

大侠幸会,在下全网同名[算法金]
0 基础转 AI 上岸,多个算法赛 Top
[日更万日,让更多人享受智能乐趣]
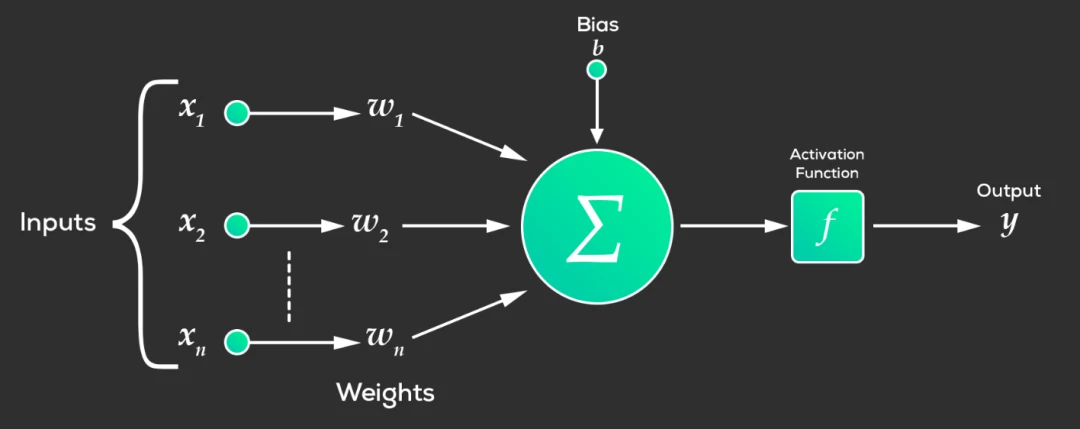

1.1 定义和函数形式
Sigmoid函数是一种常用的激活函数,其数学形式为:
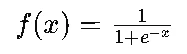
它将输入的实数映射到(0,1)之间,常用于输出层的二分类问题,可以将神经网络的输出解释为概率。
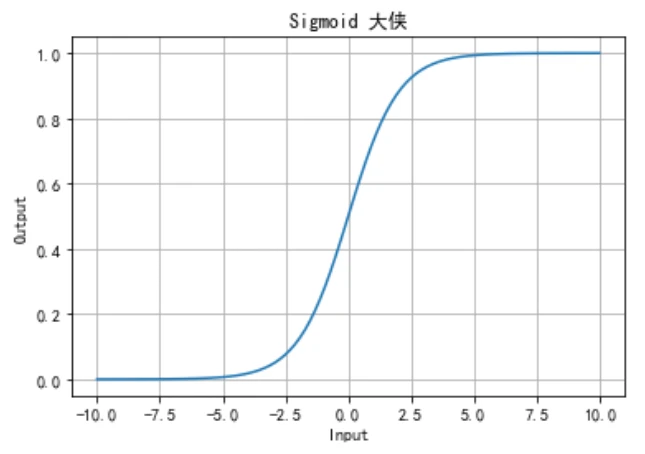
1.2 手动实现并可视化
你可以使用Python代码手动实现Sigmoid函数,并通过绘图工具将其可视化,以便理解其形状和特点。
1.3 作用和用途
Sigmoid函数在神经网络中主要用于输出层的二分类问题,将神经网络的输出映射到(0,1)之间的概率值,便于进行分类决策。
1.4 优点和局限性
- 优点:
- 输出范围为(0,1),可以被解释为概率。
- 平滑的S形曲线,可以保持梯度的连续性,有利于反向传播算法的稳定性。
- 局限性:
- Sigmoid函数存在梯度饱和问题,当输入较大或较小时,梯度会接近于零,导致梯度消失,影响网络的训练。
- Sigmoid函数的输出不是以零为中心的,可能导致梯度更新不均匀,影响训练速度。
1.5 梯度消失和梯度爆炸问题
Sigmoid函数在输入较大或较小时,会出现梯度接近于零的问题,导致梯度消失,使得网络难以收敛或学习缓慢。
1.6 建议的使用场景
- 二分类问题的输出层。
- 对输出范围有明确要求的任务。

2.1 定义和函数形式
Tanh函数(双曲正切函数)是一种常用的激活函数,其数学形式为:
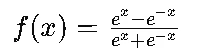
它将输入的实数映射到(-1,1)之间,具有S形曲线,常用于隐藏层的激活函数。
2.2 手动实现并可视化
你可以使用Python代码手动实现Tanh函数,并通过绘图工具将其可视化,以便理解其形状和特点。

2.3 作用和用途
Tanh函数在神经网络中常用于隐藏层的激活函数,将输入映射到(-1,1)之间,可以提供更广泛的输出范围,有利于神经网络的学习。
2.4 优点和局限性
- 优点:
- 输出范围为(-1,1),相比Sigmoid函数更广泛,可以提供更大的梯度,有利于神经网络的学习。
- Tanh函数是Sigmoid函数的平移和缩放版本,具有相似的S形曲线,但输出以零为中心,有助于减少梯度更新不均匀的问题。
- 局限性:
- Tanh函数同样存在梯度饱和问题,当输入较大或较小时,梯度会接近于零,导致梯度消失,影响网络的训练。
- Tanh函数的输出范围仍然有限,可能在某些情况下导致梯度爆炸或梯度消失问题。
2.5 梯度消失和梯度爆炸问题
Tanh函数在输入较大或较小时,同样会出现梯度接近于零的问题,导致梯度消失,使得网络难以收敛或学习缓慢。
2.6 建议的使用场景
- 隐藏层的激活函数,特别是对输出范围有明确要求的任务。
- 在需要使用Sigmoid函数的情况下,考虑使用Tanh函数代替,因为Tanh函数具有更广泛的输出范围。
3.1 定义和函数形式
ReLU函数是一种简单而有效的激活函数,其数学形式为:
它将输入的实数映射到大于等于零的范围,如果输入小于零,则输出为零;如果输入大于零,则输出与输入相同。
3.2 手动实现并可视化
你可以使用Python代码手动实现ReLU函数,并通过绘图工具将其可视化,以便理解其形状和特点。
3.3 作用和用途
