
public class ZipHelper
{
/// <summary>
/// GZipStream压缩字符串
/// </summary>
/// <param name="str"></param>
/// <returns></returns>
public Stream GZipCompress(string str)
{
byte[] buffer = System.Text.Encoding.UTF8.GetBytes(str);
MemoryStream msReturn;
using (MemoryStream msTemp = new MemoryStream())
{
using (GZipStream gz = new GZipStream(msTemp, CompressionMode.Compress, true))
{
gz.Write(buffer, 0, buffer.Length);
gz.Close();
msReturn = new MemoryStream(msTemp.GetBuffer(), 0, (int)msTemp.Length);
}
}
return msReturn;
}
/// <summary>
/// GZipStream压缩Byte数组
/// </summary>
/// <param name="str"></param>
/// <returns></returns>
public Stream GZipCompress(byte[] btArray)
{
MemoryStream msReturn;
using (MemoryStream msTemp = new MemoryStream())
{
using (GZipStream gz = new GZipStream(msTemp, CompressionMode.Compress, true))
{
gz.Write(btArray, 0, btArray.Length);
gz.Close();
msReturn = new MemoryStream(msTemp.GetBuffer(), 0, (int)msTemp.Length);
}
}
return msReturn;
}
/// <summary>
/// GZipStream解压字符串
/// </summary>
/// <param name="stream"></param>
/// <returns></returns>
public string GZipDecompress(Stream stream)
{
byte[] buffer = new byte[100];
int length = 0;
using (GZipStream gz = new GZipStream(stream, CompressionMode.Decompress))
{
using (MemoryStream msTemp = new MemoryStream())
{
while ((length = gz.Read(buffer, 0, buffer.Length)) != 0)
{
msTemp.Write(buffer, 0, length);
}
return System.Text.Encoding.UTF8.GetString(msTemp.ToArray());
}
}
}
/// <summary>
/// GZipStream解压字符串
/// </summary>
/// <param name="stream"></param>
/// <returns></returns>
public MemoryStream GZipDecompressStream(Stream stream)
{
byte[] buffer = new byte[100];
int length = 0;
using (GZipStream gz = new GZipStream(stream, CompressionMode.Decompress))
{
using (MemoryStream msTemp = new MemoryStream())
{
while ((length = gz.Read(buffer, 0, buffer.Length)) != 0)
{
msTemp.Write(buffer, 0, length);
}
return msTemp;
}
}
}
}
- 实现标准Zip文件的解压和压缩(DEFLATED压缩算法)
- 可以跨平台使用
- 可以支持不同编码的文件/文件夹名字
采用zlib库中的第三方库minizip库,不过需要对minzip做些修改以支持不同平台的编译。minizip在处理文件或文件夹名字的时候不会自动做编码转换,需要自己处理名字编码的转换,否则可能会出现文件/文件夹名字乱码的问题。
UE4自带zlib库,如果是源码版本的引擎可以到Engine/Source/ThirdParty/zlib/zlib-1.2.x/Src/contrib/minizip 中拷贝minizp源码到项目中,如果不是源码引擎里面是没有.c文件的,可以到官网下载minizip源码zlib Home Site。
项目中只需要拷贝minizip核心的文件即可,如图。

需要对minizip库做些修改,否则其他非Windows平台会有编译错误。主要是修改io接口的宏定义和一些非法语法,可以根据编译错误自行修改。
UE4模块对应的Build.cs文件需要加入对zlib库模块的依赖,还需要设置一些变量的值。
public class XXX : ModuleRules { public XXX(ReadOnlyTargetRules Target) : base(Target) { PCHUsage = PCHUsageMode.UseExplicitOrSharedPCHs; OptimizeCode = CodeOptimization.InShippingBuildsOnly; bEnableUndefinedIdentifierWarnings = false; // 为了修复编译错误 bEnableExceptions = true; // 启用std的exception,没启用的话后面做字符编码转换的时候,非Windows平台会有编译错误 PublicDependencyModuleNames.AddRange( new string[] { "Core", "Projects", "zlib" // 依赖zlib模块 } ); } } FString ZipFilename; // zip文件路径,自己赋值 FString ZipDir; // 解压目录,自己赋值 uint32 ErrorCount = 0; // 解压错误的数量 uint32 TotalCount = 0; // 文件总数(包括文件和文件夹) // 1. 打开zip文件。此处需要将FString的编码转换成操作系统使用的编码。 const unzFile& ZFile = unzOpen64(FMiniCodeConvert::WideCharToMultiByte(*ZipFilename).c_str()); // 2. 获取zip文件全局信息 unz_global_info64 ZGlobalInfo; unzGetGlobalInfo64(ZFile, &ZGlobalInfo); // 3. 获取zip文件大小,方便做解压进度记录 const int64 TotalCompressedSize = IFileManager::Get().FileSize(*ZipFilename); int64 CurrentCompressedSize = 0; // 4. 遍历zip中的所有文件,将解压后的文件字节流写入本地文件 unz_file_info64 ZFileInfo; const int NAME_BUFF_SIZE = 512; const int FILE_DATA_INIT_BUFF_SIZE = 512 * 1024; char* Filename = new char[NAME_BUFF_SIZE]; char* FileData = new char[FILE_DATA_INIT_BUFF_SIZE]; int ReadLength = 0; TotalCount = ZGlobalInfo.number_entry; for (int i = 0; i < ZGlobalInfo.number_entry; ++i) { if (i > 0) { unzCloseCurrentFile(ZFile); // 关闭当前文件 unzGoToNextFile(ZFile); // 指向下一个文件 } // 获取当前指向文件的信息 if (unzGetCurrentFileInfo64(ZFile, &ZFileInfo, Filename, NAME_BUFF_SIZE, nullptr, 0, nullptr, 0) != UNZ_OK) { ErrorCount++; continue; } // 打开当前文件,为了做读取 if (unzOpenCurrentFile(ZFile) != UNZ_OK) { ErrorCount++; continue; } // 此处需要将zip文件中名字的编码转换成FString对应的编码 FString FullFilePath = ZipDir / FMiniCodeConvert::MultiByteToWideChar(Filename); if (ZFileInfo.uncompressed_size == 0) { if (FullFilePath.EndsWith(TEXT("/")) || FullFilePath.EndsWith(TEXT("\\"))) { if (!IFileManager::Get().MakeDirectory(*FullFilePath, true)) { ErrorCount++; continue; } } else { if (!FFileHelper::SaveStringToFile(TEXT(""), *FullFilePath, FFileHelper::EEncodingOptions::ForceUTF8WithoutBOM)) { ErrorCount++; continue; } } } else { TSharedPtr<FArchive> ArchivePtr = TSharedPtr<FArchive>(IFileManager::Get().CreateFileWriter(*FullFilePath)); if (ArchivePtr != nullptr) { const double UnCompressRadio = ((double)ZFileInfo.compressed_size) / ZFileInfo.uncompressed_size; const int BlockCount = (ZFileInfo.uncompressed_size + FILE_DATA_INIT_BUFF_SIZE - 1) / FILE_DATA_INIT_BUFF_SIZE; for (int Block = 0; Block < BlockCount; ++Block) { // 读取解压的字节流 ReadLength = unzReadCurrentFile(ZFile, FileData, FILE_DATA_INIT_BUFF_SIZE); ArchivePtr->Serialize(FileData, ReadLength); // 记录当前解压进度,此处可以自己做日志输出或者做一些广播 CurrentCompressedSize += ReadLength * UnCompressRadio; } if(!ArchivePtr->Close()) { ErrorCount++; continue; } } else { ErrorCount++; continue; } } } unzClose(ZFile); delete[] Filename; delete[] FileData; - 头文件
#pragma once #include "CoreMinimal.h" #include <string> class FMiniCodeConvert { public: static std::string WideCharToMultiByte(const TCHAR* WChar); static FString MultiByteToWideChar(const char* MultiByteChar); }; 2. cpp文件
#include "FMiniCodeConvert.h" #include "Internationalization/Culture.h" #include <codecvt> #include <locale> template <class Elem, class Byte = char, class Statype = std::mbstate_t> class TCodeConvertByName : public std::codecvt<Elem, Byte, Statype> { public: explicit TCodeConvertByName(const char* Locname, size_t Refs = 0) : std::codecvt<Elem, Byte, Statype>(Locname, Refs) {} // 根据语言名称构造编码转换结构 explicit TCodeConvertByName(const std::string& Str, size_t Refs = 0) : std::codecvt<Elem, Byte, Statype>(Str.c_str(), Refs) {} // 根据语言名称构造编码转换结构 virtual ~TCodeConvertByName() {} }; typedef TCodeConvertByName<TCHAR> FCodeConvertByName; std::string FMiniCodeConvert::WideCharToMultiByte(const TCHAR* WChar) { #if PLATFORM_WINDOWS // Windows 默认使用的是ANSI编码 const std::string& OSLang = TCHAR_TO_UTF8(*FInternationalization::Get().GetDefaultLanguage()->GetName()); static std::wstring_convert<FCodeConvertByName, TCHAR> StrCnv(new FCodeConvertByName(OSLang)); try { return std::string(StrCnv.to_bytes(WChar)); } catch (std::exception) { return TCHAR_TO_UTF8(WChar); } #endif return TCHAR_TO_UTF8(WChar); } FString FMiniCodeConvert::MultiByteToWideChar(const char* MultiByteChar) { const std::string& OSLang = TCHAR_TO_UTF8(*FInternationalization::Get().GetDefaultLanguage()->GetName()); static std::wstring_convert<FCodeConvertByName, TCHAR> StrCnv(new FCodeConvertByName(OSLang)); try { return StrCnv.from_bytes(MultiByteChar).c_str(); } catch (std::exception) { return UTF8_TO_TCHAR(MultiByteChar); } } FString ZipFilename ; // 生成的zip文件路径,自己赋值 FString ZipDir; // 压缩目录,自己赋值 uint32 ErrorCount = 0; // 解压错误的数量 uint32 TotalCount = 0; // 文件总数(包括文件和文件夹) // 1. 打开zip文件。此处需要将FString的编码转换成操作系统使用的编码。 const zipFile& ZFile = zipOpen64(FMiniCodeConvert::WideCharToMultiByte(*ZipFilename).c_str(), APPEND_STATUS_CREATE); // 2. 计算待压缩文件夹大小,方便做压缩进度记录 int64 TotalUnCompressedSize = 0; int64 CurrentUnCompressedSize = 0; IFileManager::Get().IterateDirectoryRecursively(*ZipDir,[&TotalUnCompressedSize](const TCHAR* FilenameOrDirectory, bool bIsDirectory) { if (!bIsDirectory) { TotalUnCompressedSize += IFileManager::Get().FileSize(FilenameOrDirectory); } return true; }); const int FILE_DATA_INIT_BUFF_SIZE = 512 * 1024; char* FileData = new char[FILE_DATA_INIT_BUFF_SIZE]; // 3. 获取文件夹中的所有文件和目录,添加到zip文件中 TArray<FString> AllFilenames; // file or directories IFileManager::Get().FindFilesRecursive(AllFilenames, *ZipDir, TEXT("*.*"), true, true); TotalCount = AllFilenames.Num(); for (uint32 i = 0; i < TotalCount; ++i) { const FString& Filename = AllFilenames[i]; FDateTime DataTime = IFileManager::Get().GetTimeStamp(*Filename); DataTime = DataTime + (FDateTime::Now() - FDateTime::UtcNow()); // 需要加上本地时区的时间 const int64 LocalFileSize = IFileManager::Get().FileSize(*Filename); zip_fileinfo ZipFileInfo; int32 Year, Month, Day; DataTime.GetDate(Year, Month, Day); ZipFileInfo.tmz_date.tm_year = Year; ZipFileInfo.tmz_date.tm_mon = Month - 1; ZipFileInfo.tmz_date.tm_mday = Day; ZipFileInfo.tmz_date.tm_hour = DataTime.GetHour(); ZipFileInfo.tmz_date.tm_min = DataTime.GetMinute(); ZipFileInfo.tmz_date.tm_sec = DataTime.GetSecond(); ZipFileInfo.dosDate = 0; ZipFileInfo.internal_fa = 0; ZipFileInfo.external_fa = 0; FString LocalFilename = *Filename.Replace(*ZipDir, TEXT("")); // 替换成zip下的相对路径 if (LocalFilename.StartsWith(TEXT("/"))) { LocalFilename = LocalFilename.RightChop(1); } else if (LocalFilename.StartsWith(TEXT("\\"))) { LocalFilename = LocalFilename.RightChop(2); } const bool bDirectory = FPaths::DirectoryExists(AllFilenames[i]); if (bDirectory) { LocalFilename += TEXT("/"); } if (i > 0) { zipCloseFileInZip(ZFile); } // 添加新的文件/目录到zip中 if (zipOpenNewFileInZip64(ZFile, FMiniCodeConvert::WideCharToMultiByte(*LocalFilename).c_str(), &ZipFileInfo, nullptr, 0, nullptr, 0, nullptr, Z_DEFLATED, Z_DEFAULT_COMPRESSION, LocalFileSize >= UINT32_MAX) != ZIP_OK) { ErrorCount++; continue; } if (!bDirectory) { TSharedPtr<FArchive> ArchivePtr = TSharedPtr<FArchive>(IFileManager::Get().CreateFileReader(*Filename)); if (ArchivePtr != nullptr) { const int64 TotalReadSize = ArchivePtr->TotalSize(); const int BlockCount = (TotalReadSize + FILE_DATA_INIT_BUFF_SIZE - 1) / FILE_DATA_INIT_BUFF_SIZE; for (int Block = 0; Block < BlockCount; ++Block) { int CurrReadSize = 0; if (Block == BlockCount - 1) { CurrReadSize = TotalReadSize - Block * FILE_DATA_INIT_BUFF_SIZE; } else { CurrReadSize = FILE_DATA_INIT_BUFF_SIZE; } ArchivePtr->Serialize(FileData, CurrReadSize); if (zipWriteInFileInZip(ZFile, FileData, CurrReadSize) != ZIP_OK) { ErrorCount++; continue; } else { // 记录当前压缩进度,此处可以自己做日志输出或者做一些广播 CurrentUnCompressedSize += CurrReadSize; } } if (!ArchivePtr->Close()) { ErrorCount++; continue; } } else { ErrorCount++; continue; } } } delete[] FileData; zipClose(ZFile, nullptr); - 可以使用FRunnable实现多线程异步压缩和解压
- 可以修改minizip以支持其他的文件压缩算法
zipfile可以很方便地读取、写入、提取zip文件。如果在日常工作中经常需要将某些文件打包到zip,不妨试试用它实现一定程度的自动化办公。另外 Python 的 Zip imports 也是一个有趣的话题:从 zip 文件中 import 已经预先编译好的包或模块(.pyc文件)。
翻译信息
原文链接: https:// realpython.com/python-z ipfile/
作者:Leodanis Pozo Ramos
译者:muzing
译文链接: https:// muzing.top/posts/ 2a/
翻译时间:2022.3
允许转载,转载必须保留全部翻译信息,且不能对正文有任何修改

本文首发于我的博客,建议点击下方链接访问原文,阅读体验更佳。也可以查看更多技术文章。
Python zipfile:高效处理 ZIP 文件(翻译)
Python 的 zipfile 是一个旨在操作 ZIP 文件的标准库模块。在归档和压缩数字数据时,该文件格式是一种广泛采用的行业标准。可以使用它将几个相关文件打包在一起。它还可以减小文件大小并节省磁盘空间。最重要的是,它促进了计算机网络上的数据交换。
作为 Python 开发者或 DevOps 工程师,了解如何使用 zipfile 模块创建、读取、写入、填充、提取和列出 ZIP 文件是一项有用的技能。
在本教程中,您将学到如何:
- 使用 Python 的
zipfile从 ZIP 文件中读取、写入和提取文件 - 使用
zipfile读取关于 ZIP 文件内容的元数据(metadata) - 使用
zipfile来操作现有 ZIP 文件中的成员文件 - 创建新的 ZIP 文件以存档和压缩文件
如果您经常处理 ZIP 文件,那么这些知识可以帮助您精简工作流程,从而自信地处理文件。
为充分使用本教程,您应该了解处理文件、使用 ref="https://realpython.com/python-with-statement/">with 语句、使用 pathlib 处理文件系统路径,以及使用类和面向对象编程。
要获取您将用于编写本教程中的示例的代码文件和归档,请单击本链接。
ZIP 文件 是当今数字世界中最广为人知和流行的工具。这些文件相当流行,广泛用于计算机网络(尤其是 Internet)上的跨平台数据交换。
您可以使用 ZIP 文件将常规文件打包到一个归档中,压缩数据以节省一些磁盘空间,分发数字产品等等。在本教程中,您将学习如何使用 Python 的 zipfile 模块操作 ZIP 文件。
由于关于 ZIP 文件的术语有时让人感到困惑,因此本教程将遵循以下有关术语的约定:
| 术语 | 含义 |
|---|---|
| ZIP 文件, ZIP 归档,或归档 | 使用 ZIP 格式的物理文件 |
| 文件 | 常规的计算机文件 |
| 成员文件 | 作为现有 ZIP 文件的一部分的文件 |
将这些术语牢记于心,有助于避免在阅读以下部分时混淆。现在您已经准备好继续学习如何在 Python 代码中高效操作 ZIP 文件!
