
Ceph 是一个能提供文件存储(cephfs)、块存储(rbd)和对象存储(rgw)的分布式存储系统,具有高扩展性、高性能、高可靠性等优点。Ceph 在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。
中文文档
- 高性能
- 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
- 考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架等。
- 能够支持上千个存储节点的规模,支持TB到PB级的数据。
- 高可用性
- 副本数可以灵活控制。
- 支持故障域分割,数据强一致性。
- 多重故障场景自动进行修复自愈。
- 没有单点故障,自动管理。
- 高可扩展性
- 去中心化。
- 扩展灵活。
- 随着节点增加而线性增长。
- 特性丰富
- 支持三种存储接口:块存储、文件存储、对象存储。
- 支持自定义接口,支持多种语言驱动。
Ceph支持三种接口:
- Object:有原生的API,而且也兼容Swift和S3的API,适合单客户端使用
- Block:支持精简配置、快照、克隆,适合多客户端有目录结构
- File:Posix接口,支持快照
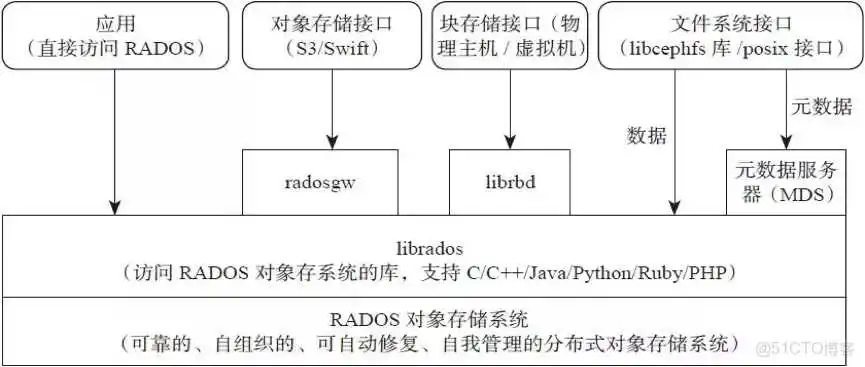
???? RADOS
全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
???? Librados
Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
???? Crush
Crush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模云环境中的应用提供了先天的便利。
???? Pool
Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,支持两种类型:副本(replicated)和 纠删码( Erasure Code)。
???? PG
PG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略,简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
???? Object
简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利 于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。
???? OSD
OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等。
Pool、PG和OSD的关系:
- 一个Pool里有很多PG;
- 一个PG里包含一堆对象,一个对象只能属于一个PG;
- PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型);
???? Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。负责坚实整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证与授权。
???? MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务。
???? Mgr
ceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。例如cephmetrics、zabbix、calamari、promethus。
???? RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
???? Admin
Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。

- 优点:
- 通过Raid与LVM等手段,对数据提供了保护;
- 多块廉价的硬盘组合起来,提高容量;
- 多块磁盘组合出来的逻辑盘,提升读写效率;
- 缺点:
- 采用SAN架构组网时,光纤交换机,造价成本高;
- 主机之间无法共享数据;
- 使用场景
- docker容器、虚拟机磁盘存储分配;
- 日志存储;
- 文件存储;
- 优点:
- 造价低,随便一台机器就可以了;
- 方便文件共享;
- 缺点:
- 读写速率低;
- 传输速率慢;
- 使用场景
- 日志存储;
- FTP、NFS;
- 其它有目录结构的文件存储
- 优点:
- 具备块存储的读写高速;
- 具备文件存储的共享等特性;
- 使用场景
- 图片存储;
- 视频存储;
要实现数据存取需要创建一个pool,创建pool要先分配PG。
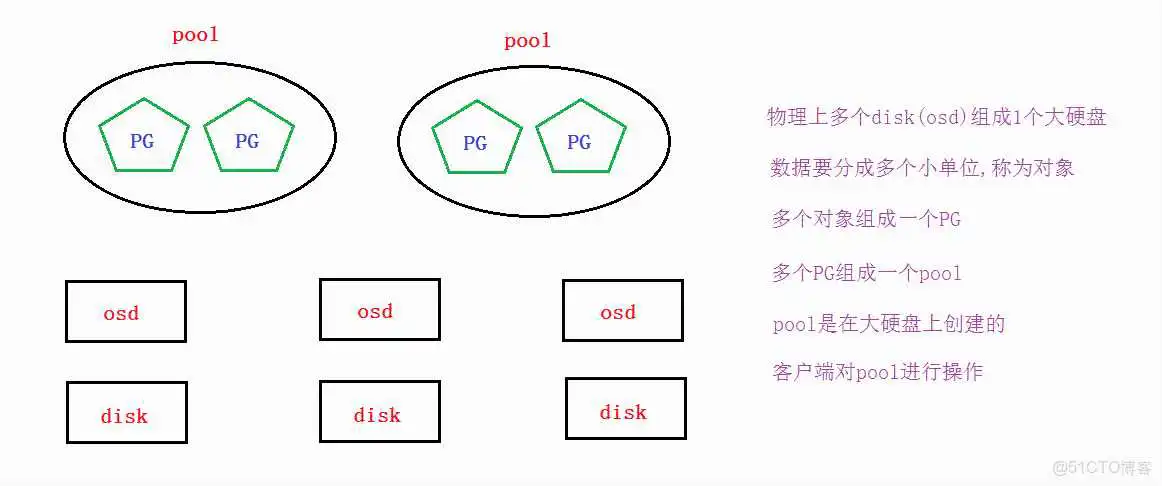
如果客户端对一个pool写了一个文件,那么这个文件是如何分布到多个节点的磁盘上呢?
答案是通过CRUSH算法。
Ceph 社区最新版本是 14,而 Ceph 12 是市面用的最广的稳定版本。
第一个 Ceph 版本是 0.1 ,要回溯到 2008 年 1 月。多年来,版本号方案一直没变,直到 2015 年 4 月 0.94.1 ( Hammer 的第一个修正版)发布后,为了避免 0.99 (以及 0.100 或 1.00 ?),制定了新策略。
x.0.z - 开发版(给早期测试者和勇士们)
x.1.z - 候选版(用于测试集群、高手们)
x.2.z - 稳定、修正版(给用户们)
x 将从 9 算起,它代表 Infernalis ( I 是第九个字母),这样第九个发布周期的第一个开发版就是 9.0.0 ;后续的开发版依次是 9.0.1 、 9.0.2 等等。
硬件要求:
- 最少三台Centos7系统虚拟机用于部署Ceph集群。硬件配置:2C4G,另外每台机器最少挂载三块硬盘(这里实验只是给了5G)
???? 环境准备
1、关闭防火墙(all)
2、关闭selinux(all)
3、关闭NetworkManager(all)
4、主机名设定和host绑定(all)
5、时间同步(all)
6、配置ssh免密码登陆(ceph_node1节点)
7、read_ahead,通过数据预读并且记载到随机访问内存方式提高磁盘读操作(all)
所有节点都需添加
1、添加epel源
2、添加ceph源(这里使用aliyun源)
只需要在ceph_node1上安装,因为它是部署节点,别的节点不用安装。
在节点上创建集群,创建一个集群配置目录
✏️ 注意:后面大部分操作都必须要cd到此目录内操作
创建一个ceph集群
在所有ceph集群节点(、、)上安装ceph和ceph-radosgw软件包
1、增减监控网络,网段为节点网段地址
2、监控节点初始化
3、将配置文件信息同步到所有ceph集群节点,方便执行一些管理命令
4、查看集群状态
该组件的主要作用是分担和扩展monitor的部分功能,减轻monitor的负担,让更好的管理ceph存储系统。
图形管理也需要用到
1、创建一个mgr
2、添加多个mgr可以实现HA
至此,ceph集群基本搭建完成,但还需要添加osd磁盘。
接着上面的集群,添加磁盘;将磁盘添加到ceph集群需要osd,osd功能是存储与数据处理,并通过检查他OSD守护进程的心跳来向Ceph Monitors 提供一些监控信息。
1、列出所有节点的磁盘,并使用zap命令清除磁盘信息准备创建osd
2、创建osd磁盘
3、验证,可以看到下面的结果中有三个osd,data中一共有60G可用(3个20G合成了一个大磁盘)
这里为了示例,故又在ceph_node3节点上添加了一块磁盘/dev/vdc
???? 补充:如果是再加一个集群节点ceph_node4并添加一个磁盘/dev/vdb,那么需要按照如下操作进行
1、准备好ceph_node4基本环节后,安装ceph相关软件
2、在ceph_node1 上同步配置到ceph_node4
3、将ceph_node4的磁盘加入集群
ceph和很多存储一样,增加磁盘(扩容)都比较方便,但要删除磁盘(裁减)会比较麻烦,不过一般也不会进行裁剪。
