
- 论文题目:Faster R-CNN: T owards Real-Time Object Detection with Region Proposal Networks
- 论文链接:https://arxiv.org/abs/1506.01497

Faster R-CNN是为了改进Fast R-CNN而提出来的。因为在Fast R-CNN文章中的测试时间是不包括search selective时间的,而在测试时很大的一部分时间要耗费在候选区域的提取上。所以作者提出了来提取候选框,使时间大大的减少了。
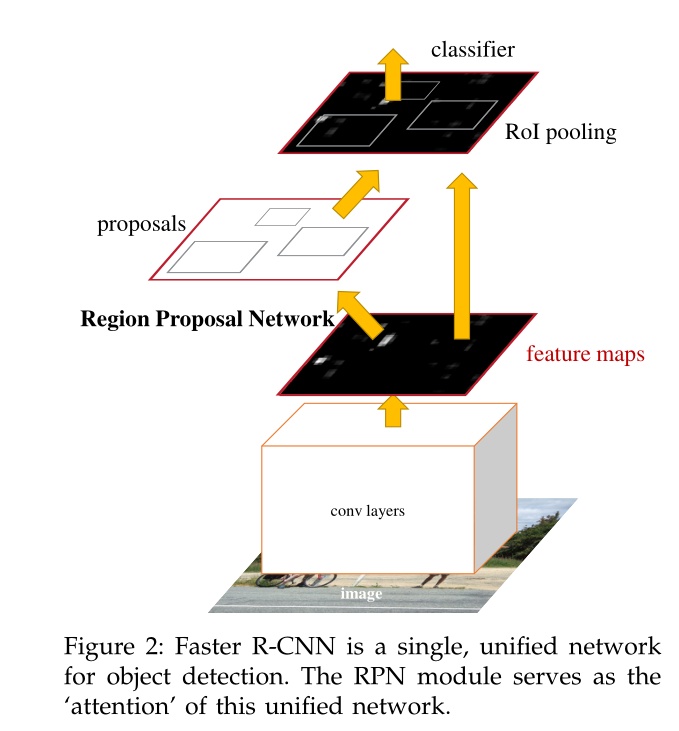
Faster R—CNN具体可分为四个结构:
- Conv layers:作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks:RPN网络用于生成region proposals。该层通过softmax判断anchors属于 positive或者 negative,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling:该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification:利用proposal feature maps计算proposal的类别,同时再次获得检测框最终的精确位置。
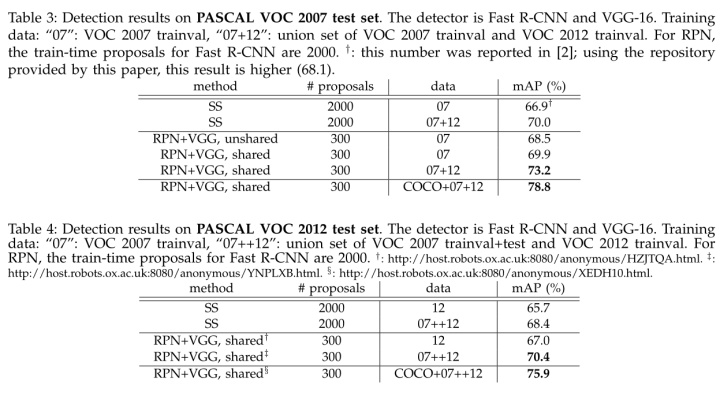
下图是VGG16模型中的faster_rcnn_test.pt的网络结构,可以清晰的看到该网络对于一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification。
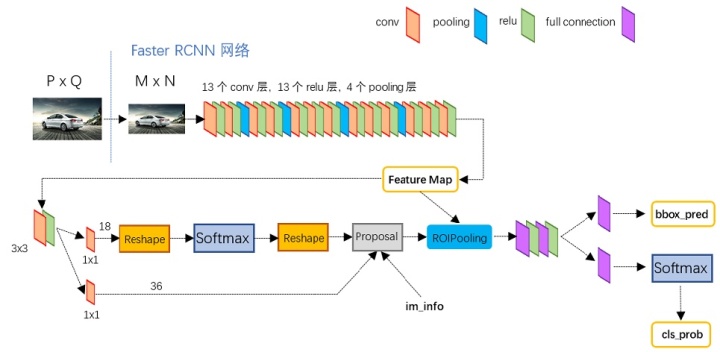
