据的目的地
String name:文件的路径;
File file:File对象指定的路径名处的文件。
作用:
1.会创建一个FileWriter对象;
2.会根据构造方法中传递的文件/文件夹路径,创建一个空的文件;
3.会把FileWriter对象指向创建好的文件。
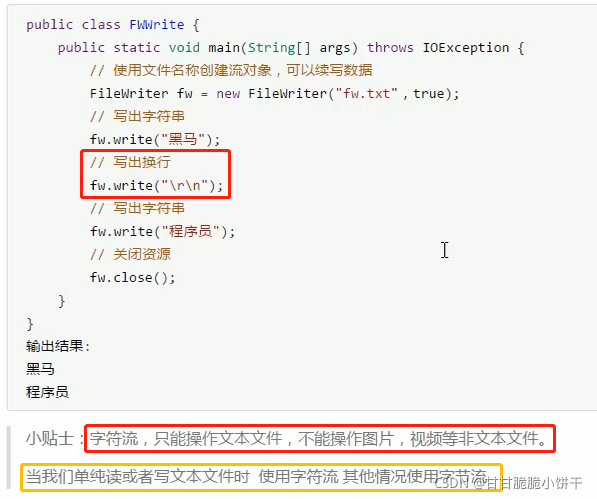
8.3.3 使用步骤【重点,与字节输出流不同】
1.创建一个FileWriter对象,构造方法中传递写入数据的目的地;
2.调用FileWriter类中的方法write,把数据先写入到内存缓冲区【计算机只能存储字节,因此有字符转换为字节的过程】;
3.使用FileWriter的flush方法,把内存缓冲区中的数据刷新到文件中;
3.释放资源【会把内存缓冲区中的数据刷新到文件中】,因此第三步可以不用写。
8.3.4 举例(一次写入一个字符)
两个构造方法的使用举例:
往d.txt中写字符:
若不调用flush方法或者close方法,数据不会由内存中写入到硬盘中。

8.3.5 关闭(close)和刷新(flush)
区别:
flush:刷新缓冲区,流对象可以继续使用;
close:先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用。

举例:

8.3.6 一次写多个字符、写入字符串的方法
1. 一次写多个字符的方法:
①public void write(char[ ] cbuf):写入字符数组
②public void write(char[ ] b,int off,int len):写入字符数组的一部分,off数组的开始索引,len写的字符个数。
2. 写入字符串的方法:
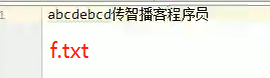
void write(String str):写入字符串
void write(String str,int off,int len):写入字符串的一部分,off字符串的开始索引,len写的字符个数。
举例:给f.txt中写字符

8.3.7 字符流数据的续写和换行
1.数据的续写
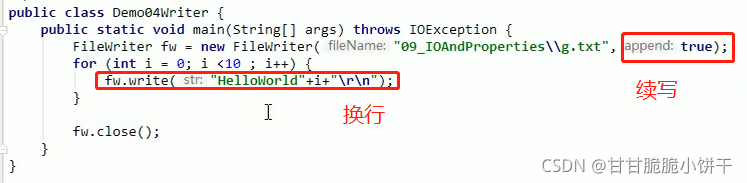
FileWriter类的另外两个构造方法:

FileWriter(File file,boolean append):根据给定的File对象构造一个FileWriter对象。
FileWriter(String fileName,boolean append):根据给定的文件名构造一个对象。
参数:
String filename、File file:写入数据的目的地路径;
boolean append:追加写开关。true:创建对象不会覆盖源文件,继续在文件内容的末尾追加写数据;false:创建一个新文件覆盖源文件。
举例:给g.txt写字符
2.换行:写换行符号
Windows:\r\n
Linux:/n;Mac:\r
举例:
9.IO异常的处理
之前的入门练习,我们一直把异常抛出。而实际开发中并不能这样处理,建议使用try…catch…finally代码块处理异常部分。
1.在JDK1.7之前:
使用try…catch…finally代码块处理流中的异常。
格式:
try{
可能会产生异常的代码
}catch(异常类变量 变量名){
异常的处理逻辑
}finally{
一定会执行的代码。如资源释放
}
举例:

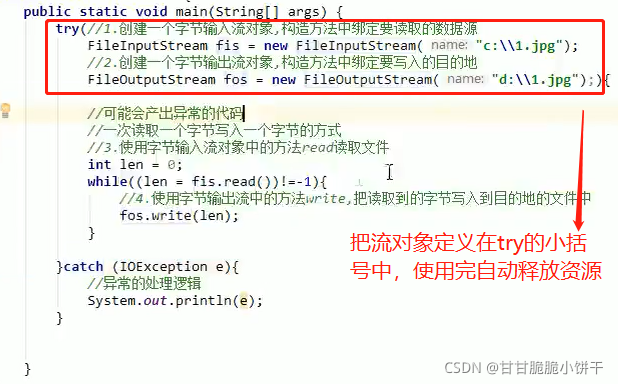
2.JDK7的新特性:
在try后面可以增加一个(),在括号中可以定义流对象。那么这个流对象的作用域就在try中有效,try中的代码执行完毕,会自动把流对象释放,不用写finally。
格式:
try(定义流对象;定义流对象…){
可能会产生异常的代码
}catch(异常类变量 变量名){
异常的处理逻辑
}
举例:
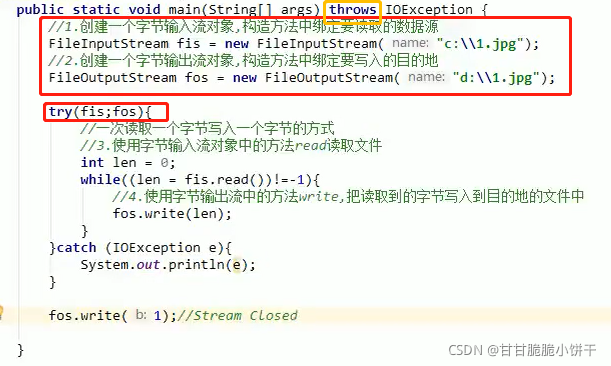
3.JDK9的新特性:
try的前面可以定义流对象,在try后面的()中可以直接引用流对象的名称(变量名)使用。在try代码执行完毕后,流对象自动释放,不用写finally。
格式:
A a=new A();
B b=new B();
try(a;b){
可能会产生异常的代码
}catch(异常类变量 变量名){
异常的处理逻辑
}
举例:比JDK7麻烦【额。。。】,既要try...catch,又要throws
二十八、属性集Properties
1.概述
Java.util.Properties extends Hashtable <k,v> implements Map <k,v> 类:
表示一个持久的属性集,可保存在流中或者从流中加载。Properties集合是唯一一个和IO流相结合的集合。

2.方法
2.1 操作字符串的方法
Properties集合是一个双列集合,属性列表中的每个键及其对应值都是一个字符串。key和value默认是字符串。因此有一些操作字符串的方法:
Object setProperty(String key,String value):调用Hashtable的put方法;
String getProperty(String key):通过key找到value值。相当于Map集合中的get(key)方法;
Set<String> stringPropertyNames():返回此属性列表中的键值,其中该键及其对应值是字符串。相当于Map集合中的keySet方法。
举例:
注意使用setProperty方法往集合添加数据时必须都是字符串,比如168记得带双引号。

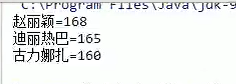
2.2 store方法
可以使用Properties集合中的方法store,把集合中的临时数据持久化写入到硬盘中存储。
1.void store(OutputStream out,String comments)
2.void store(Writer writer,String comments)
参数:
OutputStream out:字节输出流,不能写入中文。
Writer writer:字符输出流,可以写中文。
String comments:注释,用来解释说明保存的文档是做什么用的。不能使用中文,否则会乱码,默认是Unicode编码,一般使用“”空字符串。
使用步骤:
1.创建Properties集合对象,添加数据;
2.创建字节输出流/字符输出流对象,构造方法中绑定要输出的目的地;
3.使用Propertise集合中的方法store,把集合中的临时数据持久化写入到硬盘中存储;
4.释放资源。
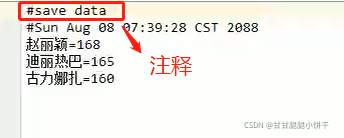
举例: 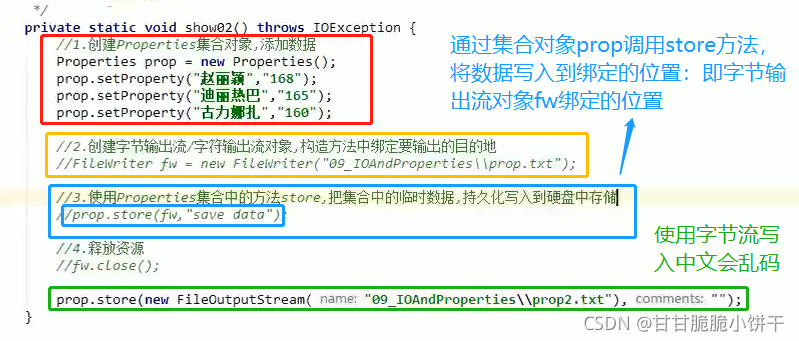
字符流存储结果:
第一行输出为store方法中写的注释。
字节流存储结果,写入的中文,导致乱码:
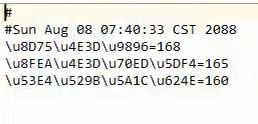
2.3 load方法【重点】
可以使用Properties集合中的方法load,把硬盘中保存的文件(键值对),读取到集合中使用。
1.void load(InputStream inStream)
2.void load(Reader reader)
参数:
InputStream inStream:字节输入流,不能读取含有中文的键值对。
Reader reader:字符输入流,能读取含有中文的键值对。
使用步骤:
1.创建Properties集合对象;
2.使用Properties集合对象中的方法load读取保存键值对的文件;
3.遍历Properties集合。
注意事项:
1.存储键值对的文件中,键与值默认的连接符号可以使用=、空格等符号;
2.存储键值对的文件中,可以使用#进行注释,被注释的键值对不会再被读取;
3.存储键值对的文件中,键与值默认都是字符串,不用再加引号。
举例:
注:字节输入流读中文会乱码。 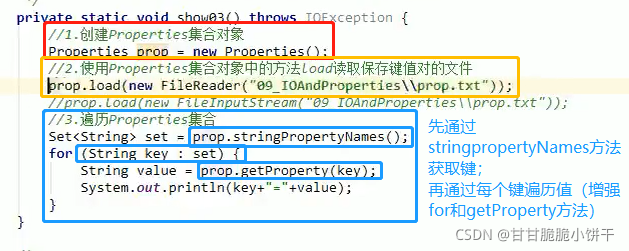
二十九、缓冲流
使用基本的字节输入流读取文件的缺点:慢,效率低。如下图:


使用字节缓冲输入流:提高效率。如下图:


1.概述

缓冲流,也叫高效流。是对4个基本字节缓冲流FileXxx流的增强,所以也是4个流,按照数据类型分类:
字节缓冲流:BufferedInputStream,BufferedOutputStream
字符缓冲流:BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
2.字节缓冲输出流:BufferedOutputStream
2.1 概述
java.io. BufferedOutputStream extends OutputStream:字节缓冲输出流。
继承了父类,可以使用OutputStream类的共性成员方法:如write、flush、close方法等。
2.2 构造方法
BufferedOutputStream(OutputStream out):创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
BufferedOutputStream(OutputStream out,int size):创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。
参数:
OutputStream out:字节输出流。可以传递FileOutputStream,缓冲流会给FileOutputStream增加一个缓冲区,提高FileOutputStream的写入效率。
int size:指定缓冲流内部缓冲区的大小,不指定就使用默认。
使用步骤【重点】
1.创建字节输出流【比如FileOutputStream对象】,构造方法中绑定要输出的目的地;
2.创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象,提高FileOutputStream对象的写入效率;
3.使用BufferedOutputStream中的write方法,把数据写入到内部缓冲区中;
4.使用BufferedOutputStream中的flush方法,把内部缓冲区中的数据刷新到文件中;
5.释放资源【会先调用flush方法刷新数据,因此第4步可以省略】。
举例
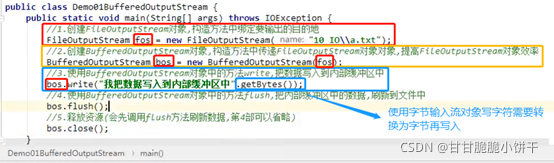
a.txt:

3.字节缓冲输入流:BufferedInputStream
3.1 概述
java.io. BufferedInputStream extends InputStream:字节缓冲输入流。
继承了父类,可以使用InputStream类的共性成员方法:如read、close方法等。
3.2 构造方法
BufferedInputStream(InputStream in):创建一个BufferedInputStream并保存其参数,即输入流in,以便将来使用。
BufferedInputStream(InputStream in,int size):创建具有指定缓冲区大小的BufferedInputStream并保存其参数,即输入流in,以便将来使用。
参数:
InputStream in:字节输出流。可以传递FileInputStream,缓冲流会给FileInputStream增加一个缓冲区,提高FileInputStream的读取效率。
int size:指定缓冲流内部缓冲区的大小,不指定就使用默认。
3.3 使用步骤【重点】
1.创建字节输出流【比如FileInputStream对象】,构造方法中绑定要读取的数据源;
2.创建BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStream对象的读取效率;
3.使用BufferedInputStream中的read方法,读取文件;
4.释放资源。
3.4 举例
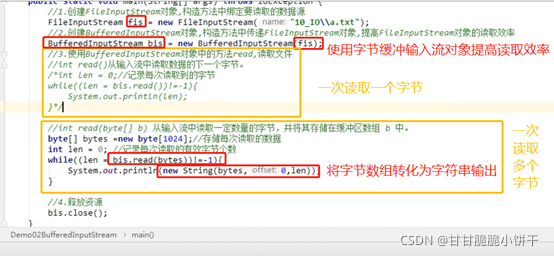
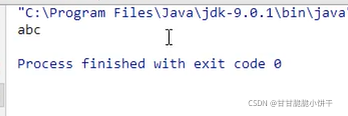
4.效率测试:复制文件
之前使用普通的字节输入、输出流复制图片:
一次读写一个字节:耗时6043秒;
使用数组缓冲,一次读取多个字节:耗时10毫秒。
使用缓冲流复制文件:

一次读写一个字节:耗时32毫秒。
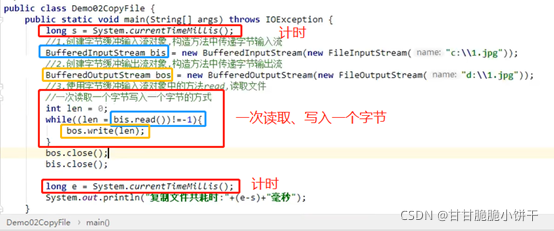
再使用数组缓冲,一次读取多个字节:耗时5毫秒。
5.字符缓冲输出流:BufferedWriter
5.1 概述
java.io. BufferedWriter extends Writer:字符缓冲输出流。
继承了父类,可以使用Writer类的共性成员方法:如write、flush、close方法等。
5.2 构造方法
BufferedWriter(Writer out):创建一个使用默认大小输出缓冲区的缓冲字符输出流;
BufferedWriter(Writer out,int sz):创建一个使用给定大小输出缓冲区的新缓冲字符输出流。
参数:
Writer out:字符输出流。可以传递FileWriter,缓冲流会给FileWriter增加一个缓冲区,提高FileWriter的写入效率。
int sz:指定缓冲流内部缓冲区的大小,不指定就使用默认。
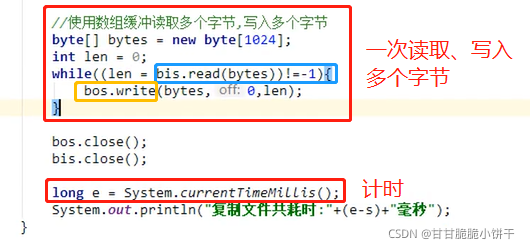
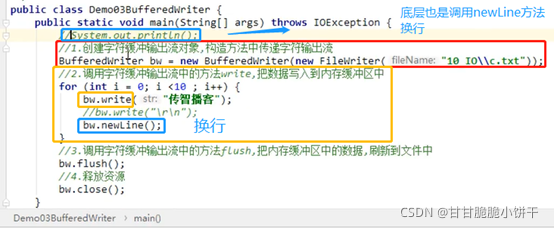
5.2.1 BufferedWriter特有的成员方法:
void newLine():写入一个行分隔符。会根据不同的操作系统获取不同的行分隔符。
5.3 使用步骤【重点】
1.创建BufferedWriter对象,构造方法中传递字符输出流【比如FileWriter对象】,提高FileWriter对象的写入效率;
2.使用BufferedWriter中的write方法(换行:newLine方法),把数据写入到内部缓冲区中;
3.使用BufferedWriter中的flush方法,把内部缓冲区中的数据刷新到文件中;
4.释放资源【会先调用flush方法刷新数据,因此第4步可以省略】。
5.4 举例
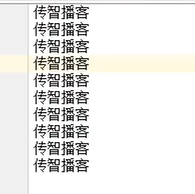
6.字符缓冲输入流:BufferedReader
6.1 概述
java.io.BufferedReader extends Reader:字符缓冲输入流。
继承了父类,可以使用Reader类的共性成员方法:如read、close方法等。
6.2 构造方法
BufferedReader(Reader in):创建一个使用默认大小输入缓冲区的缓冲字符输入流。
BufferedReader(Reader in,int sz):创建一个使用指定大小输入缓冲区的缓冲字符输入流。
参数:
Reader in:字符输入流。可以传递FileReader,缓冲流会给FileReader增加一个缓冲区,提高FileReader的读取效率。
int sz:指定缓冲流内部缓冲区的大小,不指定就使用默认。
6.2.1 BufferedReader特有的成员方法:
String readLine():读取一个文本行。读取一行数据。
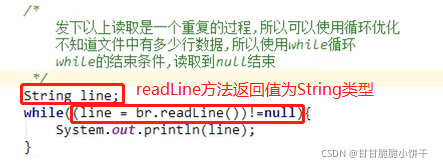
行的终止符号:通过下列字符之一即可认为某行已终止:换行(’\n’)、回车(’\r’)或回车后直接跟着换行(’\r\n’)。
返回值:包含该行内容的字符串,不包含任何行终止符,如果已经到达流末尾,则返回null。
6.3 使用步骤【重点】
1.创建BufferedReader对象,构造方法中传递字符输入流【比如FileReader对象】,提高FileReader对象的读取效率;
2.使用BufferedReader中的read方法/readLine方法,读取文本;
3.释放资源。
6.4 举例
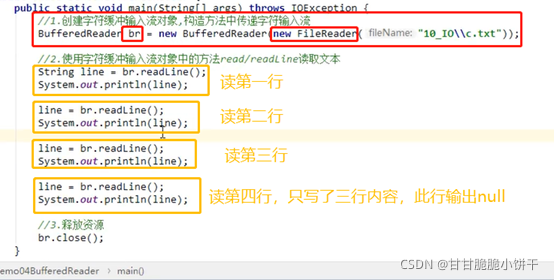
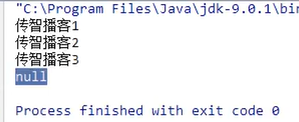
发现以上读取是一个重复的过程,可以使用循环优化。不知道文本中一共有多少行数据,使用while循环,while循环结束条件:读取到null结束。
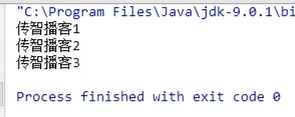
7.练习:文本排序

 实现:
实现:
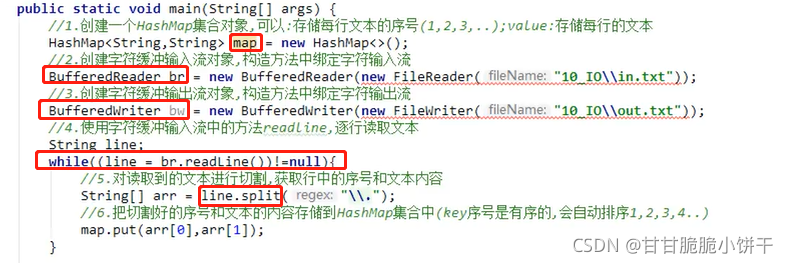
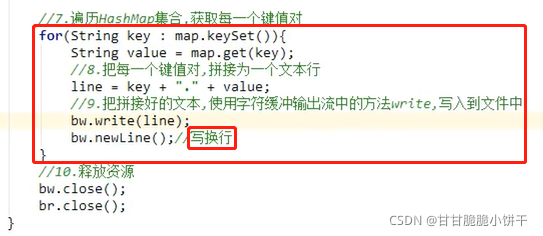
结果:

三十、转换流
1.字符编码和字符集
1.1 字符编码
编码:
字符->字节(按照某种规则将字符存储在计算机中)。
解码:
字节->字符(将计算机中的二进制数按照某种规则解析出来)。
按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。否则,按照A规则存储,再按照B规则解析,就会出现乱码的现象。
字符编码(Character Encoding):
就是一套自然语言的字符与二进制数之间的对应规则。

1.2 字符集
字符集(Charset):
也叫编码表,是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码。一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。
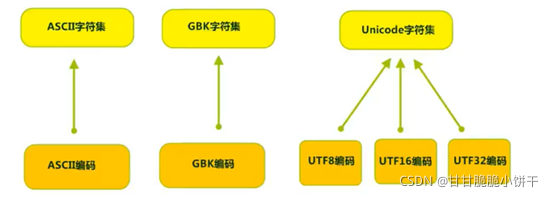
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。



2.编码引出的问题
例如使用FileReader可以读取IDEA默认编码格式为UTF-8的文件,但FileReader读取系统默认编码(中文GBK)会产生乱码。

3.转换流的原理
使用FileReader读GBK会乱码:

使用InputStreamReader读GBK可以指定编码:

同样,使用OutputStreamWriter写GBK可以指定编码:

总结:OutputStreamWriter类、InputStreamReader类【转换流】可以指定编码,FileReader底层是使用FileOutputStream实现的,只能使用IDE默认编码。
4.OutputStreamWriter类
4.1 概述
java.io. OutputStreamWriter extends Writer类,是字符流通向字节流的桥梁:可使用指定的charset将要写入流中的字符编码成字节。
继承了父类,可以使用Writer类的共性成员方法:如write、flush、close方法等。
4.2 构造方法
OutputStreamWriter(OutputStream out):创建使用默认字符编码的OutputStreamWriter。
OutputStreamWriter(OutputStream out,String charsetName):创建使用指定字符集的OutputStreamWriter。
参数:
OutputStream out:字节输出流,可以用来写转换之后的字节到文件中。
String charsetName:指定的编码表名称,不区分大小写。可以是utf-8/UTF-8,gbk/GBK...不指定就使用默认的UTF-8。
4.3 使用步骤【重点】
1.创建OutputStreamWriter对象,构造方法中传递字节输出流【比如FileOutputStream对象】和指定的编码表名称;
2.使用OutputStreamWriter中的write方法,把字符转换为字节存储在缓冲区中(编码的过程);
3. 使用OutputStreamWriter中的flush方法,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程);
4.释放资源
4.4 举例
1.使用转换流OutputStreamWriter写UTF-8格式的文件:
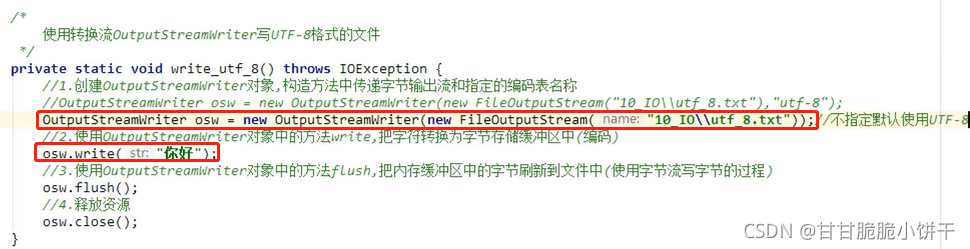
2.使用转换流OutputStreamWriter写GBK格式的文件:

5.InputStreamReader类
5.1 概述
java.io.InputStreamReader extends Reader类,是字节流通向字符流的桥梁:可使用指定的charset读取字节并将其解码为字符。
继承了父类,可以使用Reader类的共性成员方法:如read、close方法等。
5.2 构造方法
InputStreamReader(InputStream in):创建使用默认字符编码的InputStreamReader。
InputStreamReader(InputStream in,String charsetName):创建使用指定字符集的InputStreamReader。
参数:
InputStream in:字节输入流,用来读取文件中保存的字节。
String charsetName:指定的编码表名称,不区分大小写。可以是utf-8/UTF-8,gbk/GBK,…不指定就使用默认的UTF-8。
5.3 使用步骤【重点】
1.创建InputStreamReader对象,构造方法中传递字节输入流【比如FileInputStream对象】和指定的编码表名称;
2.使用InputStreamReader中的read方法,读取文件【解码】;
3.释放资源
注意事项:
构造方法中指定的编码表名称要和文件的编码相同,否则会发生乱码。
5.4 举例
1.使用转换流InputStreamReader读取UTF-8格式的文件

2.使用转换流InputStreamReader读取GBK格式的文件:

