
广度优先搜索 (Breadth First Search),又叫层次遍历或宽度优先搜索,通常是以二叉树或图作为研究对象,先从上往下对该二叉树的每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完当前层才进入下一层,直到没有结点可以访问为止。
【leetcode-102】给你二叉树的根节点 ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
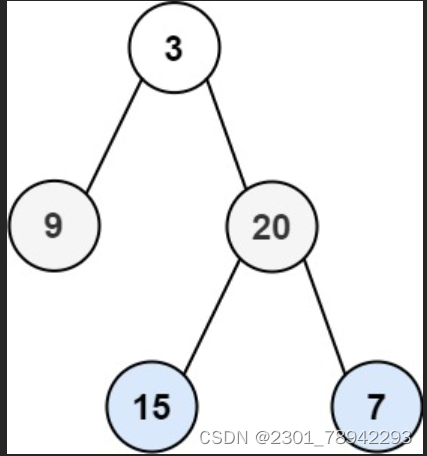
3.1.1 大致思路
创建两个vector,分别为cur和next,其中cur含有当前访问层中的所包含的节点,next含有cur(极next的上一层)的各个节点的左右子节点,创建一个数组vals用来储存各个节点的值。遍历cur中的每个节点,将其每个节点的子节点放入next中,如果是nullptr就不放(这样的话,直到该二叉树的最后一层,将不再有子节点,也可以成为循环的符合条件),同时,将cur中的每个节点的节点值放到vals中,遍历结束后将cur替换成next就可以才是下一轮的遍历了,知道cur中不再有节点为止。
3.1.2 具体步骤
1 声明一个cur的数组,并使其初始化含有root节点;
2 以cur数组中存在节点为条件,开始外层循环;
3 声明一个数组vals用来储存cur数组个各个节点的值;
4 声明一个数组next以从左到右(或从右到左)的顺序,来储存cur的子节点;
5 开始内层循环用来将cur数组中的节点的值放入vals中,并且将cur中的各个子节点的存放到next中;
6 离开内层循环(仍在外层循环内),开始善后工作:将vals放入ans内,将cur数组用next来替换
3.1.3 代码
3.2.1 大致思路
利用队列这个数据结构(先进先出)的特性,将root节点放入队列中去,然后将其值赋个用来储存各个节点值的vals数组中,然后将该节点的各个子节点再放入相同的队列(即自己这个节点的后面),如此循环。
3.2.2 具体步骤
1 声明答案ans,一个存放节点的队列q,并将root节点放到q中去;
2 以队列q不是空的作为循环条件,开启外层循环用来依次存放当前层的节点;
3 声明一个用来储存各节点值的数组vals;
4 以队列中仍有节点为循环条件,开启内层循环用来遍历当前层的节点;
5 内层循环中,声明一个暂时的变量用来存放队列头部的节点;
6 存放完成后弹出头节点,并将头节点的值存放入vals中;
7 检查当前节点是否有子节点,如有,将其子节点放入队列
8 跳出内层循环(仍在外层循环中),将vals存放入ans中
3.2.3 代码
到此这篇广度优先搜索树(广度优先搜索方法的原理是从树的根结点开始)的文章就介绍到这了,更多相关内容请继续浏览下面的相关 推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/57157.html