
在深度学习中,"transform"通常指的是数据预处理或数据增强的过程,其目的是改善模型性能,特别是通过增加训练数据的多样性来提升模型的泛化能力。
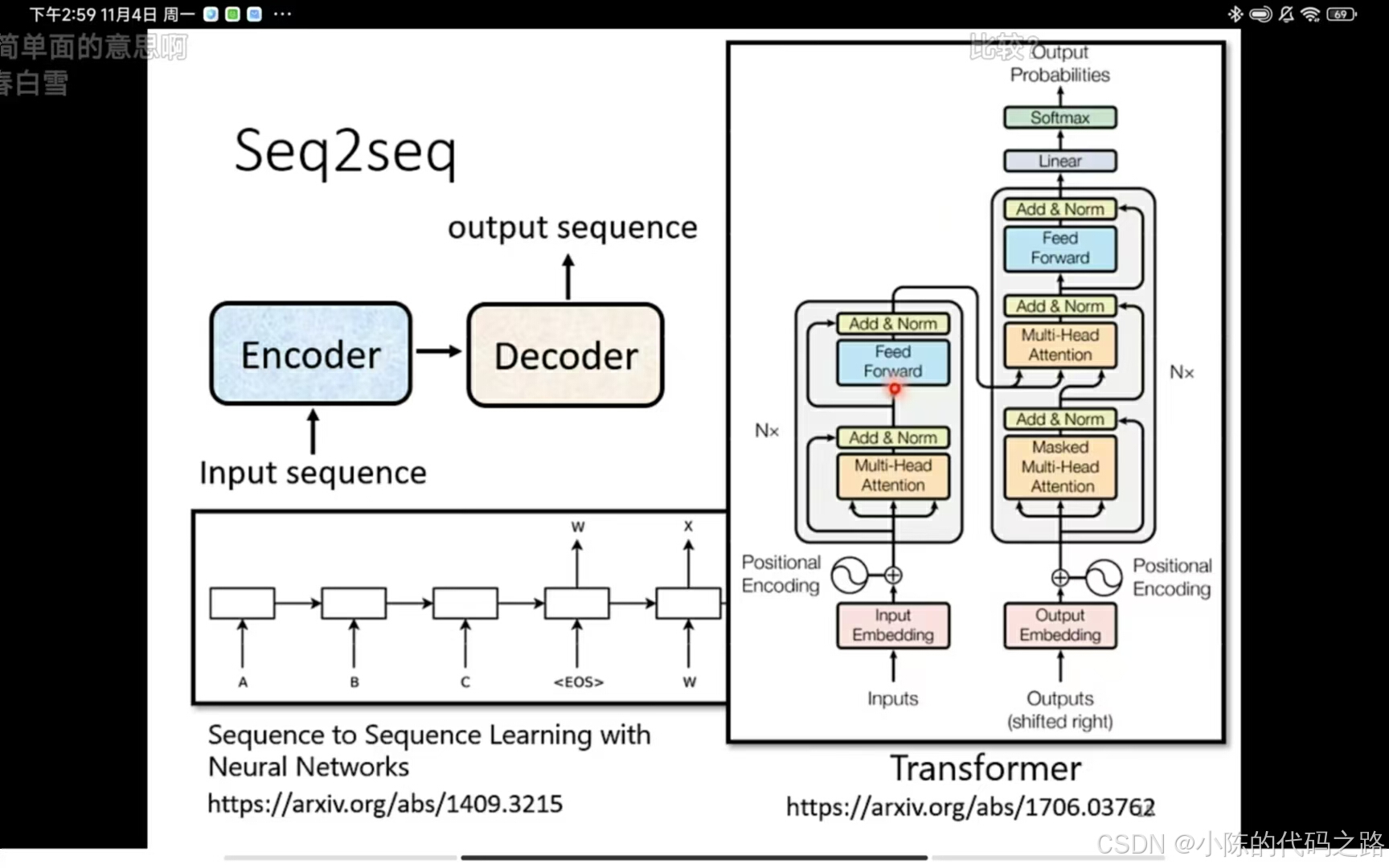
是sequence-to-sequence(seq2seq)的modle,包括一个编码器和解码器。
给一排向量输出一排向量。
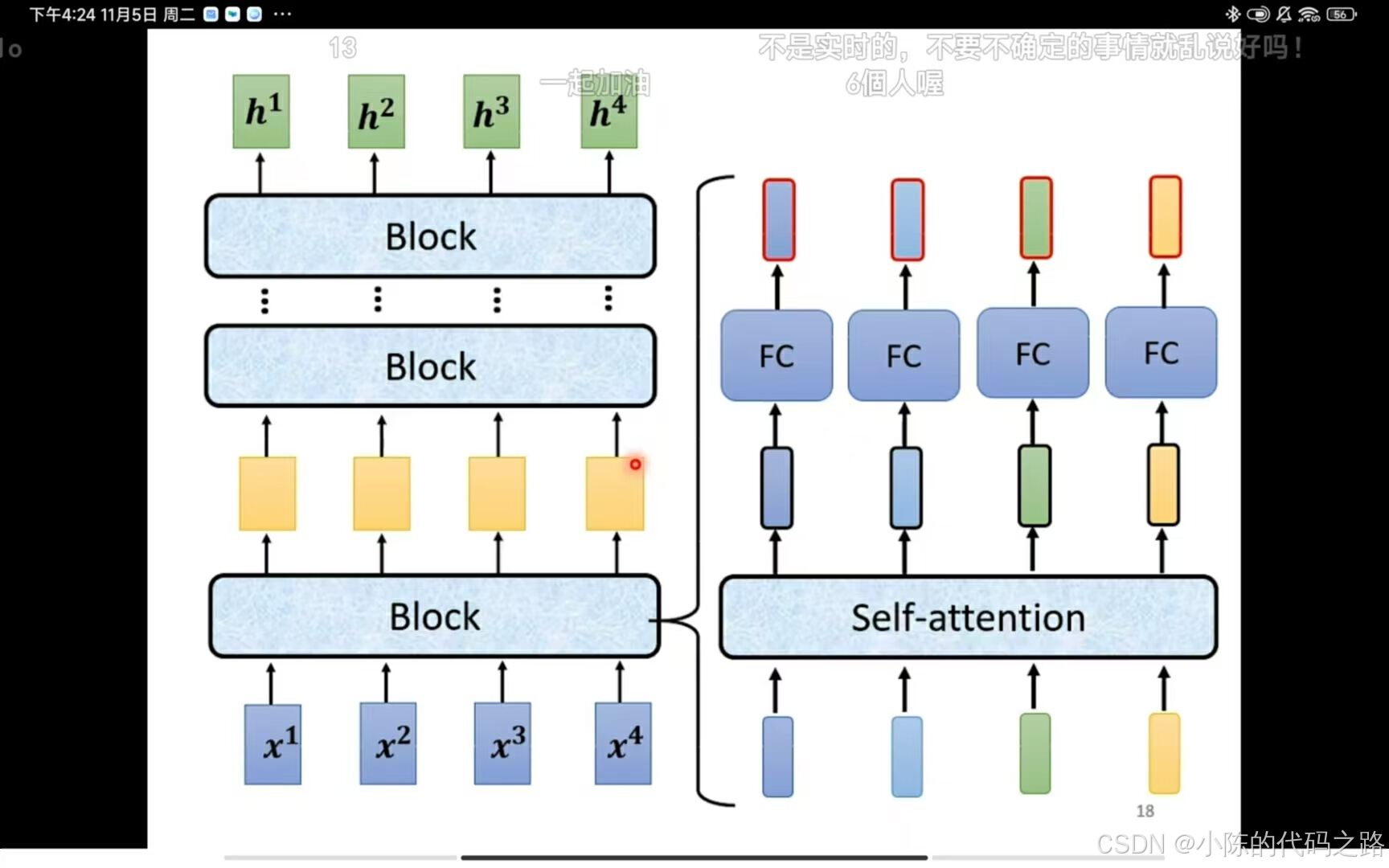