您可能已经遇到并使用过 ZIP 文件。是的,文件扩展名为 .zip 的文件无处不在!ZIP 文件,也称为ZIP 归档,是使用 ZIP 文件格式的文件。
PKWARE 是创建并首先实现此文件格式的公司。该公司整理并维护了当前的格式规范,该规范为公开可用的,允许创建使用 ZIP 文件格式读写文件的产品、程序和进程。
ZIP 文件格式是一种跨平台、可互操作的文件存储和传输格式。它结合了无损数据压缩、文件管理以及数据加密。
数据压缩并非一个归档成为 ZIP 文件的必选项。因此您可以在 ZIP 归档中包含压缩或未压缩的成员文件。ZIP 文件格式支持数种压缩算法,但其中 Deflate 是最常见的。该格式还支持使用 CRC32 进行信息完整性检查。
尽管还有其他类似的归档格式,比如 RAR 和 TAR 文件,但 ZIP 文件格式已经迅速成为高效数据存储和通过计算机网络进行数据交换的通用标准。
ZIP 文件无处不在。例如,Microsoft Office 和 Libre Office 等 office 套件依赖 ZIP 文件格式作为其 文档容器文件。这意味着 .docx 、.xlsx、 .pptx 、.odt 、.ods 、 .odp 文件实际上是包含构成每个文档的多个文件和文件夹的 ZIP 归档。其他使用 ZIP 格式的常见文件包括 .jar、 .war 和 .epub 文件。
您可能熟悉 GitHub,它为使用 Git 的软件开发和版本控制提供 Web 托管。当您将软件下载到本地计算机时,GitHub 使用 ZIP 文件打包软件项目。例如,您可以在 ZIP 文件中下载 Python Basics: A Practical Introduction to Python 3 书的练习解决方案,或者下载您选择的其他任何项目。
ZIP 文件运行您将文件聚合、压缩和加密到单个可互操作且可移植的容器中。您可以流式传输 ZIP 文件、将它们分割成段、使其自解压等。
了解如何创建、读取、写入和提取 ZIP 文件对于使用计算机和数字信息的开发者和专业人士来说可能是一项有用的技能。除其他优点外,ZIP 文件还允许您:
- 在不丢失信息的前提下减小文件大小和存储需求
- 由于减小了文件大小和单文件传输,提高了网络传输速度
- 将多个文件打包到一个归档中,以实现高效管理
- 将您的代码打包到一个归档中,以进行分发
- 通过使用加密来保护数据,这是当今的普遍需求
- 保证信息完整性,避免对数据意外或恶意更改
如果您正在寻找一种灵活、可移植且可靠的方式来归档您的数字文件,这些特性使得 ZIP 文件成为 Python 工具箱的实用补充。
是的!Python 有几个工具可以让您操作 ZIP 文件。其中一些工具在 Python 标准库 中可用。它们包括用于使用特定压缩算法(例如 zlib 、bz2 、lzma 和其他)压缩和解压缩数据的低级库。
Python 还提供了一个名为“zipfile”的高级模块,专门用于创建、读取、写入、提取和列出 ZIP 文件的内容。 在本教程中,您将了解 Python 的 zipfile 以及如何有效地使用它。
Python 的 zipfile 提供了便于使用的类和函数,允许创建、读取、写入、提取和列出 ZIP 文件包含的内容。以下是 zipfile 支持的一些附加功能:
- 大于 4 GiB 的 ZIP 文件(ZIP64 files)
- 数据解密
- 多种压缩算法,例如 Deflate、 Bzip2 与 LZMA
- 使用 CRC32 进行信息完整性检查
请注意,zipfile 确实有一些局限性。例如,当前的数据解密功能可能非常慢,因为它使用纯 Python 代码。该模块无法处理加密 ZIP 文件的创建。最后,也不支持使用多磁盘(multi-disk) ZIP 文件。尽管有这些局限性,zipfile 仍然是一个很棒且实用的工具。继续阅读以探索其功能。
在 zipfile 模块中,您会找到 ZipFile 类。这个类的工作方式很像 Python 内置的 open() 函数,允许使用不同的模式打开 ZIP 文件。读取模式("r")为默认值。也可以使用写入("w")、追加("a")和独占("x")模式。稍后您将详细学习其中每一项。
zipfile 实现了上下文管理器协议,以便于在一个 ref="https://realpython.com/python-with-statement/">with 语句中使用该类。此特性允许您快速打开和使用 ZIP 文件,而无需担心在完成工作后关闭文件。
在编写任何代码之前,请确保您拥有将要使用的文件和归档的副本:
要获取您将用于编写本教程中的示例的代码文件和归档,请单击本链接。
请将下载的资源移入您的家目录(home folder)下名为 python-zipfile/ 的目录中,以准备好工作环境。将文件放在正确的位置后,移动至新创建的目录并在那里启动 Python 交互式会话。
译者注:对于 Windows 10/11 用户,可以在任意路径创建该目录。在文件资源管理器中进入目录后,按住 Shift 键的同时鼠标右键单击空白处,然后选择“在此处打开 Powershell 窗口”,输入
python 命令即可。
首先从读取名为 sample.zip 的 ZIP 文件开始热身。为此,可以在读取模式下使用 ZipFile :
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... archive.printdir() ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428ZipFile 初始化的第一个参数可以是一个字符串,表示需要打开的 ZIP 文件的路径。这个参数也可以接受文件对象和路径类对象。在此示例中,使用了基于字符串的路径。
ZipFile 的第二个参数是一个单字母的字符串,表示用于打开文件的模式。正如您在本节开头所了解的,根据需求,ZipFile 可以接受四种可能的模式。mode 位置参数默认为 "r",所以如果想以只读模式打开归档,可以省略它。
在 with 语句中,在 archive 上调用 .printdir()。archive 变量现在包含 ZipFile 本身的实例。此函数提供了一种在屏幕上显示底层 ZIP 文件内容的快捷方法。其输出为易读的表格形式,有三列信息:
File NameModifiedSize
如果您想在尝试打开之前确保目标为有效的 ZIP 文件,那么可以将 ZipFile 包装在 href="https://realpython.com/python-exceptions/#the-try-and-except-block-handling-exceptions">try … except 语句中,并捕获任何 BadZipFile 异常:
>>> import zipfile >>> try: ... with zipfile.ZipFile("sample.zip") as archive: ... archive.printdir() ... except zipfile.BadZipFile as error: ... print(error) ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428 >>> try: ... with zipfile.ZipFile("bad_sample.zip") as archive: ... archive.printdir() ... except zipfile.BadZipFile as error: ... print(error) ... File is not a zip file第一个示例成功打开 sample.zip 而不引发 BadZipFile 异常。那是因为 sample.zip 具有有效的 ZIP 格式。另一方面,第二个示例无法成功打开 bad_sample.zip ,因为该文件不是有效的 ZIP 文件。
为检查 ZIP 文件的有消息,您还可以使用 is_zipfile() 函数:
>>> import zipfile >>> if zipfile.is_zipfile("sample.zip"): ... with zipfile.ZipFile("sample.zip", "r") as archive: ... archive.printdir() ... else: ... print("File is not a zip file") ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428 >>> if zipfile.is_zipfile("bad_sample.zip"): ... with zipfile.ZipFile("bad_sample.zip", "r") as archive: ... archive.printdir() ... else: ... print("File is not a zip file") ... File is not a zip file在这些示例中,使用一个 is_zipfile() 作为条件的条件语句。该函数接受一个保存文件系统中 ZIP 文件的路径的 filename 参数。此参数可以接受字符串、类文件或类路径对象。如果 filename 是有效的 ZIP 文件,则该函数返回 True。否则返回 False。
现在假设您想使用 ZipFile 将 hello.txt 添加到 hello.zip 归档中。为此,可以使用写入模式("w")。该模式打开一个 ZIP 文件进行写入。如果目标 ZIP 文件存在,则 "w" 模式会截断它并写入您传入的任何新内容。
注意: 如果您使用ZipFile处理现有文件,那么应该小心使用"w"模式。您可能截断 ZIP 文件并丢失所有原有内容。
如果目标 ZIP 文件不存在,则 ZipFile 会在您关闭归档时为您创建它:
>>> import zipfile >>> with zipfile.ZipFile("hello.zip", mode="w") as archive: ... archive.write("hello.txt") ...运行此代码后,python-zipfile/ 目录中将有一个 hello.zip 文件。如果使用 .printdir() 列出文件内容,那么 hello.txt 会在那里。在此示例中,可用在 ZipFile 对象上调用 .write()。此方法允许您将成员文件写入 ZIP 归档。注意 .write() 的参数应是已存在的文件。
注意: 当您在写模式下使用类且目标归档不存在时,ZipFile足够智能,可以创建一个新的归档。然而,如果这些目录尚不存在,则该类不会在目标 ZIP 文件的路径中创建新目录。
这就解释了为何如下代码无法工作:
```python
import zipfile
with zipfile.ZipFile("missing/hello.zip", mode="w") as archive: ... archive.write("hello.txt") ... Traceback (most recent call last): ... FileNotFoundError: [Errno 2] No such file or directory: 'missing/hello.zip' ```
因为目标hello.zip文件路径中的missing/目录不存在,所以会出现FileNotFoundError异常。
追加模式("a")允许您将新的成员文件追加到现有 ZIP 文件。此模式不会截断归档,故其原始内容是安全的。如果目标 ZIP 文件不存在,则 "a" 模式会为您创建一个新文件,然后追加作为参数传入 .write() 的任何文件。
为尝试 "a" 模式,更进一步添加 new_hello.txt 文件到新创建的 hello.zip 归档中:
>>> import zipfile >>> with zipfile.ZipFile("hello.zip", mode="a") as archive: ... archive.write("new_hello.txt") ... >>> with zipfile.ZipFile("hello.zip") as archive: ... archive.printdir() ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 new_hello.txt 2021-08-31 17:13:44 13此处,使用追加模式将 new_hello.txt 添加到 hello.zip 文件中。然后运行 .printdir() 以确认新文件已存在于 ZIP 文件中。
ZipFile 还支持独占模式("x")。 此模式允许您独占地创建新的 ZIP 文件并将新的成员文件写入其中。 当想要创建一个新的 ZIP 文件而不覆盖现有文件时,使用独占模式。 如果目标文件已存在,则会得到 FileExistsError。
最后,如果您使用 "w"、"a" 或 "x" 模式创建一个 ZIP 文件,然后在不添加任何成员文件的情况下关闭归档,则 ZipFile 会创建一个具有适当 ZIP 格式的空归档。
您已将 .printdir() 付诸实践。这是一种实用的方法,可用于快速列出 ZIP 文件包含的内容。与 .printdir() 一道,ZipFile 类提供了几种从现有 ZIP 文件中提取元数据的便捷方法。
以下是这些方法的摘要:
| 方法 | 描述 |
|---|---|
| .getinfo(filename) | 返回一个关于 filename 提供的成员文件的信息的 ZipInfo 对象。注意 filename 必须包含底层 ZIP 文件中目标文件的路径。 |
| .infolist() | 返回一个 ZipInfo 对象列表,每个文件占一项。 |
| .namelist() | 返回一个包含底层归档中所有成员文件名的列表。该列表中的名称是 .getinfo() 的有效参数。 |
使用这三个工具,您可以检索许多关于 ZIP 文件内容的实用信息。例如,下面的例子使用了 .getinfo():
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... info = archive.getinfo("hello.txt") ... >>> info.file_size 83>>> import datetime >>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... for info in archive.infolist(): ... print(f"Filename: {info.filename}") ... print(f"Modified: {datetime.datetime(*info.date_time)}") ... print(f"Normal size: {info.file_size} bytes") ... print(f"Compressed size: {info.compress_size} bytes") ... print("-" * 20) ... Filename: hello.txt Modified: 2021-09-07 19:50:10 Normal size: 83 bytes Compressed size: 83 bytes -------------------- Filename: lorem.md Modified: 2021-09-07 19:50:10 Normal size: 2609 bytes Compressed size: 2609 bytes -------------------- Filename: realpython.md Modified: 2021-09-07 19:50:10 Normal size: 428 bytes Compressed size: 428 bytes -------------------- >>> info.compress_size 83 >>> info.filename 'hello.txt' >>> info.date_time (2021, 9, 7, 19, 50, 10)正如您在上表中所了解到的,.getinfo() 将成员文件作为参数,并返回一个包含关于其信息的 ZipInfo 对象。
注意:ZipInfo并不想要被直接实例化。.getinfo()和.infolist()方法在被调用时会自动返回ZipInfo对象。然而,ZipInfo包含一个名为.from_file()的类方法,它允许您在需要时显式地实例化该类。
ZipInfo 对象有一些属性,可以检索有关目标成员文件的实用信息。例如,.file_size 和 .compress_size 分别保存未压缩原始文件和压缩后文件的大小(以字节为单位)。该类还有一些其他实用的属性,例如 .filename 和 .date_time ,它们返回文件名和最后修改日期。
注意: 默认情况下,
ZipFile 不会压缩输入文件以将其添加到最终归档中。这就是上例中 size 和 compressed size 大小相同的原因。您将在下面的压缩文件和目录部分了解有关此话题的更多信息。
使用 .infolist() ,您可以从指定归档中提取所有文件信息。以下是一个使用此方法生成最小报告的示例,其中包含有关 sample.zip 归档中所有成员文件的信息:
>>> import datetime >>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... for info in archive.infolist(): ... print(f"Filename: {info.filename}") ... print(f"Modified: {datetime.datetime(*info.date_time)}") ... print(f"Normal size: {info.file_size} bytes") ... print(f"Compressed size: {info.compress_size} bytes") ... print("-" * 20) ... Filename: hello.txt Modified: 2021-09-07 19:50:10 Normal size: 83 bytes Compressed size: 83 bytes -------------------- Filename: lorem.md Modified: 2021-09-07 19:50:10 Normal size: 2609 bytes Compressed size: 2609 bytes -------------------- Filename: realpython.md Modified: 2021-09-07 19:50:10 Normal size: 428 bytes Compressed size: 428 bytes --------------------for 循环迭代来自 .infolist() 的 ZipInfo 对象,检索文件名、最后修改日期、未压缩大小 ,以及每个成员文件的压缩后大小。在此示例中,使用 datetime 以人类易读的方式格式化日期。
注: 上面的例子改编自zipfile — ZIP Archive Access。
如果只需要对 ZIP 文件执行快速检查并列出其成员文件的名称,那么可以使用 .namelist():
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... for filename in archive.namelist(): ... print(filename) ... hello.txt lorem.md realpython.md因为此输出中的文件名是 .getinfo() 的有效参数,所以可以结合这两种方法来仅检索关于特定成员文件的信息。
例如,可能有一个 ZIP 文件,其中包含不同类型的成员文件(.docx、.xlsx、.txt 等)。但并不需要使用 .infolist() 获取完整信息,只需获取有关 .docx 文件的信息。那么可以按扩展名过滤文件并仅在 .docx 文件上调用 .getinfo() 。 来试一试吧!
有时需要在不解压一个 ZIP 文件的情况下读取指定成员文件。为此,可以使用 .read()。此方法接收一个成员文件的 name 并将该文件的内容作为字节返回:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... for line in archive.read("hello.txt").split(b"\n"): ... print(line) ... b'Hello, Pythonista!' b'' b'Welcome to Real Python!' b'' b"Ready to try Python's zipfile module?" b''为使用 .read(),需要以读取或追加模式打开 ZIP 文件。注意 .read() 以字节流的形式返回目标文件的内容。在此示例中,以换行符 "\n" 作为分隔符,使用 .split() 将流拆分为行。因为 .split() 正在在一个字节对象上进行操作,所以需要在字符串前添加前导 b 作为参数
ZipFile.read() 还接受名为 pwd 的第二个位置参数。此参数允许您提供用以读取加密文件的密码。要尝试此功能,您可以使用随本教程材料下载的 sample_pwd.zip 文件:
>>> import zipfile >>> with zipfile.ZipFile("sample_pwd.zip", mode="r") as archive: ... for line in archive.read("hello.txt", pwd=b"secret").split(b"\n"): ... print(line) ... b'Hello, Pythonista!' b'' b'Welcome to Real Python!' b'' b"Ready to try Python's zipfile module?" b'' >>> with zipfile.ZipFile("sample_pwd.zip", mode="r") as archive: ... for line in archive.read("hello.txt").split(b"\n"): ... print(line) ... Traceback (most recent call last): ... RuntimeError: File 'hello.txt' is encrypted, password required for extraction在第一个例子中,提供密码 secret 来读取加密文件。pwd 参数接受字节类型的值。如果在未提供所需密码的情况下对加密文件使用 .read() ,则会得到 RuntimeError,如第二个示例所示。
注意: Python 的
zipfile 支持解密。但是它不支持创建加密 ZIP 文件。这就是需要使用外部文件归档工具来加密文件的原因。
一些流行的文件归档工具包括 Windows 上的 7z 和 WinRAR,Linux 上的 Ark 和 GNOME Archive Manager,macOC 上的 Archiver。
对于大型加密 ZIP 文件,请留意解密操作可能会非常慢,因为它是在纯 Python 中实现的。在这种情况下,请考虑使用专门的程序来处理您的归档而不是使用 zipfile。
如果经常使用加密文件,那么可能希望避免每次调用 .read() 或其他接受 pwd 参数的方法时提供密码。如果是这种情况,可以使用 ZipFile.setpassword() 设置一个全局密码:
>>> import zipfile >>> with zipfile.ZipFile("sample_pwd.zip", mode="r") as archive: ... archive.setpassword(b"secret") ... for file in archive.namelist(): ... print(file) ... print("-" * 20) ... for line in archive.read(file).split(b"\n"): ... print(line) ... hello.txt -------------------- b'Hello, Pythonista!' b'' b'Welcome to Real Python!' b'' b"Ready to try Python's zipfile module?" b'' lorem.md -------------------- b'# Lorem Ipsum' b'' b'Lorem ipsum dolor sit amet, consectetur adipiscing elit. ...使用 .setpassword(),只需要提供一次密码。ZipFile 使用该唯一密码来解密所有成员文件。
相反,如果您的 ZIP 文件的各个成员文件具有不同的密码,那么需要使用 .read() 的 pwd 参数为每个文件提供特定的密码:
>>> import zipfile >>> with zipfile.ZipFile("sample_file_pwd.zip", mode="r") as archive: ... for line in archive.read("hello.txt", pwd=b"secret1").split(b"\n"): ... print(line) ... b'Hello, Pythonista!' b'' b'Welcome to Real Python!' b'' b"Ready to try Python's zipfile module?" b'' >>> with zipfile.ZipFile("sample_file_pwd.zip", mode="r") as archive: ... for line in archive.read("lorem.md", pwd=b"secret2").split(b"\n"): ... print(line) ... b'# Lorem Ipsum' b'' b'Lorem ipsum dolor sit amet, consectetur adipiscing elit. ...在这个例子中,使用 secret1 作为读取 hello.txt 的密码,secret2 作为读取 lorem.md 的。最后一个需要考虑的细节是,当使用 pwd 参数时,会覆盖可能已经通过 .setpassword() 设置的任何归档级密码。
注意: 在使用不支持的压缩算法的 ZIP 文件上调用.read()会引发NotImplementedError。如果所需的压缩模块在您的 Python 安装中不可用,也会收到错误信息。
如果您正在寻找一种更灵活的方式来读取成员文件并创建和添加新的成员文件到归档中,那么 ZipFile.open() 适合您。与内置的 open() 函数一样,该方法实现了上下文管理器协议,因此它支持 with 语句:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... with archive.open("hello.txt", mode="r") as hello: ... for line in hello: ... print(line) ... b'Hello, Pythonista!\n' b'\n' b'Welcome to Real Python!\n' b'\n' b"Ready to try Python's zipfile module?\n"在本例中,打开 hello.txt 以读取。open() 的第一个参数是 name ,表示要打开的成员文件。第二个参数是模式,像往常一样默认为 "r"。ZipFile.open() 还接受一个用于打开加密文件的 pwd 参数。此参数与 .read() 中的同名参数作用相同。
您还可以将 .open() 与 "w" 模式组合使用。此模式允许创建一个新的成员文件,向其中写入内容,最后将该文件附加到底层归档,应以追加模式打开:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="a") as archive: ... with archive.open("new_hello.txt", "w") as new_hello: ... new_hello.write(b"Hello, World!") ... 13 >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... archive.printdir() ... print("------") ... archive.read("new_hello.txt") ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428 new_hello.txt 1980-01-01 00:00:00 13 ------ b'Hello, World!'在第一个代码片段中,以追加模式("a")打开 sample.zip 。然后通过以 "w" 模式调用 .open() 创建 new_hello.txt。此函数返回一个支持 .write() 的类文件对象,它允许您将字节写入新创建的文件。
注意: 需要为.open()提供一个非现有的文件名。如果使用底层归档中已经存在的文件名,那么会最终得到一个重复的文件和一个UserWarning异常。
在此示例中,将 b'Hello, World!' 写入 new_hello.txt。当执行流退出内部 with 语句时,Python 将输入字节写入成员文件。当外部 with 语句退出时,Python 会将 new_hello.txt 写入底层 ZIP 文件 sample.zip。
第二个代码片段证实了 new_hello.txt 现在是 sample.zip 的成员文件。在这个示例的输出中需要注意的一个细节是,.write() 将新添加的文件的 Modified 日期设置为 1980-01-01 00:00:00。这是一个奇怪的行为,使用此方法时应牢记。
正如您在上一节中所了解的,可以使用 .read() 和 .write() 方法来实现不从 ZIP 归档中提取而直接读写成员文件。这两种方法都仅适用于字节。
然而,当您有一个包含文本文件的 ZIP 归档时,可能希望将其内容作为文本而不是字节来读取。至少有两种方法可以做到这一点。可以使用:
bytes.decode()io.TextIOWrapper
因为 ZipFile.read() 以字节形式返回目标成员文件的内容,故 .decode() 可以直接对这些字节进行操作。.decode() 方法使用给定的字符编码格式将 bytes 对象解码为字符串。
以下为如何使用 .decode() 以从 sample.zip 归档中的 hello.txt 文件中读取文本:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... text = archive.read("hello.txt").decode(encoding="utf-8") ... >>> print(text) Hello, Pythonista! Welcome to Real Python! Ready to try Python's zipfile module?在此示例中,将 hello.txt 的内容作为字节读取。然后调用 .decode() 来将字节解码为使用 UTF-8 作为编码的字符串。为设置 encoding 参数,使用 "utf-8" 字符串。然而,可以使用任何其他有效编码,例如 UTF-16 或 cp1252,用不区分大小写的字符串表示它们。注意 "utf-8" 是 .decode() 的 encoding 参数的默认值。
