
Ceph是什么?为什么用到Ceph?
- 集中式存储
- NAS (网络附加存储 / 网络区域存储)
- SAN (存储区域网络)
- DAS (直连附加存储)
集中式存储的优点:
- 管理简单,因为所有数据都存放在同一个节点上,所以数据的管理与维护相对简单
- 安全性高,集中式存储中只有一个数据中心,因此更容易实现安全控制
- 数据统一管理
常见的的集中式存储有:
- 分布式存储
分布式存储是一种数据存储技术。在分布式存储架构中,信息被存储于多个独立且互不干扰的设备中。不同于传统的集中式存储,分布式存储采用可扩展的存储结构,这在一定程度上提高了存储系统的可靠性,可用性和访问效率。
现在常用的存储服务有NFS,那么为什么不采用NFS呢?
我们不妨这样设想一下,NFS如果节点挂掉了,那么我们把这个节点上的硬盘拔出来,换到其他节点上,在其他节点上起一个NFS,那么数据依旧是存在的,但是,如果坏的不是节点而是硬盘呢?可能你想到了给硬盘做RAID,好,保留这个问题,继续往后看。
Moosefs就是一个分布式存储,他的技术架构就是提供一个Mater节点,来管理整个集群,client只需要通过挂载Master节点就可以往集群内存储文件
大家都知道,一个文件是由文件元数据以及文件数据组成的,文件元数据保存的就是一些简单的概要,比如这个文件多大,文件的拥有人,所属组以及访问权限这些东西,元数据一般都不大,所以会直接保存在Master节点上,而文件本身的数据则会保存在存储节点上,并且是有多副本机制的。完全不怕某个节点挂掉而导致数据丢失。
MooseFS瓶颈
虽然文件的元数据占用的空间并不大,但是在现在这个时代,也奈何不了他多啊,当元数据过多时,Master就成了Moosefs的瓶颈,因为所有的请求都是需要经过Master的,并且Moosefs(到写这篇文章的时间)是没办法做Master高可用的,想给他做高可用的方式就是2个Master,使用Keepalive提供一个VIP(虚拟IP),访问这个VIP就可以访问到2个Master节点,但是,在同一时间内,只有一个Master在工作,所以瓶颈依旧存在
看到了MooseFS的瓶颈之后,GlusterFS采取了去Master,即不需要Master节点,每个存储节点上都内嵌一个可以代替Master工作的组件,这样操作下来,所有的元数据并不是都放在同一个节点上,每个节点都只需要保存部分元数据,好像这个架构没什么问题了哈,但是我们回想一下MooseFS是如何使用的?是不是客户端挂载Master就可以使用集群了?但是现在没有Master了,或者说每个节点都是Master,那怎么办呢?
GlusterFS就要求使用GlusterFS的客户端安装一个软件,Gluster-client,并且给这个软件写一个配置文件,把所有的存储节点IP地址写进去,这样操作。但是如果后期节点需要更换,改动起来就比较麻烦。我们再来看看Ceph是怎么做的
Ceph的做法就跟前两者不同了,Moose FS不是说Master上的元数据会成为瓶颈吗?GlusterFS不是说客户端操作不易吗?那我来折中一下呢?Ceph他保留了Master节点,但是,这个Master保存的不是文件的元数据,是集群的元数据,也就是保存的集群的信息,那么既然Master保存的是集群元数据,那么文件元数据保存到哪了呢?他有专门的文件元数据节点,所有的文件元数据都保存在这个节点上,记住,这个节点只保存元数据,其他一概不管。这样说来,既解决了客户端配置维护困难,也解决了Master节点的瓶颈。
这就是Ceph的架构,他兼顾了 易维护、性能,这就是他流行的原因
现在再回头去想NFS的问题,为什么不做RAID呢?因为做RAID成本就比用Ceph的成本高了