每一排block都是如此。最后一个则输出结果。Block包括先经过一层self-attention再经过一层fully connection输出结果。
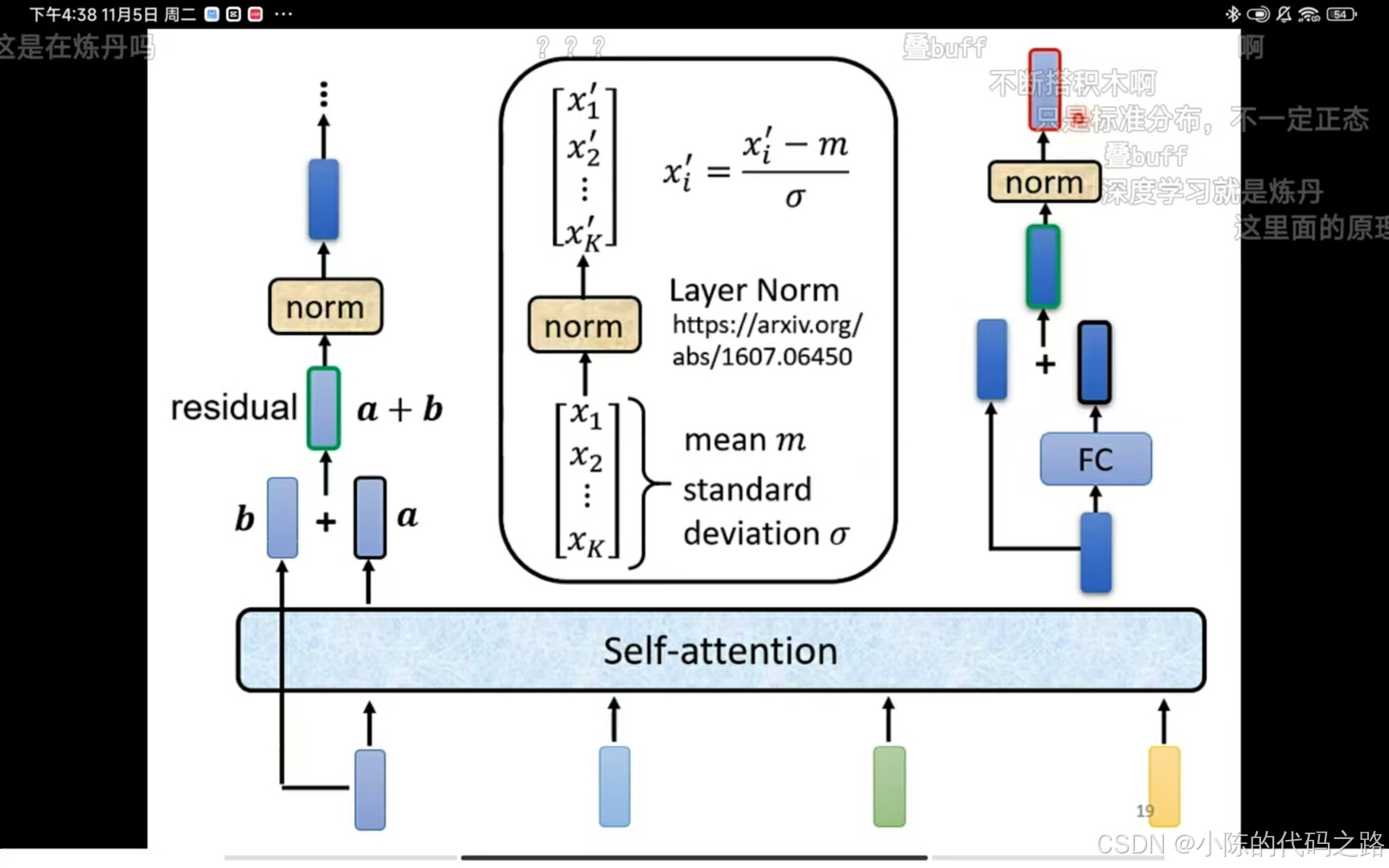
这里的self-attention和以往不同,他的结果是原输出b加上input(a)得到现输出(a+b)。
Layer Normalization(层归一化)是一种在深度学习领域中使用的技术,用于加速神经网络的训练过程,并有助于稳定学习。与批量归一化不同,层归一化不依赖于小批量中的样本,因此它特别适用于批量大小较小或者变化的情况,例如在语言模型和递归神经网络中。