6.练习:转换文件编码


实现:
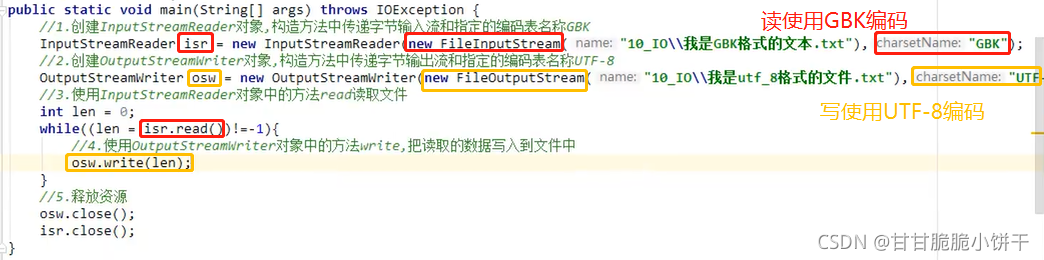
三十一、序列化流和反序列化流
1.概述
把对象以流的方式写入到文件中保存,叫写对象,也叫对象的序列化。因为对象中保存的不仅仅是字符,因此要使用字节流->ObjectOutputStream:对象的序列化流。
把文件中保存的对象,以流的方式读取出来,叫读对象,也叫对象的反序列化。因为读取的文件中保存的都是字节吗,所以要使用字节流->ObjectInputStream:对象的反序列化流。
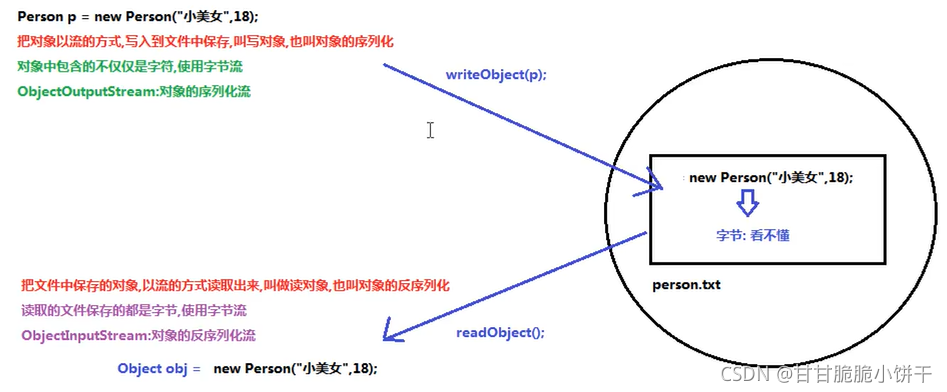
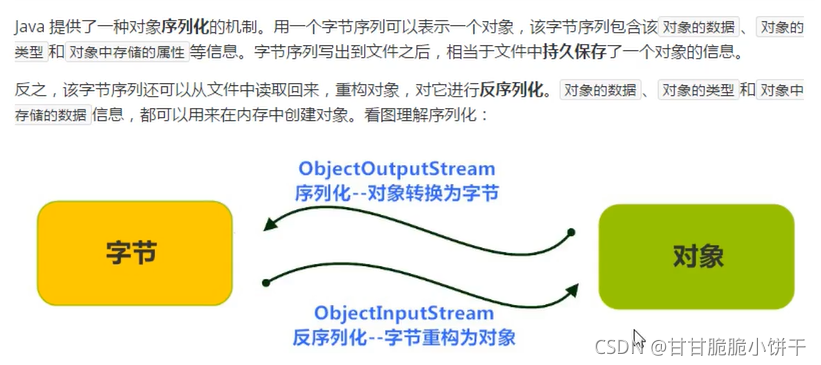
2.ObjectOutputStream类
2.1 概述
java.io. ObjectOutputStream extends OutputStream:对象的序列化流。作用:把对象以流的方式写入到文件中保存。
继承了父类,可以使用OutputStream类的共性成员方法:如write、flush、close方法等。
2.2 构造方法
ObjectOutputStream(OutputStream out):创建写入指定OutputStream的ObjectOutputStream。
参数:
OutputStream out:字节输出流
2.2.1 ObjectOutputStream特有的成员方法:
void writeObject(Object obj):将指定的对象写入ObjectOutputStream。
2.3 使用步骤【重点】
1.创建ObjectOutputStream对象,构造方法中传递字节输出流【比如FileOutputStream对象】;
2.使用ObjectOutputStream中的writeObject方法,把对象写入到文件中;
3.释放资源
2.4 序列化和反序列化使用前提
序列化和反序列化的时候,存在NotSerializableException没有序列化异常。
解决办法:
一个类必须实现java.io. Serializable接口来启动其序列化功能。未实现此接口的类无法使用其任何状态序列化或者反序列化。
Serializable接口也叫标记型接口。要进行序列化和反序列化的类必须实现Serializable接口,就会给此类添加一个标记,当我们进行序列化和反序列化的时候,就会检查此类上是否有这个标记:
有:可以进行序列化和反序列化;
没有:抛出NotSerializableException没有序列化异常。
生活中的例子:去市场卖肉->肉上的蓝色章(检测合格)->放心购买->买回来怎么吃随意。
2.5 举例
Person类:
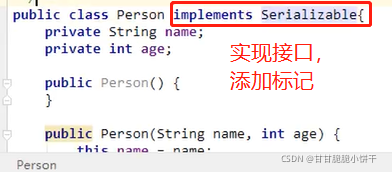
序列化:
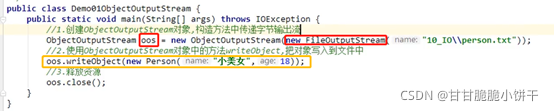
结果:因为计算机是二进制存储,无法直接打开查看,需要进行反序列化查看。

3.ObjectInputStream类
3.1 概述
java.io.ObjectInputStream extends InputStream:对象的反序列化流。作用:把文件中保存的对象,以流的方式读取出来使用。
继承了父类,可以使用InputStream类的共性成员方法:如read、close方法等。
3.2 构造方法
ObjectInputStream(InputStream in):创建从指定InputStream读取的ObjectInputStream。
参数:
InputStream in:字节输入流。
3.2.1 ObjectInputStream特有的成员方法:
void readObject():从ObjectInputStream读取对象。
3.3 使用步骤【重点】
1.创建ObjectInputStream对象,构造方法中传递字节输入流【比如FileInputStream对象】;
2.使用ObjectInputStream中的readObject方法,读取保存对象的文件;
3.释放资源;
4.使用读取出来的对象(打印)。
3.4 反序列化的使用前提
反序列化的时候,存在ClassNotFoundException(class文件找不到异常)。当不存在对象的class文件时会抛出此异常。因此反序列化的使用前提:
3.5 举例
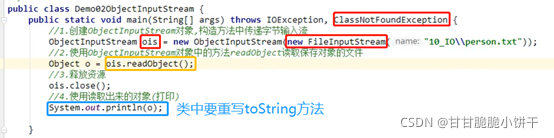
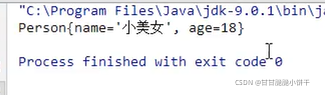
将结果强转为Person类型可以更好使用:
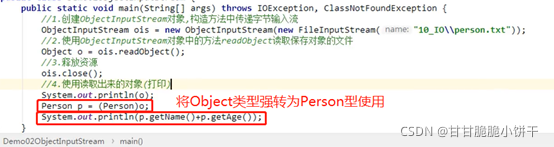

4.transient关键字
static关键字:静态关键字。
静态优先于非静态加载到内存中(静态优先于对象进入到内存中),被static修饰的成员变量不能被序列化的,序列化的都是对象。静态不属于对象,属于类,被所有对象共享。
比如上例中Person类中的成员变量age用static修饰后,反序列化读出来的age为默认值0。
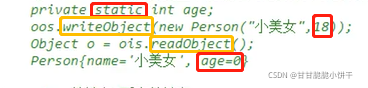
transient:瞬态关键字。用于反序列化操作。
相似的,被transient关键字修饰的成员变量,不能被序列化。如果希望成员变量不被序列化就使用transient关键字。

5.InvalidClassException异常
5.1 概述
当JVM反序列化对象时,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个ClassNotFoundException异常。
当JVM反序列化对象时,如果能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作会失败,抛出一个InvalidClassException异常。发生这个异常的原因如下:

5.2 原理
序列化时,编译器(java.exe)会把Person.java文件编译生成Person.class文件。因为Person类实现了Serializable接口,就会根据类的定义给Person.class文件添加一个序列号。

反序列化时,会使用Person.class文件中的序列号和Person.txt文件中的序列号进行比较。一样:反序列化成功;不一样:抛出序列化冲突异常:InvalidClassException。

如果序列化之后修改了类的定义,那么就会给Person.class文件重新编译生成一个新的序列号。此时直接反序列化就会抛出InvalidClassException异常。
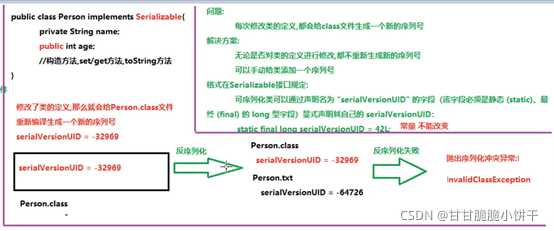
5.3 解决方案
问题:
每次修改类的定义,就会给class文件生成一个新的序列号。
解决方案:
无论是否对类的定义进行修改,都不重新生成新的序列号,可以手动给类添加一个序列号。
格式:
Serializable接口中规定了格式:可序列化类可以通过声明为“serialVersionUID”的字段(该字段必须是静态(static)、最终的(final)long型字段)显式声明自己的serialVersionUID。
如:
static final long serialVersionUID=42L;(常量,不可改变)
6.练习:序列化集合
当我们想要在文件中保存多个对象的时候,可以把多个对象存储在一个集合中,对集合进行序列化和反序列化。
分析:

实现:
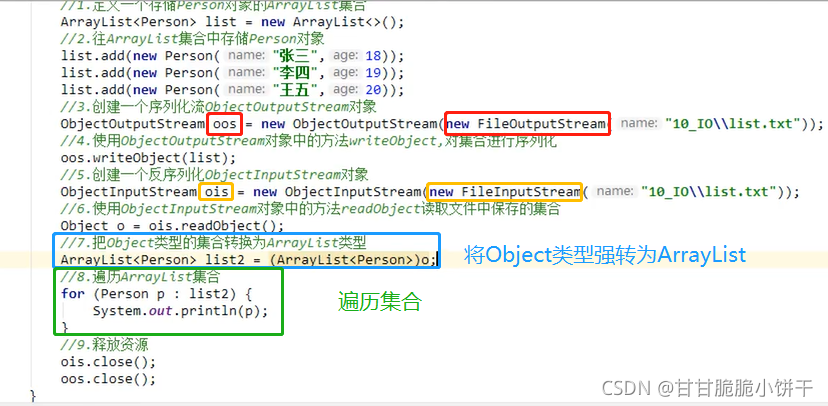
结果:
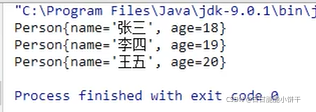
三十二、打印流
1.概述
java.io.PrintStream extends OutputStream:打印流。为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
继承了父类,可以使用OutputStream类的共性成员方法:如write、flush、close方法等。
2.特点及注意事项:
特点:
1.只负责数据的输出,不负责数据的读取;
2.与其他输出流不同,PrintStream永远不会抛出IOException。
注意事项:
1.如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表:97->a;
2.如果使用自己特有的print / println方法写数据,写的数据会原样输出:97->97。
3. PrintStream特有的方法:
4.构造方法:
PrintStream(File file):输出的目的地是一个文件。
PrintStream(OutputStream out):输出的目的地是一个字节输出流。
PrintStream(String fileName):输出的目的地是一个文件路径。
5.举例
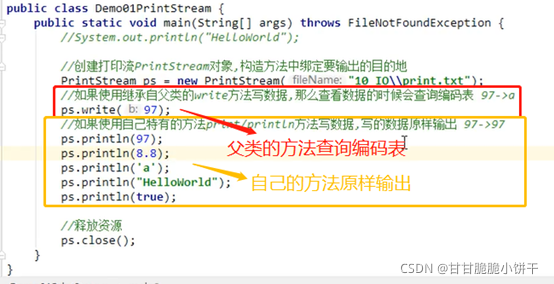
print.txt:
5.1 改变打印流的流向
可以改变输出语句的目的地(打印流的流向)。输出语句默认在控制台输出,可以使用System.setOut方法将输出语句的目的地改为参数中传递的打印流的目的地:
static void setOut(PrintStream out):重新分配“标准”输出流。
举例:
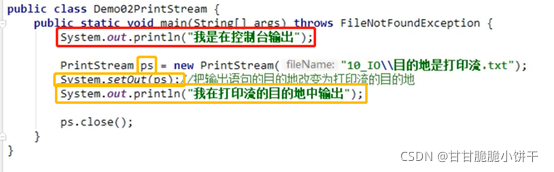
控制台输出:
目的地是打印流.txt:
三十三、网络编程入门
1.软件结构
1.1 C/S结构
全称为Client/Server结构,是指客户端和服务器结构。常见客户端程序有、迅雷等软件。
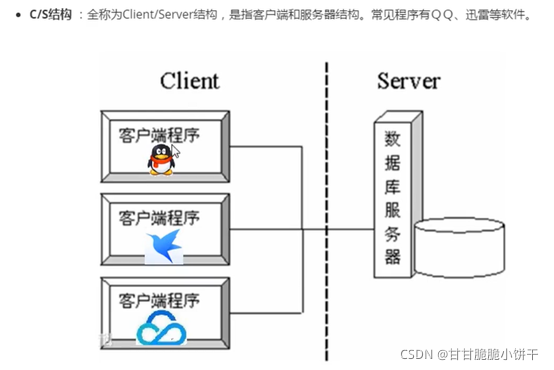
1.2 B/S结构
全称为browser/server结构,是指浏览器和服务器结构。常见浏览器有谷歌、火狐等。
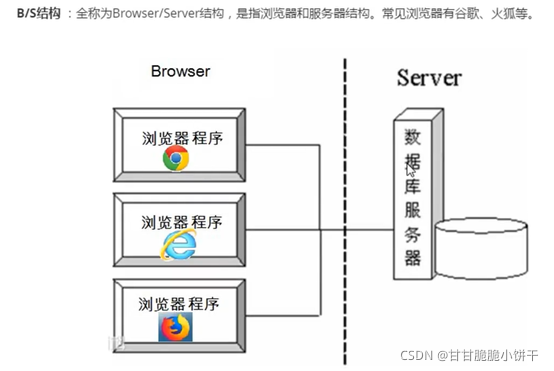
两种架构各有优势,但是无论哪种架构,都离不开网络的支持。网络编程,就是在一定的协议下,实现两台计算机的通信的程序。
2.网络通信协议
2.1 概述
通过计算机网络可以使多台计算机实现连接,位于同一网络中的计算机在进行连接和通信时需要遵守一定的规则,这就好比在道路中行驶的汽车一定要遵守交通规则一样。
在计算机网络中,这些连接和通信的规则被称为网络通信协议,它对数据的传输格式、传输速率、传输步骤等做了统一规定,通信双方必须同时遵守才能完成数据交换。
TCP/IP协议: 
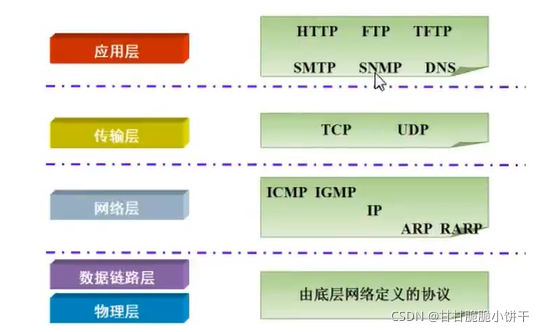

2.2 网络通信协议的分类
UDP和TCP。

UDP:效率高,不安全。
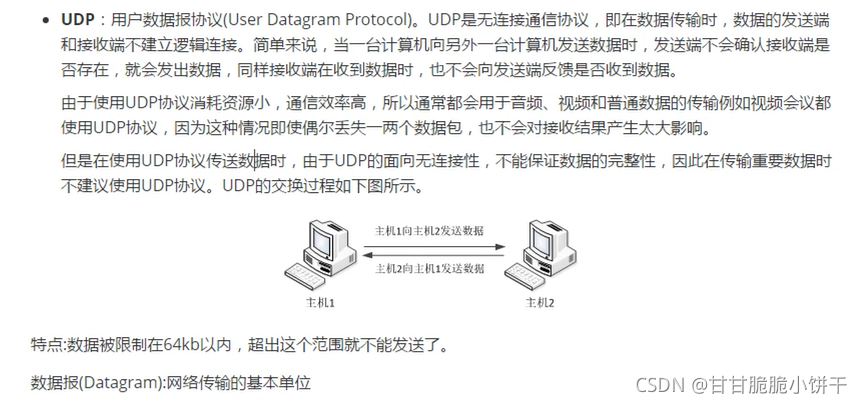
TCP:安全,效率不高。


3.网络编程三要素
网络编程三要素:协议、IP地址、端口号。
3.1 协议
计算机网络通信必须遵守的规则。
3.2 IP地址
指互联网协议地址(Internet Protocol Address),俗称IP。IP地址用来给一个网络中的计算机设备做唯一的编号。假如我们把“个人电脑”比作“一台电话”的话,那么:IP地址“IP地址”就相当于“电话号码”。
IP地址分类:

常用命令:
3.3 端口号
IP地址:唯一标识网络中的设备(计算机)。
端口号:唯一标识设备中的进程(应用程序)。由2个字节表示的整数,取值范围0-65535。
使用IP地址+端口号,就可以保证数据准确无误地发送到对方计算机的指定软件上。
常用端口号:
1.80端口:网络端口。www.baidu.com:80 完整的网址
2.数据库:MySQL:3306;Oracle:1521
3.Tomcat服务器:8080
注意:
1024之前的端口号我们不能使用,已经被系统分配给已知的网络软件了,网络软件的端口号不能重复。


4.TCP通信程序
4.1 概述
TCP通信能实现两台计算机之间的数据交互,通信的两端,要严格区分为客户端【Client,配置低的计算机】与服务器【Server,配置高的计算机】。比如用自己的电脑打开淘宝客户端,自己的电脑:客户端,访问淘宝的服务器。
两端通信时的步骤:
1.服务端程序,需要事先启动,等待客户端的连接;
2.客户端主动连接服务器端,连接成功才算通信。服务器不可以主动连接客户端。
在Java中,提供了两个类用于实现TCP通信程序:
1.客户端:java.net.Socket类表示。创建Socket对象,向服务器发出连接请求,服务器响应请求,两者建立连接开始通信。
2.服务端:java.net.ServerSocket类表示。创建ServerSocket对象,相当于开启一个服务,并等待客户端的连接。
TCP通信概述:

多个客户端可以给同一个服务器发送请求,因此服务器必须明确两件事,如下图:

4.2 TCP通信的客户端【Socket】实现
4.2.1 概述
TCP通信的客户端:向服务器发送连接请求,给服务器发送数据,读取服务器回写的数据。
java.net.Socket:表示客户端的类。此类实现客户端套接字,套接字是两台机器通信的端点。套接字:包含了IP地址和端口号的网络单位。
4.2.2 构造方法
Socket(String host,int port):创建一个流套接字并将其连接到指定主机上的指定端口号。
参数:
String host:服务器主机的名称/服务器的IP地址
int port:服务器的端口号
4.2.3 成员方法
OutputStream getOutputStream():返回此套接字的输出流。
InputStream getInputStream():返回此套接字的输入流。
void close():关闭此套接字。
4.2.4 客户端的实现步骤
1.创建一个客户端对象Socket,构造方法中绑定服务器的IP地址和端口号;
2.使用Socket对象中的getOutputStream方法,获取网络字节输出流OutputStream对象;
3.使用网络字节输出流OutputStream对象中的write方法,给服务器发送数据;
4.使用Socket对象中的getInputStream方法,获取网络字节输入流InputStream对象;
5.使用网络字节输入流InputStream对象中的read方法,读取服务器回写的数据;
6.释放资源(Socket)。
注意:
1.客户端和服务器进行交互,必须使用Socket中提供的网络流,不能使用自己创建的流对象;
2.当我们创建客户端对象Socket的时候,就会请求服务器,和服务器经过3此握手建立连接通路。这时如果服务器没有启动,就会抛出异常;如果服务器已经启动,就可以进行交互了。
4.3 TCP通信的服务器端【ServerSocket】实现
4.3.1 概述
TCP通信的服务器端:接收客户端的请求,读取客户端发送的数据,给客户端回写数据。
java.net. ServerSocket:表示服务器的类。此类实现服务器套接字。
4.3.2 构造方法
ServerSocket(int port):创建绑定到特定端口的服务器套接字。
参数:
int port:指定的端口号
4.3.3 成员方法
服务器端必须明确一件事,必须要知道是哪个客户端请求的服务器,所以可以使用accept方法获取到客户端对象Socket。
Socket accept():侦听并接受到此套接字的连接。
4.3.4 服务器的实现步骤
1.创建一个服务器对象ServerSocket,和系统要指定的端口号;
2.使用ServerSocket对象中的方法accept,获取到请求的客户端对象Socket;
3. 使用Socket对象中的getInputStream方法,获取网络字节输入流InputStream对象;
4. 使用网络字节输入流InputStream对象中的read方法,读取客户端发送的数据;
5. 使用Socket对象中的getOutputStream方法,获取网络字节输出流OutputStream对象;
6. 使用网络字节输出流OutputStream对象中的write方法,给客户端回写数据;
7. 释放资源(Socket,ServerSocket)。
4.4 举例
三十四、函数式接口
1.概念
函数式接口在java中是指:有且只有一个抽象方法的接口,当然接口中可以包含其他的方法(默认,静态,私有)。