ReLU函数在神经网络中广泛用于隐藏层的激活函数,能够加速训练过程,避免了Sigmoid函数和Tanh函数存在的梯度消失问题。
3.4 优点和局限性
- 优点:
- ReLU函数在输入大于零时,梯度恒为1,不会饱和,避免了梯度消失问题,有利于加速训练过程。
- 计算简单,只需比较输入和零的大小即可,运算速度快。
- 只有一个分段,导数在大多数情况下为常数,便于反向传播计算。
- 局限性:
- ReLU函数在输入小于零时,导数为零,称为“神经元死亡”,可能导致对应神经元永远无法激活,称为“ReLU死亡”问题。
- 输出不以零为中心,可能导致梯度更新不均匀,影响网络性能。
3.5 梯度消失和梯度爆炸问题
ReLU函数在输入小于零时,导数为零,可能导致梯度消失问题。但在输入大于零时,梯度恒为1,不会饱和,避免了梯度爆炸问题。
3.6 建议的使用场景
- 隐藏层的激活函数,特别是在需要加速训练过程和处理稀疏数据的情况下。
- 对于不需要输出负值的任务,可以考虑使用ReLU函数代替其他激活函数。
4.1 定义和函数形式
Leaky ReLU函数是对ReLU函数的改进,其数学形式为:
其中a是一个小的斜率(通常接近于零),当输入小于零时,不再输出零,而是输出输入的一个小比例,以解决ReLU函数在负数部分输出为零的问题。
4.2 手动实现并可视化
你可以使用Python代码手动实现Leaky ReLU函数,并通过绘图工具将其可视化,以便理解其形状和特点。
4.3 作用和用途
Leaky ReLU函数在神经网络中用于隐藏层的激活函数,能够解决ReLU函数在负数部分输出为零的问题,避免“神经元死亡”的情况。
4.4 优点和局限性
- 优点:
- 解决了ReLU函数在负数部分输出为零的问题,避免了“神经元死亡”的情况。
- 保留了ReLU函数的大部分优点,计算简单,不会出现梯度爆炸问题。
- 局限性:
- 需要额外的参数a,需要手动调整或者通过训练学习,可能增加了模型的复杂性。
- 当a的值选择不当时,可能会导致模型性能下降。
4.5 梯度消失和梯度爆炸问题
Leaky ReLU函数在输入小于零时,输出的斜率为常数,不会出现梯度消失问题;在输入大于零时,输出的斜率为1,不会出现梯度爆炸问题。
4.6 示例和应用
- 隐藏层的激活函数,特别是在需要避免ReLU死亡问题的情况下。
- 适用于训练速度较慢的深度神经网络。
4.7 建议的使用场景
- 在需要避免ReLU函数输出为零的情况下使用,例如对负值敏感的任务或深度神经网络中的隐藏层。
- 当需要控制负值部分输出的比例时,可以通过调整参数a来灵活使用Leaky ReLU函数。
5.1 定义和函数形式
Parametric ReLU函数是对ReLU函数的改进,其数学形式为:
其中a是一个学习的参数,可以被网络训练得到,与Leaky ReLU函数不同的是,Parametric ReLU函数的斜率是通过训练得到的。
5.2 手动实现并可视化
你可以使用Python代码手动实现Parametric ReLU函数,并通过绘图工具将其可视化,以便理解其形状和特点。
5.3 作用和用途
Parametric ReLU函数在神经网络中用于隐藏层的激活函数,与ReLU和Leaky ReLU相比,其斜率可以通过训练过程中学习得到,具有更强的灵活性。
5.4 优点和局限性
- 优点:
- 可以通过学习得到参数a,具有更强的灵活性,可以根据任务自动调整斜率。
- 解决了ReLU函数输出为零和Leaky ReLU函数固定斜率的问题。
- 局限性:
- 需要额外的参数a,增加了模型的复杂度。