层归一化的这种特性使得它在处理序列数据时非常有效,因为它可以为序列中的每个元素独立地执行归一化,而不需要依赖于其他样本。
对于里面的fully connection同理,与input相加之后再经过一个norm得到最终的输出,至此一个block结束。
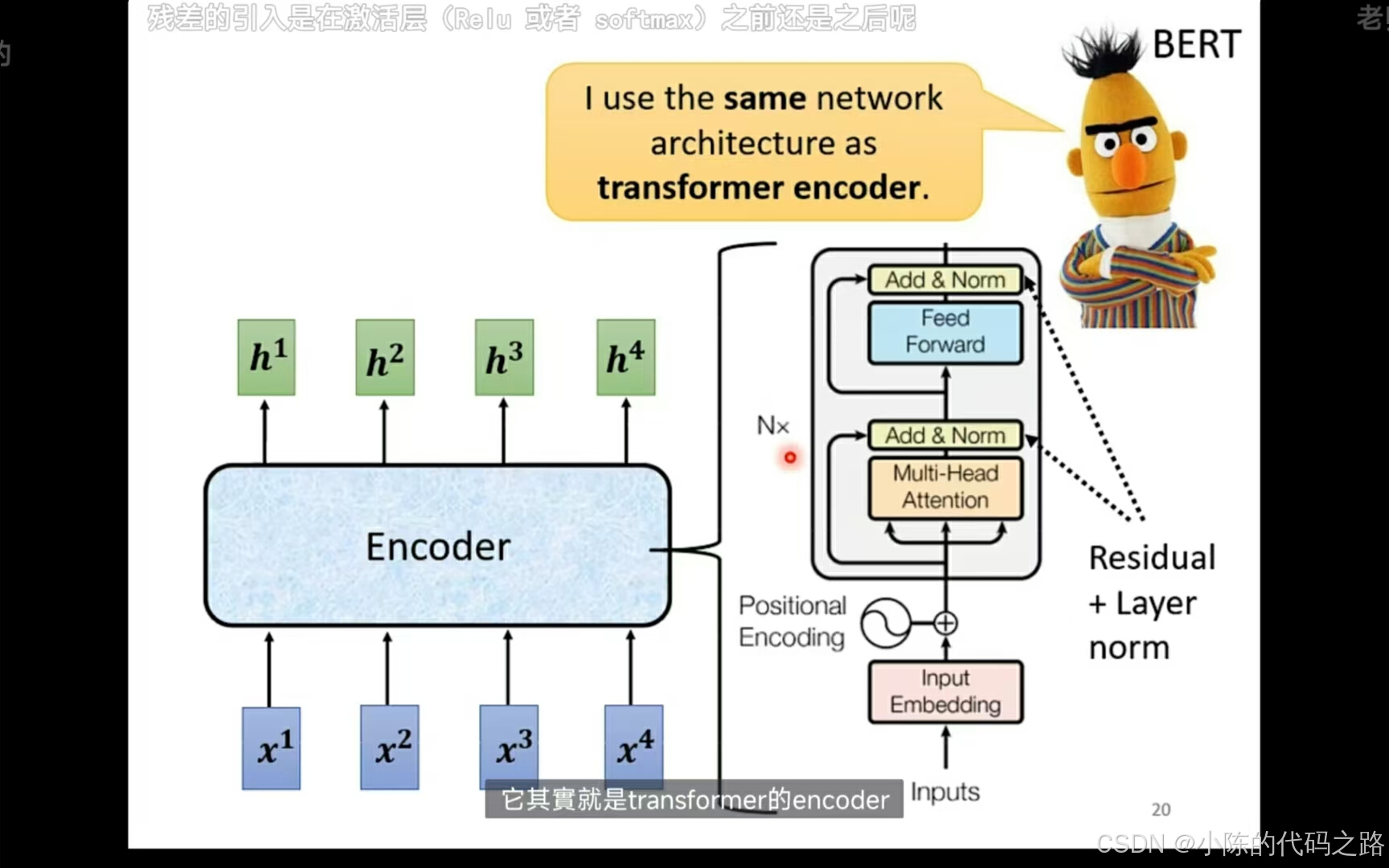
Positional Encoding 是在 Transformer 模型中用来引入序列中单词的位置信息的一种方法。由于 Transformer 模型本身并不具有处理序列顺序的能力(因为它基于自注意力机制,而不是递归或卷积结构),Positional Encoding 的加入使得模型能够理解词在序列中的相对或绝对位置。
前一半部分就是self-attention加norm ,后半部分就是fully connection加norm。
到此这篇conv啥意思(conv%)的文章就介绍到这了,更多相关内容请继续浏览下面的相关 推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/51620.html