
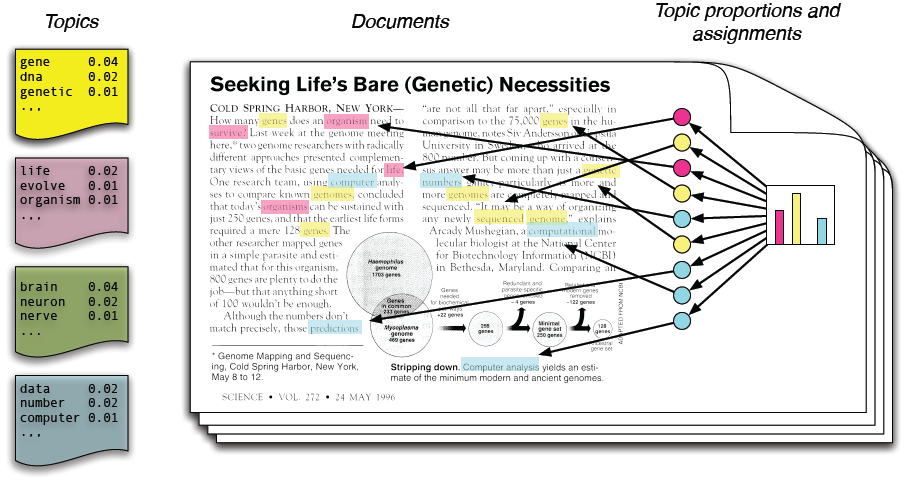
# 1. LDA主题建模简介
主题建模是一种无监督机器学习技术,用于从文本数据中发现隐藏的主题或模式。LDA(潜在狄利克雷分配)主题建模是一种流行的主题建模算法,它基于贝叶斯概率框架,假设文本数据是由一系列潜在主题生成的。
LDA主题建模的过程包括两个主要步骤:主题推断和主题解释。在主题推断阶段,算法通过迭代优化过程估计潜在主题及其在文本数据中的分布。在主题解释阶段,研究人员将推断出的主题与文本数据中的单词或短语联系起来,以理解主题的含义。
# 2. LDA主题建模在金融科技中的应用理论基础
2.1 LDA主题建模的原理和算法
LDA(潜在狄利克雷分配)主题建模是一种无监督机器学习算法,用于从文本数据中发现潜在主题。其原理是基于概率模型,假设文本数据是由一系列主题组合而成,每个主题由一组相关的词语表示。
LDA算法的具体步骤如下:
- 预处理:对文本数据进行预处理,包括分词、去停用词、词干化等。
- 构建文档-词语矩阵:将预处理后的文本数据转换为文档-词语矩阵,其中每一行代表一个文档,每一列代表一个词语,元素表示词语在文档中出现的次数。
- 初始化主题:随机初始化主题,每个主题由一组词语表示。
- 迭代采样:对于每个词语,根据其在文档中出现的概率和主题的概率分布,将其分配到一个主题。
- 更新主题:根据分配的词语,更新主题的概率分布。
- 重复迭代:重复上述步骤,直到算法收敛或达到预定的迭代次数。
2.2 LDA主题建模在金融科技中的适用性分析
LDA主题建模在金融科技领域具有广泛的适用性,原因如下:
- 文本数据丰富:金融科技领域产生大量的文本数据,包括新闻、报告、社交媒体帖子等。
- 主题提取需求:金融科技行业需要从文本数据中提取主题,以了解市场趋势、客户需求和风险因素。
- 无监督学习:LDA主题建模是一种无监督学习算法,不需要标记数据,这在金融科技领域尤为重要,因为标记数据成本高且耗时。
此外,LDA主题建模在金融科技领域还具有以下优势:
- 主题可解释性:LDA主题建模的结果以主题的形式呈现,这些主题由一组相关的词语表示,易于理解和解释。
- 主题动态性:LDA主题建模可以随着新数据的引入而更新,从而捕获文本数据中的动态变化。
- 可扩展性:LDA主题建模算法可并行化,适用于大规模文本数据集。
代码块:
python
import gensim
from gensim import corpora
# 预处理文本数据
documents = ["This is a document about finance.", "This is another document about technology."]
stopwords = gensim.parsing.preprocessing.STOPWORDS
texts = [[word for word in gensim.utils.simple_preprocess(doc) if word not in stopwords] for doc in documents]
# 构建文档-词语矩阵
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
# 初始化LDA模型
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=2, random_state=100)
# 打印主题
for idx, topic in lda_model.print_topics(-1):
print('Topic: {}
Words: {}'.form
到此这篇lda主题模型是什么领域的(lda主题分析是什么)的文章就介绍到这了,更多相关内容请继续浏览下面的相关推荐文章,希望大家都能在编程的领域有一番成就!版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/53790.html