
写在前面作者也是在看其他博主的文章进行的学习及思考,部分学习内容会借鉴其他博主的文章,借鉴部分会标注博主的链接,可直接点链接去看博主的原文章。作者最后的自问环节会放在文章最后。
一、YOLOV5网络结构
博主的原链接:【YOLO系列】YOLOv5超详细解读(源码详解+入门实践+改进)-CSDN博客
里面可以看到YOLOV5的网络结构。
输入端的Mosaic数据增强步骤:
(1)随机选取图片拼接基准点坐标(Xc,Yc),另随机选取四张图片。
(2)四张图片根据基准点,分别经过尺寸调整和比例缩放后,放置在指定尺寸的大图的左上,右上,左下,右下位置。
(3)根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
(4)依据指定的横纵坐标,对大图进行拼接。处理超过边界的检测框坐标。
采用Mosaic?数据增强的方式有几个优点:
(1)丰富数据集:随机使用4张图像,随机缩放后随机拼接,增加很多小目标,大大增加了数据多样性。
(2)增强模型鲁棒性:混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
(3)加强批归一化层(Batch Normalization)的效果:当模型设置BN操作后,训练时会尽可能增大批样本总量(BatchSize),因为BN原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么BN计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
(4)Mosaic数据增强算法有利于提升小目标检测性能:Mosaic数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标,从而提升了模型的检测能力。
输入端自适应的具体过程
①获取数据集中所有目标的宽和高。
②将每张图片中按照等比例缩放的方式到resize指定大小,这里保证宽高中的最大值符合指定小。
③将bboxs从相对坐标改成绝对坐标,这里乘以的是缩放后的宽高。
④筛选bboxes,保留宽高都大于等于两个像素的bboxes.
⑤使用k-means聚类三方得到n个anchors,与YOLOv3、YOLOv4操作一样。
⑥使用遗传算法随机对anchors的宽高进行变异。倘若变异后的效果好,就将变异后的结果赋值给anchors;如果变异后效果变差就跳过,默认变异1000次。这里是使用anchor_fitness方法计算得到的适应度fitness,然后再进行评估。
自问:
- 看到了mosaci数据增强的优点,哪它的缺点是什么?
如果数据集本来就是选择很多小目标的检测,那么mosaci数据增强就会导致较小的目标变得更小,导致模型的泛化能力变差。
二 、Backbone(骨干)
Focus结构
Focus模块在YOLOv5中是图片进入Backbon前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长得差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
缺点:Focus对某些设备不支持且不友好,开销很大,另外切片对不齐的话模型就崩了。
后期还改进了:
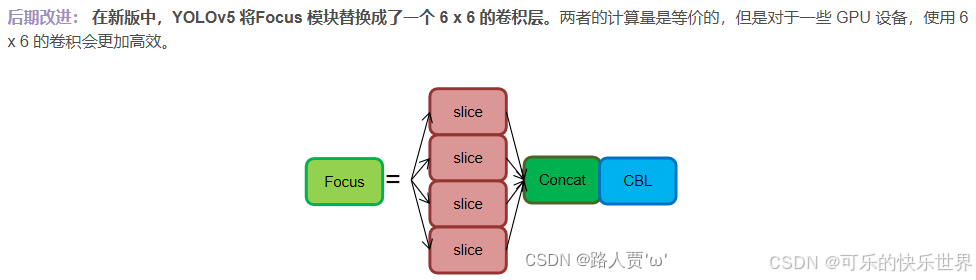
CSP结构
YOLOv5与YOLOV4不同点在于,YOLOV4中只有主干网络使用了CSP结构。而YOLOv5中设计了两种CSP结构,以YOLOv5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
自问:
看博主得文章知道了,Backbone得改进模块,除了改进模块,其他还有什么模块,又是什么结构?