- 需要更多的计算资源和训练时间,可能导致训练过程更加复杂和耗时。
5.5 梯度消失和梯度爆炸问题
Parametric ReLU函数在输入小于零时,具有可学习的斜率,有助于避免梯度消失问题;在输入大于零时,输出的斜率为1,不会出现梯度爆炸问题。
5.6 示例和应用
- 隐藏层的激活函数,特别是在需要更灵活的斜率调整的情况下。
- 适用于需要对负值部分输出进行自适应调节的任务。
5.7 建议的使用场景
- 当需要更灵活的斜率调整时,可以考虑使用Parametric ReLU函数代替ReLU和Leaky ReLU函数。
- 当任务要求输出的负值部分具有不同的影响程度时,可以使用Parametric ReLU函数进行自适应调节。
6.1 定义和函数形式
ELU函数是一种激活函数,其数学形式为:
其中,α是一个较小的正数,通常取为1。ELU函数结合了ReLU的优点,并且解决了ReLU函数在负数部分输出为零的问题。
6.2 手动实现并可视化
你可以使用Python代码手动实现ELU函数,并通过绘图工具将其可视化,以便理解其形状和特点。
6.3 作用和用途
ELU函数在神经网络中作为激活函数,结合了ReLU的优点,能够加速训练,并解决了ReLU函数在负数部分输出为零的问题。
6.4 优点和局限性
- 优点:
- 在输入大于零时,ELU函数的导数始终为1,避免了ReLU函数的“神经元死亡”问题,有利于加速训练。
- 在输入小于等于零时,ELU函数不会输出零,解决了ReLU函数的“神经元死亡”问题,增强了模型的稳定性。
- 局限性:
- ELU函数相对复杂,计算代价较高。
6.5 梯度消失和梯度爆炸问题
ELU函数在输入大于零时,导数恒为1,不会出现梯度消失问题;在输入小于等于零时,导数的值也较大,有利于避免梯度消失问题。
6.6 示例和应用
- 隐藏层的激活函数,特别是在需要加速训练和提高稳定性的情况下。
- 适用于需要对负值部分输出进行更灵活处理的任务。
6.7 建议的使用场景
- 当需要解决ReLU函数的“神经元死亡”问题时,可以考虑使用ELU函数代替。
- 当需要更灵活地调节负值部分输出的情况下,可以使用ELU函数进行更细致的调节。
7.1 定义和函数形式
Softmax函数是一种常用的激活函数,用于将向量转化为概率分布,其数学形式为:
其中,Xi 是输入向量的第i个元素,n是向量的长度。Softmax函数将输入向量的每个元素转化为一个概率值,使得所有元素的概率之和为1。
7.2 手动实现并可视化
你可以使用Python代码手动实现Softmax函数,并通过绘图工具将其可视化,以便理解其形状和特点。
7.3 作用和用途
Softmax函数常用于神经网络的多分类问题的输出层,将神经网络的输出转化为类别概率分布,便于进行分类决策。
7.4 优点和局限性
- 优点:
- 将神经网络的输出转化为概率分布,直观且易于理解。
- 求解简单,可用于多分类问题。
- 局限性:
- Softmax函数对输入的敏感度较高,可能在输入较大或较小时产生数值不稳定的情况。
- Softmax函数的输出受到输入的所有元素的影响,可能导致类别之间的差异不够明显。
7.5 梯度消失和梯度爆炸问题
Softmax函数的梯度通常通过交叉熵损失函数进行反向传播计算,不会出现梯度消失或梯度爆炸的问题。
7.6 示例和应用
- 图像分类任务中的多分类问题。
- 自然语言处理中的词语分类问题。
7.7 建议的使用场景
- 多分类问题的输出层,特别是需要将神经网络的输出解释为类别概率分布时。
- 当任务需要处理多个类别的情况,且类别之间没有明显的顺序关系时。
