
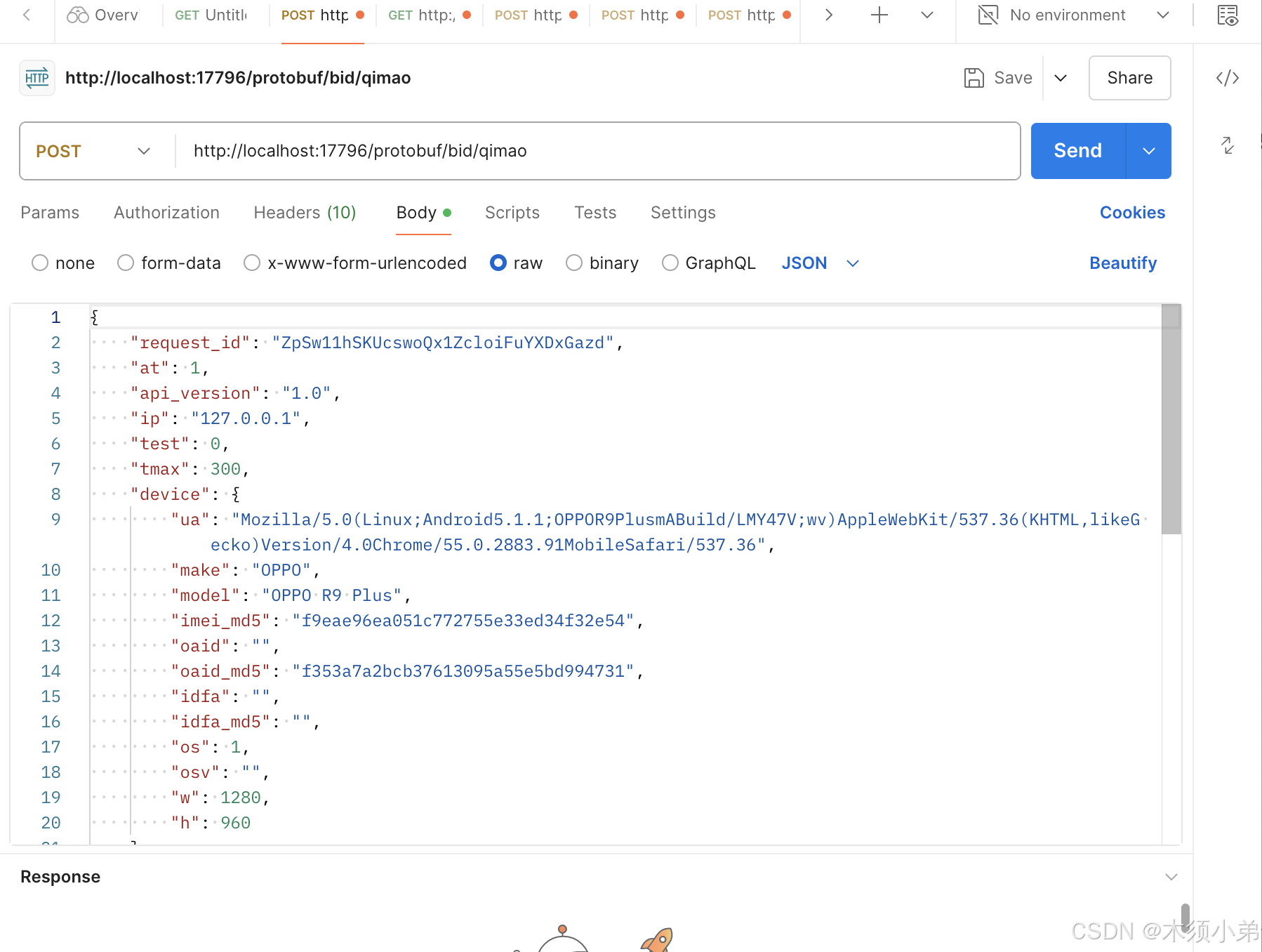
对方请求我们的接口是带protobuf的,是以protobuf形式的,
Protocol Buffers(通常简称为 Protobuf)和 JSON 都是用来序列化数据结构的
protobuf 通常产生更小的二进制数据,这在带宽受限的环境中尤为重要,如移动网络或物联网设备。由于 Protobuf 使用二进制格式,解析和序列化通常比 JSON 快得多
一、发送带json请求体的protobuf请求(真实的请求是不带/protobuf/的我们带这个,跳转到protobufController是想观察链路中参数的信息)
然后就会跳转到protocolbuf的controller里读取protobuf的配置文件,拿到这个配置文件的calss类的类名路径名等信息(QimaoADX)。根据URL截取出qimao adapter的名字。
二、通过反射获取一个protobuf请求对象(QimaoADX)
然后通过反射创建protobuf的请求对象。他先是使用class.forname,动态加载类,并返回类的class对象,拿到的protobuf的配置文件的类名,然后
Method method = clazz.getMethod("newBuilder");
获取这个类的newBuilder方法。clazz.getMethod("newBuilder")找到类中名为newBuilder的静态方法。
Object obj= method.invoke(null);
然后调用method的invoke方法执行这个newBuilder方法。
newBuilder是一种建造者模式,通常用于对象需要很多参数才能构建的情况,特别是当某些参数是可选的时候。
反射的好处:这样通过反射创建对象可以动态加载类,如果我们不用反射,而是直接new一个对象,那这个对象就是写死到class文件,在程序运行前就让类加载器加载了。
但是如果我们用了反射,我们就可以动态加载,按需加载。我们可以用Class.forName()让类加载器加载我们想要的类,用到哪个模块就加载哪个模块。
三、将postman请求的json对象转为protobuf的消息