我去看了YOLOV5的代码发现,backbone中是c3,conv、sppf模块,为啥博主文章却和代码里的有些不同。重新查阅了相关信息,发现了一个博主写的backbone写的很细,推荐:
YOLOv5的Backbone详解_yolov5 backbone-CSDN博客
三、Neck(颈部)
借鉴PANet的FPN+PAN结构(自顶向下+自底向上)——特征金字塔
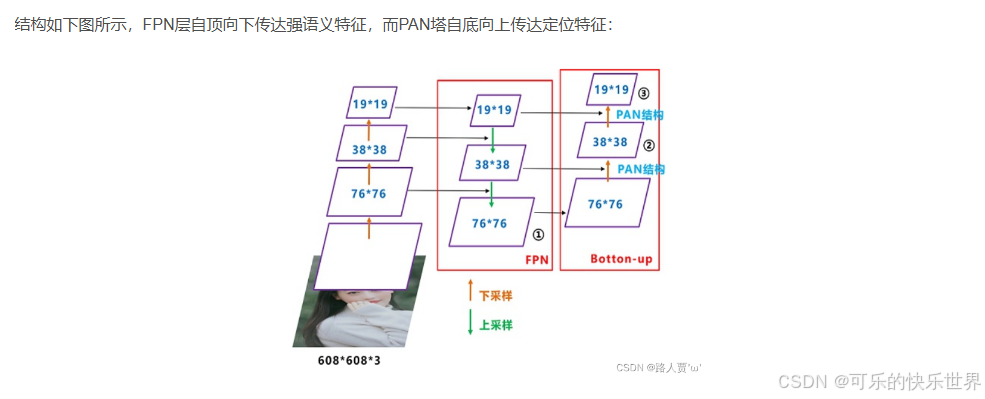
自问
看代码发现实际并没有专门写出neck部分,是将neck和和head俩个部分合在了一起。也是为了方便在models/yolo.py中的加载。
查阅相关信息,又找到了neck部分写的特别好的文章。哈哈,就是推荐:
YOLOv5的Neck端设计-CSDN博客
四、Head(头部)
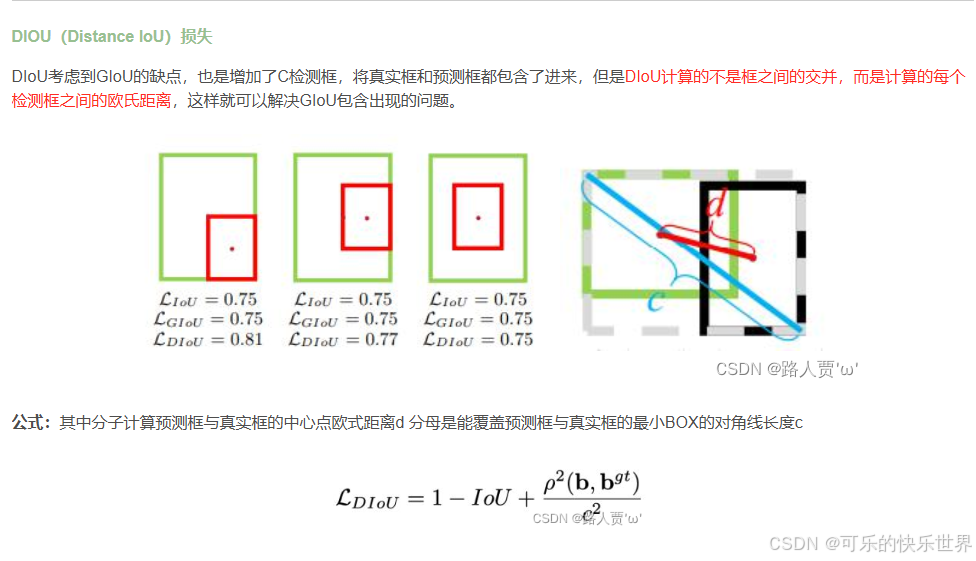
Bounding box 损失函数(包括IOU_Loss、GIOU_Loss、DIOU_Loss、CIOU_Loss)
链接:【YOLO系列】YOLOv4论文超详细解读2(网络详解)-CSDN博客
截图我自己看:
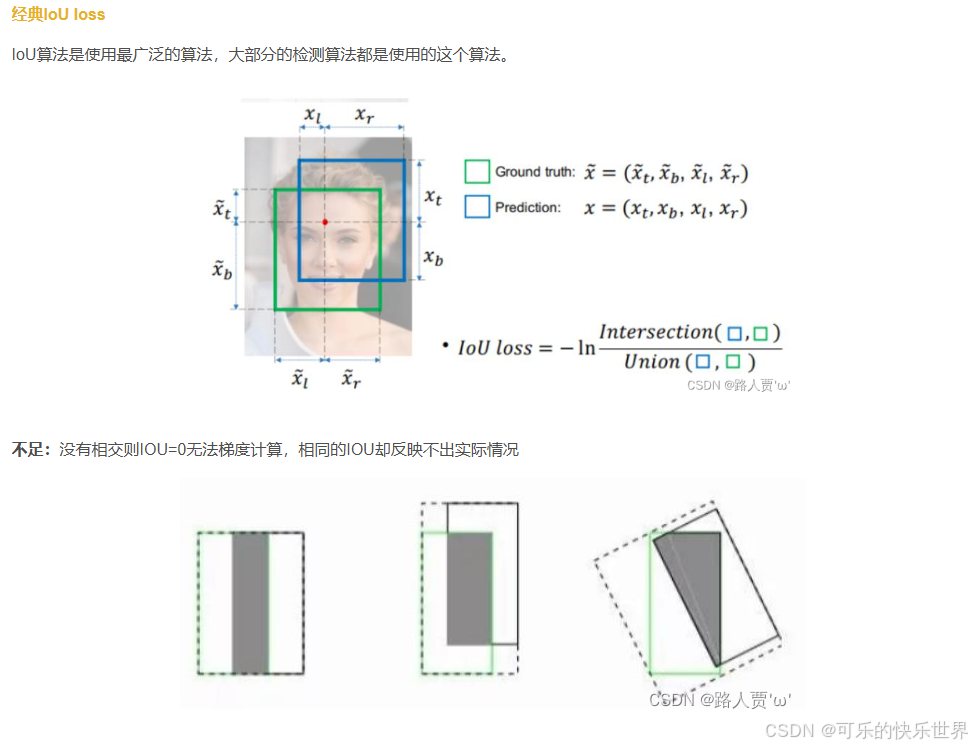
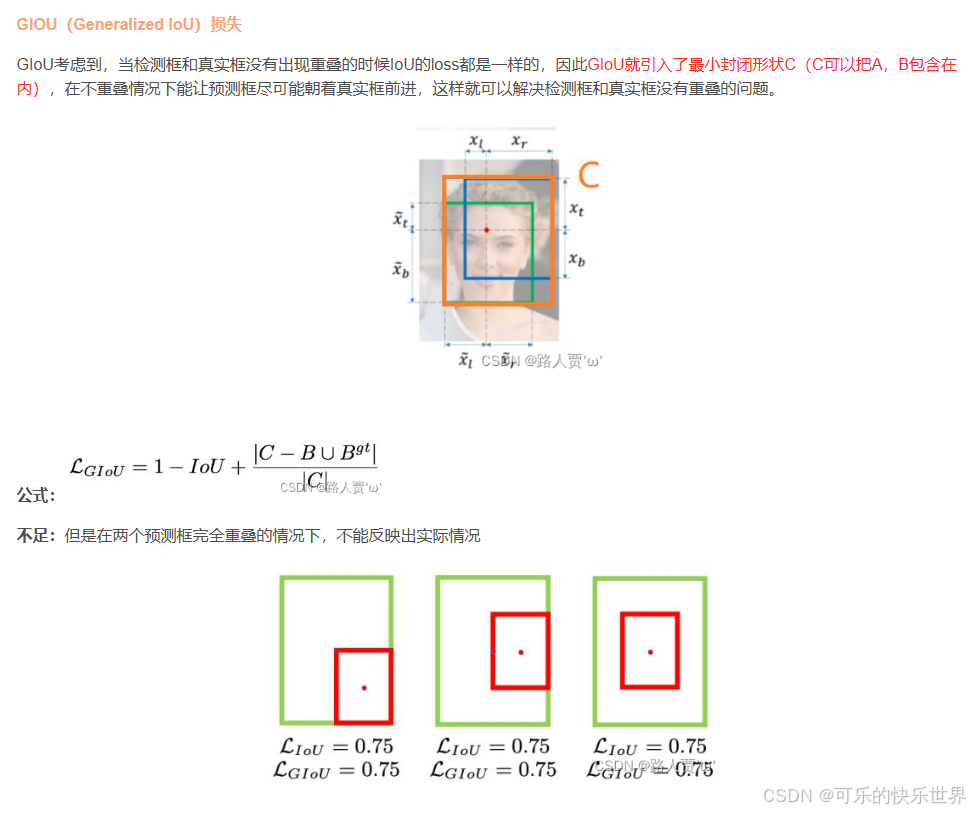

NMS非极大值抑制
NMS的本质是搜索局部极大值,抑制非极大值元素。
非极大值抑制,主要就是用来抑制检测时冗余的框。因为在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
