

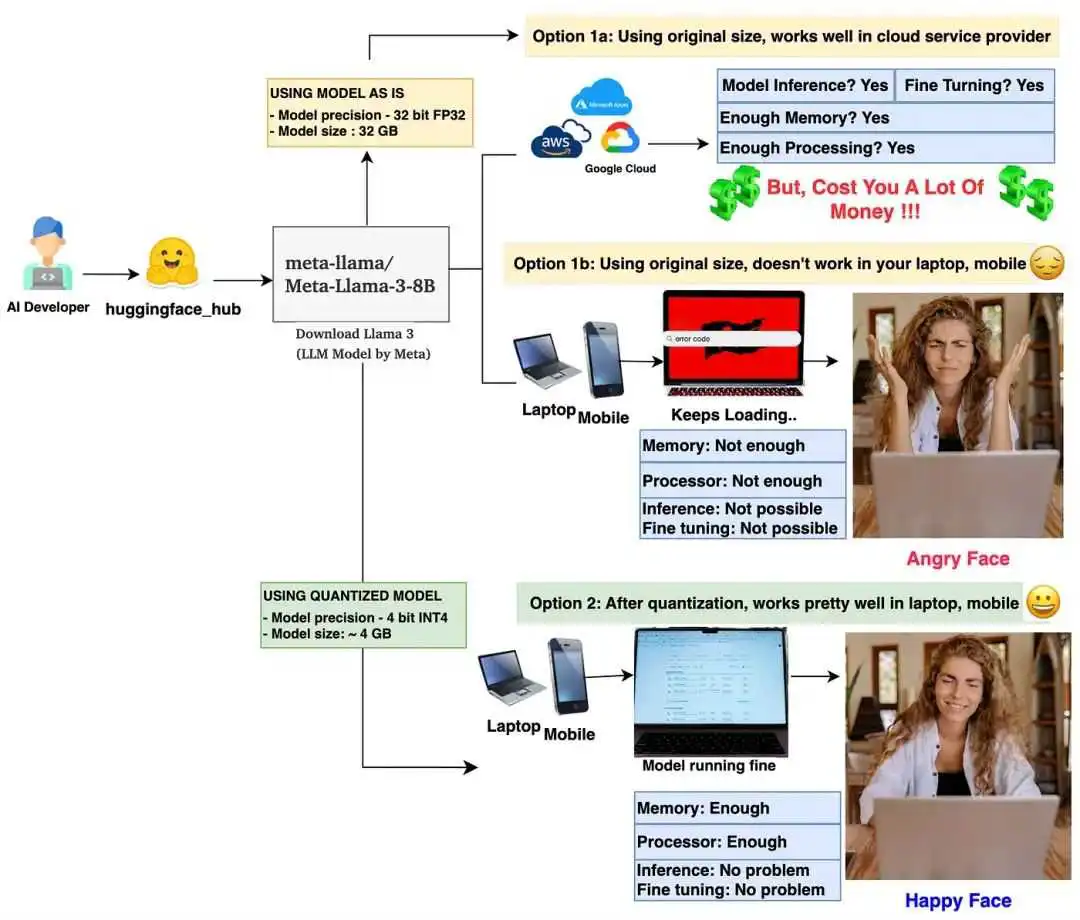
-
https://pub.towardsai.net/want-to-learn-quantization-in-the-large-language-model-57f062d2ec17
-
首先,了解量化的是什么以及为什么需要它。 -
接下来,深入学习如何进行量化,并通过一些简单的数学推导来理解。 -
最后编写一些PyTorch 代码,以对 LLM 权重参数进行量化和反量化。
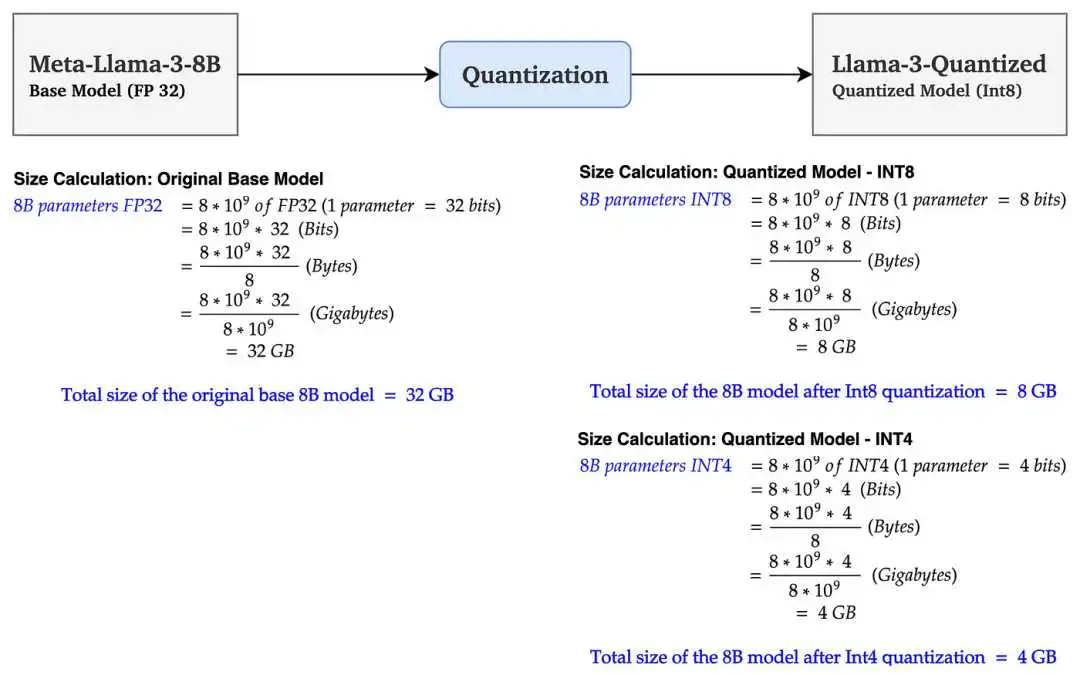
这么算,7B的大模型FP16部署权重14G,INT8是8G,INT4再砍半是4G
-
降低显存需要 -
提升推理性能
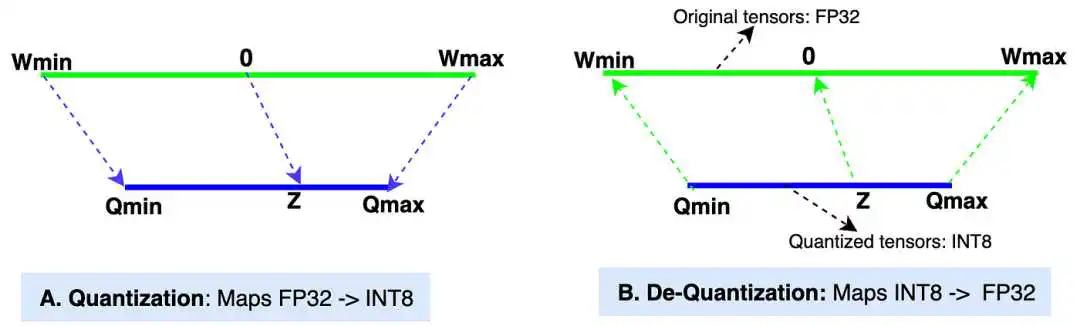
-
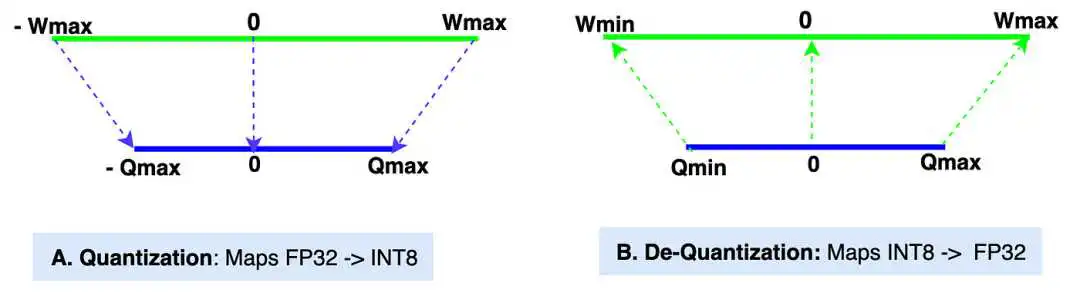
Wmin, Wmax: 原始张量的最小值和最大值(数据类型:FP32,32 位浮点)。在大多数现代 LLM 中,权重张量的默认数据类型是 FP32。 -
Qmin, Qmax: 量化张量的最小值和最大值(数据类型:INT8,8 位整数)。我们也可以选择其他数据类型,如 INT4、INT8、FP16 和 BF16 来进行量化。我们将在示例中使用 INT8。 -
缩放值(S):在量化过程中,缩放值将原始张量的值缩小以获得量化后的张量。在反量化过程中,它将量化后的张量值放大以获得反量化值。缩放值的数据类型与原始张量相同,为 FP32。 -
零点(Z): 零点是量化张量范围中的一个非零值,它直接映射到原始张量范围中的值 0。零点的数据类型为 INT8,因为它位于量化张量范围内。 -
量化: 图中的“A”部分展示了量化过程,即 [Wmin, Wmax] -> [Qmin, Qmax] 的映射。 -
反量化: 图中的“B”部分展示了反量化过程,即 [Qmin, Qmax] -> [Wmin, Wmax] 的映射。