使用ProtobufUtils.json2pb方法。
message = ProtobufUtils.json2pb(json, reqMessage);
四、根据请求头中的url,拼接一个不带protobuf的url,再用HttpUtils.sendHttpRequest发送一遍http请求。
因为有的媒体是发给我们protobuf类型的,有的直接发json类型的,所以要统一到json类型处理
因为我们接收的请求有的是带protobuf的,所以我们要统一到解析请求体的controller里,就要将url中protocol去掉,再用HttpUtils.sendHttpRequest发送一遍http请求。

我们就到了AdxController
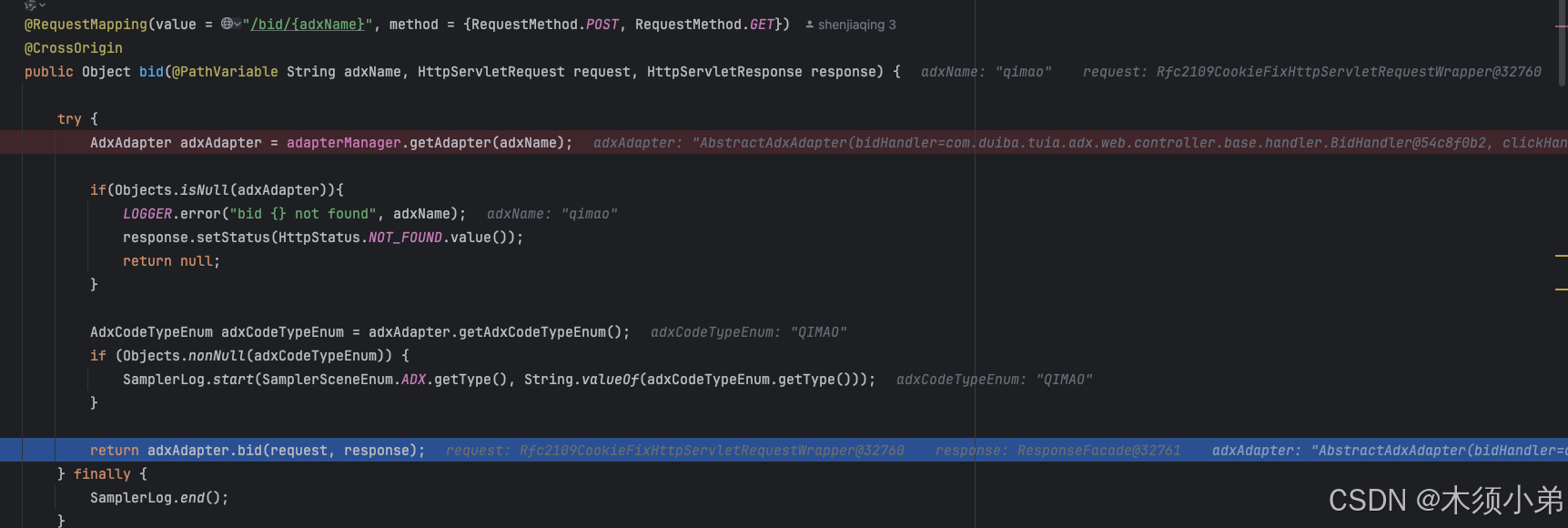
在这里就是抽象的bid竞价方法,win胜出方法,exposure曝光方法,click点击方法(点击广告要走的逻辑)。
在bid方法里,我们根据名称获取到QimaoAdapter,执行
return adxAdapter.bid(request, response);
就会去到QimaoAdapter的bid方法里,而这里是调用父类的bid方法。

我们就到了AbstractAdxAdapter的bid方法
五、在这个抽象的AdxAdapter中实现具体方法。
1、用具体的BidRequest构建CommonBidRequest
首先,我们要建立一个通用请求对象CommonBidRequest,然后把请求体里的数据和对象(Imp、Device、geo)塞入CommonBidRequest,注意有些字段是必须传入的不然构建返回体的时候没东西构建。
这里就涉及到很多业务上的知识,不完全理解业务的话这里就不知道怎么写了。比如我们要接收的json要包含string类型的广告id外,还要有很多对象,比如广告资源位描述对象,App信息,设备信息等,而device对象里除了有设备的操作系统等字符串,还要有geo地理位置对象,这个地理位置对象里面还要包含经纬度,国家代码等信息。
2、用CommonBidRequest对象执行竞价链路得到commonBidResponse(redis,布隆过滤器,Lua)
