
Frequency-Spatial Entanglement Learning for Camouflaged Object Detection
基于频域-空域纠缠学习的视频目标检测
European Conference on Computer Vision 2024
Paper Code

伪装目标检测是计算机视觉领域的一个研究热点。主要的挑战在于伪装物体与其周围环境在空间域中的高度相似性,使得识别变得困难。现有的方法试图通过最大化空间特征的区分能力来降低像素相似性的影响,设计复杂,但往往忽略了特征在空间域的敏感性和局部性,导致结果不理想。提出了一种新的方法来解决这一问题,该方法将频率域和空间域的表示方法结合起来,引入了频率-空间纠缠学习(FSEL)方法.该方法包括一系列用于表示学习的纠缠Transformer模块(ETB),用于语义增强的联合域感知模块,以及用于频域和空域特征集成的双域逆向分析器。具体地说,ETB利用频率自注意来有效表征不同频带之间的关系,而纠缠前馈网络通过纠缠学习来促进不同域特征之间的信息交互。
Keywords:伪装物体检测·计算机视觉·频率空间纠缠学习
隐藏目标检测(COD)的研究重点是识别现实世界中的隐藏目标。该研究对于在计算机视觉中开发鲁棒的视觉感知模型至关重要。COD具有广泛的应用,包括医学图像分析,物种保护和工业缺陷检测。
在早期阶段,一些COD方法依靠手工制作的特征来检测伪装物体。然而,由于这些物体的外观极具挑战性,因此获得的结果往往不令人满意。后来,随着深度学习的进步和大规模数据集的出现,许多基于深度学习的COD方法相继被提出。由于有大量数据可供训练,这些方法有可能自动提取特征并检测伪装物体,从而产生令人印象深刻的性能。最近,研究人员已经引入了各种技术,用于使用边界引导、多尺度策略、不确定性感知、分散注意力挖掘等来从空间域探索输入特征的有用信息。我们已经观察到COD方法主要集中在单一的空间特征上。虽然这些空间特征对于COD任务是有利的,但是它们通常容易受到来自复杂背景的干扰。这种脆弱性源于它们对像素级信息的依赖,主要侧重于单个像素的局部强度和空间位置。此外,空间特征具有局部属性,这意味着特征内的像素可能仅表现出与周围像素的某些相关性。也就是说,仅仅依靠空间特征可能难以区分隐藏物体和背景内的细微变化。因此,如何克服空间特征的局限性,获得准确的COD结果是一个关键问题。近来,通过傅里叶变换生成的频率特征已经被示出具有全局特性,并且已经被证明对于理解图像内容是有益的。这可以帮助打破空间要素的瓶颈。