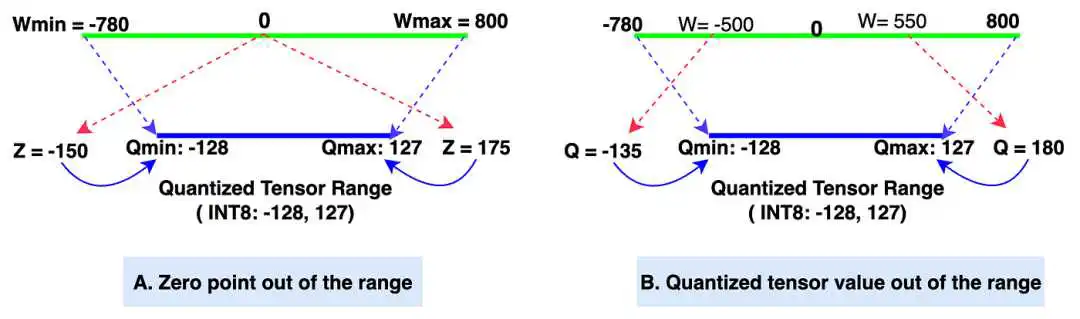
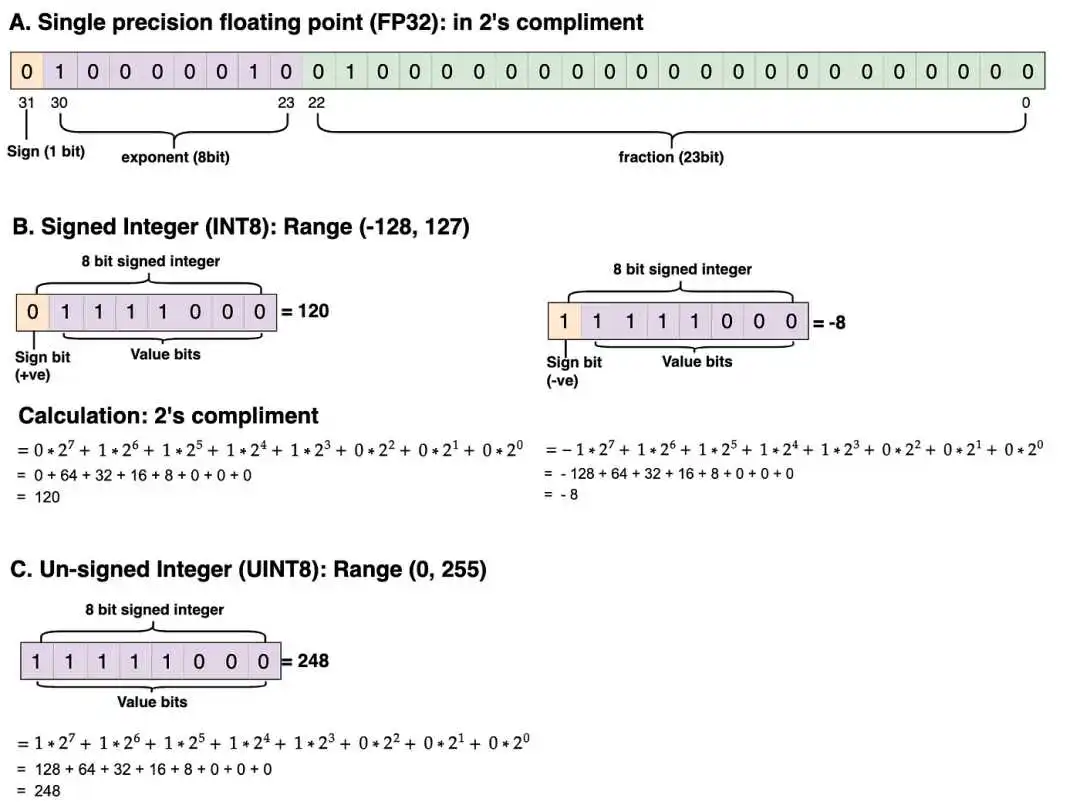
量化张量值的范围为-128到127(INT8,带符号整数数据类型)。如果量化张量值的数据类型为UINT8(无符号整数),则范围为0到255。


