
本文将从CNN解决了什么问题、人类的视觉原理、CNN的基本原理、典型的CNN及实际应用四个方面,带您一文搞懂卷积神经网络CNN。
图像处理存在两个难题:
- 数据量巨大: 图像由像素组成,每个像素又由RGB三个颜色参数表示。
对于一张1920×1080 像素的图片,就需要处理6百万个参数。(1920*1080*3=)
- 特征保留困难: 传统图像处理方法很难保留原始图像特征。例如:图像中物体的位置发生变化,传统方法处理后的数据会有很大差异。
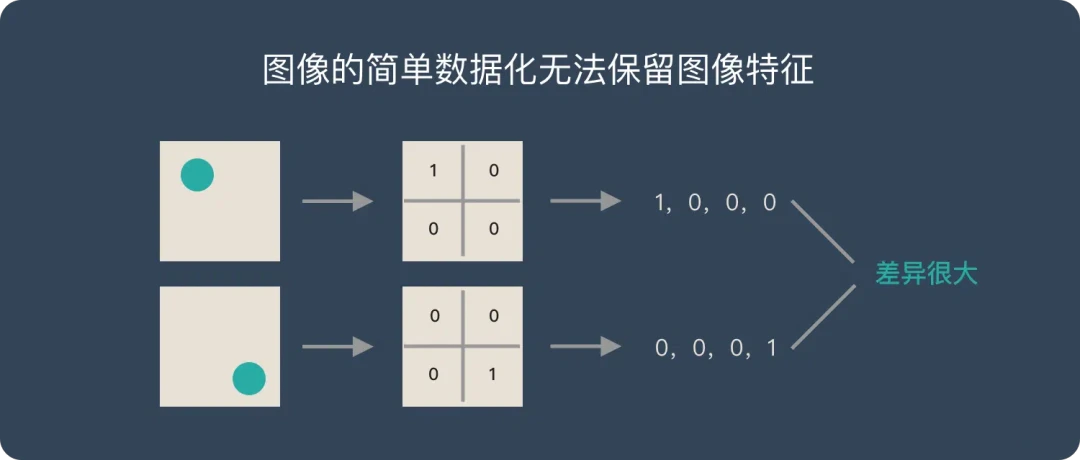
CNN解决问题:
- 提取特征: 卷积操作提取图像特征,如边缘、纹理等,保留图像特征。
- 数据降维: 池化操作大幅降低参数量级,实现数据降维,大大减少运算量,避免过拟合。
在我们了解 CNN 原理之前,先来看看人类的视觉原理是什么?
1981年诺贝尔医学奖:
- 获得者:David Hubel(大卫·休伯尔)、Torsten Nils Wiesel(托斯坦·威泽尔)、Roger Sperry(罗杰·斯佩里)
- 主要贡献:发现了视觉系统的信息处理,可视皮层是分级的。
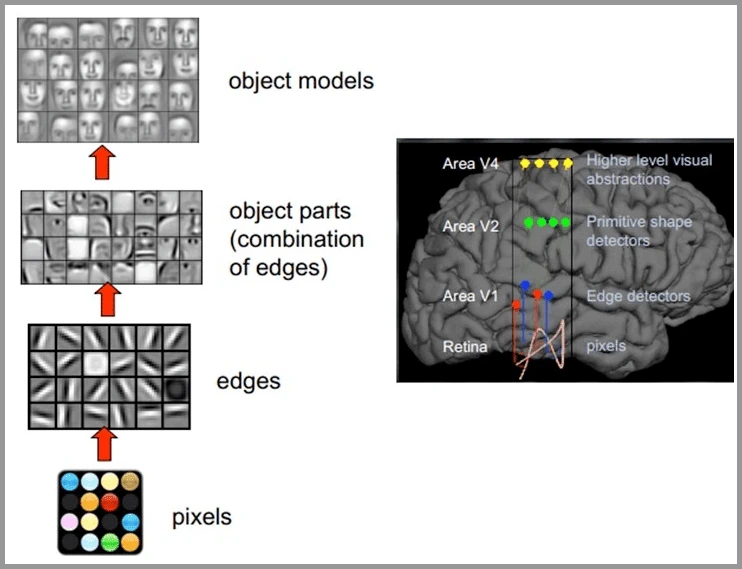
人类视觉原理:
- 光信号感知:原始信号摄入,光信号转化为神经信号。
- 初级视觉处理:神经信号传送到大脑的初级视觉皮层,进行初步特征提取,例如边缘、纹理等。
