
通过给定的索引(index)和列(column)的值重新生一个DataFrame对象。
根据列值对数据进行整形(生成一个“透视”表)。从指定的索引/列中使用唯一的值来形成结果数据帧的轴。此函数不支持数据聚合,多个值将导致列中的多索引。
index:指定一列做为生成DataFrame对象的索引,如果为空则默认为原来的索引。
columns:指定一列的值作为列名,必须传值。
values:指定一列作为生成DataFrame对象的值。可以为空。






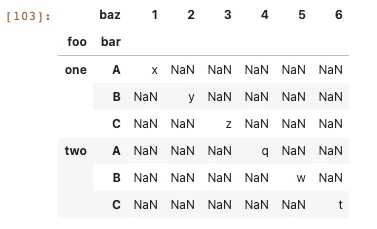
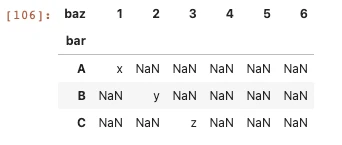
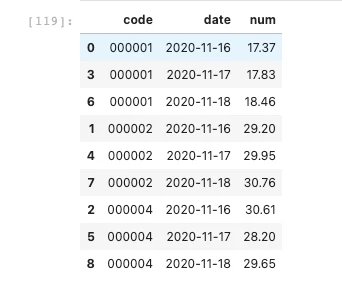
现在要上图中的不同code之间从2020-11-16到2020-11-18三天内num序列数的相关性。
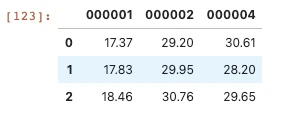
第二种方法就是使用pivot函数,一行代码解决,运行快速。
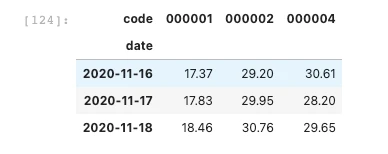
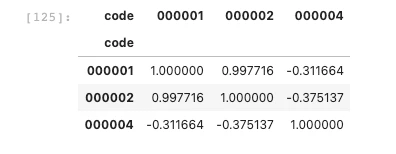
想要的形式的dataframe生成了就可以直接调用corr()函数直接求出code之间的相关性了
到此这篇关于pandas应用实例之pivot函数的文章就介绍到这了,更多相关pandas pivot函数内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
到此这篇pivot函数的作用(pd.pivot函数)的文章就介绍到这了,更多相关内容请继续浏览下面的相关 推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/haskellbc/80796.html