2.格式
只要确保接口中有且只有一个抽象方法即可:
修饰符 interface 接口名称{
public abstract 返回值类型 方法名称(可选参数信息);
//其他非抽象方法内容
}
由于接口中抽象方法的public abstract是可以省略的,所以定义一个函数式接口很简单,举例:
public interface MyFunctionInterface{
void myMethod;
}
3.FunctionalInterface注解
作用:可以检测接口是否是一个函数式接口。
是:编译成功。
否:编译失败(接口中没有抽象方法或者抽象方法的个数大于1)。
举例:
接口中定义两个了两个抽象方法,FunctionalInterface注解报错:
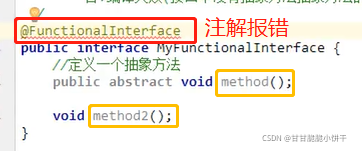
有且只有一个抽象方法才会编译成功:
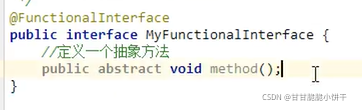
4.使用
一般可以作为方法的参数和返回值类型。
4.1 作为方法的参数
举例1:
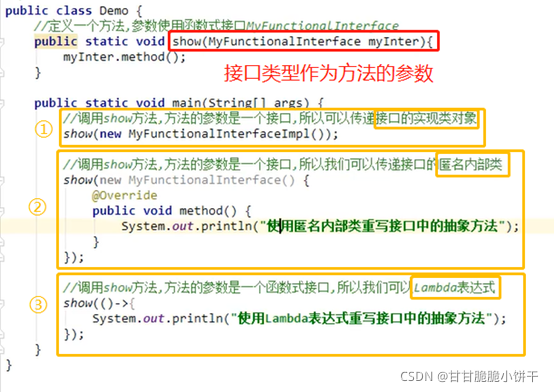
举例2:
定义参数为函数式接口的方法并调用:
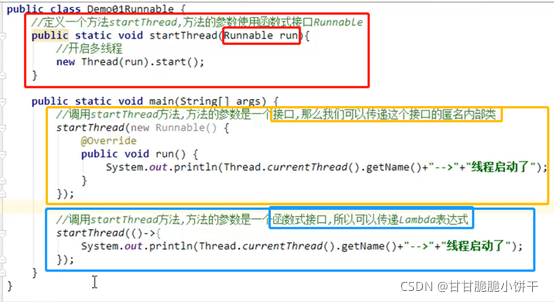
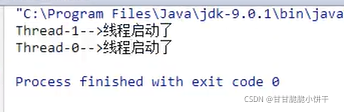
4.2 作为返回值类型
定义方法,返回值类型为函数式接口:
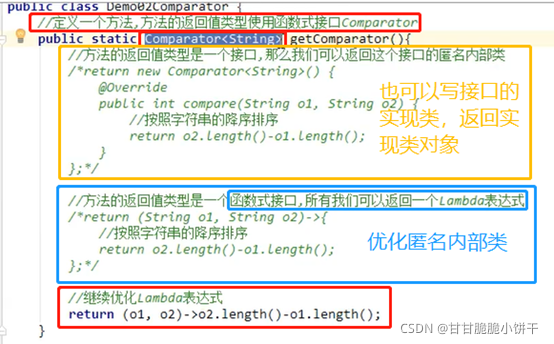
主方法:使用sort方法,重写自己制定的排序规则(重写Comparator接口中的compara方法)。
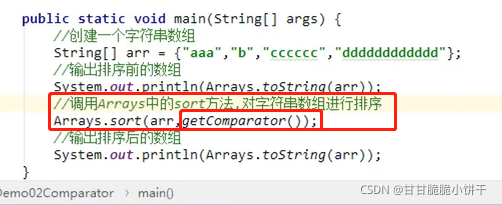
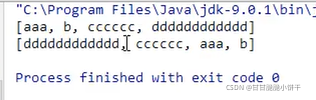
5.函数式编程
5.1 Lambda的延迟执行
有些场景的代码执行后,结果不一定被使用,从而造成性能浪费。而Lambda表达式是延迟执行的,这正好可以作为解决方案,提升性能。
5.2 性能浪费的日志案例
注:日志可以帮助我们快速地定位问题,记录程序运行过程中的情况,以便项目的监控和优化。
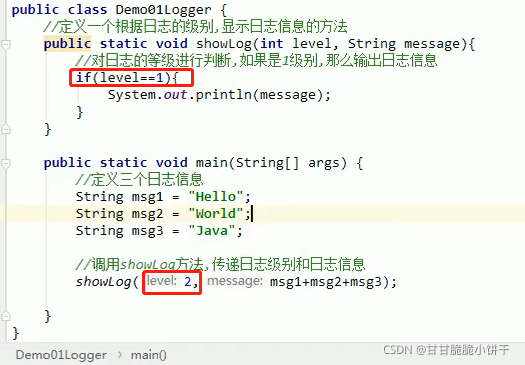
问题:
发现以上代码存在的性能浪费问题:调用showLog方法,传递的第二个参数是一个拼接后的字符串,即先把字符串拼接好再调用showLog方法。若传递的日志等级level不等于1,那么字符串就白拼接了。
5.3 使用Lambda优化日志案例
Lambda的特点:延迟加载。
Lambda的使用前提:必须存在函数式接口。
定义函数式接口MessageBuilder:
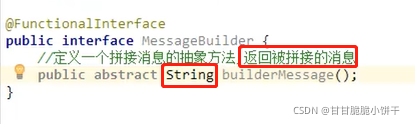
主方法:
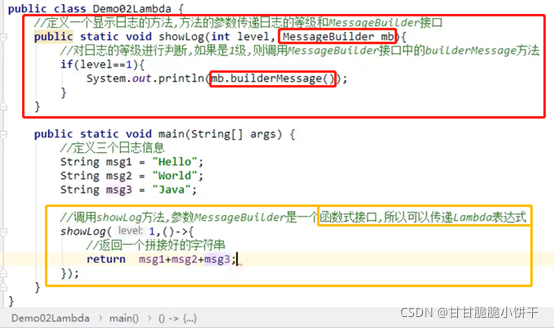
测试:
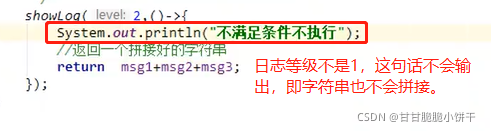
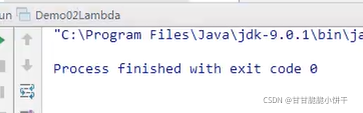
使用Lambda表达式作为参数传递,仅仅是把参数传递到showLog方法中。①只有满足条件即日志的等级是1级,才会调用MessageBuilder接口中的builderMessage方法,才会进行字符串的拼接。②如果条件不满足即日志等级不是1级,那么MessageBuilder接口中的builderMessage方法就不会执行,拼接字符串的代码也不会执行,不会存在性能的浪费。
6.常用函数式接口
JDK提供了大量常用的函数式接口用以丰富Lambda的典型应用场景,它们主要在java.util.function包中被提供。
6.1 Supplier接口
6.1.1 概述
java.util.function.Supplier<T>:接口仅包含一个无参的方法:T get()。用来获取一个泛型参数指定类型的对象数据。由于这是一个函数式接口,这也就意味着对应的Lambda表达式需要“对外提供”一个符合泛型类型的对象数据。
Supplier<T>接口被称之为生产型接口,即指定接口的泛型是什么类型,接口中的get方法就会生产什么类型的数据。
6.1.2 举例:求数组元素最大值
举例1:方法返回值类型为string型

举例2:求数组元素的最大值
使用supplier接口作为方法的参数类型,通过Lambda表达式求出int数组中的最大值,方法返回值类型为int。提示:接口的泛型请使用java.lang.Integer类。
要使用函数式接口作为方法的参数,先定义方法:
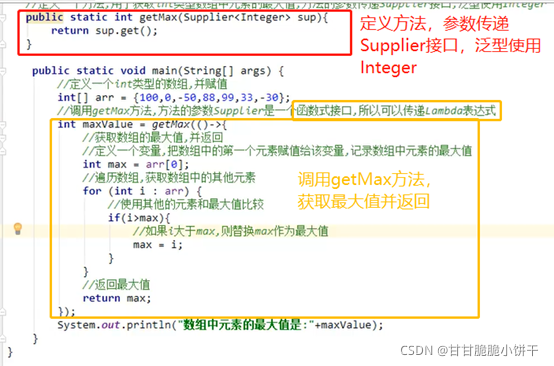
6.2 Consumer接口
6.2.1 概述
java.util.function.Consumer<T>接口则正好与Supplier接口相反,它不是生产一个数据,而是消费一个数据,其数据类型由泛型决定。
6.2.2 抽象方法:accept
Consumer<T>接口是一个消费型接口,即指定接口的泛型是什么类型,就可以使用accept方法消费(使用)什么类型的数据。至于具体怎么消费,需要自定义(输出,计算…)。
6.2.3 Consumer接口的默认方法:andThen
如果一个方法的参数和返回值全都是Consumer类型,那么就可以实现效果:消费数据的时候,首先做一个操作,然后再做一个操作,实现组合操作。而这个方法就是Consumer接口中的默认方法:andThen。下面是JDK的源码:

andThen方法需要两个Consumer接口,可以把两个Consumer接口组合到一起,再对数据进行消费。谁写前面谁先消费。
获取字符串的大写和小写格式,两个消费需求:大写、小写,因此方法的参数需要使用两个Consumer接口和一个字符串,不需要返回值,直接输出。
举例:
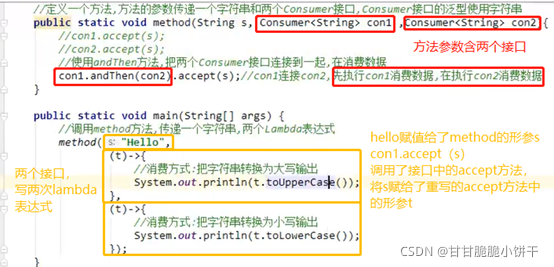
6.2.4 举例:格式化打印信息
举例1:
定义一个方法,方法的参数传递一个字符串的姓名和Consumer接口,泛型使用String,可以使用Consumer接口消费字符串的姓名,不需要返回值,返回值类型为void。
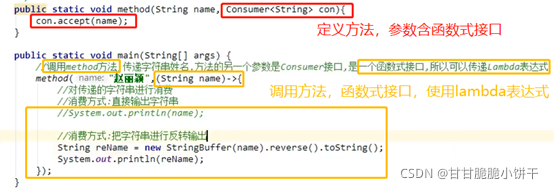
举例2:
格式化打印信息,两个消费需求:打印姓名、打印性别,因此方法的参数需要两个Consumer接口和一个字符串,不需要返回,返回值类型为void。

定义方法:

主方法:
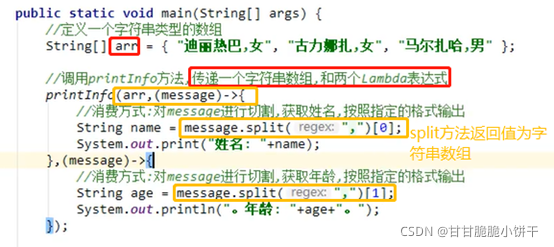
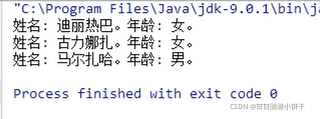
6.3 Predicate接口
6.3.1 概述
有时候我们需要对某种类型的数据进行判断,从而得到一个Boolean值结果,这时可以使用java.util.function. Predicate<T>接口。
6.3.2 抽象方法:test
Predicate接口中包含一个抽象方法:boolean test(T t):用来指定数据类型数据进行判断的方法。结果:符合条件返回true,不符合条件返回false。
举例:
定义一个方法,参数传递一个string类型的字符串。传递一个Predicate接口,泛型使用string。使用Predicate中的test方法对字符串进行判断,并把判断结果返回,返回值类型为Boolean。
举例:
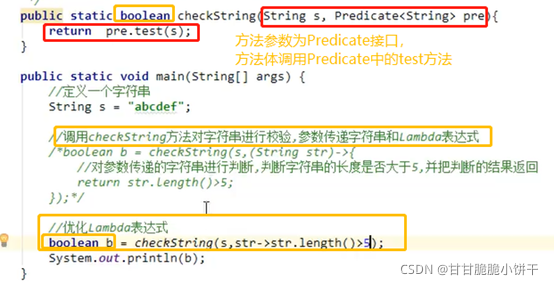
6.3.3 Predicate接口的默认方法:and、or、negate方法
既然是条件判断,就会存在与、或、非三种常见的逻辑关系。
1.and方法
将两个Predicate条件使用“与”逻辑连接起来实现“并且”的效果。有false则false。
举例:

需要一个字符串、两个判断条件,因此方法的参数需要一个字符串和两个Predicate接口。
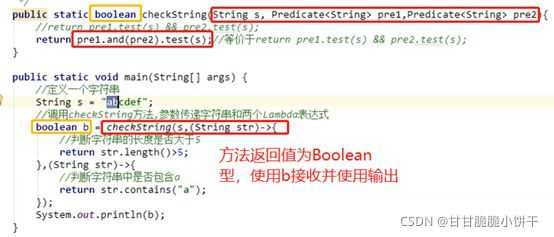
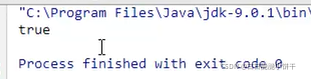
2.or方法
“或”,有true则true。

3.negate方法
非(取反)运算符,非真则假,非假则真。
举例:

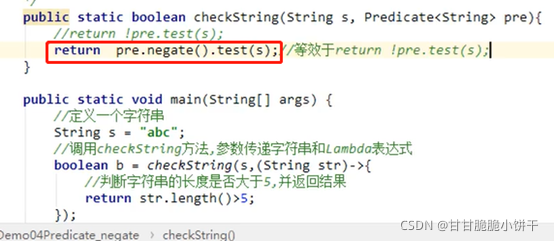
6.3.4 举例:集合信息筛选

分析:
1.有两个判断条件,因此需要使用两个Predicate接口、一个包含人员信息的数组为方法的参数,返回值为ArrayList集合;
2.必须同时满足两个条件,使用and方法。
定义过滤的方法:
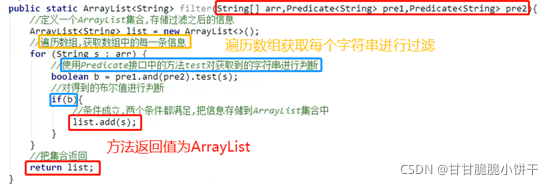
主方法:
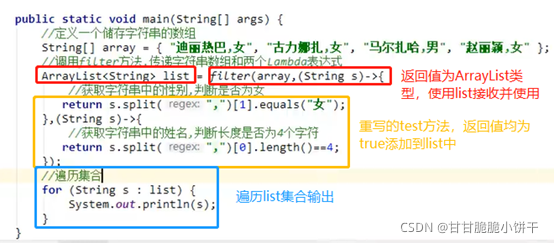

6.4 Function接口
6.4.1 概述
java.util.function.Function<T,R>接口:用来根据一个类型的数据得到另一个类型的数据(转换数据类型),前者称为前置条件,后者称为后置条件。
6.4.2 抽象方法:apply
Function接口中最主要的抽象方法为:R apply(T t),根据类型T的参数获取类型类型R的结果。
举例:将String类型转换为Integer类型
定义一个方法,方法的参数传递一个字符串类型的整数和一个Function接口,接口的泛型使用<String, Integer>,使用Function中的apply方法把字符串类型的整数转换为Integer类型的整数,无返回值,直接输出即可。

主方法:
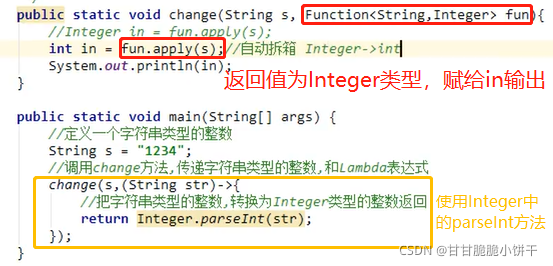
6.4.3 Function的默认方法:andThen
Function接口中有一个默认的andThen方法,用来进行组合操作。该方法同样用于“先做什么,再做什么”的场景,和Consumer中的andThen差不多。
举例:

