
面对文本评估任务时,人们总是习惯性地想找到一个标准答案作为参考。这源自于一个很自然的思路,和参考相似的答案大概率是一个好的答案。许多文本评估方法的实现都是基于这个直觉,例如经典的 BLEU 和 METEOR,例如近年来基于 embedding 相似性提出的 BERTScore 和 MoverScore。这类方法,可以称为 Ref-free 方法。
Ref-based 方法使用广泛,相信大家都早有耳闻并应用实际研究中。然而,近两年大模型飞速发展,让我们不禁要问:与参考文本的相似度,真的能够反映生成文本的质量吗?如果修改了评估标准呢?如果这个任务本没有标准答案呢?更重要的是,我们真的有能力为每一个新的任务都创建对应的参考文本吗?
近年来蓬勃兴起的无参考评估方法,即 Ref-free 方法,或许提供了一种可能的解决思路。这类方法通常基于某个基座语言模型,利用条件生成概率等方式对文本进行评估,并在不少任务上取得了不错的结果。然而,什么时候我们可以用 Ref-free 的方法,各类方法的优劣如何,却一直缺乏相应的研究,而这,恰恰是本文的研究中心。

论文链接:

结论先行
我们发现,参考文本在大多数评估场景中并非必要,应用基于语言模型的 Ref-free 的方法通常会有更好的效果,尤其是在和基于 n-gram 的 BLEU,METEOR 等方法比较之时。较为简单的任务场景中,例如 summarization 和 data-to-text。唯一需要注意的是,Ref-free 方法的优势也正是劣势所在,其使用受到模型本身理解能力的影响,需要在应用前进行测试。
举个例子,对于开放的对话任务,如果 ref-free 的基座模型并未接触过相关数据,其表现往往不尽人意。我们还需要指出的是,无论是哪种方案,都无法达到与人类相同的程度,其结果仅作为辅助支撑材料之一。

说完结论,回归正题。我们说参考文本不好,Ref-free 方法更好,总归要给出一个好的标准。为了方便叙述,以下我们将评估方法称为 metrics。这个标准,我们选择了业内沿用至今的黄金标准——人类评分,也就是评估任务的 ground truth。如果一个评估方法可以给出与人类相似,甚至一摸一样的打分,那么我们就认为这是一个好的评估方法。
2.1 相关性
既然是评估分数之间的相似性,最简单的指标自然是相关性。显然,metric生成的分数与人类评分相关性越高,代表效果越好。这里我们采用了Spearman Correlation作为相关性的计算方法。
具体来说,假设我们现在有 个待评估文本,Metrics 输出的分数是 ,对应的人类评估分数是 ,则相关系数的计算如下所示。
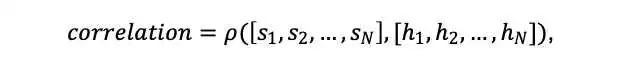
2.2 扰动识别Perturbation Detection
还有一个很直观的评价指标,好的 metric 应当敏锐地识别出句子中存在的缺陷。因此我们可以通过人为的方式破坏原本的语句。对比句子原本的评分,如果 metric 可以给被破坏的文本打出更低的分数,证明它判断出了句子质量的下降。显然这是一个二分类的问题,我们用最简单的准确度 accuracy 进行评估。
除了扰动识别,我们也可以从分布的角度去考虑 metric 对文本质量的分辨能力。在实验中,对于每个数据集,我们根据人类的评分将文本划分为高质量组与低质量组。接下来,我们收集模型对两组文本的打分,两组分数各自构成了分布 A(高质量组)和分布 B(低质量组)。显然这两组分数应当有足够的差异度,才能证明模型分得清两类文本。
我们采用 Kolmogorov-Smirnov 分数,简称 KS 分数,进行评价。KS 分数可以用于计算两个分布之间的相似性,计算公式如下。这里 F 代表累计密度函数,KS 分数为 0 代表两组数据的分布一致。KS 分数越高,代表 metric 的表现越好。

最后,我们还想知道各个 metric 的评分稳定性:它们的打分会收到文本质量的影响吗?我们借用了 xxx 提出的 Meta-Correlation。理想状态下,metric 打分质量与文本质量应当不存在相关性,即 meta-correlation 接近于 0. 若是接近于 1(或者 -1),则代表它们在遇到质量高(或者低)的文本时能够有更好的表现。


实验
a)相关性实验
我们收集了来自 dialogue,data-to-text 和 summarization 三种不同任务的数据集用于实验,包含对 coherence,consistency 和 fluency 三种指标(简写为 COH,CON 和 FLU)的评估结果。数据集中的每个样例都包含待评估文本 hyp,用于 hyp 生成的输入文本 src,参考文本 ref,和人类针对这个指标的评分结果。