一些最近的COD方法已经开始在其方法中结合频率线索。这些方法根据其目的可分为两大类。第一类别是通过不同的频率变换直接作用于输入图像以提取频率特征,然后将其与空间特征组合。然而,伪装图像常包含大量的背景噪声,使得从图像中获得的频率特征不可靠。当与空间特征聚合时,这可能会引入一些不必要的背景噪声,从而导致分割不足的结果。第二类关注来自编码器的初始特征。例如,Cong等人设计了一个频率感知模块,通过利用高频特征和低频特征来提高对隐藏对象的检测。He等人提出了频率注意模块,通过考虑高频和低频分量来获得相应特征的重要部分。虽然这些方法已经显示出有希望的结果,但它们只关注高频和低频特征,忽略了在这两个频率之间的一些信息。
基于上述讨论,本文提出了一种新的方法,称为频率空间纠缠学习的准确的被隐藏的对象检测。我们的方法结合了全局频率特征和局部空间特征,以优化初始输入特征,提高其鉴别能力。具体来说,我们首先建立了一个频率自注意力,以获得有区别的全局频率特征,该特征对每个频带之间的相关性进行建模,并学习输入频带中不同频率之间的依赖关系。此外,在Entanglement Transformer Block中引入了频率和空间特征之间的纠缠学习,允许它们相互学习和协作以进行优化。此外,利用联合域感知模块和双域反向解析器来优化输入特征,并生成包含频率和空间信息的强大表示,从而扩展了全局频率特征的适用性。
伪装的对象通过颜色、纹理和形状的自适应变化表现出与其背景高度的视觉相似性。这在空间域中区分对象和背景像素方面产生了挑战。另外,空间域中特征的局部性在理解伪装物体方面是有限的。针对这一问题,本文实施几个策略:1)扩展到空间域之外,并利用傅立叶变换将特征映射到频域,允许更全局的视角:2)分析了所有频带之间的关系,将全局频率特征与局部空间特征相结合; 3)将频率特征扩展到多个分量,以充分利用对对象的全局理解。
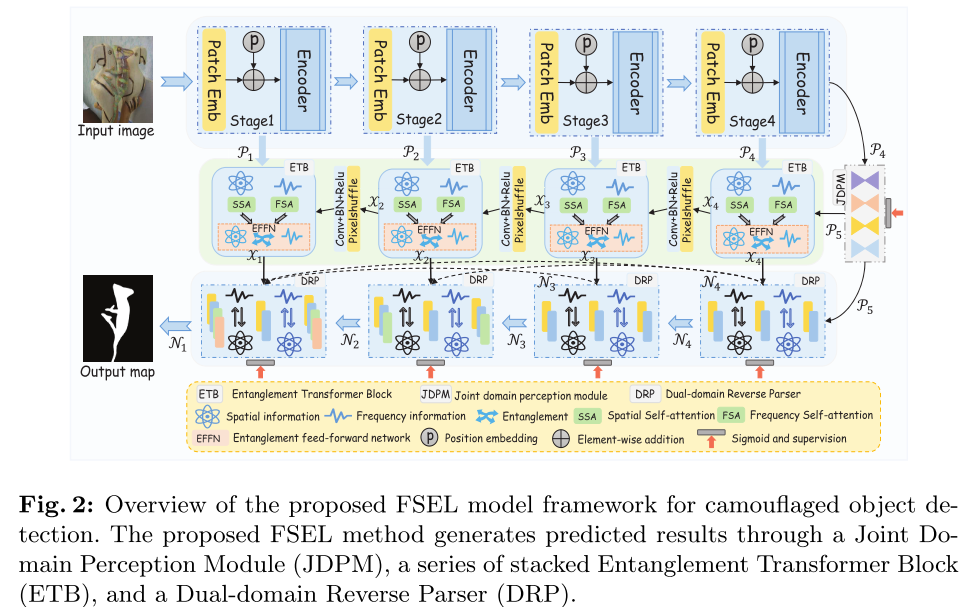
FSEL模型的完整架构如上图所示。给定输入图像Ic ∈ RH×W×3,首先使用编码器(即,PVTv 2 /ResNet/Res2Net)以提取初始特征,分辨率为。然后是JDPM通过整合来自频率-空间域的多感受野信息来捕获更高级别的语义特征P5以指导定位。在此之后,ETB对跨长距离关系进行建模,并从初始特征在频域和空间域上执行纠缠学习,以生成区别性特征X={Xi}4 i=1。为了保证预测图N={Ni}4 i=1的质量,设计了一个DRP以通过频域和空间域中的辅助优化来聚合特征流。
整体就是backbone提取四层特征,第四层再经过JDPM处理得高级特征P5;除此之外每层特征都要经过ETB处理,然后通过DRP聚合每层处理后的特征和高层特征,得到最后结果。
联合域感知模块 JDPM
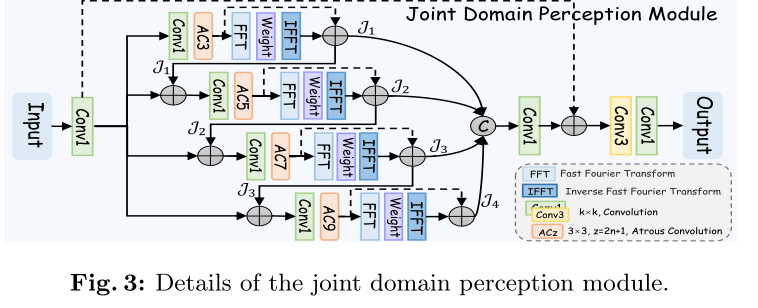
多尺度信息有利于不同区域的语境理解。我们观察到有些方法通常通过空间域中的多个感受野的不同卷积生成多尺度特征。然而,空间卷积运算的感受野受限,在数据处理过程中,微小的波动可能会被忽略,导致次优化结果。