时刻注意,您需要事先知道要使用 .decode() 处理的任何成员文件的字符编码格式。如果使用了错误的字符编码,那么代码将无法将底层字节正确解码为文本,最终可能会得到大量无法辨认的字符。
译者注:对于简体中文读者,最常见的一个乱码错误是,中文文本文件使用 Windows 默认的GB2312编码保存,而此处被以默认的UTF-8解码。因此见到许多“烫烫烫的锟斤拷”时不必惊慌,指定使用GB2312再尝试读取一次,很可能便解决了问题。
从成员文件中读取文本的第二个选项是使用 io.TextIOWrapper 对象,它提供具有缓冲的文字流。这次需要使用 .open() 而不是 .read()。以下是一个使用 io.TextIOWrapper 将 hello.txt 成员文件作为文字流读取的示例:
>>> import io >>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... with archive.open("hello.txt", mode="r") as hello: ... for line in io.TextIOWrapper(hello, encoding="utf-8"): ... print(line.strip()) ... Hello, Pythonista! Welcome to Real Python! Ready to try Python's zipfile module?在本例的内层 with 语句中,从 sample.zip 归档中打开成员文件 hello.txt。然后将生成的二进制类文件对象 hello 作为参数传递给 io.TextIOWrapper。这通过使用 UTF-8 字符编码格式解码 hello 的内容来创建有缓冲的文字流。因此,可以直接从目标成员文件中获得文字流。
就像 .encode() 一样,io.TextIOWrapper 类接受一个 encoding 参数。您应该始终为此参数指定一个值,因为默认文本编码取决于运行代码的操作系统,并且可能并非尝试解码的文件的正确值。
提取给定归档的内容是对 ZIP 文件执行的最常见操作之一。根据您的需要,可能希望一次提取一个文件,或一次提取所有文件。
ZipFile.extract() 可以完成第一个任务。此方法接受一个 member 成员文件的名称,并将其提取到由 path 指定的目录。目标 path 默认为当前目录:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... archive.extract("new_hello.txt", path="output_dir/") ... 'output_dir/new_hello.txt'现在 new_hello.txt 将会出现在 output_dir/ 目录中。如果目标文件名已存在于输出目录中,则 .extract() 将不经请求确认直接覆盖它。如果输出目录不存在,则 .extract() 会为您创建它。注意 .extract() 返回提取文件的路径。
成员文件的名称必须是 .namelist() 返回的文件全名。它也可以是一个包含文件信息的 ZipInfo 对象。
您还可以将 .extract() 用于加密文件。在这种情况下,需要提供所需的 pwd 参数或使用 .setpassword() 设置归档级密码。
当涉及到从归档中提取所有成员文件时,可以使用 .extractall()。顾名思义,此方法将所有成员文件提取到目标路径(默认为当前目录):
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... archive.extractall("output_dir/") ...运行此代码后,sample.zip 中的所有当前内容将出现在 out_dir/ 目录中。如果将一个不存在的目录传递给 .extractall(),那么该方法会自动创建这个目录。最后,如果目标目录中已经存在任何成员文件,那么 .extractall() 将不经请求确认直接覆盖掉它们,所以要小心。
如果只需要从给定归档中提取一些成员文件,则可以使用 members 参数。此参数接受成员文件列表,即手头归档中全部文件列表的子集。最后,就像 .extract() 一样,.extractall() 方法也接受 pwd 参数来提取加密文件。
有时候,不使用 with 语句可以便捷地打开一个给定的 ZIP 文件。在这些情况下,需要在使用后手动关闭归档以完成所有写入操作并释放获取的资源。
为此,可以在 ZipFile 对象上调用 .close():
>>> import zipfile >>> archive = zipfile.ZipFile("sample.zip", mode="r") >>> # 在代码的不同部分使用归档 >>> archive.printdir() File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428 new_hello.txt 1980-01-01 00:00:00 13 >>> # 完成后关闭归档 >>> archive.close() >>> archive <zipfile.ZipFile [closed]>调用 .close() 会关闭 archive 。在退出程序之前,必须调用 .close()。否则可能无法执行某些写入操作。例如,如果打开一个 ZIP 文件追加("a")新的成员文件,则需要关闭归档以写入文件。
到目前为止,您已经学会了如何操纵现有的 ZIP 文件。您已经学会了使用 ZipFile 的不同模式来读取、写入和追加成员文件。您还学习了如何读取相关元数据以及如何提取给定 ZIP 文件的内容。
在本节中,您将编写一些练习示例,帮助您学习如何使用 zipfile 和其他 Python 工具从多个输入文件和整个目录创建 ZIP 文件。您还将学习如何使用 zipfile 进行文件压缩等。
有时您需要从多个相关的文件创建 ZIP 归档。这样将所有的文件放在一个容器中,以便通过计算机网络分发或与朋友同事分享。为此可以创建目标文件列表并使用 ZipFile 和循环将它们写入归档:
>>> import zipfile >>> filenames = ["hello.txt", "lorem.md", "realpython.md"] >>> with zipfile.ZipFile("multiple_files.zip", mode="w") as archive: ... for filename in filenames: ... archive.write(filename) ...此处,创建了一个 ZipFile 对象,并将所需的归档名称作为其第一个参数。"w" 模式允许您将成员文件写入最终的 ZIP 文件。
for() 循环遍历您输入的文件列表,并使用 .write() 将它们写入底层 ZIP 文件。一旦程序流退出 with 语句,ZipFile 会自动关闭归档,保存更改。现在获得了一个包含原始文件列表中所有文件的 multiple_files.zip 归档。
将一个目录中的内容打包到单个归档中是 ZIP 文件的另一个日常用法。Python 有几个工具可以与 zipfile 一起使用来完成这项任务。例如,可以使用 pathlib 读取给定目录的内容。有了这些信息,可以使用 ZipFile 创建一个容器归档。
在 python-zipfile/ 目录中,有一个名为 source_dir/ 的子目录,内容如下:
source_dir/ │ ├── hello.txt ├── lorem.md └── realpython.md在 source_dir/ 中,只有三个普通文件。因为目录不包含子目录,所以可以使用 pathlib.Path.iterdir() 直接迭代其内容。按照这个思路,以下是从 source_dir/ 的内容构建 ZIP 文件的方法:
>>> import pathlib >>> import zipfile >>> directory = pathlib.Path("source_dir/") >>> with zipfile.ZipFile("directory.zip", mode="w") as archive: ... for file_path in directory.iterdir(): ... archive.write(file_path, arcname=file_path.name) ... >>> with zipfile.ZipFile("directory.zip", mode="r") as archive: ... archive.printdir() ... File Name Modified Size realpython.md 2021-09-07 19:50:10 428 hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609在此示例中,从源目录创建一个 pathlib.Path 对象。第一个 with 语句创建了一个可以写入的 ZipFile 对象。然后对 .iterdir() 的调用会返回一个遍历底层目录中条目的迭代器。
因为在 source_dir/ 中没有任何子目录,.iterdie() 函数只生成(yield)文件。for 循环遍历文件并将它们写入归档。
在此示例中,将 file_path.name 传递给 .write() 的第二个参数。此参数名为 arcname,保存着生成的归档中成员文件的名称。到目前为止,以上所有示例都依赖于 arcname 的默认值,即与作为第一个参数传递给 .write() 的文件名相同。
如果不将 file_path.name 传递给 arcname,那么源目录将作为 ZIP 文件的根目录。根据您的需要,这也可能是有效的结果。
现在查看工作目录中的 root_dir/ 文件夹。在此例中,您会发现以下结构:
root_dir/ │ ├── sub_dir/ │ └── new_hello.txt │ ├── hello.txt ├── lorem.md └── realpython.md此处有普通文件和一个包含单个文件的子目录。如果想创建一个具有相同内部结构的 ZIP 文件,那么需要一个工具来递归地遍历 root_dir/ 下的目录树。
以下是如何使用 zipfile 和 pathlib 模块中的Path.rglob() 来 zip 一个像上面那个一样的完整的目录树的方法:
>>> import pathlib >>> import zipfile >>> directory = pathlib.Path("root_dir/") >>> with zipfile.ZipFile("directory_tree.zip", mode="w") as archive: ... for file_path in directory.rglob("*"): ... archive.write( ... file_path, ... arcname=file_path.relative_to(directory) ... ) ... >>> with zipfile.ZipFile("directory_tree.zip", mode="r") as archive: ... archive.printdir() ... File Name Modified Size sub_dir/ 2021-09-09 20:52:14 0 realpython.md 2021-09-07 19:50:10 428 hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 sub_dir/new_hello.txt 2021-08-31 17:13:44 13在此示例中,使用 Path.rglob() 递归遍历 root_dir/ 下的目录树。然后将每个文件和子目录写入目标 ZIP 归档。
这一次,使用 Path.relative_to() 来获取每个文件的相对路径,然后将其结果传递给 .write() 的第二个参数。这样生成的 ZIP 文件最终具有与源目录相同的内部结构。再一次,如果您希望源目录作为 ZIP 文件的根目录,则可以去掉这个参数。
如果您的文件占用了太多磁盘空间,那么可以考虑压缩它们。Python 的 zipfile 支持一些流行的压缩方法。但该模块默认情况下不会压缩文件。如果想让文件更小,那么需要显式地为 ZipFile 提供一种压缩方法。
通常,术语 stored 指代写入未压缩的 ZIP 文件的成员文件。这就是为什么 ZipFile 的默认压缩方法称为 ZIP_STORED,它实际上是指简单存储在归档中未压缩的成员文件。
compression 方法是 ZipFile 初始化方法的第三个参数。如果想在文件写入 ZIP 归档时压缩文件,则可以将此参数设置为以下常量之一:
| 常量 | 压缩方法 | 所需模块 |
|---|---|---|
| zipfile.ZIP_DEFLATED | Deflate | zlib |
| zipfile.ZIP_BZIP2 | Bzip2 | bz2 |
| zipfile.ZIP_LZMA | LZMA | lzma |
这些是您目前可以与 ZipFile 一起使用的压缩方法。除此之外的方法会引发 NotImplementedError。从 Python 3.10 开始,zipfile 没有其他额外可用的压缩方法。
作为一项附加的 requirement,如果选择其中一种方法,则为其提供支持的压缩模块必须在您的 Python 安装中可用。否则,会得到一个 RuntimeError 异常,然后代码会崩溃。
在压缩文件时,另一个与 ZipFile 相关的参数是 compresslevel。此参数控制使用的压缩级别。
使用 Deflate 方法,compresslevel 可以取从 0 到 9 的整数。使用 Bzip2 方法,可以传递从 1 到 9 的整数。在这两种情况下,当压缩级别增加时,压缩率会更高,压缩速度会更慢。
注意: PNG、JPG、MP3 之类的二进制文件,已经使用了某种压缩方式。因此,将它们添加到 ZIP 文件可能并不会使数据变得更小,因为它已经被压缩到一定程度。
现在假设您要使用 Deflate 方法来归档和压缩给定目录的内容(这是 ZIP 文件中最常用的方法)。为此可以运行以下代码:
>>> import pathlib >>> from zipfile import ZipFile, ZIP_DEFLATED >>> directory = pathlib.Path("source_dir/") >>> with ZipFile("comp_dir.zip", "w", ZIP_DEFLATED, compresslevel=9) as archive: ... for file_path in directory.rglob("*"): ... archive.write(file_path, arcname=file_path.relative_to(directory)) ...在此示例中,将 9 传递给 compresslevel 以获得最大压缩。提供此参数时要使用关键字参数。这是因为 compresslevel 并非 ZipFile 初始化时的第四个位置参数。
注意:ZipFile的初始化时,接受名为allowZip64的第四个参数。这是一个布尔参数,告诉ZipFile为大于 4 GB 的文件使用.zip64扩展。
运行此代码后,在当前目录中会出现一个 comp_dir.zip 文件。如果将该文件的大小与原始 sample.zip 文件的进行比较,会发现文件大小显著减小。
依次创建 ZIP 文件可能是日常编程中的另一个常见需求。例如,可能需要创建一个包含或不包含内容的初始 ZIP 文件,然后在新成员文件可用时立即追加它们。在这种情况下,需要多次打开和关闭目标 ZIP 文件。
为解决这个问题,可以在追加模式("a")下使用 ZipFile,像先前那样。此模式允许您安全地将新成员文件追加到 ZIP 归档而不截断其当前内容:
>>> import zipfile >>> def append_member(zip_file, member): ... with zipfile.ZipFile(zip_file, mode="a") as archive: ... archive.write(member) ... >>> def get_file_from_stream(): ... """Simulate a stream of files.""" ... for file in ["hello.txt", "lorem.md", "realpython.md"]: ... yield file ... >>> for filename in get_file_from_stream(): ... append_member("incremental.zip", filename) ... >>> with zipfile.ZipFile("incremental.zip", mode="r") as archive: ... archive.printdir() ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428在此示例中,append_member() 是一个将文件(member)追加到输入 ZIP 归档(zip_file)的函数。要执行此操作,该函数会在每次被调用时打开和关闭目标归档。使用函数来执行此任务可以根据需要多次复用代码。
get_file_from_stream() 函数是一个生成器函数,用于模拟要处理的文件流。同时,for 循环使用 append_number() 将成员文件依次添加到 incremental.zip 中。如果在运行此代码后检查工作目录,那么您会发现一个 incremental.zip 归档,其中包含传递到循环中的三个文件。
对 ZIP 文件执行的最常见操作之一是将其内容提取到文件系统中的指定目录中。您已经学习了使用 .extract() 和 .extractall() 从归档中提取一个或所有文件的基础知识。
再举一个例子,回到 sample.zip 文件。此时归档包含四个不同类型的文件。有两个 .txt 文件和两个 .md 文件。假设只想提取 .md 文件。为此,可以运行以下代码:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... for file in archive.namelist(): ... if file.endswith(".md"): ... archive.extract(file, "output_dir/") ... 'output_dir/lorem.md' 'output_dir/realpython.md'with 语句打开 sample.zip 以供读取。循环使用 namelist() 遍历归档中的每个文件,而条件语句检查文件名是否以 .md 扩展名结尾。如果是,则使用 .extract() 将手头的文件解压到目标目录 output_dir/。
到目前为止,您已经了解了 zipfile 中可用的两个类: ZipFile 和 ZipInfo。该模块还提供了另外两个在某些情况下能派上用场的类。它们是 zipfile.Path 和 zipfile.PyZipFile。在以下两节中,您将了解这些类的基础知识及其主要功能。
当使用您最爱的归档应用程序打开 ZIP 文件时,会看到归档的内部结构。可能在归档的根目录中有文件。也可能有包含更多文件的子目录。归档看起来很像文件系统上的普通目录,每个文件都位于特定路径(PATH)。
zipfile.Path 类可以构建路径对象以快速创建和管理给定 ZIP 文件中的成员文件和目录的路径。该类接受两个参数:
root接受一个 ZIP 文件,可以是ZipFile对象,也可以是字符串格式的指向物理 ZIP 文件的路径。at保存归档中特定成员文件或目录的位置。它默认为空字符串,表示归档的根路径。
以老朋友 sample.zip 作为目标,运行以下代码:
>>> import zipfile >>> hello_txt = zipfile.Path("sample.zip", "hello.txt") >>> hello_txt Path('sample.zip', 'hello.txt') >>> hello_txt.name 'hello.txt' >>> hello_txt.is_file() True >>> hello_txt.exists() True >>> print(hello_txt.read_text()) Hello, Pythonista! Welcome to Real Python! Ready to try Python's zipfile module?这段代码展示了 zipfile.Path 实现了与 pathlib.Path 对象相同的几个功能。可以使用 .name 获取文件的名称。可以使用 .is_file() 来检查路径是否指向一个普通文件。可以检查给定文件是否存在于特定 ZIP 文件中,等等。
Path 还提供了 .open() 方法来使用不同的模式打开成员文件。例如,下面的代码打开 hello.txt 以供读取:
>>> import zipfile >>> hello_txt = zipfile.Path("sample.zip", "hello.txt") >>> with hello_txt.open(mode="r") as hello: ... for line in hello: ... print(line) ... Hello, Pythonista! Welcome to Real Python! Ready to try Python's zipfile module?使用 Path,可以快速创建指向给定 ZIP 文件中特定成员文件的路径对象,并使用 .open() 立即访问其内容。
就像使用 pathlib.Path 对象一样,可以通过在 zipfile.Path 对象上调用 .iterdir() 来列出 ZIP 文件的内容:
>>> import zipfile >>> root = zipfile.Path("sample.zip") >>> root Path('sample.zip', '') >>> root.is_dir() True >>> list(root.iterdir()) [ Path('sample.zip', 'hello.txt'), Path('sample.zip', 'lorem.md'), Path('sample.zip', 'realpython.md') ]显然,zipfile.Path 提供了许多实用的功能,您可以使用这些功能快速管理 ZIP 归档中的成员文件。
zipfile 中另一个实用的类是 PyZipFile。这个类与 ZipFile 非常相似,当需要将 Python 模块和包捆绑到 ZIP 文件中时,它特别方便。与 ZipFile 的主要区别在于,PyZipFile 初始化时使用一个名为 optimize 的可选参数,它允许您通过在归档前将 Python 代码编译为字节码来优化 Python 代码。
PyZipFile 提供与 ZipFile 相同的接口,但增加了 .writepy()。此方法可以接受一个 Python 文件(.py)作为参数,并将其添加到底层 ZIP 文件中。如果 optimize 为 -1(默认值),则 .py 文件会自动编译为 .pyc 文件,然后添加到目标归档中。为什么会这样?
从 2.3 开始,Python 解释器支持从 ZIP 文件导入 Python 代码,这种功能称为 Zip imports。它可以创建可导入的 ZIP 文件以将模块和包作为单个归档分发。
注意: 也可以使用 ZIP 文件格式来创建和分发 Python 可执行应用程序(通常称为 Python Zip 应用程序)。要了解如何创建它们,请查看 Python’s zipapp: Build Executable Zip Applications。
当需要生成可导入的 ZIP 文件时,PyZipFile 很有用。打包 .pyc 文件而不是 .py 文件使得导入过程效率大幅提高,因为它跳过了编译步骤。
在 python-zipfile/ 目录中,有一个 hello.py 模块,其内容如下:
"""Print a greeting message.""" # hello.py def greet(name="World"): print(f"Hello, {name}! Welcome to Real Python!")这段代码定义了一个名为 greet() 的函数,它接受 name 作为参数并将问候消息打印到屏幕上。现在假设您想将此模块打包成一个 ZIP 以进行分发。为此,可以运行以下代码:
>>> import zipfile >>> with zipfile.PyZipFile("hello.zip", mode="w") as zip_module: ... zip_module.writepy("hello.py") ... >>> with zipfile.PyZipFile("hello.zip", mode="r") as zip_module: ... zip_module.printdir() ... File Name Modified Size hello.pyc 2021-09-13 13:25:56 311在此示例中,对 .writepy() 的调用会自动将 hello.py 编译为 hello.pyc,并将其存储在 hello.zip 中。当使用 printdir() 列出归档的内容时就很明显了。
将 hello.py 捆绑到一个 ZIP 文件后,可以使用 Python 的 import 系统从其包含的归档中导入此模块:
>>> import sys >>> # Insert the archive into sys.path >>> sys.path.insert(0, "/home/user/python-zipfile/hello.zip") >>> sys.path[0] '/home/user/python-zipfile/hello.zip' >>> # Import and use the code >>> import hello >>> hello.greet("Pythonista") Hello, Pythonista! Welcome to Real Python!从 ZIP 文件导入代码的第一步是使该文件在 sys.path 中可用。此变量包含一个字符串列表,该列表为模块指定 Python 的搜索路径。要向 sys.path 添加新项,可以使用 .insert()。
为了让这个示例正常工作,需要更改占位符路径并将路径指向您的文件系统上的 hello.zip。一旦可导入 ZIP 文件在此列表中,就可以像使用常规模块一样导入代码。
最后,考虑一下工作目录中的 hello/ 子目录。它包含一个具有以下结构的小型 Python 包:
hello/ | ├── __init__.py └── hello.py__init__.py 模块将 hello/ 目录转换为 Python 包。hello.py 模块与在上一个示例中使用的模块相同。现在假设您想将此包捆绑到一个 ZIP 文件中。这种情况下,可以执行以下操作:
>>> import zipfile >>> with zipfile.PyZipFile("hello.zip", mode="w") as zip_pkg: ... zip_pkg.writepy("hello") ... >>> with zipfile.PyZipFile("hello.zip", mode="r") as zip_pkg: ... zip_pkg.printdir() ... File Name Modified Size hello/__init__.pyc 2021-09-13 13:39:30 108 hello/hello.pyc 2021-09-13 13:39:30 317对 .writepy() 的调用将 hello 包作为参数,在其中搜索 .py 文件,将它们编译成 .pyc 文件,最后将它们添加到目标 ZIP 文件 hello.zip 中。同样,可以按照之前学习的步骤从该归档中导入代码:
>>> import sys >>> sys.path.insert(0, "/home/user/python-zipfile/hello.zip") >>> from hello import hello >>> hello.greet("Pythonista") Hello, Pythonista! Welcome to Real Python!因为现在代码在一个包中,需要先从 hello 包中导入 hello 模块。然后就可以正常访问 greet() 函数了。
Python 的 zipfile 还提供了一个最小的命令行界面,允许您快速访问模块的主要功能。例如,可以使用 -l 或 --list 选项列出现有 ZIP 文件的内容:
$ python -m zipfile --list sample.zip File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428 new_hello.txt 1980-01-01 00:00:00 13此命令展示与对 sample.zip 归档调用 printdir() 相同的输出。
现在假设您要创建一个包含多个输入文件的新 ZIP 文件。在这种情况下,可以使用 -c 或者 --creat 选项:
$ python -m zipfile --create new_sample.zip hello.txt lorem.md realpython.md $ python -m zipfile -l new_sample.zip File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428此命令创建一个 new_sample.zip 文件,其中包含 hello.txt、 lorem.md、 realpython.md 文件。
如果需要创建一个 ZIP 文件来归档整个目录怎么办?例如,您可能拥有自己的 source_dir/,其中包含与上例相同的三个文件。 可以使用以下命令从该目录创建 ZIP 文件:
$ python -m zipfile -c source_dir.zip source_dir/ $ python -m zipfile -l source_dir.zip File Name Modified Size source_dir/ 2021-08-31 08:55:58 0 source_dir/hello.txt 2021-08-31 08:55:58 83 source_dir/lorem.md 2021-08-31 09:01:08 2609 source_dir/realpython.md 2021-08-31 09:31:22 428使用此命令,zipfile 将 source_dir/ 作为生成的 source_dir.zip 文件根目录。像往常一样,可以通过使用 -l 选项运行 zipfile 来列出归档内容。
注意:当使用
zipfile 从命令行创建归档时,库在归档文件时隐式使用 Deflate 压缩算法。
还可以使用命令行中的 -e 或 --extract 选项提取给定 ZIP 文件的所有内容:
python -m zipfile --extract sample.zip sample/运行此命令后,工作目录中将有一个新的 sample/ 文件夹。 新文件夹将包含 sample.zip 归档中的当前文件。
可以在命令行中与 zipfile 一起使用的最后一个参数时 -t 或 --test。该选项测试给定文件是否为有效的 ZIP 文件。来吧,试一试!
