
本文是对复现代码的解释,完整代码在simon3dv/PointNet1_2_pytorch_reproduced (ps:当时只写完pointnet就没时间更下去了, 反正现在pointnet++已经有至少两个pytorch版本了, 所以我也没更)
/experiments/prepare_data.ipynb
作者在实验时仅选取了40个类别,每个类别各100个不同的CAD模型,得到4000个CAD模型。(但我下载出来的ModelNet40并不是4000个CAD模型,而是训练集有9843个,测试集有2468个,而且类内数量不同)
ModelNet10选取了对应于NYU RGB-D数据集的其中10个类别。
对于此,PointNet论文中已经有所解释,
可以推理出,data是从均匀采样后且标准化为单位圆后的2048个点,faceId是2048个点对应的面的序号,label是类别标签,normal是法向量。为了验证data是否已标准化,我做了以下验证,求点云的直径,标准化后应该为1。可以看出已经很接近1了(但不清楚为什么有点误差)。
可以看出normal确实是对data标准化为单位圆后的结果。这里对标准化的方法进一步分析, pointnet/utils/pc_util.py 中有以下代码,可以直接使用。这里标准化是用点云/直径的方式,如果用min-max标准化会导致变形。
接下来回来继续看Pointnet官方,整个文件夹一共有7个.h5文件,应该包括了整个训练集和测试集。
可以看到,train有5个.h5,一共是9840个(2048,3)维的点,而test有2个.h5,一共有2468个点,与论文里说的一致。
“在网格面上均匀采样1024个点,标准化为单位圆。”我的代码如下(由于pointnet没给采样代码,这里先用最简单的随机采样进行实现):
Pointnet论文中训练时增强数据:一是沿垂直方向随机旋转,二是点云抖动,对每个点增加一个噪声位移,噪声的均值为0,标准差为0.02,我的代码如下:
ShapeNet也是一个大型3D CAD数据集,包含3Million+ models and 4K+ categories。旨在采用一种数据驱动的方法来从各个对象类别和姿势的原始3D数据中学习复杂的形状分布(比如看到杯子侧面就能预测到里面是空心的),并自动发现分层的组合式零件表示。包含的任务有:object category recognition, shape completion, part segmentation,Next-Best-View Prediction, 3D Mesh Retrieval.但是,ShapeNet(这篇文章中)使用的模型采用卷积深度置信网络将几何3D形状表示为3D体素网格上二进制变量的概率分布,而不是像后来出现的PointNet那样直接以点云的原始形式作为输入。
PointNet用的是其中的子集,包含16881个形状,16个类别,50个部件,标签在采样点上。下载连接在shapenetcore_partanno_v0(pre-released)(1.08GB),shapenetcore_partanno_segmentation_benchmark_v0()(635MB) 或者 pointnet作者提供的shapenet_part_seg_hdf5_data(346MB)
接下来对分割进行着色:
将所有数据导入,在Dataset创建时传入所有数据。但仍然有一个问题:每次训练开始都要读二十分钟的数据,很不方便调试。最后,我对所有数据先单位球标准化,再随机从网格面采样2048个点,然后保存为.h5格式。
见3.1.6 ModelNet40 mesh_sample,预处理用mesh_sample(random即可)的方法,要考虑面积加权,最后准确率才会比较高。直接用点采样的话哪怕用fps准确率也会下降0.03.
PointNet官方代码对T-Net的fc3对weight零初始化,bias初始化为单位矩阵。我在实验中也发现,如果不这么做,准确率在第一个epoch就非常低,后面很难超越不加T-Net的方案。tensorflow代码为
我的代码为
对于损失函数,官方是在softmax classification loss基础上加一个0.001权重的L2范数,代码如下。
其中F.nll_loss是negative log likelihood loss,但输入的是一个对数概率向量和一个标签,不会为我们计算对数,所以最好配合F.log_softmax使用。
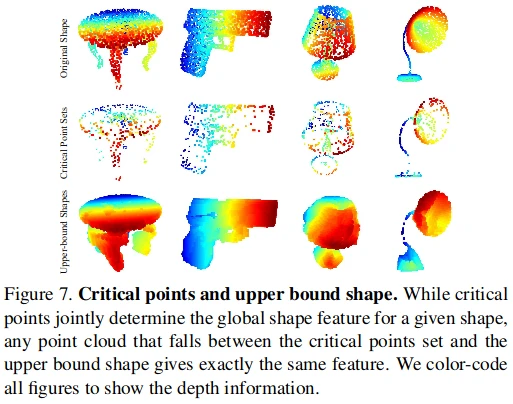
从(bs,n_points,1024)的逐点特征maxpool成(bs,1,1024)的全局特征时,这n_points个点对全局特征的贡献不同。有的点去掉不会影响全局特征,因为这个点的1024维特征在maxpool时都没有取到最大值;而另一些点去掉就会改变全局特征,这些点称为“关键点”,是原始点云的子集。而上界点集,可以理解为从[-1,1] x [-1,1] x -1,1遍历所有的点,如果一个点加入原始点云中不改变全局特征,则这个点在上界点集中,因此,原始点云是上界点集的子集。
pointnet的官方github并没有发布求关键点集和上界点集的方法,为此我自己做了简单的实现:
对于关键点集,只要在pointnet做maxpool时返回索引即可
而对于上界点集,则首先在原始点云中找到一个非关键点的点,(这是为了方便加入新的一个点)
然后遍历标准化后的空间的所有点,并替换刚刚找到的非关键点的点,然后求全局特征,如果全局特征发生改变,则加入上界点集。
对于ModelNet40的分类,采用默认参数:(epoch=135(BestEpoch), batchsize=16, Adam(learning_rate=0.001,weight_decay=1e-4),no data_augumentation,no T-Net)
KITTI 3D Object Detection.


这些是直接运行F-Pointnets官方代码的结果:
训练
为了避免每次训练都花大量时间读取和预处理数据,这里首先基于2Dbox标签和2D检测器得到的box分别提取视锥点云和标签。
calib/*.txt提供的校准矩阵分别是
- 校正后的投影矩阵()P0(左灰),P1(右灰),P2(左彩),P3(右彩)
- 校正旋转矩阵():R0_rect
- Tr_velo_to_cam
- Tr_imu_to_velo
坐标系有四个,分别是reference,rectified,image2和velodyne:
根据校准矩阵可以在坐标系之间相互投影,由于时间原因原理这里就不介绍了,而实现在Frustum-Pointnet/kitti/kitti_object/Calibration中非常详细,可以直接用。主要记住标签是rect camera coord的,所以都往这个坐标系做投影即可。
能不能找些Car的3D CAD模型能否作为额外数据来改善kitti的3D目标检测性能, 毕竟kitti数据是真的少. 3D目标检测里好像还没人这么做.
- download vtk https://vtk.org/download/#latest and compile:
unzip VTK
cd VTK
mkdir build
cd build
cmake ..
make
sudo make install - install mayavi and PyQt5
pip install mayavi
pip install PyQt5
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/29659.html