在这里创建一个竞价请求上下文对象,对竞价请求解析里面的参数,自定义过滤器和设置广告底价,还创建了一个布隆过滤器,记录当前请求的设备号和请求次数。然后经过一系列参数的set和一些算法,得到CommonBidResponse。
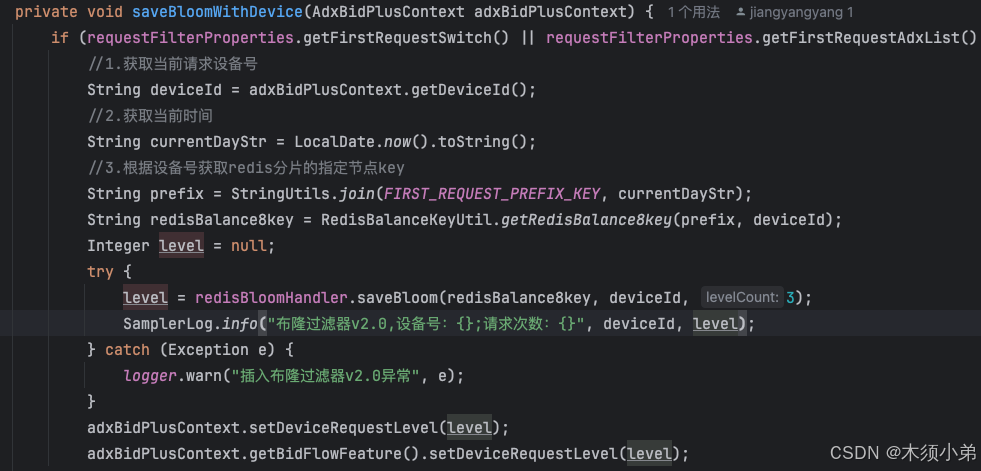
布隆过滤器具体操作:
布隆过滤器是在redis里实现的,redisBloomHandler 是一个负责与 Redis 交互并操作布隆过滤器的类的实例,当 saveBloom 方法被调用时,它会在 Redis 中对应的键 redisBalance8key 下操作键对应布隆过滤器(redis里有很多布隆过滤器),将 设备id经过hash算法添加进去。
1、根据设备id,调用RedisBalanceKeyUtil.getRedisBalance8key方法,把设备id进行md5哈希运算,然后使用特定的哈希算法对哈希值处理,得到一个Redis的哈希键。
在redis里使用md5生成键名有几个好处:
1⃣️性能优化:使用MD5散列可以实现键值的均匀分布,从而优化Redis的性能。这是因为MD5产生的散列值分布均匀,有助于负载均衡,减少热点问题。
2⃣️安全性:虽然MD5在密码学上被认为不安全,但在生成Redis键名时,它仍能提供一定程度的安全性,防止恶意用户通过构造特定的键名来影响系统的性能或稳定性
3⃣️键名一致性:MD5提供了一种将任意长度的字符串转换为固定长度的十六进制字符串的方法。这有助于确保键名的一致性
2、对大规模设备信息,使用布隆过滤器快速检查设备是否存在然后记录设备号和请求次数。用得到的Redis哈希键作为键,设备id作为值,调用saveBloom方法传入布隆过滤器。
使用布隆过滤器的好处:
1⃣️节省内存:相比传统的数据结构(如哈希表),布隆过滤器占用的内存空间要少得多。
2⃣️快速查询:布隆过滤器的查询操作非常快,几乎与集合大小无关,只依赖于位数组的大小和哈希函数的数量。
3⃣️避免存储大量设备ID:在广告领域,尤其是处理大量设备请求时,直接存储所有设备ID及其请求记录会消耗大量的内存资源。
4⃣️处理高并发请求:布隆过滤器非常适合处理高并发场景下的请求过滤,它可以在不造成显著延迟的情况下,快速响应大量请求。