Python 标准库中还有一些其他工具可用于在更底层进行归档、压缩和解压缩文件。Python 的 zipfile 在内部使用了其中的几个,主要用于压缩目的。 以下是部分工具的摘要:
| 模块 | 描述 |
|---|---|
| zlib | 允许使用 zlib 库进行压缩和解压缩 |
| bz2 | 提供使用 Bzip2 压缩算法来压缩和解压数据的接口 |
| lzma | 提供使用 LZMA 压缩算法压缩和解压缩数据的类和函数 |
不同于 zipfile,其中一些模块支持从内存和数据流中压缩和解压数据,而不是普通文件和归档。
在 Python 标准库中,可以找到支持 TAR 归档格式的 tarfile。还有一个名为 gzip 的模块,它提供了一个压缩和解压数据的接口,类似于 GNU Gzip 程序的做法。
例如,可以使用 gzip 创建一个包含一些文本的压缩文件:
>>> import gzip >>> with gzip.open("hello.txt.gz", mode="wt") as gz_file: ... gz_file.write("Hello, World!") ... 13运行此代码后,当前工作目录中将会有一个 hello.txt.gz 归档,其中包含 hello.txt 的压缩版本。在 hello.txt 中有文本 Hello, World!。
在不使用 zipfile 的情况下创建 ZIP 文件的一种快速且高级的方法是使用 shutil。该模块可以对文件和文件集合执行多项高级操作。当涉及到归档操作时,有 make_archive(),它可以创建归档,例如 ZIP 或 TAR 文件:
>>> import shutil >>> shutil.make_archive("shutil_sample", format="zip", root_dir="source_dir/") '/home/user/sample.zip'此代码在工作目录中创建一个名为 sample.zip 的压缩文件。此 ZIP 文件将包含输入目录 source_dir/ 中的所有文件。当您需要一种快速且高级的方式在 Python 中创建 ZIP 文件时,make_archive() 函数非常方便。
当需要从 ZIP 归档中读取、写入、压缩、解压和提取文件时,Python 的 zipfile 是一个方便的工具。ZIP 文件格式已经成为行业标准,可以打包和压缩数字数据。
使用 ZIP 文件的好处包括将所有相关文件归档到一起、节省磁盘空间、便于通过计算机网络传输数据、捆绑 Python 代码以进行分发等。
在教程中,您学到了如何:
- 使用 Python 的
zipfile来读取、写入、提取现有 ZIP 文件。 - 使用
zipfile读取关于 ZIP 文件内容的元数据 - 使用
zipfile操作现有 ZIP 文件中的成员文件 - 创建您自己的 ZIP 文件以归档和压缩您的数字数据
您还学习了如何在命令行中使用 zipfile 来列出、创建和提取 ZIP 文件。有了这些知识,您就可以使用 ZIP 文件格式有效地归档、压缩和处理您的数字数据。
ubuntu文件夹中存在很多zip后缀文件,需要解压。
运行命令:
for zip in *.zip; do unzip $zip; done
zip 是一个非常常见的压缩包格式,本文主要用于说明如何使用代码 文件或文件夹压缩为 zip压缩包及其解压操作, 我们采用的是 微软官方的实现,所以也不需要安装第三方的组件包。
使用的时候记得 using System.IO.Compression;
/// <summary> /// 将指定目录压缩为Zip文件 /// </summary> /// <param name="folderPath">文件夹地址 D:/1/ </param> /// <param name="zipPath">zip地址 D:/1.zip </param> public static void CompressDirectoryZip(string folderPath, string zipPath) { DirectoryInfo directoryInfo = new(zipPath); if (directoryInfo.Parent != null) { directoryInfo = directoryInfo.Parent; } if (!directoryInfo.Exists) { directoryInfo.Create(); } ZipFile.CreateFromDirectory(folderPath, zipPath, CompressionLevel.Optimal, false); } 其中 CompressionLevel 是个枚举,支持下面四种类型
| 枚举 | 值 | 注解 |
|---|---|---|
| Optimal | 0 | 压缩操作应以最佳方式平衡压缩速度和输出大小。 |
| Fastest | 1 | 即使结果文件未可选择性地压缩,压缩操作也应尽快完成。 |
| NoCompression | 2 | 该文件不应执行压缩。 |
| SmallestSize | 3 | 压缩操作应尽可能小地创建输出,即使该操作需要更长的时间才能完成。 |
我方法这里直接固定了采用 CompressionLevel.Optimal,大家可以根据个人需求自行调整。
/// <summary> /// 将指定文件压缩为Zip文件 /// </summary> /// <param name="filePath">文件地址 D:/1.txt </param> /// <param name="zipPath">zip地址 D:/1.zip </param> public static void CompressFileZip(string filePath, string zipPath) { FileInfo fileInfo = new FileInfo(filePath); string dirPath = fileInfo.DirectoryName?.Replace("\\", "/") + "/"; string tempPath = dirPath + Guid.NewGuid() + "_temp/"; if (!Directory.Exists(tempPath)) { Directory.CreateDirectory(tempPath); } fileInfo.CopyTo(tempPath + fileInfo.Name); CompressDirectoryZip(tempPath, zipPath); DirectoryInfo directory = new(tempPath); if (directory.Exists) { //将文件夹属性设置为普通,如:只读文件夹设置为普通 directory.Attributes = FileAttributes.Normal; directory.Delete(true); } } 压缩单个文件的逻辑其实就是先将我们要压缩的文件复制到一个临时目录,然后对临时目录执行了压缩动作,压缩完成之后又删除了临时目录。
/// <summary> /// 解压Zip文件到指定目录 /// </summary> /// <param name="zipPath">zip地址 D:/1.zip</param> /// <param name="folderPath">文件夹地址 D:/1/</param> public static void DecompressZip(string zipPath, string folderPath) { DirectoryInfo directoryInfo = new(folderPath); if (!directoryInfo.Exists) { directoryInfo.Create(); } ZipFile.ExtractToDirectory(zipPath, folderPath); } 至此 C# 使用原生 System.IO.Compression 实现 zip 的压缩与解压 就讲解完了,有任何不明白的,可以在文章下面评论或者私信我,欢迎大家积极的讨论交流,有兴趣的朋友可以关注我目前在维护的一个 .NET 基础框架项目,项目地址如下
GitHub https://github.com/dashiell-zhang/NetEngine.git
在网上下载压缩包文件后,解压时经常会遇到如下图所示的解压文件失败或压缩包文件损坏等提示,导致无法解压,达芬奇今天分享下遇到这种问题的原因及如何继续解压和修复。
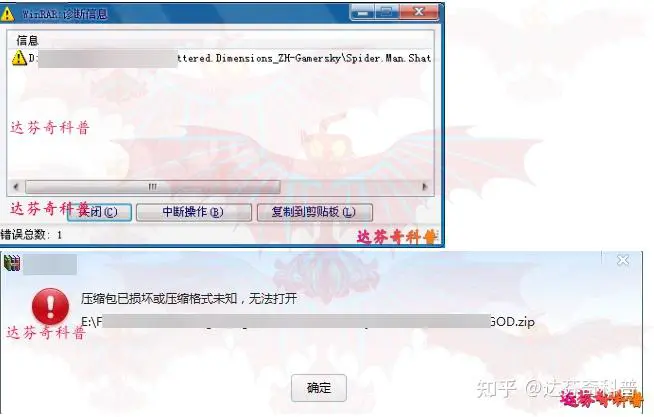
2.文件可能包含病毒或者被病毒感染,你就可能会看到此提示文件;
3.文件可能包含一些激活成功教程文件或者注册表文件,会被某些杀毒软件,提示包含病毒,无法解压;
4.源文件在压缩过程中,由于压缩软件问题,导致压缩文件不完整;
5.解压软件不合适,或者出现问题,导致无法解压正常文件。
达芬奇建议可以依次用下面几种方法尝试修复操作,从上往下,依次尝试方法修复。
文件可能是下载过程中网速慢或网络不稳定导致下载不全;重新下载后,很多情况下都可解决。
你如果使用的是WINRar解压缩软件,建议换成7-zip解压软件;可以下载最新版本7-ZIP。用7-ZIP解压缩软件进行解压;
下载地址:https://wwc.lanzouw.com/iESER0ec01zi
密码:1r5g
你如果使用的7-ZIP出现问题,那么下载WinRAR,利用Winrar压缩软件进行解压缩。
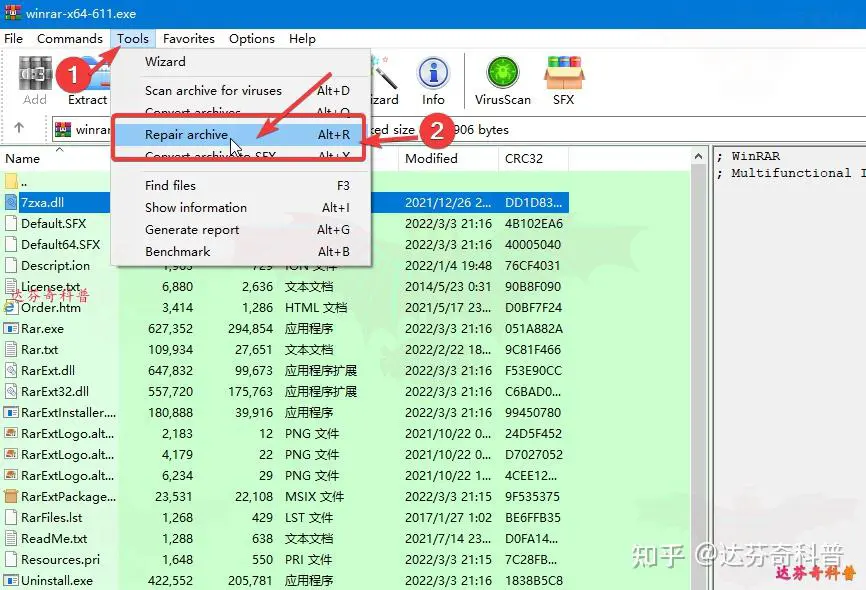
如下图,用winrar打开压缩文件,在工具栏窗口选择“工具”>”修复文件”,进行修复;
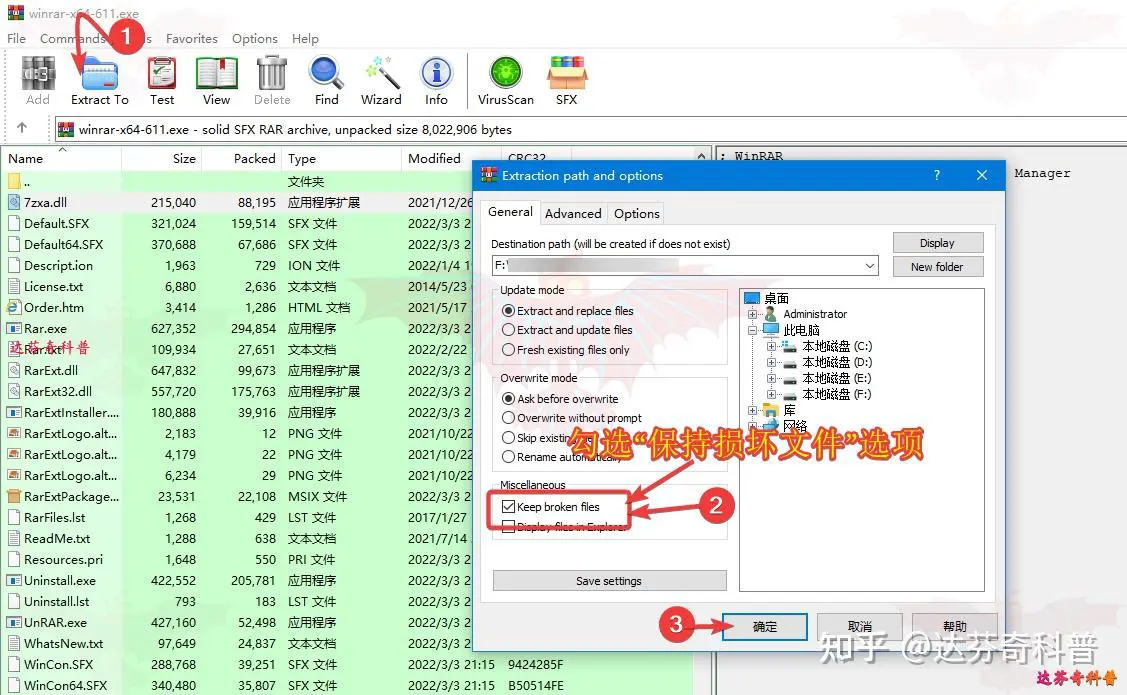
如下图所示,用Winrar打开后,点击菜单栏的“提取到”选项,弹出解压窗口,勾选“保持损坏文件“选项,强制解压,最后点击确定;
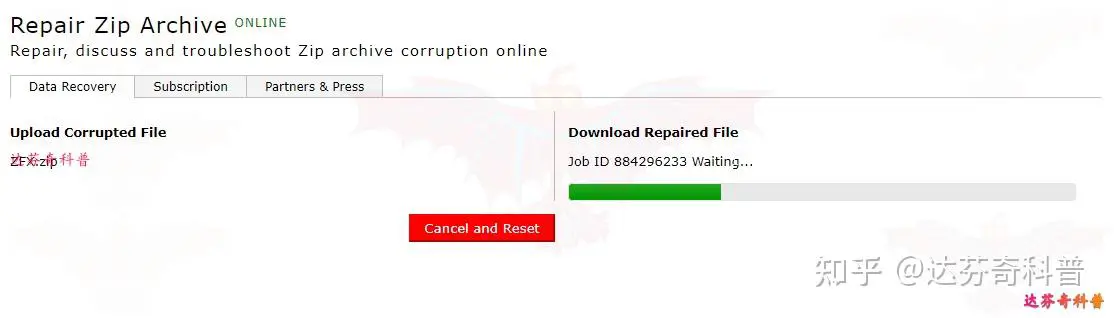
网站:Repair Zip Archive ONLINE
网址:https://online.officerecovery.com/zip/
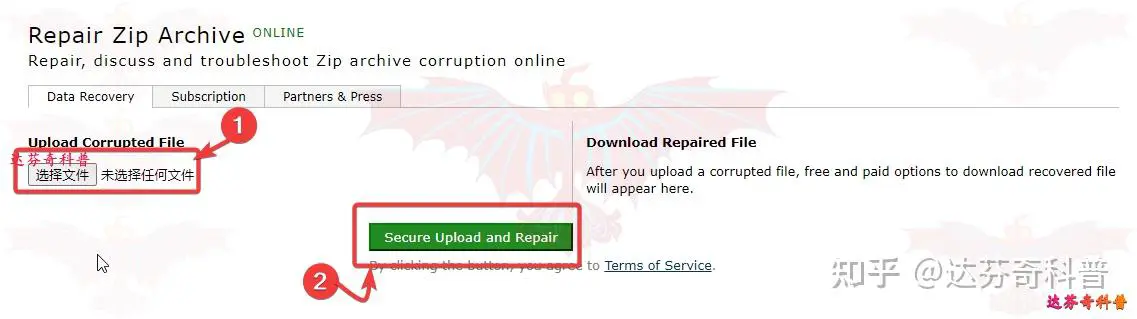
Repair Zip Archive ONLINE是一个免费的在线修复损坏压缩文件软件,可以登录此网站尝试修复损坏压缩文件,但在线修复文件的文件大小限制为100MB。使用方法见下图:选择要修复文件>安全上传并修复>修复过程中,最后下载修复文件即可。(修复比较慢,大家耐心等待)
此网站同时还配有修复离线工具软件,可下载安装进行离线修复;
下载地址:https://wwc.lanzouw.com/iBunk0ec05zc 密码:7ad0
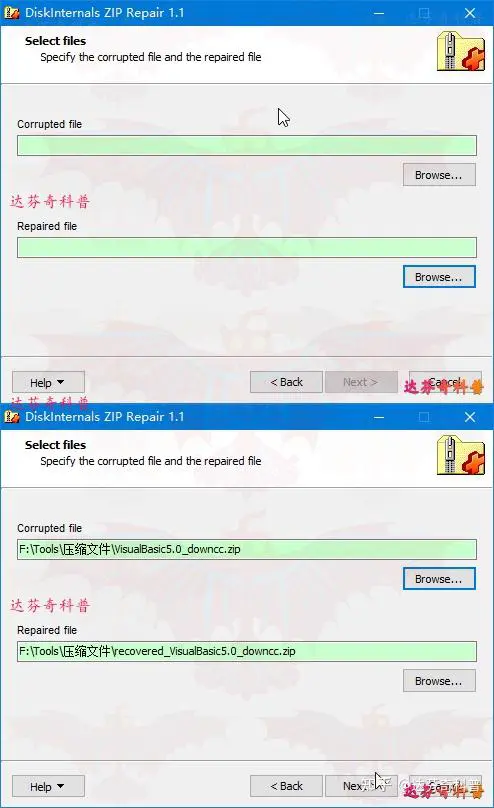
DiskInternals ZIP Repair是一款免费的简单实用的修复压缩文件工具。
下载地址:https://wwc.lanzouw.com/ioD0T0ebzyqb 密码: 1usn

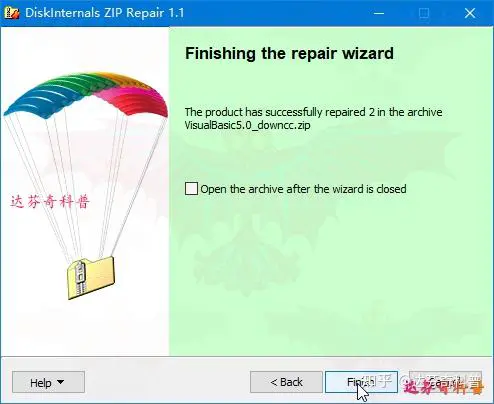
使用方法:下载软件后,双击exe文件,即可开启安装,如下图所示,会出现用户选择被损坏文件窗口,选择待修复文件(此处软件会默认修复文件名,在源文件名前加recovered一词),并确认修复文件地址;点击下一步(next);
如下图所示,出现如下窗口,即代表已经完成文件修复,接着点击“Finish”(完成)。
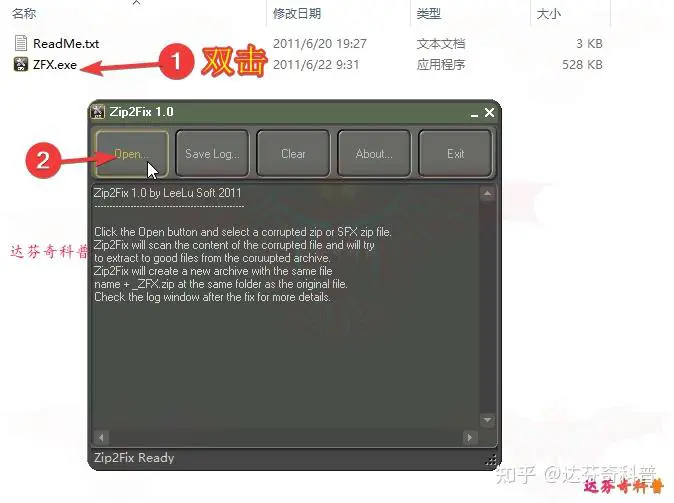
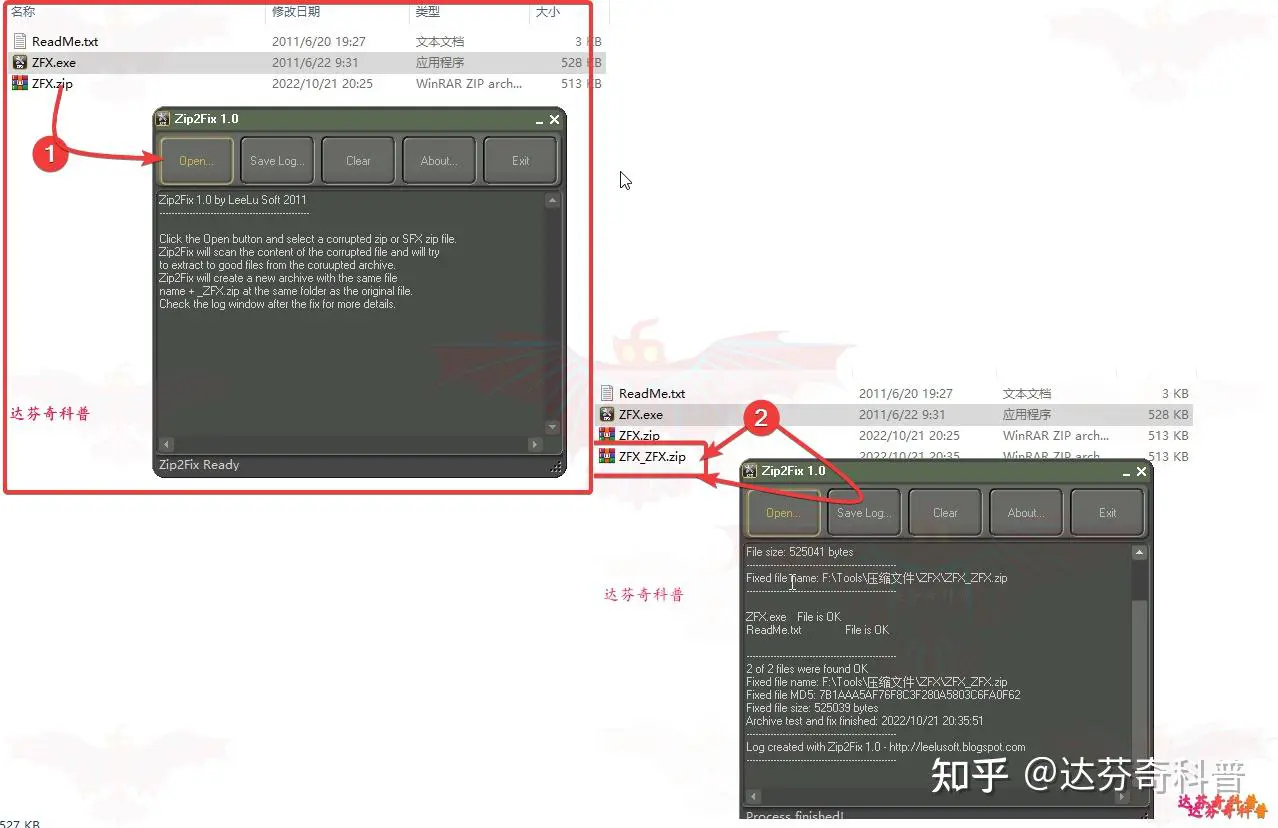
ZFX软件是一款mini小程序软件,大小仅528K,此软件可以将压缩文件中损坏文件自动剔除出去,并将完好文件重新压缩成一个新文件。
下载地址:https://wwc.lanzouw.com/iz2na0ebzyrc 密码: cbwr
使用方法:解压文件后,如下图,双击ZFX.exe文件,软件无需安装,直接打开,选择要修复的压缩文件;
打开待修复文件后,即自动进入修复模式,并自动将待修复文件修复后保存到本文件夹中,文件名会默认在源文件名后添加_ZFX。(注意:此软件使用过程中,可能会把文件中的正常文件识别为破坏文件,注意做好源文件备份)
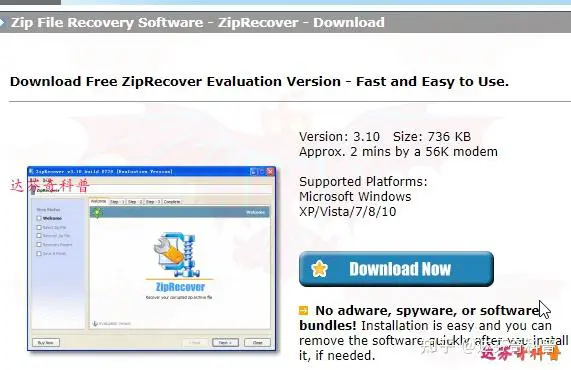
ZipRecover是一个收费软件,但有一个免费试用版,如果想要使用完全版,需要付费享用。
免费试用版下载地址:https://wwc.lanzouw.com/in2Yy0ebzyte 密码:9ow4
今天的达芬奇分享就到这里啦,大家按照达芬奇分享的方法依次尝试解决,若还有任何疑问都可在下方留言,达芬奇会尽可能为每个疑问者解答。如果对你有帮助也请多多转发分享,让更多人看到,帮助更多人 !