算法流程:
1.对所有预测框的置信度降序排序
2.选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的IOU
3.根据步骤2中计算的IOU去除重叠度高的,IOU>threshold阈值就直接删除
4.剩下的预测框返回第1步,直到没有剩下的为止
SoftNMS:
当两个目标靠的非常近时,置信度低的会被置信度高的框所抑制,那么当两个目标靠的十分近的时候就只会识别出一个BBox。为了解决这个问题,可以使用softNMS.
它的基本思想是用稍低一点的分数来代替原有的分数,而不是像NMS一样直接置零。
自问:
关于代码的解读是否可以找到?
关于代码的解释博主原链接:YOLOv5的head详解_yolov5 head-CSDN博客
该博主将代码的各部分的作用都解释出来了。
五、总结
YOLOV5网络采用的mosaci数据增强,和yolov4一样,提升小物体的检测性能。
backbone的Focus和CSP结构,有效提高了模型的特征提取能力。
Neck部分采用的是FPN和PAN结合的特征金字塔结构,能够在保持高效性的同时提升模型的性能。
Head部分采用的是YOLOv5头结构,且给出了几个可以表述损失的函数结果,可以输出网络的预测结果。同时有了一个NMS非极大值抑制,极大阻碍了YOLO端到端部署,该问题一直在YOLOV10才提出了解决的办法。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/do-yfwjc/41865.html