在saveBloom中,写了一个Lua脚本,设置设备的请求次数,防止并发请求修改设备请求次数。帮助redis高效插入数据。
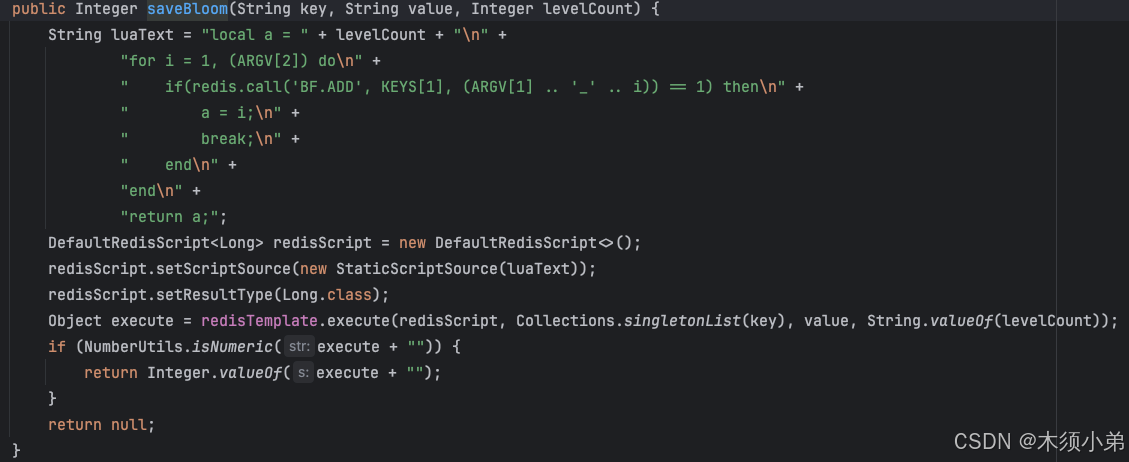
使用Lua脚本的好处:
1、减少网络开销。
本来我们在Redis里面需要去执行三四个命令,但是在Lua脚本里面我们只需要调用一个就可以达到我们的目的。
2、Redis里面,对Lua脚本执行是一个原子性的操作,要么同时执行,要么同时失败。
3、具有复用性。
使用Lua脚本限制请求次数
- 原子性:Lua脚本在Redis中执行时是原子的,这意味着在脚本执行期间不会有其他命令插入或修改数据。这对于计数操作非常重要,避免了并发问题。
- 逻辑集中:可以在一个脚本中完成多个操作,比如检查设备ID是否存在、增加请求计数、判断计数是否超过阈值等。
- 减少网络开销:将多个操作放在一个脚本中执行,减少了客户端和Redis之间的通信次数。
3、把commonBidResponse转化为广告主想要返回的类型QimaoAdx.PriceResponse
这里我们就执行类似解析出请求体里的类型到公共类型的逻辑。这里是根据广告主发给我们的他想要的参数字段的文档,构建一个返回值。
六、返回一个Byte[]类型的字节数组。里面是返回的广告主想要的返回内容

七、通过反射创建一个protobuf响应对象

八、通过工具类将byte数组转换成postman可识别的json对象
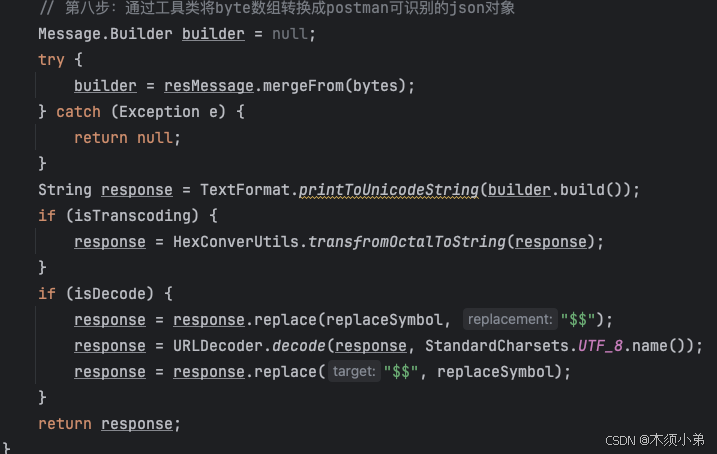
这一步是方便我们在postman里看protobuf的参数的。
其实真实的请求是不走protobufController的,直接走AdxController。


版权声明:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若内容造成侵权、违法违规、事实不符,请将相关资料发送至xkadmin@xkablog.com进行投诉反馈,一经查实,立即处理!
转载请注明出处,原文链接:https://www.xkablog.com/bcyy/39141.html