如果直接提取压缩包文件,里面包含中文会出现乱码。于是想到了个办法,先解压到一个临时路径,然后对文件名重新编码,再移动到目标文件夹。
from zipfile import ZipFile import os,shutil # 需要提取的压缩包文件路径 root_path = r"D:\XHXIAIEIN\Downloads" zip_filename = 'file.zip' # 如果文件夹不存在,先创建 def create_directory(folder): if not os.path.exists(folder): os.makedirs(folder) # 补全压缩包路径 zip_filepath = os.path.join(root_path,zip_filename) # 打开压缩包 with ZipFile(zip_filepath, 'r') as zip: # 创建一个临时目录,用来存放解压后的文件 temp_path = os.path.join(root_path, 'tmp') create_directory(temp_path) # 解压压缩包中的文件到临时目录中 zip.extractall(temp_path, members=[m for m in zip.infolist()]) # 将压缩包文件名用作文件夹名 folder_name = os.path.splitext(zip_filename)[0] file_path = os.path.join(root_path, folder_name) create_directory(file_path) # 移动临时目录中的文件到指定目录中,并在移动时解决文件名中存在的乱码问题 for file in os.listdir(temp_path): temp_file_path = os.path.join(temp_path, file) new_file_path = os.path.join(file_path, file.encode('cp437').decode('gbk')) shutil.move(temp_file_path, new_file_path) # 删除临时文件夹 shutil.rmtree(temp_path)由于 Mac 里的软件不像 Windows 那样「内卷」的厉害,所以整个应用市场基本上都是免费软件提供基础功能,付费软件提供额外服务,这个商业模式还是比较健康的。
解压缩软件也是如此。作为电脑装机必备的软件,其重要性不言而喻。

压缩文件的格式种类比较多,最常见的有三种,分别是7z、zip、rar。不常见的压缩格式还有诸如,apz、ar、bz、car、dar、cpgz、hbc等。
rar是一种常见的压缩格式,而且是一种专利文件格式,主要用于数据压缩和归档打包方面。相比于另一种常见的压缩格式zip,rar压缩格式有着更高的压缩比,但也存在着压缩和解压速度较慢的特点。
zip文件压缩格式是另一种常见的数据压缩和文档归档存储格式,由于zip的出现时间较早的缘故,zip与后来者的压缩过格式有一些无法忽视的缺点,比如zip原声不支持unicode,这容易导致一部分的资源共享困难,压缩和解压会出现乱码,尤其在东亚文化圈中尤其显著。
7-zip压缩格式是一款免费开源的压缩软件格式,7-zip是基于GNU LGPL协议发布的软件,是完全开源的,7-zip是通过全新的算法来使压缩比大幅提高。7-zip 不仅比zip压缩比更高,而且相对于rar,占用更少的系统资源。也是如今最推荐的压缩格式。
下面就让果果盘点一下 2022 年度最值得推荐的压缩软件吧 。
归档实用工具——免费
归档实用工具是苹果自带的解压缩软,与 Mac 系统无缝链接,右击选择压缩,双击即可解压,但是只支持压缩和解压 ZIP 格式,而且与 Windows 互传的时候容易乱码,一般都需要安装第三方软件作为补充。
优点:与系统绑定,操作便捷
缺点:支持格式少,容易乱码。
The Unarchiver ——免费
The Unarchiver 是乌克兰知名软件开发商 MacPaw 出品的免费解压缩软件,他们公司开发的 CleanMyMac 也是 Mac 装机必备软件。除主流的 Zip、RAR、7-zip 外,包括 LZH、 ARC、 ISO 等格式 The Unarchiver 都能打开。但是 The Unarchiver 只能解压没有压缩功能,所以一般被当做额外补充。
优点:免费快捷
缺点:只能解压,不能压缩

Keka ——开源免费
Keka 是一款开源且免费的 Mac 解压缩软件,支持压缩为 7Z,ZIP,TAR 等。支持 7Z,ZIP, RAR, TAR, GZIP等等格式的解压缩。
Keka 可以直接在官网免费下载,也可以在 App Store 搜索并购买来支持开发商,两者没有其他区别。
优点:免费,支持格式较多
缺点:在解压用中文作为密码的文件时容易出错,另外图标也有些怪。
BetterZip ——付费
BetterZip 曾经是 Mac 上标杆级的解压缩软件,按空格即可预览压缩文件的操作很得人心。支持主流格式的解压,分卷解压,还有密码管理功能方便操作。
优点:功能强大,解压格式多
缺点:价格略高

Bandzip ——付费
在 Windows 上知名的压缩软件 Bandzip 其实也有 Mac (两者账号并不通用),整体功能与 BetterZip 差不多,但是 UI 界面风格偏 Windows,与 Mac 电脑不太搭,售价也比 BetterZip 贵些。
优点:功能强大,解压格式多
缺点:价格最高,UI 一般

解压专家Oka ——付费
跟 BetterZip 同样支持预览压缩包内容,分卷压缩和密码管理,支持右键快速菜单和众多解压格式,还有一个特别的功能,可以监视制定文件夹的新增压缩文件。说它是 BetterZip 的最佳平替不过分。
优点:功能强大,解压格式多
缺点:软件名称有点难记

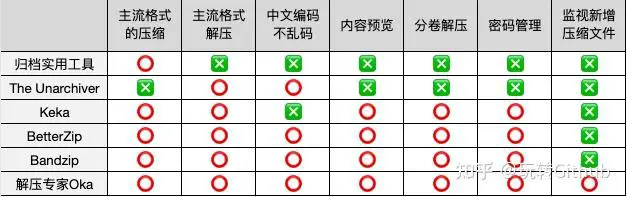
综合来看,如果只需要一般的解压功能可以选择 The Unarchiver,如果不差钱可以选择 BetterZip ,此外都推荐 解压专家 Oka。
本期分享一个批量压缩文件夹的 Python 程序工具。
在平常工作中有需要上传资源包的需求,每个资源包都需要被压缩为 zip 格式才能被上传,资源包的数量较多,于是决定使用 Python 脚本完成。
具体的需求是这样的:将指定文件夹中所有的文件夹压缩为zip包。
这个脚本需要使用 os 模块读取文件夹下的所有文件夹名,遍历所有文件夹,然后使用第三方模块 zipfile 的相应函数完成完成任务。后期为了方便使用,使用(简陋的)可视化操作页面完成了重构。

完整代码如下,需要的小伙伴自取。也可以直接下载可运行exe程序。
注意:目前版本只支持对非空文件夹打包。
bat_zip.exe
完整 Python 代码:
import os import zipfile import tkinter as tk from tkinter import filedialog, messagebox def open_folder(): folder_path = filedialog.askdirectory() folder_entry.set(folder_path) def batch_zip_one(start_dir, zip_file): """ 将目标目录打包为zip格式文件 """ zip_file = zip_file + '.zip' z = zipfile.ZipFile(zip_file, 'w', zipfile.ZIP_DEFLATED) for path, dirname, file_name in os.walk(start_dir): fpath = path.replace(start_dir, '') fpath = fpath and fpath + os.sep for filename in file_name: s = os.path.join(path, filename) z.write(os.path.join(path, filename), fpath + filename) z.close() def batch_zip_all(): start_dir = folder_entry.get() folders = os.listdir(start_dir) for f in folders: batch_zip_one(start_dir + "/" + f, start_dir + "/" + f) print(start_dir + "/" + f) root = tk.Tk() root.title("文件批量打包工具") root.geometry('150x150') root.resizable(0,0) folder_entry = tk.StringVar() folder_button = tk.Button(root, text="选择文件夹", command=open_folder) folder_button.pack() search_button = tk.Button(root, text="批量打包", command=batch_zip_all) search_button.pack() root.mainloop()拒收通知
此 PEP 已被拒绝。,在 PEP 279 中介绍, 涵盖了本 PEP 中提出的用例,并且 PEP 作者已经 遥 不可 及。enumerate()
介绍
此 PEP 描述了经常提出的公开循环的功能 for 循环中的计数器。此 PEP 跟踪 此功能。它包含对功能的描述和 概述了支持该功能所需的更改。这个PEP 总结在邮件列表论坛中进行的讨论,并提供 URL 以获取更多信息(如适用)。CVS 修订版 此文件的历史记录包含权威的历史记录。
赋予动机
Python 中的标准 for 循环遍历 序列 [1]。通常,需要遍历索引或 元素和索引都代替。
用于实现此目的的常见习语是不直观的。这 PEP提出了两种不同的指数暴露方式。
循环计数器迭代
当前循环索引的习语利用了 内置功能:range
for i in range(len(sequence)): # work with index i元素和索引的循环可以通过以下方式实现 旧成语或使用新的内置函数 [2]:zip
for i in range(len(sequence)): e = sequence[i] # work with index i and element e或:
for i, e in zip(range(len(sequence)), sequence): # work with index i and element e建议的解决方案
已经讨论了三种解决方案。一个添加一个 nonreserved 关键字,另一个增加了两个内置功能。 第三种解决方案将方法添加到序列对象中。
非保留关键字
该解决方案将扩展 for 循环的语法,方法是将 也可以使用的可选条款 而不是子句。<variable> indexing<variable> in
因此,循环序列的索引将变为:
for i indexing sequence: # work with index i类似地,在索引和元素上循环如下:
for i indexing e in sequence: # work with index i and element e内置功能和
此解决方案添加了两个内置函数和 . 这些的语义可以描述如下:indicesirange
def indices(sequence): return range(len(sequence)) def irange(sequence): return zip(range(len(sequence)), sequence)这些功能可以急切地或懒惰地实现,并且 应该易于扩展,以便接受多个序列 论点。
使用这些函数将简化循环的习语 在索引以及元素和索引上:
for i in indices(sequence): # work with index i for i, e in irange(sequence): # work with index i and element e序列对象的方法
此解决方案建议将 和 方法添加到序列中,从而实现循环 仅索引,包括索引和元素,以及仅元素 分别。indicesitemsvalues
这将极大地简化循环索引的习语 以及循环访问元素和索引:
for i in sequence.indices(): # work with index i for i, e in sequence.items(): # work with index i and element e此外,它还允许对元素进行循环 以一致的方式排列序列和字典:
for e in sequence_or_dict.values(): # do something with element e对于这三种解决方案,都存在一些或多或少的粗糙补丁 作为 SourceForge 的补丁:
foriindexingainl:公开 for 循环计数器 [3]- 将 和 添加到内置项 [4]
indices()irange() - 将方法添加到 ListObject [5]
items()
所有这些都被BDFL宣布并拒绝。
请注意,关键字只是 语法等并不妨碍 .indexingNAMEindexing
由于没有添加关键字和现有代码的语义 保持不变,三种解决方案都可以实施 在不破坏现有代码的情况下。
https://www.bilibili.com/read/readlist/rl
例如:将common.war解压到指定的目录 -d 指定目录
[root@oracle upload]# unzip -oq common.war -d common
例:将当前目录下的所有文件和文件夹全部压缩成test.zip文件,-r表示递归压缩子目录下所有文件
[root@mysql test]# zip -r test.zip https://www.zhihu.com/topic//*
功 能说明:解压缩zip文 件
语 法:unzip [-cflptuvz][-agCjLMnoqsVX][-P <密 码>][.zip文 件][文件][-d <目录>][-x <文件>] 或 unzip [-Z]
补充说明:unzip为.zip压缩文件的解压缩程序。
参 数:
-c 将 解压缩的结果显示到屏幕上,并对字符做适当的转换。
-f 更 新现有的文件。
-l 显 示压缩文件内所包含的文件。
-p 与-c参数类似,会将解压缩的结果显示到屏幕上,但不会执行任 何的转换。
-t 检 查压缩文件是否正确。,但不解压。
-u 与-f参数类似,但是除了更新现有的文件外,也会将压缩文件中 的其他文件解压缩到目录中。
-v 执 行是时显示详细的信息。或查看压缩文件目录,但不解压。
-z 仅 显示压缩文件的备注文字。
-a 对 文本文件进行必要的字符转换。
-b 不 要对文本文件进行字符转换。
-C 压 缩文件中的文件名称区分大小写。
-j 不 处理压缩文件中原有的目录路径。
-L 将 压缩文件中的全部文件名改为小写。
-M 将 输出结果送到more程 序处理。
-n 解 压缩时不要覆盖原有的文件。
-o 不 必先询问用户,unzip执 行后覆盖原有文件。
-P<密码> 使 用zip的密码选项。
-q 执 行时不显示任何信息。
-s 将 文件名中的空白字符转换为底线字符。
-V 保 留VMS的文件版本信 息。
-X 解 压缩时同时回存文件原来的UID/GID。
[.zip文件] 指定.zip压缩文件。
[文件] 指定 要处理.zip压缩文 件中的哪些文件。
-d<目录> 指 定文件解压缩后所要存储的目录。
-x<文件> 指 定不要处理.zip压 缩文件中的哪些文件。
-Z unzip -Z等 于执行zipinfo指 令。
功能说明:压缩文件。
语 法:zip [-AcdDfFghjJKlLmoqrSTuvVwXyz$][-b <工 作目录>][-ll][-n <字 尾字符串>][-t <日 期时间>][-<压 缩效率>][压 缩文件][文件...][-i <范本样式>][-x <范本样式>]
补充说明:zip是个使用广泛的压缩程序,文件经它压缩后会另外产生具 有".zip"扩展名 的压缩文件。
参 数:
-A 调 整可执行的自动解压缩文件。
-b<工作目录> 指 定暂时存放文件的目录。
-c 替 每个被压缩的文件加上注释。
-d 从 压缩文件内删除指定的文件。
-D 压 缩文件内不建立目录名称。
-f 此 参数的效果和指定"-u"参 数类似,但不仅更新既有文件,如果某些文件原本不存在于压缩文件内,使用本参数会一并将其加入压缩文件中。
-F 尝 试修复已损坏的压缩文件。
-g 将 文件压缩后附加在既有的压缩文件之后,而非另行建立新的压缩文件。
-h 在 线帮助。
-i<范本样式> 只 压缩符合条件的文件。
-j 只 保存文件名称及其内容,而不存放任何目录名称。
-J 删 除压缩文件前面不必要的数据。
-k 使 用MS-DOS兼容格 式的文件名称。
-l 压 缩文件时,把LF字符 置换成LF+CR字 符。
-ll 压 缩文件时,把LF+CR字 符置换成LF字符。
-L 显 示版权信息。
-m 将 文件压缩并加入压缩文件后,删除原始文件,即把文件移到压缩文件中。
-n<字尾字符串> 不 压缩具有特定字尾字符串的文件。
-o 以 压缩文件内拥有最新更改时间的文件为准,将压缩文件的更改时间设成和该文件相同。
-q 不显 示指令执行过程。
-r 递 归处理,将指定目录下的所有文件和子目录一并处理。
-S 包 含系统和隐藏文件。
-t<日期时间> 把 压缩文件的日期设成指定的日期。
-T 检 查备份文件内的每个文件是否正确无误。
-u 更 换较新的文件到压缩文件内。
-v 显 示指令执行过程或显示版本信息。
-V 保 存VMS操作系统的文 件属性。
-w 在 文件名称里假如版本编号,本参数仅在VMS操 作系统下有效。
-x<范本样式> 压 缩时排除符合条件的文件。
-X 不 保存额外的文件属性。
-y 直 接保存符号连接,而非该连接所指向的文件,本参数仅在UNIX之 类的系统下有效。
-z 替 压缩文件加上注释。
-$ 保 存第一个被压缩文件所在磁盘的卷册名称。
-<压缩效率> 压 缩效率是一个介于1-9的 数值。
把一个文件abc.txt和一个目录dir1压缩成为yasuo.zip:
# zip -r yasuo.zip abc.txt dir1
Zip压缩包因其高效的文件压缩和便捷的文件传输功能,被广大用户广泛使用。但当我们设置了压缩包的密码以保护其中的重要数据时,有时却会因为遗忘密码而陷入困境。下面小编将详细介绍当Zip压缩包密码忘记时,如何找回或重置密码的几种方法?

在设置Zip压缩包密码时,有些人可能会选择设置一个密码提示,以便在忘记密码时进行提示。如果您在设置密码时设置了密码提示,那么可以在尝试输入密码时,根据提示信息回忆密码。这是一种比较简单且有效的方法,但前提是您必须记得设置的密码提示。
如果您有原始未加密的备份文件,可以使用该备份文件替代忘记密码的文件。但需要注意的是,这种方法只适用于您之前已经进行了备份的情况。
当您无法通过密码提示找回密码时,可以尝试使用密码激活成功教程工具来找回密码。如PassFab for ZIP解密工具可以通过暴力激活成功教程、字典攻击等方法尝试猜测密码。具体操作步骤如下:
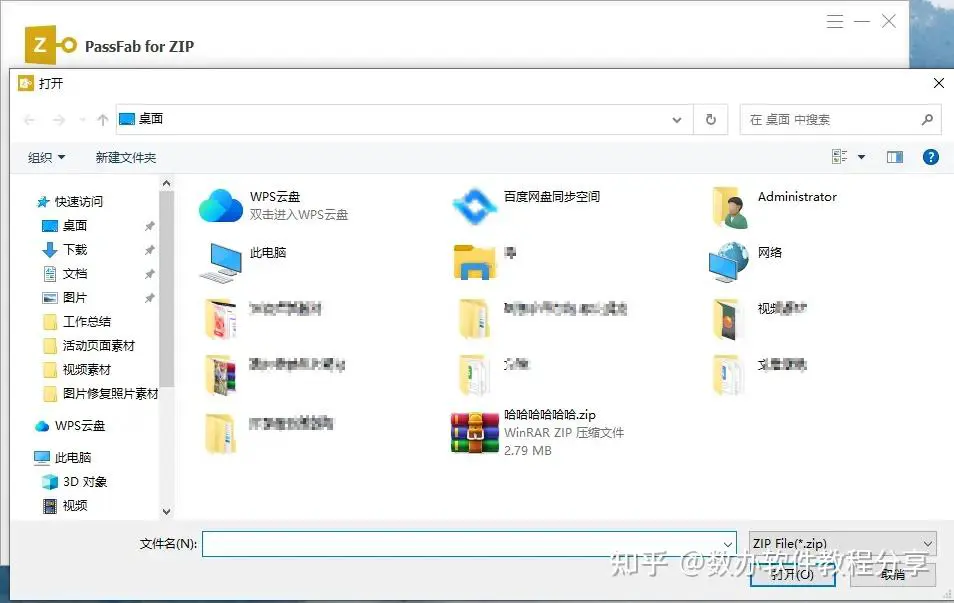
第1步:导入加密的ZIP文件
下载安装后启动 PassFab for ZIP,您将看到主界面。
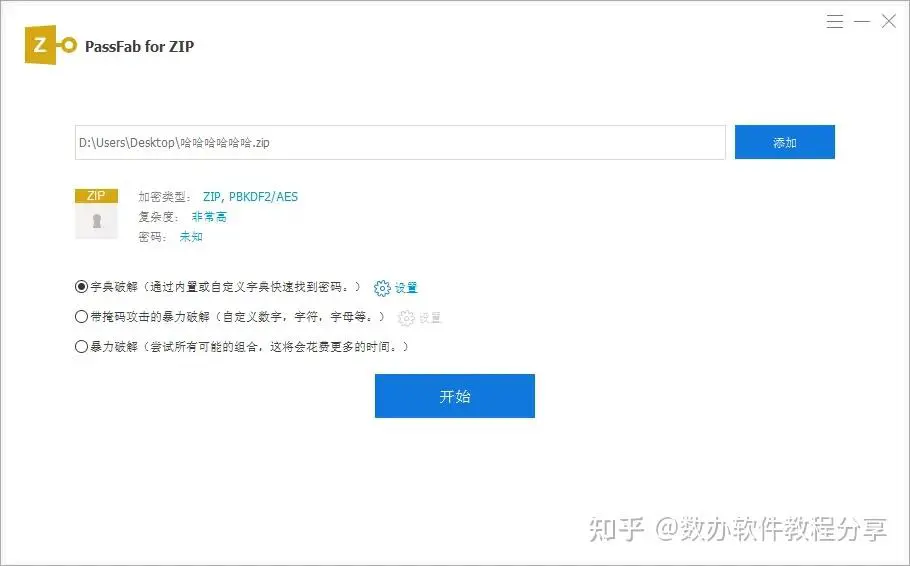
第 2 步:选择合适的激活成功教程方式
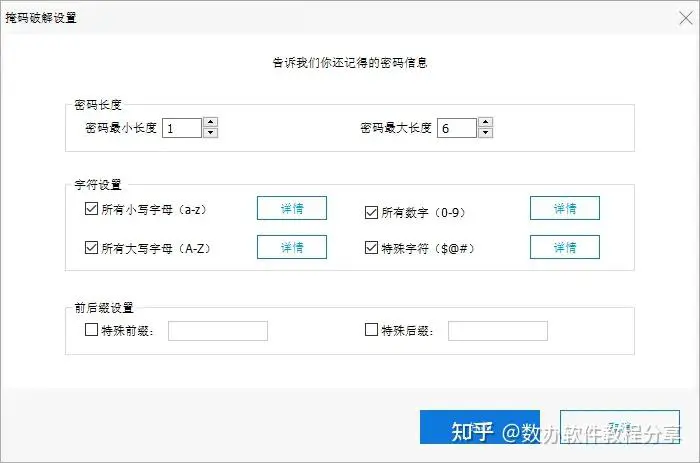
选择选择合适的激活成功教程方式:
1.暴力激活成功教程:如果你完全忘记了密码,可以选择此激活成功教程方式它会自动尝试所有可能的密码组合。
2.带掩码攻击的暴力激活成功教程:如果你能提供任何有关密码的线索,点击“设置”按照你的记忆提供相应的线索。
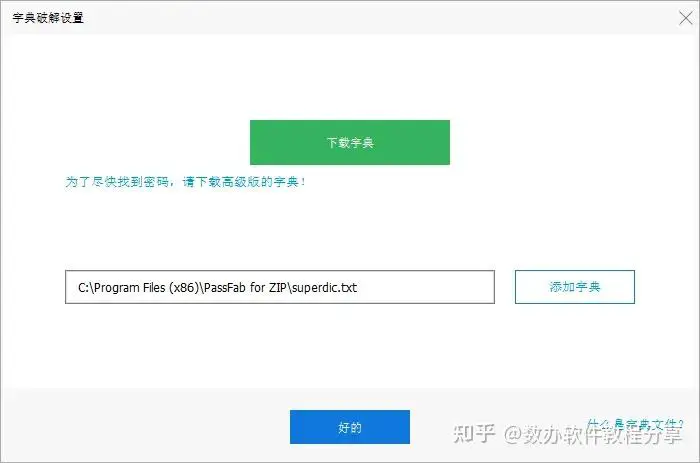
3.字典激活成功教程:如果你有记录密码的文档,可以将其存储为”.txt“文档,然后选择“设置”点击“添加字典”,该方式可以快速的在内置的字典或你添加的字典中查找密码。
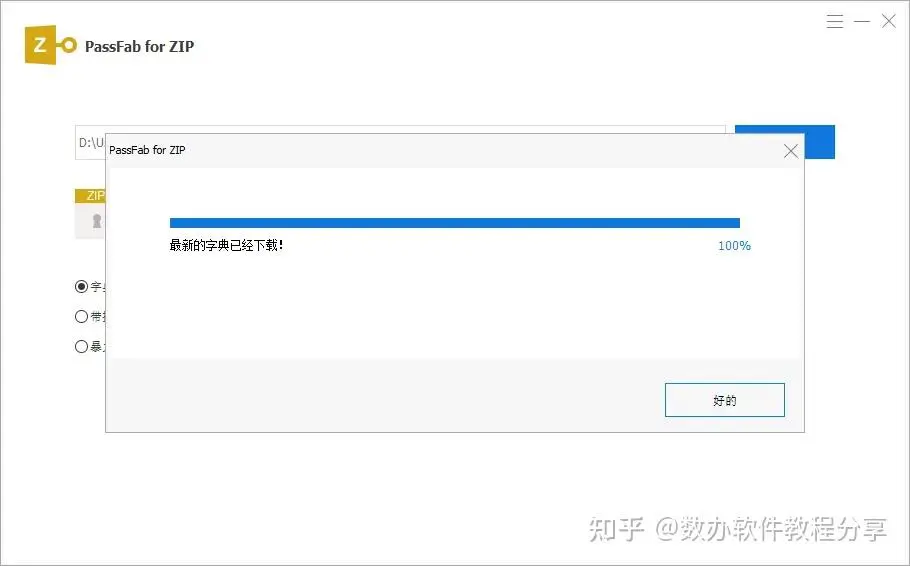
注意:有时会弹出一个提示升级字典库的视窗,这一步非常重要,请务必等待升级完成。
第 3 步:开始激活成功教程ZIP档密码
点击“开始”来进行密码激活成功教程,激活成功教程完成后就可以关闭软体了,然后使用找到的密码去访问加密的office档案就可以了。
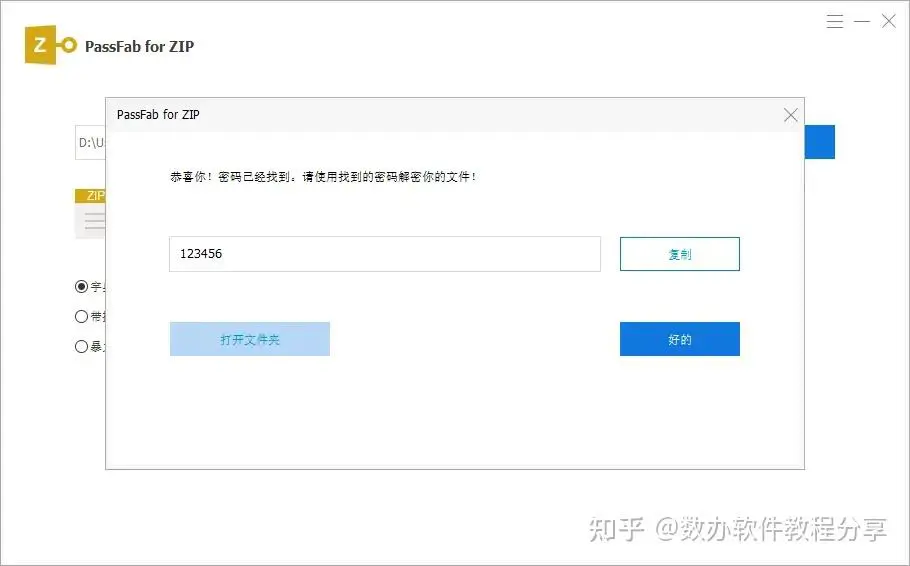
面对Zip压缩文件密码问题,我们可以采取多种策略来进行解决。关键是要根据实际情况选择合适的办法,以便更高效地完成解密工作。同时,我们也要意识到网络安全的重要性,定期更新密码,保护好自己的数据安全。

“太公……太……哎哟……”
员外刚一个转身,与家仆高才撞了个满怀。
员外用手点指:“你你你……你这小厮,跌跌撞撞,成何体统!”