因此,提出了一个联合域感知模块(JDPM),通过在多尺度特征中引入频率变换来重建多感受野信息。如图所示,JDRM使用分层结构来提取不同感受野的频率-空间信息。从技术上讲,使用特征P4作为输入,首先使用1×1卷积(C1)减少其通道数。然后,构造一组填充率为z的3×3的膨胀卷积来捕获局部多尺度空间特征。接下来,使用快速傅立叶变换(fft(·))将局部空间特征变换到频域,并执行冗余滤波。然后,使用快速傅里叶逆变换(ifft(·))和复特征的模来获得全局频率特征,其被定义为:
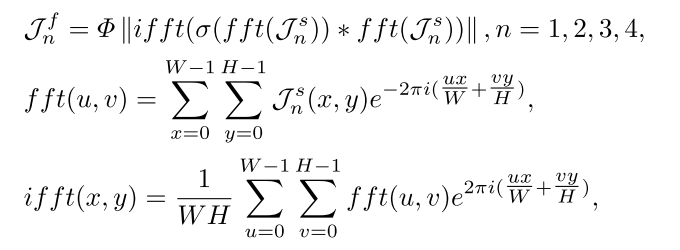
其中Φ·和 * 表示模运算和逐元素乘法。σ(·)表示一组权重系数,依次包含卷积、批量归一化、ReLU、卷积和sigmoid函数。(u,v)和(x,y)表示频域坐标和空间域坐标,i表示虚部。然后,将全局频率特征与局部空间特征聚合,生成中间多尺度特征Jn,即。
最后,连接所有多尺度特征并引入残差连接,通过3 × 3和1 × 1卷积生成具有1通道的粗略特征图P5,可以表示为:
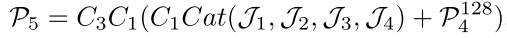
其中Ck表示k×k卷积。Cat和“+”表示连接和元素加法。
其实是用第四层的特征,先来个卷积缩减通道数得到X:用膨胀卷积处理,再经过傅里叶变换,变换结果与自己逐元素乘,再经过卷积归一化激活sigmoid,然后傅里叶逆变换再求模,得到的结果为J1;以后先用Ji-1与X相加,再重复这个操作得到J1、2、3、4;把它们cat到一起,再经过卷积与X残差连接,再卷积,得到最后的结果。这些操作为了结合空间域与频域。
纠缠Transformer块 ETB
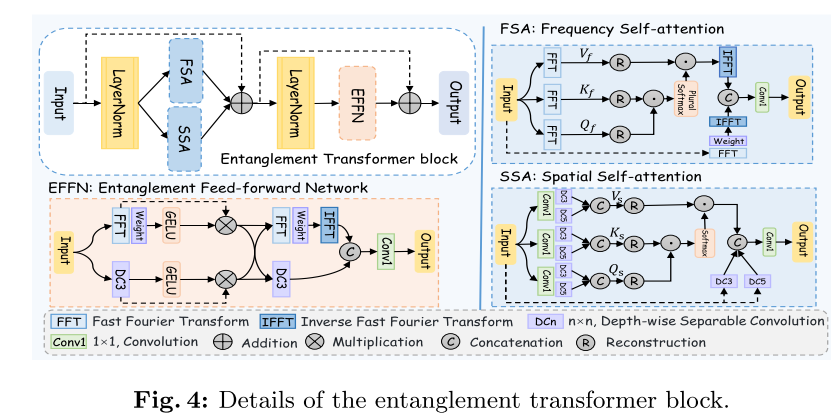
与之前仅基于空间域中的局部特征对长范围依赖性建模不同,ETB结合了来自频率域和空间域的不同关系。此外,提出在ETB中对不同领域的特征进行纠缠学习,允许整合诸如颜色、纹理、边缘、光谱、幅度和能量等信息。这种方法有利于通过考虑各种类型的信息来学习区分表征。如图所示,ETB由三个关键部分组成:频率自注意(FSA)、空间自注意(SSA)和纠缠前馈网络(EFFN)。
它接收encoder的特征和处理过的高级特征,先经过一个layer normalization,然后分别经过频率自注意(FSA)和 空间自注意(SSA),得到的两个特征再与初始输入残差连接,然后经过layerNorm和自定义的前馈网络EFFN,再残差连接,得到最后的结果。
频率自注意力FSA。为了更好地分析频率信号,引入了自注意结构,使得模型能够获取不同频带之间的关系和相互作用,学习重要性权重,并进行自适应融合。以同级初始特征和优化后的高层特征为输入,并经过层归一化生成特征P。然后,利用快速傅里叶变换在频域中得到Query Qf=fftQ(P),Key Kf=fftK(P),Value Vf=fftV(P),然后对Query (eQf∈RC×HW)和Key(eKf∈RHW×C)的投影进行整形,使它们的点积生成转置-注意映射(Λf,Λf= eQf ⊙ eKf),其中⊙表示矩阵乘法。