
解释什么是Conv1d,Conv2d,Conv3d归结为解释什么是1d,2d,3d。
这个是指除去chanel,除去batch_size,你的输入是多少维的。
比如说:
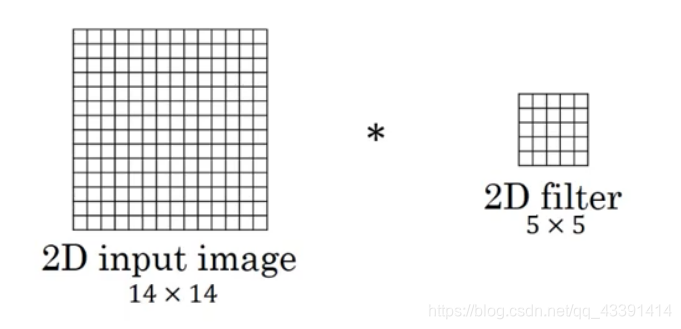
Conv2d
计算机视觉中,手写数字识别,训练的时候数据形状为:(batch_size,1,28,28),除去batch_size,除去chanel,其实(28,28),也就是两维的,所以使用,此时卷积核(没有batch_size,参数是共享的)除去chanel,也是二维的。
Conv1d
自然语言处理中一个句子序列,一维的,所以使用,此时卷积核(没有batch_size,参数是共享的)除去chanel,也是一维的。

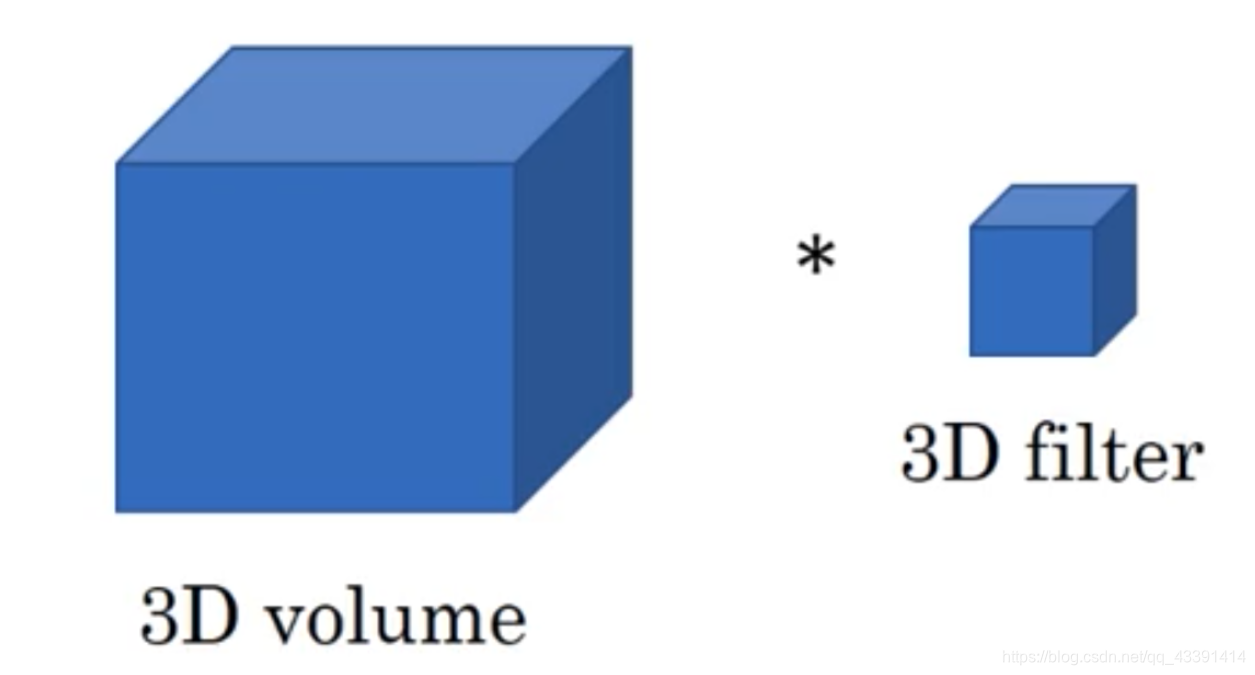
Conv3d
这个或许比较难以理解,因为有人会觉得,这个3d是不是没有去掉chanel,去掉不就是2d了吗?本身chanel这个东西你怎么定义都是随便的,这个3d的东西是不是应该有chanel,是根据我们具体问题具体分析的。我们要从感受野,CNN的思想出发,如果你觉得有一个3d的东西是一个整体,不可分割(注意,如果有channel,那么channel之间的操作是独立的,互不影响!),必须一小块体积一小块体积来使用局部卷积,那么这个东西就没有channel,就应当使用。
实战
conv1d
我们的数据a的shape为[1,2,3],即batch_size=1,“chanel”=2,这个chanel其实可能是自然语言处理中的句子长度seq_len(懂得都懂!)

定义卷积层。

上述是4个卷积核。第一个卷积核是[2,2],其有一个专属于这个卷积核的偏置,其将会和我们的数据[2,2],[2,0],[2,2]分别做内积,然后分别加上这个相同的偏置bias,得到含有3个数的向量,其作为第一个通道,然后第二个卷积也是这样做,,从而得到4个通道,每个通道都是3个数的向量。

版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/65049.html