定义方法,转换了两次,因此方法的参数需要使用一个字符串和两个Function接口(一个泛型使Function<String, Integer>,一个泛型使用Function<Integer,String>),无返回值,直接输出即可。

主方法:
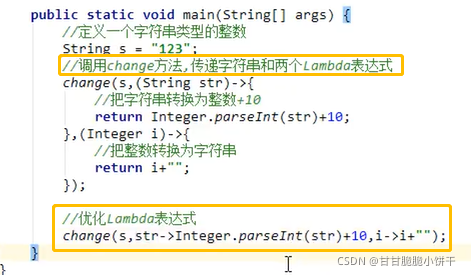
6.4.4 举例:自定义函数模型拼接

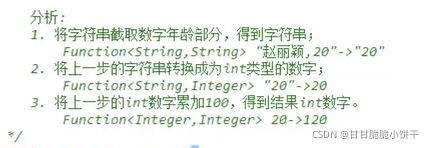
定义方法,方法的参数使用三个Function接口(字符串->字符串,字符串->int型,int型->int型)组合操作和一个字符串,返回值类型为int。

主方法:
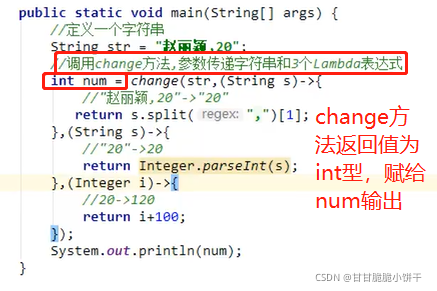
三十五、Stream流
1.概述
说到Stream便容易想到I/O,而实际上,谁规定“流”一定就是“IO流”呢。在Java8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念,用于解决已有集合类库既有的弊端。
IO流主要用于读写,而Stream流主要用于对集合和数组进行简化操作。
1.1 传统集合的多步遍历代码
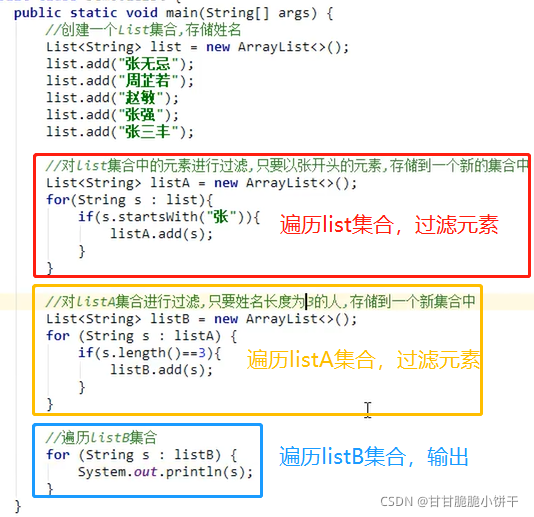
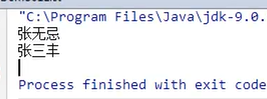
1.2 循环遍历的弊端
每当需要对集合中的每个元素进行操作时,总是需要循环。

1.3 Stream的更优写法
使用Stream流的方式遍历集合,对集合中的数据进行过滤。Stream流是JDK1.8之后出现的,关注的是做什么,而不是怎么做。
JDK1.8之后,集合中添加了stream方法,可以把集合转换为stream流,stream中有个方法filter进行过滤。
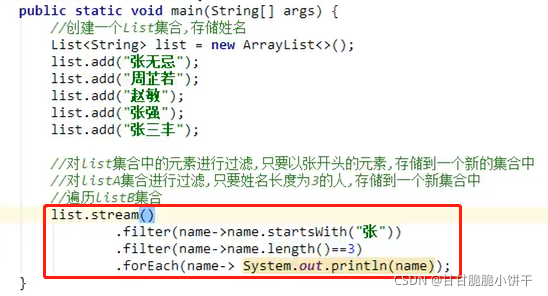
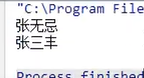
2.流式思想概述
注意,请暂时忘记对传统IO流的固有印象!
整体来看,流式思想类似于工厂车间的“生产流水线”,当需要对多个元素进行操作(特别是多步操作)时,考虑到性能及便利性,我们应该首先拼好一个“模型”步骤方案,然后再按照方案去执行它(类似于工厂中需要建立一个生产线生产商品)。
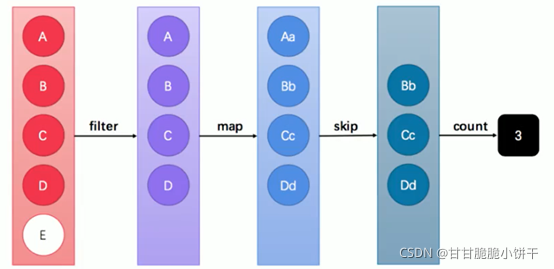
上图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型到另一个流模型。而最右侧的数字3是最终结果。
只有当终结方法count执行时,前面三步才会执行,得益于Lambda的延迟执行特性。

3.特点
Stream流是一个来自数据源的元素队列:
1.元素是特定类型的对象,形成一个队列。Java中的Stream并不会存储元素,而是按需计算;(比如工厂生产瓶子,每一步都不会拿走瓶子,直到最后一步)
2.数据源:流的来源可以是集合、数组等;
3.Pipelining:中间操作都会返回流对象本身。这样多个操作可以串联成一个管道,如同流式风格(fluent style)。这样做可以对操作进行优化,比如延迟执行和短路。
4.内部迭代:以前对集合的遍历都是通过Iterator或者增强for的方式,显示的在集合外部进行迭代,这叫做外部迭代。Stream提供了内部迭代的方式,流可以直接调用遍历方法。
注意:
Stream流属于管道流,只能被消费(使用)一次。第一个Stream流调用完毕方法就会关闭,数据就会流转到下一个Stream上。第一个Stream流已经关闭不能再调用方法了,会报错。
4.使用步骤
当使用一个流的时候,通常包括3个基本步骤:
获取一个数据源(source,集合/数组)->数据转换(把集合/数组转换为Stream流)->执行操作获取想要的结果。
每次转换,原有Stream对象不改变,返回一个新的Stream对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道。
5.获取流
Java.util.stream.Stream<T>是Java8新加入的最常用的流接口(不是函数式接口)。
获取流有两种方式:
1.所有的Collection集合都可以通过stream默认方法获取流;
2. Stream接口的静态方法of方法(参数是可变参数)可以获取数组对应的流。
5.1 根据Collection获取流

5.2 根据Stream接口的of方法获取流
6. Stream流中的常用方法
分为两种:
1.延迟方法:返回值类型仍然是Stream接口自身类型的方法,因此支持链式调用(除了终结方法外,其余方法均为延迟方法)。
2.终结方法:返回值类型不再是Stream接口自身类型的方法,因此不再支持类似StringBuilder那样的链式调用。本小节中,终结方法包括count方法和forEach方法(其余自行参考API文档)。
6.1 遍历:forEach方法【终结方法】
虽然名字叫forEach,但是与for循环中的“for-each(增强for)”昵称不同。
void forEach(Consumer<? Super T> action):该方法接收一个Consumer接口函数,会将每一个流元素交给该函数进行处理。
简单记,forEach方法,用来遍历流中的数据。
forEach方法是一个终结方法,遍历之后就不能继续调用Stream流中的其他方法。
举例:
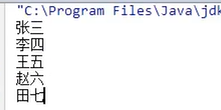
6.2 过滤:filter方法【延迟方法】
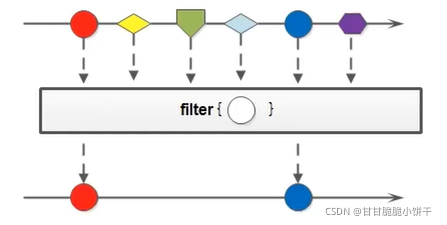
可以使用filter方法将一个流转换为另一个子集流。
Stream<T> filter(Predicate<? super T> predicate):该接口接收一个Predicate函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
filter方法是一个延迟方法,只是对流中的元素进行过滤,返回的是一个新的流,所以可以继续调用Stream流中的其他方法。
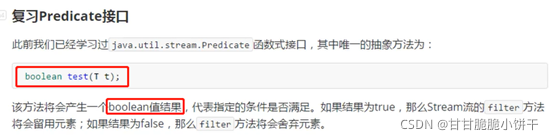
举例:
Filter方法返回值为stream,可以继续赋给一个新的stream继续使用。
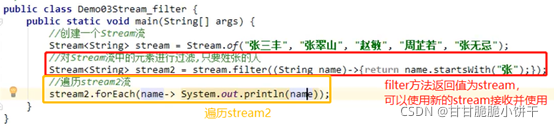
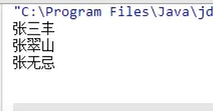
6.3 映射:map方法【延迟方法】
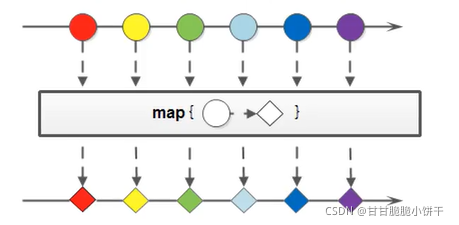
如果需要将流中的元素映射到另一个流中,可以使用map方法。
<R> Stream<R> map(Function<? Super T,? extenda R> mapper):该接口需要一个Function函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
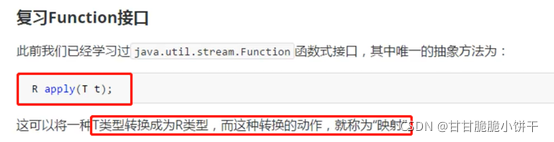
map 方法是一个延迟方法,只是对流中的元素进行类型转换,返回的是一个新的流,所以可以继续调用Stream流中的其他方法。
举例:
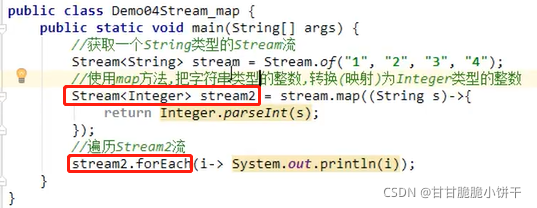
6.4 统计个数:count方法【终结方法】
正如旧集合Collection当中的size方法一样,流提供count方法来统计其中的元素个数。
long count():该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。
该方法是终结方法,使用后不能再使用stream中的其他方法。
举例:
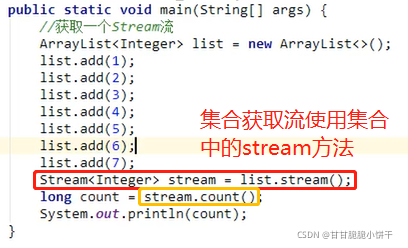
6.5 取用前几个:limit方法【延迟方法】
limit方法可以对流进行截取,只取用前n个。
Stream<T> limit(long maxSize):参数是一个long型,如果集合当前长度大于参数则进行截取,否则不进行操作。
limit方法是一个延迟方法,只是对流中的元素进行截取,返回的是一个新的流,所以可以继续调用Stream流中的其他方法。
举例:
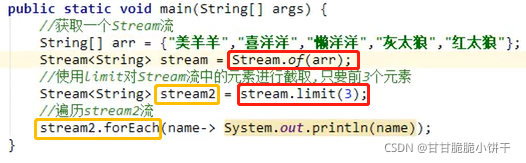
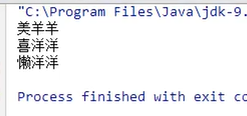
6.6 跳过前几个:skip方法【延迟方法】
如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的新流。
Stream<T> skip(long n):如果流的当前长度大于n,则跳过前n个,否则将会得到一个长度为0的空流。
skip方法是一个延迟方法,只是跳过流中的前几个元素,返回的是一个新的流,所以可以继续调用Stream流中的其他方法。
举例:
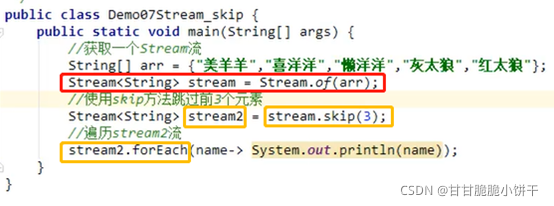
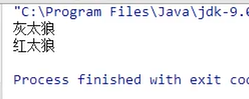
6.7 组合:concat方法【延迟方法】
如果有两个流,希望合并为一个流,那么可以使用Stream接口中的concat方法。