高才坐在地上喘气笑脸道:“恭……恭喜……太……太公……法……法师……找到了!”
那一日,我闲来无事,一路游山玩水,无意间来到这个不大的镇甸。
正在路上走着,不期与这高才打了个照面。
没想到这小厮属社牛的,上前招呼都不打拽着我的胳膊就走。
这还了得,这有砖有瓦有王法的地方,竟敢光天化日之下强抢民男,是何居心,哪方道理?
这小厮将我拖了半里地,见我正欲发作,便直言道我就是他要找的法师。
什么法师?
我像法师?
他说我眉分八彩、目若朗星,相貌甚伟、仪表堂堂,不是法师,难道是道士?
合着这叫法师啊,虽然你说的都是事实,但是我不会法术啊!
高才却指天赌誓,说家中正请法师,如若得力,员外爷必有重谢!
真新鲜哈,正好我也没啥事,且随他前去观看观看。
由此才有了开头一幕。
来到庄上,与员外寒暄两句,便将我请入厅中,各自分宾主落坐。
仆人献茶退下后,老员外突然失声抽泣,热泪两行、口打嗐声,诉说前情。
我这才知道,原来这户人家老夫妇二人,虽衬金衬银,却家中无子,唯有一个宝贝千金。
本想家中颇有些财产,便安排上门招赘,好将女儿留在身边。
半年前,来一男子,口称二十多里外福崚镇人,父母皆已往生,现单身一人,愿意入赘。
员外夫妇自然欢喜,可时间一久,人品素肠暴露,平日里好吃懒做打骂下人也就罢了,如今吃了些酒就爱撒泼耍疯,连员外老夫妇俩都要打骂。
前几日他居然擅自将小姐单独关在后院,还将大门上锁。
后来趁他不在,才从小姐口中得知,这锁的密码可能就放在家中电脑的一个压缩文件里。
可当找到了这个文件时,却发现它需要输入密码才能打开。
然而众人不知密码,猜测尝试无论多少次都不行。
之前也请过几个法师来看过,烧香的烧香,祷告的祷告,作法的作法,听说连暴力激活成功教程啥的黑客工具都用上了,还不是个个败下阵来,毫无办法。
员外看我毛发稀疏、镜片深厚,五官貌相与众不同必是大材,因此对我抱有一线希望。
怎么听这味儿,这法师是专业搞计算机的?
我还在纳闷,只见员外屏退左右,将电脑从一墙壁暗盒中取出……
打开电脑,找到那个 ZIP 压缩文件,双击它就管你要密码,否则啥都看不见。
操作都没问题,不过你说这叫什么事,连黑客都搞不定的事,我能有什么办法呢,我又不黑!
员外看出我有些为难,便吩咐道:“来啊!先给法师拿二百两银子!”
哎哟……我……这不就见外了嘛!
就冲我的专业,我不能再怠慢了……
我口送法号,念念有词,结果研究了半天,毫无起色。
正在一筹莫展之际,我突然灵光乍现,想到了一种可能的情况。
会不会是……?
于是我用立马用16进制文件编辑器打开这个压缩文件,用眼睛扫了扫,果然验证了我的猜测!
哈哈,我紧锁的双眉舒展了开来,原来如此……
先来简单说说关于 ZIP 文件的小姿势,真的是简单地说说。
ZIP 是一种我们常见的压缩格式,一个 ZIP 文件通常由三大部分组成:
- 压缩源文件数据区,以
50 4B 03 04开头。 - 压缩源文件目录区,以
50 4B 01 02开头。 - 压缩源文件目录结束标志,以
50 4B 05 06开头。
这里我截了三幅图,各位可以对照参看。
压缩源文件数据区,就是一个或多个文件被压缩后它们的数据部分。
注意哈,这个标记不仅仅是在文件开头,只要压缩包里有多个文件,那么其他地方也存在对应的多个文件数据区。

压缩文件目录区,可以简单地理解为存放的是压缩源文件的索引记录。
其标记大概像这样。

压缩文件目录结束标志,与前者压缩文件目录区对应,形成一个目录的完美闭环。

光这么说,各位肯定得糊涂,还是画图为妙。
以下就是一个普通 ZIP 文件里面的样子,应该可以看到一些规律吧。
数据区1 数据区2 数据区N …… 目录区1 目录区结束标志1 目录区2 目录区结束标志2 目录区N 目录区结束标志N ……对于压缩文件1,在 ZIP 文件里就是先放数据区1,再放目录区1和目录区结束标志1。
剩下的以此类推,好理解了吧?
好,接下来揭秘。
我们只要知道有这么两个神秘的地方……
第一个,数据区加密位置,偏移量为 6 ,也就是在数据区开头后面的第 7 位(开头都是从 0 开始的)。
这个偏移为 6 的位置,叫做全局方式位标记。
来,上图,光靠想象不行的,还得看图。
看到没,从数据区 50 4B 03 04 标记往后边数(从 50 开始数),第 7 个就是全局方式位标记。
先记住它,后面要用。

接下来第二个,目录区加密位置,偏移量为 8 ,也就是目录区开头后面的第 9 位(开头都是从 0 开始的)。
这个偏移为 8 的位置,也叫做全局方式位标记,只是它是目录区的。
接着上图,看到没,从数据区 50 4B 01 02 标记往后边数(从 50 开始数),第 9 个就是全局方式位标记。

其他的这个那个不用管,就这么两个地方,就是我们变戏法的关键所在!
原理非常简单,要看一个 ZIP 文件是否加密,主要就是看压缩源文件(数据区)的全局方式位标记和压缩源文件(目录区)的全局方式位标记。
那么这两个地方怎么看,有什么讲究呢?
咳咳……员外,那个饭菜准备得……!
哦哦,虚位以待、随时恭候?
好好好,重点来了,听好!
答案可能简单得让你掉下巴,关键就在这两个标记数值的奇偶上,也就是单双数上,而和其他因素没有关系,并且不影响加密属性。
简单一句话,标记为偶数(如:00 、02 、04 等)则表示无加密,标记为奇数(如:01 、 03 、 07 等)则表示有加密。
当然了,数据区标记和目录区标记要相互配合,不能单蹦,这个网上很多教程都没有说清楚。
有人说了,这能行吗?
是骡子是马拉出来溜溜呗!
我们随便拿个 ZIP 文件来试试不就知道了?
找一个未加密的 ZIP 文件,用 WinHex 或是其他16进制编辑软件打开它。
先找到数据区标志 50 4B 03 04 ,然后将第 7 位改成任意奇数。

接着找到目录区标志 50 4B 01 02 ,然后将第 9 位改成任意奇数。

好了,保存,打完收工!
收什么工,还没测试呢!
测试很简单,打开刚才修改过的 ZIP 文件,你会发现奇迹出现了!
原来不要密码的,现在它……它居然……居然要密码了!
不管是系统自带的解压软件,还是第三方的解压工具,都会提示需要输入密码。
如果想要恢复成原来不需要输入密码的状态,那么只需要将修改的标记位再改为偶数即可。
是不是既简单又魔幻?
