
参考&鸣谢
(一)玩命死磕Java内存模型(JMM)与Volatile关键字底层原理
众所周知,语言使用虚拟机屏蔽了平台差异,避免像那样直接与操作系统接触,从而做到了无视平台,一次编译到处运行!为此,程序想要运行,必须跑在之上,示意图如下:

在运行期间,会把自己管理的内存划分为以上区域(运行时数据区),每个区域有着各自的用途,在程序运行时会发挥着不同的作用。而运行时数据区总共可划分为线程私有区、线程共享区两大块,下面来简单说说各大区域具体作用。
方法区(Method Area)
方法区(在之后被更改为元数据空间),该区域属于线程共享区,又称(非堆)内存,主要用于存储已被虚拟机加载的类信息、常量、静态变量、编译后的代码缓存等数据。值得注意的是:在方法区中有一个叫运行时常量池()的区域,它主要用来存放编译器生成的各种字面量和符号引用,这些内容会在类加载完成后载入到运行时常量池中,以便后续使用。
该区域有可能导致异常,根据虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出异常。
JVM堆(Java Heap)
堆也属于线程共享的内存区域,它在虚拟机启动时创建,是所管理的内存中,最大的一块,主要用来存放对象实例,几乎的所有对象都在这里分配内存(注意这里用的是“几乎”,有些对象不一定在堆中)。
堆空间是垃圾收集器管理的主要区域,因此很多时候也被称做堆,如果在堆中没有空闲内存提供给新对象分配时,此时就会触发回收;如若经过后依旧没有空闲内存,并且堆空间也无法再扩展时,将会抛出异常。
程序计数器(Program Counter Register)
程序计数器属于线程私有区域,是一小块内存空间,主要作为线程所执行的行号指示器。字节码解释器工作时,通过改变这个计数器的值,来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能,都需要依赖这个计数器来完成。
主要作用其实就是因为时间片在调度线程工作时,会“中断/挂起”某个线程的操作,让另外一个线程开始工作,当“中断”的线程重新被再次调度时,如何得知上次执行到那行代码了?就是靠程序计数器来得知上次执行的位置。
虚拟机栈(Java Virtual Machine Stacks)
虚拟机栈也属于线程私有区,它有着另一个名字叫:线程栈,操作系统在创建线程时分配,虚拟机栈的总数与线程数对应,主要在执行方法时,作为临时内存区域使用。
当线程开始执行一个方法时,会先创建一个栈桢来存储方法的的变量表、操作数栈、动态链接、返回值、返回地址等信息。每个方法从调用至结束,对于一个栈桢在虚拟机栈中的入栈和出栈过程,如下:

本地方法栈(Native Method Stacks)
本地方法栈属于线程私有的数据区域,该区域跟所编写的方法相关,会在本地方法栈中,维护一张本地方法登记表,当有线程需调用方法时,这里会登记是哪个线程调用了哪个本地方法/接口,并不会在本地方法栈中直接发生调用,这里只是做个调用登记,而真正的调用,需要通过本地方法接口去调用本地方法库中编写的函数。
一般情况下,我们无需关心此区域,因为在虚拟机中,和虚拟机栈已经合二为一了。
之所以说这些的内容,是为了让大家搞清内存模型,和内存模型是完全两个不同的概念。内存模型是程序在运行期间的数据区域,对于操作系统来说,它本质还是存在于主内存之中。
则是语言与硬件架构层面的概念,主要作用是规定硬件架构与语言的内存模型,并不存在具体的代码,而仅仅只是一种规范,并不能说是某些技术实现。
(简称)内存模型,本身是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。
由于运行程序的实体是线程,每个线程创建时,都会为其分配工作内存,用于存储线程私有的数据。而内存模型中,规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问。当线程想对一个变量进行赋值/运算等操作时,必须在工作内存中进行。
为此,当线程想操作变量时,首先要将变量从主内存拷贝的自己的工作内存,然后对变量进行操作,操作完成后,再将变更后的值刷写回主内存。也就是说:线程不能直接操作主内存中的变量,为了避免造成数据污染问题,必须将主内存中的变量,拷贝到工作内存中。
有些小伙伴会疑惑:Java中线程在操作一个对象时,对象不应该是在堆中吗?栈内不是只能存对象的引用地址吗?这时线程是直接在堆上操作的吗?