静态方法,可以直接通过接口名调用。
concat方法是一个延迟方法,只是合并两个流为一个新的流,所以可以继续调用Stream流中的其他方法。
举例:
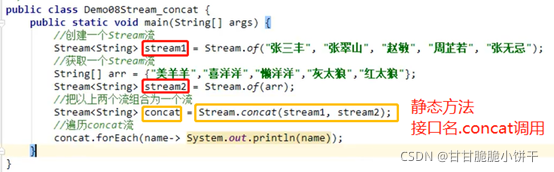
7.练习:集合元素处理(传统方式)

最终要创建Person对象,因此先创建Person类:

第一个队伍:

第二个队伍:
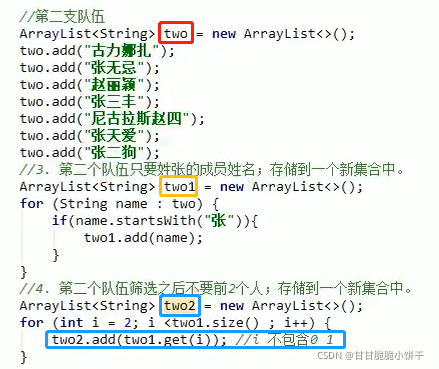
合并队伍,创建Person对象,遍历输出:

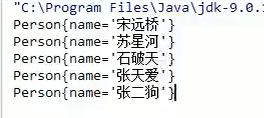
使用传统的方式每次都需要使用循环遍历。
8.练习:集合元素处理(Stream方式)

最终要创建Person对象,因此先创建Person类:

第一个队伍:
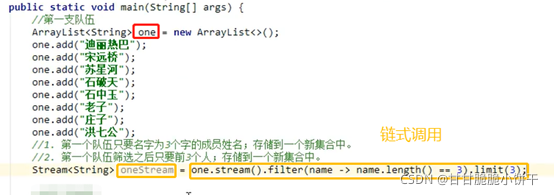
第二个队伍:
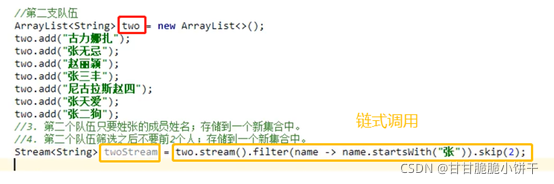
合并队伍,创建Person对象,遍历输出:

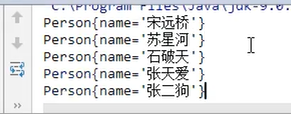
三十六、方法引用
1.概述
在使用Lambda表达式的时候,我们实际上传递进去的代码就是一种解决方案:拿什么参数做什么操作。那么考虑一种情况:如果我们在Lambda中所指定的操作方案,已经有地方存在相同方案,那是否还有必要再写重复逻辑?
1.1 冗余的Lambda场景
定义一个打印的函数式接口:
主方法:
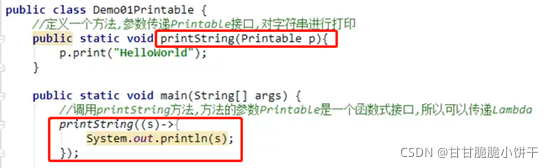
1.2 问题分析
Lambda表达式重写Printable接口的print方法,重写的内容是:调用out对象中的方法println打印参数传递的字符串,把参数s传递给了System.out对象,调用out对象中的方法println对字符串进行了输出。
注意:
1. System.out对象是已经存在的;
2. println方法也是已经存在的。
所以可以使用方法引用来优化Lambda表达式:可以使用System.out对象直接引用(调用)println方法。

2.方法引用符
双冒号::为引用运算符,而它所在的表达式被称为方法引用。如果Lambda要表达的函数方案已经存在于某个方法的实现中,那么则可以通过双冒号来引用该方法作为Lambda的替代者。
2.1 语义分析
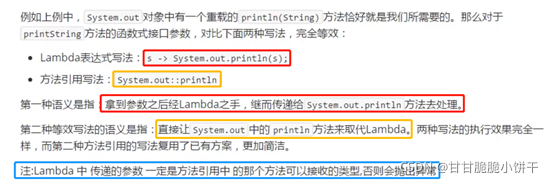
2.2 推导与省略

3.通过对象名引用成员方法
这是最常见的一种用法。使用前提:对象名已经存在,成员方法也已经存在。就可以使用对象名来引用成员方法。
举例:
如果一个类中已经存在了一个成员方法:
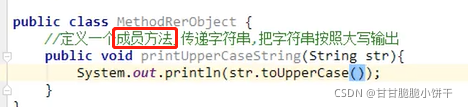
对Lambda的简化,使用Lambda必须有函数式接口:
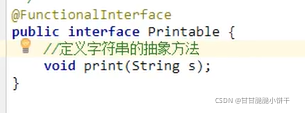
测试类:
使用Lambda表达式:
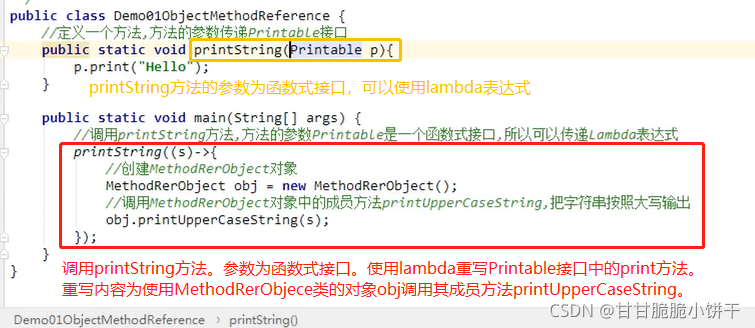
使用方法引用优化Lambda表达式:

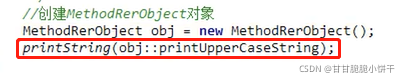
4.通过类名称引用静态方法
使用前提:类已经存在,静态成员方法也已经存在。就可以通过类名直接引用静态成员方法。
举例:
对Lambda的简化,使用Lambda必须有函数式接口:

测试类:
使用Lambda表达式:
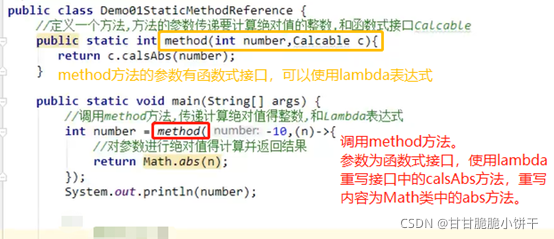
使用方法引用优化Lambda表达式:

5.通过super引用成员方法
使用前提:如果存在继承关系,当Lambda中需要出现super调用时,也可以使用方法引用进行替代。
举例:
定义见面的函数式接口:
父类:
子类及方法:
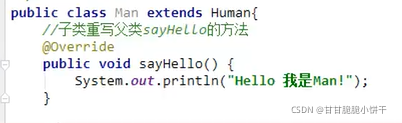

使用Lambda:

优化Lambda:

使用方法引用优化Lambda:
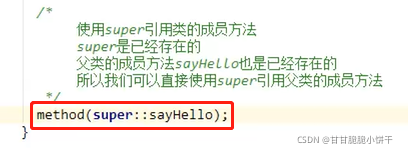
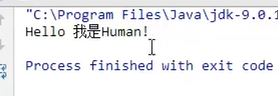
6.通过this引用成员方法
this代表当前对象,如果需要引用的方法就是当前类中的方法,那么可以使用“this::成员方法”的格式来使用方法引用。
举例:
函数式接口:
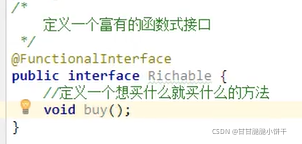
丈夫类:
使用Lambda调用本类方法:

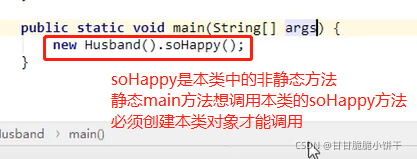
使用方法引用优化Lambda:

7.类的构造器引用
也称构造方法的引用。由于构造器的名称和类名完全一样,并不固定。所以构造器引用使用 类名称::new 的格式表示。
举例:
定义Person类:

定义创建Person对象的函数式接口:
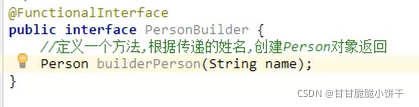
测试类:

使用方法引用优化Lambda:

8.数组的构造器引用
数组也是Object的子类对象,所以同样具有构造器,只是语法稍有不同。
举例:
创建一个创建数组的函数式接口:

测试类:
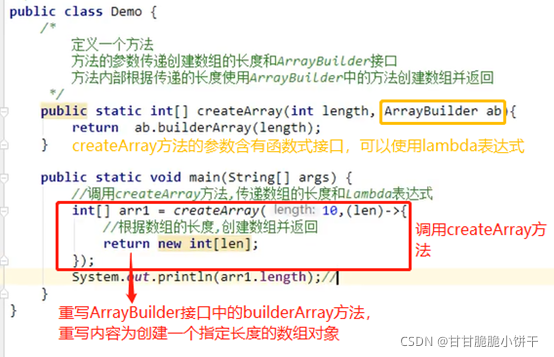
使用方法引用优化Lambda:
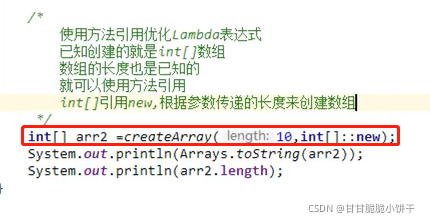

三十七、Junit单元测试
1. Junit概述
测试分类:
1.黑盒测试:不需要写代码。给输入值,看程序是否能够输出期望的值。
2.白盒测试:需要写代码。关注程序具体的执行流程。Junit单元测试是白盒测试的一种。
2. Junit使用:白盒测试

判定结果:
一般会使用断言操作来处理结果:Assert.assertEquals(期望的结果,运算的结果);
控制台红色:失败。
控制台绿色:成功。
举例:
测试加法失败:
测试减法成功:
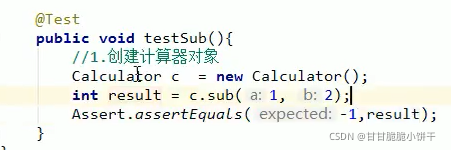
3.@Before和@After

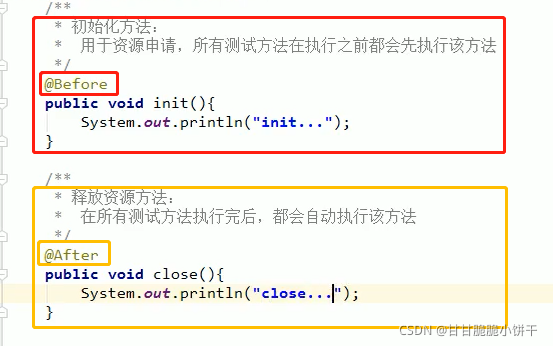
三十八、反射
1.概述
反射被称为框架设计的灵魂。框架:半成品软件,可以在框架的基础上进行软件开发,简化代码。
反射:
将类的各个组成部分封装为其他对象,这就是反射机制。
好处:
1.可以在程序运行的过程中操作这些对象。
2.可以解耦。提高程序的可扩展性。
Java代码在计算机中经历的三个阶段:
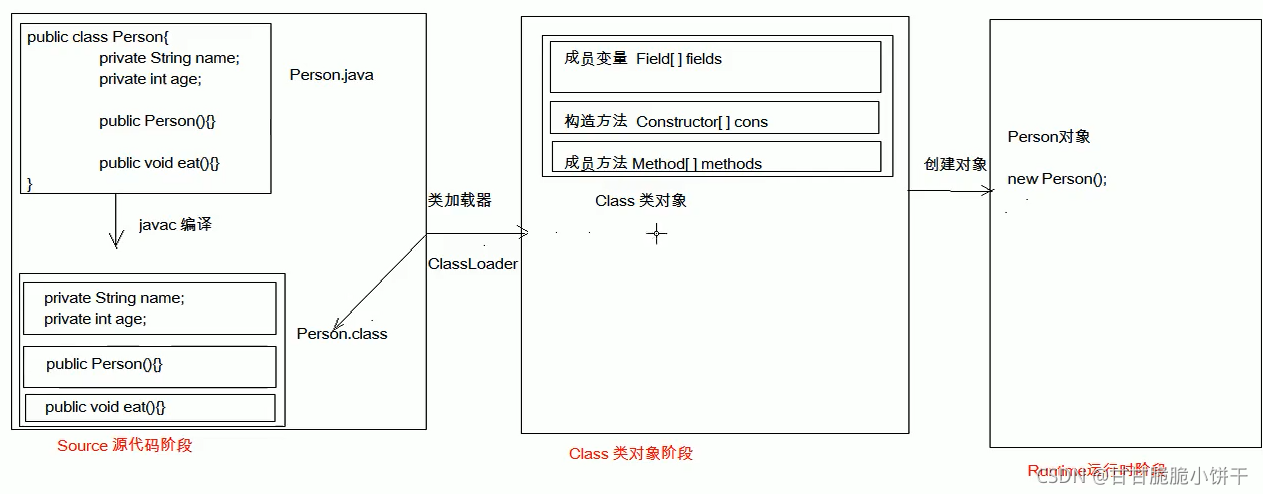
2.获取class对象的方式
三种方式:分别对应Java代码在计算机中经历的三个阶段。
1.Source源代码阶段:只有class字节码文件,还未加载进内存->Class.forName(“全类名”);->静态方法。将字节码文件加载进内存,返回class对象->多用于配置文件,将类名定义在配置文件中,读取文件,加载类。
2.已经将字节码文件加载进内存,已经有class类对象->类名.class->通过类名的属性class获取->多用于参数的传递。
3.已经有类的对象->对象.getClass()-> getClass()方法在Object类中定义,所有对象都可以使用->多用于对象获取字节码的方式。
注意:
同一个字节码文件(*.class)在一次程序运行过程中。只会被加载一次,不论通过哪一种方式获取的Class对象都是同一个。
举例:
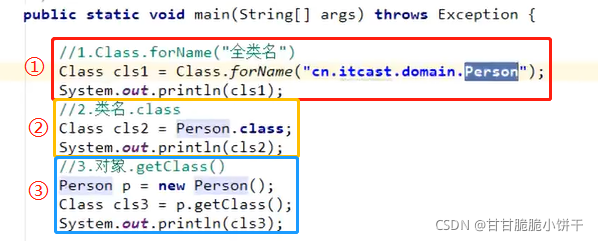