Conv layers
Conv layers包含了conv,pooling,relu三种层。所有的conv层都是:kernel_size=3,pad=1,stride=1。所有的pooling层都是:kernel_size=2,pad=1,stride=1。
Region Proposal NetWork(RPN)
经典的检测方法生成检测框都非常耗时,如使用方法生成检测框。而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。
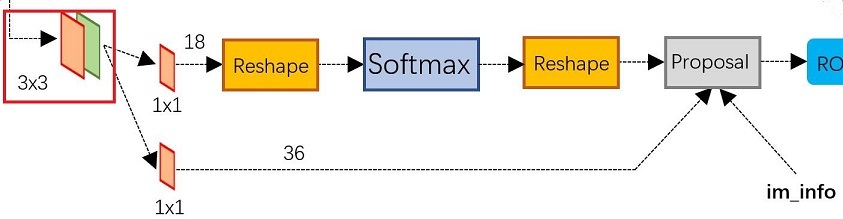
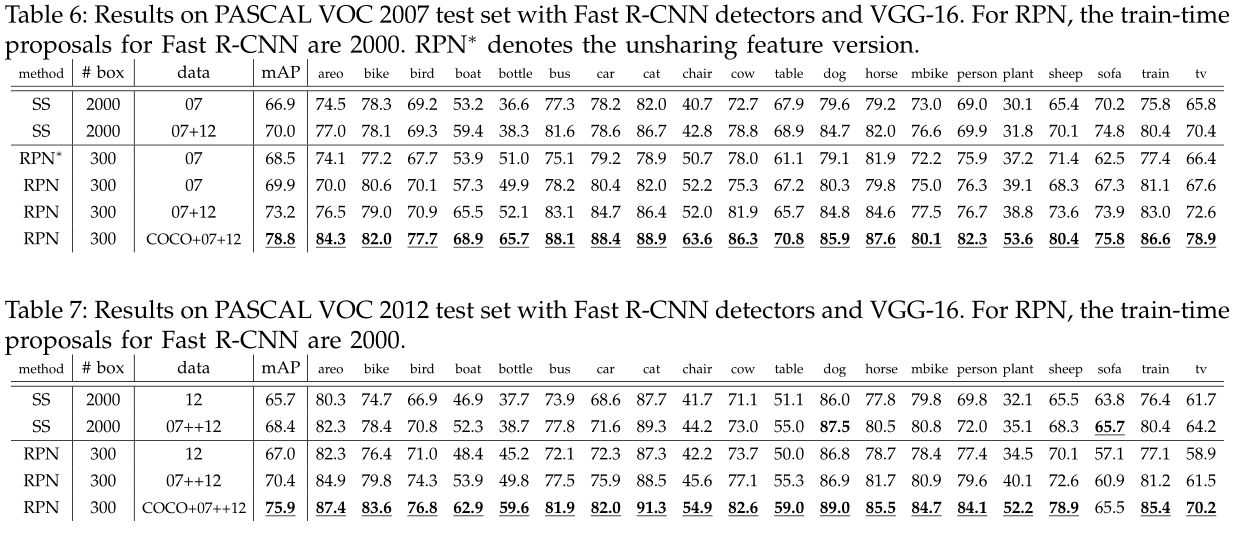
上图展示了RPN网络的具体结构。可以看到RPN网络实际分为2条线,上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
Anchor
在每个滑动窗口的位置,我们同时预测多个,每个位置最大可能的设置为。每个回归层输出4k个坐标(即x,y,w,h),分类层输出2k个。RPN默认设置为,,因此每个位置输出9个。对于大小为W×H(通常为2400)的卷积特征图,总共有W Hk。如下图所示:
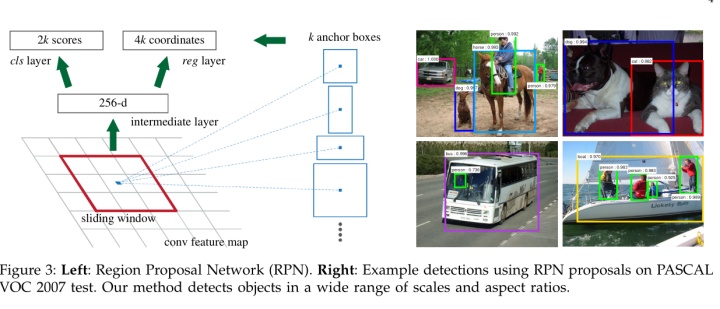
注意:全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练
Loss Function
我们定义在faster r-cnn中,最小化多任务损失,公式如下:
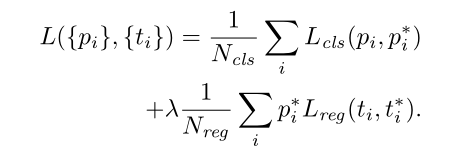
公式中,i是中anchor的索引,
是目标的概率。如果anchor是
的话,
对于,我们采用如下的四个坐标,具体含义可以参照原文:
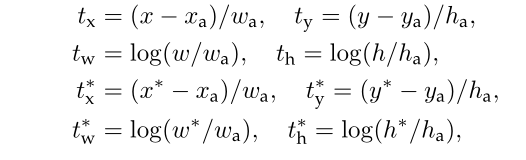
训练RPN
RPN可以通过反向传播和随机梯度下降(SGD)进行端到端的训练。我们遵循“以图像为中心”的采样策略来训练这个网络。每个小批都来自一个包含许多正面和负面示例anchor的图像。我们可以对所有anchor的损失函数进行优化,但这将偏向于负样本,因为它们占主导地位。相反,我们在一张图像中随机抽取256个锚点来计算一个小批量的损失函数,其中抽样的正锚点和负锚点的比例高达1:1。如果一个图像中有少于128个positive样本,我们用negative样本填充这个小批。
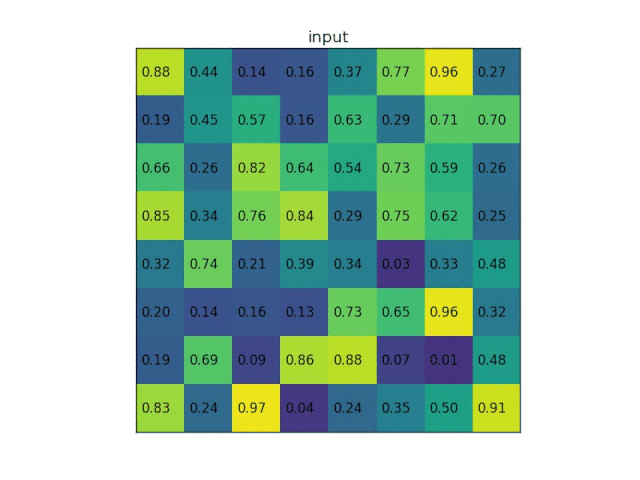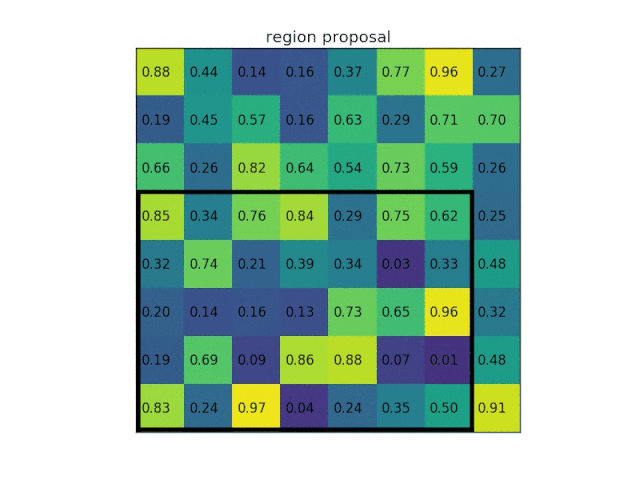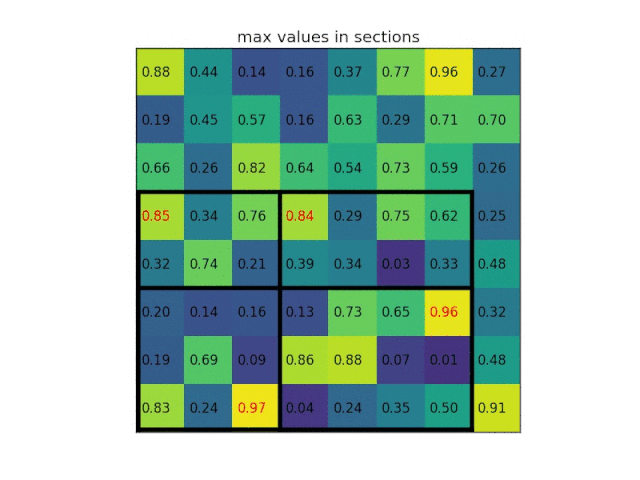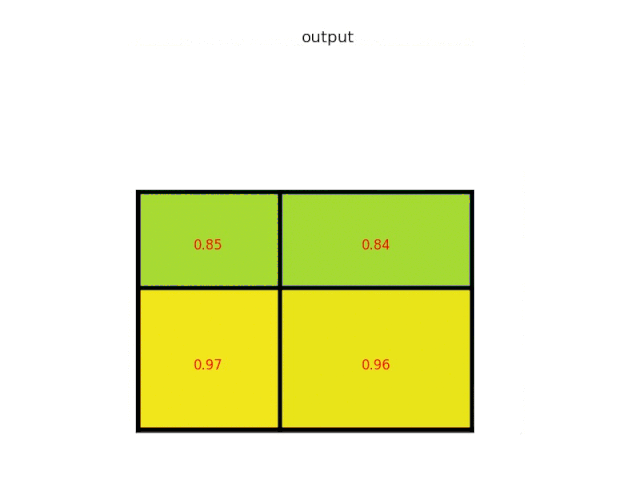
ROI Pooling的作用是对不同大小的region proposal,从最后卷积层输出的feature map提取大小固定的feature map。因为全连接层的输入需要尺寸大小一样,所以不能直接将不同大小的region proposal映射到feature map作为输出,需要做尺寸变换。即将一个hw的region proposal分割成HW大小的网格,然后将这个region proposal映射到最后一个卷积层输出的feature map,最后计算每个网格里的最大值作为该网格的输出,所以不管ROI pooling之前的feature map大小是多少,ROI pooling后得到的feature map大小都是H*W。
下面是ROI polling layer层的一个经典动图:从图中可以直接看到ROI polling是怎样使输出都是固定的形状。