这就是传说中的 ZIP 伪加密!
说白了就是假的加密,不是真的加密。
这的确很有趣的对不对,为此我之前还特意做了一个小工具,方便伪加密和伪解密。
毕竟有时压缩包里不止一个文件,挨个查找并修改标记位能把人给干麻了!
网管小贾的ZIP伪加密演示程序
下载链接:https://pan.baidu.com/s/1ocqW2AsqK9UEoWYXtJsRvw
提取码:<关注公众号,发送001102>
知道了伪加密的原理,现在我们也就终于明白了,为啥输入任何密码都没有用,原因就是它根本就没有密码啊喂!
经过一番折腾,压缩文件中的密码文本文件总算是给解出来了!
员外冲着我竖起了两个大拇指,直呼:“真乃神人也!”
我谦虚地擦了擦口水,摸了摸肚子……
席间,我也没客气,吃了个沟满壕平,一边抹嘴一边喊:“服务员……那个……有水果没?”
高才闻声赶来给我满酒,说一会儿水果就到。
之后他恳请我送他一个伪加密演示程序。
我自然慷慨赠与,不过同时告诫他,不可用此做出什么坏事,否则若是我知道定将其化为齑粉。
高才一呲牙,承诺定当铭记在心。
随后仆人送上水果,高才顺手递给我一只大红桃,附耳告诉我今晚小姐想感谢我,顺便一睹法师尊容,可否留宿一夜,明日再走。
我咬了一口桃子,顿觉甘甜可口、满齿留香。
我表面默不作声,实则计上心来……
将技术融入生活,打造有趣之故事
网管小贾 / http://sysadm.cc
7z压缩包如何设置加密?今天给大家分享7-zip加密、解密教程。包括忘记了压缩包密码该如何解决?
右键文件选择7-zip打开压缩软件进行压缩或者在打开7-zip软件找到需要压缩的文件,点击添加,开始压缩文件
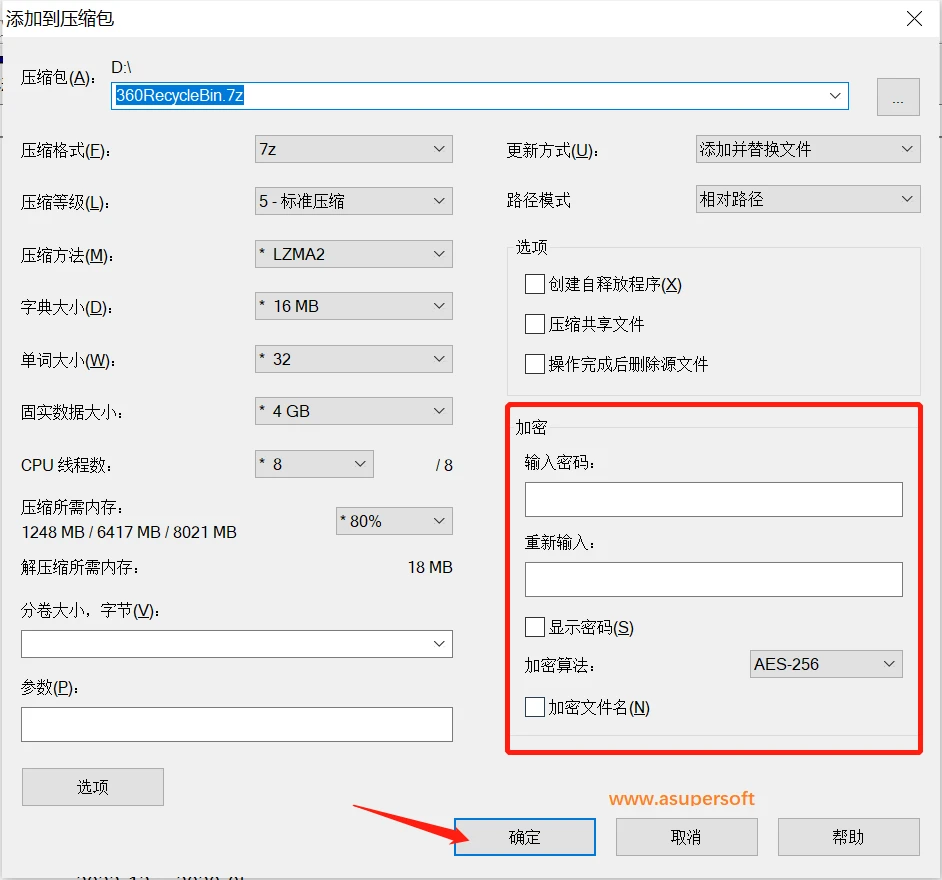
在压缩文件设置界面,我们可以看到有加密模块,在这里我们设置压缩包密码,点击确定就可以开始压缩带有密码的压缩包了。
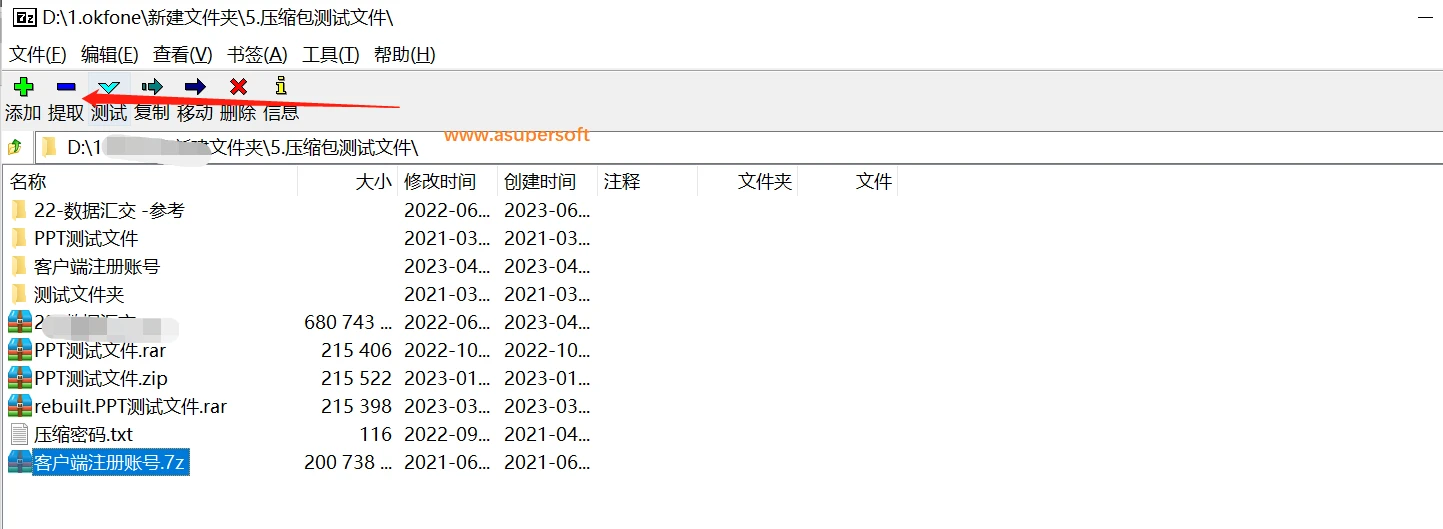
因为压缩工具没有提供解密功能,所以我们需要打开工具,找到需要解密的压缩包,点击提取功能。
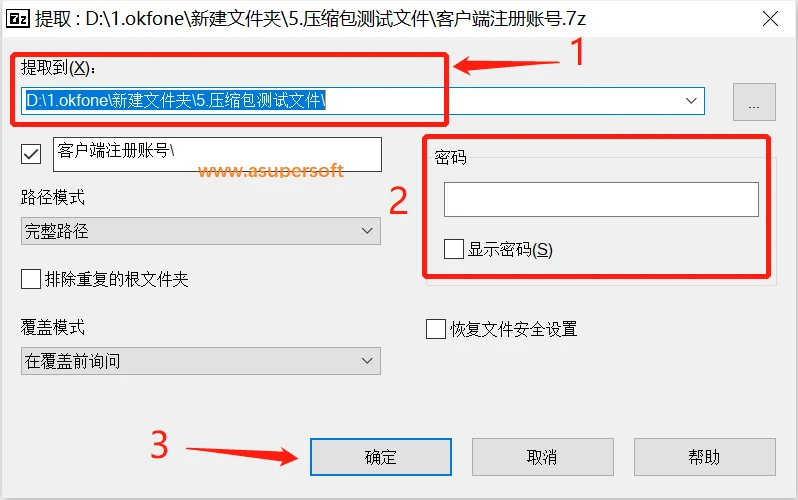
我们先将文件解压路径设置好,然后在密码出输入压缩包的密码,点击确定。压缩包成功解压之后,我们再将文件压缩为不带密码的压缩包即可完成解密。
我们可以看到,想要解密压缩包密码,需要先输入密码才行,然后,压缩工具除了没有提供解密功能以外,也没有提供恢复密码的功能。所以忘记了密码,我们就只能自己解决问题。比如尝试多个自己经常会用到的密码进行解压,如果碰到了正确的密码,那就可以顺利解压了,比如使用密码辅助工具,选择工具中提供的方法,让工具帮助我们找回密码
以上就是zip压缩包怎么加密码保护的设置方法,希望可以帮助到大家。
先介绍一下关于zip伪加密的小知识点~
zip伪加密是在文件头的加密标志位做修改,进而再打开文件时识被别为加密压缩包
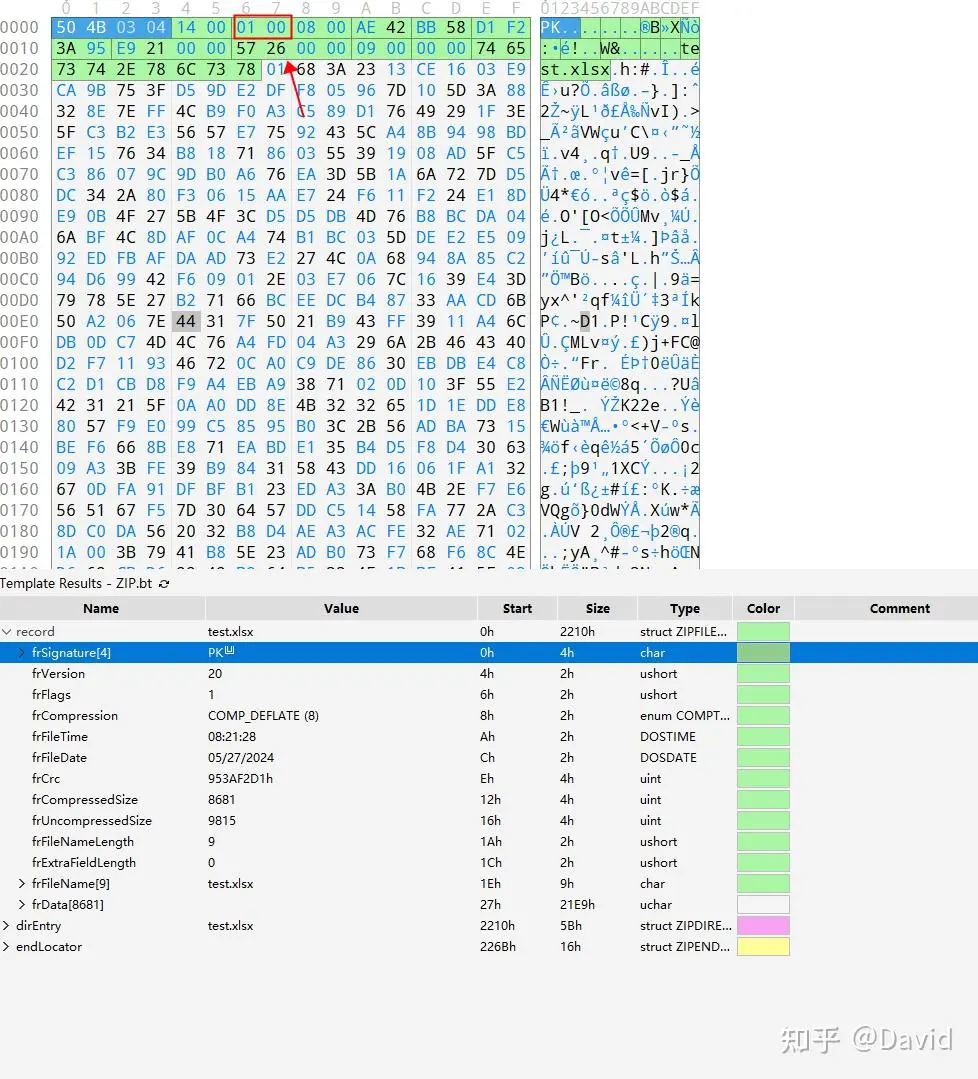
一个 ZIP 文件由三个部分组成:
压缩源文件数据区+压缩源文件目录区+压缩源文件目录结束标志
压缩源文件数据区:
50 4B 03 04:这是头文件标记(0x04034b50)
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密)
08 00:压缩方式
5A 7E:最后修改文件时间
F7 46:最后修改文件日期
16 B5 80 14:CRC-32校验(1480B516)
19 00 00 00:压缩后尺寸(25)
17 00 00 00:未压缩尺寸(23)
07 00:文件名长度
00 00:扩展记录长度
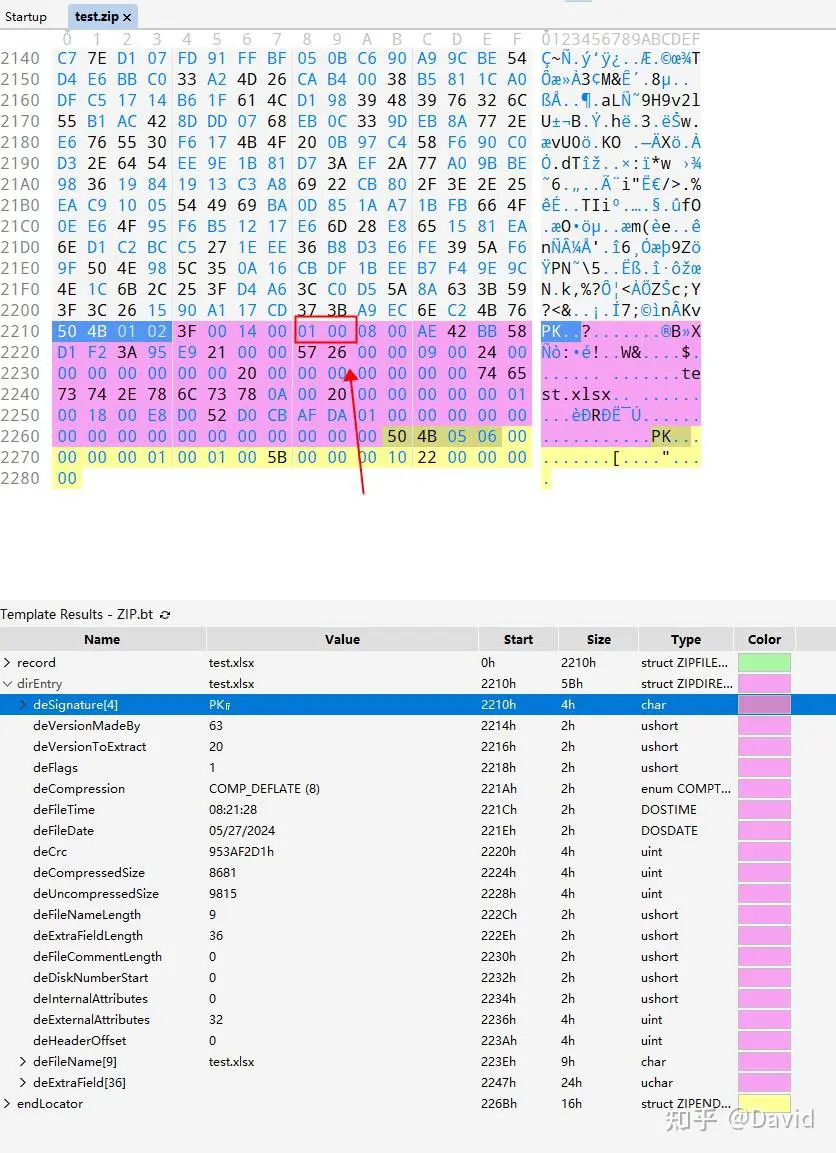
压缩源文件目录区:
50 4B 01 02:目录中文件文件头标记(0x02014b50)
3F 00:压缩使用的 pkware 版本
14 00:解压文件所需 pkware 版本
00 00:全局方式位标记(有无加密,这个更改这里进行伪加密,改为09 00打开就会提示有密码了。注意:这里只要是奇数就是加密,偶数就是未加密)
08 00:压缩方式
5A 7E:最后修改文件时间
F7 46:最后修改文件日期
16 B5 80 14:CRC-32校验(1480B516)
19 00 00 00:压缩后尺寸(25)
17 00 00 00:未压缩尺寸(23)
07 00:文件名长度
24 00:扩展字段长度
00 00:文件注释长度
00 00:磁盘开始号
00 00:内部文件属性
20 00 00 00:外部文件属性
00 00 00 00:局部头部偏移量
压缩源文件目录结束标志:
50 4B 05 06:目录结束标记
00 00:当前磁盘编号
00 00:目录区开始磁盘编号
01 00:本磁盘上纪录总数
01 00:目录区中纪录总数
59 00 00 00:目录区尺寸大小
3E 00 00 00:目录区对第一张磁盘的偏移量
00 00:ZIP 文件注释长度
接下来查看下加密后的zip压缩包的对应标志位
因此,在真实的zip加密包中,压缩源文件数据区和压缩源文件目录区的加密标志位都被修改为了“01 00”。
因为加密标志位有两类,下面分别对其进行测试
1、只修改“压缩源文件数据区的加密标志位”
测试结果:未实现“伪加密”
2、只修改“压缩源文件目录区的加密标志位”
测试结果:实现“伪加密”
3、同时修改“压缩源文件数据区的加密标志位”和“压缩源文件目录区的加密标志位”
测试结果:实现“伪加密”
结论:可见实现zip压缩包伪加密的核心是修改“压缩源文件目录区的加密标志位”。
添加伪加密:java -jar ZipCenOp.jar e test.zip
去除伪加密:java -jar ZipCenOp.jar r test.zip
下载链接:ZipCenOp.jar
以上是个人对于zip包伪加密的总结,欢迎批评指正。
在日常工作和学习中,我们经常会遇到需要压缩文件以节省存储空间或便于传输的情况。然而,有时即便使用了Zip格式进行压缩,得到的压缩包体积仍然过大,无法满足需求。本文将深入探讨几种专业的策略和技巧,帮助您有效缩小Zip压缩包的体积。