结果:
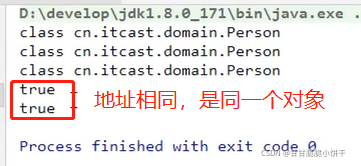
3.使用class对象
获取功能:以下四种获取方式,不带Declared的方法只能获取公共的, 带Declared的方法能获取所有权限的,包括private。因此都需要忽略访问权限修饰符的安全检查:setAccessible(true):暴力反射。
3.1 获取成员变量们
field类位于java.lang.reflect包下。在Java反射中Field类描述的是类的属性信息。 
使用Field对象:

举例:
getFields、getField :

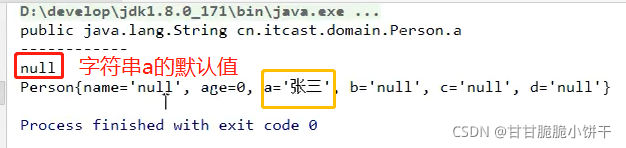
getDeclaredFields:
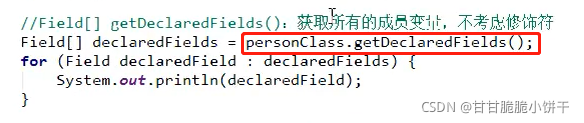
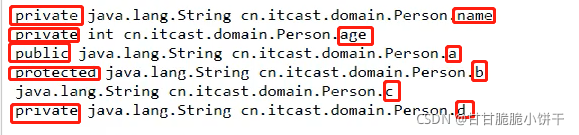
getDeclaredField:
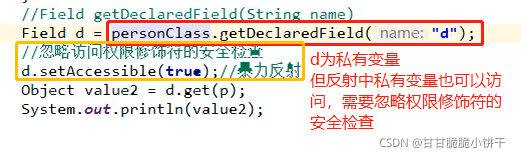

3.2 获取构造方法们


使用构造方法对象:

举例:

使用全参构造方法:

结果:输出了构造方法和创建的对象

使用空参构造方法:
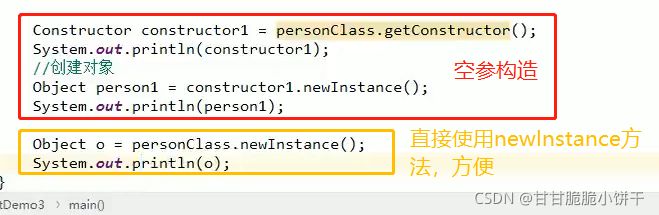

3.3 获取成员方法们


使用方法对象:

举例:
Person类中定义的构造方法:
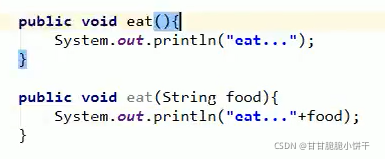
获取class对象:

获取指定名称和参数列表的方法:
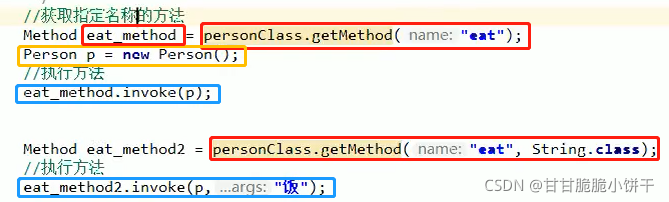
获取所有public修饰的方法:
注意除了Person类中自定义的一些方法,Person类无直接父类,还会打印出直接继承Object类中隐藏的方法。
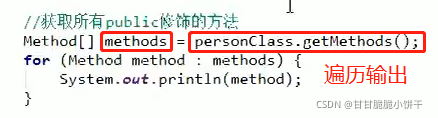
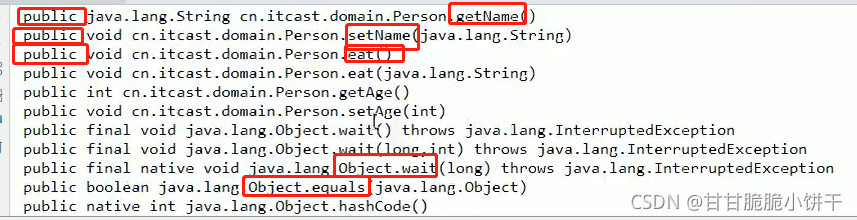
3.4 获取类名
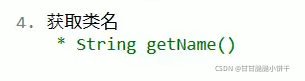
举例:

4.反射案例
需求:写一个“框架”,不能改变该类任何代码的前提下,可以帮我们创建任意类的对象,并且执行其中的任意方法。
定义类:
Person:
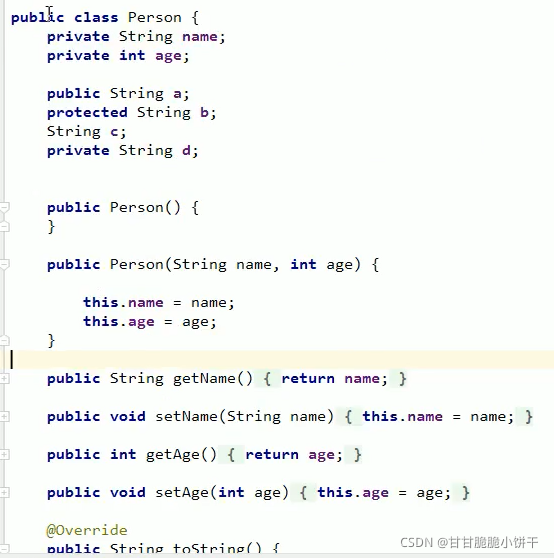

Student:
框架类:
可以创建任意类的对象,并且执行其中的任意方法。
以前的写法:
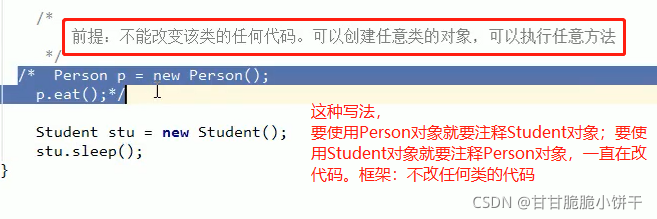
使用反射:

定义配置文件:
比如配置Person类的eat方法:
加载配置文件:

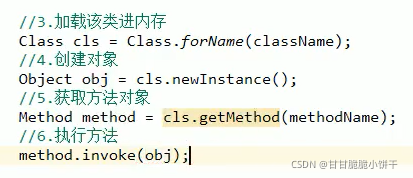
结果:
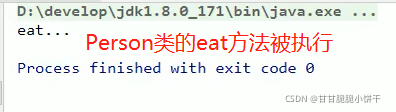
只需改配置文件为Student类的sleep方法:

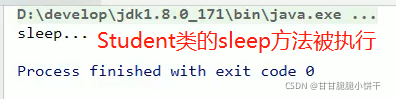
三十九、注解
1.概念
注释:用文字描述程序,给程序员看。
注解:说明程序,给计算机看的。

2.JDK中预定义的一些注解
@Override:检测被该注解标注的方法是否是继承自父类(接口)的。
@Deprecated:该注解标注的内容,表示已过时。
@SuppressWarnings:压制警告,一般传递参数all:@SuppressWarnings(”all”)。
举例:



3.自定义注解
注解本质是一个接口,接口中可以定义什么注解中就可以定义。

4.元注解
用于描述注解的注解。

5.在程序中使用(解析)注解
即获取注解中定义的属性值
反射案例使用注解:
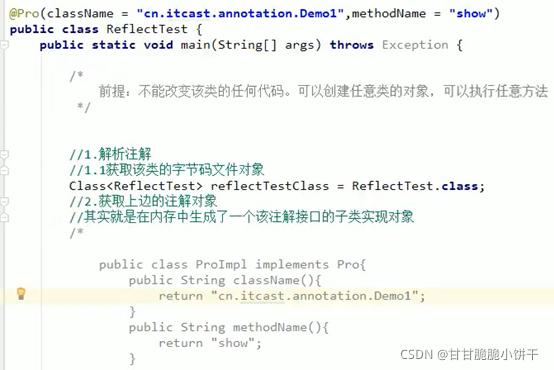

解析:

6.注解案例
帮小明测试他定义的计算器类中的每个方法是否正确。
计算器类:

测试注解:
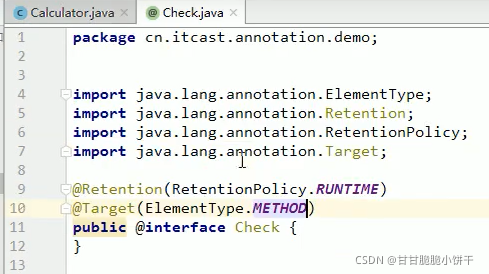
想验证哪个方法给哪个方法上加Check注解即可:比如测试加减乘除四个方法:
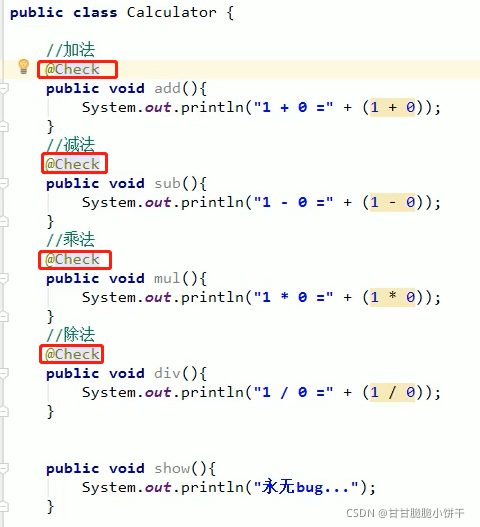
当主方法执行后,会自动执行被检测的所有方法(加了Check注解的方法),判断方法是否有异常,记录到文件中。
测试框架类:
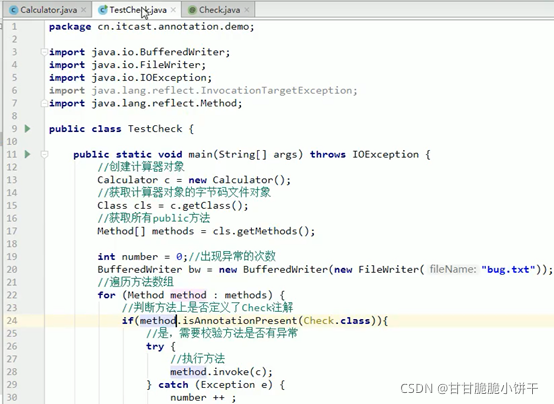

结果:产生了bug.txt文件
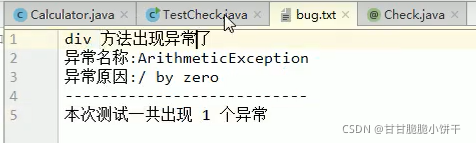
7.注解小结

10.25撒花
到此这篇Java基础_java基础知识点整理的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/jjc/6275.html