- 高级视觉处理:初级视觉皮层的信息传递到高级视觉皮层,进行复杂的特征提取,例如颜色、形状、运动等。
- 识别与认知:将输入的图像与已有的知识进行匹配和识别。
构成部分:
- 卷积层: 用来提取图像的局部特征。
- 池化层:用来大幅降低参数量级,实现数据降维。
- 全连接层: 用来输出想要的结果。

基本原理:
- 卷积层:通过卷积核的过滤提取出图片中局部的特征,类似初级视觉皮层进行初步特征提取。
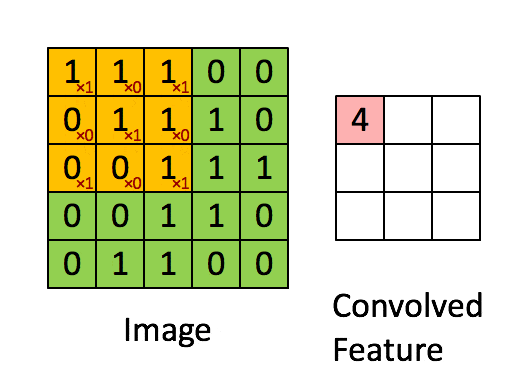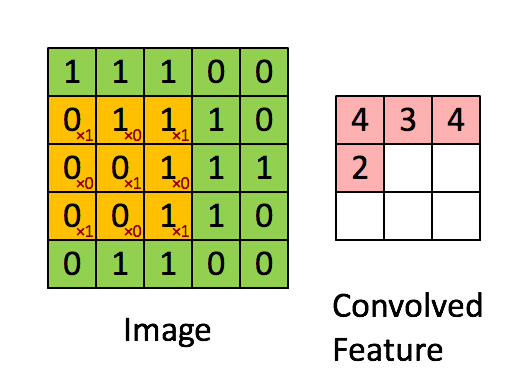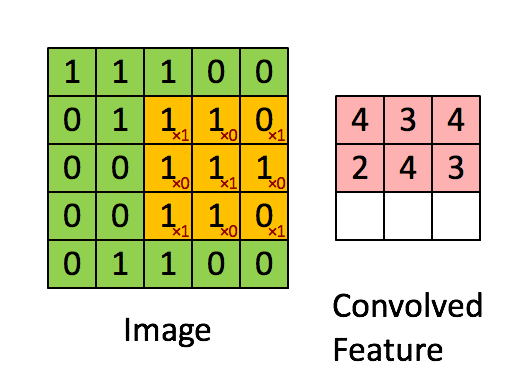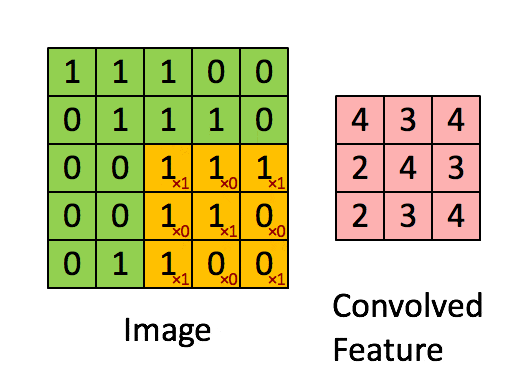
使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
- 池化层:下采样实现数据降维,大大减少运算量,避免过拟合。
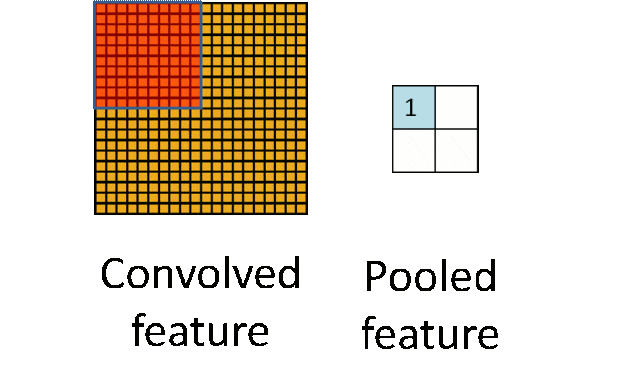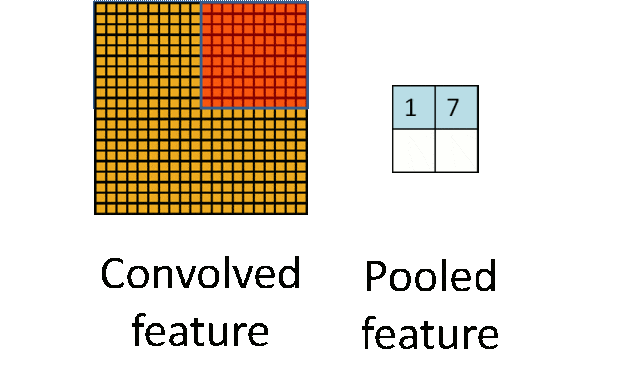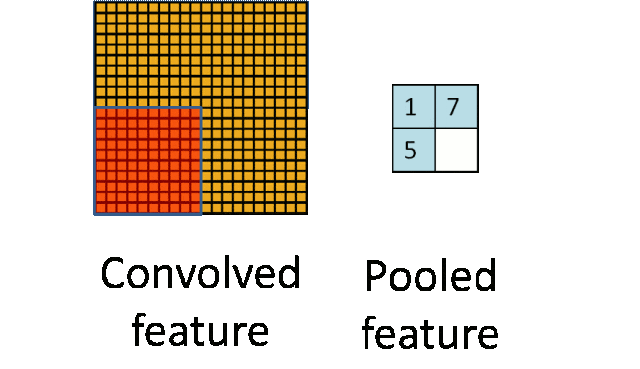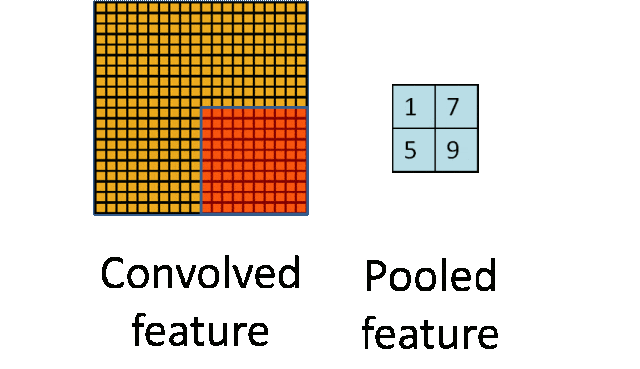
原始是20×20的,进行下采样,采样为10×10,从而得到2×2大小的特征图。