这里简单说一下,当线程操作一个对象时,会先根据引用地址去找到主存中的真实对象,然后会将对象拷贝到自己的工作内存再操作……(因为任何一个对象,都是由基本数据组成的)。如果当操作的对象较大时,比如一个的对象,这时并不会完全拷贝,而是将自己需要操作的那部分成员拷贝回来。
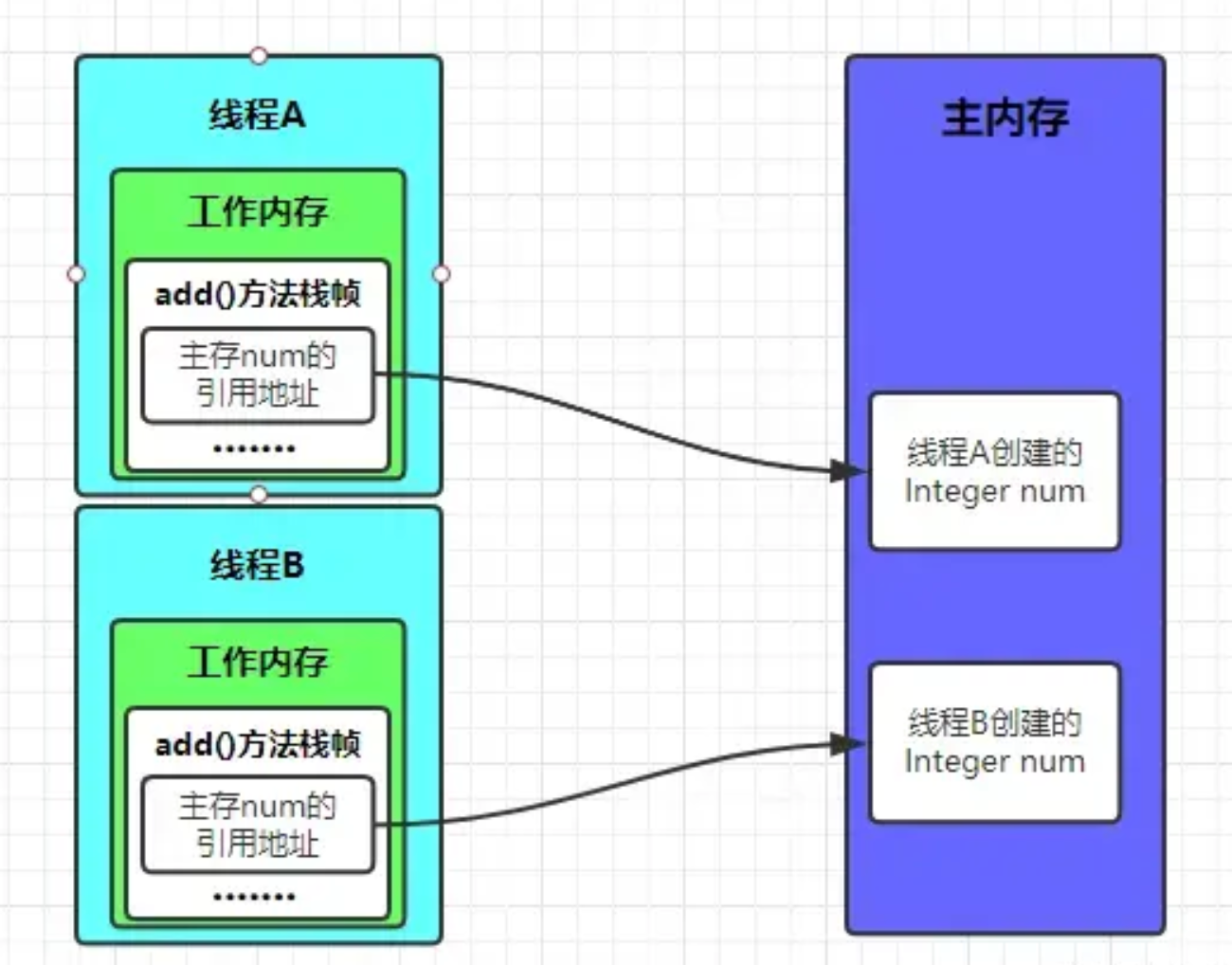
前面说过,工作内存是每个线程的私有数据区域,因此不同的线程间,无法访问对方的工作内存,线程间的通信(传值)必须要靠主内存来完成,其简要访问过程如下图:
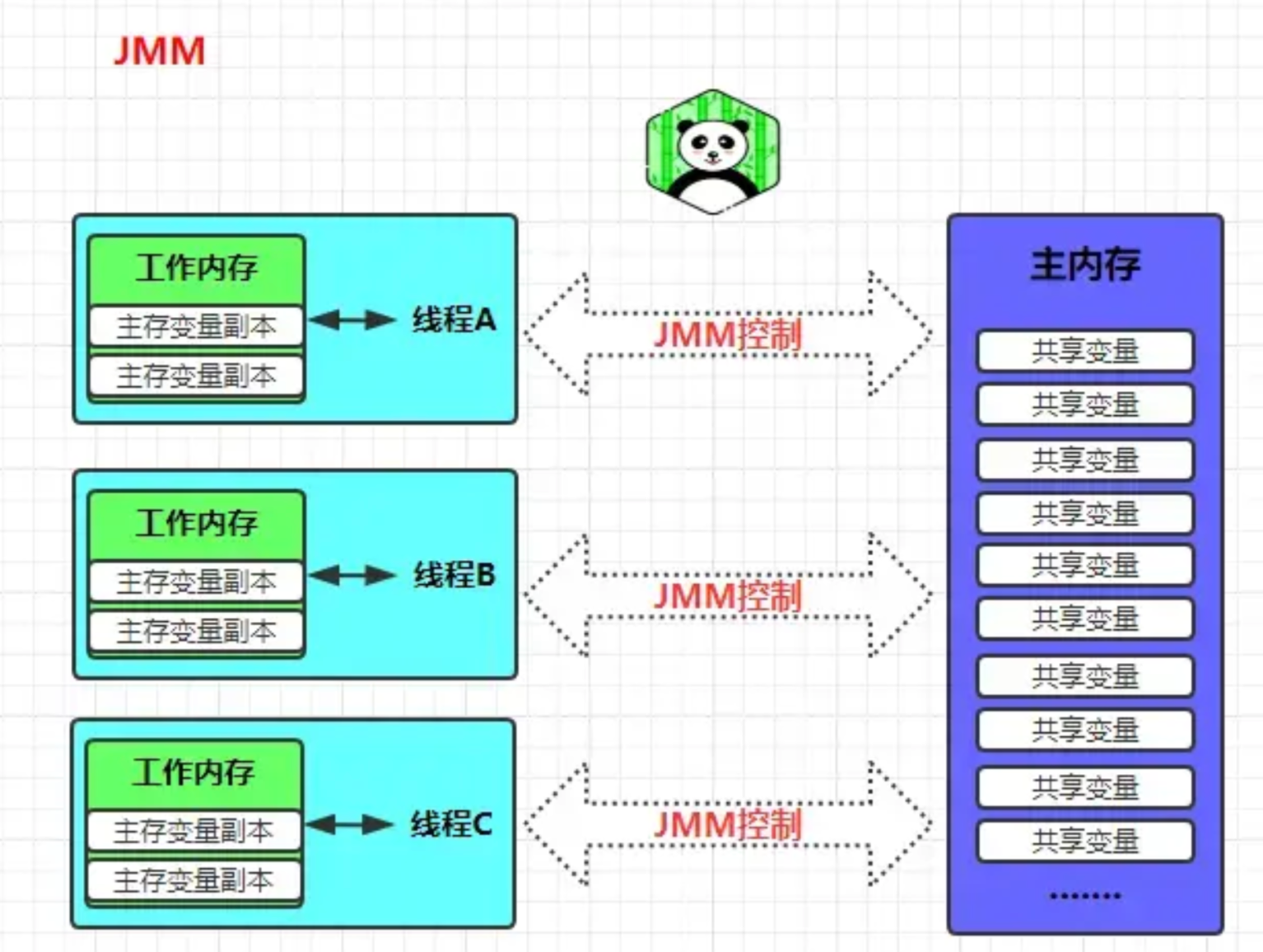
重点注意:与内存区域,这是两个不同层次的概念,在理解时,请不要带着内存模型的思维去理解。更恰当的说:描述的是一组规则,通过这组规则控制程序中,各个变量在共享数据区域和私有数据区域的访问方式,是围绕原子性、有序性、可见性拓展延伸的。