这里以删除ceph_node3节点上的osd.3磁盘为例
1、查看osd磁盘状态
2、先标记为out,标记后再次查看状态,可以发现权重置为0了,但状态还是up
3、再rm删除,但要先去osd.3对应的节点上停止ceph-osd服务,否则rm不了
4、查看集群状态,可以发现有一条警告,没有在crush算法中删除,osd也恢复了三个,磁盘大小也从80G变为了60G,说明删除成功。
5、在crush算法中和auth验证中删除
6、在osd.3对应的节点上卸载
7、在osd.3对应的节点上删除osd磁盘产生的逻辑卷
至此,就完全删除了。如果需要再加回来,按照上面的扩容osd操作即可。
官方文档
RBD即RADOS Block Device的简称,RBD块存储是最稳定且最常用的存储类型。RBD块设备类似磁盘可以被挂载。 RBD块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在Ceph集群的多个OSD中。如下是对Ceph RBD的理解。
- RBD 就是 Ceph 里的块设备,一个 4T 的块设备的功能和一个 4T 的 SATA 类似,挂载的 RBD 就可以当磁盘用;
- resizable:这个块可大可小;
- data striped:这个块在Ceph里面是被切割成若干小块来保存,不然 1PB 的块怎么存的下;
- thin-provisioned:精简置备,1TB 的集群是能创建无数 1PB 的块的。其实就是块的大小和在 Ceph 中实际占用大小是没有关系的,刚创建出来的块是不占空间,今后用多大空间,才会在 Ceph 中占用多大空间。举例:你有一个 32G 的 U盘,存了一个2G的电影,那么 RBD 大小就类似于 32G,而 2G 就相当于在 Ceph 中占用的空间 ;
块存储本质就是将裸磁盘或类似裸磁盘(lvm)设备映射给主机使用,主机可以对其进行格式化并存储和读取数据,块设备读取速度快但是不支持共享。
ceph可以通过内核模块和librbd库提供块设备支持。客户端可以通过内核模块挂在rbd使用,客户端使用rbd块设备就像使用普通硬盘一样,可以对其就行格式化然后使用;客户应用也可以通过librbd使用ceph块,典型的是云平台的块存储服务(如下图),云平台可以使用rbd作为云的存储后端提供镜像存储、volume块或者客户的系统引导盘等。
使用场景:
- 云平台(OpenStack做为云的存储后端提供镜像存储)
- K8s容器
- map成块设备直接使用
- ISCIS,安装Ceph客户端
1、建立存储池,并初始化
2、创建一个块设备
3、将创建的卷映射成块设备
4、查看映射
5、格式化,挂载
???? 删除块存储方法
官网文档
Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问. Jewel 版本 (10.2.0) 是第一个包含稳定 CephFS 的 Ceph 版本. CephFS 需要至少一个元数据服务器 (Metadata Server - MDS) daemon (ceph-mds) 运行, MDS daemon 管理着与存储在 CephFS 上的文件相关的元数据, 并且协调着对 Ceph 存储系统的访问。
对象存储的成本比起普通的文件存储还是较高,需要购买专门的对象存储软件以及大容量硬盘。如果对数据量要求不是海量,只是为了做文件共享的时候,直接用文件存储的形式好了,性价比高。
底层是核心集群所依赖的, 包括:
- OSDs (ceph-osd): CephFS 的数据和元数据就存储在 OSDs 上
- MDS (ceph-mds): Metadata Servers, 管理着 CephFS 的元数据
- Mons (ceph-mon): Monitors 管理着集群 Map 的主副本
Ceph 存储集群的协议层是 Ceph 原生的 librados 库, 与核心集群交互.
CephFS 库层包括 CephFS 库 libcephfs, 工作在 librados 的顶层, 代表着 Ceph 文件系统.最上层是能够访问 Ceph 文件系统的两类客户端.