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。Classification部分网络结构如下图所示。
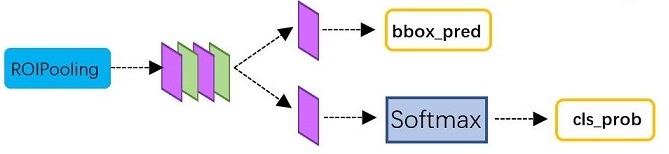
从RoI Pooling获取到7x7=49大小的proposal feature maps后,送入后续网络,可以看到做了如下2件事:
1、通过全连接和softmax对proposals进行分类,这实际上已经是识别的范畴了
2、再次对proposals进行bounding box regression,获取更高精度的rect box
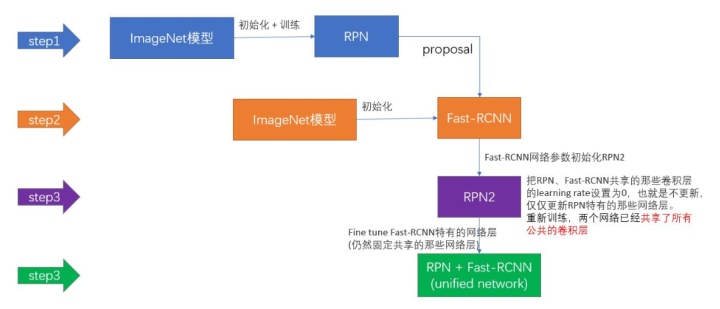
Faster R-CNN的训练,是在已经训练好的model(如VGG_CNN_M_1024,VGG,ZF)的基础上继续进行训练。实际中训练过程分为6个步骤:
- 在已经训练好的model上,训练RPN网络,对应stage1_rpn_train.pt
- 利用步骤1中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第一次训练Fast RCNN网络,对应stage1_fast_rcnn_train.pt
- 第二训练RPN网络,对应stage2_rpn_train.pt
- 再次利用步骤4中训练好的RPN网络,收集proposals,对应rpn_test.pt
- 第二次训练Fast RCNN网络,对应stage2_fast_rcnn_train.pt
下面是一张训练过程流程图:
https://github.com/rbgirshick/py-faster-rcnngithub.com
到此这篇cnn神经网络(CNN神经网络算法流程图)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/26651.html