与内存区域唯一相似点就是:都存在共享数据区域和私有数据区域。或许在某些地方,我们可能会看见主内存被描述为堆内存,工作内存被称为线程栈,这个说法虽不是那么专业,可是要表达的含义大致相同,下面来具体说说中的主内存和工作内存。
主内存
在中,主内存属于线程共享区,从某个程度上讲,主存应该包括了堆和方法区。
主要存储的是共享数据,不管是类的成员变量、还是方法中的局部变量,又或者共享的类信息、常量、静态变量等数据,包括所有线程创建的实例对象,都会被存放在主内存中(除开栈上分配的对象)。
由于属于共享数据区域,多条线程对同一个数据进行非原子性操作时,就会发生线程安全问题。
工作内存
工作内存则属于线程私有区,从某个程度上讲,应该包括程序计数器、虚拟机栈以及本地方法栈。
主要存储当前方法的所有本地变量信息,每个线程的工作内存对其它线程不可见,比如的工作内存中,存储着主内存中拷贝回来的某个共享变量副本,这对于线程也是不可见的。
就算是两个线程执行的是同一段代码、同一个方法,它们也只会在各自的工作内存中,创建属于当前线程的本地变量、字节码行号指示器、相关方法等信息,而不会两者之间共用一块内存的数据。
注意:由于工作内存是每个线程的私有数据,线程间无法相互访问工作内存,线程之间的通讯需要依赖于主存,因此存储在工作内存的数据不存在线程安全问题。
工作内存与主内存的关系
弄清楚主内存和工作内存后,接着了解一下两者的数据存储类型及操作方式。
根据虚拟机规范,对于一个实例对象的成员方法而言,如果方法中包含的本地变量(局部变量),是八大基本数据类型,这将直接存储在工作内存的栈帧结构的局部变量表中。
倘若本地变量是引用类型,那么该对象的在内存中的具体引用地址,将会被存储在工作内存的栈帧结构的局部变量表中;而具体的实例对象,将存储在主内存(共享数据区域:堆)中。但对于实例对象的成员字段,不管是基本数据类型,还是等包装类型,又或者是引用类型,都会被存储到堆区(栈上分配除外)。
至于变量以及类本身相关信息将会存储在主内存中。