8.1 定义和函数形式
Swish函数是由谷歌提出的激活函数,其数学形式为:
Swish函数结合了线性性质和非线性性质,可以被视为是ReLU函数的平滑版本,一定程度上提升了模型的性能。
8.2 手动实现并可视化
你可以使用Python代码手动实现Swish函数,并通过绘图工具将其可视化,以便理解其形状和特点。
8.3 作用和用途
Swish函数作为一种激活函数,在神经网络中用于隐藏层的激活函数。它结合了线性性质和非线性性质,在一定程度上提升了模型的性能。
8.4 优点和局限性
- 优点:
- Swish函数结合了ReLU函数的非线性性质和sigmoid函数的平滑性质,具有更好的性能表现。
- 相较于ReLU函数,Swish函数在一些情况下能够提供更好的结果。
- 局限性:
- Swish函数相对复杂,计算代价较高,可能增加模型的训练时间和资源消耗。
8.5 梯度消失和梯度爆炸问题
Swish函数的梯度通常不会出现梯度消失或梯度爆炸的问题,但在极端情况下可能存在数值不稳定的情况。
8.6 示例和应用
- 在图像分类、语音识别等领域中的深度学习任务中广泛应用。
9.1 定义和函数形式
Maxout函数是一种激活函数,将输入的一组实数分成若干组,然后取每组的最大值作为输出,其数学形式为:
其中,x 是输入向量,Wi 和 bi 是参数,k 是每组的大小。
9.2 通过Python代码手动实现并可视化
由于Maxout函数的实现涉及参数 w 和 b,因此在这里我们只提供一个简单的示例来说明其原理。在实际应用中,参数通常是通过神经网络的训练学习得到的。
Maxout函数输出:[3 6 9]
9.3 作用和用途
Maxout函数在神经网络中常用于隐藏层的激活函数,能够提供更强的拟合能力,增强模型的表达能力。
9.4 优点和局限性
- 优点:
- Maxout函数具有更强的拟合能力,能够处理更复杂的非线性关系。
- 相对于其他激活函数,Maxout函数可以通过学习参数来自适应地决定最大值的组合。
- 局限性:
- Maxout函数的参数较多,可能增加了模型的复杂度和训练时间。
- 对于小数据集或者低维数据,可能会出现过拟合的情况。
9.5 梯度消失和梯度爆炸问题
Maxout函数的梯度通常通过反向传播算法进行计算,不会出现梯度消失或梯度爆炸的问题。
9.6 建议的使用场景
- 当需要处理复杂的非线性关系时,可以考虑使用Maxout函数作为隐藏层的激活函数。
- 适用于大数据集和高维数据的深度学习任务。
- 图像分类、语音识别等领域中的深度学习任务。
10.1 定义和函数形式
Softplus函数是一种激活函数,其数学形式为:
Softplus函数是ReLU函数的平滑版本,避免了ReLU在零点处不可导的问题,同时保留了ReLU函数的非线性特性。
10.2 通过Python代码手动实现并可视化
你可以使用Python代码手动实现Softplus函数,并通过绘图工具将其可视化,以便理解其形状和特点。
10.3 作用和用途
Softplus函数常用于神经网络的隐藏层的激活函数,特别是在较深的神经网络中。它是ReLU函数的平滑版本,可以缓解梯度消失问题,同时保留了非线性特性。
10.4 优点和局限性
- 优点:
- Softplus函数是ReLU函数的平滑版本,避免了ReLU在零点处不可导的问题。
- 具有较好的非线性特性,在一些深度神经网络中表现良好。
- 局限性:
- Softplus函数的计算较复杂,可能会增加模型的训练时间。
- 当输入较大时,Softplus函数的输出接近线性关系,可能导致信息损失。