频率注意力图(Λf)是一种复杂类型,不能直接激活。因此,我们提取实部(Λre f,Λre f =(Λf +conj(Λf))/2)与虚部(Λim f,Λim f =(Λf −conj(Λf))/2 i),其中conj(·)表示共轭复数,然后激活并合并真实的部和虚部输入输出为了获得激活的注意力图(a ~ f),如下所示:
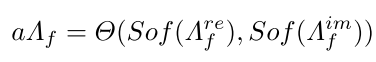
其中,Θ(·,·)表示将虚部和真实的部组合成复数的组合函数。Sof(·)表示Softmax函数。随后,使用注意力映射aΛf来优化频率特征Vf上的权重,然后使用快速傅里叶逆变换(ifft(·))将其转换到原始域,并采用模运算来获得频率注意力特征。此外,我们还引入了一个频率残差连接来增加频率信息,并且最后融合特征以产生频率特征X1f,其被公式化为:
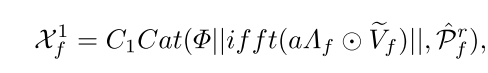
其中Cat(·,·)和Cat(·,·)是连接和矩阵乘法。Φ·表示模运算。eVf是整形的Vf。
FSA:首先经过fft得到 qkv,然后用注意力公式计算即可,再ifft转到空间域;此外还经过fft、卷积(weight)、ifft 得到的特征与注意力后的特征残差连接。最后卷积,输出。
空间自注意力SSA。考虑到伪装物体的不固定尺寸,在空间自注意力中嵌入了丰富的情境信息。与FSA类似,以特征P为输入,对位置信息进行1×1卷积编码,然后利用3×3和5×5的两个深度可分离卷积,得到自注意所需的查询Q、密钥Ks和值Vs。然后,通过重构的Qes s和Kes s生成注意力图(aΛs,aΛs= Sof(eQs ⊙ eKs)),并利用Softmax函数激活。随后,使用激活的注意图aΛs来校正Vs的权重。此外,为了增加空间局部信息(Pr s,P r s=Cat(DC3 P,DC5 P)),我们执行残差连接以生成空间特征Xr s,如所示:
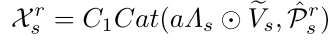
SSA:同样的先卷积、深度可分离卷积,得到特征qkv,再用注意力公式;同时input还单独做深度可分离卷积,然后与注意力后的特征残差连接,最后卷积,输出。
纠缠前馈网络。频率和空间特征通常包含不同的信息。频域主要关注信号的全局能量分布和变化,而空间信息则作用于局部像素级细节和空间结构,所有这些对于理解伪装物体至关重要。在EFFN中,这些特征被看作是两种状态,它们可以在纠缠过程中进行纠缠学习,以获得更鲁棒和更强的表示。具体地说,我们首先将全局频率特征X1f和局部空间特征X1s进行纠缠,使其相互适应,然后进行残差连接,得到综合特征X1c,即X1c = X1s + X1f +P128 ψ,对综合特征X1c进行层归一化,提高稳定性,然后对归一化后的特征X 1c(X1c =LN(X1c))在EFFN中进行非线性纠缠学习。