需要注意的是:在主内存中的实例对象可以被多条线程共享,倘若两条线程同时调用同一个类的、同一个方法,那这两条线程需要将操作的数据,拷贝一份到自己的工作内存中,在工作内存运算完成后,才刷新到主内存,简单示意图如下所示:
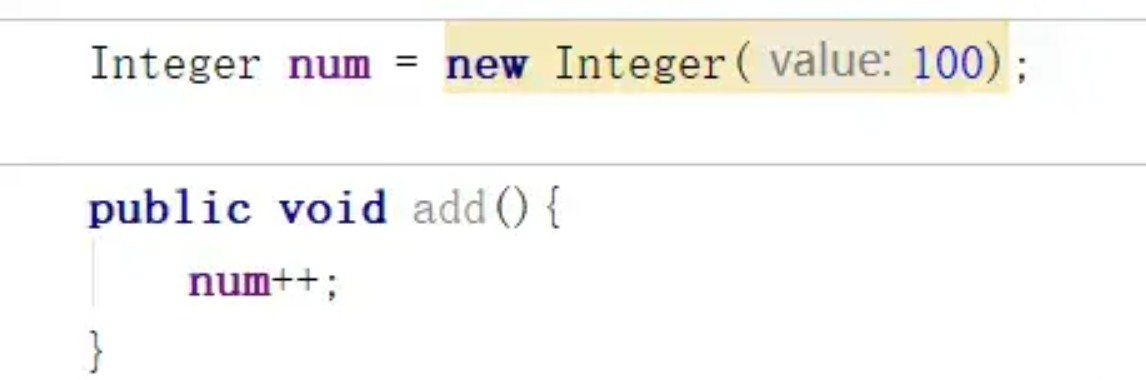
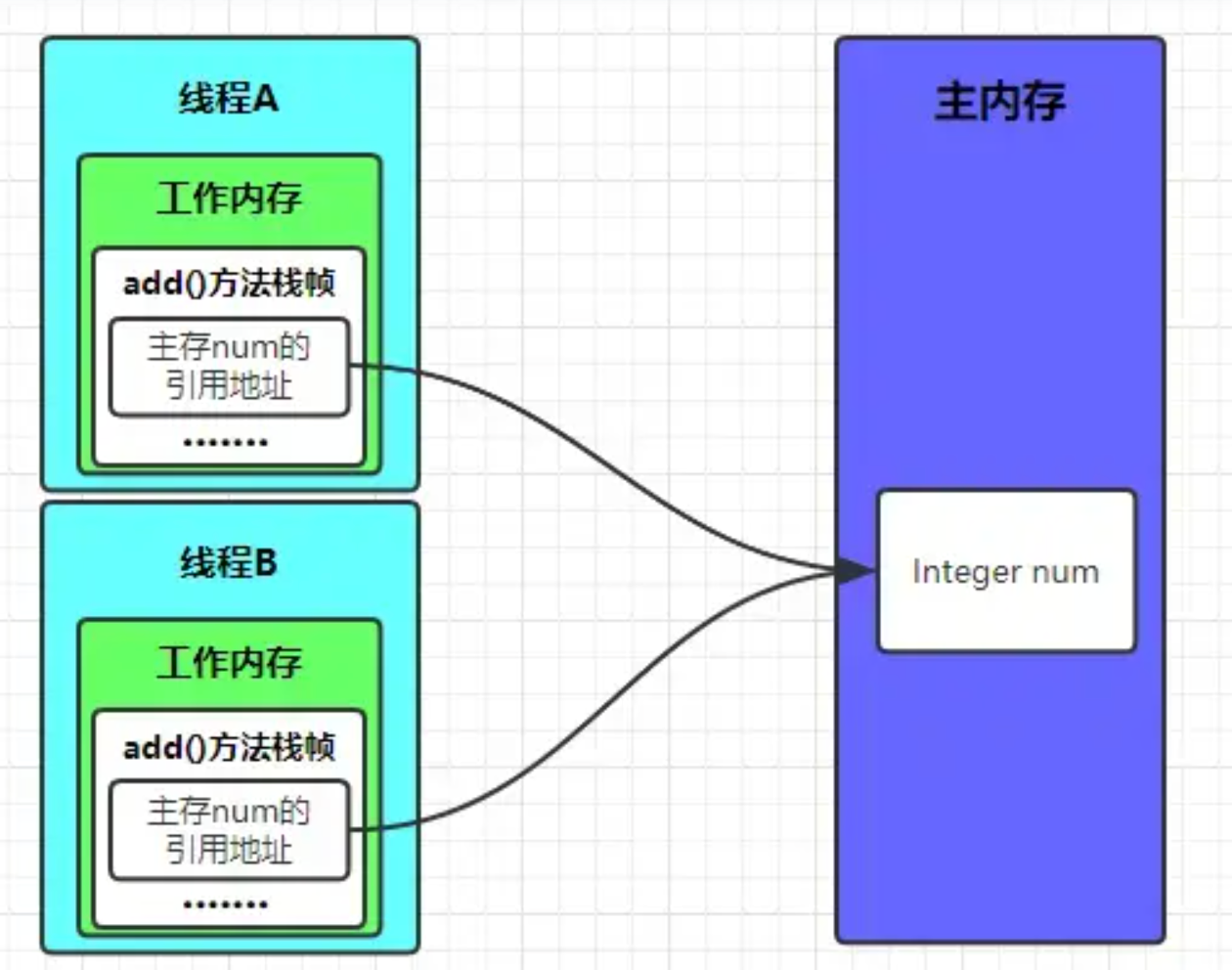
方法内的局部变量操作:
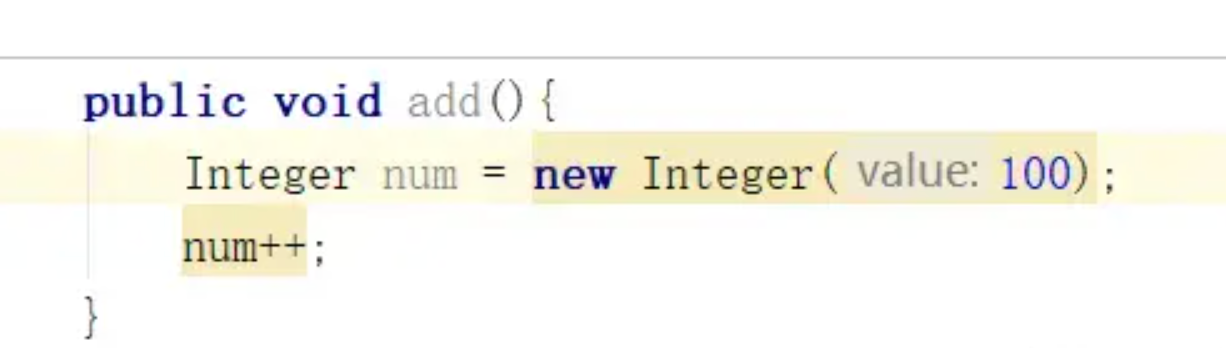
在 Java 中,JVM 内存模型(JVM Memory Model)和 Java 内存模型(Java Memory Model, JMM)都是关于内存的关键概念,但它们处于不同层级,解决的问题也不同。
JVM 内存模型 关注的是运行时的内存结构,将内存划分为方法区、堆、程序计数器、虚拟机栈和本地方法栈。这些内存区域在 JVM 中具有特定的用途,比如方法区存储类信息和常量,堆则是对象实例的主要存放区。程序计数器用于跟踪当前线程的执行进度,虚拟机栈和本地方法栈则用来维护每个线程的方法调用状态和本地方法信息。这种结构使 JVM 能高效地分配和管理资源,支持线程的并发执行和垃圾回收。
Java 内存模型(JMM) 则专注于多线程环境下的内存交互规则。JMM 通过主内存和工作内存的模型,定义了线程如何在主内存和自己私有的工作内存之间进行数据的存取和更新,来确保数据一致性。JMM 通过约束原子性、有序性和可见性来解决多线程场景下的内存可见性问题,使得在并发编程中,开发者可以明确和安全地管理线程间的数据共享。
通过了解 JVM 和 JMM 内存模型,我们能够更好地理解 Java 线程是如何管理和访问内存的,尤其是在并发编程中,理解这些规则能帮助开发者在设计程序时避免线程间数据冲突,提高并发程序的健壮性和性能。
到此这篇jvm内存模型图(jvm内存模型 知乎)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/60706.html