方法一:
适当减少文件内的不必要文件。
方法二:
使用7-zip格式压缩包,会比zip格式压缩包的压缩率更大。
方法三:
对文件进行压缩的时候,选择分卷压缩,按照文件大小,将文件分为几个压缩包,按照需要进行解压使用。
在压缩界面我们找到分卷压缩的设置框,根据文件大小
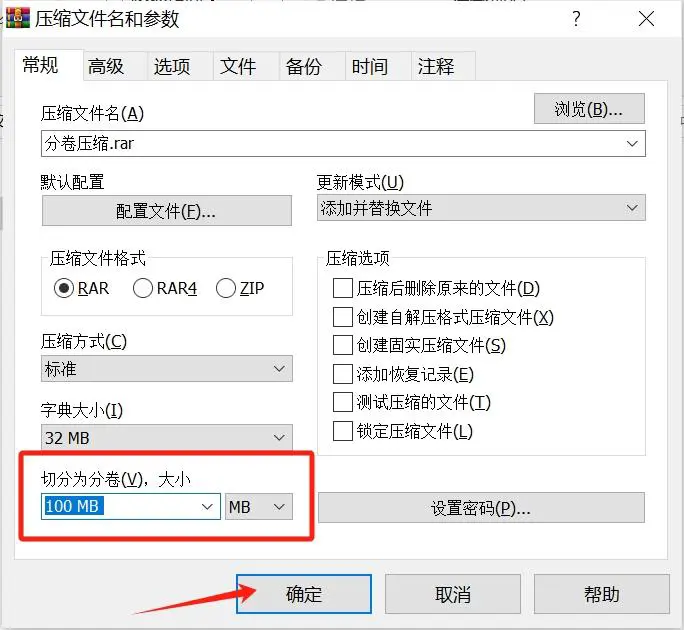
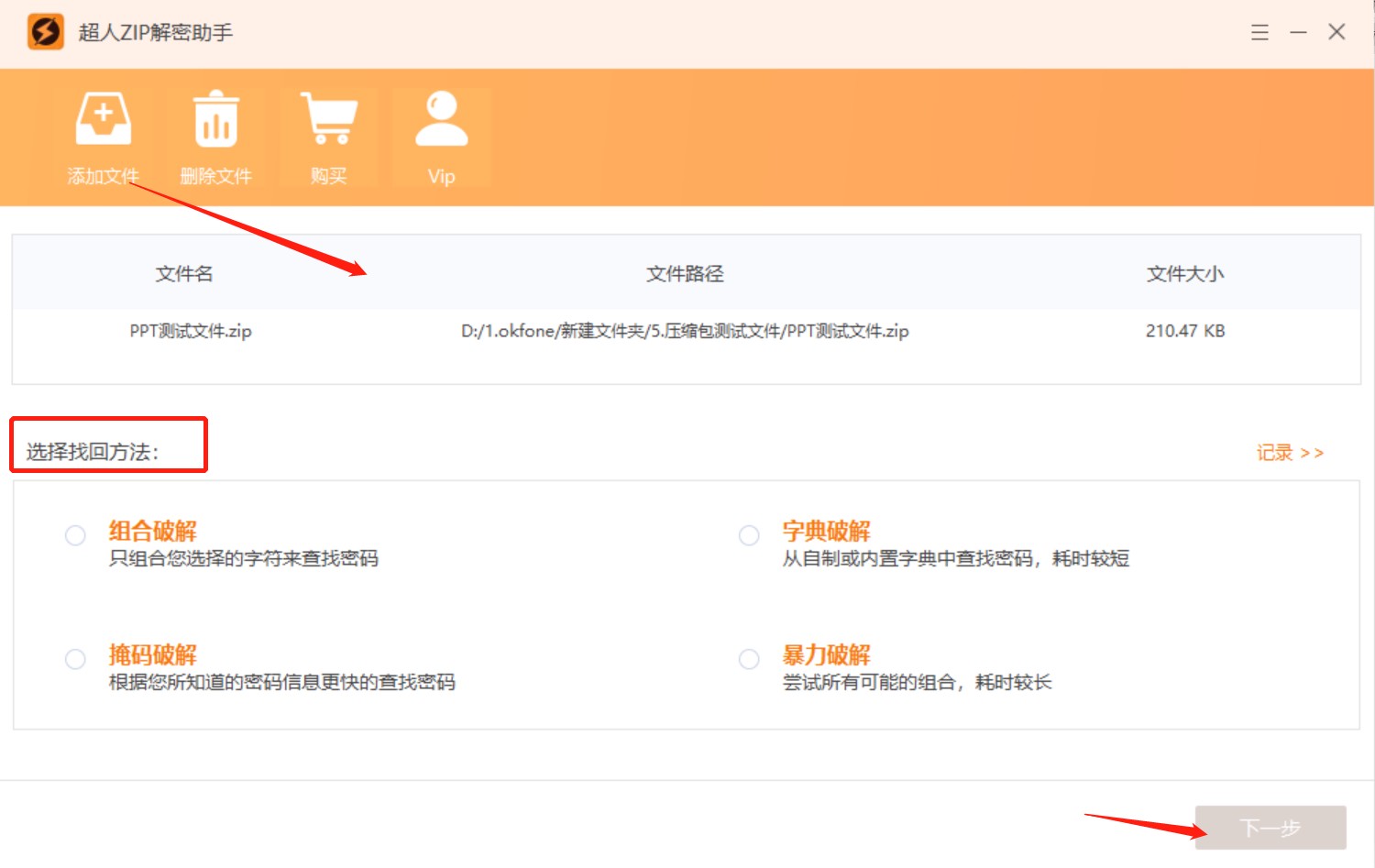
这里需要注意的是,分卷压缩出来的压缩包,不要随意修改保存路径和文件名,其中的一个文件有改变会导致后期无法解压整个压缩包。并且对压缩包如果进行了加密,解压的时候仍然需要输入密码才能够解压出文件,忘记了密码,需要找回密码,比如使用超人ZIP解密助手提供的四种方法帮助我们找回密码。
以上就是缩小zip压缩包体积的三种方法,希望可以帮助到大家~
在处理大量数据或需要通过网络传输大型文件时,Zip分卷压缩成为了一种高效的数据管理方式。这种技术将一个大文件分割成多个较小的压缩包(通常称为“分卷”),便于存储、传输和共享。然而,对于初次接触Zip分卷压缩的用户来说,解压这些文件可能会有些困惑。本文将提供专业指南,帮助您轻松完成Zip分卷压缩文件的解压过程。
找到需要解压的分卷压缩包,建议大家右键选择第一个分卷压缩包,使用压缩软件进行解压,因为压缩软件不同,对于解压分卷压缩包的要求也不同。
比如WinRAR仅支持点击第一个文件进行解压,7-Zip使用其他分卷压缩包解压会出现错误,而一些其他的压缩软件支持任一个分卷压缩包进行解压。
注意:分卷压缩出来的压缩包,不要修改其中任一个压缩包的名称及路径,否则会导致解压失败。
如果在分卷压缩的时候设置了密码,在解压的时候,我们也需要输入密码才能够解压,如果忘记了密码,我们需要先将分卷压缩包合并成一个压缩包,然后早找回密码。
想要合并压缩包,我们可以使用7-zip中的合并功能,右键选择第一个压缩包,选择【合并文件】即可
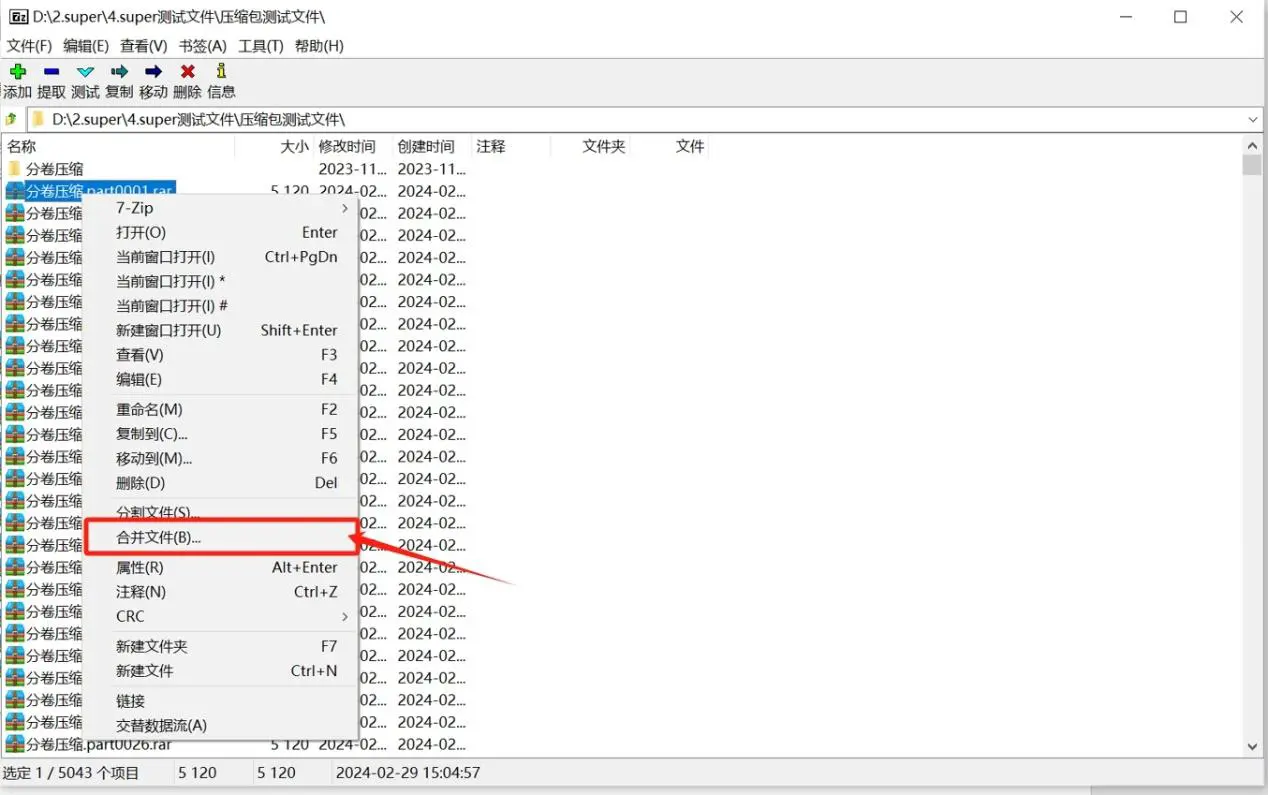
合并好的zip压缩包,我们可以尝试使用工具帮助我们找回密码,比如奥凯丰 ZIP解密大师,将压缩包添加到软件中,提供四种方法帮助我们找回密码
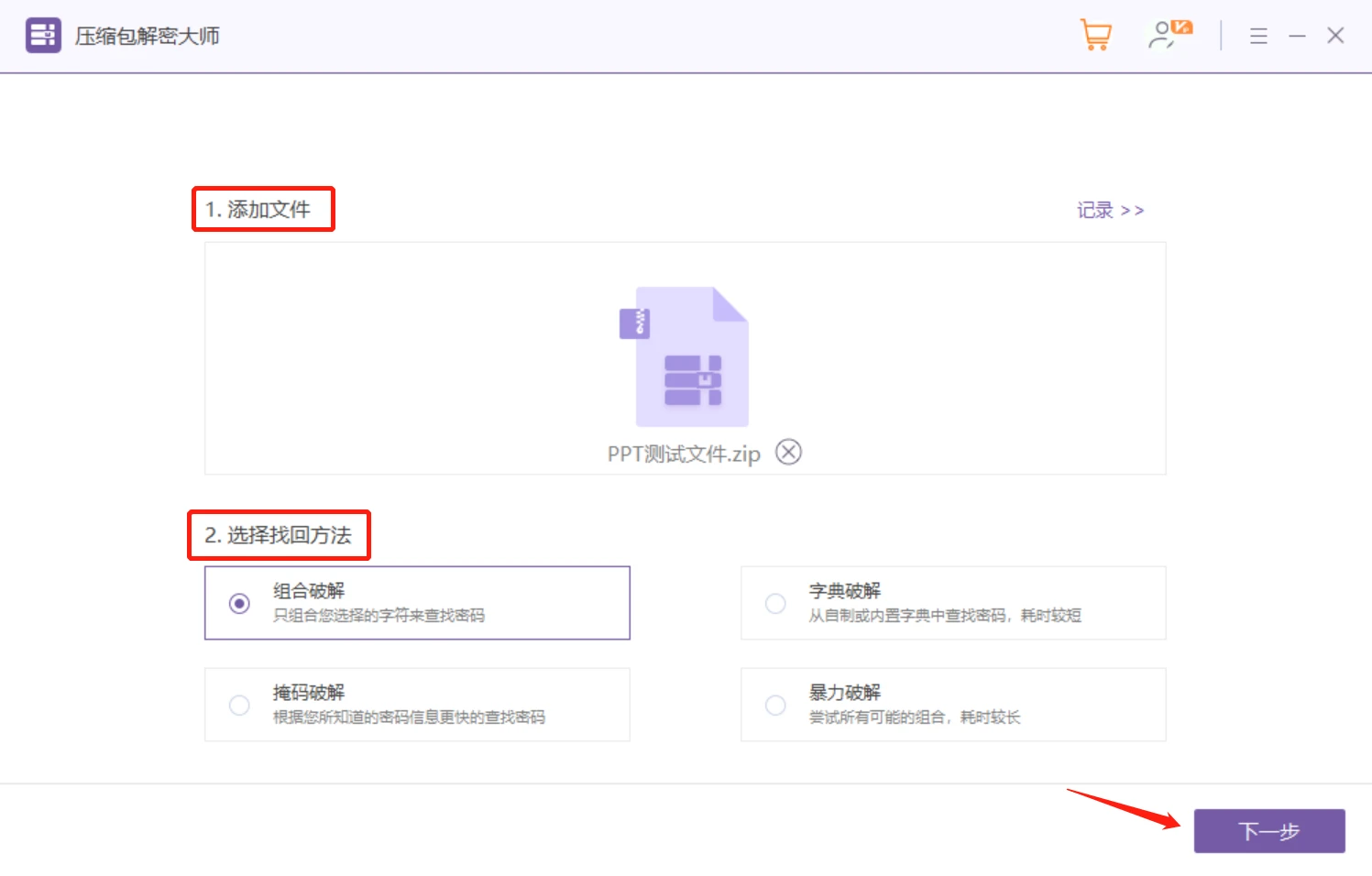
以上就是zip分卷压缩合并解压的方法,希望可以帮助到大家。
在处理ZIP压缩文件时,密码保护是一种常见的安全措施,用于确保文件内容的安全性和隐私性。然而,在某些情况下,您可能需要删除ZIP压缩包的密码,以便更轻松地访问其内容。本文将介绍四种高效且专业的技术方法,帮助您删除ZIP压缩包的密码。
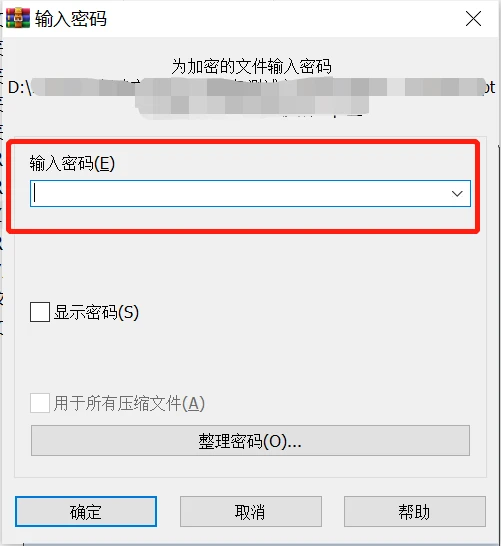
方法一:
最原始的方法,就是通过解压文件,将解压出的文件重新进行压缩,并且在压缩过程中不进行加密。即可达到取消密码的目的。当然解压文件需要输入正确的压缩包密码。
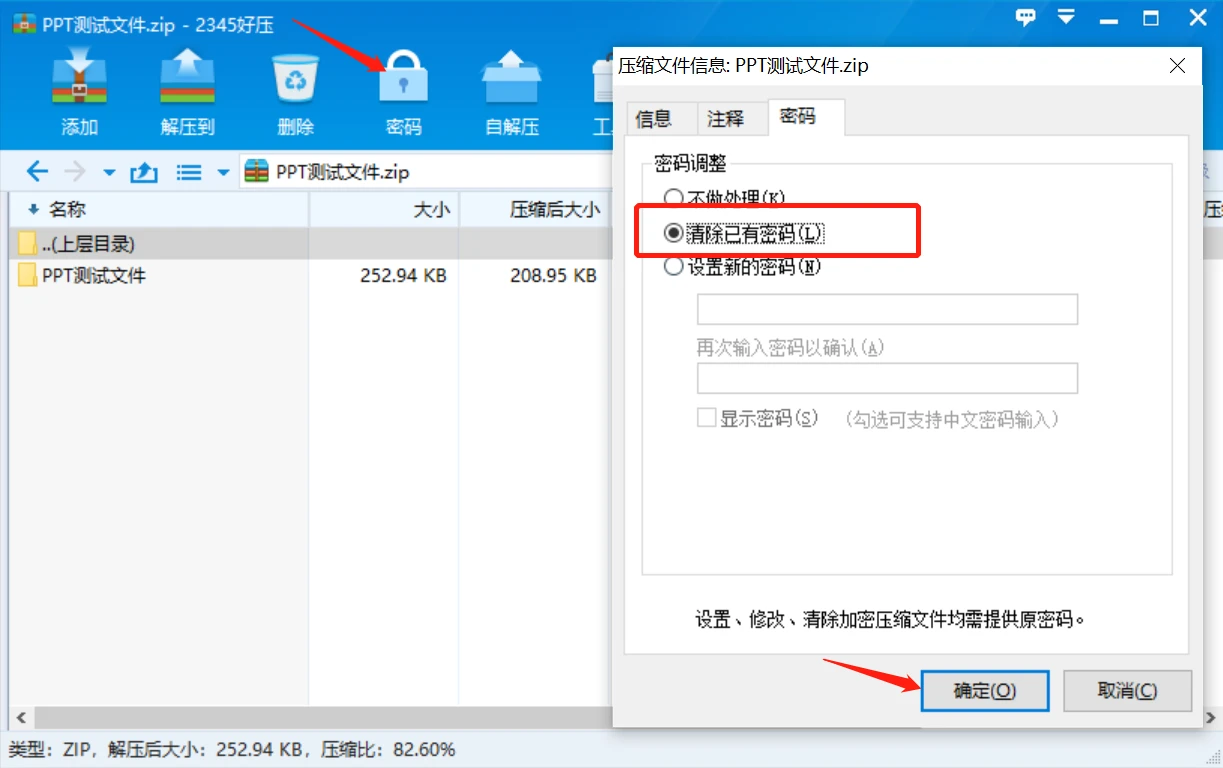
方法二:
还有一种方法就是看大家使用的压缩软件了,首先可以确定的是winrar、7-zip这两个压缩软件没有取消密码功能,比如我用的这个压缩软件是带有取消密码功能的。打开软件,点击密码 – 清除已有密码,输入压缩包的密码点击【确定】就可以了。
方法三:
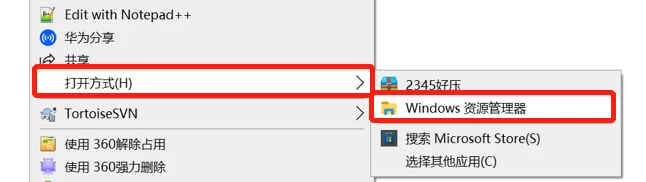
然后会出现一个压缩包名称一样的文件夹,我们在文件夹中的空白处点击鼠标右键,选择最下面的删除密码
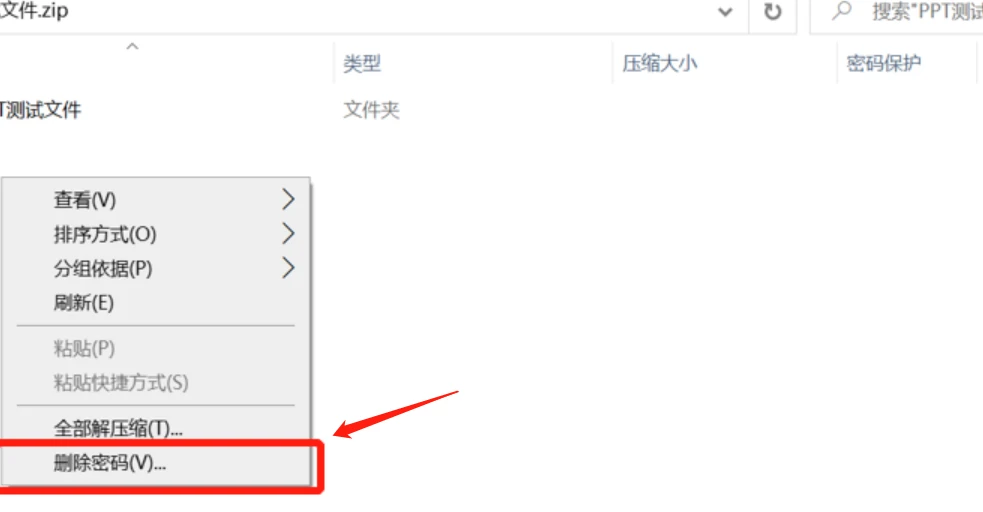
最后,在弹出的密码提示框中,输入zip压缩包密码点击确定,就可以删除zip密码了。
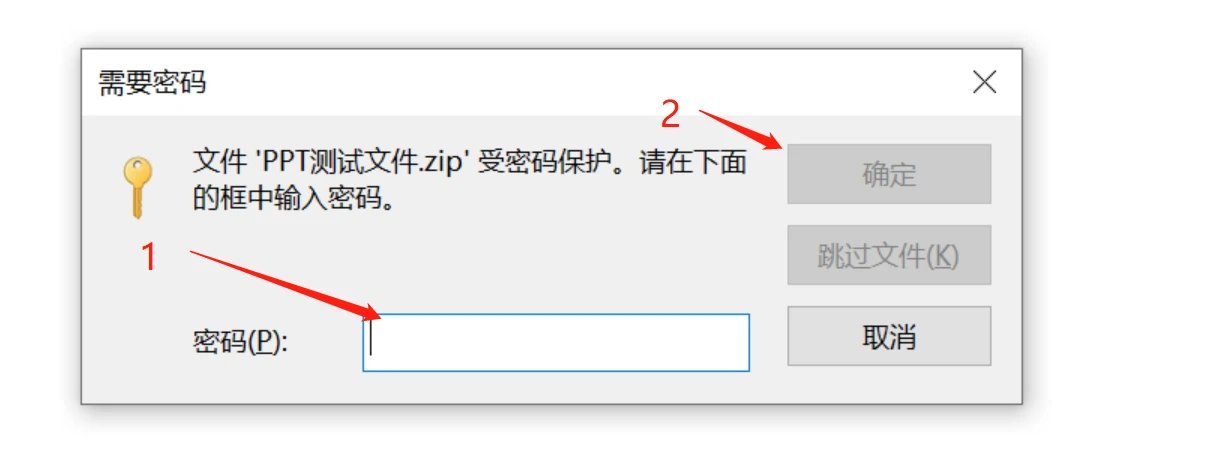
方法四:
但是如果我们忘记了密码或者没有密码,那我们就不能使用以上方法删除zip密码的,我们需要先找回密码才能够继续删除密码。找回密码,我们可以自己尝试输入不同的密码直到找到正确的密码也可以使用工具帮我们找回密码,比如超人ZIP解密助手,四种方法支持我们找回密码。
以上就是删除zip压缩包密码的四种方法,希望能够帮助到大家~
ZIP分卷压缩包作为一种有效节省空间、便于传输大文件的方法,被广泛应用。然而,对于不熟悉这一技术的用户来说,如何正确解压ZIP分卷压缩包可能成为一个难题。本文将为您提供专业的方法,帮助您轻松解决ZIP分卷压缩包的解压过程。
一、
我们可以直接点击第一个分卷压缩包,直接解压,就可以将文件整个解压出来了
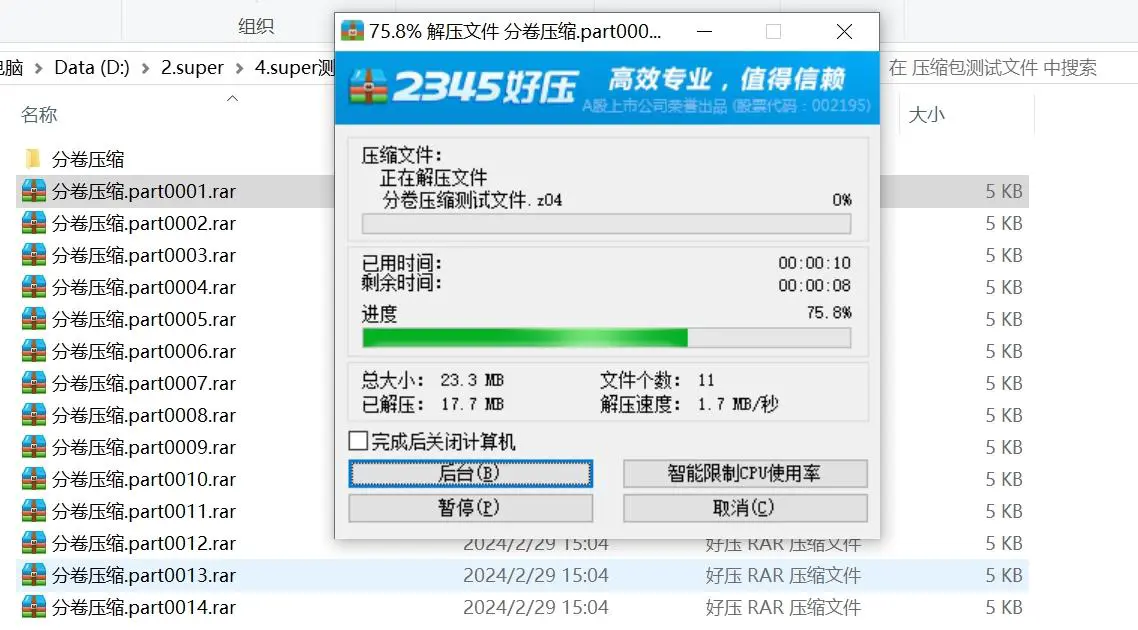
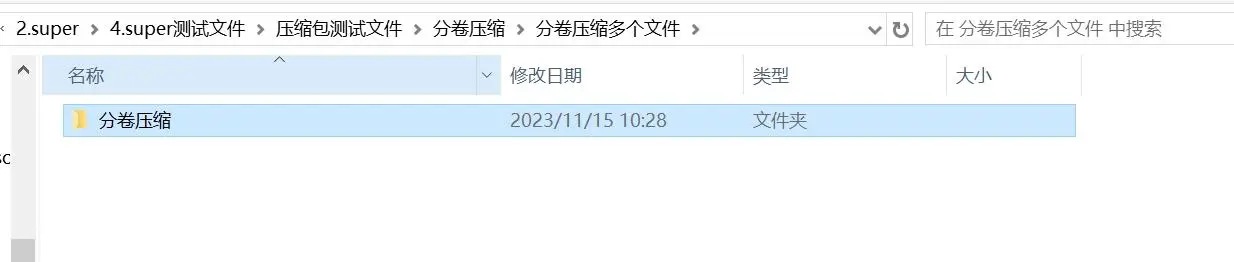
解压出来的文件是整个的
二、
除此之外,我们还可以使用7-ZIP中的合并压缩包功能,我们打开7-ZIP,找到需要合并的分卷压缩包,点击上方工具栏中的【文件】
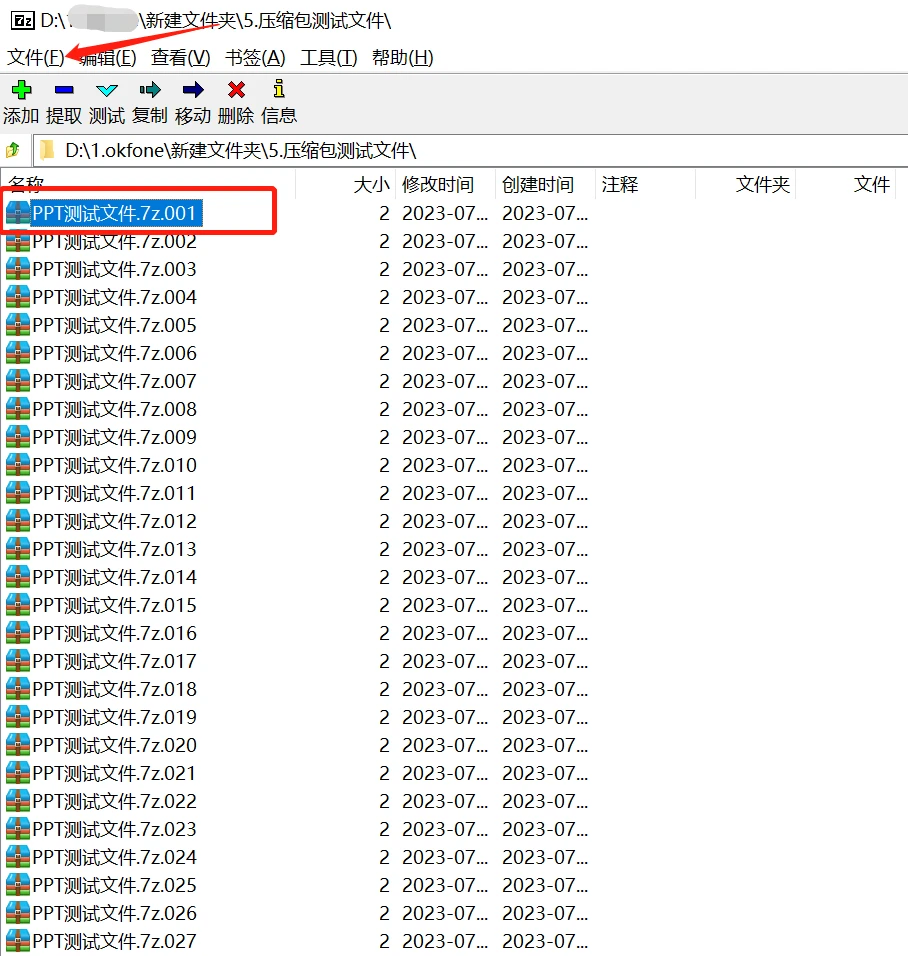
然后在功能列表中找到并点击【合并文件】
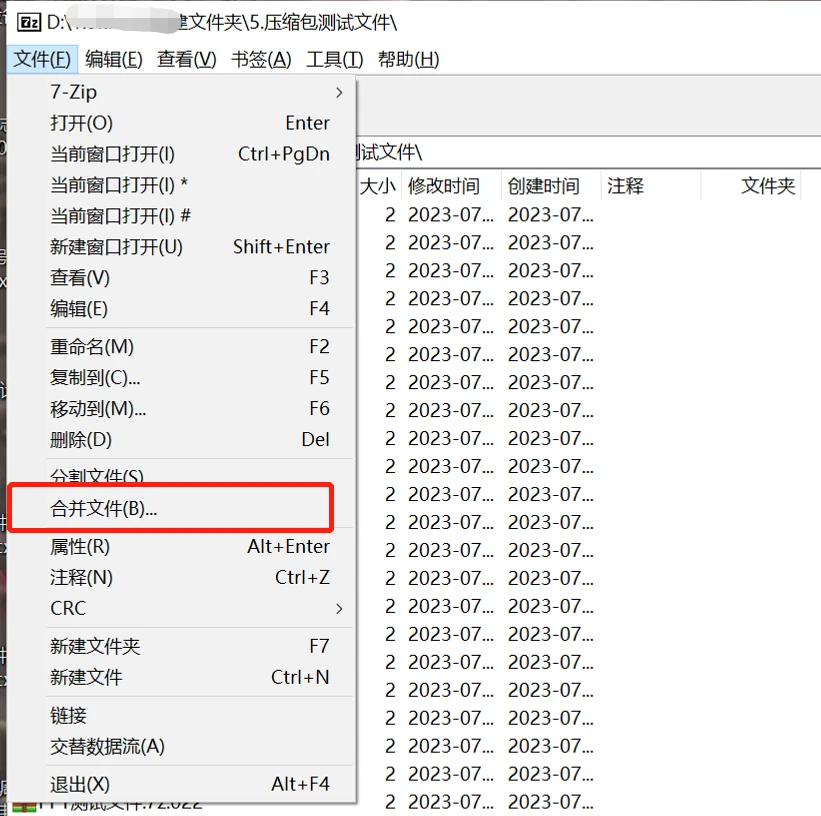
选择合并后压缩包的保存路径,点击【确定】就可以开始合并分卷压缩包了,然后我们再解压文件就是整个文件夹了。
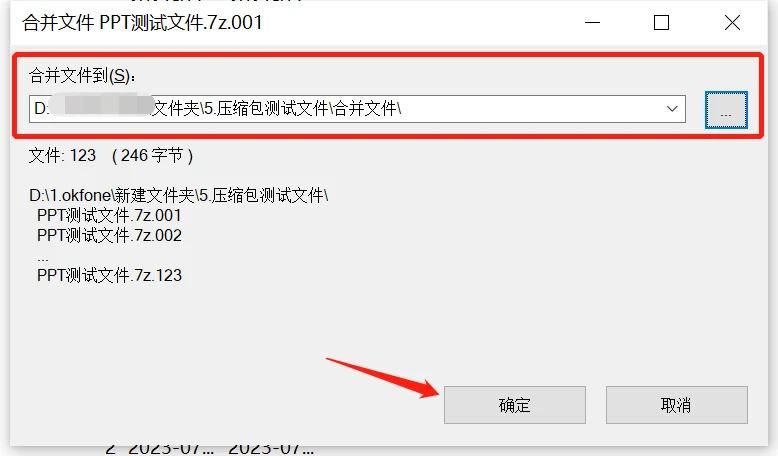
如果在进行分卷压缩时设置了加密,我们需要输入密码之后才能够进行方法一的操作,并且分卷压缩包合并之后,加密密码仍然存在,如果忘记了密码,我们需要先将zip分卷压缩包合并为一个,然后借助工具帮助找回压缩包密码,才能够解压文件了,比如超人ZIP解密助手,提供了四种方法,帮助我们找回zip压缩包密码
以上就是ZIP分卷压缩如何解压的两种解决方法,希望可以帮助到大家~
到此这篇安装软件后缀zip是什么意思(安装软件后缀zip是什么意思啊)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/hd-yjs/12932.html