1、创建mds(也可以做多个mds实现HA),这里做三个mds
2、一个Ceph文件系统需要至少两个RADOS存储池(cephfs-data和cephfs-metadata),一个用于数据,一个用于源数据。进行创建者两个
注:一般 metadata pool 可以从相对较少的 PGs 启动, 之后可以根据需要增加 PGs. 因为 metadata pool 存储着 CephFS 文件的元数据, 为了保证安全, 最好有较多的副本数. 为了能有较低的延迟, 可以考虑将 metadata 存储在 SSDs 上.
3、创建一个CephFs
4、在Monitor 上,创建一个用户,用于访问CephFs,cephx配置参考
5、验证key是否生效
6、检查CephFs和mds状态
✏️ 以 kernel client 形式挂载 CephFs
中文官档
这里在另外一台新的客户端进行挂载示例
1、创建一个挂载目录
2、挂载目录
3、自动挂载
4、验证是否挂载成功
✏️ 以 FUSE client 形式挂载 CephFs
中文官档
1、安装ceph-common和ceph-fuse
2、将集群的ceph.conf拷贝到客户端
3、在ceph_node1节点上生成客户端密钥,并拷贝到客户端/etc/ceph目录
3、使用ceph-fuse挂载 CephFs
4、自动挂载
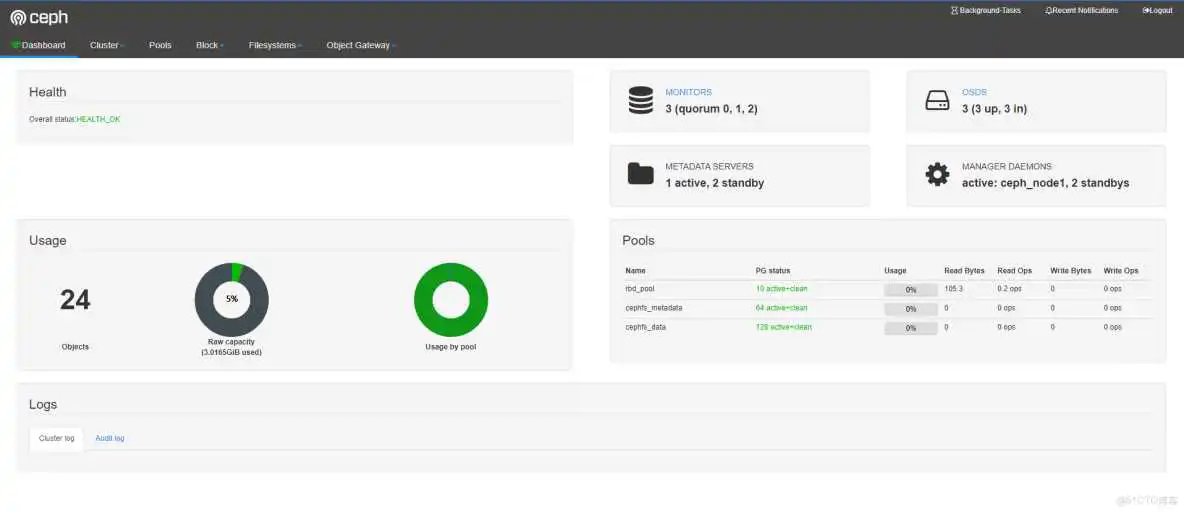
Ceph 的监控可视化界面方案很多----grafana、Kraken。但是从Luminous开始,Ceph 提供了原生的Dashboard功能,通过Dashboard可以获取Ceph集群的各种基本状态信息。
mimic版 (nautilus版) dashboard 安装。如果是 (nautilus版) 需要安装 ceph-mgr-dashboard
1、查看ceph状态,找到active的mgr
2、生成并安装自签名的证书
3、生产key pair,并配置给ceph mgr
4、重启下mgr dashboard
5、在ceph active mgr上配置server addr和port
若使用默认的8443端口,则可跳过该步骤
6、生成登陆认证的用户名和密码
7、web页面访问
人生是条无名的河,是浅是深都要过; 人生是杯无色的茶,是苦是甜都要喝; 人生是首无畏的歌,是高是低都要唱。
到此这篇ceph存储池是用来存储文件的(ceph存储的优点)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/70563.html