- 全连接层:经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果
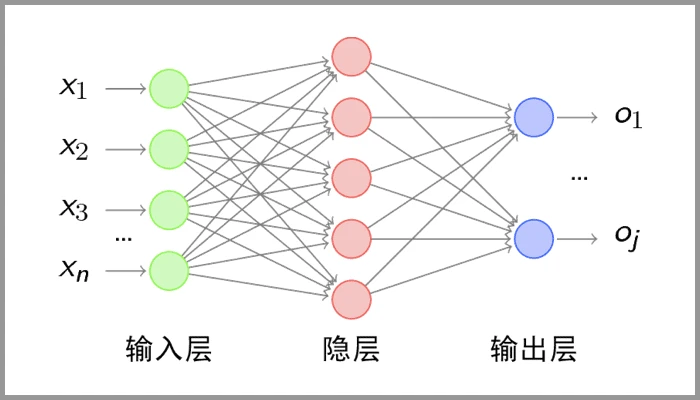
典型的 CNN 并非只是上面提到的3层结构,而是多层结构。

例如,LeNet-5被誉为是卷积神经网络的“Hello Word”。LeNet-5是图灵奖获得者Yann LeCun(杨立昆)在1998年提出的CNN算法,用来解决手写识别的问题。
LeNet-5 的网络结构:
- 输入层: INPUT
- 三个卷积层: C1、C3和C5
- 两个池化层: S2和S4
- 一个全连接层: F6
- 输出层: OUTPUT
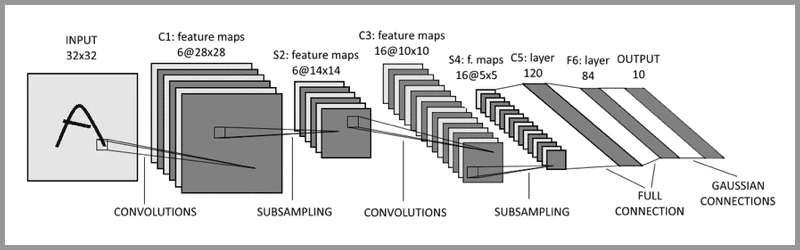
输入层- 卷积层 – 池化层- 卷积层 – 池化层 – 卷积层 – 全连接层 - 输出层
实际应用:
- 图像分类:可以节省大量的人工成本,将图像进行有效的分类,分类的准确率可以达到 95%+。典型场景:图像搜索。
- 目标定位:可以在图像中定位目标,并确定目标的位置及大小。典型场景:自动驾驶。
- 目标分割:简单理解就是一个像素级的分类。典型场景:视频裁剪。
- 人脸识别:非常普及的应用,戴口罩都可以识别。典型场景:身份认证。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/cjjbc/12694.html