10.5 梯度消失和梯度爆炸问题
Softplus函数的梯度通常通过反向传播算法进行计算,相比于ReLU函数,Softplus函数的梯度在输入较小或较大时更稳定,可以缓解梯度消失和梯度爆炸问题。
10.6 建议的使用场景
- 当需要缓解ReLU函数在零点处不可导的问题,同时保留非线性特性时,可以考虑使用Softplus函数作为隐藏层的激活函数。
- 适用于较深的神经网络中,特别是在需要缓解梯度消失问题的情况下。
11.1 定义和函数形式
Mish函数是一种激活函数,其数学形式为:
Mish函数由印度的研究人员提出,相比ReLU函数,Mish函数在一些任务上表现更好。
11.2 通过Python代码手动实现并可视化
你可以使用Python代码手动实现Mish函数,并通过绘图工具将其可视化,以便理解其形状和特点。
11.3 作用和用途
Mish函数常用作神经网络的激活函数,相比ReLU函数,在一些任务上表现更好。它结合了ReLU函数、tanh函数和softplus函数的优点。
11.4 优点和局限性
- 优点:
- Mish函数在一些任务上表现更好,相比ReLU函数具有更强的拟合能力。
- 结合了ReLU函数、tanh函数和softplus函数的优点,具有较好的非线性特性。
- 局限性:
- Mish函数相对较复杂,计算代价较高,可能增加模型的训练时间。
- 当输入较大时,Mish函数的输出可能接近线性关系,可能导致信息损失。
11.5 梯度消失和梯度爆炸问题
Mish函数的梯度通常通过反向传播算法进行计算,相比于ReLU函数,Mish函数的梯度在输入较小或较大时更稳定,可以缓解梯度消失和梯度爆炸问题。
11.6 建议的使用场景
- 当需要更好的拟合能力,以及结合ReLU、tanh和softplus函数的优点时,可以考虑使用Mish函数作为隐藏层的激活函数。
- 适用于深度神经网络的隐藏层激活函数。
- 在一些任务上表现更好,例如图像分类、语音识别等领域的深度学习任务。
12.1 定义和函数形式
GELU函数(Gaussian Error Linear Units)是一种激活函数,其数学形式为:
GELU函数由OpenAI提出,被证明在一些NLP(自然语言处理)任务上效果良好。
12.2 通过Python代码手动实现并可视化
你可以使用Python代码手动实现GELU函数,并通过绘图工具将其可视化,以便理解其形状和特点。
12.3 作用和用途
GELU函数常用于深度神经网络的激活函数,特别是在一些NLP任务中表现良好。它结合了高斯分布和非线性激活函数的优点。
12.4 优点和局限性
- 优点:
- GELU函数在一些NLP任务中表现良好,具有较好的非线性特性。
- 结合了高斯分布和非线性激活函数的优点,能够提升模型的性能。
- 局限性:
- GELU函数相对复杂,计算代价较高,可能增加模型的训练时间。
12.5 梯度消失和梯度爆炸问题
GELU函数的梯度通常通过反向传播算法进行计算,相比于ReLU函数,GELU函数的梯度在输入较小或较大时更稳定,可以缓解梯度消失和梯度爆炸问题。
12.6 示例和应用
- 在一些NLP任务中广泛应用,例如情感分析、文本分类等。
12.7 建议的使用场景
- 当需要在NLP任务中获得更好的性能时,可以考虑使用GELU函数作为隐藏层的激活函数。
- 适用于需要较好的非线性特性的深度学习任务中。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/haskellbc/16704.html