Ceph的版本命名跟OpenStack一样,采取英文字母命令A-Z,目前最新版是R版
- mon:集群监视器(就是master)
- osd:集群存储节点
- mgr:集群管理器
以上三个节点必装,缺一不可 - mds:文件元数据节点
- rgw:对象存储网关
- nfs-genasha:为ceph对外提供NFS协议的文件存储服务
- rbd-mirror:块设备镜像服务
ceph的部署方式有:
- Cephadm(官方推荐)
- ceph-ansible
- ceph-deploy(N版本之前使用)
- DeepSea
- 手工部署(极其复杂,不推荐)
每个节点都要做
安装git是因为需要拉取cephadm,因为欧拉操作系统暂时用不了官方的cephadm,需要下载另一个版本
不要使用cephadm add-repo 因为在欧拉上是不支持的
--mon-ip指定monitor,指定一个就行,后期可以添加
--initial-dashboard-user admin 指定dashboard的用户名是admin,不指定也行
--initial-dashboard-password 123 指定dashboard的用户名是123,不指定也行
--dashboard-password-noupdate 第一次登录dashboard无需修改密码
安装完之后会有一个回显
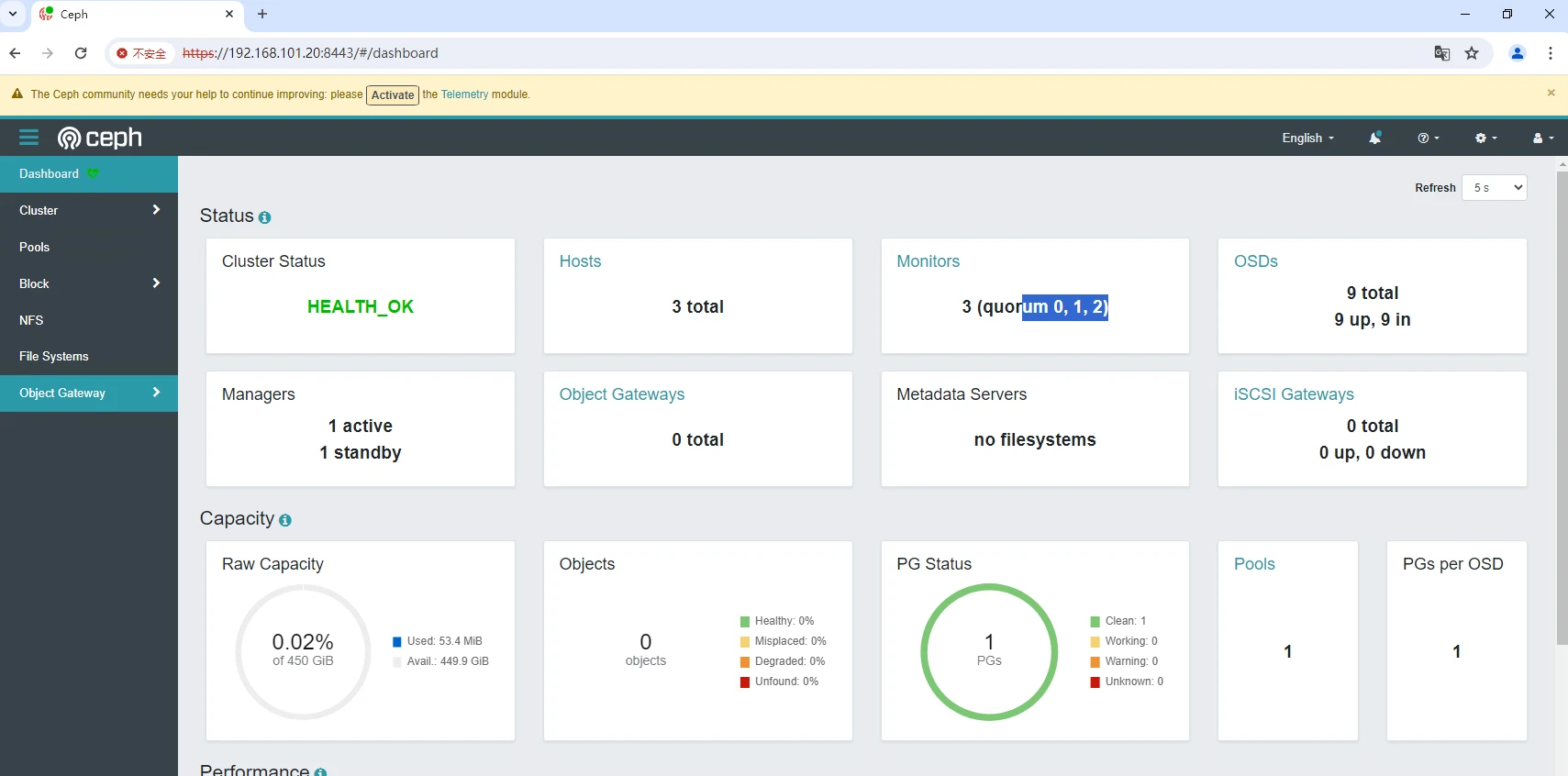
装完之后我们可以使用ceph -s 来查看集群状态
3.2.1 群健康的3种状态
3.2.2 services
这里可以看到有一个mon,没有osd,没有osd是up
osd的状态:
- up且in: 代表osd运行正常且至少承载了一个PG
- up且out:代表osd运行正常,但是没有承载PG,新加入集群的osd为这个状态
- down且in:表示osd运行异常,但承载了一个PG
- down且out:表示osd运行异常,且没有承载PG
3.2.3 健康详细情况
这里会详细的说明为什么不健康
有一个命令 ceph orch 他是用来管理节点以及 orch 信息的c
通过ps可以看到ceph具体的进程,运行在哪个机器上,内存占用是多少,允许最大占用内存是多少,这里的image id就是容器使用的镜像ID,cephadm部署出来的集群就是基于容器的
需要将/etc/ceph/ceph.pub这个公钥传到被添加的节点上
4.1.1 发放公钥
4.1.2 被添加节点安装容器引擎
4.1.3 添加节点
Lables 就是标签,当某个节点拥有_admin标签时,集群就会把连接客户端连接ceph集群的认证文件发放到该节点上
4.1.4 标签修改
添加标签
目前是只有ceph01拥有admin标签,在/etc/ceph 下有一些其他节点没有的文件
这个时候,ceph03就可以使用ceph客户端来操作ceph集群了
删除标签
4.2 关闭mon自动扩展
4.3 将mon服务固定在某几个节点
如果有一个mon节点挂掉了,而此时又添加了一台新的节点,那么按照ceph集群的控制,可能会在新的节点上启动一个mon,但我们并不想他更换mon节点,此时可以这么做
这样操作之后,mon就只会在有mon标签的节点上去启动
首先需要ceph节点上有空闲的盘,然后将空闲的盘添加进来,必须是一块裸盘,在一千的版本是允许是一个目录的
在添加节点之后ceph会将这块盘做成一个lvm,可以使用lvs去查看
添加完之后我们使用命令来查看
这里显示有9个osd,并且状态是up且in,说明没问题
到这里ceph的部署就结束了
到此这篇ceph存储搭建(cephfs搭建)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/80547.html