这里其实是一条路走深度可分离卷积,一条走fft转频域再加权,然后激活,残差连接,得到的两个特征cat到一起再走两条路:深度可分离卷积和fft、加权、ifft,再cat、卷积,输出。
双域反向解析器 DRP
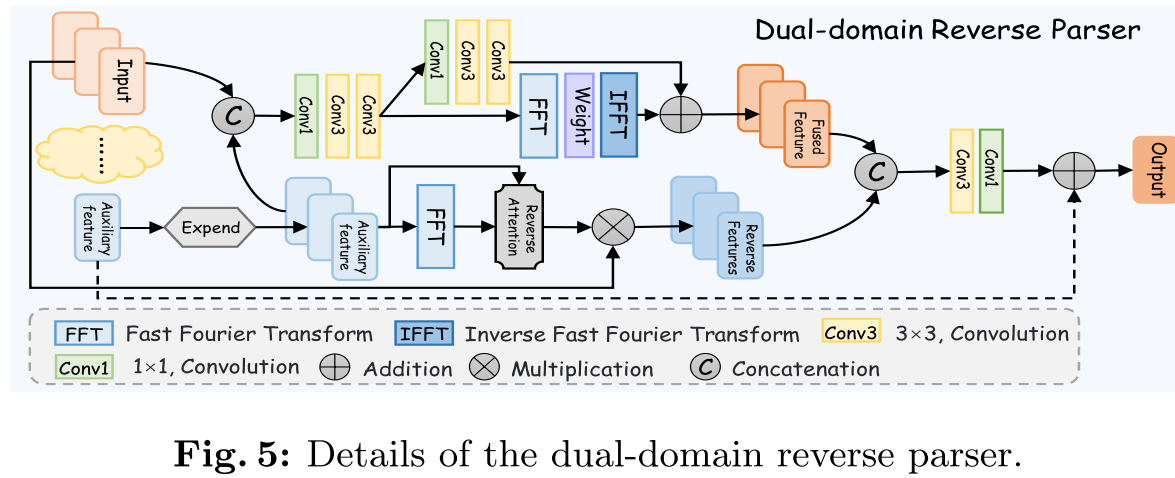
双域反向解析器(DRP),它在频域和空间域中优化和聚合来自多级特征X的各种信息。首先取特征X4作为优化目标,并使用高级语义特征P5作为辅助目标。DRP由两个分支组成,在第一个分支中,首先扩展辅助特征P5的通道以匹配优化目标的维度,并将这些特征聚合得到特征I4,即,I4=Con(Cat(Ex(P5),X4)),其中Ex(·)表示将通道扩展到128,Con(·)表示1×1卷积和2个3×3卷积。然后将特征I4分离到空间域和频率域。在频域中执行快速傅立叶变换(fft(·))和快速傅立叶逆变换(ifft(·)),并采用一系列卷积运算(Con(·))来优化空间域中的特征。随后,它们被聚合以获得融合特征N1 4,即,
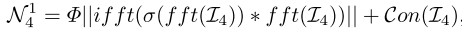
其中,Φ·表示模运算。“+”表示元素加法。在第二个分支中,我们产生混合反向注意力图(Ar,Ar=(1-Sig(P5))+(1-Sig(Φ|| FFT(P5)||),其中Sig(·)表示Sigmoid函数。与其他方法不同,反向注意图(Ar)包含丰富的频率-空间信息,以有效地获得反向特征N2 4,即,N2 4 =Ar * X4。接下来,整合特征N1 4和N2 4以生成最终特征N4,即N4= C3 Cat(N1 4,N2 4)+P5。随后,Ni+1将继续优化特征Xi(i = 1,2,3)作为所提出的DRP中的辅助目标。
这里每个模块的输入很奇怪,每一级都不一样,就是有本层处理的特征和上一层的特征,还有更高层的特征。所以1:有1234,2:有234,3:有34,4:有45(这就离谱为啥3不要5,不可解释)。首先除了本层处理后的特征reshape,再把它们所有都cat到一起,经过卷积处理后,再分别经过卷积和fft那一套,然后相加,(这里跟代码又不一致,代码里直接经过卷积后的特征和未经过卷积直接fft的);其中辅助特征还经过fft,取反,再与前面聚合的特征cat,再卷积,与input的本层特征相加,输出。
损失采用BCE和IoU,深度监督。
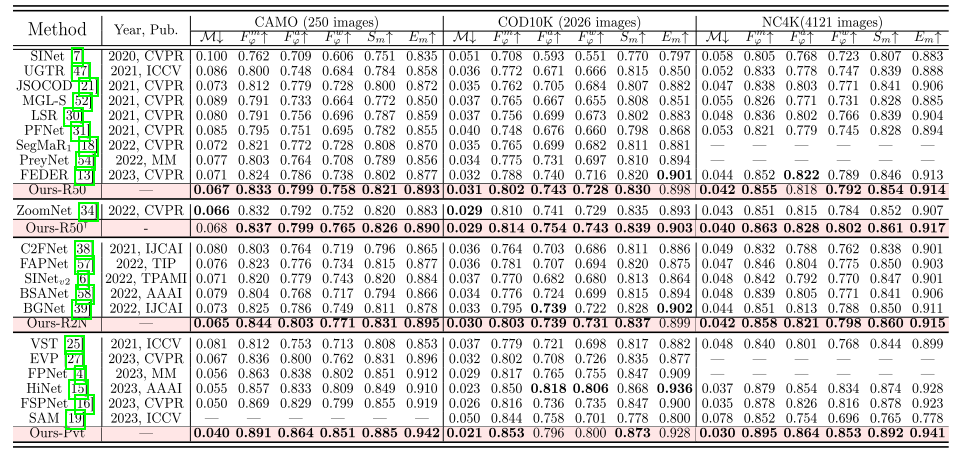
好复杂的网络结构设计,不懂为什么这样堆叠堆叠就起作用了。
版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/60755.html