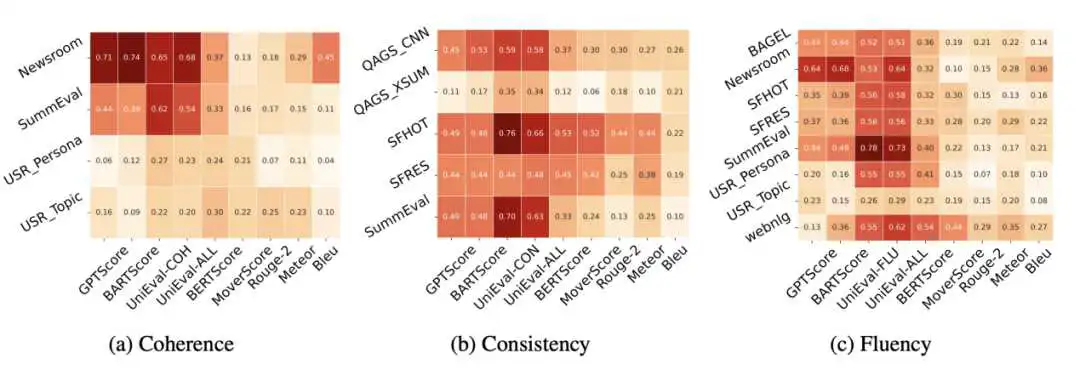
表中展现了各个 metrics 生成的分数与人类评分的相关性。结果非常有意思,我们发现 Ref-free 的表现在大部分任务上远超 Ref-based 的方法。这促使我们反思,reference 在评估中到底扮演了一个什么样的角色。
我们从 SummEval 中抽取出了部分案例,发现同一个 hyp 根据不同 ref 计算出的分数差异明显。换言之,Ref-based 的评估结果严重依赖于使用的ref。另一方面无论是什么评估 criterion,我们都采用了相同的 reference,这显然也是不合理的。
最后,直觉上,用基于 n-gram的 匹配评价 fluency 和 coherence 等并不符合逻辑,且在开放性生成任务上,较低的匹配分数无法说明文本的质量。
因此,我们非常建议采用新的 Ref-free 的方式用于评估任务。这类方法基于自然语言模型,能够利用语言模型中包含的语义信息。唯一需要注意的是,Ref-free 方法的效果严重依赖于模型本身的生成能力,因此在拓展到不同任务上时,需要进行预测试。
同时,评估 fluency 这类与 src 并不相关的指标时,为了降低 data-to-text 等任务中不常规 src 输入的影响,可以采用仅需要 hyp 作为输入的 method,例如 UniEva 对 fluency 的评估模式。
b)扰乱实验


上图展现了不同 metrics 对判断扰乱的准确性。对于 coherence,我们采用了重排段落语句的扰乱方式。对于 fluency,我们采用了 subject-verb disagreement 的扰乱方式。从结果可以看到,Ref-free 方法对于 Perturbation 有着很不错的敏感度,但 Ref-based 就不让人满意了。
对于 coherence,几个基于 n-gram 的方法几乎无法识别出 perturbation。原因也很清楚,因为我们用于 coherence 的 perturb 方法是对句子进行打乱,并不会影响 n-gram 的匹配,因此 BLUE 等 metric 将对 perturb 前后的文本给出相同的分数。
对于 fluency 评估表现上的差异,一种可能的解释是,Ref-based 的方法关注句子的表层特性,而对深层语义信息的利用却不如 Ref-free 的方法。
c)KS分数
KS 的结果同样是 Ref-free 优于 Ref-based,实际上与 Correlation 的分析结果是一致的。评分与 correlation 越相近的 metrics,对于质量不同的文本也有着更好的分辨率。
d)稳定性实验

根据 meta-correlation 的计算结果,很遗憾,我们发现,这篇文章中包含的 evaluation metrics 并不具有理想的稳定性。事实上,我们发现,对于 Ref-free Metrics 和表现较好的 Ref-based metrics BERTScore,其评估效果几乎稳定的与文本质量呈现负相关。
这说明,Ref-free metrics 对于质量较差的文本可以给出负面的评分,但是却无法对高质量文本做出正确的评估。至于 Ref-based Metrics,他们则没有一致的表现输出。考虑到原本便很低的相关性,这更像是一种随机的结果。
这也进一步说明,目前为止,evaluation metrics 都远没有到达可以替代人类的程度,人类的干预对于准确的评估必不可少。

尾声
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/goyykf/58061.html