# !pip install torch; 安装torch库,如果你还没有安装的话
# 导入torch库
import torch
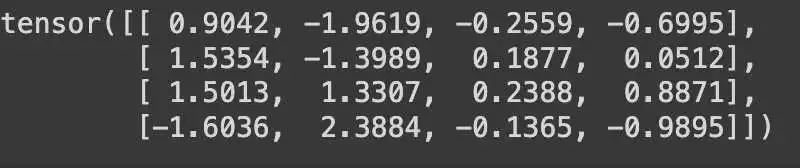
original_weight = torch.randn((4,4))
print(original_weight)

def asymmetric_quantization(original_weight):
# 定义你想要量化的数据类型。在我们的示例中,是INT8。
quantized_data_type = torch.int8
# 从原始的FP32权重中获取Wmax和Wmin值。
Wmax = original_weight.max().item()
Wmin = original_weight.min().item()
# 从量化数据类型中获取Qmax和Qmin值。
Qmax = torch.iinfo(quantized_data_type).max
Qmin = torch.iinfo(quantized_data_type).min
# 使用缩放公式计算缩放值。数据类型 - FP32。
# 如果你想了解公式的推导过程,请参考本文的数学部分。
S = (Wmax - Wmin)/(Qmax - Qmin)
# 使用零点公式计算零点值。数据类型 - INT8。
# 如果你想了解公式的推导过程,请参考本文的数学部分。
Z = Qmin - (Wmin/S)
# 检查Z值是否超出范围。
if Z < Qmin:
Z = Qmin
elif Z > Qmax:
Z = Qmax
else:
# 零点的数据类型应与量化后的值相同,为INT8。
Z = int(round(Z))
# 我们有了original_weight、scale和zero_point,现在我们可以使用数学部分推导出的公式计算量化后的权重。
quantized_weight = (original_weight/S) + Z
# 我们还将对其进行四舍五入,并使用torch clamp函数,确保量化后的权重不会超出范围,并保持在Qmin和Qmax之间。
quantized_weight = torch.clamp(torch.round(quantized_weight), Qmin, Qmax)
# 最后,将数据类型转换为INT8。
quantized_weight = quantized_weight.to(quantized_data_type)
# 返回最终的量化权重。
return quantized_weight, S, Z
def asymmetric_dequantization(quantized_weight, scale, zero_point):
# 使用本文数学部分推导出的反量化计算公式。
# 还要确保将量化后的权重转换为浮点型,因为两个INT8值(quantized_weight和zero_point)之间的减法会产生不期望的结果。
dequantized_weight = scale * (quantized_weight.to(torch.float32) - zero_point)
return dequantized_weight
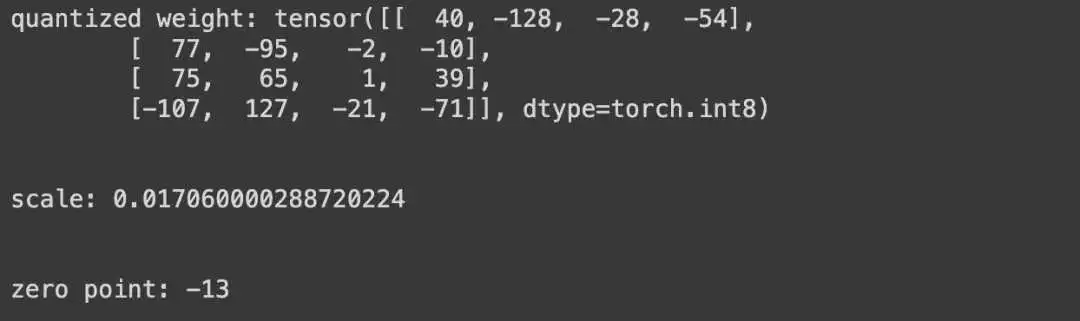
quantized_weight, scale, zero_point = asymmetric_quantization(original_weight)
print(f"quantized weight: {quantized_weight}")
print("\n")
print(f"scale: {scale}")
print("\n")
print(f"zero point: {zero_point}")
dequantized_weight = asymmetric_dequantization(quantized_weight, scale, zero_point)
print(dequantized_weight)
quantization_error = (dequantized_weight - original_weight).square().mean()
print(quantization_error)

-
https://github.com/tamangmilan/llm_quantization/blob/main/llm_quantization_part_1.ipynb

扫描二维码添加小助手微信

版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/72004.html